






目录
引言
在Kubernetes集群中,为了确保资源的有效利用和应用的高可用性,我们通常需要监控集群中各个Pod的资源使用情况,并根据这些信息进行相应的调整。Horizontal Pod Autoscaler (HPA) 就是这样一种机制,它可以根据Pod的资源使用情况自动调整Pod的副本数量。而Metrics-Server,作为Kubernetes的一个核心组件,为HPA提供了关键的度量数据支持。本文将详细解析Metrics-Server与HPA之间的关系、工作原理以及它们在实际应用中的重要性
一、概述
(一)Metrics-Server简介
Metrics-Server是Kubernetes的一个附加组件,用于收集集群中各个资源的度量数据,如CPU、内存等。这些数据通过Kubernetes API Server暴露给外部用户或组件,以供它们进行决策或分析。在Kubernetes 1.8版本之前,通常使用Heapster作为度量数据的收集者,但自1.8版本起,Heapster被废弃,Metrics-Server成为了推荐的替代方案
(二)Metrics-Server的工作原理
Metrics-Server的工作原理相对简单,它定期从Kubernetes集群中的各个节点上收集度量数据,并将这些数据聚合后存储在内存中。然后,当外部用户或组件(如HPA)需要查询这些度量数据时,Metrics-Server会通过Kubernetes API Server提供相应的API接口进行响应。由于Metrics-Server只存储最近一段时间的度量数据(默认为1分钟),因此它不会成为集群的存储瓶颈
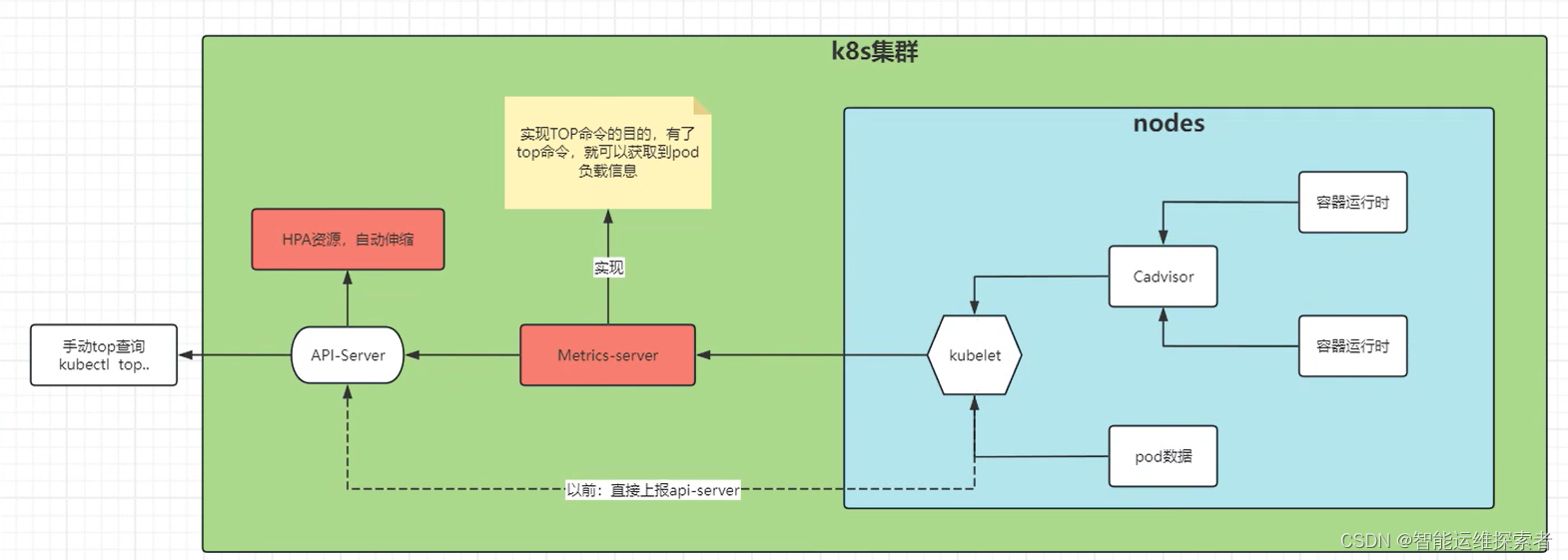
cAdvisor: 用于收集、聚合和公开 Kubelet 中包含的容器指标的守护程序。
kubelet: 用于管理容器资源的节点代理。 可以使用 /metrics/resource 和 /stats kubelet API 端点访问资源指标。
节点层面资源指标: kubelet 提供的 API,用于发现和检索可通过 /metrics/resource 端点获得的每个节点的汇总统计信息。
metrics-server: 集群插件组件,用于收集和聚合从每个 kubelet 中提取的资源指标。 API 服务器提供 Metrics API 以供 HPA、VPA 和 kubectl top 命令使用。Metrics Server 是 Metrics API 的参考实现。
(三)HPA与Metrics-Server的作用
Metrics-Server组件的作用:获取集群中的pod、节点等负载信息
HPA资源的作用:通过Metrics-Server获取的负载信息,自动伸缩的创建或者删除pod
(四)HPA与Metrics-Server的关系
HPA是Kubernetes的一个自动扩展控制器,它可以根据Pod的资源使用情况自动调整Pod的副本数量。而Metrics-Server为HPA提供了关键的度量数据支持。当HPA需要决定是否需要扩展或缩减Pod的副本数量时,它会通过Kubernetes API Server查询Metrics-Server收集的度量数据,然后根据这些数据进行决策。
例如,如果某个Deployment的Pod的CPU利用率超过了设定的阈值,HPA就会增加该Deployment的Pod副本数量;反之,如果CPU利用率过低,HPA就会减少Pod副本数量
(五)HPA与Metrics-Server的重要性
Metrics-Server和HPA在Kubernetes集群中扮演着至关重要的角色。Metrics-Server通过收集集群中各个资源的度量数据,为外部用户或组件提供了丰富的信息支持;而HPA则利用这些信息实现了Pod的自动扩展和缩减,从而确保了集群资源的有效利用和应用的高可用性。
在实际应用中,Metrics-Server和HPA可以帮助我们解决以下问题:
资源浪费:通过自动扩展和缩减Pod的副本数量,可以避免因资源分配不均或过度分配而导致的资源浪费。
应用性能:当应用面临高并发或高负载时,HPA可以迅速增加Pod副本数量以满足需求,从而确保应用的性能和稳定性。
运维效率:Metrics-Server和HPA的自动化特性可以大大减轻运维人员的工作压力,提高运维效率
更多详细信息访问:资源指标管道 | Kubernetes
二、部署metrics-server组件
(一)镜像获取
镜像获取的方式有多种
1.本地上传镜像包
使用docker load -i 镜像包名称 指令获取镜像
[root@node01 opt]#ls metrics-server.tar
metrics-server.tar
[root@node01 opt]#docker load -i metrics-server.tar
0b97b1c81a32: Loading layer [==================================================>] 1.416MB/1.416MB
87ea89a1eabb: Loading layer [==================================================>] 39.61MB/39.61MB
Loaded image: k8s.gcr.io/metrics-server-amd64:v0.3.22.GitHub下载
3.国内云下载
docker pull registry.aliyuncs.com/google_containers/metrics-server:v0.6.3
在所有节点上部署镜像
[root@node01 opt]#docker images |grep metrics-server
registry.aliyuncs.com/google_containers/metrics-server v0.6.3 817bbe3f2e51 14 months ago 68.9MB
k8s.gcr.io/metrics-server-amd64 v0.3.2 46aec181fcb3 5 years ago 40.8MB(二)安装metrics-server组件
安装metrics-server组件,就是给k8s集群安装top指令。
1.获取yaml文件
[root@master01 metrics]#wget https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.7.1/high-availability-1.21+.yaml
[root@master01 metrics]#ls
high-availability-1.21+.yaml
2.修改文件内容
[root@master01 metrics]#vim high-availability-1.21+.yaml
......
136 requiredDuringSchedulingIgnoredDuringExecution:
137 - labelSelector:
138 matchLabels:
139 k8s: metrics-server
#修改硬策略的标签,由于本机的coredns实例的标签键位k8s-app,需要修改为不一致的,或者注释pod反亲和
......
142 topologyKey: kubernetes.io/hostname
143 containers:
144 - args:
145 - --kubelet-insecure-tls #启动允许使用不安全的TLS证书
146 - --cert-dir=/tmp
147 - --secure-port=10250
148 - --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
149 - --kubelet-use-node-status-port
150 - --metric-resolution=15s
151 image: registry.aliyuncs.com/google_containers/metrics-server:v0.6.3
#修改镜像为阿里云的镜像
......
197 ---
198 apiVersion: policy/v1beta1 #1.20版本以前的K8s集群修改PodDisruptionBudget资源的版本为v1beta
199 kind: PodDisruptionBudget
200 metadata:
201 labels:
202 k8s-app: metrics-server
3.创建资源
[root@master01 metrics]#kubectl apply -f high-availability-1.21+.yaml
serviceaccount/metrics-server created
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created
clusterrole.rbac.authorization.k8s.io/system:metrics-server created
rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created
clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created
clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server created
service/metrics-server created
deployment.apps/metrics-server created
poddisruptionbudget.policy/metrics-server created
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created
4.验证是否安装成功
//查看资源信息
[root@master01 metrics]#kubectl get pod -n kube-system |grep metrics-server
metrics-server-98c7c894d-skwjb 1/1 Running 0 3m55s
metrics-server-98c7c894d-xq8qr 1/1 Running 0 3m55s
[root@master01 metrics]#kubectl get deployment metrics-server -n kube-system
NAME READY UP-TO-DATE AVAILABLE AGE
metrics-server 2/2 2 2 4m3s
//使用top命令查看node节点的top值
[root@master01 metrics]#kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
master01 227m 5% 2078Mi 56%
node01 100m 2% 965Mi 26%
node02 114m 2% 580Mi 15%
//查看pod资源的top值
[root@master01 metrics]#kubectl top pod -A
NAMESPACE NAME CPU(cores) MEMORY(bytes)
helm-test harbor-nginx-7db9b84fc4-p5tpl 1m 3Mi
kube-flannel kube-flannel-ds-8sgt8 10m 18Mi
kube-flannel kube-flannel-ds-nplmm 7m 21Mi
kube-flannel kube-flannel-ds-xwklx 7m 20Mi
kube-system coredns-74ff55c5b-dwzdp 4m 15Mi
kube-system coredns-74ff55c5b-ws8c8 3m 15Mi
kube-system etcd-master01 22m 336Mi
kube-system kube-apiserver-master01 85m 398Mi
kube-system kube-controller-manager-master01 14m 51Mi
kube-system kube-proxy-psdnv 4m 23Mi
kube-system kube-proxy-zmh82 1m 15Mi
kube-system kube-proxy-zwnx2 1m 22Mi
kube-system kube-scheduler-master01 4m 18Mi
kube-system metrics-server-98c7c894d-fsb4n 6m 20Mi
kube-system metrics-server-98c7c894d-nqph6 11m 14Mi
三、部署HPA
(一)创建deployment
创建deployment控制器,用来生成pod,进行压测
[root@master01 metrics]#cat deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: dm-hpa
labels:
app: centos
spec:
replicas: 1 #设置副本数量为1个
selector:
matchLabels:
app: centos
template:
metadata:
labels:
app: centos
spec:
containers:
- name: centos
image: centos:7
command: ["/bin/bash", "-c", "yum -y install epel-release;yum -y install stress;sleep 36000"]
#下载stress压测工具,并设置睡眠时间为36000s
resources:
requests:
cpu: "50m"
limits:
cpu: "150m"
#设置现在CPU资源
创建资源
[root@master01 metrics]#kubectl apply -f deployment.yaml
deployment.apps/dm-hpa created
[root@master01 metrics]#kubectl get pod
NAME READY STATUS RESTARTS AGE
dm-hpa-556f64fc9-9fcff 1/1 Running 0 14s(二)创建HPA资源
[root@master01 metrics]#cat hpa.yaml
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: hpa-tools
spec:
maxReplicas: 10
minReplicas: 2
scaleTargetRef:
apiVersion: apps/vl
kind: Deployment
name: dm-hpa
targetCPUUtilizationPercentage: 50
------------------------------------------------------------------------------
maxReplicas:10 #指定pod最大的数量是10(自动扩容的上限)
minReplicas:2 #指定pod最小的pod数量是2(自动缩容的下限)
scaleTargetRef #指定弹性伸缩引用的目标
apiVersion: apps/vl #目标资源的api
kind: Deployment #目标资源的类型是Deployment
name:dm-hpa #目标资源的名称
targetCPUUtilizationPercentage: 50 #使用cpu阈值(使用到达多少,开始扩容、缩容)
创建HPA资源
[root@master01 metrics]#kubectl apply -f hpa.yaml
horizontalpodautoscaler.autoscaling/hpa-tools created
[root@master01 metrics]#kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-tools Deployment/dm-hpa 0%/50% 2 10 10 8s
[root@master01 metrics]#kubectl get pod
NAME READY STATUS RESTARTS AGE
dm-hpa-556f64fc9-9fcff 1/1 Running 0 6m34s
dm-hpa-556f64fc9-vzs6p 0/1 ContainerCreating 0 1s
[root@master01 metrics]#kubectl get pod
NAME READY STATUS RESTARTS AGE
dm-hpa-556f64fc9-9fcff 1/1 Running 0 6m38s
dm-hpa-556f64fc9-vzs6p 1/1 Running 0 5s
#由于设置的最小阈值为2所以它会自动创建pod,满足最小阈值的需求(三)进行压测
进入pod使用stress压测工具进行压测
[root@master01 metrics]#kubectl exec -it dm-hpa-556f64fc9-9fcff sh
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
sh-4.2# stress --cpu 4
stress: info: [97] dispatching hogs: 4 cpu, 0 io, 0 vm, 0 hdd动态检测HPA
[root@master01 pod]#kubectl get hpa -w
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-tools Deployment/dm-hpa 1%/50% 2 10 2 14m
hpa-tools Deployment/dm-hpa 0%/50% 2 10 2 15m
hpa-tools Deployment/dm-hpa 1%/50% 2 10 2 16m
hpa-tools Deployment/dm-hpa 130%/50% 2 10 2 17m
查看Pod资源
[root@master01 pod]#kubectl get pod
NAME READY STATUS RESTARTS AGE
dm-hpa-556f64fc9-2zxgf 1/1 Running 0 39s
dm-hpa-556f64fc9-6jsz2 1/1 Running 0 9s
dm-hpa-556f64fc9-9fcff 1/1 Running 0 24m
dm-hpa-556f64fc9-9gt96 1/1 Running 0 39s
dm-hpa-556f64fc9-9jlm7 1/1 Running 0 9s
dm-hpa-556f64fc9-c6jgk 1/1 Running 0 24s
dm-hpa-556f64fc9-cd8xb 1/1 Running 0 9s
dm-hpa-556f64fc9-fzz5q 1/1 Running 0 9s
dm-hpa-556f64fc9-pc74k 1/1 Running 0 24s
dm-hpa-556f64fc9-vzs6p 1/1 Running 0 17m
#达到最大阈值10pod生成后,CPU负载也会平摊随之下降
[root@master01 pod]#kubectl get hpa -w
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-tools Deployment/dm-hpa 0%/50% 2 10 2 30m
hpa-tools Deployment/dm-hpa 50%/50% 2 10 2 30m
hpa-tools Deployment/dm-hpa 149%/50% 2 10 2 30m
hpa-tools Deployment/dm-hpa 150%/50% 2 10 4 31m
hpa-tools Deployment/dm-hpa 134%/50% 2 10 7 31m
hpa-tools Deployment/dm-hpa 106%/50% 2 10 10 31m
hpa-tools Deployment/dm-hpa 92%/50% 2 10 10 32m
hpa-tools Deployment/dm-hpa 68%/50% 2 10 10 36m
hpa-tools Deployment/dm-hpa 57%/50% 2 10 10 37m
hpa-tools Deployment/dm-hpa 52%/50% 2 10 10 37m
hpa-tools Deployment/dm-hpa 33%/50% 2 10 10 37m
hpa-tools Deployment/dm-hpa 31%/50% 2 10 10 37m
......
当结束压测时,CPU资源会释放,同时Pod实例也会释放
[root@master01 pod]#kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-tools Deployment/dm-hpa 0%/50% 2 10 10 22m
----------------------------------------------------------------------------------------
[root@master01 pod]#kubectl get pod
NAME READY STATUS RESTARTS AGE
dm-hpa-556f64fc9-9fcff 1/1 Running 0 34m
dm-hpa-556f64fc9-vzs6p 1/1 Running 0 27m
-----------------------------------------------------------------------------------------
#Pod缩容的时间可能在5-6分钟左右,
#HPA 扩容的时候,负载节点数量上升速度会比较快;但回收的时候,负载节点数量下降速度会比较慢。
#原因是防止在业务高峰期时因为网络波动等原因的场景下
#果回收策略比较积极的话,K8S集群可能会认为访问流量变小而快速收缩负载节点数量
#而仅剩的负载节点又承受不了高负载的压力导致崩溃,从而影响业务四、命名空间的资源限制
Kubernetes对资源的限制实际上是通过cgroup来控制的,cgroup是容器的一组用来控制内核如何运行进程的相关属性集合。针对内存、CPU 和各种设备都有对应的 cgroup。
默认情况下,Pod 运行没有 CPU 和内存的限额。这意味着系统中的任何 Pod 将能够像执行该 Pod 所在的节点一样, 消耗足够多的 CPU 和内存。一般会针对某些应用的 pod 资源进行资源限制,这个资源限制是通过 resources 的 requests 和 limits 来实现。requests 为创建 Pod 时初始要分配的资源,limits 为 Pod 最高请求的资源值。
(一)创建命名空间
[root@master01 metrics]#kubectl create ns test
namespace/test created
[root@master01 metrics]#kubectl get ns test
NAME STATUS AGE
test Active 8s
(二)对资源数量的限制
创建deployment资源
[root@master01 metrics]#vim deployment.yaml
[root@master01 metrics]#cat deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: centos-test
namespace: test
labels:
app: centos1
spec:
replicas: 6 #指定要运行的Pod副本数为6个
selector:
matchLabels:
app: centos1
template:
metadata:
labels:
app: centos1
spec:
containers:
- name: centos1
image: centos:7
command: ["/bin/bash", "-c", "yum -y install epel-release;yum -y install stress;sleep 36000"]
resources:
limits:
cpu: "1000m"
memory: "512Mi"
---
apiVersion: v1
kind: ResourceQuota #资源配额的类型
metadata:
name: ns-resource
namespace: test #资源配额适用的命名空间
spec:
hard: #定义硬限制,即不能超过的资源配额
pods: "5" #命名空间中可以存在的Pod的最大数量为5个
services: "3" #命名空间中可以存在的Service的最大数量为3个
services.nodeports: "2" #命名空间中可以存在的具有NodePort的Service的最大数量为2个创建资源
[root@master01 metrics]#kubectl apply -f deployment.yaml
deployment.apps/centos-test created
resourcequota/ns-resource created
[root@master01 metrics]#kubectl get all -n test
NAME READY STATUS RESTARTS AGE
pod/centos-test-845c47f786-44bl8 1/1 Running 0 3s
pod/centos-test-845c47f786-55jhp 1/1 Running 0 3s
pod/centos-test-845c47f786-6lmvv 1/1 Running 0 3s
pod/centos-test-845c47f786-gckv2 1/1 Running 0 3s
pod/centos-test-845c47f786-kwbl7 1/1 Running 0 3s
pod/centos-test-845c47f786-r9jsk 1/1 Running 0 3s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/centos-test 6/6 6 6 3s
NAME DESIRED CURRENT READY AGE
replicaset.apps/centos-test-845c47f786 6 6 6 3s
[root@master01 metrics]#kubectl run nginx --image=nginx:1.18.0 -n test
Error from server (Forbidden): pods "nginx" is forbidden: exceeded quota: ns-resource, requested: pods=1, used: pods=6, limited: pods=
------------------------------------------------------------------------------------------
#ResourceQuota 是用来限制命名空间内资源使用的配额,并且当超出限制时,
#它主要影响的是未来的资源请求,比如新的Pod的创建请求
#在指定的命名空间中的ResourceQuota已经被达到或超过时,Kubernetes API服务器会拒绝Pod的创建请求,并返回一个错误。
#但是,对于已经存在的Pod,ResourceQuota 并不会自动删除或终止它们(三)对资源配额的限制
如果Pod没有设置requests和limits,则会使用当前命名空间的最大资源;如果命名空间也没设置,则会使用集群的最大资源。
K8S 会根据 limits 限制 Pod 使用资源,当内存超过 limits 时 cgruops 会触发 OOM。
这里就需要创建 LimitRange 资源来设置 Pod 或其中的 Container 能够使用资源的最大默认值
[root@master01 metrics]#vim limit.yaml
[root@master01 metrics]#cat limit.yaml
apiVersion: v1
kind: LimitRange #表示使用limitrange来进行资源控制
metadata:
name: test2-limit
namespace: test
spec:
limits:
- default: #default: 即 limit 的值
memory: 512Mi
cpu: "1"
defaultRequest: #defaultRequest: 即 request 的值
memory: 256Mi
cpu: "0.5"
type: Container #类型支持 Container、Pod、PVC














 2019
2019

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









