







对于数据驱动编程最大的难点在抽象出数据库和数据解析(有点类似于一个文本解析器),这两部分的设计的灵活度就决定了程序的扩展性和紧凑性。
目前比较简单的就是用数组等作为数据库,数据解析基本上是查表,所以也有很多小伙伴直接称为表驱动编程,然而对于数据驱动编程远远可以设计得比表驱动复杂,所以这也是在开发中选择数据驱动方法编码的一个决定因素。
下面作者还是以比较基础的实例跟大家分析分析:
1.状态机的实现
参考demo:
#include <stdio.h>
#include <stdlib.h>
//构造数据
#define STATUE1 (0)
#define STATUE2 (1)
#define STATUE3 (2)
#define MAX_STATUE (3)
int Statue1Process(int param);
int Statue2Process(int param);
int Statue3Process(int param);
/***************************************
14 * Fuciton:数据驱动编程实例
15 * Author :(公众号:最后一个bug)
16 ***************************************/
//构造数据库
typedef int (*PStatueMachineProcess)(int param);
PStatueMachineProcess MachineProcess[MAX_STATUE] =
{
Statue1Process,
Statue2Process,
Statue3Process
};
int Statue1Process(int param)
{
printf("Statue1Process\n");
return STATUE2;
}
int Statue2Process(int param)
{
printf("Statue2Process\n");
return STATUE3;
}
int Statue3Process(int param)
{
printf("Statue3Process\n");
return STATUE1;
}
int main(int argc, char *argv[]) {
int statue = STATUE1;
int count = 0;
//数据库解析和逻辑引导
while(1)
{
statue = (MachineProcess[statue])(1);
count++;
if(count > 10)break;
}
printf("公众号:最后一个bug\n");
return 0;
}
分析一下:
这样实现状态机应该比if-else方便多了,上面的代码对于有一定编程经验的小伙伴而言,似乎仅仅只是用了一个函数指针数据就搞定了,如果我们再认真解读一下,其实在该过程中仅仅就是状态数据发生了变化,其他均是绑定一套连贯处理,这里的状态数据作为了数组的标识,所以在此也说明数据驱动的特点:仅仅只对数据敏感。
从上面的处理可以发现该方式可以减少switch和if-else的使用。
2消息处理机制
参考demo:
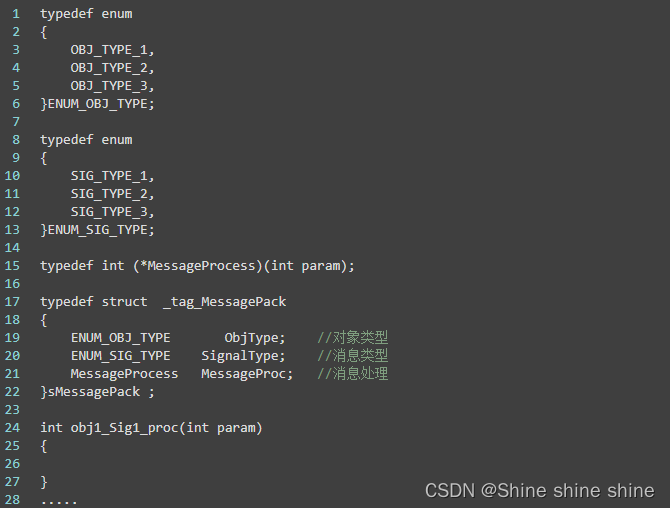
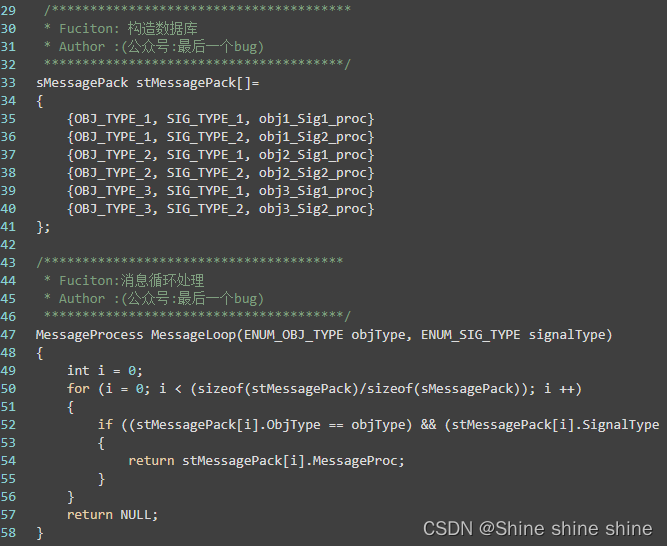
分析一下:
上面代码仅仅只是给大家简单的体验一下数据驱动编程方法,对于效率等等作者没有过多的考虑,其性能与所设计的数据结构有关系。所以这样的处理也避免了很多小伙伴进行硬编码的习惯。
4、最后小结
最后对于数据驱动编程并不是万能的,可能对于有些设计反而起到副作用,一般用于实现逻辑相对比较清晰的处理,不过对于简化条件语句还是非常好用的,所以对于这些编程思路,需要根据具体情况进行选择,同时也要对目标项目有较强的理解能力。
原文链接https://mp.weixin.qq.com/s/NDb6YklksT4JkYRo_N7wKg















 223
223











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









