







最近,用kettle把DB2的数据抽取到impala上,发现数据量异常,数据错开等情况。
检查发现DB2源表里的数据某个字段中内容含有英文的逗号,而impala上建的表TERMINATED BY ','也用英文逗号分隔的,所以造成数据错乱;另外源表数据字段内容包含换行、回车符也会导致到impala数据分隔异常 数据错乱。
解决方案:针对分隔符,导致的 ;可以换一种分隔符 |,重新建表
CREATE TABLE DB_NAME.TB_NAME (
ROW_ID DECIMAL(20,0),
SLOGAN STRING,
CREATED_TIME TIMESTAMP
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '|'
WITH SERDEPROPERTIES ('field.delim'='|', 'serialization.format'='|')
STORED AS TEXTFILE
LOCATION 'hdfs://IP:8020/user/hive/warehouse/XX.db/TB_NAME'
kettle 数据输出组件上的分隔符也对应调整
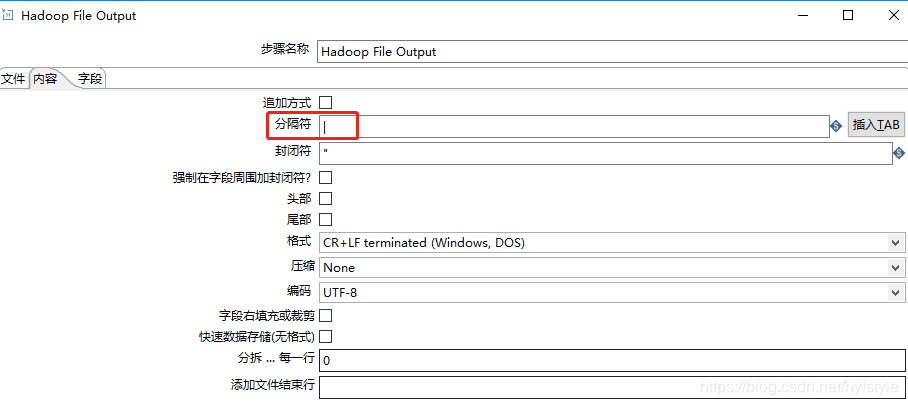
或者不需要重建表,获取数据时将字段中的英文逗号转换成中文的replace(SLOGAN,',',',')
如果源数据中存在换行回车符,可以trim(replace(replace(SLOGAN ,CHAR(13),''),CHAR(10),' '))
如果都有直接都替换再传到impala trim(replace(replace(replace(SLOGAN ,',',',') ,CHAR(13),''),CHAR(10),' '))
发现用kettle抽取DB2数据库的数据到impala上的表(TEXTFILE格式存储的表),源表中的字段例如ROW_ID是DECIMAL数值型的,impala上也是DECIMAL数值型的,如果不指定字段的长度和精度,hdfs文件里有数据内容,但是impala表select时row_id显示为null;指定了BigNumber类型的长度和精度后(hdfs文件中该字段值不足20位会在前面用0补齐位数)则能select出来



例如源表字段CREATED_TIME是TIMESTAMP格式的, impala上对应字段也是TIMESTAMP的,hdfs文件里的内容在时分秒后面有.000000000,则impala上查询数据时显示null;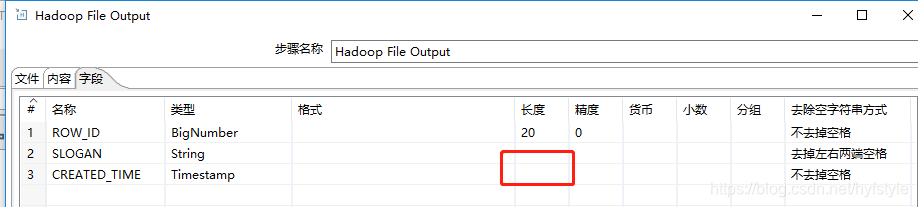
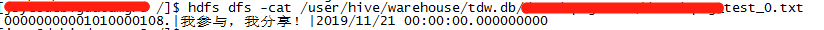
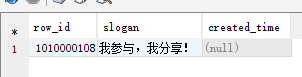
源表日期数据要格式化转换下to_char(CREATED_TIME,'YYYY-MM-DD HH24:MI:SS') as CREATED_TIME再传即可
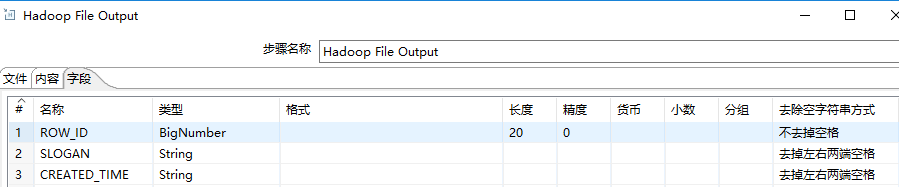


所以 源表数据字段类型、长度等要匹配上Impala表的字段数据类型,否则select不出来,显示null
备注:如果是mysql库里的TIMESTAMP的字段传到impala上(impala对应字段类型也是TIMESTAMP),日期数据转换下date_format(CREATED_TIME,'%Y-%m-%d %H:%i:%S') or date_format(CREATED_TIME,'%Y-%m-%d %T')
impala常用数据类型: 源自官方文档
| 数据类型 | 详细说明 |
|---|---|
| BIGINT | Range:-9223372036854775808 - 9223372036854775807 ;用于建表或者sql中:CREATE TABLE t1(x BIGINT);SELECT CAST(1000 AS BIGINT) |
| DOUBLE | 存储4.94065645841246544e-324d 至 1.79769313486231570e+308 范围内的浮点值 |
| DECIMAL | 存储十进制值 , Range:-10^38 +1 至 10^38 –1,最长的是DECIMAL(38, 0) |
| INT | 存储 -2147483648 至 2147483647范围内的 4字节 整数 |
| SMALLINT | 存储 -32768至32767范围内的 2字节 整数 |
| TINYINT | 存储 -128至127范围内的 1字节 整数 |
| FLOAT | 存储 1.40129846432481707e-45 至 3.40282346638528860e+38 范围内的单精度浮点值 |
| STRING | 存储 字符串值 |
| VARCHAR | 存储可变长度字符,最大长度为65535,VARCHAR(max_length) |
| CHAR | 存储固定长度字符,最大长度为255,CHAR(length) |
| BOOLEAN | 只存储true或false值 |
| TIMESTAMP | 存储时间格式的值,Range: 1400-01-01 to 9999-12-31,DATE_ADD (timestamp, INTERVAL interval time_unit) |
| ARRAY | ARRAY < type >,存储可变数量的有序元素,Complex Types (CDH 5.5 or higher only) |
| MAP | MAP < primitive_type, type >,存储可变数量的键值对,Complex Types (CDH 5.5 or higher only) |
| STRUCT | STRUCT < name : type [COMMENT ‘comment_string’], … > ,表示单个项目的多个字段,Complex Types (CDH 5.5 or higher only) |
| REAL | 是DOUBLE类型的一个别名,REAL and DOUBLE interchangeably(可交换的) |
www:
有张表的记录数据有创建时间和更新时间 TIMESTAMP格式,而且数据量较大;而记录在创建以后可能N天之后会进行更新(大于1次),每天要从DB2数据库更新数据到impala上;
创建TEXTFILE格式存储数据的临时表和PARQUET格式的正式表;每天根据临时表的数据 overwrite 正式表 insert overwrite table XX.XXXX partition(dt_month_id,dt_day_id) select * from XX.XXXX_tmp;
一开始我根据创建时间或者更新时间的年月日创建分区,后面直接获取最近几天更新记录数据,到最后 impala上总记录数据总是或多(根据更新时间创建分区)或少(根据创建时间创建),因为获取的数据量肯定比实际分区文件中的文件或多或少。
最终的解决办法是:截取创建时间的年月日创建分区cast(to_char(CREATED_TIME,'YYYYMMDD') as int) as dt_day_id,每天获取最近几天更新记录的创建时间最小值,获取大于等于最小创建时间的记录数据 更新那些天的文件: where CREATED_TIME >= (select substr(min(CREATED_TIME),1,10) || ' 00:00:00' from XX.TB_NAME where to_char(LAST_UPD_TIME,'YYYYMMDD') >= to_char(current date - 2 day,'YYYYMMDD') )














 3889
3889











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









