







简介
使用单个字符串来描述、匹配一系列符合某个句法规则的字符串,是一门表达式语言。
使用的离线regex工具:RegexBuddy
使用的在线工具:debuggex
正则表达式引擎包括DFA和NFA,DFA匹配时不回溯,逻辑或(|)匹配时并行匹配,占用资源多且不支持捕获分组等功能,java正则表达式使用的是NFA引擎。
元字符
| 符号 | 含义 |
|---|---|
| . | 匹配换行符外的任意字符,当开启单行模式时,可匹配换行符 |
| \w | 匹配单词,字母数字下划线 |
| \s | 匹配空白符,空格换行制表 |
| \d | 匹配数字 |
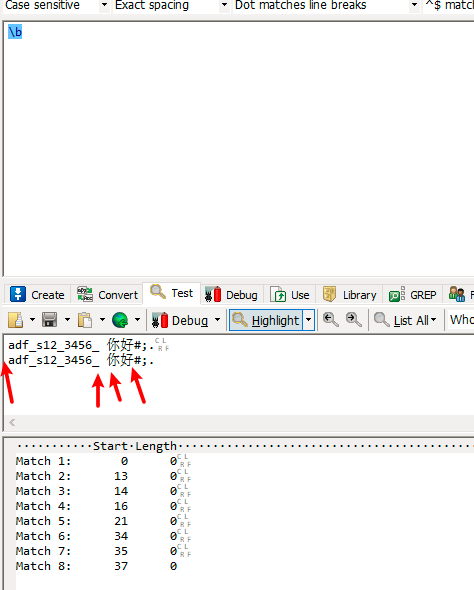
| \b | 匹配边界,单词的开始或结束 |

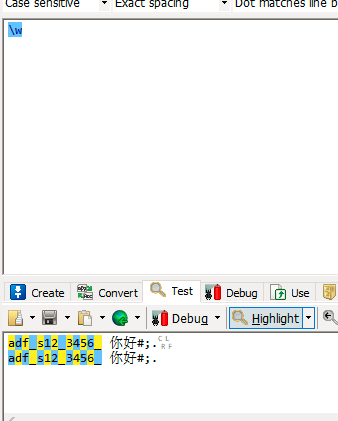
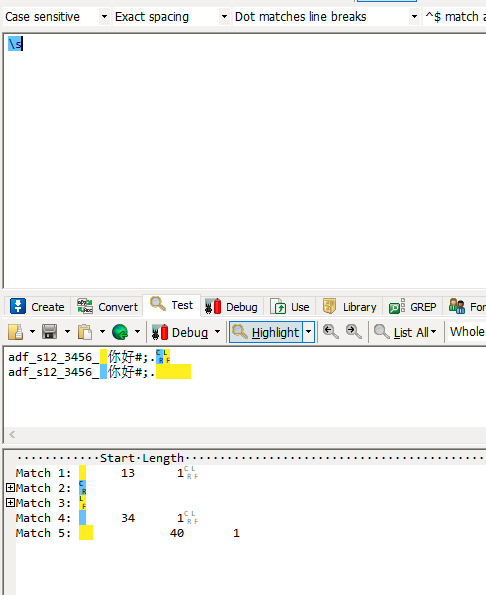
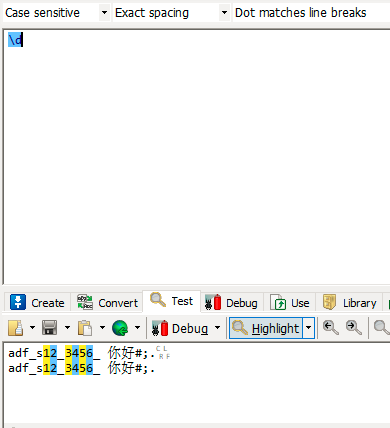
此处把中文的开始和结束也匹配了,符号的开始结束并没有匹配
反义符
\W : 匹配\w不匹配的。
\S : 匹配\s不匹配的。
\D:匹配\d不匹配的。
\B:匹配边界,非单词的开始或结束。
边界符
| 符号 | 含义 |
|---|---|
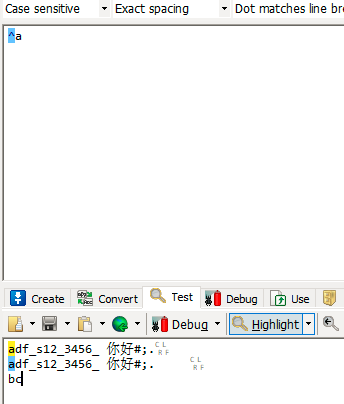
| ^ | 匹配字符串的开始 |
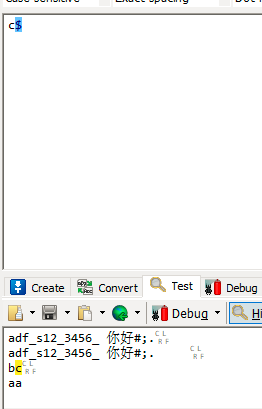
| $ | 匹配字符串的结束 |
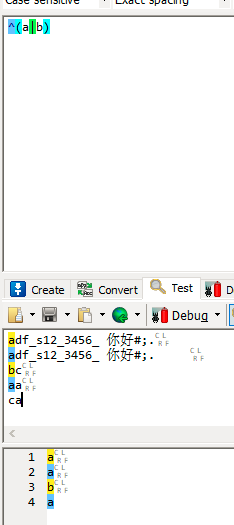
| [x] | 匹配单个字符,括号内字符无需转义 |
| () | 表示分组,方便提取 |
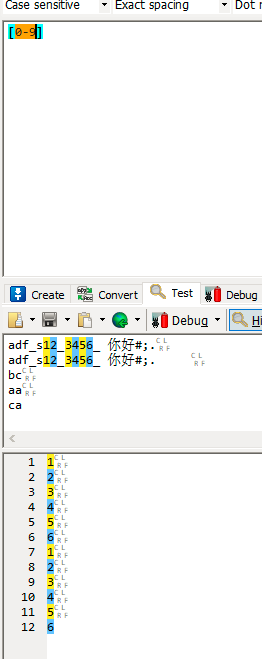
| - | 表示区间 |

转义符
| 符号 | 含义 |
|---|---|
| \ | 匹配正则占用的字符 |
| \\ | 匹配\本身 |
| \t | 匹配制表符 |
| \r | 匹配回车符 |
| \n | 匹配换行符 |
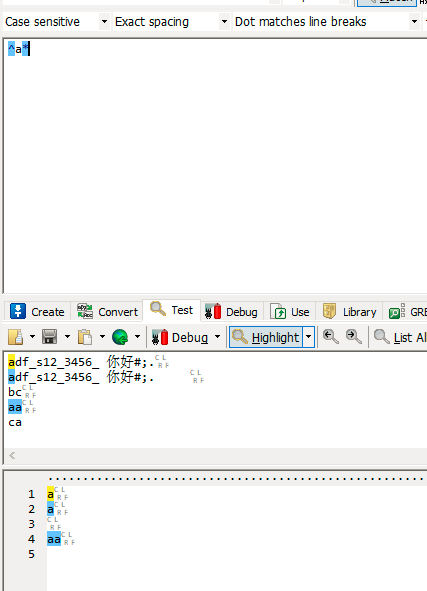
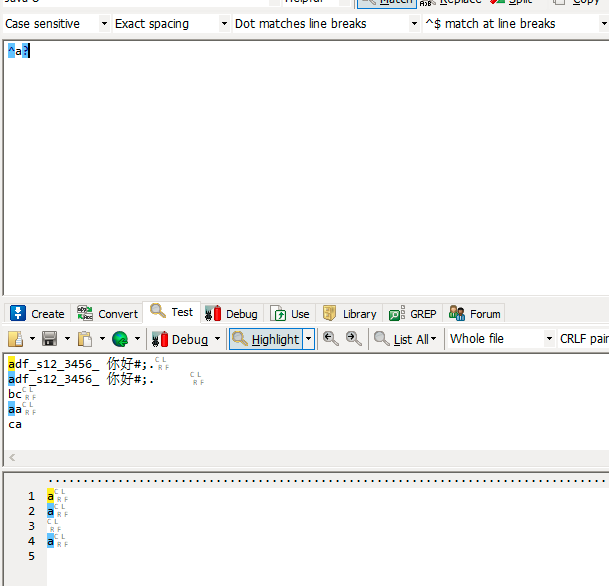
重复匹配
计量符
| 符号 | 含义 |
|---|---|
| * | 重复0次或多次 |
| + | 重复至少一次 |
| ? | 重复0次或1次 |
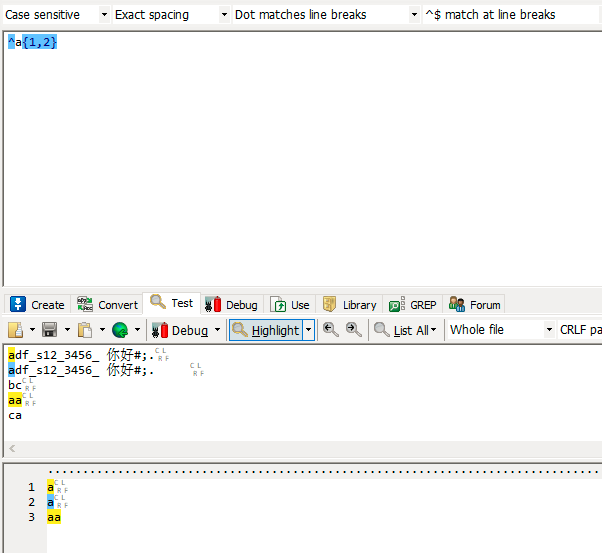
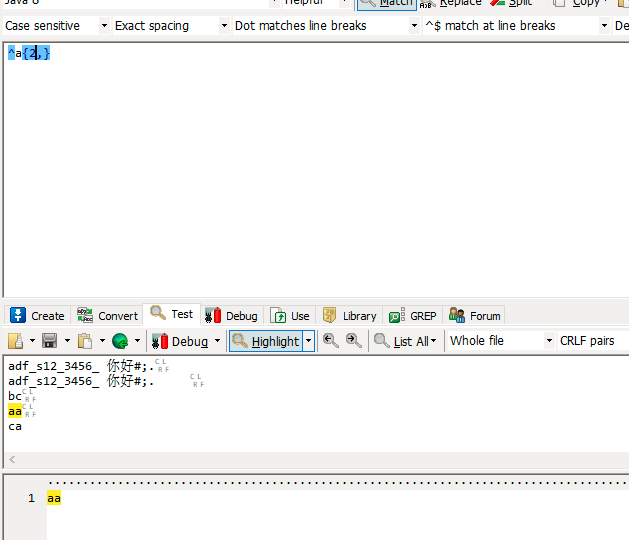
| {n,m} | 重复至少n次,至多m次 |
| {n,} | 重复至少n次 |
| {n} | 重复n次 |

逻辑符
| 符号 | 含义 |
|---|---|
| | | 逻辑或 |
| ! | 逻辑非 ,环视否定顺序 |
| = | 逻辑等于,环视肯定顺序 |
| <= | 环视肯定逆序 |
| <! | 环视否定逆序 |
具体应用见零宽断言
分组匹配
分组命名规则:(?exp)
系统自命名规则:从左往右,从外往里
贪婪与懒惰
贪婪:尽可能多的重复匹配,在匹配成功的基础上,会继续向右匹配检查有无更长匹配字符串。
懒惰:尽可能少的重复匹配,一旦匹配成功,立刻结束匹配。
| 符号 | 含义 |
|---|---|
| *? | 重复0次或多次,尽可能少的重复匹配 |
| +? | 重复至少一次 ,尽可能少的重复匹配 |
| ?? | 重复0次或1次,尽可能少的重复匹配 |
| {n,m}? | 重复至少n次,至多m次 ,尽可能少的重复匹配 |
| {n,}? | 重复至少n次 ,尽可能少的重复匹配 |
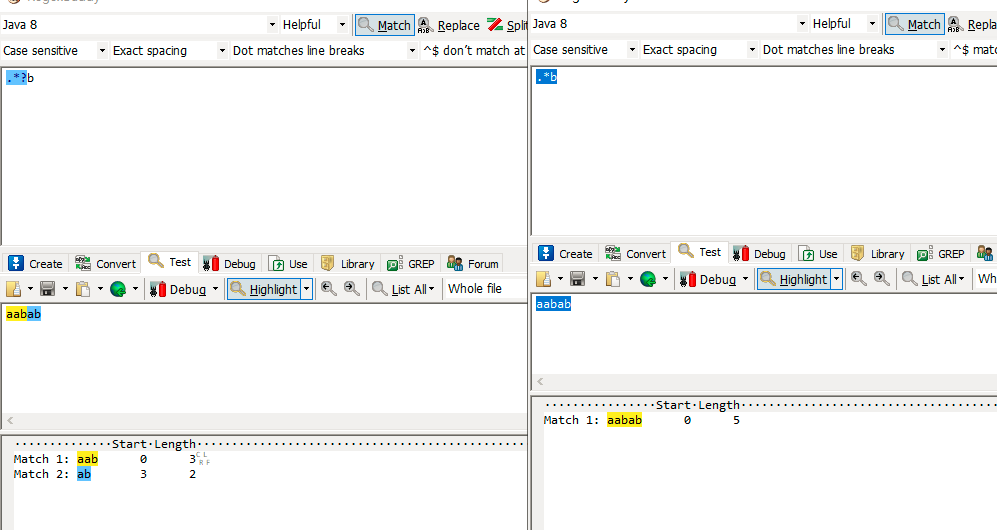
.*b匹配aabab过程:正则表达式包含.*和b两部分,控制权先由.*取得,.*优先多次匹配。
优先级从高到低排序:(字符X代表除换行符的任意字符)XX…XXXb —> XXb —> b
- 正则.* 优先匹配 a,匹配成功,继续匹配
- 正则.* 优先匹配 a,匹配成功,继续匹配
- 正则.*优先匹配b,匹配成功,继续匹配
- 正则.* 优先匹配 a,匹配成功,继续匹配
- 正则.*优先匹配b,匹配成功,继续匹配
- 达到字符串尾,正则.*匹配完成,控制权交由正则b
- 由于已达字符串尾,正则b匹配失败,回溯,控制权交由正则.*
- 正则.*回溯不匹配b,正则.*将控制权交由正则b
- 正则b匹配b,匹配成功,正则表达式达到尾部,匹配一处文本aabab,字符串达到尾部,完成匹配
- 匹配文本 aabab
.*?b匹配aabab过程:正则表达式包含.*?和b两部分,控制权先由.*?取得,.*?优先忽略匹配。
优先级从高到低排序:(字符X代表除换行符的任意字符) b —> XXb —> XX…XXXb
- 正则.*?优先忽略匹配a,将控制权交由正则b
- 正则b匹配失败,回溯,将控制权交由正则.*?
- 正则.*?回溯匹配a,匹配成功
- 正则.*?优先忽略匹配a,将控制权交由正则b
- 正则b匹配失败,回溯,将控制权交由正则.*?
- 正则.*?回溯匹配a,匹配成功
- 正则.*?优先忽略匹配b,将控制权交由正则b
- 正则b匹配b,匹配成功,正则达到尾部,匹配一处文本aab,开始下一轮匹配,控制权交由正则.*?。
- 正则.*?优先忽略匹配a,将控制权交由正则b
- 正则b匹配失败,回溯,将控制权交由正则.*?
- 正则.*?回溯匹配a,匹配成功
- 正则.*?优先忽略匹配b,将控制权交由正则b
- 正则b匹配b,匹配成功,正则表达式达到尾部,匹配一处文本ab,字符串达到尾部,完成匹配
- 匹配文本aab、ab两个
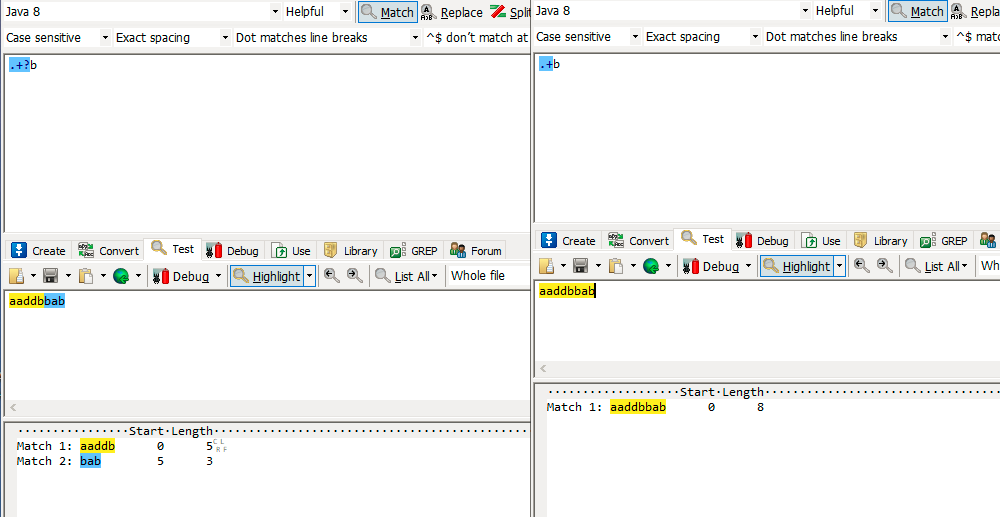
.+b匹配aaddbbab过程:正则表达式包含.+和b两部分,控制权先由.+取得,.+优先多次匹配。
优先级从高到低排序:(字符X代表除换行符的任意字符)XX…XXXb —> XXb —> Xb
- 正则.+优先匹配 a,匹配成功,继续匹配
- 正则.+优先匹配 a,匹配成功,继续匹配
- 正则.+优先匹配 d,匹配成功,继续匹配
- 正则.+优先匹配 d,匹配成功,继续匹配
- 正则.+优先匹配 b,匹配成功,继续匹配
- 正则.+优先匹配 b,匹配成功,继续匹配
- 正则.+优先匹配 a,匹配成功,继续匹配
- 正则.+优先匹配 b,匹配成功,继续匹配
- 达到字符串尾,正则.+匹配完成,控制权交由正则b
- 由于已达字符串尾,正则b匹配失败,回溯,控制权交由正则.+。
- 正则.+回溯不匹配b,控制权交由正则b
- 正则b匹配b,匹配成功,正则表达式达到尾部,匹配一处文本aaddbbab,字符串达到尾部,匹配完成。
- 匹配文本aaddbbab
.+?b匹配aaddbbab过程:正则表达式包含.+?和b两部分,控制权先由.+?取得,.+?优先一次匹配。
优先级从高到低排序:(字符X代表除换行符的任意字符) Xb —> XXb —> XX…XXXb
- 正则.+? 优先匹配 a,匹配成功
- 正则.+?忽略匹配a,将控制权交由正则b
- 正则b匹配失败,回溯,将控制权交由正则.+?
- 正则.+?匹配a,匹配成功
- 正则.+?忽略匹配d,将控制权交由正则b
- 正则b匹配失败,回溯,将控制权交由正则.+?
- 正则.+?匹配d,匹配成功
- 正则.+?忽略匹配d,将控制权交由正则b
- 正则b匹配失败,回溯,将控制权交由正则.+?
- 正则.+?匹配d,匹配成功
- 正则.+?忽略匹配b,将控制权交由正则b
- 正则b匹配b,匹配成功,正则达到尾部,匹配一处文本aaddb,开始下一轮匹配,控制权交由正则.+?。
- 正则.+? 优先匹配 b,匹配成功
- 正则.+?忽略匹配a,将控制权交由正则b
- 正则b匹配失败,回溯,将控制权交由正则.+?
- 正则.+?匹配a,匹配成功
- 正则.+?忽略匹配b,将控制权交由正则b
- 正则b匹配b,匹配成功,正则达到尾部,匹配一处文本bab,字符串达到尾部,完成匹配。
- 匹配文本aaddb、bab
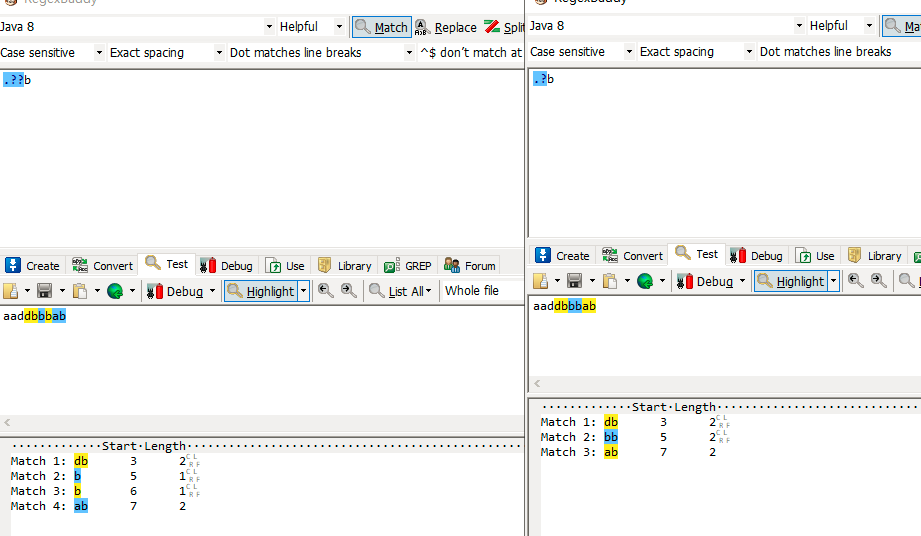
.?b匹配aaddbbbab过程:正则表达式包含.?和b两部分,控制权先由.?取得,.?优先一次匹配。
优先级从高到低排序:(字符X代表除换行符的任意字符)Xb —> b
- 正则.? 优先匹配 a,匹配成功,正则.?匹配完成,控制权交由正则b
- 正则b匹配失败,回溯,控制权交由正则.?
- 正则.?不匹配a,控制权交由正则b
- 正则b匹配失败,跳过当前单词,抵达下一处a,控制权交由正则.?
- 正则.? 优先匹配 a,匹配成功,正则.?匹配完成,控制权交由正则b
- 正则b匹配失败,回溯,控制权交由正则.?
- 正则.?不匹配a,控制权交由正则b
- 正则b匹配失败,跳过当前单词,抵达下一处d,控制权交由正则.?
- 正则.? 优先匹配 d,匹配成功,正则.?匹配完成,控制权交由正则b
- 正则b匹配失败,回溯,控制权交由正则.?
- 正则.?不匹配d,控制权交由正则b
- 正则b匹配失败,跳过当前单词,抵达下一处d,控制权交由正则.?
- 正则.? 优先匹配 d,匹配成功,正则.?匹配完成,控制权交由正则b
- 正则b匹配b,匹配成功,正则表达式达到尾部,匹配文本db,开始下一轮匹配,控制权交由正则.?
- 正则.? 优先匹配 b,匹配成功,正则.?匹配完成,控制权交由正则b
- 正则b匹配b,匹配成功,正则表达式达到尾部,匹配文本bb,开始下一轮匹配,控制权交由正则.?
- 正则.? 优先匹配 a,匹配成功,正则.?匹配完成,控制权交由正则b
- 正则b匹配b,匹配成功,正则表达式达到尾部,匹配文本ab,字符串达到尾部,匹配结束
- 匹配文本db、bb、ab
.??b匹配aaddbbbab过程:正则表达式包含.??和b两部分,控制权先由.??取得,.??优先忽略匹配。
优先级从高到低排序:(字符X代表除换行符的任意字符)b —> Xb
- 正则.?? 优先忽略匹配 a,控制权交由正则b
- 正则b匹配失败,回溯,控制权交由正则.??
- 正则.??匹配a,匹配成功,控制权交由正则b
- 正则b匹配失败,跳过当前单词,抵达下一处a,控制权交由正则.??
- 正则.?? 优先忽略匹配 a,控制权交由正则b
- 正则b匹配失败,回溯,控制权交由正则.??
- 正则.??匹配a,匹配成功,控制权交由正则b
- 正则b匹配失败,跳过当前单词,抵达下一处d,控制权交由正则.??
- 正则.?? 优先忽略匹配 d,控制权交由正则b
- 正则b匹配失败,回溯,控制权交由正则.??
- 正则.??匹配d,匹配成功,控制权交由正则b
- 正则b匹配失败,跳过当前单词,抵达下一处d,控制权交由正则.??
- 正则.?? 优先忽略匹配 d,控制权交由正则b
- 正则b匹配失败,回溯,控制权交由正则.??
- 正则.??匹配d,匹配成功,控制权交由正则b
- 正则b匹配b,匹配成功,正则表达式达到尾部,匹配文本db,开始下一轮匹配,控制权交由正则.??
- 正则.?? 优先忽略匹配 b,控制权交由正则b
- 正则b匹配b,匹配成功,正则表达式达到尾部,匹配文本b,开始下一轮匹配,控制权交由正则.??
- 正则.?? 优先忽略匹配 b,控制权交由正则b
- 正则b匹配b,匹配成功,正则表达式达到尾部,匹配文本b,开始下一轮匹配,控制权交由正则.??
- 正则.?? 优先忽略匹配 a,控制权交由正则b
- 正则b匹配失败,回溯,控制权交由正则.??
- 正则.??匹配a,匹配成功,控制权交由正则b
- 正则b匹配b,匹配成功,正则表达式达到尾部,匹配文本ab,字符串达到尾部,匹配完成
- 匹配文本db、b、b、ab
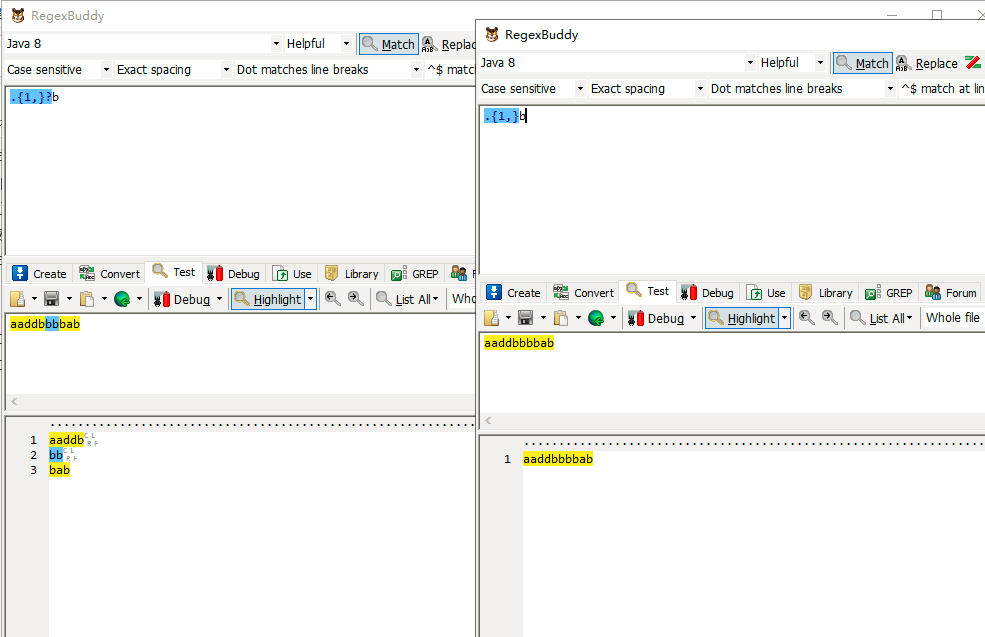
.{1,2}b优先级从高到低排序:(字符X代表除换行符的任意字符)XXb —> Xb
.{1,2}?b优先级从高到低排序:(字符X代表除换行符的任意字符)Xb —> XXb
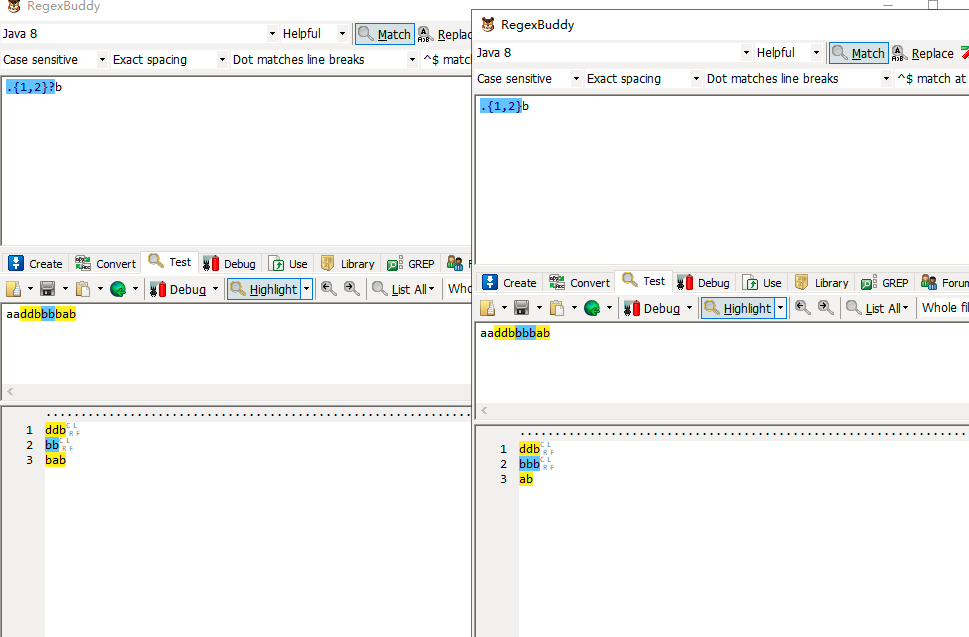
.{1,}b优先级从高到低排序:(字符X代表除换行符的任意字符)XX…XXXb —> Xb
.{1,}?b优先级从高到低排序:(字符X代表除换行符的任意字符)Xb —> XX…XXXb
总结:从当前位置开始,按照优先级逐个比对,若优先级中所有可能都匹配失败,则移动到下一个位置。
处理选项
| 符号 | 含义 |
|---|---|
| IgnoreCase | 匹配时不区分大小写 |
| Multiline | 匹配每一行的行首行尾,扩大^和$的范围 |
| singleline | 扩大.的范围,可以匹配换行符 |
| ExplicitCapture | 仅捕获显示命名组 |
反向引用
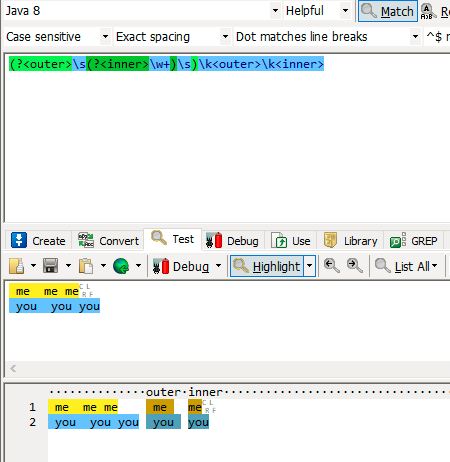
分组引用:
- 未命名分组 引用方式\index,基1
- 已命名分组 引用方式\k<groupname>

非获取匹配
不捕获分组匹配到的文本,该分组也无组号。
(?:exp) eg: indust(?:y|ies) === (industy|industies)
先行断言:后面固定,取前面的值
后发断言:前面固定,取后面的值
零宽断言
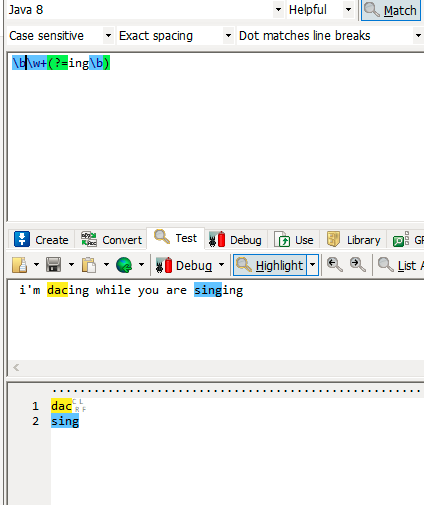
(?=exp) 零宽度正预测先行断言
eg: i’m dacing while you are singing。
取例子中的动词 pattern: \b\w+(?=ing)\b。
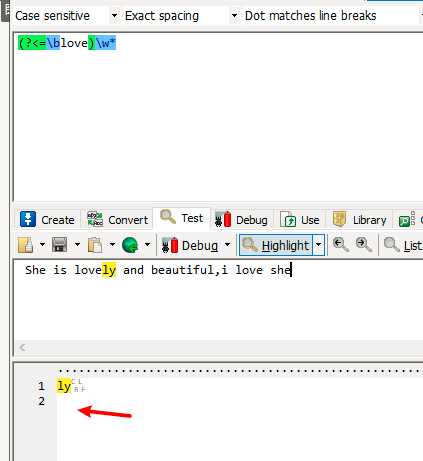
(?<=exp) 零宽度正回顾后发断言
eg: She is lovely and beautiful,i love she。
取love后面的值。 pattern : (?<=\blove)\w*
负向零宽断言
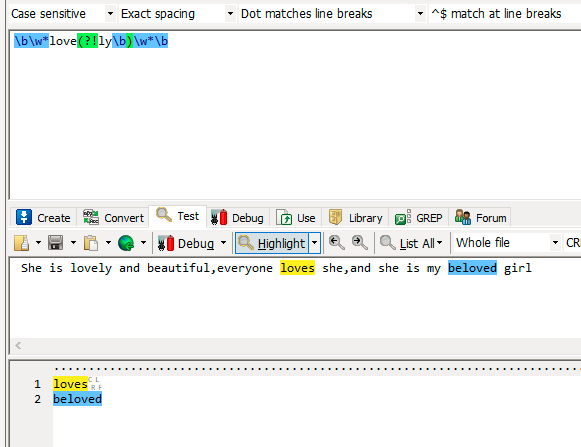
(?!exp) 零宽度负预测先行断言
eg: She is lovely and beautiful,everyone loves she,and she is my beloved girl
查找这样的单词,出现了字母love,love后面却不是ly。 pattern: \b\w*love(?!ly\b)\w*\b。
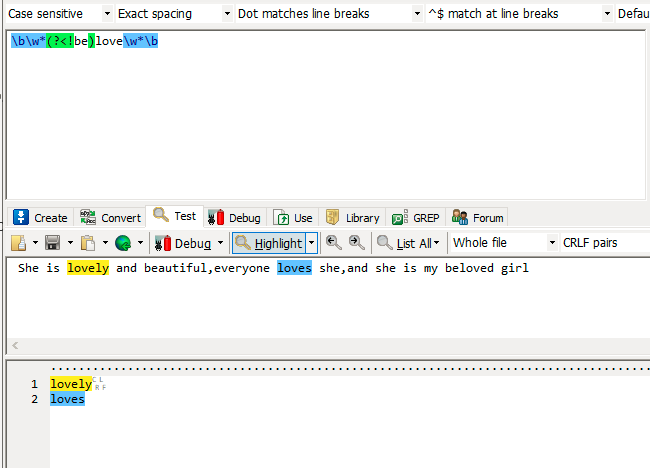
(?<!exp) 零宽度负回顾后发断言
eg: She is lovely and beautiful,everyone loves she,and she is my beloved girl
查找这样的单词,出现了字母love,love前面却不是be。 pattern: \b\w*(?<!be)love\w*\b。














 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









