







介绍
Storm是一个实时并行计算系统。对比与经典的hadoop,storm的优势就在于实时性。简单来说,hadoop可以用来对海量的数据进行批量的处理,但这些数据是静态的,处理过程中不会对新产生的数据进行处理。当处理完之后,hadoop进程就可以结束,并输出最终结果。而storm的进程会持续的运行,不存在一个终结状态。一旦有新的数据到来,storm就出对其进行处理,然后继续等待其他的数据。而我们可以随时查看其运行状态并获取当前结果。这也就是我们所说的流式处理。
日志处理就是流式处理的一个典型场景。每天每个服务器都在持续不断的产生新的日志,如果是采用hadoop,可能会采用定时任务的方式,每几分钟或者每小时或者每天来对当前产生的日志进行批量处理。这样做得弊端是显而易见的,日志的产生并不存在这样一个时间节点,上一小时和下一小时产生的日志本质上是连续的。如果强行的定义一个时间点的话,则可能将两端时间之间的联系性给消除。而storm则可以持续不断的对日志进行处理和输出,产生一个连续的结果,更能够反映出日志中的本质现象。
作为一个持续性的进程,对性能和稳定性的要求也会更高。因为不像hadoop,本身处理时间较短,出现差错可以随时重启,损失不大。对于storm来说,一旦出现意外中断,将意味着相当一段时间的数据积累被销毁。因此,storm本身在容错性方面也提供了较为完善的机制。
拓扑(topology)
拓扑(topology)是storm对其并行任务的一个定义,其相当于hadoop中的mapreduce任务。正如前面所说,一个mapreduce任务最终是会停止的,而一个拓扑任务将永远运行下去。在拓扑中,节点分为两类:spout和bolt。简单来说,spout负责生产数据,bolt负责处理并传递数据。而数据则是以元组(tuple)的方式进行传递的。
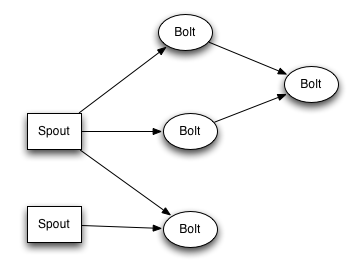
在这个拓扑图中,两个spout可以看成是两种不同的数据来源。而在第一级的bolt中,上面两个可以看成同一个bolt,第三个则属于另外一种bolt,他们对数据的需求和处理方式是相互不影响的。这也是storm的另一个优势,在一个拓扑中,你可以包含多种多样的任务,同时进行处理。这样既能很好的满足不同的需求,又能够保证性能上的优势。在storm中,对于一个单一的任务,数据的流动应当呈现出单向性,即spout->bolt1->bolt2->…。而每一个bolt则可以根据机器性能,对实际的单元个数进行设置。这样一来,storm就可以保证每个数据都经过了相同的处理。
对于数据从spout/bolt流向下一级的bolt的过程,storm提供了分组的特性。可以定义如何对tuple进行合理的划分(例如,在统计词汇数目的时候,把相同的单词分发到同一个bolt中去):
- 随机分组(Shuffle grouping):随机分发tuple到Bolt的任务,保证每个任务获得相等数量的tuple。
- 字段分组(Fields grouping):根据指定字段分割数据流,并分组。例如,根据“user-id”字段,相同“user-id”的元组总是分发到同一个任务,不同“user-id”的元组可能分发到不同的任务。
- 全部分组(All grouping):tuple被复制到bolt的所有任务。这种类型需要谨慎使用。
- 全局分组(Global grouping):全部流都分配到bolt的同一个任务。明确地说,是分配给ID最小的那个task。
- 直接分组(Direct grouping):这是一个特别的分组类型。元组生产者决定tuple由哪个元组处理者任务接收。
集群
storm集群中的节点分为两种:nimbus和supervisor。和大部分的分布式系统类似,nimbus作为主节点,负责任务分发,状态监控,错误恢复等管理技能。而supervisor则作为worker执行具体的,其中,每一个supervisor中的拓扑是总拓扑的一个子集。而nimbus会管理这些supervisor,来构成一个完整的拓扑任务。
配置
storm在github上有源码,但是我在使用的过程中,出现了编译问题。在这里,还是更加推荐去http://www.apache.org/dyn/closer.lua/storm/apache-storm-0.10.0/apache-storm-0.10.0.tar.gz下载稳定的release版本。
对于0.10.0版本,请务必使用java1.7,否则会出现编译问题。
下载并解压后,创建conf/storm.yaml文件,写入如下内容:
storm.zookeeper.servers:
- "localhost"
storm.zookeeper.port: 2181
nimbus.host: "localhost"
storm.local.dir: "/tmp/storm"
storm.log.dir: "/tmp/storm/logs"
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
其中,storm.local.dir是storm保存集群信息的地方,storm.log.dir是log的输出目录。其他参数可根据具体情况进行配置。
storm.yaml这个文件创建完后,一定要将其复制到“~/.storm/storm.yaml”中去,如果是root则是“/root/.storm/storm.yaml”,否则这些配置文件将不能被正确的读取。
接着,如果zookeeper已经启动了的话,就可以通过bin/storm nimbus和bin/storm supervisor来分别启动nimbus和supervisor节点了。同时,还可以通过bin/storm ui来在本地的8080端口开启一个ui界面,用来查看storm的实时状态。
最后,如果已经打包好了拓扑任务,就可以通过bin/storm jar [path-to-jar] [main-class]来启动任务了。
storm编程
使用storm编程,相对于链接jar来说,使用maven更加方便。如下是我的一个maven配置文件,如果需要使用storm-kafka的话,请务必注意kafka的版本号(可以和实际的kafka版本号存在不同),否则会出现冲突。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<artifactId>storm</artifactId>
<groupId>org.apache.storm</groupId>
<version>0.10.0</version>
</parent>
<groupId>org.apache.storm</groupId>
<artifactId>storm-starter</artifactId>
<packaging>jar</packaging>
<name>storm-starter</name>
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.10</artifactId>
<version>0.9.0.1</version>
<exclusions>
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-kafka</artifactId>
<version>${project.version}</version>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>${project.version}</version>
<!-- keep storm out of the jar-with-dependencies -->
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/jvm</sourceDirectory>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>1.4</version>
<configuration>
<createDependencyReducedPom>true</createDependencyReducedPom>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
想要实现spout可以继承BaseRichSpout,然后对其中的三个方法进行重写即可
public class MySpout extends BaseRichSpout {
SpoutOutputCollector collector;
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
// 第一次运行需要做的事
}
@Override
public void nextTuple() {
// 产生一条数据
collector.emit(string)
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
//定义元组的结构
declarer.declare(new Fields("string"));
}
}
类似的,bolt的实现只需要继承BaseRichBolt即可
public class MyBolt extends BaseBasicBolt{
@Override
public void execute(Tuple tuple, BasicOutputCollector collector) {
// 产生一条数据
collector.emit(string)
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
//定义元组的结构
declarer.declare(new Fields("string"));
}
}
最后,就可以在main函数中,利用spout和bolt定义拓扑了
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("sentences", new RandomSentenceSpout(), 5);
builder.setBolt("split", new SplitSentence(), 8)
.shuffleGrouping("sentences");
builder.setBolt("count", new WordCount(), 12)
.fieldsGrouping("split", new Fields("word"));
storm本身提供了许多示例,这里推荐FastWordCountTopology作为开始。具体更加深入的编程技巧,请参考其范例集合。
storm-kafka
storm-kakfa 是一个storm提供的一个单独模块,因此,需要在pom.xml加上相应的dependency才行,这里上面已经给出。maven下载好之后,继承KafkaSpout进行使用就可以了。
这里引入了两个新的类:SpoutConfig和Scheme。其中,SpoutConfig是用来配置zookeeper对应的信息和zookeeper中的路径。在SpoutConfig中的最后一个参数是UID,用来标记当前的spoutconfig,可以通过UUI.randomUUID().toString()获取,但是必须保持不变,否则无法获取到上一次的offset信息。Scheme 则是用来定义如何处理从kafka获取的数据的,通常情况下,用SringScheme就足够了,它会默认将kafka处获得的信息转化成string发送出去。在调用构造参数获得SpoutConfig实例后,必须再次设置zkServers, zkPort 和zkRoot,否则storm-kafka将无法成功连接到zookeeper上。
public class MyKafkaSpout extends KafkaSpout {
public final static String TOPIC_SUBSCRIBED = "test";
public LogKafkaSpout() {
this(getSpoutConfig());
}
public LogKafkaSpout(SpoutConfig spoutConfig){
super(spoutConfig);
}
public static SpoutConfig getSpoutConfig() {
BrokerHosts hosts = new ZkHosts("localhost:2181");
// UID会记录之前的信息,不能随便改动
// 部分log信息会被打印到/tmp/d0cadc5f-7661-4ac5-b009-790210c4dfa5
SpoutConfig spoutConfig = new SpoutConfig(hosts, TOPIC_SUBSCRIBED, "/" + TOPIC_SUBSCRIBED, "d0cadc5f-7661-4ac5-b009-790210c4dfa5");
spoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme());
// 必须设置,否则storm-kakfa无法保存kafka对应的offset数值
spoutConfig.zkServers = new ArrayList<String>(){{add("localhost");}};
spoutConfig.zkPort = 2181;
spoutConfig.zkRoot = "/" + TOPIC_SUBSCRIBED;
return spoutConfig;
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("log"));
}
}















 2446
2446











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









