







上一篇attention介绍了Bahdanau等人提出的一种soft-attention模型。 Luong等人在此基础上提出了两种简单且有效的方式:全局(global)和局部(local)的方式。所谓的global,就是指每次都关注整个source sentence,而local则是在每个时间t,只关注一部分source sentence。
Luong等人提出的global类似于Bahdanau等人的soft-attention方式,但是比他们会简单一些;local的方式可以看成是hard-attention与soft-attention的一种平衡,计算代价比soft-attention小,并且相较于hard-attention,它可微且便于训练。
先来一波Decoder示意图:

首先,Encoder部分其实是大同小异的,通过RNN获得各个时间t的hidden state
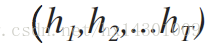
(以下用下标i表示对应目标语言的第i个词,j表示源语言的第j个词)
文中定义decoder端生成最终目标词yi的概率为:

这里作者引入了一个attention hidden state 
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 328
328











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









