







csv
CSV (Comma Separated Values),即逗号分隔值(也称字符分隔值,因为分隔符可以不是逗号),是一种常用的文本格式,用以存储表格数据,包括数字或者字符。很多程序在处理数据时都会碰到csv这种格式的文件。python自带了csv模块,专门用于处理csv文件的读取,后缀名是.csv。
在爬虫和很多案例里面都会把数据写到csv文件里,爬虫下来的数据会用于数据分析,对数据进行持久化处理(保存),读取数据用到的就是csv,然后进行数据分析。
csv模块的使用
写入csv文件
- 1 通过创建writer对象,主要用到2个方法。一个是writerow,写入一行。另一个是writerows写入多行
- 2 使用DictWriter 可以使用字典的方式把数据写入进去
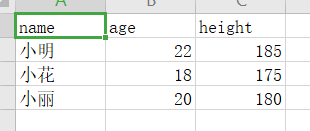
例题:按图示的样式存入数据,第一列是姓名,标题为姓名,年龄,身高。
#导入库
import csv
#待写入的数据,放到列表里,可以用元组,也可以用字典格式
# 第一种方法
person = [
('小明', 22, 185), ('小花', 18, 175), ('小丽', 20, 180)
]
#写入的表头
header = ('name', 'age', 'height')
# w 写的模式,用newline=""来消除空行
# 用wps打开没有问题,但是用office打开会出现乱码,把'utf-8'改为'utf-8-sig'
with open('person.csv', 'w', encoding='utf-8-sig', newline="") as f:
write = csv.writer(f)
write.writerow(header) #写入表头
# for i in person:
# write.writerow(i) # 方法一 writerow,遍历出每一条数据,分别写入
write.writerows(person) # 方法二 writerows,直接写入数据
# 第二种方法,以字典的形式传入
person = [
{'name': "小明", 'age': '22', 'height': '185'},
{'name': "小花", 'age': '18', 'height': '175'},
{'name': "小丽", 'age': '20', 'height': '180'}
]
# key跟表头一一对应
header = ('name', 'age', 'height')
with open('dic_per.csv', 'w', encoding='utf-8', newline="") as f1:
DictWrite = csv.DictWriter(f1, header)
DictWrite.writeheader()
DictWrite.writerows(person)
with open(),第一个参数传入文件名和文件类型,第二个参数是模式,是读还是写入,默认的是读"r",可写可不写,第三个参数是中文的编码。as f ,给写文件的操作重新命名,把with open 赋值给f,后面用新命名调用。 把写入的对象赋值给write,用对象的写入方法进行操作,第一行写入表头,后面遍历每一个列表的元素,分别写入文件;后续再文件进行操作的时候一定要先把文件关闭,否则会提示没有权限操作文件。写入的文件会有空行,可以用newline="“来消除空行。用wps打开文件是没有问题的,用office打开会出现乱码的情况,这是把编码方式改为"utf-8-sig”。用csv.DictWriter()方法的时候,后面要传两个参数,第二个是表头。
with open就是相当于f.open()和f.close(),自动关闭文件;如果不用with 需要在代码尾部再输入f.close()。
读取文件
- 1 通过reader()读取到的每一条数据是一个列表。可以通过下标的方式获取具体某一个值
- 2 通过DictReader()读取到的数据是一个字典。可以通过Key值(列名)的方式获取数据
# 读取文件
# 方法一:
with open('dic_per.csv', 'r', encoding='utf-8') as wr:
f1 = csv.reader(wr)
print(type(f1), f1) # <class '_csv.reader'> <_csv.reader object at 0x000002124DB0E8D0>
for i in f1:
print(i) # 以列表的形式输出,可以用下标取值
print(i[0]) # 通过下标取列表的值,取出第一列
# 方法二:
with open('person.csv', 'r', encoding='utf-8') as wr:
f = csv.DictReader(wr)
print(type(f), f) # <class '_csv.reader'> <_csv.reader object at 0x000002124DB0E8D0>
for i in f:
print(i) # 以列表的形式输出,可以用下标取值
print(i['name']) # 通过关键字取列表的值,取出第一列
# 方法三:
# 导入pandas
import pandas as pd
# .表示当前路径
data = pd.read_csv(open('./person.csv'))
# 绝对路径为从盘符开始的,也可用绝对路径,要注意对每一个"\",都要多加一个"\"进行转义,或用r开头
print(data)
"."表示当前路径,从盘符开始的为绝对路径。
正则案例-爬取天气预报
用户需求
目标url:http://www.weather.com.cn/weather/101180801.shtml
从url里爬取开封7天的天气情况,在爬取之前先看一下爬取的数据是否在网页源码中,如果在,就是静态加载的网页,只需要向url发送请求,获取网页源码中的数据,从而提取出我们需要的数据就可以了。

在页面点右键,查看网页源代码,在里面可以看到,7天的天气信息(日期 天气状况 温度 风力)都在源码中。
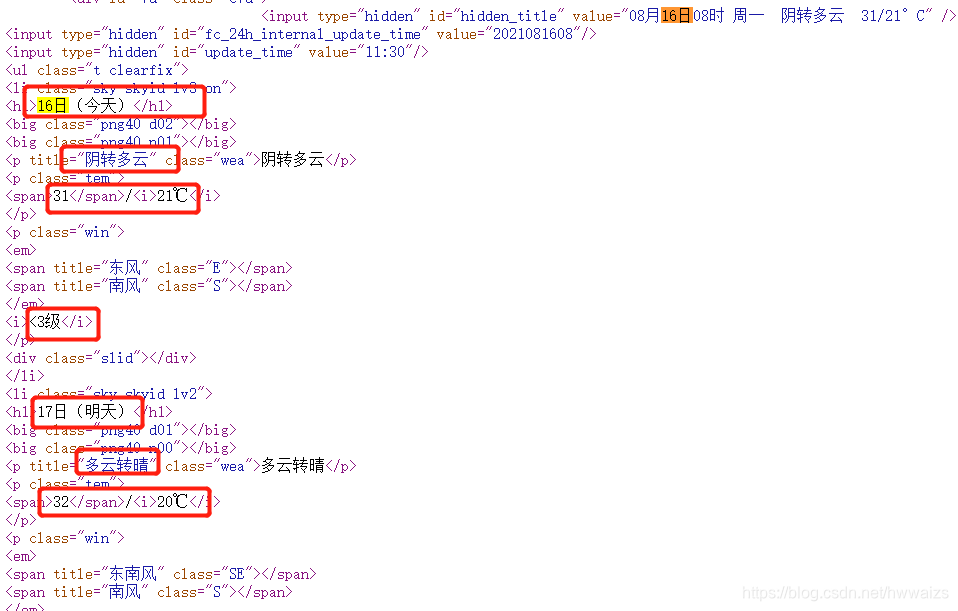
页面分析
在16日(今天)的框内,点右键,检查,在Elenents里面可以看到16日天气的情况,把相应的标签逐级点开,可以看到需要的数据。
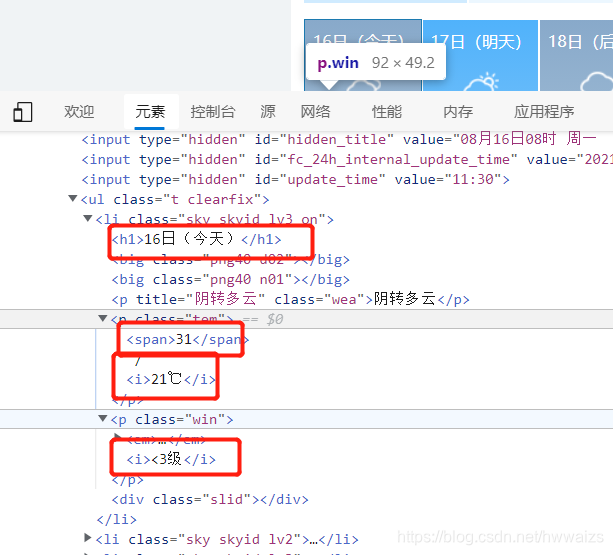
光标分别移动到下面6个li上,经过的每一个li代表每天的天气,对应的天气标签处于高亮的状态,可以看到每一个li对应每一天的天气情况。当光标位于"<div id ="7d">" class=7处,所有的标签都处于高亮。
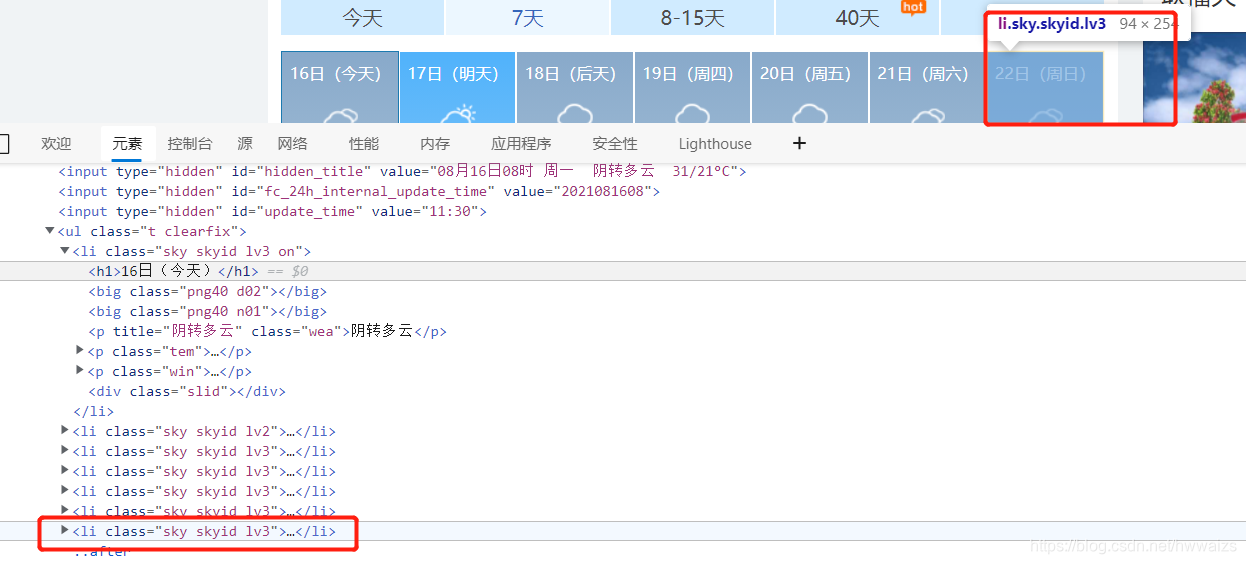
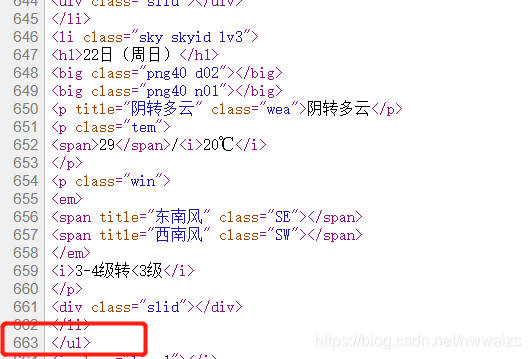
在Elenents里面看到的效果是经过最终渲染的,并不等同于网页源码,进一步确认一下,可以复制·class=“t clearfix”·,到源码里查看一下。一般从<ul开头,到下一个<\ul>结束的位置,中间的数据都是需要的。
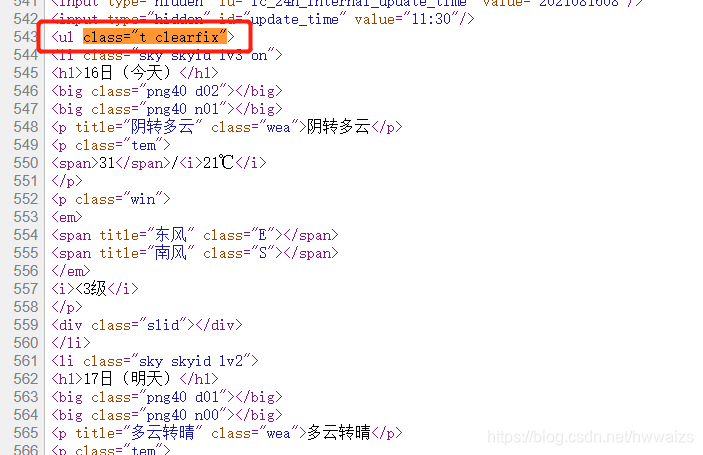
<ul class="t clearfix">
<li class="sky skyid lv3 on">
<h1>16日(今天)</h1>
<big class="png40 d02"></big>
<big class="png40 n01"></big>
<p title="阴转多云" class="wea">阴转多云</p>
<p class="tem">
<span>31</span>/<i>21℃</i>
</p>
<p class="win">
<em>
<span title="东风" class="E"></span>
<span title="南风" class="S"></span>
</em>
<i><3级</i>
</p>
<div class="slid"></div>
</li>
<li class="sky skyid lv2">
<h1>17日(明天)</h1>
<big class="png40 d01"></big>
<big class="png40 n00"></big>
<p title="多云转晴" class="wea">多云转晴</p>
<p class="tem">
<span>32</span>/<i>20℃</i>
</p>
<p class="win">
<em>
<span title="东南风" class="SE"></span>
<span title="南风" class="S"></span>
</em>
<i><3级</i>
</p>
<div class="slid"></div>
</li>
<li class="sky skyid lv3">
<h1>18日(后天)</h1>
<big class="png40 d07"></big>
<big class="png40 n02"></big>
<p title="小雨转阴" class="wea">小雨转阴</p>
<p class="tem">
<span>32</span>/<i>22℃</i>
</p>
<p class="win">
<em>
<span title="东南风" class="SE"></span>
<span title="南风" class="S"></span>
</em>
<i><3级</i>
</p>
<div class="slid"></div>
</li>
<li class="sky skyid lv3">
<h1>19日(周四)</h1>
<big class="png40 d07"></big>
<big class="png40 n08"></big>
<p title="小雨转中雨" class="wea">小雨转中雨</p>
<p class="tem">
<span>31</span>/<i>24℃</i>
</p>
<p class="win">
<em>
<span title="南风" class="S"></span>
<span title="南风" class="S"></span>
</em>
<i>3-4级转<3级</i>
</p>
<div class="slid"></div>
</li>
<li class="sky skyid lv3">
<h1>20日(周五)</h1>
<big class="png40 d07"></big>
<big class="png40 n00"></big>
<p title="小雨转晴" class="wea">小雨转晴</p>
<p class="tem">
<span>31</span>/<i>22℃</i>
</p>
<p class="win">
<em>
<span title="北风" class="N"></span>
<span title="东南风" class="SE"></span>
</em>
<i>3-4级转<3级</i>
</p>
<div class="slid"></div>
</li>
<li class="sky skyid lv3">
<h1>21日(周六)</h1>
<big class="png40 d02"></big>
<big class="png40 n02"></big>
<p title="阴" class="wea">阴</p>
<p class="tem">
<span>31</span>/<i>25℃</i>
</p>
<p class="win">
<em>
<span title="南风" class="S"></span>
<span title="东南风" class="SE"></span>
</em>
<i><3级转3-4级</i>
</p>
<div class="slid"></div>
</li>
<li class="sky skyid lv3">
<h1>22日(周日)</h1>
<big class="png40 d02"></big>
<big class="png40 n01"></big>
<p title="阴转多云" class="wea">阴转多云</p>
<p class="tem">
<span>29</span>/<i>20℃</i>
</p>
<p class="win">
<em>
<span title="东南风" class="SE"></span>
<span title="西南风" class="SW"></span>
</em>
<i>3-4级转<3级</i>
</p>
<div class="slid"></div>
</li>
</ul>
实现过程
- 1.向目标url发送请求,拿到整个的网页源代码数据(html文件)
- 2.从源码中找到<ul标签(正则,过滤到不相干的数据),继续解析li标签,再从中匹配处需要的内容(正则)
- 3.最后把提取的内容做持久化操作(csv),保存到本地
用到的工具: requests模块(请求数据),re正则(匹配数据),csv模块(写入数据)
实现步骤
有时候 url正常,headers正常,也发起了请求,解析不到数据,这时候需要从返回的内容里查找一下是否有需要的数据。
import re
import requests
import csv
url = 'http://www.weather.com.cn/weather/101180801.shtml'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36 Edg/92.0.902.62'
}
# 1.向目标url发送请求,获取网页源码
res = requests.get(url, headers=headers)
html = res.content.decode('utf-8')
# print(html)
# 2.解析数据,去源码中匹配ul标签
rpt = r'.*?(<ul class="t clearfix">.*?<i class="line1"></i>).*?'
# <ul class="t clearfix">在源码中只有一个,通过分组对匹配到的数据进行过滤。.*?非贪婪模式,re.S换行匹配,如果group()里不传参数,打印的还是所有的内容。
zz1 = re.match(rpt, html, re.S).group(1)
# print(zz1)
# 继续解析li标签里的数据,ul里面的li标签有多个,所以要进行多值匹配,用findall。
data = re.findall(r'.*?<h1>.*?</li>.*?', zz1, re.S)
# print(data)
# 存储所有数据的大列表
lst_data = []
for i in data:
# # print(i)
# # print('*'* 50)
pat = re.compile(r'.*?<h1>(.*?)</h1>.*?<p.*?>(.*?)</p>.*?<i>(.*?)</i>.*?<i>(.*?)</i>.*?', re.S)
li_data = pat.match(i)
# print(li_data.group(1), end=" ")
# print(li_data.group(2), end=" ")
# print(li_data.group(3), end=" ")
# print(li_data.group(4), end=" ")
# print()
li_dict = {'日期': li_data.group(1), '天气': li_data.group(2), '温度': li_data.group(3), '风力': li_data.group(4)}
# print(li_dict)
lst_data.append(li_dict)
header = ['日期', '天气', '温度', '风力']
with open('kaifengtianqi.csv', 'w', encoding='utf-8', newline="") as f:
write = csv.DictWriter(f, header)
write.writeheader()
write.writerows(lst_data)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









