






目录
hbase在虚拟机手动操作就是shell操作,与之对应的是在idea或者其他java环境上进行java api操作,但结果都是一样的,都能实现客户需求。
命令汇总
| 命令 | 功能 | 命令 | 功能 |
| create | 创建表 | count | 统计行数 |
| put | 插入或更新数据 | delete | 删除指定的行或列的数据 |
| get | 获取指定行或列的数据 | deleteall | 删除整个行或者列的数据 |
| scan | 扫描表并返回表的数据 | truncate | 删除表的数据,结构还在 |
| describe | 查看表的结构 | drop | 删除整个表(包括数据和结构)慎用 |
需求
有以下的订单数据,要将其保存在HBase中
| 订单id | 订单状态 | 支付金额 | 支付方式id | 用户id | 操作时间 | 商品分类 |
| 001 | 已付款 | 200.5 | 1 | 1001 | 2021-3-1 18:01:40 | 手机 |
基本操作
创建表
语法:
create ‘表名’,’列簇名1’,’列簇名2’,..
说明:
create要小写
一个表可以包含多个列簇

查看表
语法:
list
describe ‘表名’

删除表

禁用表
语法:
disable ‘表名’
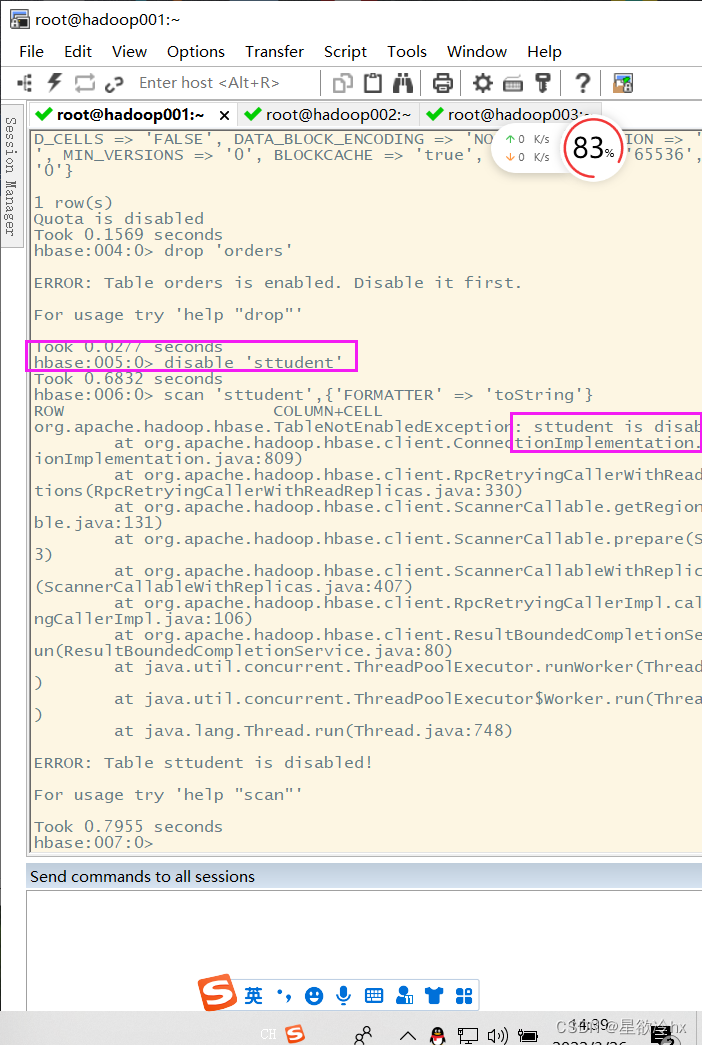
启用表
语法:
enable ‘表名’

数据操作
添加数据
语法:
put ‘表名’,’rowkey’,’列簇名:列名’,’值’


获取(查看)数据
语法:
get ‘表名’,’rowkey’

注意:
如果显示中文乱码,是因为hbase shell中显示中文是十六进制编码,要正确显示中文,需要添加选项,格式:
,{'FORMATTER' => 'toString'}

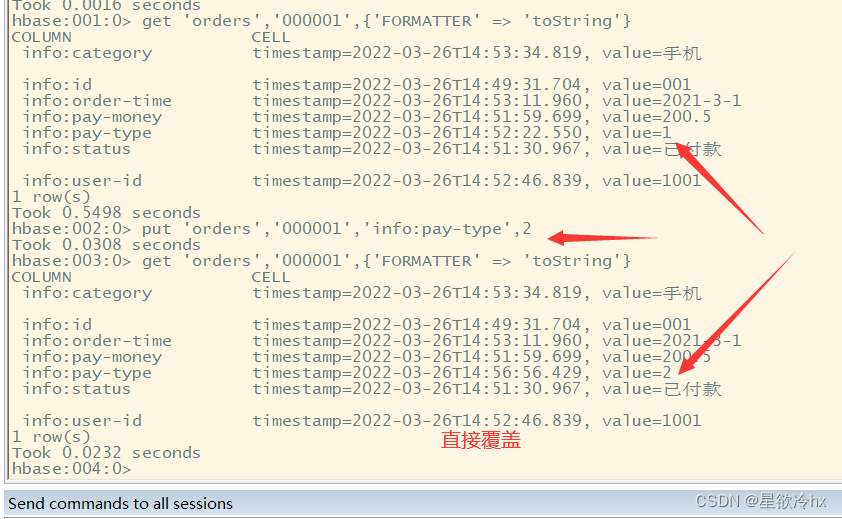
更新(修改)数据
语法:
put ‘表名’,’rowkey’,’列簇名:列名’,’新值’
注意
在HBase中会自动维护表中数据的版本
每执行一次put操作,都会生成新的时间戳
删除数据
删除指定的列
语法:
delete ‘表名’,’rowkey’,’列簇名:列名’
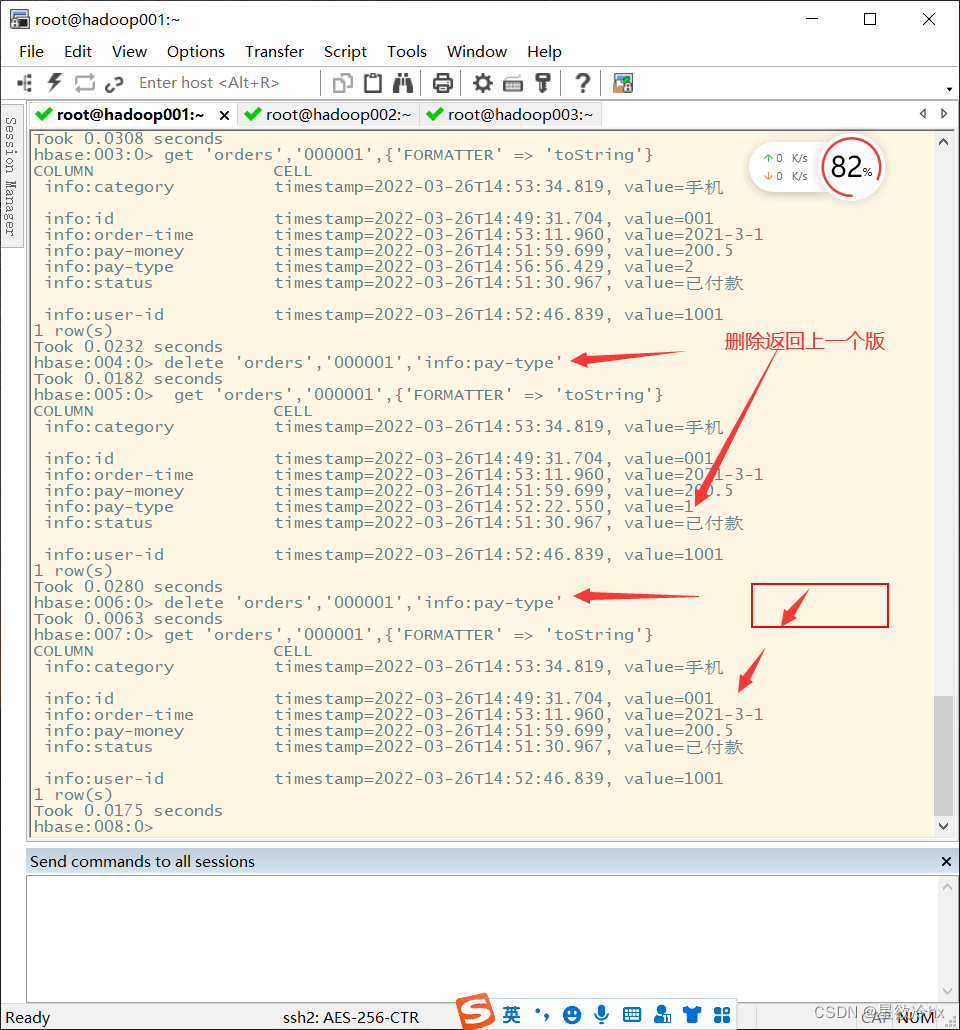
无法用delete
删除一整行

删除整行数据
语法:
deleteall ‘表名’,’rowkey’
说明:
HBase删除数据时,其实并不是真的删除,而是给数据做一个删除标志,再查询数据的时候不显示出来。

清空表
语法:
truncate ‘表名’

数据的导入
数据文件的准备
模拟某系统产生日志数据文件,把这些数据文件导入到hbase中
https://pan.baidu.com/s/1fOK51F-krqJz9tDFzxBr8w?pwd=1234 提取码:1234
这是数据

上传数据文件到服务器

创建表

执行命令导入数据文件
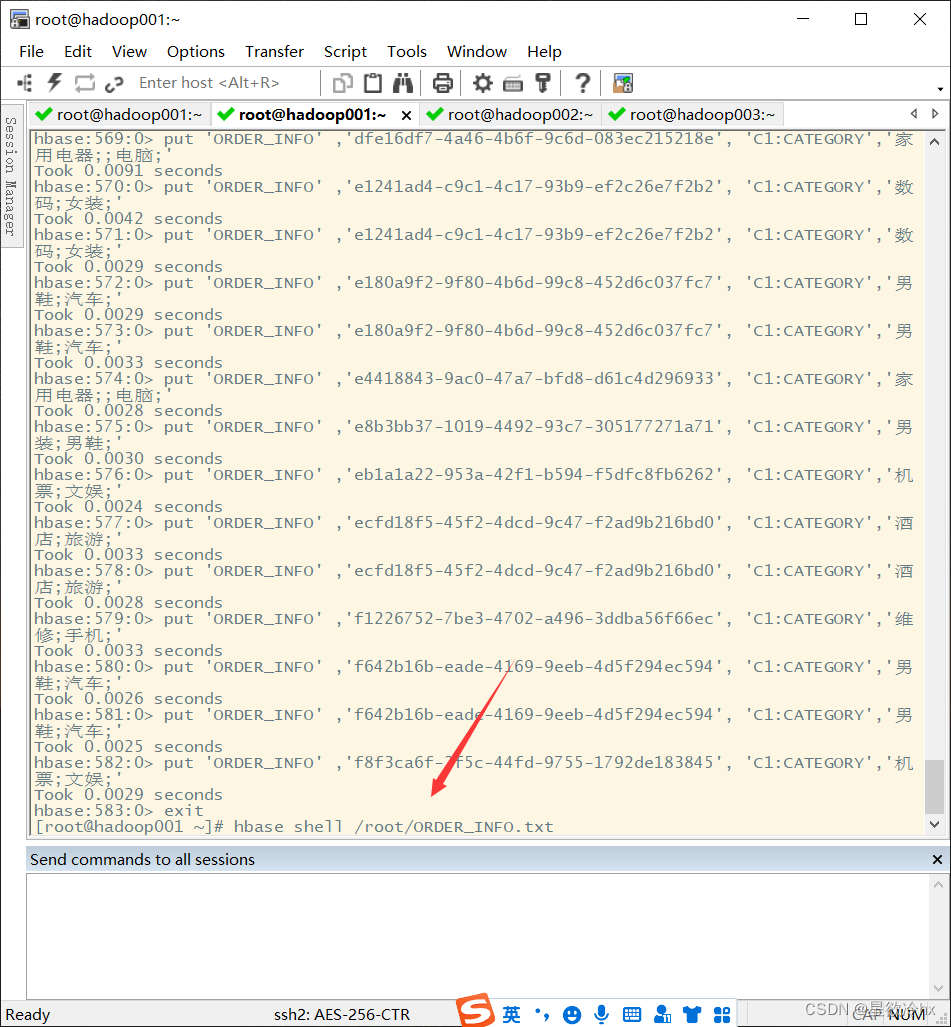
查看数据
scan 'ORDER_INFO',{'FORMATTER' => 'toString'}

计数操作
统计表中共有多少条记录
计数命令
语法:
count ‘表名’

注意:
当数据量很大的时候,这个操作比较耗时
MR程序计算
当数据量很大很大时,可以通过HBase提供的MR程序来运行计数统计。
语法:
hbase org.apache.hadoop.hbase.mapreduce.RowCounter ‘表名’
注意:
启动yarn集群

启动历史服务器,命令:mapred --daemon start historyserver

history的web ui

mr得出结果

扫描操作
全表扫描
语法:
scan ‘表名’,{FORMATTER=>’toString’}
scan "ORDER_INFO",{FORMATTER=>'toString'}
注意:
尽量避免全表扫描一张很大很大的表

限定记录数
语法:
scan ‘表名’,{FORMATTER=>'toString',LIMIT=>数字}
scan "ORDER_INFO",{FORMATTER=>'toString',LIMIT=>2}

限定列
语法:
scan "ORDER_INFO",{FORMATTER=>'toString',COLUMNS=>[‘列簇名1:列名1’,’列簇名1:列名2’,……]}
scan "ORDER_INFO",{FORMATTER=>'toString',LIMIT=>2,COLUMNS=>['C1:PAYWAY','C1:STATUS']}

限定rowkey

语法:
scan "ORDER_INFO",{ROWPREFIXFILTER=>’rowkey’}

scan "ORDER_INFO",{FORMATTER=>'toString',COLUMNS=>['C1:PAYWAY','C1:STATUS'],ROWPREFIXFILTER=>'0'}
限定rowkey的前不是0

过滤器(FILTER)
简介
在HBase中,如果要对海量的数据进行扫描查询,尤其是全表扫描效率很低,可以使用过滤器Filter来提高查询的效率。Filter可以根据主键、列簇、列、版本号(时间戳)等对数据进行过滤查询。
在HBase中,使用过滤器有两种方式,一是在命令行中使用基于jRuby语法的命令选项实现交互式查询,如上所用,另一种是基于JAVA API的方式来进行编程开发。
过滤器
可以通过show_filters命令,来查看HBase内置的过滤器

| 类别 | 过滤器 | 功能 |
| rowkey过滤器 | RowFilter | 实现行键字符串的比较和过滤 |
| PrefixFilter | rowkey前缀过滤器 | |
| KeyOnlyFilter | 只对单元格的键过滤不显示值 | |
| FirstKeyOnlyFilter | 只扫描显示相同键的第一个单元格,其键值对会显示出来 | |
| 列过滤器 | FamilyFilter | 列簇过滤器 |
| QualifierFilter | 列限定符过滤器,只显示对应列簇列名的数据 | |
| ColumnPrefixFilter | 对列名称的前缀进行过滤 | |
| MultipleColumnPrefixFilter | 可以指定多个前缀对列名过滤 | |
| ColumnRangeFilter | 列名称范围过滤器 | |
| 值过滤器 | ValueFilter | 值过滤器,找到符合值条件的键值对 |
| SingleColumnValueFilter | 在指定的列簇和列名中进行比较的值过滤器 | |
| ColumnValueFilter | 列值过滤器 | |
| SingleColumnValueExcludeFilter | 排除匹配成功的值 | |
| 其他过滤器 | ColumnPaginationFilter | 对一行的所有列分页,只返回[offset,offset+limit]范围内的列 |
| PageFilter | 对显示结果按行进行分页显示 | |
| TimestampsFilter | 时间戳过滤器,支持等值,可以设置多个时间戳 | |
| ColumnCountGetFilter | 限制每个逻辑行返回值对的个数,在get方法中使用 | |
| DependentColumnFilter | 允许用户指定一个参考列或引用列来过滤其他列的过滤器 |
过滤器的用法
过滤器一般结合scan命令来使用,语法:
scan ‘表名’,{FILTER=>”过滤器(比较运算符,’比较器表达式’)”}
举例:
需求一:查询指定订单的数据,订单号为“02602f66-adc7-40d4-8485-76b5632b5b53”
scan 'ORDER_INFO',{FORMATTER=>'toString',FILTER=>"RowFilter(=,'binary:02602f66-adc7-40d4-8485-76b5632b5b53')"}


比较知识
参考Apache的官网
参考文档:
https://hbase.apache.org/devapidocs/index.html
比较运算符
| 比较运算符 | 功能 |
| = | 等于 |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| != | 不等于 |

- 比较器
| 比较器 | 功能 |
| BinaryComparator | 匹配完整字节数组 |
| BinaryPrefixComparator | 匹配字节数组前缀 |
| BitComparator | 匹配比特位 |
| NullComparator | 匹配空值 |
| RegexStringComparator | 匹配正则表达式 |
| SubStringComparator | 匹配子字符串 |
比较器表达式
| 比较器 | 表达式语音缩写 |
| BinaryComparator | binary:值 |
| BinaryPrefixComparator | binaryprefix:值 |
| BitComparator | bit:值 |
| NullComparator | null |
| RegexStringComparator | regexstring:正则表达式 |
| SubStringComparator | substring:值 |
案例一:使用RowFilter查询指定订单id的数据
需求:
查询指定订单的数据,订单号为“02602f66-adc7-40d4-8485-76b5632b5b53”、订单状态及支付方式
分析
- 因为订单id就是表的rowkey,所以应该使用rowkey过滤器RowFilter来过滤数据
- 比较运算符:=
- 比较器表达式:binary:值
命令
scan 'ORDER_INFO',{FORMATTER=>'toString',FILTER=>"RowFilter(=,'binary:02602f66-adc7-40d4-8485-76b5632b5b53')",COLUMNS=>['C1:PAYWAY','C1:STATUS']}

案例二:查询状态为已付款的订单
需求:
查询状态为已付款的订单
分析
- 因为状态为已付款要查询指定值的数据,所以不能使用rowkey过滤器,而是要使用值过滤器
- 状态为列名,已付款为值,所以可以选用SingleColumnValueFilter,查看api文档,需要传入四个参数:
- 列簇
- 列标识符(列名)
- 比较运算符
- 比较器

命令:
scan 'ORDER_INFO',{FORMATTER=>'toString',FILTER=>"SingleColumnValueFilter('C1','STATUS',=,'binary:已付款')"}


注意:
- 列簇名和列名大小写一定要对
- 列名写错了过滤不了数据,但是hbase不会报错,因为hbase是无模式的
案例三:组合多条件过滤
需求
查询支付方式为1,且金额大于3000的订单
分析
- 此处需要使用多个过滤器组合使用共同实现查询的要求,多个过滤器可以使用AND(且)、OR(或者)来进行组合。
- 使用值过滤器SingleColumnValueFilter实现对应列值的查询
- 支付方式为1的过滤器:
SingleColumnValueFilter('C1','PAYWAY',=,'binary:1')
金额大于3000的过滤器:
SingleColumnValueFilter('C1','PAY_MONEY',>,'binary:3000')
两个过滤器的关系:且用AND来实现
命令
scan 'ORDER_INFO',{FORMATTER=>'toString',FILTER=>"SingleColumnValueFilter('C1','PAYWAY',=,'binary:1') AND SingleColumnValueFilter('C1','PAY_MONEY',>,'binary:3000')",COLUMNS=>['C1:PAYWAY','C1:PAY_MONEY']}

练习1:支付方式为1,,且金额不大于3000的订单
scan 'ORDER_INFO',{FORMATTER=>'toString',FILTER=>"SingleColumnValueFilter('C1','PAYWAY',=,'binary:1') AND SingleColumnValueFilter('C1','PAY_MONEY',<=,'binary:3000')",COLUMNS=>['C1:PAYWAY','C1:PAY_MONEY']}

INCR
incr(increament)可以实现某个单元格的值进行原子性计数,默认累加1。
需求
某新闻app应用为了统计每个新闻的每隔一段时间的访问次数,将新闻数据保存在HBase中,该表格的数据如下:
| 新闻ID | 访问次数 | 时间段 | rowkey |
| 0000000001 | 12 | 00:00-01:00 | 0000000001_00:00-01:00 |
| 0000000002 | 20 | 01:00-02:00 | 0000000002_01:00-02:00 |
要求,原子性的增加新闻的访问次数。
incr操作
语法:
incr ‘表名’,’rowkey’,’列簇:列名’,累加值(默认累加1)
说明:
如果某一列要实现计数功能,必须要使用incr来创建对应的列
使用put创建的列是不能实现累加的
导入测试数据
https://pan.baidu.com/s/1HfVKmsKvCeSiQ3TaUpF7Tw?pwd=1234 提取码:1234
数据集在这


导入hbase

显示前5行数据\
scan "NEWS_VISIT_CNT",{FORMATTER=>'toString',LIMIT=>5}

获取计数器的值命令
语法:
get_counter,’表名’,’rowkey’,’列簇:列名’
get_counter "NEWS_VISIT_CNT",'0000000001_00:00-01:00','C1:CNT'


使用incr进行累加操作

shell管理操作
status
显示服务器的状态
whoami
显示当前用户

list
显示当前所有的表

count
统计指定表的记录数

describe
显示表的结构信息

exists
判断某个表是否存,适用于表很多的时候

is_enabled、is_disabled
判断表是否启用或禁用
alter
改变表和列簇的模式

其他
disable和enable
禁用和启动表
drop
删除表
truncate
清空表的数据,保留表的结构
hbase shell 操作差不多就是这些了,下一文章(3),将和大家一起学习hbase的java api操作
如遇侵权,请联系删除。















 536
536











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











