







爬取古诗文网
需求
爬取网页中诗词的数据,爬取每首诗的名字、作者、朝代和诗词的内容
页面分析
爬取页面的诗词,复制任意诗词的内容,在网页源码中可以找到,说明网页是静态加载出来的,说明显示的url就是爬取的目标,可以直接用url获取数据。目标url:https://www.gushiwen.cn/。
任意选择一首诗词的标题,点右键检查,会发现标题的内容存放在p标签下的a标签内。

标签折叠到p标签内,可以看到第一个p标签里存放的是诗词的标题,第二个p标签存放的是作者和朝代,下面的div标签里存放的是诗词的内容。

继续往上折叠标签,我们会发现,每一首的诗词都存放在div[@class=“sons”]的标签里,而所有的诗词内容都存放在div[@class=“left”]的标签里

翻到页面底部,发现需要进行翻页操作,点击下一页找到url,试着把后面的2改为1,可以进入第一页的界面。
https://www.gushiwen.cn/default_2.aspx 第二页
https://www.gushiwen.cn/default_1.aspx 第一页
也可以通过下面的输入数字进行跳转页面,两种方法都可以
https://www.gushiwen.cn/default.aspx?page=2 第二页
https://www.gushiwen.cn/default.aspx?page=1 第一页
代码实现
1.创建scrapy项目
我这里pycham的项目目录在D盘,进入cmd,输入cd回车,输入D:回车,把路径切换到D盘,把项目的目录复制进去回车就进入到了项目文件目录下。输入scrapy startproject +项目名称,创建完成后 输入cd + 项目名称 进入项目内部,输入 scrapy genspider + 爬虫文件名 + 网站域名,创建爬虫文件。
2.进行文件的配置
settings.py
LOG_LEVEL = 'WARNING'
BOT_NAME = 'prose'
SPIDER_MODULES = ['prose.spiders']
NEWSPIDER_MODULE = 'prose.spiders'
ROBOTSTXT_OBEY = False
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36 Edg/92.0.902.62'
}
ITEM_PIPELINES = {
'prose.pipelines.ProsePipeline': 300,
}
如果要使用另一个py文件中的变量、方法可以通过导入类的方式导入到使用的py文件中
方法一:直接导。默认pycharm打开的目录为根目录,一级一级的导入。from day22.mySpider.mySpider.items import MyspiderItem
方法二:自己设定根目录。在需要设定根目录的文件夹处点右键,Mark Directory as —> Sources Root,导入的时候 用import 文件夹名 就可以了,如 from mySpider.items import MyspiderItem

右键点击下一页,发现下一页在a标签内,里面href的值是下一个url的地址,我们可以通过href的属性值来实现翻页处理

3.其他运行文件
启动程序
start.py
from scrapy import cmdline
# cmdline.execute(['scrapy', 'crawl', 'gsw']) # 方法一
cmdline.execute('scrapy crawl gsw'.split(" ")) # 方法二
管道文件
pipelines.py
import json
class ProsePipeline:
# 第一种方法:
# def process_item(self, item, spider):
# # print(item) # 测试一下管道是否接收到数据,接收到就能打印
# item传过来是对象,要先强转为字典,再转为json格式的字符串,nsure_ascii=False处理中文的
# item_json = json.dumps(dict(item), ensure_ascii=False)
# with open('prose.txt', 'a', encoding='utf-8') as f:
# f.write(item_json + '\n')
# return item
# 第二种方法
def open_spider(self, spider):
self.f = open('prose.txt', 'w', encoding='utf-8')
def process_item(self, item, spider):
# print(item) # 测试一下管道是否接收到数据,接收到就能打印
item_json = json.dumps(dict(item), ensure_ascii=False)
self.f.write(item_json + '\n')
return item
def close_spider(self, spider):
self.f.close()
items.py
import scrapy
class ProseItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
author = scrapy.Field()
dynasty = scrapy.Field()
comtents = scrapy.Field()
pass
爬虫文件
gsw.py
import scrapy
from prose.items import ProseItem # 导入items里的ProseItem类
class GswSpider(scrapy.Spider):
name = 'gsw'
allowed_domains = ['gushiwen.cn']
start_urls = ['http://gushiwen.cn/']
def parse(self, response):
div_sons = response.xpath('.//div[@class="left"]/div[@class="sons"]')
for div_son in div_sons:
# 古诗文的标题
title = div_son.xpath('.//b/text()').get()
# 古诗文的作者和朝代
# getall() 返回的是列表,可以根据索引取值
# 这时要注意xpath的路径里如果不加".",数据会有异常,重复打印
# 在各首诗之间会有其他内容,找到的会是空值
try:
name = div_son.xpath('.//p/a/text()').getall()
author = name[0] # 作者
dynasty = name[1] # 朝代
# extract()等价于getall()
# xpath得到的数据是个列表,列表元素的首和尾有空格,用strip()去掉首位的空格
# 用""空字符串拼接列表元素,返回字符串
contson = div_son.xpath('.//div[@class="contson"]/text()').extract()
comtents = ''.join(contson).strip()
# 第一种方法:字典的形式
# item = {}
# item['title'] = title
# item['author'] = author
# item['dynasty'] = dynasty
# item['comtents'] = comtents
# 第二种方法:实例化对象的方式。导入items里的ProseItem类,在类里提前创建几种方法
item = ProseItem(title=title, author=author, dynasty=dynasty, comtents=comtents)
# print(item)
yield item # 发送给管道
except:
print(title)
next_page = response.xpath('.//a[@id="amore"]/@href').get()
# print(next_page)
# 如果取到了下一页的数据,就做翻页处理
if next_page:
# 第一种方法:
# req = scrapy.Request(next_page)
# yield req # 返回给引擎,重复发送给调度器、下载器、爬虫程序、管道等一系列操作
yield scrapy.Request(
url=next_page, # 获得的url给哪个函数解析的,用callback
# callback=self.parse # 回调函数,默认的当前函数,如果还用当前函数进行解析,可省略。
)
打印界面会有空值,因为网页中各诗词间有图片等其他内容,找到的为空。
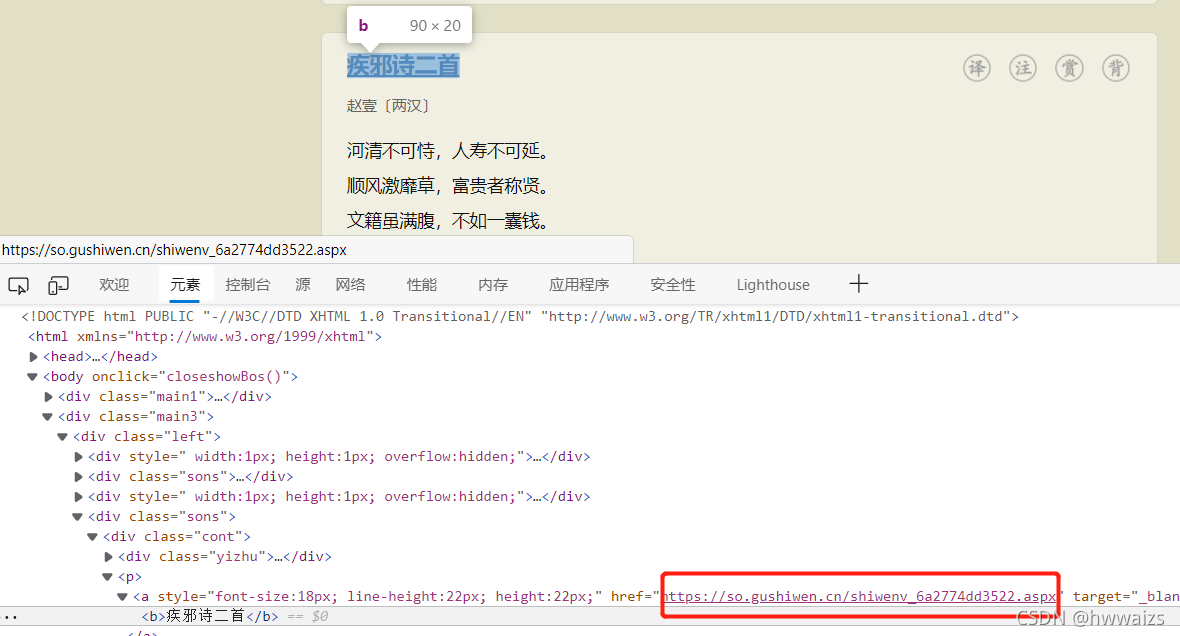
4.爬取译文
通过页面检查,发现古诗以及译文的内容都在网页源码中,因此只需要对原来的url发起请求就可以获得数据。对诗文的题目点右键,检查可以发现,在p标签下的a标签里有译文内容的url,若要获取译文,只需要对这个url发起请求就可以了。
gsw.py
import scrapy
from prose.items import ProseItem # 导入items里的ProseItem类
class GswSpider(scrapy.Spider):
name = 'gsw'
allowed_domains = ['gushiwen.cn']
start_urls = ['http://gushiwen.cn/']
def parse(self, response):
div_sons = response.xpath('.//div[@class="left"]/div[@class="sons"]')
for div_son in div_sons:
# 古诗文的标题
title = div_son.xpath('.//b/text()').get()
# 获取详情页面你的url,xpath返回的是se'le
detail_url = div_son.xpath('.//p/a/@href').get()
# 古诗文的作者和朝代
# getall() 返回的是列表,可以根据索引取值
# 这时要注意xpath的路径里如果不加".",数据会有异常,重复打印
# 在各首诗之间会有其他内容,找到的会是空值
try:
name = div_son.xpath('.//p/a/text()').getall()
author = name[0] # 作者
dynasty = name[1] # 朝代
# extract()等价于getall()
# xpath得到的数据是个列表,列表元素的首和尾有空格,用strip()去掉首位的空格
# 用""空字符串拼接列表元素,返回字符串
contson = div_son.xpath('.//div[@class="contson"]/text()').extract()
comtents = ''.join(contson).strip()
# 第一种方法:字典的形式
# item = {}
# item['title'] = title
# item['author'] = author
# item['dynasty'] = dynasty
# item['comtents'] = comtents
# 第二种方法:实例化对象的方式。导入items里的ProseItem类,在类里提前创建几种方法
item = ProseItem(title=title, author=author, dynasty=dynasty, comtents=comtents, detail_url=detail_url)
# print(item)
# yield item # 发送给管道
yield scrapy.Request(
url=detail_url,
callback=self.parse_url,
meta={'items': item}
)
except:
print(title)
# next_page = response.xpath('.//a[@id="amore"]/@href').get()
# # print(next_page)
# # 如果取到了下一页的数据,就做翻页处理
# if next_page:
# # 第一种方法:
# # req = scrapy.Request(next_page)
# # yield req # 返回给引擎,重复发送给调度器、下载器、爬虫程序、管道等一系列操作
# yield scrapy.Request(
# url=next_page, # 获得的url给哪个函数解析的,用callback
# # callback=self.parse # 回调函数,默认的当前函数,如果还用当前函数进行解析,可省略。
# )
# 解析详情页面的数据(译文)
def parse_url(self, response):
item = response.meta['items']
translate = response.xpath('.//div[@class="contyishang"]/p/text()').getall()
item['translate'] = ''.join(translate).strip()
print(item)

















 1024
1024

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









