







分类目录:《系统学习Python》总目录
从最底层来看,类基本上就是命名空间,这点很像Python的模块。但是类和模块不同的是,类还支持生成多个对象、命名空间继承以及运算符重载。
要了解多个对象的概念是如何工作的,我们需要先了解Python的OOP模型中的两种对象:类对象和实例对象:
- 类对象:提供默认行为,是实例对象的工厂
- 实例对象:程序处理的实际对象
各自都有独立的命名空间,但是同时继承了创建该实例的类中的变量名。类对象来自语句,而实例来自调用。每次调用一个类,你就会得到这个类的一个新的实例。
这种对象生成的概念和我们目前为止所见的大多数其他程序构件有着很大的不同。实际上,类是产生多个实例的工厂。相比之下,所有模块在程序中只能导入一个副本。事实上,这也就是我们需要用到reload,它在原位置更新一个单例共享的模块对象。借助类,每个实例都有了它们自己的、独立的数据,从而支持类所建模型的对象的多个版本。
在这一角色下,类实例类似于闭包函数的基于调用的状态,但是这是类模型本身的一部分,并且类中的状态是显式的属性而不是隐式的作用域引用。此外,这只是类所做的部分工作——它们也支持通过继承实现的定制化、运算符重载,以及通过方法实现的多态行为。一般来讲,类是更加完整的编程工具,尽管OOP和函数式编程并不是相互排压的编程范式。我们通过在方法中使用函数化的工具,编写自身就是生成器的方法,以及编写用户定义的选代器等来将二者结合起来。
下面就是从类对象和实例对象出发,对Python中OOP本质的一个快速总结。正如我们将看到的,从某种程度上来说Python的类与def和模块很相似,但是Python中的类和其他编程语言中的相比可能就大不相同了。
类对象提供默认行为
当我们执行class语句时,就会得到类对象。以下是Python类的主要特性:
class语句创建类对象并将其赋值给一个名称:就像函数的def语句,Python的class语句也是可执行语句。当其执行时会产生新的类对象,并被赋值给class头部的名称。此外,就像def一样,class语句一般是在其所在文件被导入时执行的。class语句内的赋值语句会创建类的属性:就像模块文件一样,class语句内顶层的赋值语句(不是在嵌套的def之内)会产生类对象中的属性。从技术角度来讲,class语句定义了一个局部作用域,该作用域会变成类对象的属性的命名空间,就像模块的全局作用域一样。在执行class语句后,类的属性可用点号加名称访问:object.name。- 类属性提供了对象的状态和行为:类对象的属性记录了可由这个类所创建的所有实例共享的状态信息和行为。类内部的函数
def语句会生成方法,方法可用于处理实例。
实例对象是具体的元素
当调用类对象时,我们得到了实例对象。以下是类的实例的重点概要:
- 像函数那样调用类对象会创建新的实例对象:每次类被调用时,都会建立并返回新的实例对象。实例代表了程序领域中的具体元素。
- 每个实例对象继承了类的属性并获得了自己的命名空间:由类所创建的实例对象是新的命名空间。它们一开始是空的,但是会继承创建该实例的类对象内的属性。
- 在方法内对
self属性做赋值运算会产生每个实例自己的属性:在类的方法函数内,第一位参数(按惯例称为self)会引用当前处理的实例对象。对self的属性做赋值运算,会创建或修改实例内的数据,而不是类的数据。
最终的结果就是,类定义了公用的、共享的数据和行为,并生成实例。实例反映了具体的应用程序中的实体,并记录了每个实例自己的随着对象变化的数据。
实例
我们下面用一个真实的例子,来看看这些概念在实际中是如何工作的。首先,让我们编写一个Python的class语句,来定义一个名为FirstClass的类:
class FirstClass:
def setdata(self, value):
self.data = value
def display(self):
print(self.data)
一般来说这种语句是当其所在的模块文件导入时运行的。就像通过def建立的函数,这个类在Python抵达并执行语句前是不会存在的。
就像所有复合语句一样,class开头一行会列出类的名称,后面再接一个或多个内嵌并且缩进的语句的主体。在这里嵌套的语句是def,它们定义了类要暴露出的行为的函数,def本质上是赋值运算。在这里是在class语句的作用域内,把函数对象赋值给名称setdata和display,从而产生附加在类上的FirstClass.setdata和FirstClass.display属性。事实上,所有在类嵌套代码块的顶层被赋值的名称,都会成为类的属性。
位于类中的函数通常称为方法。方法采用一般的def语句编写,并且支持之前我们讲过的所有关于函数的内容,不过在方法函数被调用时,第一位参数自动接收隐含的实例对象,即调用的主体。我们需要创建一些类的实例来理解其工作原理:
x = FirstClass()
y = FirstClass()
以此方式调用类时会产生实例对象,而这些实例对象其实是可访问类属性的命名空间。可以说,我们此时有三个对象:两个实例对象和一个类对象。其实是有三个相链接的命名空间,如下图所示:
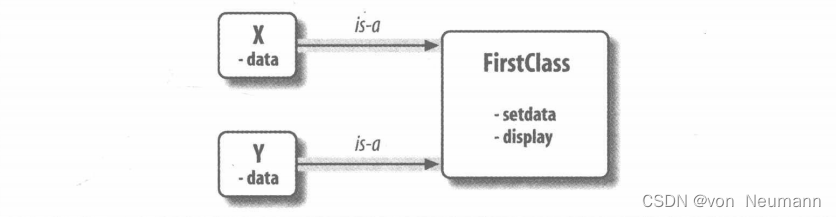
以OOP观点来看,我们说x和y都是FirstClass对象,也就是说它们都继承了附加于类上的名称。这两个实例一开始是空的,但是它们被连接到创建它们的类。如果对实例以及类对象内的属性名称做点号运算,Python就会通过继承搜索访问类中的名称(除非该名称也位于实例内):
x.setdata('hy592070616')
y.setdata('MachineLearning')
×或y本身都没有setdata属性,为了寻找这个属性,Python会顺着实例到类的连接搜索。而这就是所谓的Python的继承:继承是在属性点号运算时发生的,而且只与查找连接对象内的名称有关。在这里,是通过遵循上图的is-a连接。
在FirstClass的setdata函数中,传入的值会被赋给self.data。在方法中,self会自动引用当前处理的实例(x或y),所以赋值语句会把值储存在实例的命名空间,而不是类的命名空间:这也就是上图中变量名data的创建的方式。因为类可以产生多个实例,所以方法必须通过self参数才能获取当前处理的实例。当调用类的display方法来打印self.data时,我们会发现每个实例的值都不相同。另外,名称display在×和y中都相同,因为它是来自(或继承自)类的:
x.display()
y.display()
输出:
hy592070616
MachineLearning
注意,我们在每个实例内的data成员储存了不同类型的对象,这里分别是字符串和浮点数。就像Python中的其他事物,实例属性(有时称作成员)并没有声明。与简单变量一样,实例在首次赋值后就会存在。事实上,如果在调用setdata之前就对某一实例调用display,则会触发名称未定义的错误,这是因为data属性在setdata方法赋值前,是不会在内存中存在的。
另一种理解该模型的动态性的方式是,我们可以在类的内部或外部修改实例属性。在类的内部,通过方法对self进行赋值运算,而在类的外部,则可以通过对实例对象进行赋值运算:
x.data = 'hy592070616: MachineLearning'
x.display()
输出:
hy592070616: MachineLearning
虽然比较少见,但是我们甚至还可以通过在类方法函数外对变量名进行赋值运算,从而在实例命名空间内产生全新的属性:
x.blog = 'CSDN'
这样会增加一个名为blog 的新属性,实例对象x的所有类方法都可以选择使用它。类通常可以选择通过对self参数进行赋值运算从而建立实例的所有属性的。程序可以访问、修改或创建其所引用的所有对象的属性。
通常,添加类所不能使用的数据是没有意义的,因此我们可以基于属性访问运算符重载,使用额外的“私有”代码来阻止这种操作。不过,自由的属性访问使用了更少的语法,甚至有些情况下它是有用的——例如,在编写我们稍后看到的数据记录代码时。
















 1330
1330











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











