






持续更新…
具体不懂的看对应版本的帮助文档…
也可以查看 W3school的python教程
Python
- 1. Python简介和环境搭建
- 2. Python基础语法
- 2.1 编码
- 2.2 标识符
- 2.3 关键字(保留字)
- 2.4 注释
- 2.5 行与缩进
- 2.6 多行语句(延续符) `\`
- 2.7 空行
- 2.8 print函数 `print(对象,...,对象n)`/`print(对象,...,对象n, end="")`/`print(对象,...,对象n, sep="间隔符")`
- 2.9 导包 `import`/`from...import`
- 2.10 头部注释模板
- 2.11 help函数
- 2.12 切片(字符串截取)`print(字符串名[n,m,x])`
- 2.13 控制台输入 `input(prompt)`
- 2.14 格式化(占位符,格式化函数)
- 2.15 range函数
- 2.16 全局变量和局部变量
- 2.17 文档字符串 `""`
- 2.18 推荐的函数调用方式 `if __name__ == '__main__':`
- 2.19 python有重写,没有重载
- 3. 变量与数据类型、运算符和语句结构
- 4. 函数(函数定义,函数调用,参数传递,匿名函数)
- 5. 文件读写
- 6. 面向对象
- 7. 异常处理
1. Python简介和环境搭建
1.1 Python简介
Python是一个高层次的结合了解释性,互动性和面向对象的脚本语言。
Python的设计具有很强的可读性,它具有比其他语言更有特色的语法结果。
Python
1)解释性语言:开发中没有编译环节,类似于php和perl语言;
2)交互式语言:可以在Python提示符,直接互动执行程序;
3)面向对象语言:Python支持面向对象风格或代码封装在对象的编程技术。
Python像Perl语言一样,Python源代码同样遵循GPL(GNU General Public License)协议。
Python语言特点
1)易于学习:较少的关键字,结构简单,明确定义的语法;
2)易于阅读:代码定义清晰
3)易于维护:源代码容易维护
4)广泛的标准库:Python的最大的优势之一就是丰富的库;
5)互动模式:终端输入执行代码,就可获得结果,互动的测试和调试代码片段;
6)可移植性
7)可扩展性:比如你需要运行一段关键代码,而又不想公开算法,就可以使用C或C++完成编码后,从Python程序中调用;
8)数据库:Python提供所有主要的商业数据库接口;
9)GUI编程:Python支持GUI可以创建和移植到许多系统调用;
10)可嵌入式:可将Python潜入到C或C++程序,让你的程序的用户获得“脚本化”的能力。
Python2.x和Python3.x区别
Python的3.0版本,常被称为Python 3000或简称Py3k,相对与Python的早期版本,这是一个较大的升级,值得注意的是,Python 3.0在设计的时候为了不代入过多的累赘,没有考虑向下兼容,所以许多针对早期Python版本设计的程式都无法早Python 3.0上正常执行;
为了照顾现有程式,Python 2.6作为了一个过渡版本,基本使用了Python 2.x的语法和库,同时考虑了向Python 3.0的迁移,允许使用部分Python 3.0的语法和函数。
新的Python程式建议使用Python 3.0版本的语法。
除非执行环境无法安装Python 3.0或者程式本身使用了不支援Python 3.0的第三方库,目前不支持Python 3.0的第三方库有Twisted,py2exe,PIL等。
大多数第三方库都正在努力地相容Python 3.0版本,即使无法立即使用Python 3.0,也建议编写相容Python 3.0的程式,然后使用Python 2.6,Python 2.7来执行。
1.2 Python的安装和环境搭建
1)Python在windows下的安装,并且安装后需要配置环境变量(略)
在windows下,验证Python是否安装成功
进入命令提示符(cmd),输入python

2)安装PyCharm和jdk,注意PyCharm需要java环境,所以使用该软件,那么同时也要安装jdk,jdk安装后也要配置环境变量,jdk可以安装多个版本,便于在开发时灵活切换,jdk最好安装两个较稳定的版本,一般jdk8有安装的必要。jdk和PyCharm安装过程略

验证jdk是否安装和配置环境变量成功
进入命令提示符(cmd)输入java -version、java、javac



3)进入PyCharm
新建名为learn的项目

项目中新建一个study.py文件,一个.py文件就是模块


2. Python基础语法
2.1 编码
默认情况下,Python 3源码文件以UTF-8编码,所有字符串都是unicode字符串,也可以为源码文件指定不同的编码标识符。
2.2 标识符
标识符是用户编程时使用的名字,用于给变量、常量、函数、语句块等命名,以建立起名称与使用之间的关系。
1)第一个字符必须是字母表中字母或下划线;
2)标识符的其他部分有字母、数字和下划线组成;
3)标识符对大小写敏感;
4)不可使用关键字。
eg:
定义变量
_name = 'Tom'
a_name7 = 'Smith'

2.3 关键字(保留字)
eg:
打印出Python的所有关键字(保留字)和关键字的数量
from keyword import kwlist;
print(kwlist)
print(len(kwlist))
我使用的python版本是3.7.1,一共有35个关键字

2.4 注释
2.4.1 单行注释 #
功能:单行注释
格式:
# 单行注释 单行注释 单行注释
eg:
# 定义一个变量

2.4.2 块注释 ''' '''/""" """
功能:块注释
格式一(三个单引号开头,三个单引号结尾):
'''
块注释
块注释
一般用于注释
'''
格式二(三个双引号开头,三个双引号结尾):
"""
块注释
块注释
一般用于文档字符串,用于对函数的参数和返回值进行说明
"""
eg:
格式一

格式二:

2.5 行与缩进
Python最具特色的就是用缩进来表示代码块,而不需要用大括号{}。
统一使用4个空格代表一个缩进
eg:
比如分支结构
a, b = 1, 2
if a > b:
print("a大于b")
else:
print("a小于等于b")

2.6 多行语句(延续符) \
Python通常是一行写完一条语句,如果单行语句过长,我们可以使用反斜杠\来实现多行语句。
功能:在一行的语句过长时可,使用多行语句
格式:
语句语句语句语句语句语句 \
语句语句语句语句语句语句 \
语句语句语句语句语句语句 \
eg:
total = 1 + 2 + 3 + 4 + 5 + \
6 + 7 + 8 + 9 + 10 + \
12 + 13

2.7 空行
1)函数之间或类的方法之间用空行分隔,表示一段新代码的开始;类和函数入口之间也用空行分隔,以突出函数入口的开始。
2)空行与缩进不同,空行并不是Python语法的一部分,书写时不插入空行,Python解释器也不会出错,但空行的作用在于分隔两段不同功能或含义的代码,便于日后代码的维护或重构。
eg:
分隔两个函数
# 分隔两个函数,推荐空两行
# 两个方法之间用空行分隔
def func():
pass
def func2():
pass

2.8 print函数 print(对象,...,对象n)/print(对象,...,对象n, end="")/print(对象,...,对象n, sep="间隔符")
1)print默认输出是换行的,如果要实现不换行需要在变量末尾加上end="";
2)print打印多个对象时,默认使用一个空格间隔,要想指定间隔可以使用sep指定间隔符。
功能:输出,换行
格式一:
# print()输出,自动换行
print(对象,...,对象n)
功能:输出,不换行
格式二:
# print(,end="")输出,不换行
# print打印多个对象时,默认使用一个空格间隔
print(对象,...,对象n, end="")
功能:输出多个对象,sep指定间隔符
格式三:
print(对象,...,对象n, sep="间隔符")
eg:
# print()输出,自动换行
print("a + b")
# print(,end="")输出,不换行
print("a + b", "= c", end="")
# sep指定间隔符
print("\na", "b", "b", sep='%')

2.9 导包 import/from...import
包中一个.py文件,就是一个模块。
在python中用import或者from...import来导入包中的模块
功能:导入模块
格式:
import 模块名 [as 别名]
功能:导入模块中函数或成员
格式:
from 模块名 import 函数名/成员,函数名2/成员2,...,函数名n/成员n
功能:将某个模块中的函数或成员全部导入
格式:
from 模块名 import *
eg:
导入sys模块
import sys

导入sys模块的特定成员
# path其实就是系统的path环境变量
from sys import argv, path

自定义模块
1)新建一个包p1,用来放置我们的模块,注意新建后会出现一个,__init__.py,如果没有这个文件,我们就无法查找模块的路径
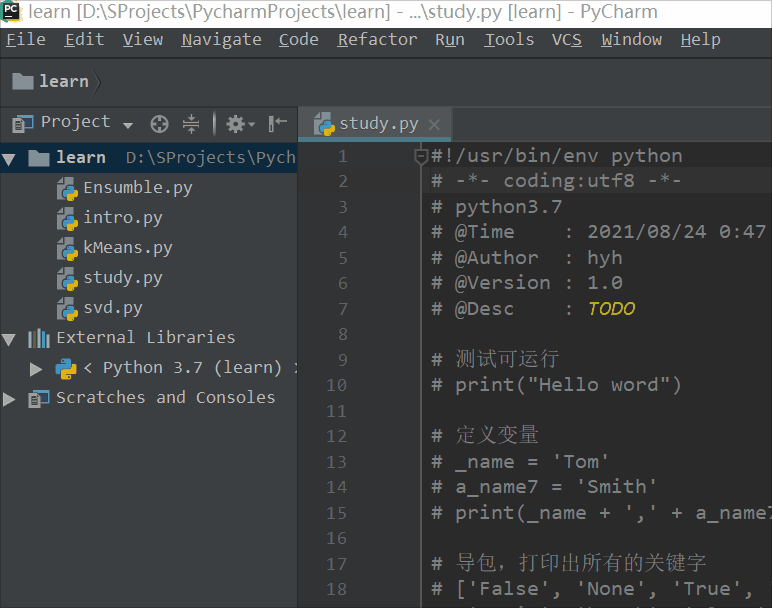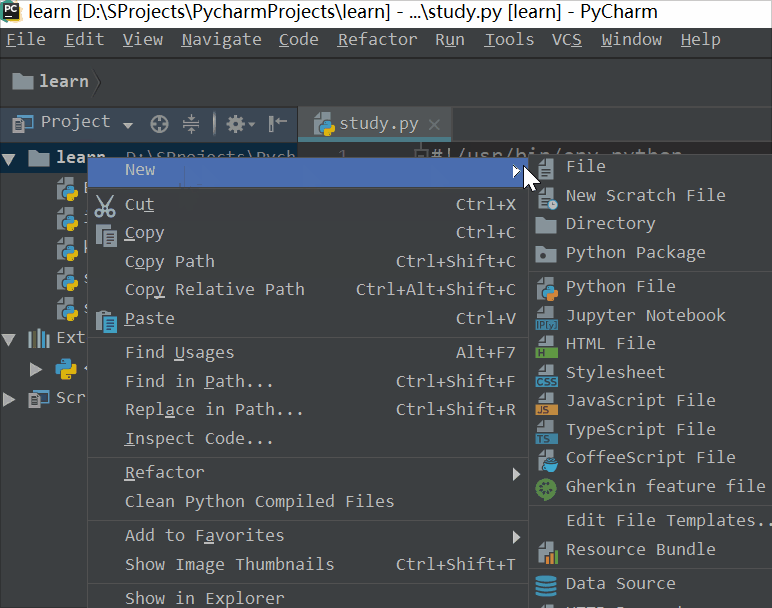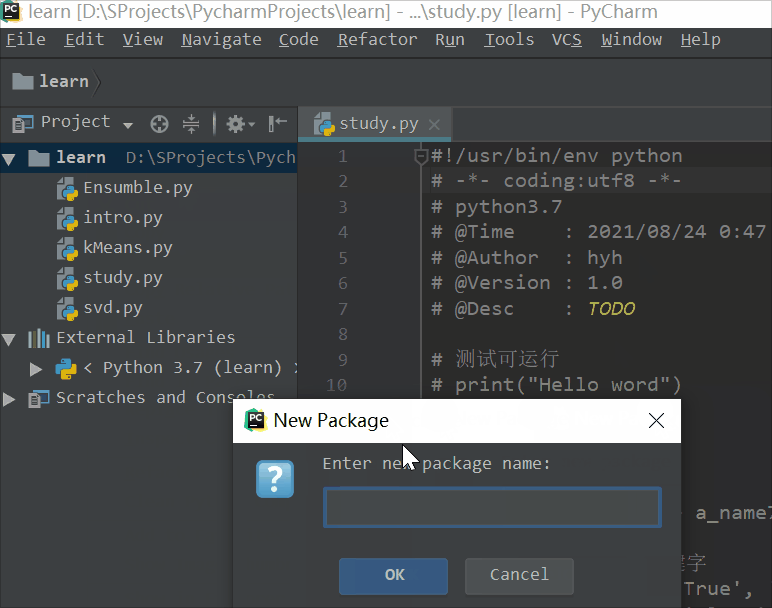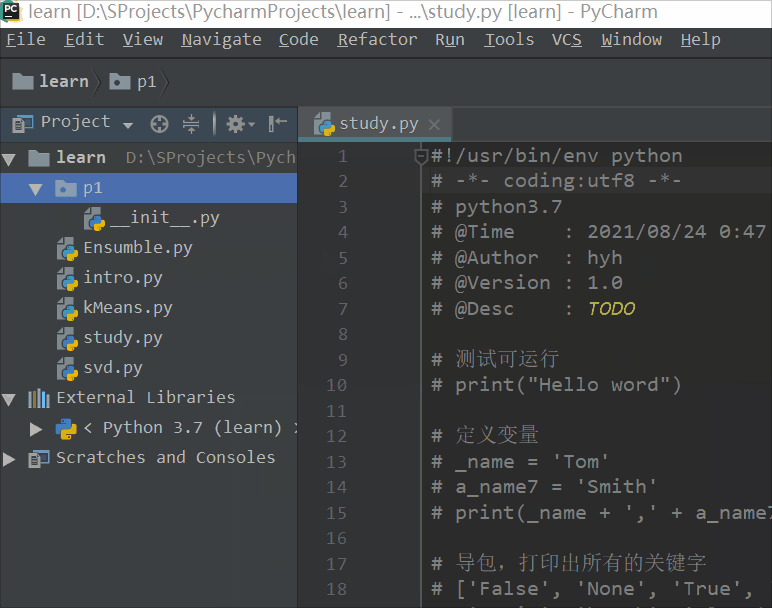
2)包p1中新建m1模块m1.py,m2模块m2.py
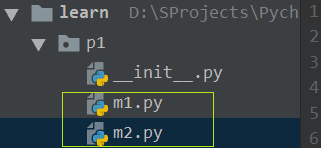
m1.py
#!/usr/bin/env python
# -*- coding:utf8 -*-
# python3.7
# @Time : 2021/08/29 22:32
# @Author : hyh
# @Version : 1.0
# @Desc : TODO
def func():
print("m1-func")
def func2():
print("m1-func2")
if __name__ == '__main__':
func()
func2()
m2.py
#!/usr/bin/env python
# -*- coding:utf8 -*-
# python3.7
# @Time : 2021/08/29 22:32
# @Author : hyh
# @Version : 1.0
# @Desc : TODO
class A:
def method(self):
print("m2-classA-method")
def method2(self):
print("m2-classA-method2")
class B:
def method(self):
print("m2-classB-method")
def method2(self):
print("m2-classB-method2")
if __name__ == '__main__':
a = A()
b = B()
a.method()
a.method2()
b.method()
b.method2()
3)在study.py中导包调用模块
方式一:导入模块
# 导入模块m1(该模块中有定义的函数)
import p1.m1 as pm1 # 为了简化模块名p1.m1,我们起一个别名pm1
# 导入模块m2(该模块中有定义的类)
import p1.m2 as pm2 # 为了简化模块名p1.m2,我们起一个别名pm2
if __name__ == '__main__':
pm1.func()
pm1.func2()
pm2.A().method()
pm2.A().method2()
pm2.B().method()
pm2.B().method2()

方式二:
# from p1.m1 import func # 导入模块中的函数func
# from p1.m1 import func2 # 导入模块中的函数func2
from p1.m1 import func, func2 # 导入模块中的多个函数
# from p1.m1 import * # 导入模块中的所有函数,不推荐
# from p1.m2 import A # 导入模块中的类A
# from p1.m2 import B # 导入模块中的类B
from p1.m2 import A, B # 导入模块中的多个类
# from p1.m2 import * # 导入模块中的所有类,不推荐
if __name__ == '__main__':
func()
func2()
# 调用一个类中的方法
# 如果类中的方法只是部分需要使用,建议使用导包的方式来调用
# 如果类中的方法全部要使用,推荐使用继承的方式来调用
a = A()
a.method()
a.method2()
b = B()
b.method()
b.method2()

2.10 头部注释模板
在linux下,使用/usr/bin/env目录下的python解释器运行脚本
格式:
#!/usr/bin/env python
在windows下,指定文件编码格式
格式:
# -*- coding:utf8 -*-
eg:
设置python文件头部注释模板过程
File->Setting->File and Code Template->Python Script->设置python文件头部注释模板内容->Apply

当创建python文件时,头部模板自动生成

2.11 help函数
调用python的help函数可以打印输出一个函数的文档字符串
eg:
help(max),可以查看max内置函数的参数列表和规范文档
help(max)

从文档字符串可以看出这个函数可以判断多个对象中的最大值
print(max(1, 2, 3, 4, 12, 3))

我们也可以将光标移动到max函数上,然后按住ctrl + b直接跳到函数定义中去看

2.12 切片(字符串截取)print(字符串名[n,m,x])
功能:截取字符串切片
格式:
# n,m都表示下标的位置
# 左闭右开 n能取到,m不能取到 范围:n~m-1
# x 代表步长,即间隔取字符
print(字符串名[n,m,x])
eg:
# 输出字符串'hello world!'的切片 2~7位置上的字符 'ello w'
str1 = 'hello world!'
print(str1[1:7])

# 输出整个字符串
# 方式1、方式2、方式3、方式4、方式5等价
str1 = 'rivers a raging'
print(str1) # 方式1
print(str1[:]) # 方式2 默认 : 左右两边就是字符串开始和结束的下标
print(str1[0: len(str1)]) # 方式3 同理
print(str1[0:]) # 方式4 同理
print(str1[:len(str1)]) # 方式5 同理
# 按照 : 左右两边就是字符串开始和结束的下标,可以这样写
print(str1[:-4]) # 右边的下标-4 输出'rivers a ra'

# 第三位数字代表步长,可以让切片间隔取
str1 = 'rivers a raging'
print(str1[::3]) # 在'rivers a raging'的基础上隔3个字符间隔取

2.13 控制台输入 input(prompt)
eg:
content = input("请输入一个整数:") # input接受的任意内容,统一都是字符串的形式
if content < 10:
print('输入了一个小于10的整数')
else:
print('输入了一个大于等于10的整数')
2.14 格式化(占位符,格式化函数)
python中%d
Python format 格式化函数
python的%d、%s、%r等的用法
2.15 range函数
python2.x range() 函数可创建一个整数列表,一般用在 for 循环中
range()函数可以生成数列,可以指定区间的值,也可以指定区间并规定增量,甚至可以是负数等。
格式:
range(start, stop[, step])
2.16 全局变量和局部变量
eg:
a = 1 # 全局变量,定义在函数体外,作用于整个代码
def func():
a = 2 # 局部变量,定义在函数体中,作用于函数内部
print(a) # 2
func()
print(a) # 1
a = 1 # 全局变量,定义在函数体外,作用于整个代码
def func():
global a # global关键字,声明变量是一个全局变量
a = 2
print(a) # 2
func()
print(a) # 2
print(func.__doc__) # 查看文档字符串的全部内容
2.17 文档字符串 ""
1)文档字符串是用于对函数的参数和返回值进行说明。
2)在函数内部写三个双引号,IDE自动补全后面三个双引号,回车自动生成文档字符串。
eg:
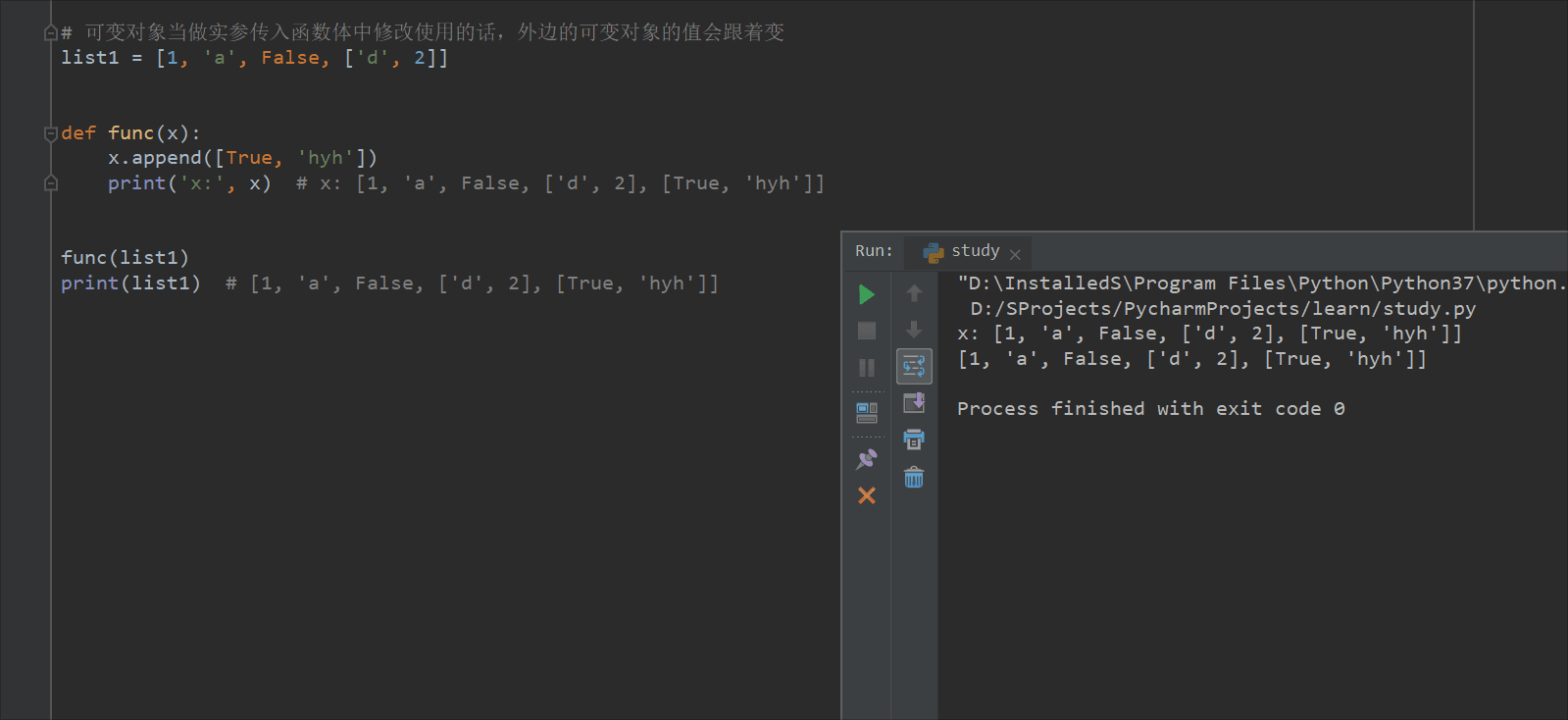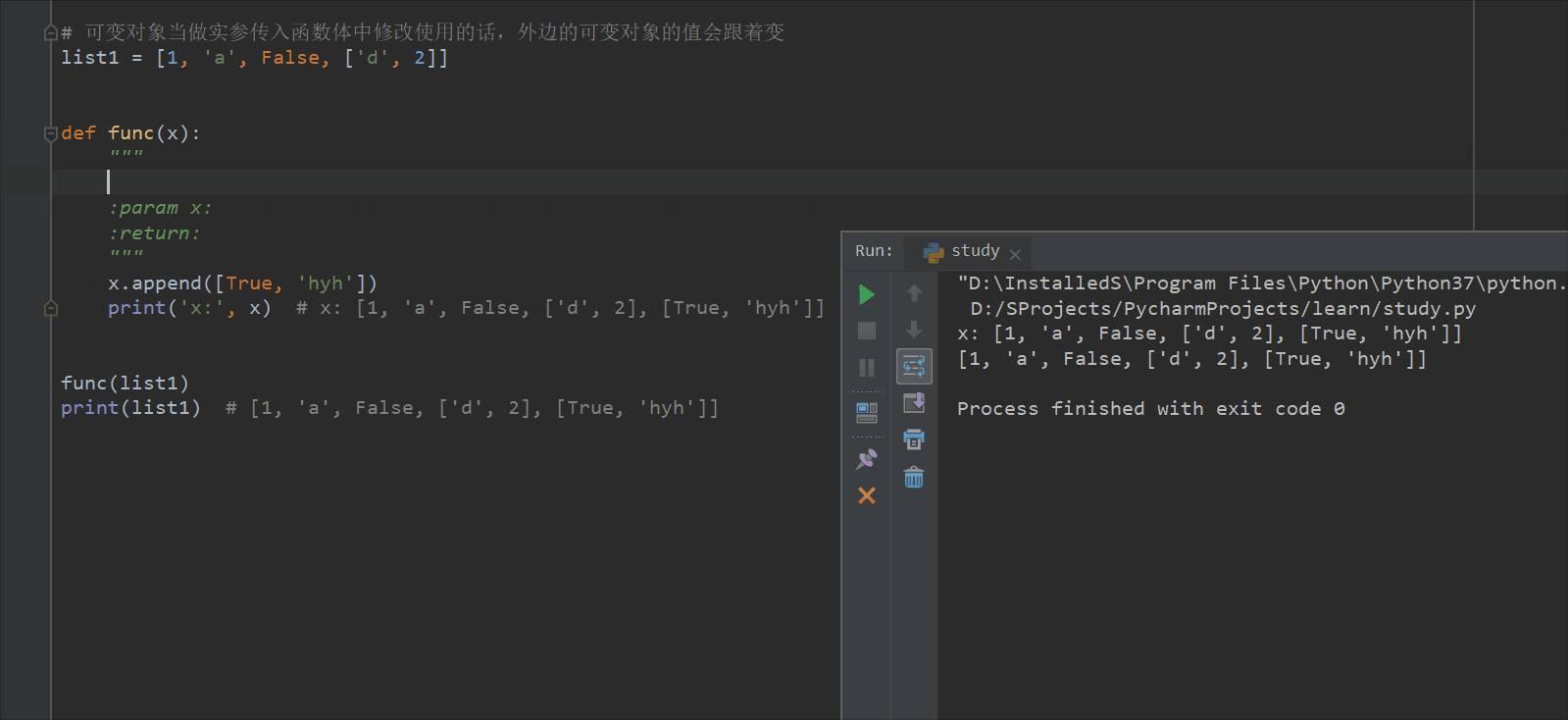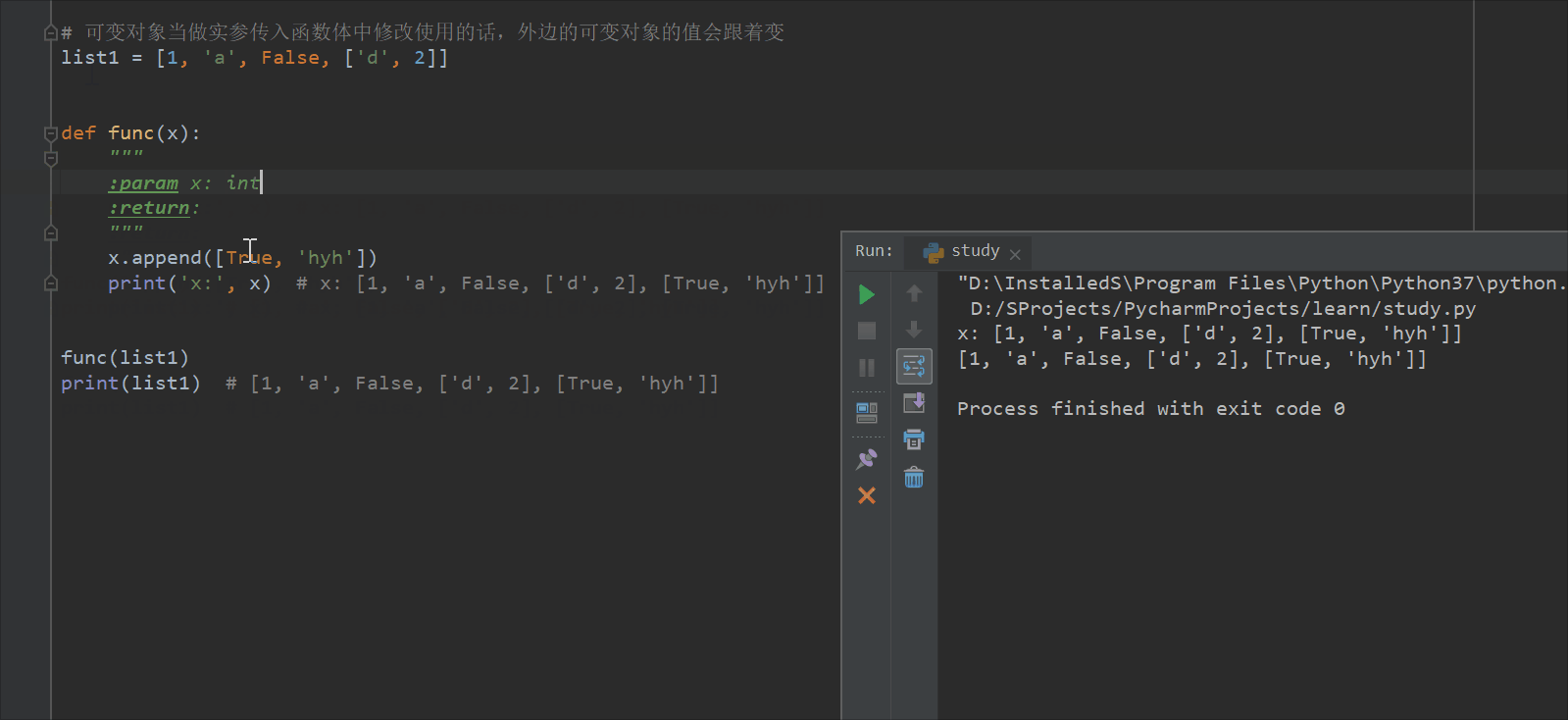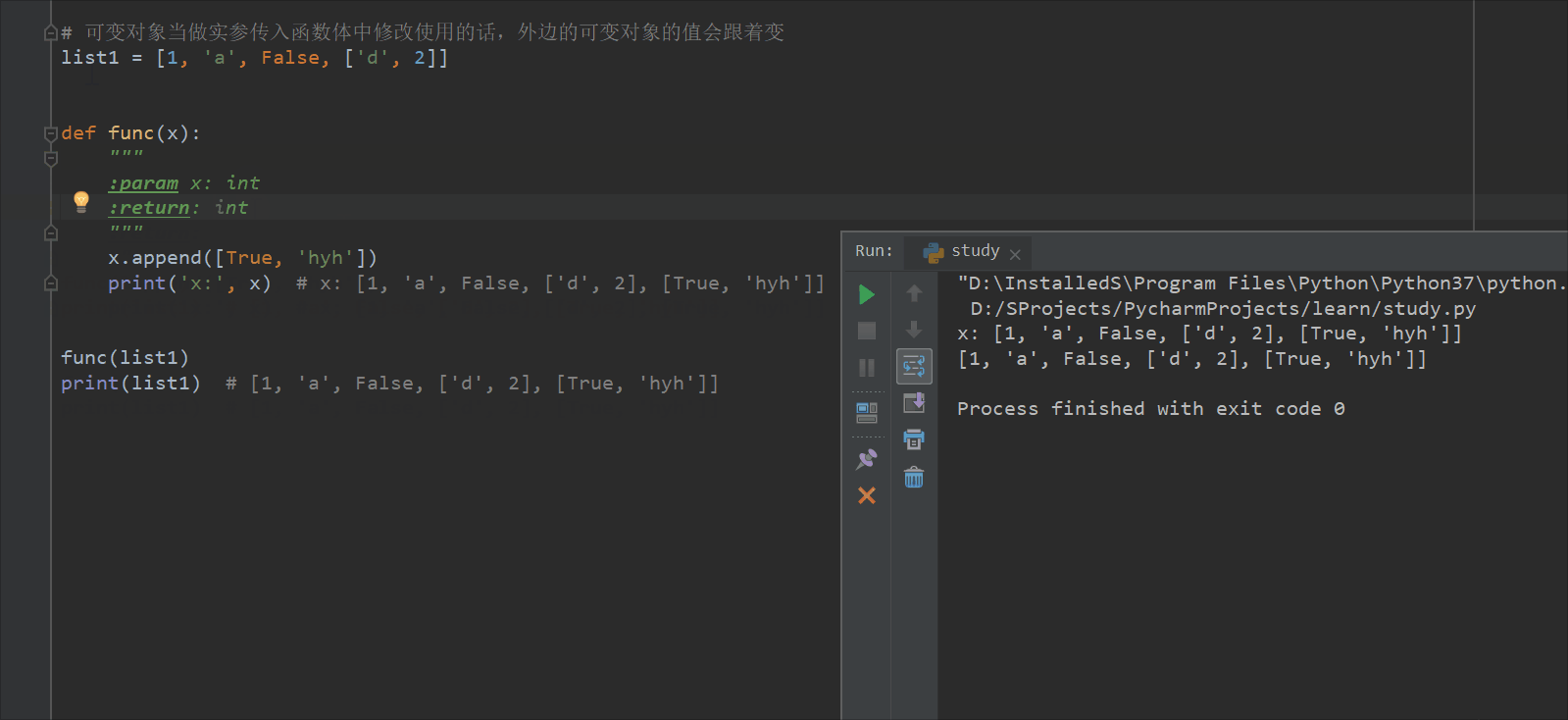
# 可变对象当做实参传入函数体中修改使用的话,外边的可变对象的值会跟着变
list1 = [1, 'a', False, ['d', 2]]
def func(x):
"""
:param x: int
:return: int
"""
x.append([True, 'hyh'])
print('x:', x) # x: [1, 'a', False, ['d', 2], [True, 'hyh']]
func(list1)
print(list1) # [1, 'a', False, ['d', 2], [True, 'hyh']]
print(func.__doc__) # 查看文档字符串的全部内容

2.18 推荐的函数调用方式 if __name__ == '__main__':
如果自己执行当前文件,条件满足,对应的调用语句会执行,若跨模块导包调用时,如果条件不满足,不会执行调用语句。
eg:
def func(name, age):
print("姓名:%s, 年龄:%d" % (name, age))
# 其实并不推荐这种调用函数的方式
func('hyh', 24)
# 推荐这种调用函数的方式
# 这种方式:如果自己执行当前文件,条件满足,对应的调用语句会执行,若跨模块导包调用时,如果条件不满足,不会执行调用语句
# 原因:就是要限制函数执行的条件,如果不限制,倘若在另一个模块导包后,会从上到下执行这个包可执行的语句,而不是单单执行你指定要执行的函数!
if __name__ == '__main__':
func('hyh2', 26)
print(__name__) # 模块自己调用自己的函数时,__name__ = __main__,别的模块导入后,__name__ = 被导入的模块名
2.19 python有重写,没有重载
重写:父类方法不能满足子类的需求时,就可以在子类中重新定义一个同名的方法。
重载:首先python没有重载,重载是指方法名相同,方法的参数个数,顺序和类型不同,根据方法调用时传入的参数来决定具体调用哪个方法。(C++和Java中都有重载,而python没有)
3. 变量与数据类型、运算符和语句结构
3.1 变量与数据类型 type()、id()
变量
1)Python中的变量是不需要声明,每个变量在使用前都必须赋值,变量赋值后才会被创建;
2)在Python中,变量没有类型,所谓的类型是变量所指的内存中对象的类型。
3)python允许一次为多个变量赋值;
4)注意,python没有单独的字符类型,一个字符就是长度为1的字符串
内置type()函数可以用来查询变量所指的对象类型
内置的id()函数可以用来查询变量的内存空间地址
Python3中有六个标准数据类型
1)Number 数字
2)String 字符串
3)List 列表
4)Tuple 元组
5)Sets 集合
6)Dictionary 字典
eg:
整型变量,浮点型变量,字符串
counter = 100 # 整型变量
miles = 10000.0 # 浮点型变量
name = 'hyh' # 字符串(单引号或双引号引起来)
print(type(counter), type(miles), type(name))
print(id(counter), id(miles), id(name))

一次为多个变量赋值
# 格式一:a = b = c = 值
a = b = c = 1
# 格式二:a, b, c = 值1, 值2, 值3
d, e, f = 1, 1, 1

3.1.1 Number(数字)
Number
python3中支持int(长整类),float(浮点型),bool(布尔型),complex(复数型)
1)在python3中,只有一种整数类型int,表示长整型,没有python2中的long
2)+可用作数值运算,注意,字符型和数值型不能拼接使用
3)数值的除法/,总是返回一个浮点数,取整用//,取余用%。
功能:一次为多个变量赋值
格式一:
a = b = c = 值
格式二:
a, b, c = 值1, 值2, 值3
eg:
# 数值的除法`/`,总是返回一个浮点数
print(4 / 2)
# 取整
print(5 // 2)
# 取余
print(5 % 2)

3.1.2 String(字符串)
1)Python中的字符串用单引号' '或者双引号" "引起来,同时可以使用反斜杠\转义特殊字符;
2)我们也可以使用字符串截取(切片),对字符串进行处理,详见2.12节;
3)Python字符串有两种索引方式,从左至右以0开始,从右往左以-1开始;
4)Python中的字符串不能改变,如果改了变量的值,也不是指向同一个位置的字符串对象了,即可变对象修改后前后地址不变,而不可变对象修改之后,前后地址改变,比如列表就是可变对象。
5)+可用作字符串的连接符,*可复制当前字符串,紧跟的数字为复制的次数;
6)字符串前面加一个r或R表示让字符串原样输出,即里面的字符不转译;
7)eval() 函数用来执行一个字符串表达式,并返回表达式的值。
| 方法 | 含义 |
|---|---|
字符串.isdigit() | 判断字符串是否为纯数字 |
字符串.isupper() | 判断字符串是否为纯大写 |
字符串.islower() | 判断字符串是否为纯小写 |
字符串.isalpha() | 判断字符串是否为纯字母 |
字符串.isalnum() | 判断字符串是否为字母或数字 |
字符串.index(sub[, start[, end]]) | S.index(sub[, start[, end]]) -> int 返回s中找到sub字符串sub的最低索引,这样sub就包含在s中[start:end]。可选参数start和end被解释为切片表示法。 |
字符串.replace(old, new, count) | 字符串替换 |
字符串.join(iterable) | 把可迭代对象的元素连接到字符串的末尾 |
字符串.split(sep[, maxsplit]) | 在指定的分隔符处拆分字符串,并返回列表;sep:分隔符,maxsplit: 最多分多少次 |
| … | … |
| 转义字符 | 含义 |
|---|---|
\n | 回车 |
\r | 换行 |
\t | 制表符 |
\\ | 一个反斜杠 |
| … | … |
eg:
# 转义字符
print('Down by riverside\n', end="")
print('or\\and')
print('Down by riverside\r', end="")
print('you \t me')
# 字符串连接
str1 = 'Now I\'m'
str2 = 'traveling light'
print(str1 + str2)
# 字符串赋重复*4
print('hyh '*4)

# 字符串原样输出,字符不转义
print(r'Now I\'m') # 方式1
print(R'Now I\'m') # 方式2

# Python中的字符串不能改变,如果改了变量的值,也不是指向同一个位置的字符串对象了
str1 = 'My spirit lifted high'
print(id(str1))
str1 = str1 + '?'
print(id(str1))
# 更改了数组,就不会出现这种情况,数组是可变的
list1 = [1, 2, 3]
print(id(list1))
list1.append(4)
print(id(list1))

# 判断字符串是否为纯数字
print('hyh_4'.isdigit())
# 判断字符串是否为纯大写
print('RRR'.isupper())
# 判断字符串是否为纯小写
print('rrA'islower())
# 判断字符串是否为纯字母
print('nciew9'.isalpha())
判断字符串是否为字母或数字
print('nciew9'.isalnum())
# 返回字母'ay'第一次出现的位置的下标
str1 = 'everyday'
print(str1.index('ay'))
# 将字符串中的e全部替换成u
print(str1.replace('e','x'))
# 将字符串中的e替换成u,只替换一次
print(str1.replace('e','x', 1))
# 把可迭代的字符串对象连接到字符串的末尾
print(''.join(["1", '2', '4']))
# 把可迭代的字符串对象连接到字符串的末尾,以*间隔
print('*'.join(['2', '4', '0.5']))
# 以字母'a'分隔字符串
print("banana".split('a'))
# 以字母'a'分隔字符串,分隔2次
print("banana".split('a', 2))

# 执行一个字符串表达式,并返回表达式的值
a = '4*5 - 4 + (4 + 5)%2'
b = eval(a)
print(type(a), a, type(b), b) # <class 'str'> 4*5 - 4 + (4 + 5)%2 <class 'int'> 17

3.1.3 List(列表)
1)列表(List)是一种有序和可更改,允许重复的成员的集合;
2)列表是python中使用最频繁的数据类型;
3)列表可以完成大多数数据结构的实现,列表中的类型可以不相同,它支持数字,字符串,列表的嵌套;
4)列表同字符串一样可以被切片,可以索引
5)+可以作为列表的连接运算符,*可以作重复添加操作。
6)与python字符串不同的是列表中元素可以改变
| 方法 | 含义 |
|---|---|
len(列表) | 列表长度 |
append(Object) | 将对象添加到列表的末尾 |
insert(index, Object) | 要在指定的索引处添加对象 |
remove(Object) | 删除指定的对象 |
insert(index) | 要在指定的索引处删除对象 |
clear | 清空列表 |
index(Object, start, stop) | 返回具有指定对象的第一个元素的索引 |
count(object) | 返回具有指定对象的数量 |
sort(key, reverse) | 对列表进行排序,默认是升序排序 |
reverse() | 颠倒列表的顺序 |
| … | … |
eg:
# 定义一个列表
list1 = [23, 1.2, 45, 'ab', 45]
print(list1)
# 打印列表的长度
print(len(list1))
# 打印下标为3的对应的值
print(list1[3])
# 定义一个嵌套的列表
list2 = [23, 1.2, 'ab', [9, 'a', True, False], 45]
# 取list1列表里的下标为3的成员(列表)的下标为2的成员
print(list2[3][2]) # True

# 列表切片
list1 = [2, '3', 0, 'as', 4.5, True, [1, 3]]
print(list1[:]) # 跟字符串切片同理,左闭右开,当左右什么都不写,左边代表开始下标,右边是结束下标
print(list1[:2]) # [2, '3']
print(list1[2:]) # [0, 'as', 4.5, True, [1, 3]]
print(list1[1:-1]) # ['3', 0, 'as', 4.5, True]
# 步长设为2
print(list1[2:-2:2]) # [0, 4.5]

# 使用+运算符合并两个列表
list1 = [2, 'd', 'e', ['x'], 2.3]
list2 = [False, 4]
print(list1 + list2)
print(list2*4) # list2列表中成员重复4次
# 给第3个和第4个的成员赋值
list1[2:4] = [3, 1.4]
print(list1) # [2, 'd', 3, 1.4, 2.3]
# 删除第2个到第4个成员
list1[1:5] = [] # [2, 2.3]

# 向列表末尾添加一个对象
list1 = [2, True, 7.89, 's']
print(list1)
list1.append(False)
print(list1) # [2, True, 7.89, 's', False]
# 向下标0处添加一个对象
list1.insert(0, 'x')
print(list1) # ['x', 2, True, 7.89, 's', False]
# 删除指定的对象
list1.remove(False)
print(list1) # ['x', 2, True, 7.89, 's']
# 删除下标为3的对象
list1.pop(3)
print(list1) # ['x', 2, True, 's']
# 向下标1处添加一个对象
list1.insert(1, [1, False])
print(list1) # ['x', [1, False], 2, True, 's']

list1 = [2, True, 7.89, 's']
# 清空列表
list1.clear()
print(list1) # []
# 清空列表
list1 = [2, True, 7.89, 's']
list1 = []
print(list1) # []
# del关键字 删除指定索引处的对象
list1 = [2, True, 7.89, 's']
del list1[1]
print(list1) # [2, 7.89, 's']
# del 完整地删除列表 变量也删除了
del list1
print(list1) # None

list1 = [2, True, 7.89, 3.4, True, 2, 3, 2]
# 返回指定对象的第一个元素的索引
print(list1.index(True)) # 1
# 返回指定对象的数量
print(list1.count(2)) # 3
# 对列表进行排序,默认是升序排序
list1.sort()
print(list1) # [True, True, 2, 2, 2, 3, 3.4, 7.89]
# 对列表进行降序排序
list1.sort(reverse=True) # [7.89, 3.4, 3, 2, 2, 2, True, True]
print(list1)
# 颠倒列表的顺序
list1.reverse()
print(list1) # [True, True, 2, 2, 2, 3, 3.4, 7.89]

3.1.4 Tuple(元组)
1)元组是有序且不可更改,允许重复的成员的集合。在 Python 中,元组是用圆括号()编写的;
2)元组中的元素类型可以不相同;
3)元组支持索引,支持切片,步长;
4)+可以作为列表的连接运算符,*可以作重复添加操作;
5)元组虽然不可以修改(即修改元组元素的操作是非法的),但是它可以包含可变的对象,比如list列表;
| 方法 | 含义 |
|---|---|
count(x) | 返回元组中指定值出现的次数 |
index(x, start, end) | 在元组中搜索指定的值并返回它被找到的位置 |
eg:
# 定义元组
tuple1 = (1, 'a', False, ('d', 2))
print(type(tuple1)) # <class 'tuple'>
# 支持索引,输出下标为3的元素
print(tuple1[3]) # ('d', 2)
# 支持索引,输出下标为3的元素的下标为1的元素
print(tuple1[3][1]) # 2

tuple1 = (1, 'a', False, ('d', 2))
# 元组也可以切片,跟字符串,列表的切片原理相同,这里不再赘述
print(tuple1[:]) # (1, 'a', False, ('d', 2))
print(tuple1[2:4]) # (False, ('d', 2))
print(tuple1[:-2]) # (1, 'a')
# 设置步长2
print(tuple1[::2]) # (1, False)
# 连接两个元组
tuple2 = ((True, 'hyh', 'a'), 4.5)
print(tuple1 + tuple2) # (1, 'a', False, ('d', 2), (True, 'hyh', 'a'), 4.5)
# 元组重复*3
print(tuple2*3) # ((True, 'hyh', 'a'), 4.5, (True, 'hyh', 'a'), 4.5, (True, 'hyh', 'a'), 4.5)

tuple1 = (1, 'a', False, ('d', 2), ('d', 2))
# 返回元组中指定值出现的次数
print(tuple1.count(('d', 2))) # 2
# 在元组中搜索指定的值并返回它被找到的位置
print(tuple1.index(('d', 2), 3, 4)) # 4
# 注意下面这种情况
tuple2 = (1, [2, 4.5])
tuple2[1][1] = 3
print(tuple2) # (1, [2, 3]) 这种情况是可以修改的,因为修改的是List列表

3.1.5 Set(集合)
1)是一个无序和无索引,没有重复的成员的集合;
2)基本的功能是进行成员关系的测试和删除重复的元素;
3)可以使用大括号{}或者set()函数创建集合;
4)由于是无序集合,所以不支持索引和切片;
5)集合中元素的数据类型可以不同,但集合中不能嵌套列表、元组、集合、字典
6)并集|,差集-,交集&,A∪B - (A∩B)即取不同时在两边出现的元素^
| 方法 | 含义 |
|---|---|
clear() | 删除集合中的所有元素 |
remove(element) | 删除指定元素 |
pop() | 从集合中删除第一个元素(相当于队列形式) |
add(element) | 向集合添加元素(末尾添加,相当于队列形式) |
update(s) | 用此集合和其他集合的并集来更新集合,s:集合 |
copy() | 返回集合的副本 |
| … | … |
eg:
# 定义集合,注意集合的定义和字典的定义要区别开来
set1 = set() # 定义一个空集合
print(type(set1)) # <class 'set'>
set2 = {1, 2, 4.5, True, False, 1} # 定义一个非空集合
print(set2) # 自动去重的同时升序排列 {False, 1, 2, 4.5}

set1 = set('bdbbcdnnb') # 这里其实是一种强制类型转化,即字符串转换成集合
set2 = set('yytetennb') # 这里其实是一种强制类型转化,即字符串转换成集合
# 求并集
print(set1 | set2)
# 求差集
print(set1 - set2)
# 求交集
print(set1 & set2)
# 求不同时在两边出现的元素
print(set1 ^ set2)

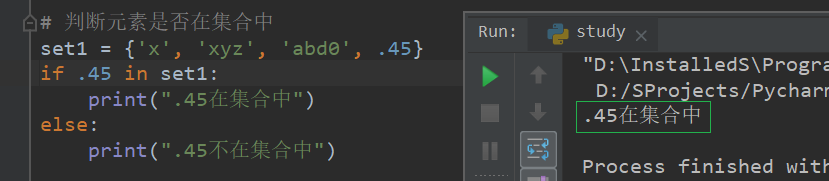
# 判断元素是否在集合中
set1 = {'x', 'xyz', 'abd0', .45}
if .45 in set1:
print(".45在集合中")
else:
print(".45不在集合中")
set1 = {3, False, 4.5, .7, 'as'}
# 清空集合所有元素
set1.clear()
print(set1) # set()
set1 = {3, False, 4.5, .7, 'as'}
# 删除指定元素
set1.remove(3)
print(set1) # {False, 0.7, 'as', 4.5}
# 从集合中删除第一个元素(相当于队列形式)
set1.pop()
print(set1) # {0.7, 'as', 4.5}
# 向集合添加元素(末尾添加,相当于队列形式)
set1.add(True)
print(set1) # {0.7, True, 'as', 4.5}
# 用此集合和其他集合的并集来更新集合
set1.update({2, 4, 'a', .56})
print(set1) # {0.7, True, 'as', 0.56, 4.5, 2, 4, 'a'}
# 返回集合的副本
print(id(set1.copy())) # 1937296682568
print(id(set1)) # 1937297278568

3.1.6 Dictionary(字典)
1)是一个无序,可变和有索引,没有重复的成员的集合;
2)字典是一种映射类型,字典用{}标识,它是一个无需的键(key): 值(value)对集合;
3)键必须使用不可变类型,键唯一;
4)创建空字典使用{}。
| 方法 | 含义 |
|---|---|
keys() | 返回包含字典键的列表 |
values() | 返回字典中所有值的列表 |
key(k) | 返回指定键对应的值,k:键 |
pop(k) | 删除拥有指定键的元素 |
clear() | 删除字典中的所有元素(清空所有的键值对) |
eg:
# 定义一个空字典
dict1 = {}
print(dict1) # {}
print(type(dict1)) # <class 'dict'>
# 定义一个非空字典
dict2 = {'name': 'hyh', 'age': 16, 'tel': 'xxxxxxxxxxx'}
print(dict2) # {'name': 'hyh', 'age': 16, 'tel': 'xxxxxxxxxxx'}
# 可变
dict2['name'] = 'tom'
dict2['age'] = 78
print(dict2) # {'name': 'tom', 'age': 78, 'tel': 'xxxxxxxxxxx'}
# 有索引,字典通过键名来访问键名对应的值,由于字典无序所以不支持下标的形式
print(dict2['age']) # 78

dict1 = {'name': 'hyh', 'age': 16, 'tel': 'xxxxxxxxxxx'}
# 获取所有的键名
print(dict1.keys()) # dict_keys(['name', 'age', 'tel'])
# 返回字典中所有值的列表
print(dict1.values()) # dict_values(['hyh', 16, 'xxxxxxxxxxx'])
# 返回指定键对应的值
print(dict1.get('tel')) # xxxxxxxxxxx
# 删除拥有指定键的元素
print(dict1.pop('tel')) # xxxxxxxxxxx
# 删除字典中的所有元素(清空所有的键值对)
dict1.clear()
print(dict1) # {}

3.2 数据类型转换
当我们需要对数据的内置类型进行转换(数据类型的转换),你只需要将数据类型作为函数名即可。
下面几个内置函数可以执行数据类型之间的转换,这些函数返回一个新的对象,表示转换的值。
| 函数 | 描述 |
|---|---|
int(x[,base]) | 将x转换成一个整数 |
float(x) | 将x转换成一个浮点数 |
complex(real[,imag]) | 创建一个复数 |
str(x) | 将对象x转换成字符串 |
repr(x) | 将对象x转换成表达式字符串 |
eval(str) | 计算在字符串中有效的python表达式,并返回一个对象 |
tuple(s) | 将序列s转换成一个元组 |
list(s) | 将序列s转换成一个列表 |
set(s) | 转换成可变集合 |
dict(d) | 创建一个字典,d必须是一个序列 (key,value)元组 |
frozenset(s) | 转换成不可变集合 |
chr(x) | 将一个整数转换为一个字符 |
unichr(x) | 将一个整数转换为Unicode字符 |
ord(x) | 将一个字符转换为它的整数值 |
oct(x) | 将一个整数转换成一个八进制字符串 |
hex(x) | 将一个整数转换成十六进制字符串 |
3.2.1 数值型之间转换 float()、int()、bool()、complex()
1)整型(int)转换为浮点型(float);
2)浮点型(float)转换为整型(int),仅保留整数部分,不四舍五入。
3)整型和浮点型如果不等于0,那么转换成布尔型就是True,否则就是False;
等…
eg:
# 这里只列举了整型和浮点型之间的转换,其他数值型同理
# 整型(int)转换为浮点型(float)
a = 5
print(type(a), a, '转换成', type(float(a)), float(a)) # <class 'int'> 5 转换成 <class 'float'> 5.0
# 浮点型(float)转换为整型(int)
b = 6.78
print(type(b), b, '转换成', type(int(b)), int(b)) # <class 'float'> 6.78 转换成 <class 'int'> 6

3.2.2 数值型和字符串之间转换
1)数值型转换为字符串
2)字符串转换为数值型
eg:
# 数值型转换为字符串
a = .5
b = 4
c = True
d = 1-2j
print(type(a), a, '转换成', type(str(a)), str(a)) # <class 'float'> 0.5 转换成 <class 'str'> 0.5
print(type(b), b, '转换成', type(str(b)), str(b)) # <class 'int'> 4 转换成 <class 'str'> 4
print(type(c), c, '转换成', type(str(c)), str(c)) # <class 'bool'> True 转换成 <class 'str'> True
print(type(d), d, '转换成', type(str(d)), str(d)) # <class 'complex'> (1-2j) 转换成 <class 'str'> (1-2j)
# 字符串转数值型
# 注意!字符串要想转换成数值型,字符串里必须都是数字,不能有字母或其他符号
# 注意小数不能转换成整型,会报错
e = '789'
print(type(e), e, '转换成', type(int(e)), int(e)) # <class 'str'> 789 转换成 <class 'int'> 789
print(type(e), e, '转换成', type(float(e)), float(e)) # <class 'str'> 789 转换成 <class 'float'> 789.0
print(type(e), e, '转换成', type(bool(e)), bool(e)) # <class 'str'> 789 转换成 <class 'bool'> True
print(type(e), e, '转换成', type(complex(e)), complex(e)) # <class 'str'> 789 转换成 <class 'complex'> (789+0j)

3.2.3 其他
eg:
# 字符串转换成列表
a = 'hyh 12-26'
b = list(a) # 字符串的每个字符都是列表的一个成员
print(type(a), a, type(b), b) # <class 'str'> hyh 12-26 <class 'list'> ['h', 'y', 'h', ' ', '1', '2', '-', '2', '6']
# 字符串转换成元组
c = 'hyh 12-26'
d = tuple(c) # 字符串的每个字符都是元组的一个成员
print(type(c), c, type(d), d) # <class 'str'> hyh 12-26 <class 'tuple'> ('h', 'y', 'h', ' ', '1', '2', '-', '2', '6')
# 字符串转换成集合
e = 'hyh 12-26'
f = set(e) # 字符串的每个字符,自动去重后,每个字符都是集合的一个成员
print(type(e), e, type(f), f) # <class 'str'> hyh 12-26 <class 'set'> {'h', 'y', ' ', '1', '-', '2', '6'}
# 进制转换
g = 64
h = bin(g) # 二进制
print(h) # 0b1000000
i = oct(g) # 八进制
print(i) # 0o100
j = hex(g) # 十六进制
print(j) # 0x40

3.3 运算符
1)算术运算符
2)赋值运算符
3)比较运算符(关系运算符)
4)逻辑运算符
5)身份运算符
6)成员运算符
7)位运算符
3.3.1 算术运算符
算术运算符与数值一起使用来执行常见的数学运算。
| 算数运算符 | 名称 |
|---|---|
+ | 加 |
- | 减 |
* | 乘 |
/ | 除 |
% | 取模 |
** | 幂 |
// | 地板除(取整除) |
eg:
a = 4
b = 6
x = 3
# 除
print(b / a) # 1.5
# 取模
print(b % a) # 2
# 幂
print(a ** x) # 64
# 还有一种内置的方法也可以做幂运算
print(pow(a, x)) # 64
# 取整除
print(b // a) # 1

3.3.2 赋值运算符
赋值运算符用于为变量赋值。
| 赋值运算符 | 名称 |
|---|---|
= | 等于 |
+= | _ |
-= | _ |
*= | _ |
/= | _ |
%= | _ |
//= | _ |
**= | _ |
&= | 二进制计算_ |
|= | 二进制计算_ |
^= | 二进制计算_ |
>>= | 二进制计算_ |
<<= | 二进制计算_ |
eg:
a, b, c, d, e, f = 10, 4.5, 2, 1, 20, 3
a += b # 等价于 a = a + b, 其他的同理
print('a =', a) # a = 14.5
a -= b # 等价于 a = a - b
print('a =', a) # a = 10.0
a *= b # 等价于 a = a * b
print('a =', a) # a = 45.0
a /= b # 等价于 a = a / b
print('a =', a) # a = 10.0
a %= b # 等价于 a = a % b
print('a =', a) # a = 1.0
a //= b # 等价于 a = a // b
print('a =', a) # a = 0.0
b **= a # 等价于 b = b ** a
print('b =', b) # b = 1.0
c &= d # 等价于 c = c & d 0000 0010 & 0000 0001 = 0000 0000
print('c =', c) # c = 0
c |= d # 等价于 c = c | d 0000 0000 | 0000 0001 = 0000 0001
print('c =', c) # c = 1
e ^= f # 等价于 e = e ^ f 0001 0100 ^ 0000 0011 = 0001 0111
print('e =', e) # e = 23
e >>= f # 等价于 e = e >> f 0001 0111 >> 3 = 0000 0010
print('e =', e) # e = 2
e <<= f # 等价于 e = e << f 0000 0010 << 3 = 0001 0000
print('e =', e) # e = 16

3.3.3 比较运算符
比较运算符用于比较两个值。
| 比较运算符 | 名称 |
|---|---|
== | 等于 |
!= | 不等于 |
> | 大于 |
< | 小于 |
>= | 大于等于 |
<= | 小于等于 |
eg:
a, b = 3, 4.5
print(a == b) # False
print(a != b) # True
print(a < b) # True
print(a > b) # False
print(a <= b) # True
print(a >= b) # False

3.3.4 逻辑运算符
逻辑运算符用于组合条件语句。
| 逻辑运算符 | 名称 |
|---|---|
and | 与,如果两个语句都为真,则返回 True |
or | 或,如果其中一个语句为真,则返回 True |
not | 非 ,反转结果,如果结果为 true,则返回 False |
eg:
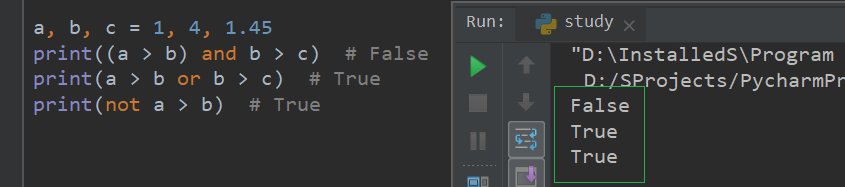
a, b, c = 1, 4, 1.45
print(a > b and b > c) # False
print(a > b or b > c) # True
print(not a > b) # True
3.3.5 身份运算符
身份运算符用于比较对象,不是比较它们是否相等,但如果它们实际上是同一个对象,就具有相同的内存位置。
| 身份运算符 | 名称 |
|---|---|
is | 如果两个变量是同一个对象,则返回 true |
is not | 如果两个变量不是同一个对象,则返回 true |
eg:
a, b = 3, 3
print(id(a), id(b)) # 140719180526480 1862767588024
# is
print(id(a) is id(b)) # False
# is not
print(id(a) is not id(b)) # True

eg:
3.3.6 成员运算符
成员资格运算符用于测试序列是否在对象中出现。
| 身份运算符 | 名称 |
|---|---|
in | 如果对象(序列)中存在具有指定值,则返回 True |
not in | 如果对象(序列)中不存在具有指定值,则返回 True |
eg:
# in
list1 = ['3', 'ab', '456', True, 'ab', 0]
if 'ab' in list1:
print("yes") # yes
else:
print("no")
# not in
list1 = ['3', 'ab', '456', True, 'ab', 0]
if 'ab' not in list1:
print("yes ")
else:
print("no ") # no

3.3.7 位运算符
位运算符用于比较(二进制)数字。
| 比较运算符 | 描述 |
|---|---|
& | 二进制计算 AND 按位与 如果两个位均为 1,则将每个位设为 1 |
| | 二进制计算 OR 按位或 如果两位中的一位为 1,则将每个位设为 1 |
^ | 二进制计算 XOR 异或 如果两个位中只有一位为 1,则将每个位设为 1 |
~ | 二进制计算 NOT 反转所有位 |
<< | 二进制计算 Zero fill left shift 通过从右侧推入零来向左移动,推掉最左边的位 |
>> | 二进制计算 Signed right shift 通过从左侧推入最左边的位的副本向右移动,推掉最右边的位 |
a, b = 5, 2 # bin(a) = 0101 bin(b) = 0010
print(a & b) # 0000 0 按位与 对应位置两个数都为1,结果为1,否则0
print(a | b) # 0111 7 按位或 对应位置两个数至少有一个为1,结果为1,否则0
print(a ^ b) # 0111 7 异或 对应位置两者相异为1,否则0
print(~ a) # 11111010 -6 按位取反 对数据的每个二进制位取反,有符号二进制的补码形式
print(a << 2) # 00010100 20 左移 将二进制左边前二位去掉,右边补两个0
print(a >> 2) # 00000001 1 右移 将二进制右边二位去掉,左边补两个0
# 这里解释一下a按位取反后-6是怎么得到的
# 首先bin(a) = 0000 0101
# 按位取反后 1111 1010 这个数就是最后的结果
# 接下来
# 我们计算 1111 1010的原码
# 1111 1010是补码的形式,所以反码:1111 1010 - 1 = 1111 1001
# 反码:1111 1001 ——按位取反——> 原码:0000 0110 换算成十进制为 6
# 所以 1111 1010 就是 -6

3.4 运算符的优先级
Python运算符的优先级
| 运算符(优先级由高到底) | 描述 |
|---|---|
** | 指数(最高优先级) |
~ + - | 按位翻转,一元加号(正),一元减号(负) |
* / % // | 乘,除,取模,整除 |
+ = | 加法,减法 |
>> << | 右移,左移 |
& | 按位与 (位运算符) |
^ | | 异或(位运算符),按位或(位运算符) |
<= < > >= | 小于等于, 小于,大于,大于等于 都是比较运算符 |
== != | 等于,不等于 都是比较运算符 |
= %= /= //= -= += *= **= | 赋值运算符 |
is is not | 身份运算符 |
in not in | 成员运算符 |
not or and | 逻辑运算符 |
eg:
a = (1 + 2 ** 3 / 4) == 5
print(a) # False

3.5 语句结构
1)顺序结构:从上到下,从左到右,遇到有缩进的方法或类方法直接跳过。
2)分支结构(选择结构),可嵌套
3)循环结构,可嵌套
3.4.1 条件控制 if...else、if...elif...else、if嵌套
1)python没有像其他大多数语言一样使用大括号{}表示语句体,而是通过语句缩进来判断语句体,缩进默认4个空格;
2)条件语句写完后用冒号:,表示接下来是满足条件后要执行的语句块;
3)在python中没有switch-case语句
if…else
格式:
if 条件语句:
执行语句
else:
执行语句
eg:
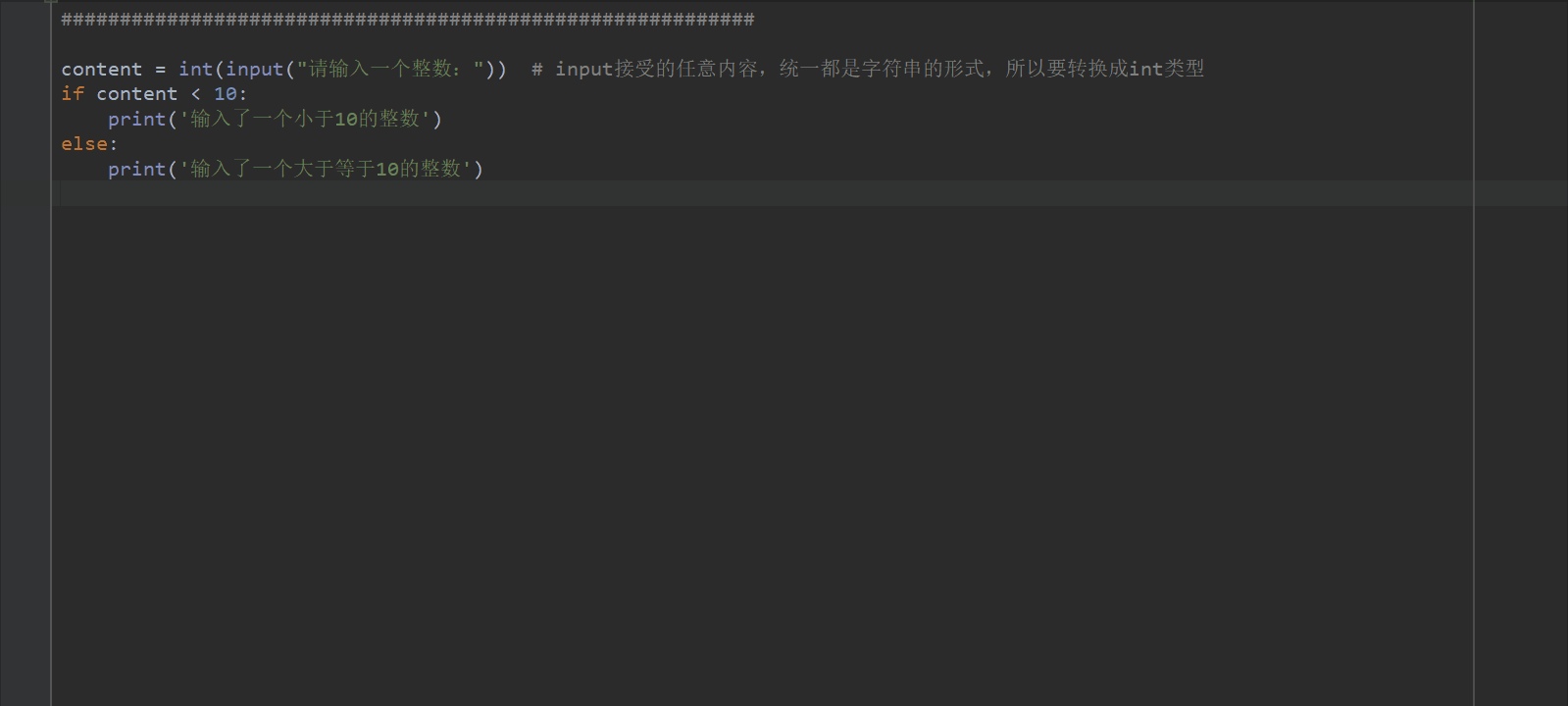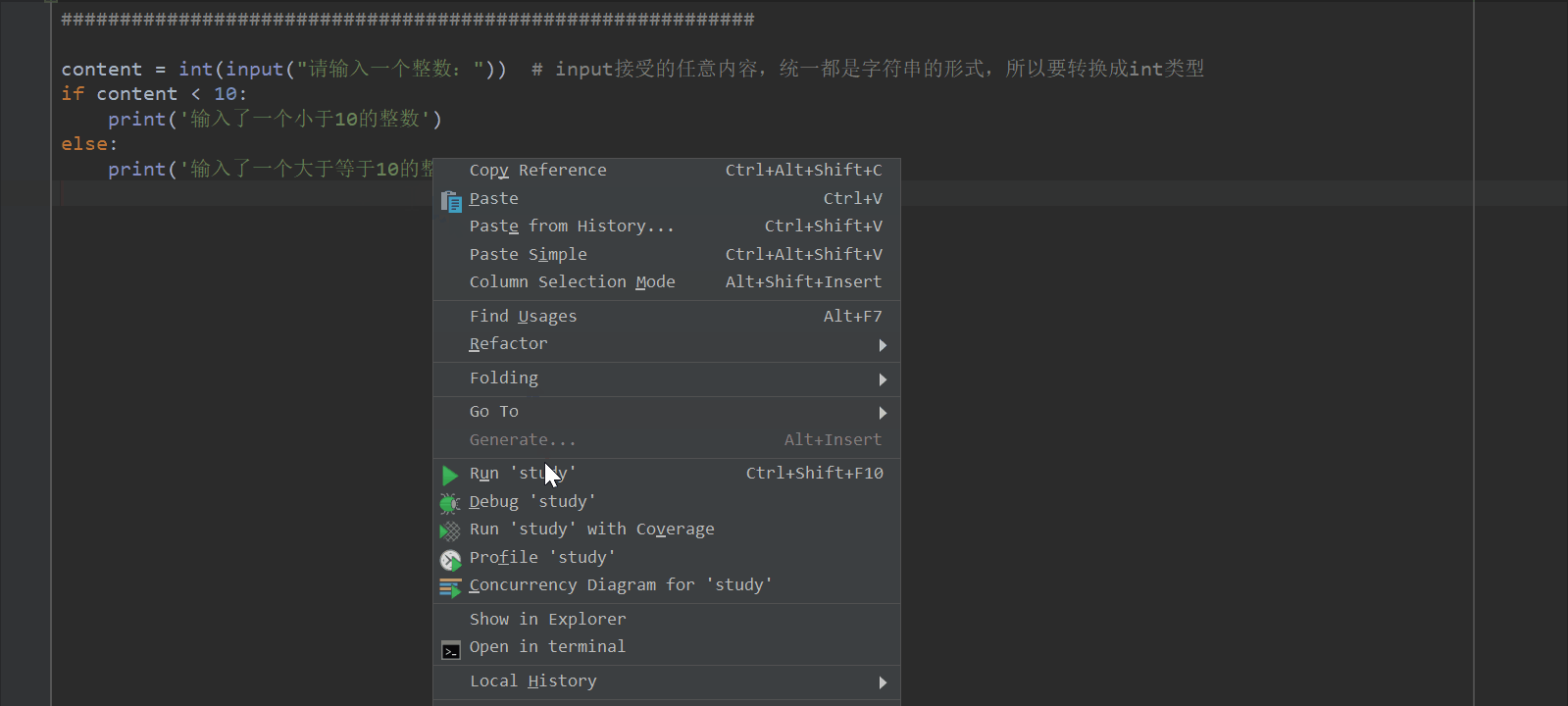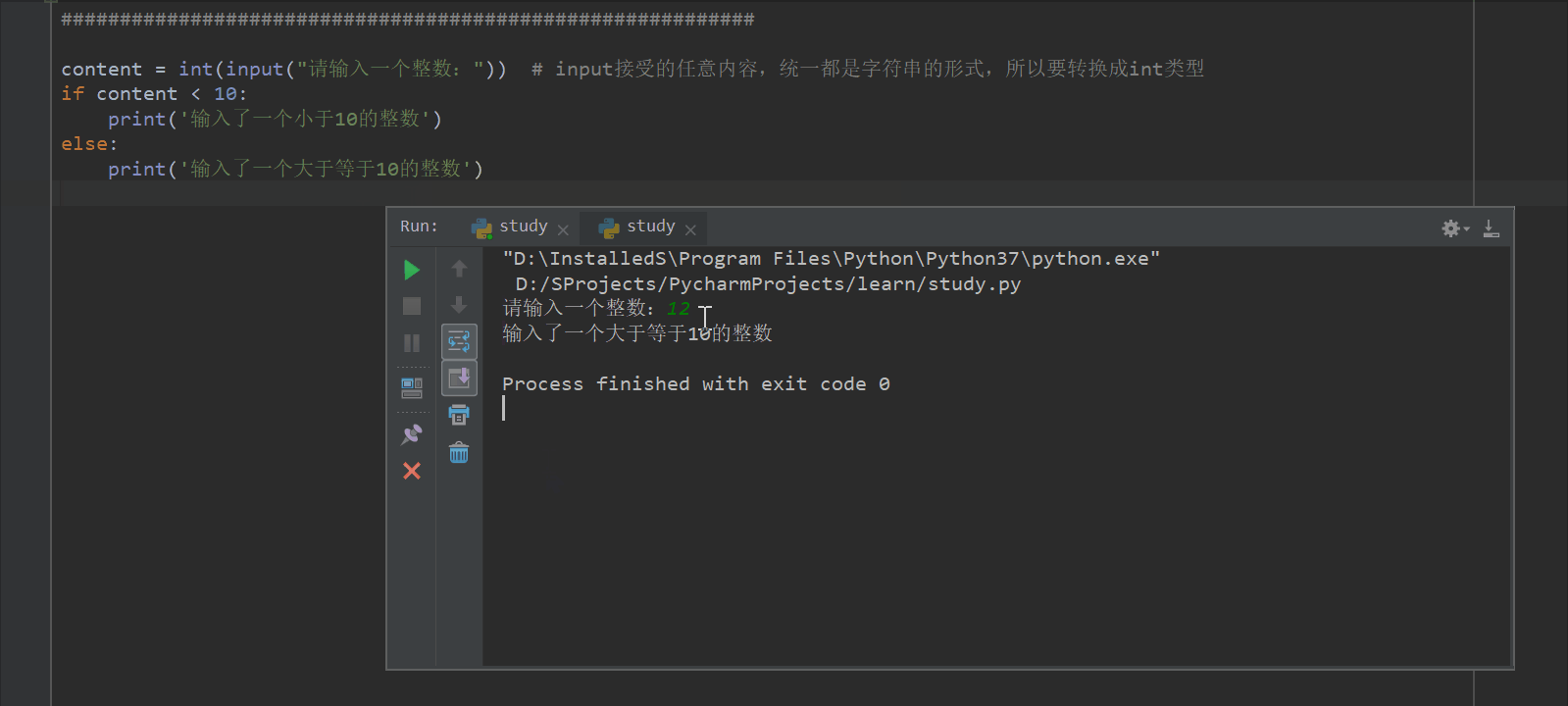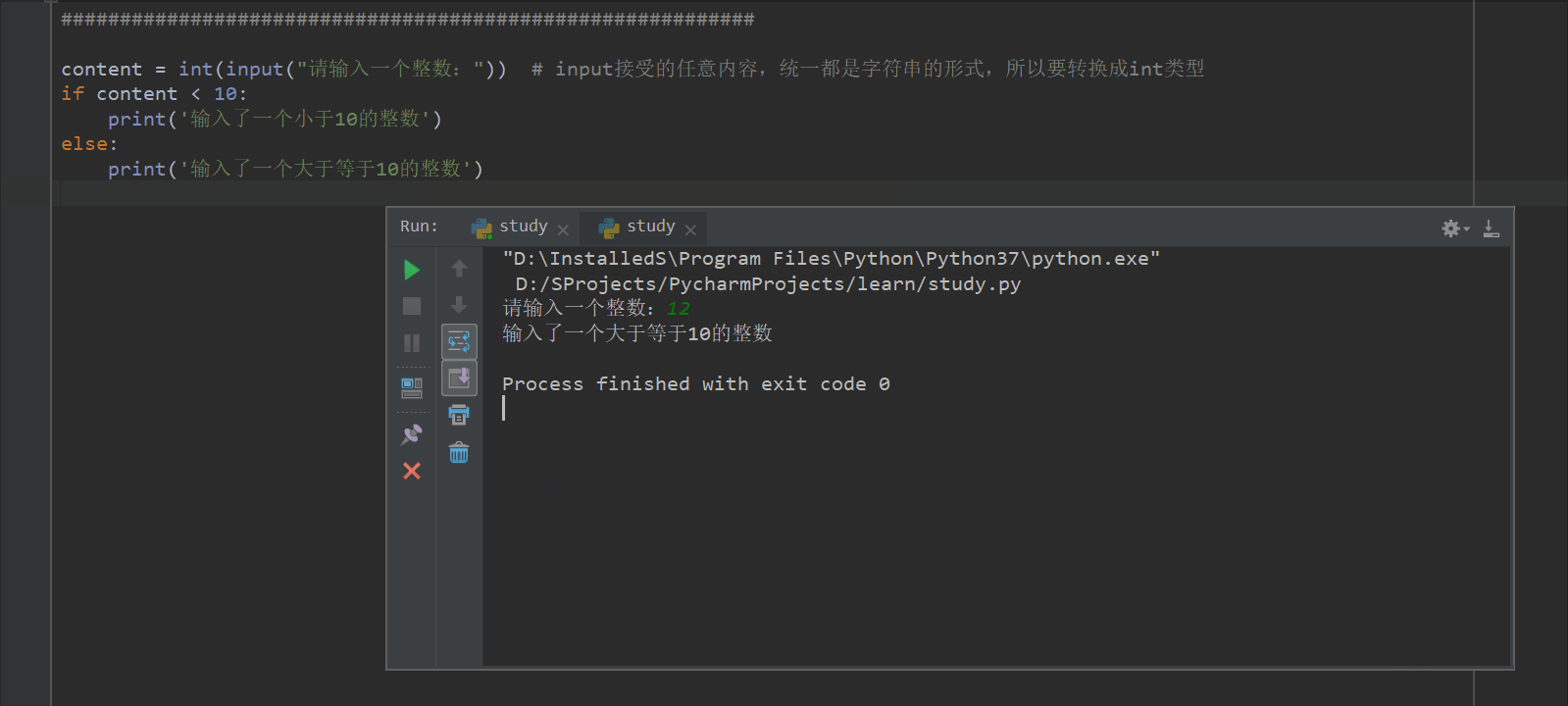
content = input("请输入一个整数:") # input接受的任意内容,统一都是字符串的形式
if content < 10:
print('输入了一个小于10的整数')
else:
print('输入了一个大于等于10的整数')
if…elif…else
格式:
if 条件语句:
执行语句
elif 条件语句:
执行语句
...
elif 条件语句:
执行语句
else:
执行语句
eg:
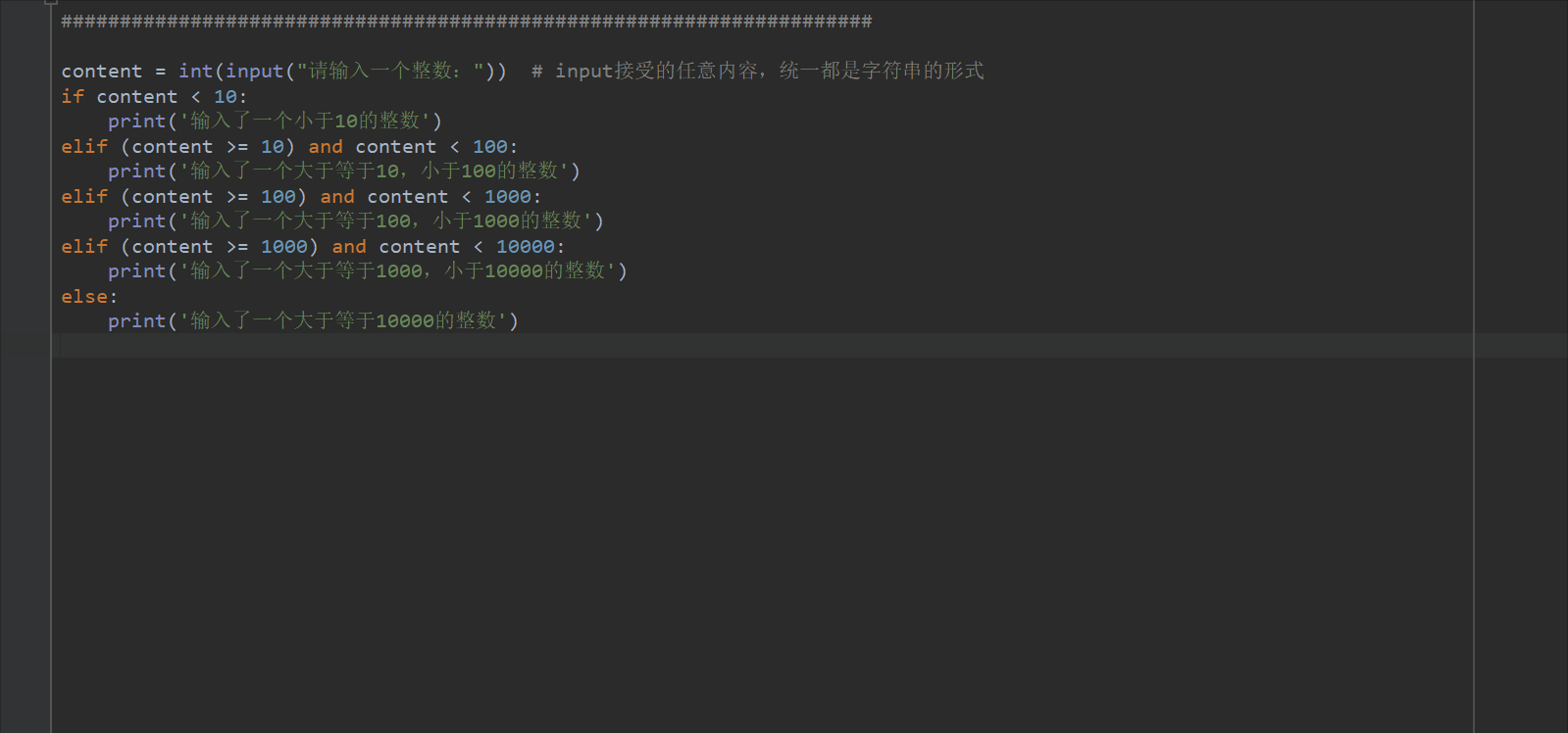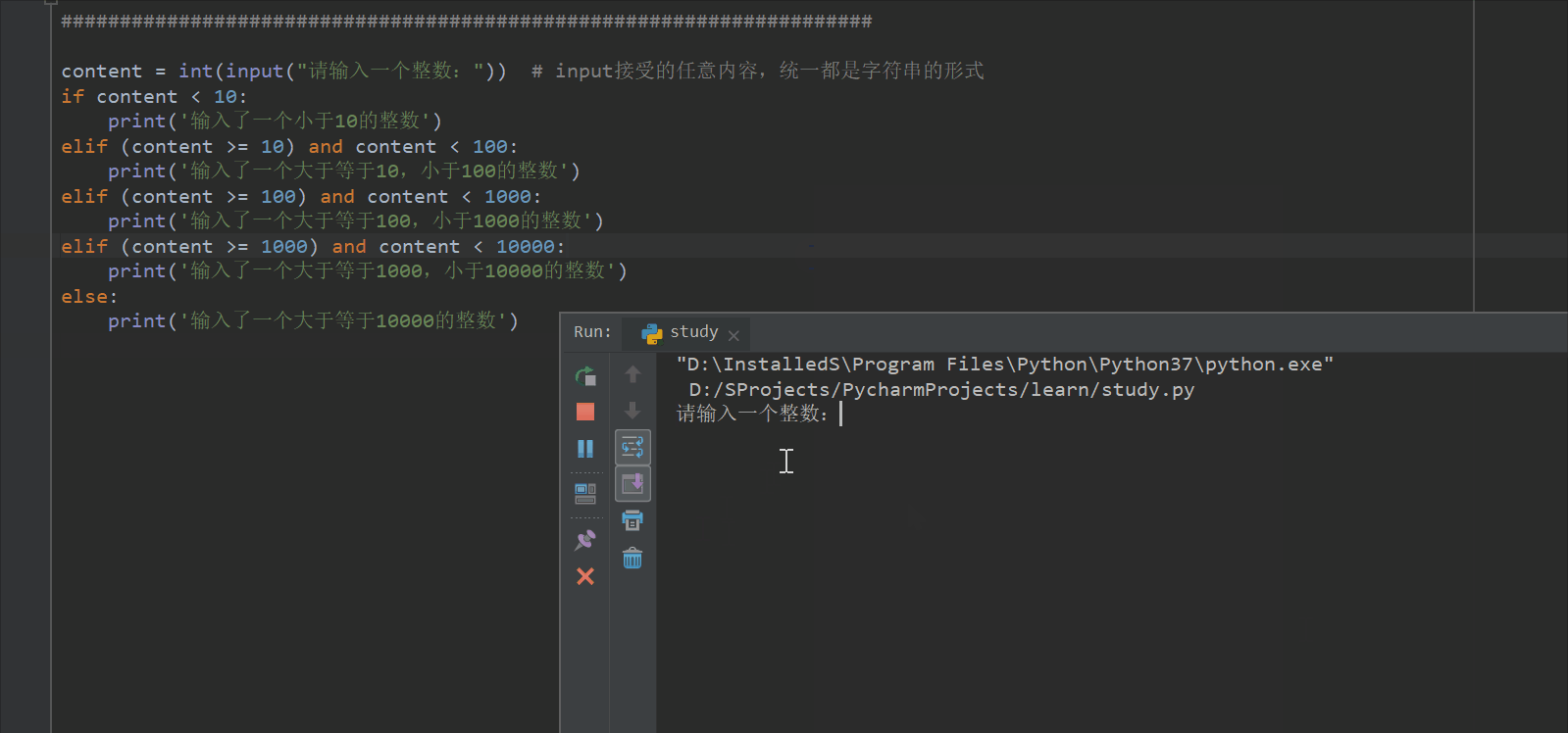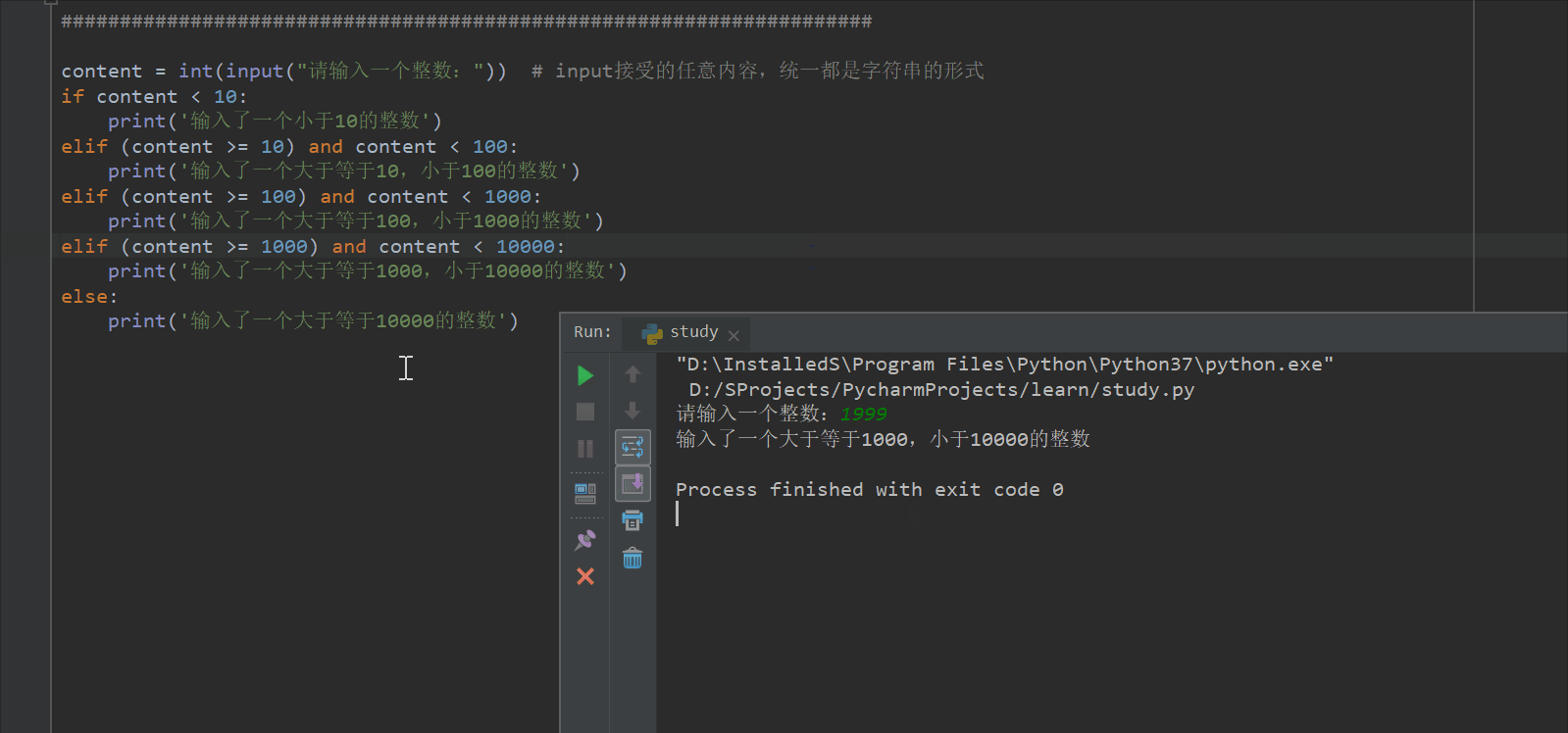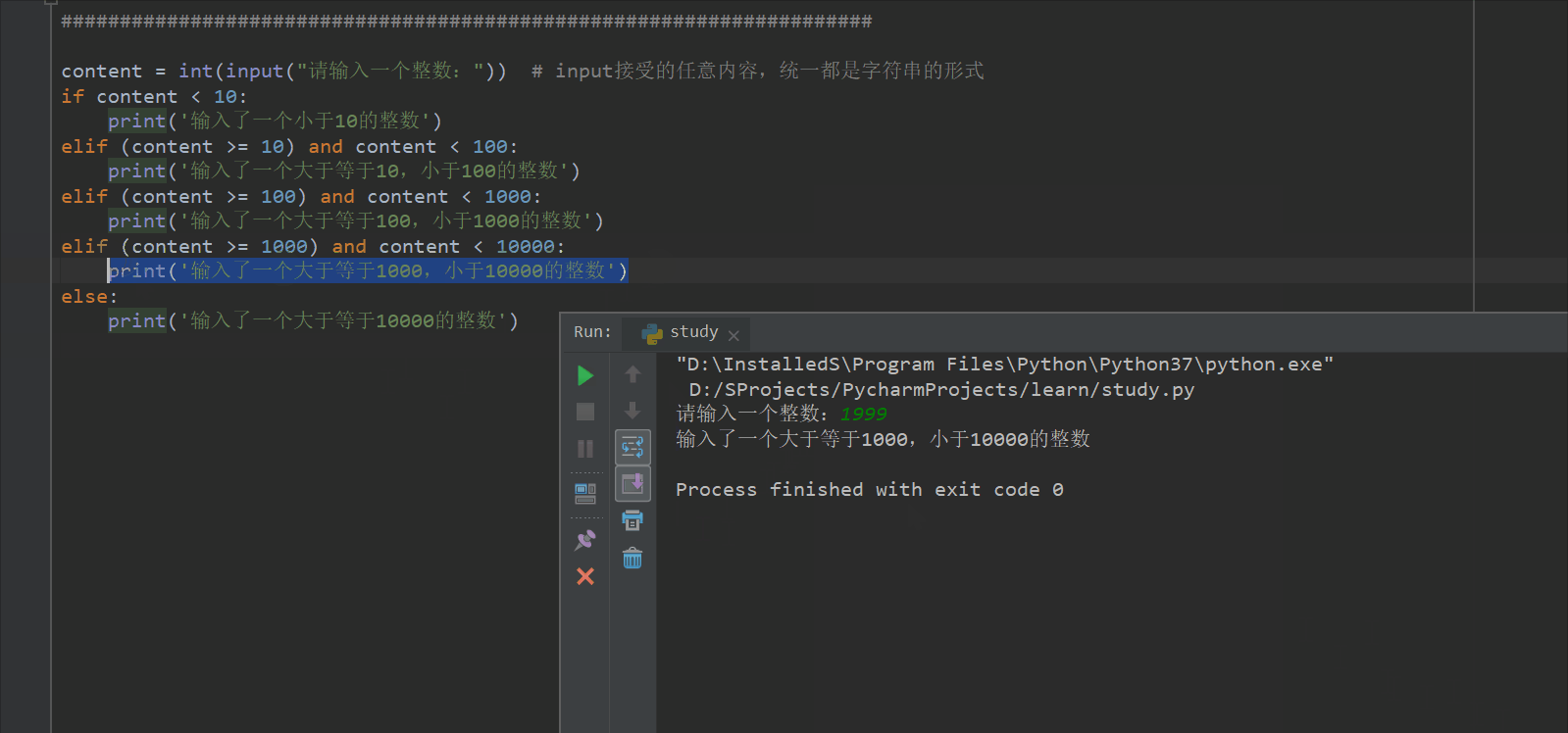
content = int(input("请输入一个整数:")) # input接受的任意内容,统一都是字符串的形式
if content < 10:
print('输入了一个小于10的整数')
elif (content >= 10) and content < 100:
print('输入了一个大于等于10,小于100的整数')
elif (content >= 100) and content < 1000:
print('输入了一个大于等于100,小于1000的整数')
elif (content >= 1000) and content < 10000:
print('输入了一个大于等于1000,小于10000的整数')
else:
print('输入了一个大于等于10000的整数')
if嵌套
eg:
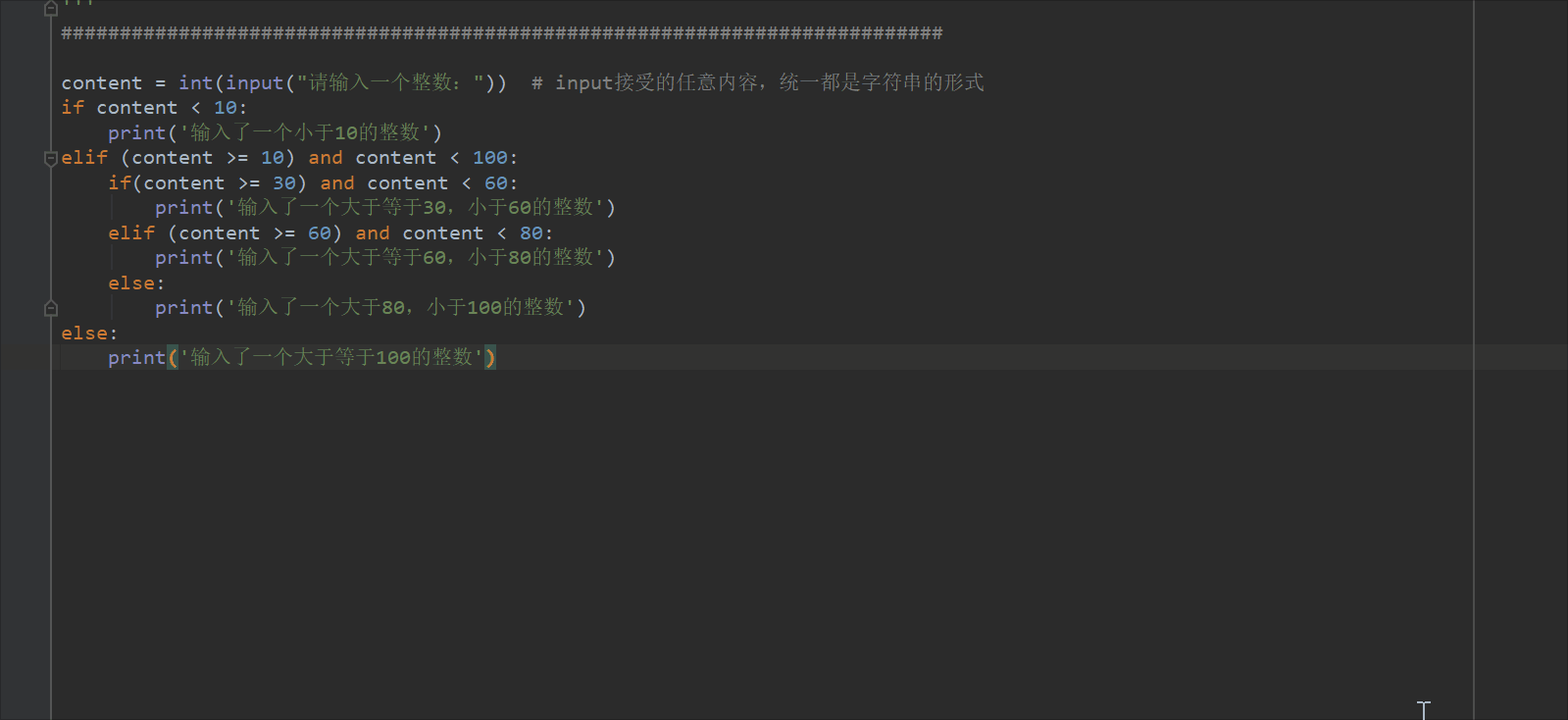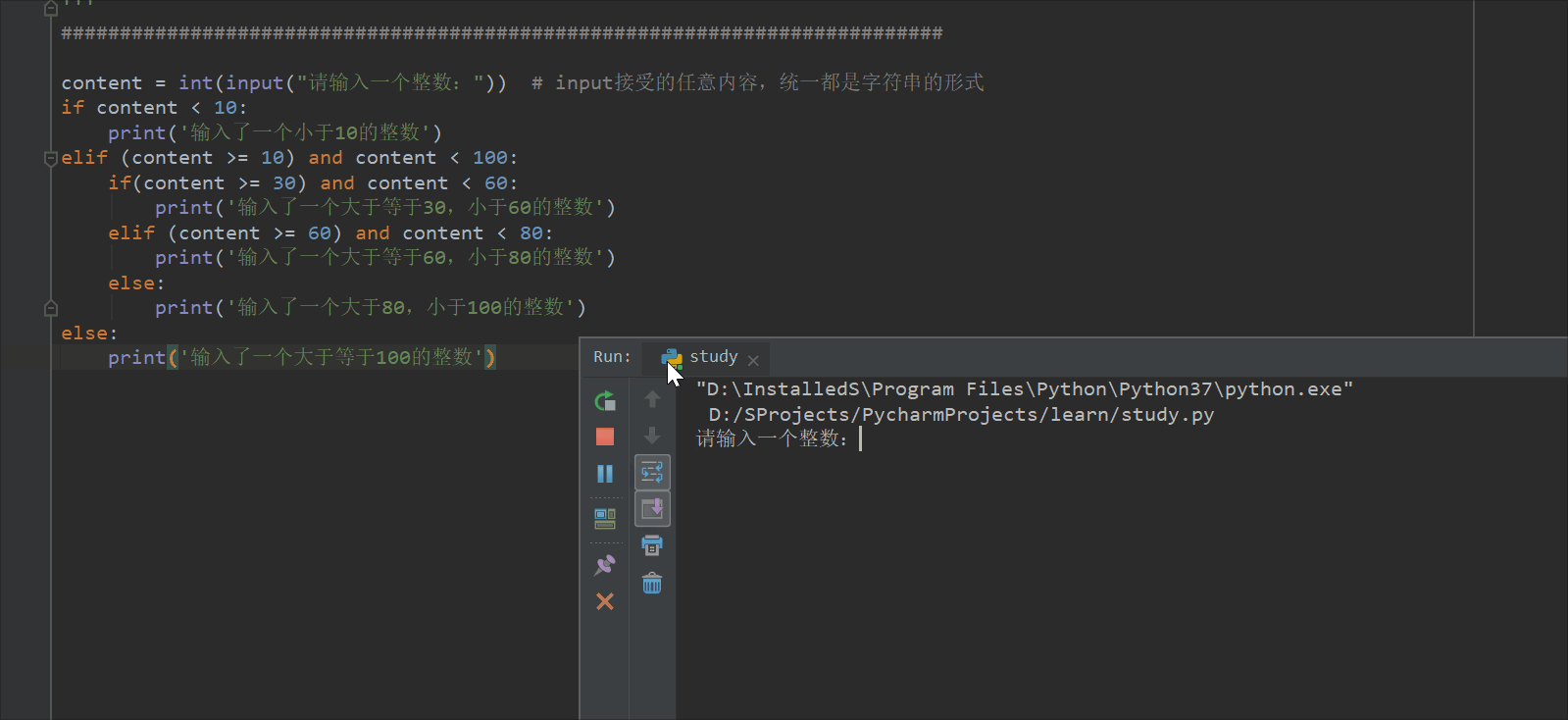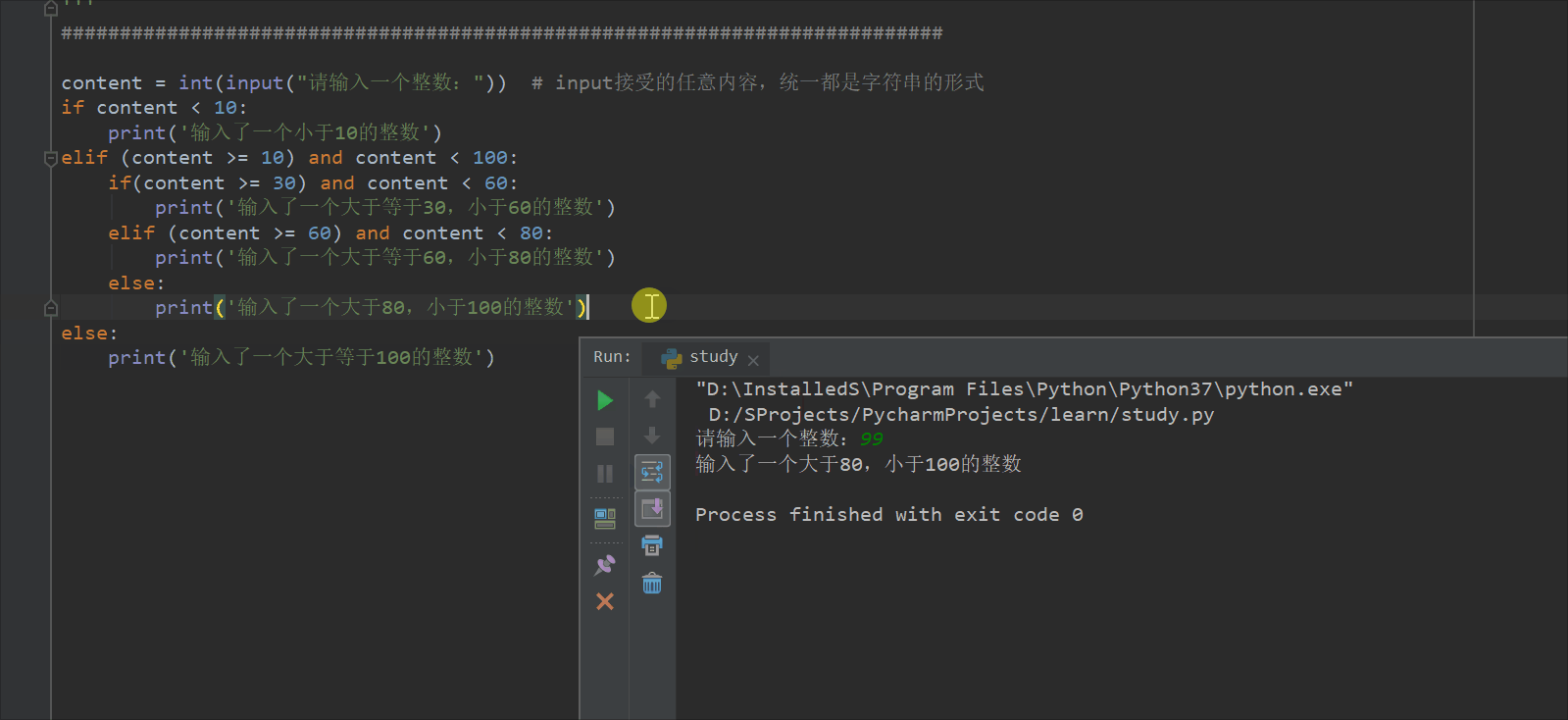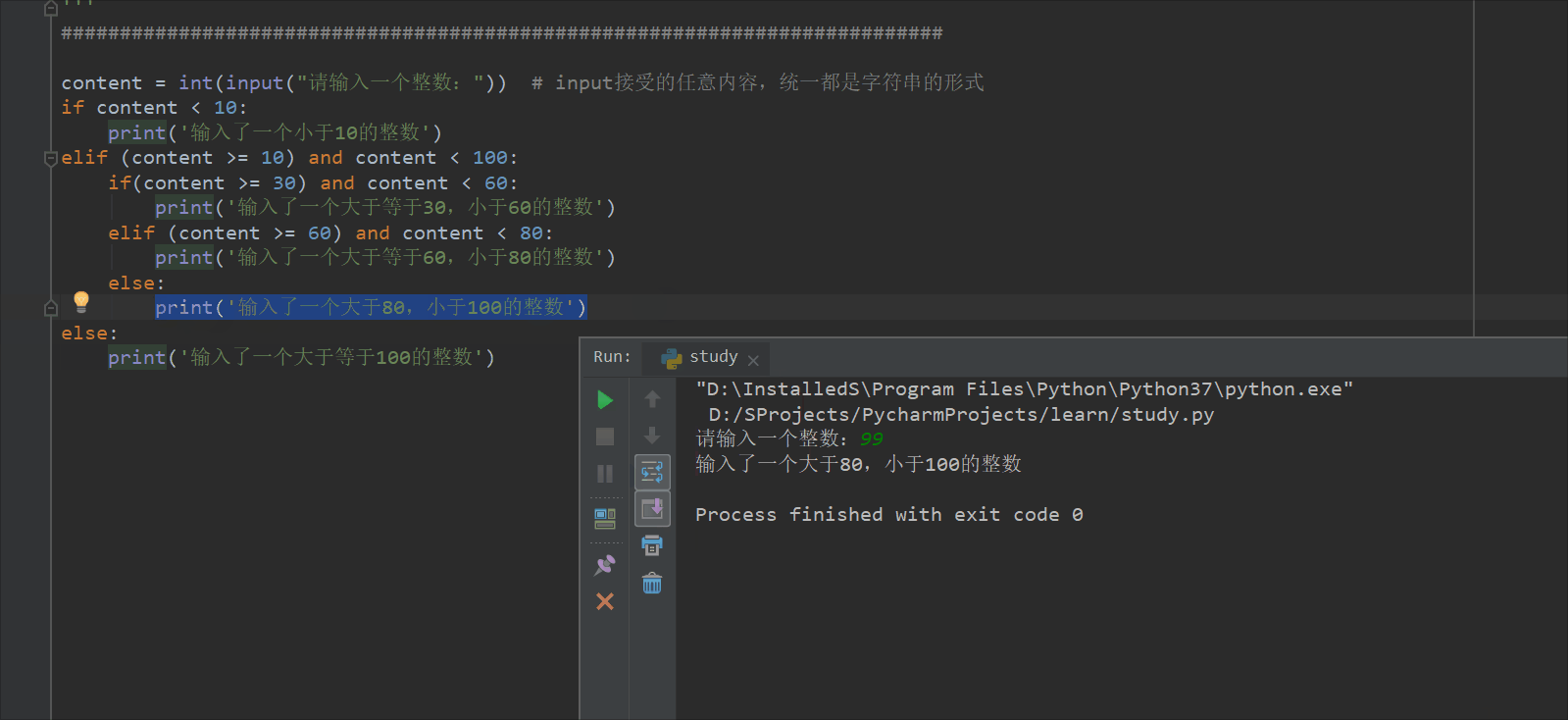
content = int(input("请输入一个整数:")) # input接受的任意内容,统一都是字符串的形式
if content < 10:
print('输入了一个小于10的整数')
elif (content >= 10) and content < 100:
if(content >= 30) and content < 60:
print('输入了一个大于等于30,小于60的整数')
elif (content >= 60) and content < 80:
print('输入了一个大于等于60,小于80的整数')
else:
print('输入了一个大于80,小于100的整数')
else:
print('输入了一个大于等于100的整数')
3.4.2 循环语句 while循环、for循环
1)python中没有do...while循环
2)知道循环次数最好用for循环,不知道循环次数的最好用while循环
3)循环里也可以使用分支语句(if…else等)
4)for循环可以遍历任何序列的项目,如一个列表或者一个字符串。
while循环
eg:
# 求1-5所有整数的和
i, total = 1, 0
while i <= 5:
print('i = %d' % i)
total += i
i += 1
print(total) # 15

for循环
eg:
# 求1~100的所有整数和
total = 0
for i in range(1, 101): # 左闭右开
total += i
print(total) # 5050
# 求1~50每隔5个数字就加和的结果
total2 = 0
for i in range(1, 50, 5): # 左闭右开
print('total2 = total2 + i = %d' % total2 + ' + %d' % i)
total2 += i
print(total2) # 235
# 求1~10所有奇数加和的结果
total3 = 0
for i in range(1, 10, 2): # 左闭右开
print('total3 = total3 + i = %d' % total2 + ' + %d' % i)
total3 += i
print(total3) # 25

3.4.3 控制语句 break、contine、pass
1)控制语句在while循环和for循环中都适用;
2)控制结构(顺序-分支-循环)
pass:空语句,也叫占位语句。
eg:
# 1~4能被2整除就打印,否则什么都不做
for i in range(1, 5):
if i % 2 == 0:
print(i)
else:
pass # 希望这种情况不做任何处理

contine:结束本轮循环,继续后面的循环
eg:
# 打印出1~10中满足步长为2,且不等于5的整数
# 打印出1~10中满足步长为2,且不等于5的整数
for i in range(1, 11, 2):
if i == 5:
continue
else:
print(i, '', end="") # 1 3 7 9

break:直接结束整个循环
eg:
# 打印出1~10中满足步长为2的整数,如果整数等于5,就停止打印
for i in range(1, 11, 2):
if i == 5:
break
else:
print(i, '', end="") # 1 3

3.4.4 循环后跟else
放在循环体后面,非必须,循环体中没有break语句,else语句才会执行。
eg:
# 循环体中有break
# 打印出1~10中满足步长为2的整数,如果整数等于5,就停止打印
for i in range(1, 11, 2):
if i == 5:
break
else:
print(i, '', end="") # 1 3
else:
print("循环体中没有break语句!!")
# 循环体中没有break
# 打印出1~10中满足步长为2的整数,如果整数等于5,就停止打印
for i in range(1, 11, 2):
if i == 5:
continue
else:
print(i, '', end="") # 1 3 7 9
else:
print("循环体中没有break语句!!") # 循环体中没有break语句!!

4. 函数(函数定义,函数调用,参数传递,匿名函数)
4.1 函数定义,函数调用
1)python定义函数使用def关键字;
2)在函数体当中,可以有return语句,也可以没有;没有的时候和return后不跟要返回的对象时,这两种情况,函数都默认返回的是None;
3)如果函数体中的return可以同时返回零到多个对象,如果返回多个时,外面调用的地方使用的是一个对象来接收返回的多个对象时,那么接收对象的类型就是元组。
格式:
def 函数名(参数列表):
函数体
eg:
# 计算矩形面积函数
def area(width, height): # 函数定义
return width * height
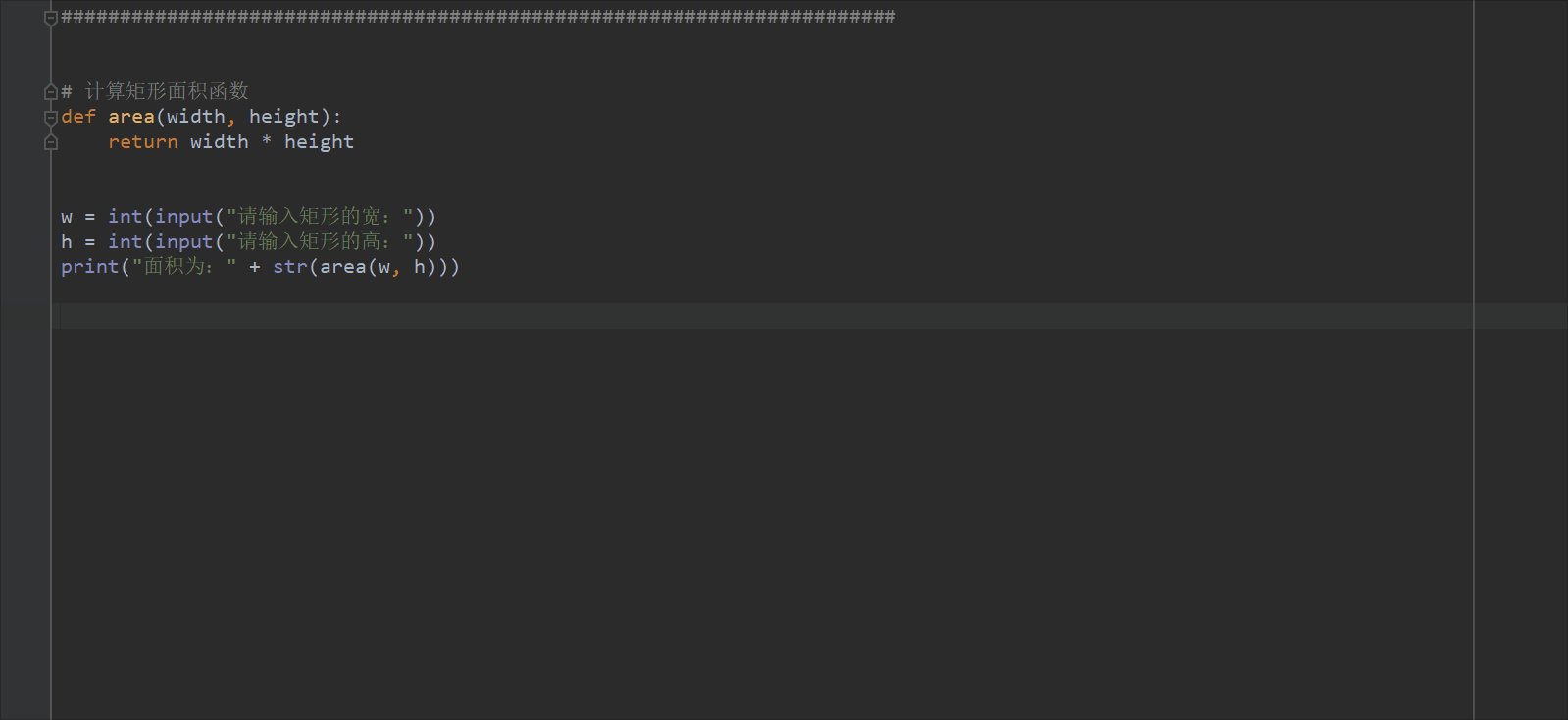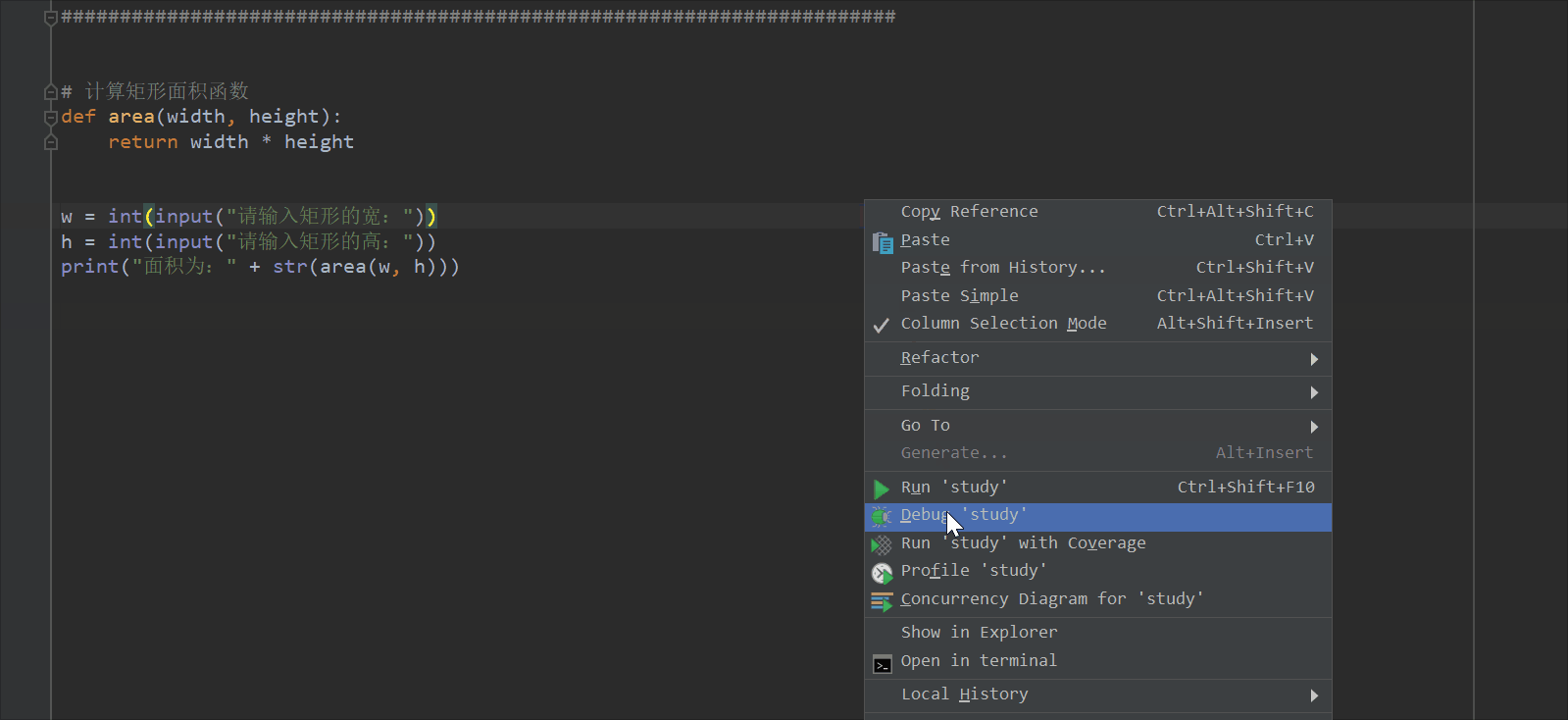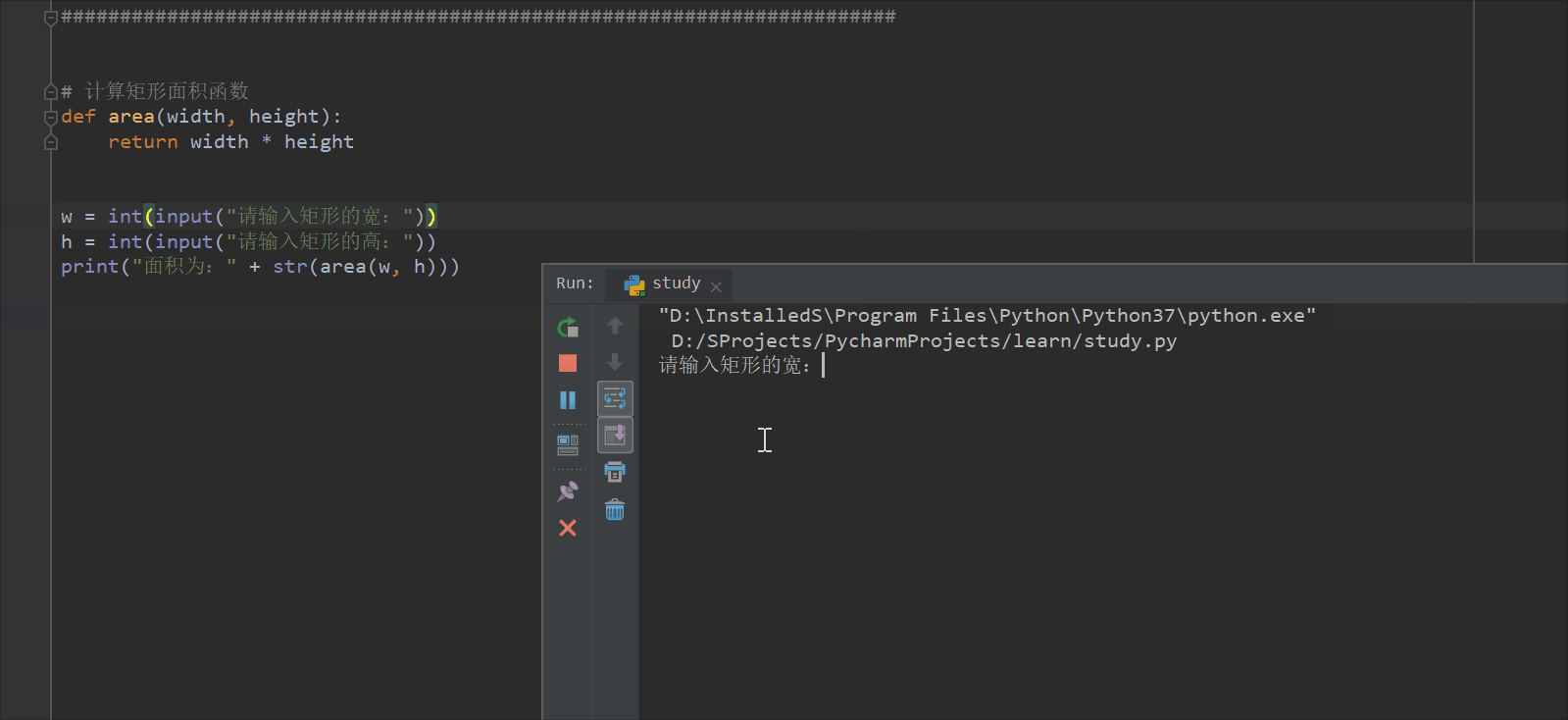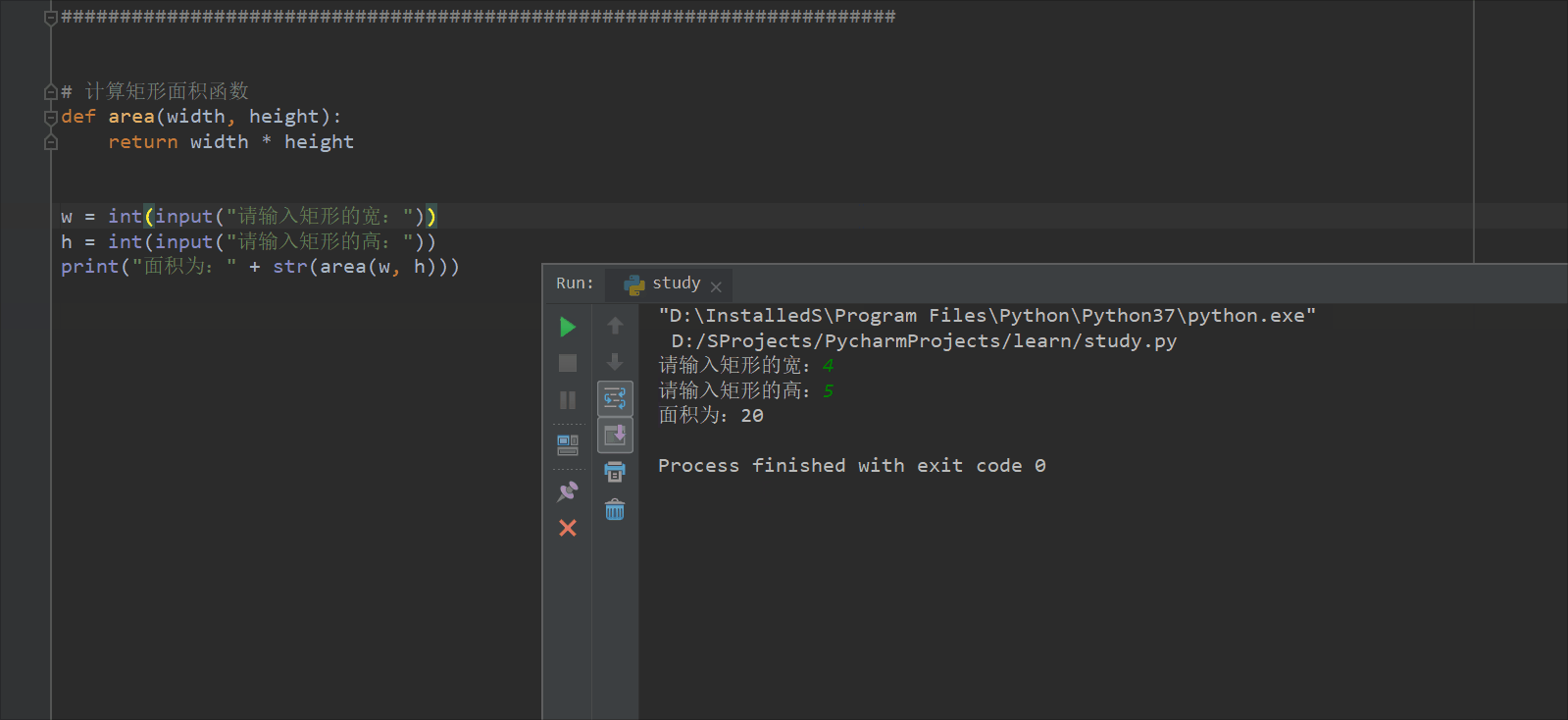
w = int(input("请输入矩形的宽:"))
h = int(input("请输入矩形的高:"))
print("面积为:" + str(area(w, h))) # 函数调用,传参
def func(x, y): # 函数定义
return x, y, x - y, x + y, x * y # return可以同时返回零到多个对象
result = func(4, 5)
# 使用的是一个对象来接收返回的多个对象时,那么接收对象的类型就是元组
print(result, type(result)) # (4, 5, -1, 9, 20) <class 'tuple'>
result2, result3, result4, result5, result6 = func(4, 5) # 使用多个对象来接收
print(result2, result3, result4, result5, result6) # 4 5 -1 9 20

4.2 参数传递
可变和不可变对象在函数中传参使用
1)不可变对象:数值型、字符串、元组
修改了对象的值之后,对象前后的内存地址会改变。
2)可变对象:列表,集合,字典
修改了对象的值之后,对象前后的内存地址不会改变,还指向同一个对象。
3)不可变对象当做实参传入函数体中修改使用的话,外边的不可变对象的值不变(类似C++的值传递)
4)可变对象当做实参传入函数体中修改使用的话,外边的可变对象的值会跟着变(类似C++的引用传递)
eg:
# 可变对象当做实参传入函数体中修改使用的话,外边的可变对象的值会跟着变
list1 = [1, 'a', False, ['d', 2]]
def func(x):
x.append([True, 'hyh'])
print('x:', x) # x: [1, 'a', False, ['d', 2], [True, 'hyh']]
func(list1)
print(list1) # [1, 'a', False, ['d', 2], [True, 'hyh']]

4.2.1 参数类型-必须参数
必须参数:实参的个数,顺序和类型必须与形参一致。
eg:
def func(name, age):
print("姓名:%s, 年龄:%d" % (name, age))
# 实参的个数,顺序和类型必须与形参一致
func('hyh', 45) # 姓名:hyh, 年龄:45

4.2.2 参数类型-关键字参数
1)关键字参数和函数调用关系密切,函数调用使用关键字参数来确定传入的参数值。
2)使用关键字参数允许函数调用时参数的顺序与声明时不一致,因为python解释器能够用参数名匹配参数值。
eg:
def func(name, age):
print("姓名:%s, 年龄:%d" % (name, age))
# 函数调用使用关键字参数来确定传入的参数值
# 关键字参数允许函数调用时参数的顺序与声明时不一致
func(age=45, name='hyh') # 姓名:hyh, 年龄:45

4.2.3 参数类型-默认参数
为形参指定默认值,当实参没有传递对应的值的时候,默认值就派上了用场。
eg:
# 为形参指定默认值
def func(name="hyh", age=20):
print("姓名:%s, 年龄:%d" % (name, age))
if __name__ == '__main__':
func(age=37) # 姓名:hyh, 年龄:37
func('tom') # 姓名:tom, 年龄:20
func() # 姓名:hyh, 年龄:20

4.2.4 参数类型-不定长参数
1)不定长参数,可以接收零到多个参数,若调用的时候会传入不定个实参,建议定义函数的时候使用不定长参数。
2)加了星号*的变量名会存放所有未命名的变量参数,如果在函数调用时没有指定参数,它就是一个空元组,我们也可以不向函数传递未命名的变量。
eg:
# 不定长参数
def sum_num(* num):
total = 0
for i in num:
total += i
return total
if __name__ == '__main__':
result = sum_num(1, 2, 3, 4)
print("加和后:%d" % result) # 加和后:10
print(add()) # 在函数调用时没有指定参数,num就是一个空元组

4.3 匿名函数
1)匿名函数的使用场景:单行语句;不想为函数起名;一次性使用。
2)形参可以是零到多个。
3)所谓的匿名就是不再使用def语句这样的标准的形式来定义一个函数。
4)lambda的主体是一个表达式,而不是一个代码块,仅仅能在lambda表达式中封装有限的逻辑进去。
格式:
# 表达式的结果就是要返回的值
lambda [arg1[,arg2,...,argn]]: 表达式
eg:
sum1 = lambda x, y, z: x + y + z
if __name__ == '__main__':
print(sum1(1, 2, 3)) # 6

5. 文件读写
5.1 txt文件读写
在测试时,txt文件通常用来存储日志。
方式一:非主流的.txt文件读写方式,不推荐使用
# 非主流的.txt文件读写方式,不推荐使用
# 写.txt文件 不推荐这种方式
f = open('test.txt', 'w') # 以写(覆盖)的方式打开test.txt文件,并得到一个文件打开对象f
f.write("You never know what hand you're going to get dealt next. 世事难料,且行且知。") # 向文件中写入
f.close() # 关闭打开的文件对象
# 读.txt文件 不推荐这种方式
f2 = open('test.txt', 'r') # 以读的方式打开test.txt文件,并得到一个文件打开对象f
result = f2.read() # 读文件中的所有内容
print(result)
f2.close() # 关闭打开的文件对象
方式二:主流的.txt文件读写方式,推荐使用
优点:读写完成后,不需要每次写关闭文件的语句,会自动帮我们关闭。
# 主流的.txt文件读写方式,推荐使用
# 读写完成后,不需要每次写关闭文件的语句,会自动帮我们关闭
# 文件的打开模式:
# r:读 w:覆盖写 a:追加 b:二进制 +:比如r+表示除了读还可以写 rb:以二进制读的方式打开文件等
# 写.txt文件 推荐这种方式 加了with...as...
with open('test.txt', 'w') as f:
f.write("You never know what hand you're going to get dealt next. 世事难料,且行且知。") # 向文件中写入
# 读.txt文件 推荐这种方式 加了with...as...
with open("test.txt", 'r') as f2:
print(f2.read()) # 读文件中的所有内容
eg:
使用主流.txt文件写应用
# 以追加的方式写
with open('test.txt', 'a') as f:
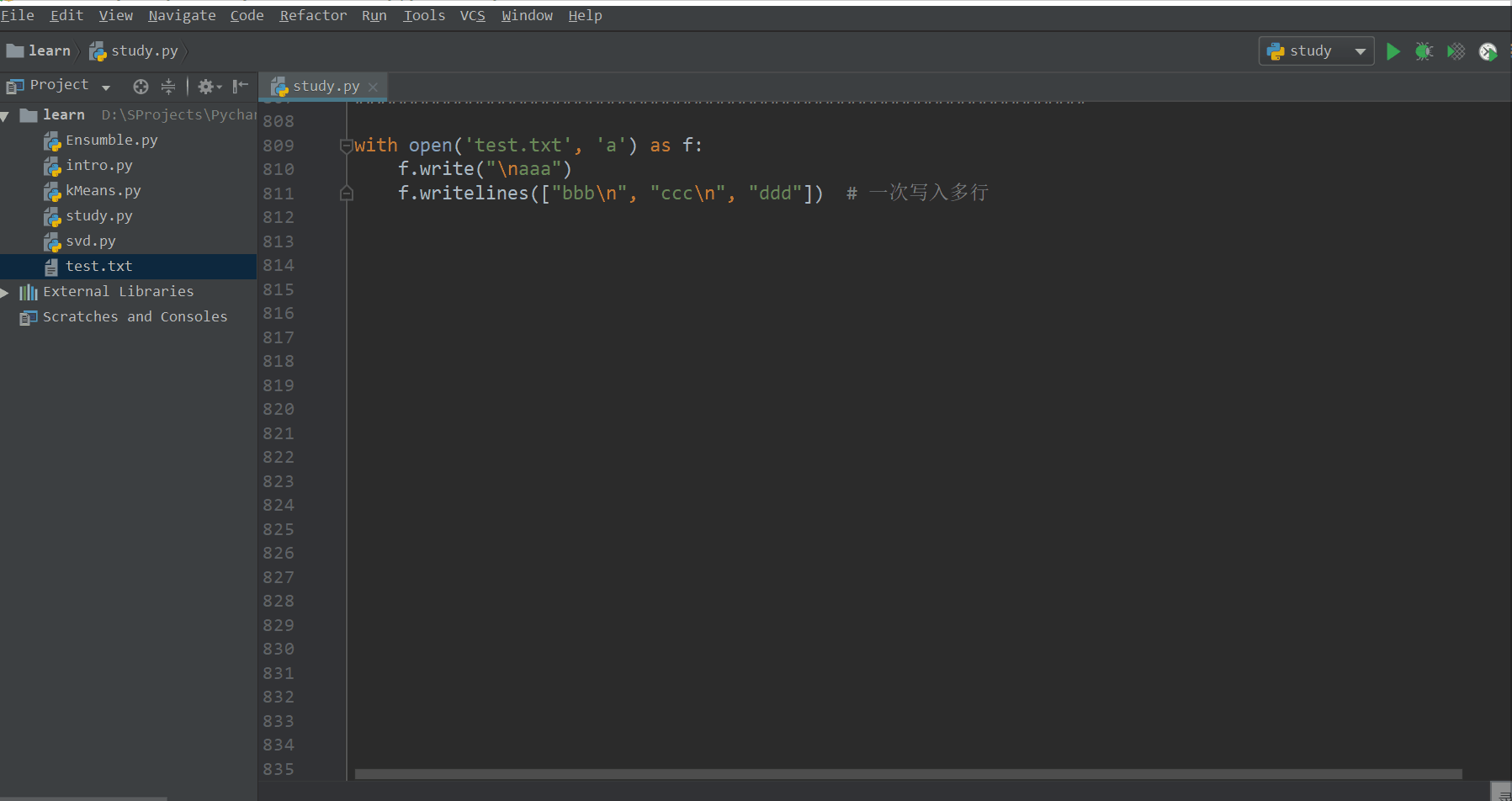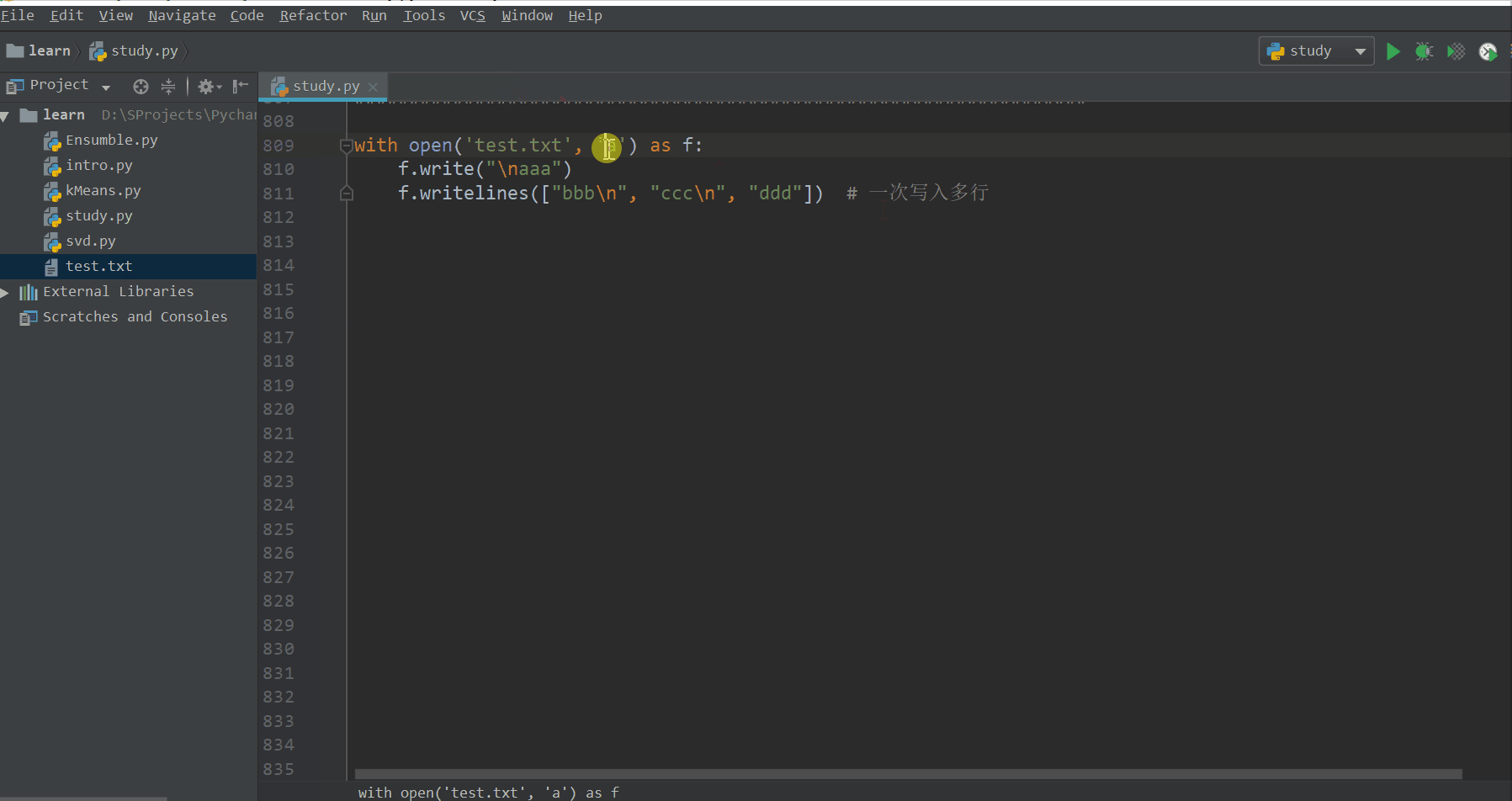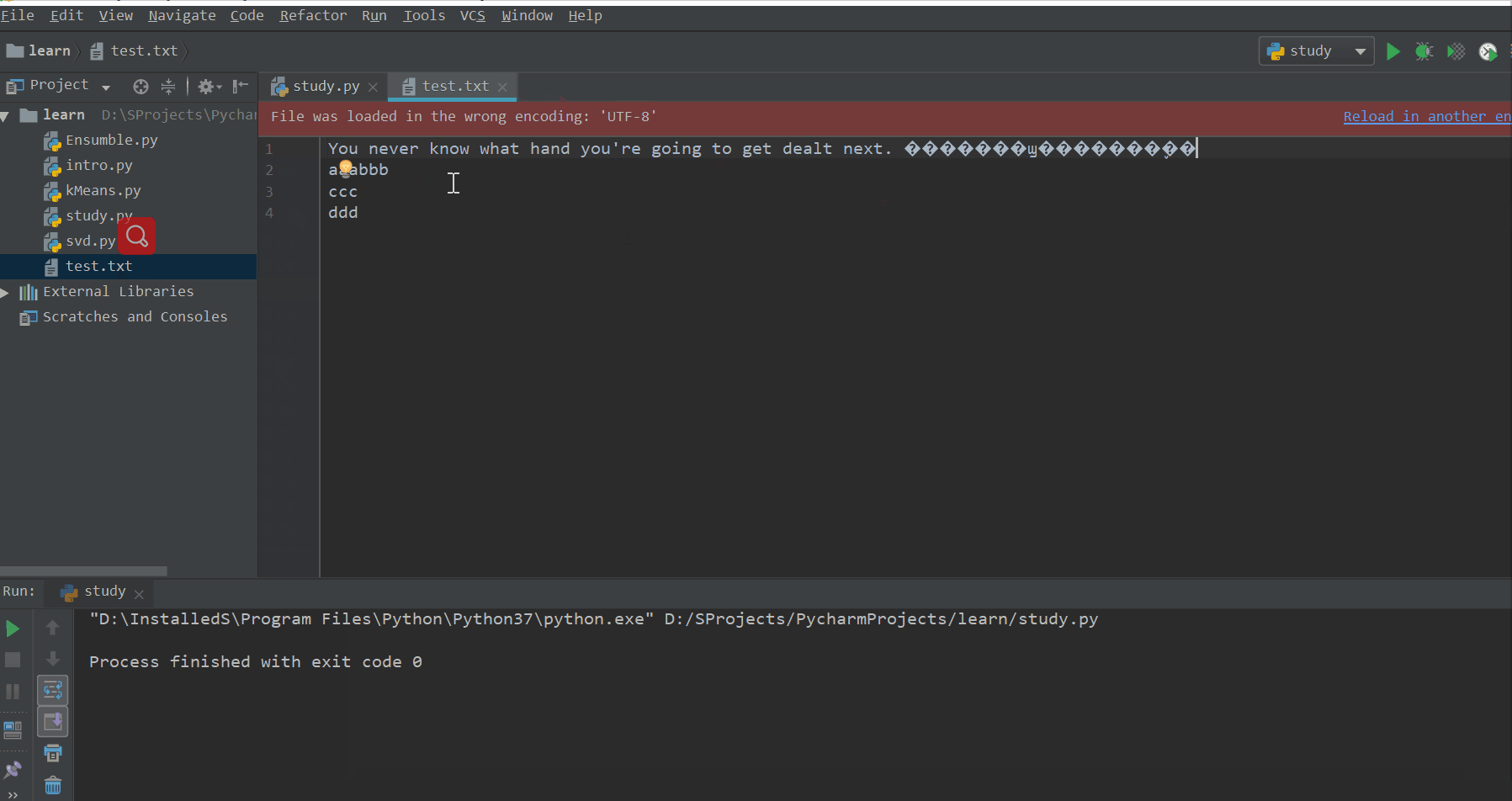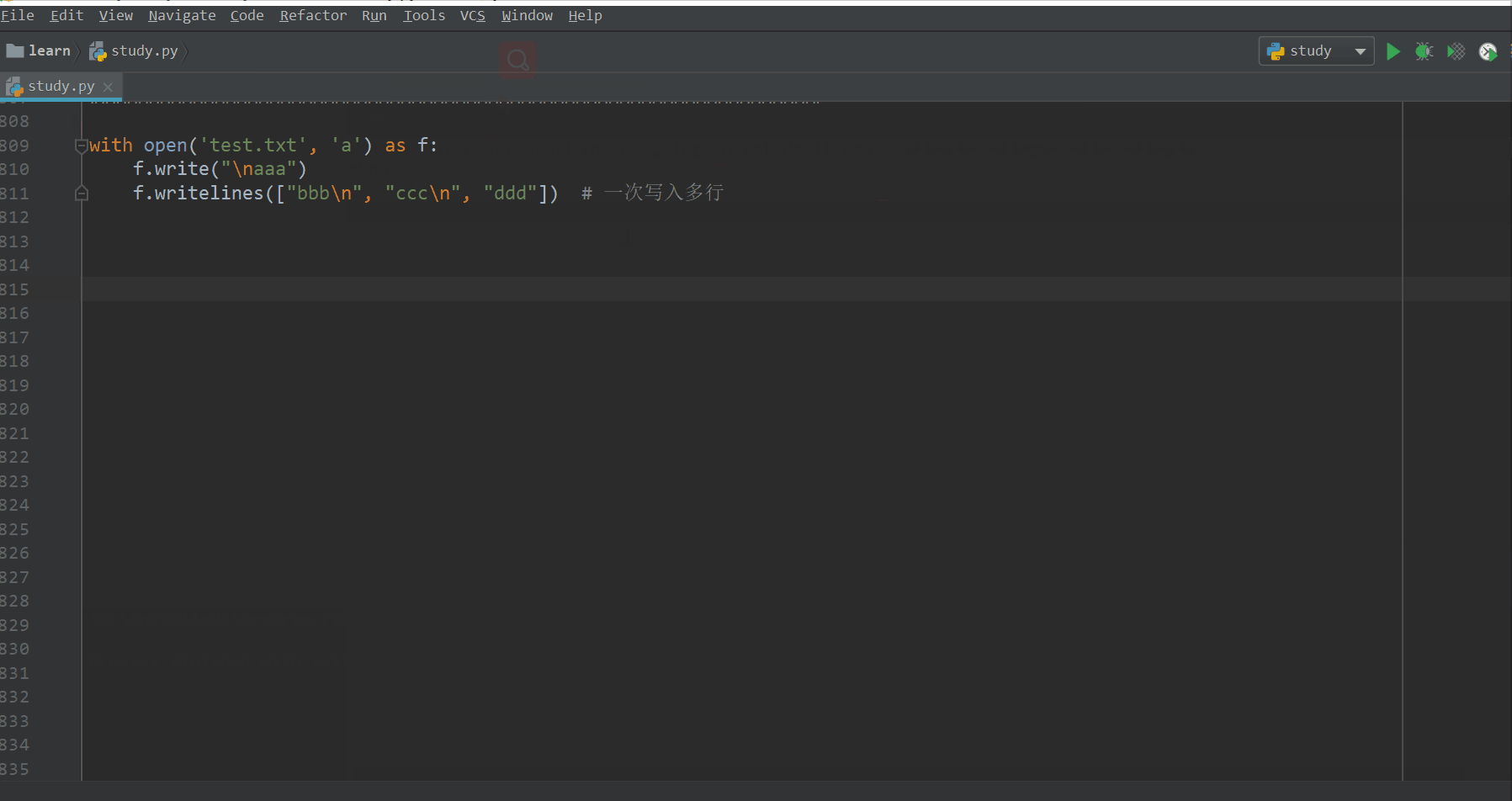
f.write("\naaa")
f.writelines(["bbb\n", "ccc\n", "ddd"]) # 一次写入多行
使用主流.txt文件读应用
读一行
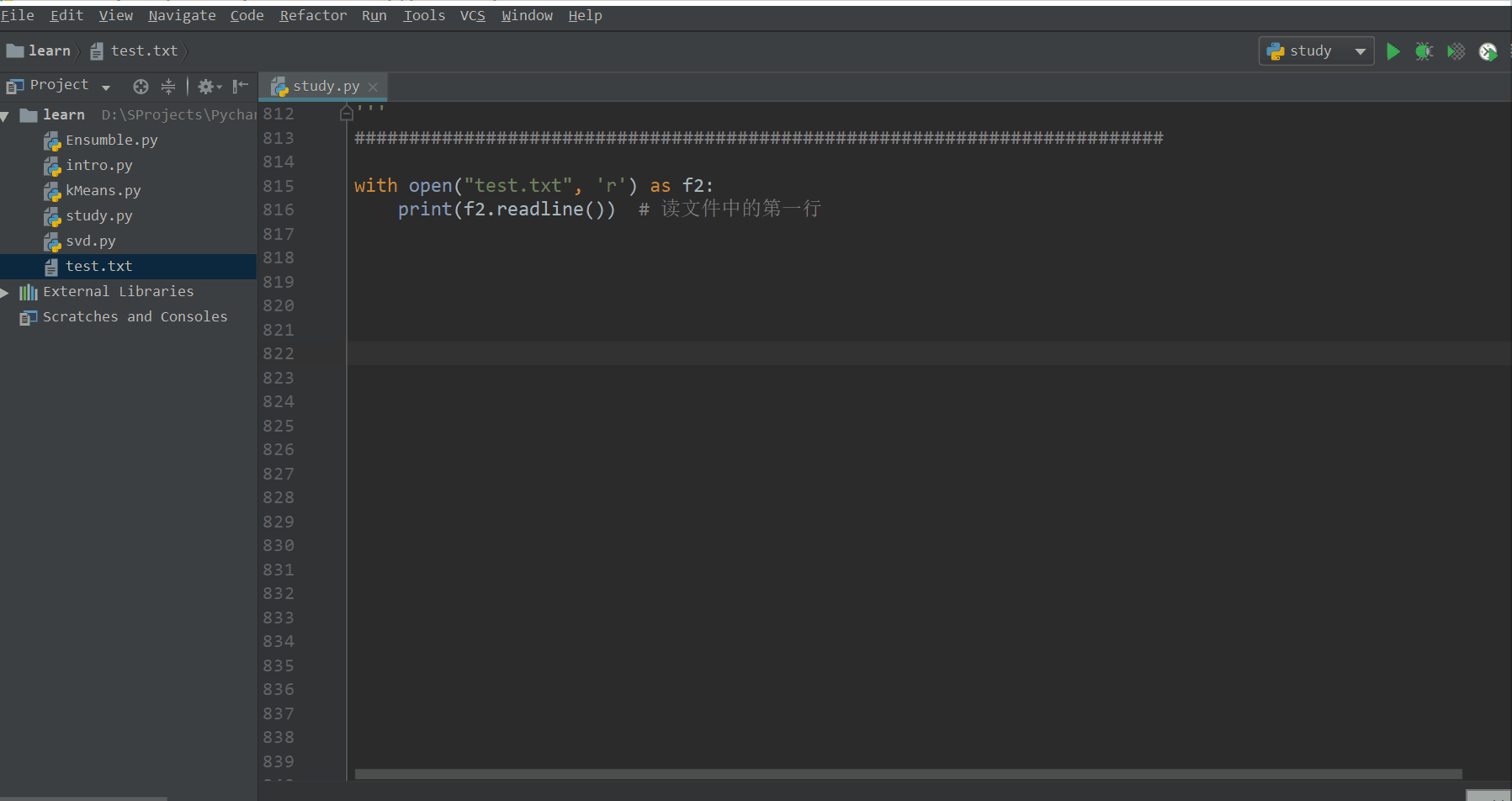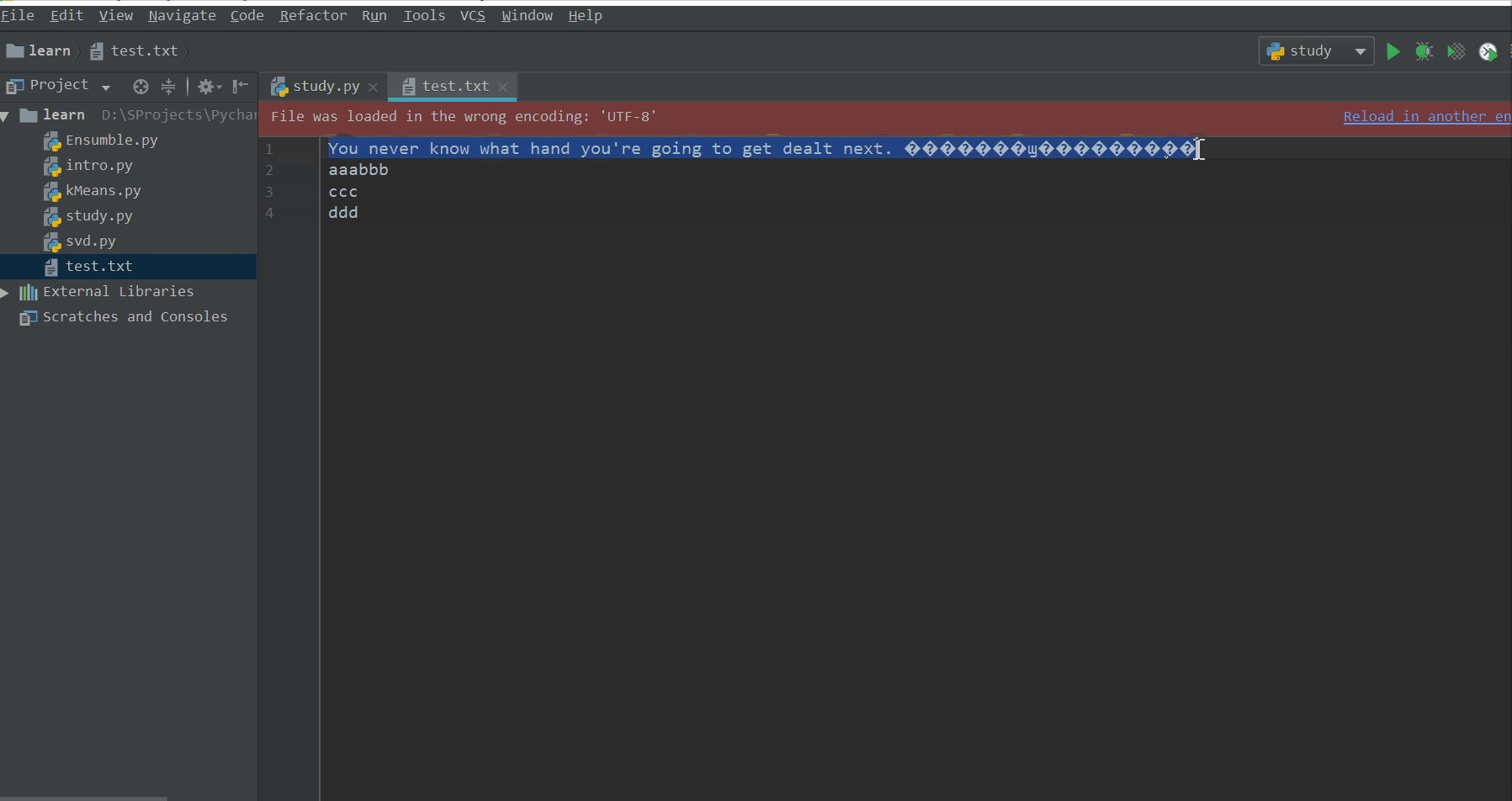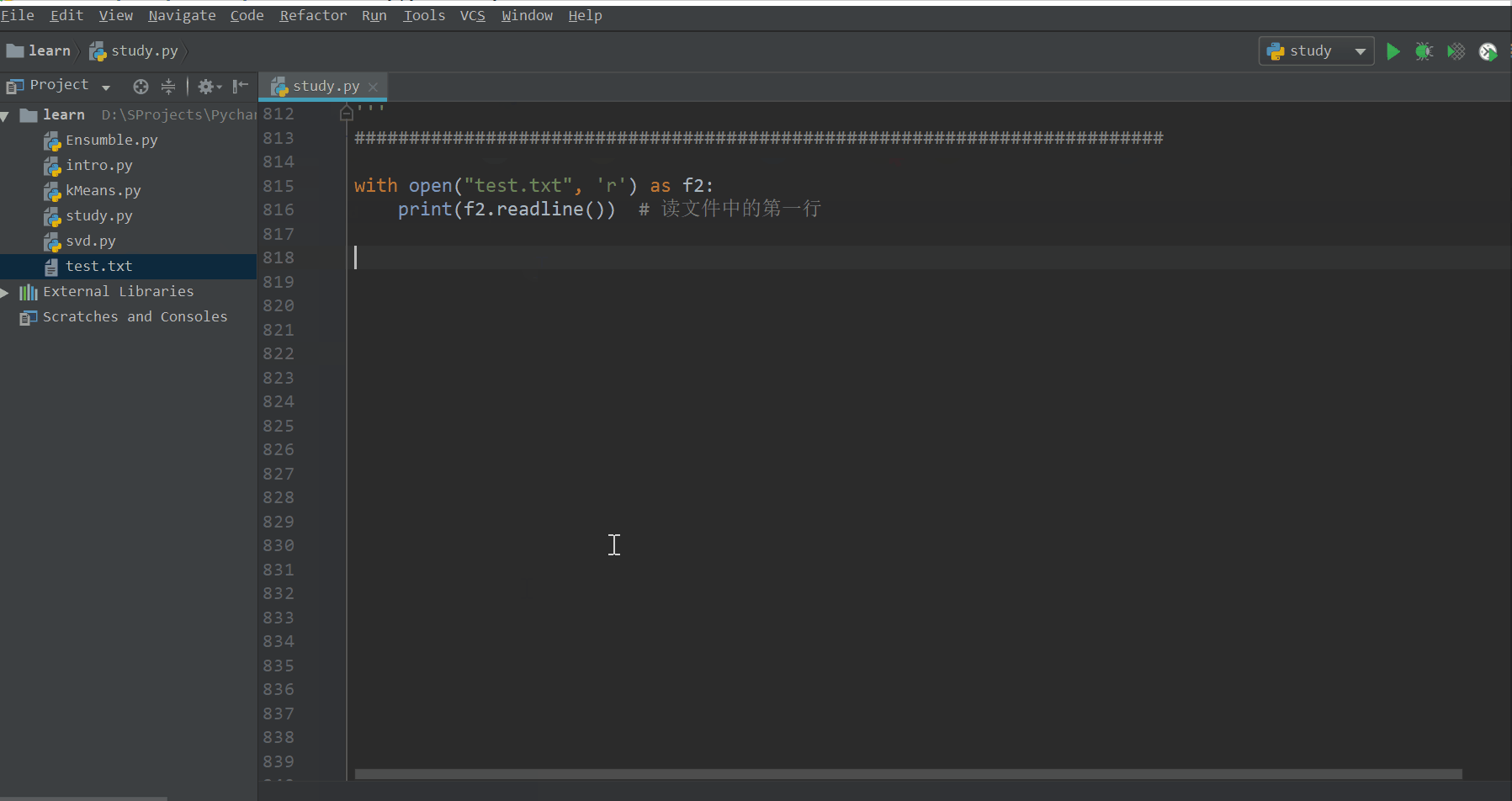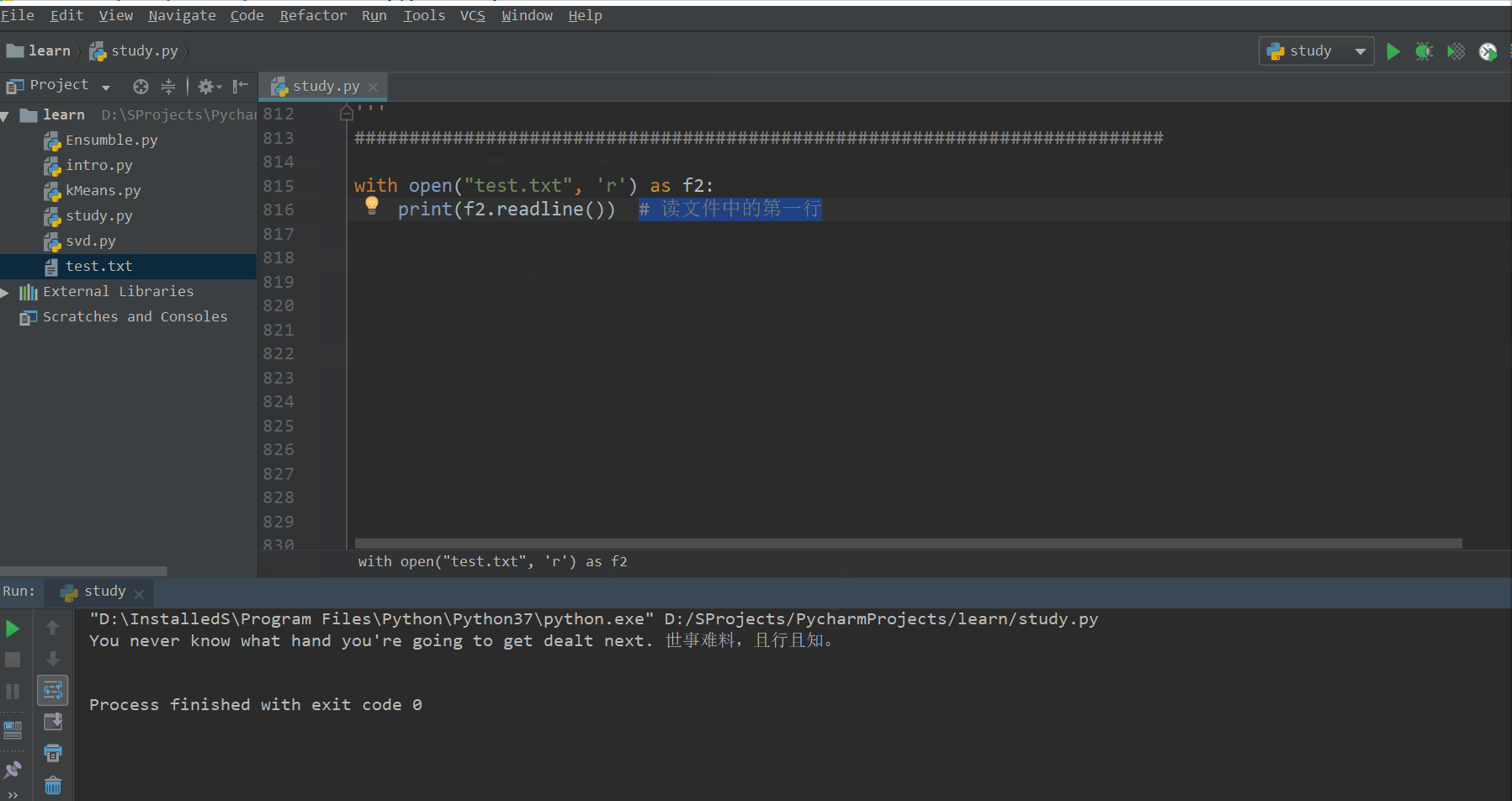
with open("test.txt", 'r') as f2:
print(f2.readline()) # 读文件中的第一行
读所有行,以列表的形式返回,每行作为列表的一个成员,每个成员会自动带\n
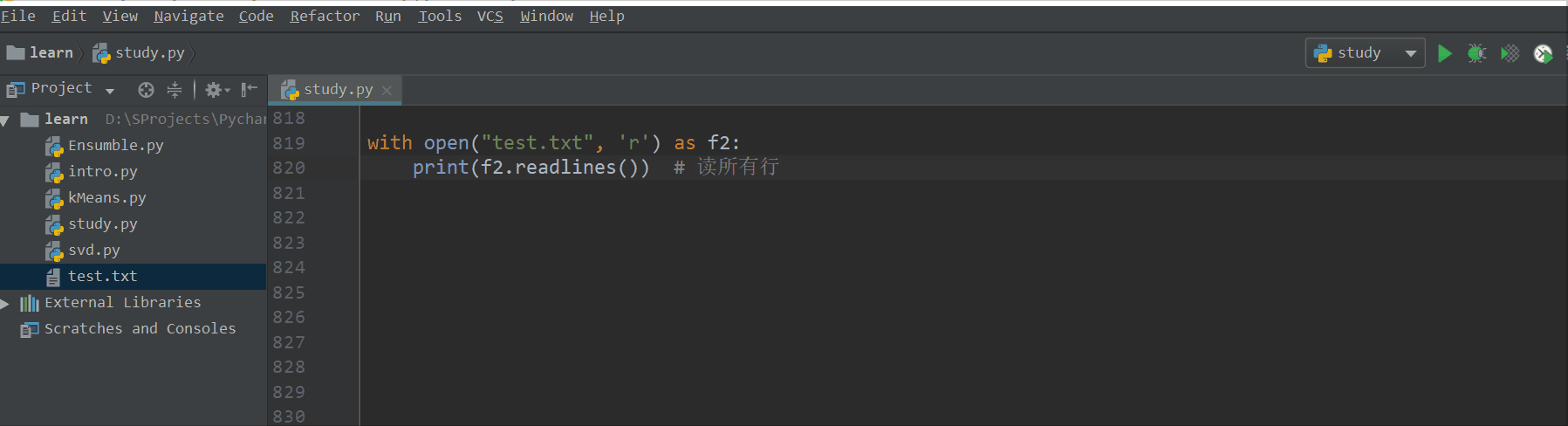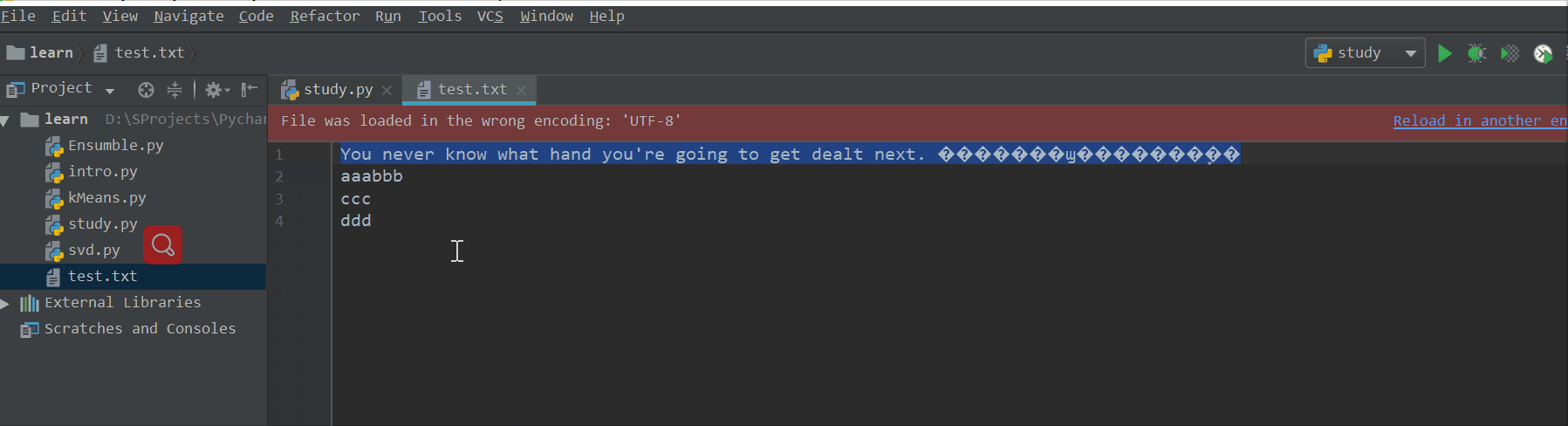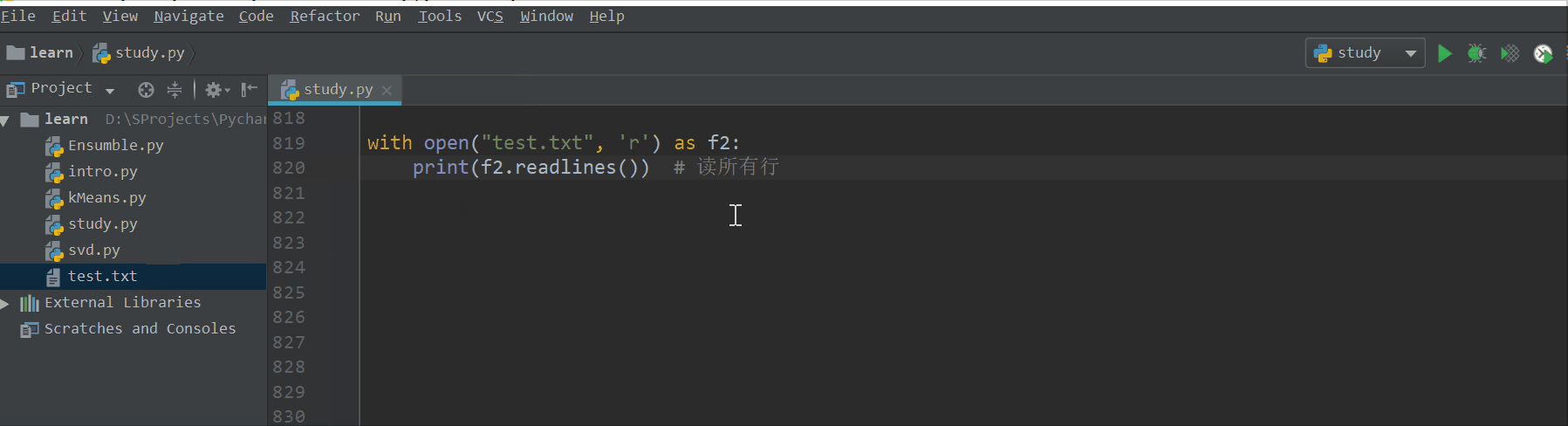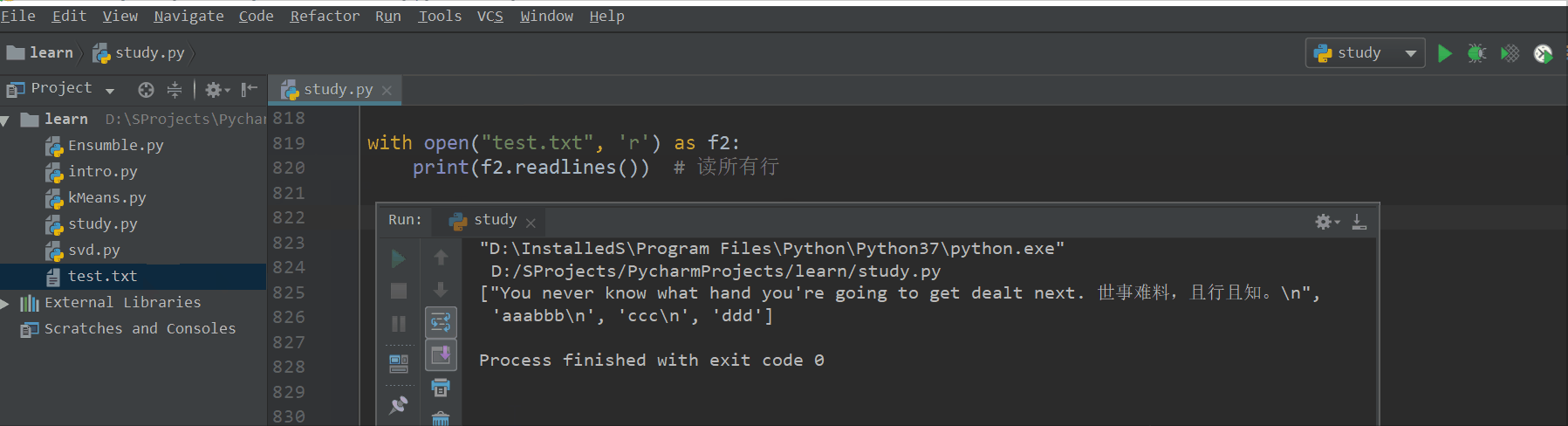
with open("test.txt", 'r') as f2:
print(f2.readlines()) # 读所有行
读所有行,以列表的形式返回,每行作为列表的一个成员,以行做分隔(每个成员不带\n)
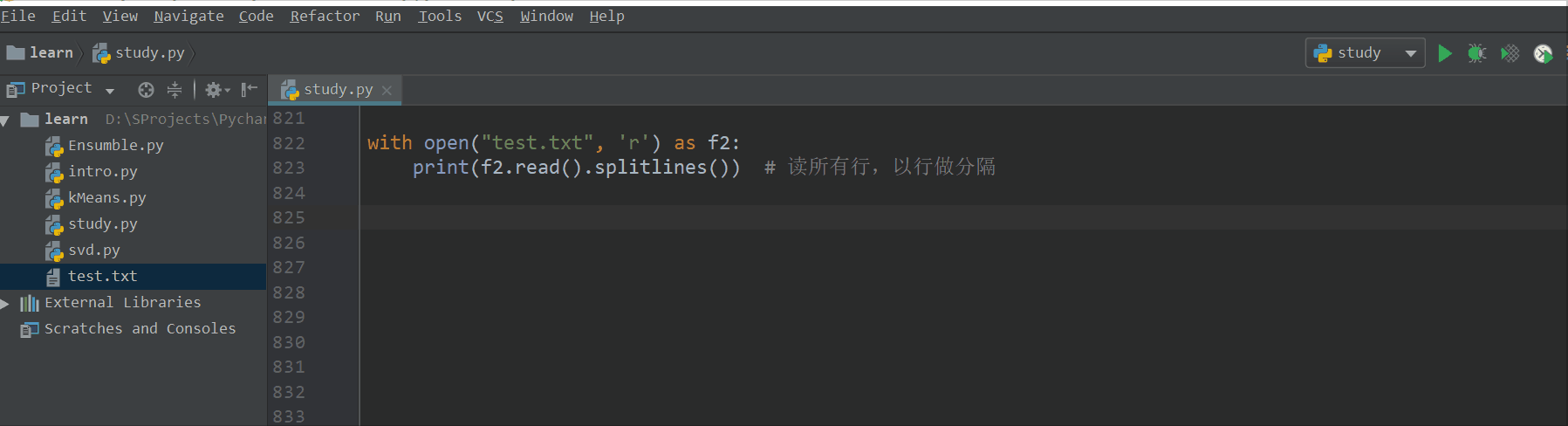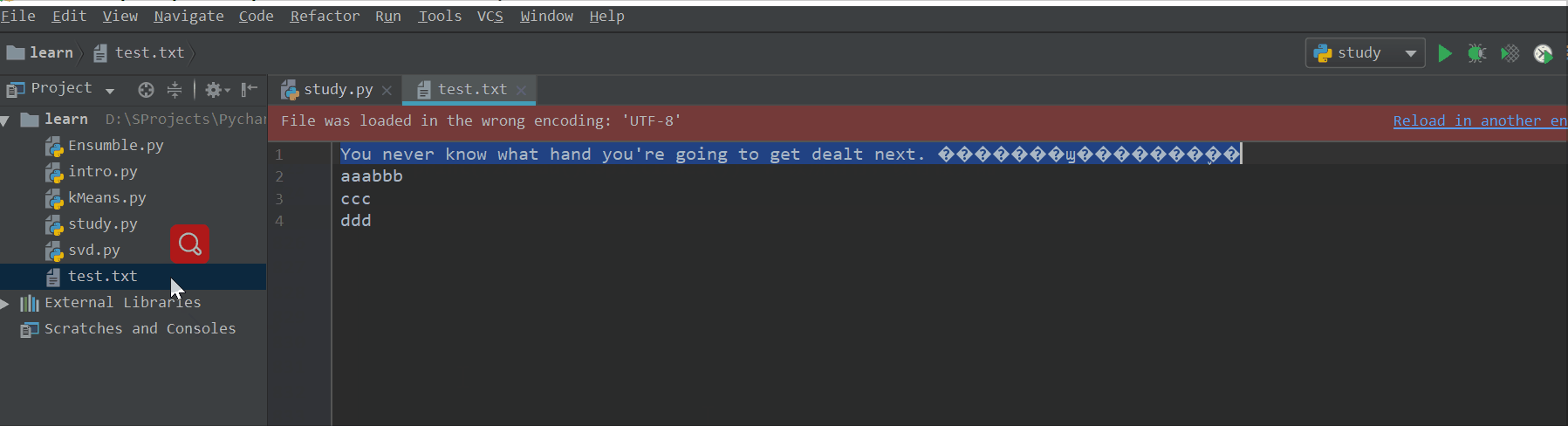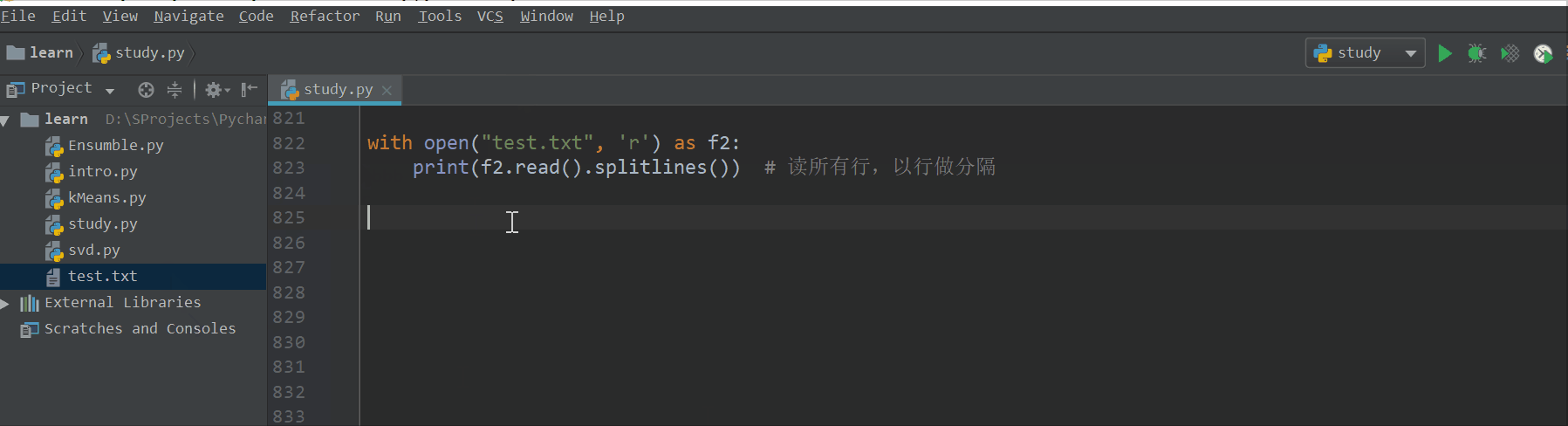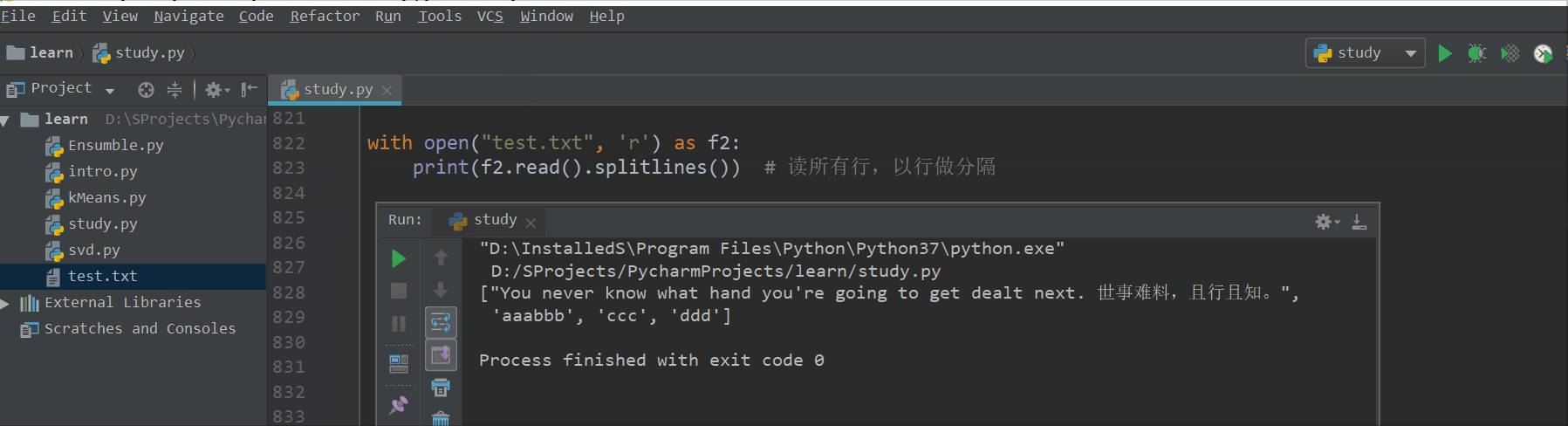
with open("test.txt", 'r') as f2:
print(f2.read().splitlines()) # 读所有行,以行做分隔
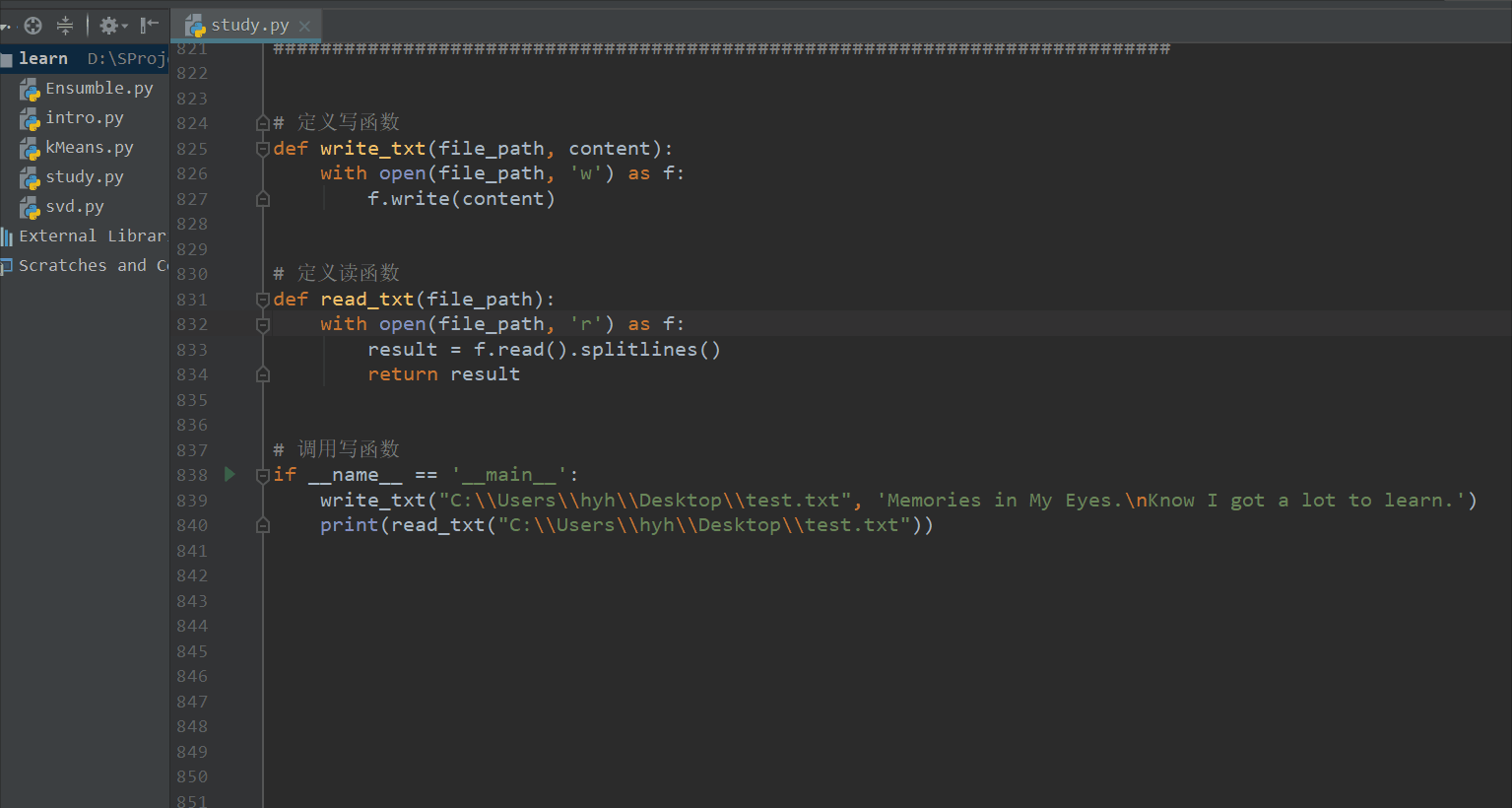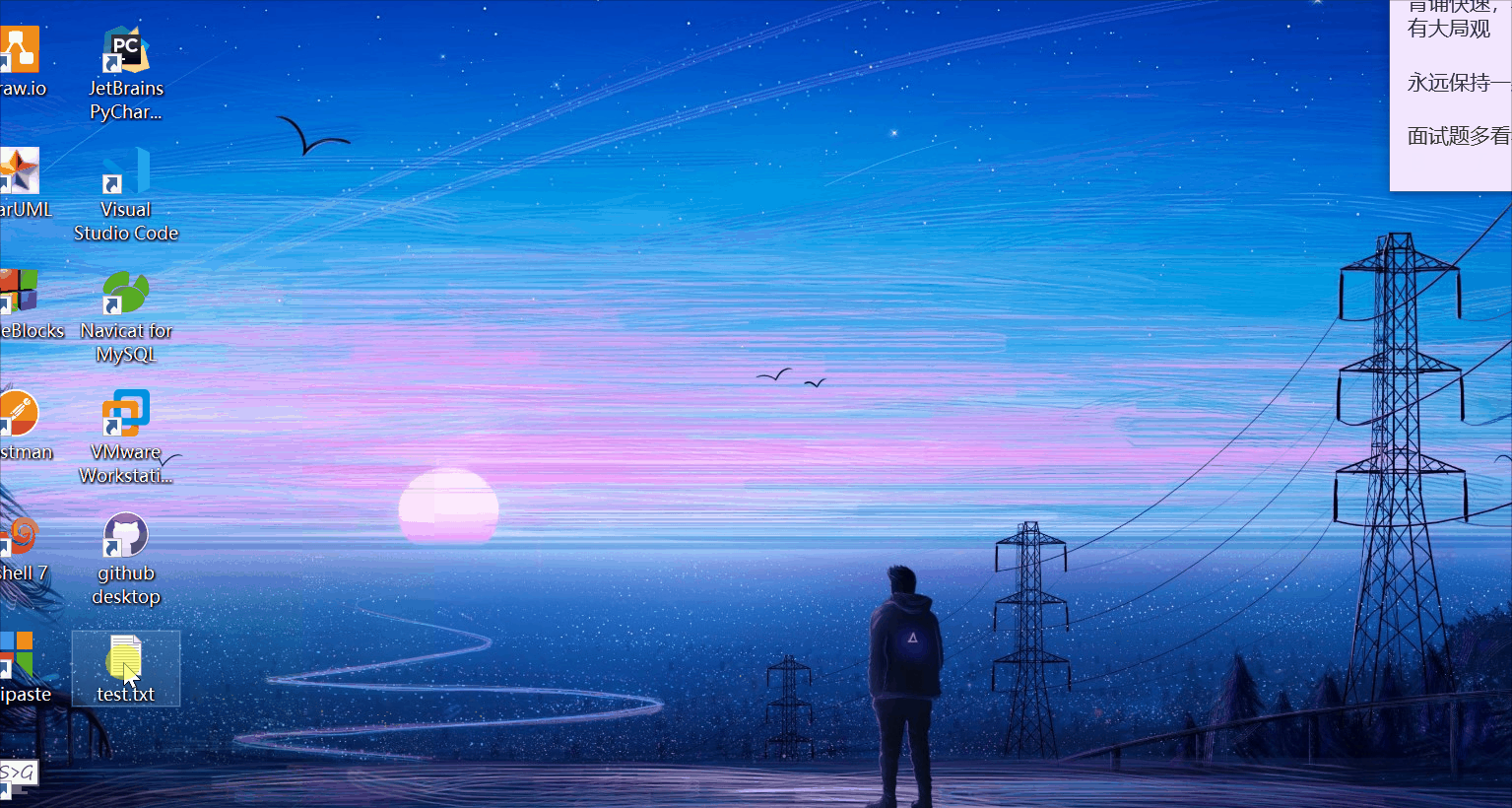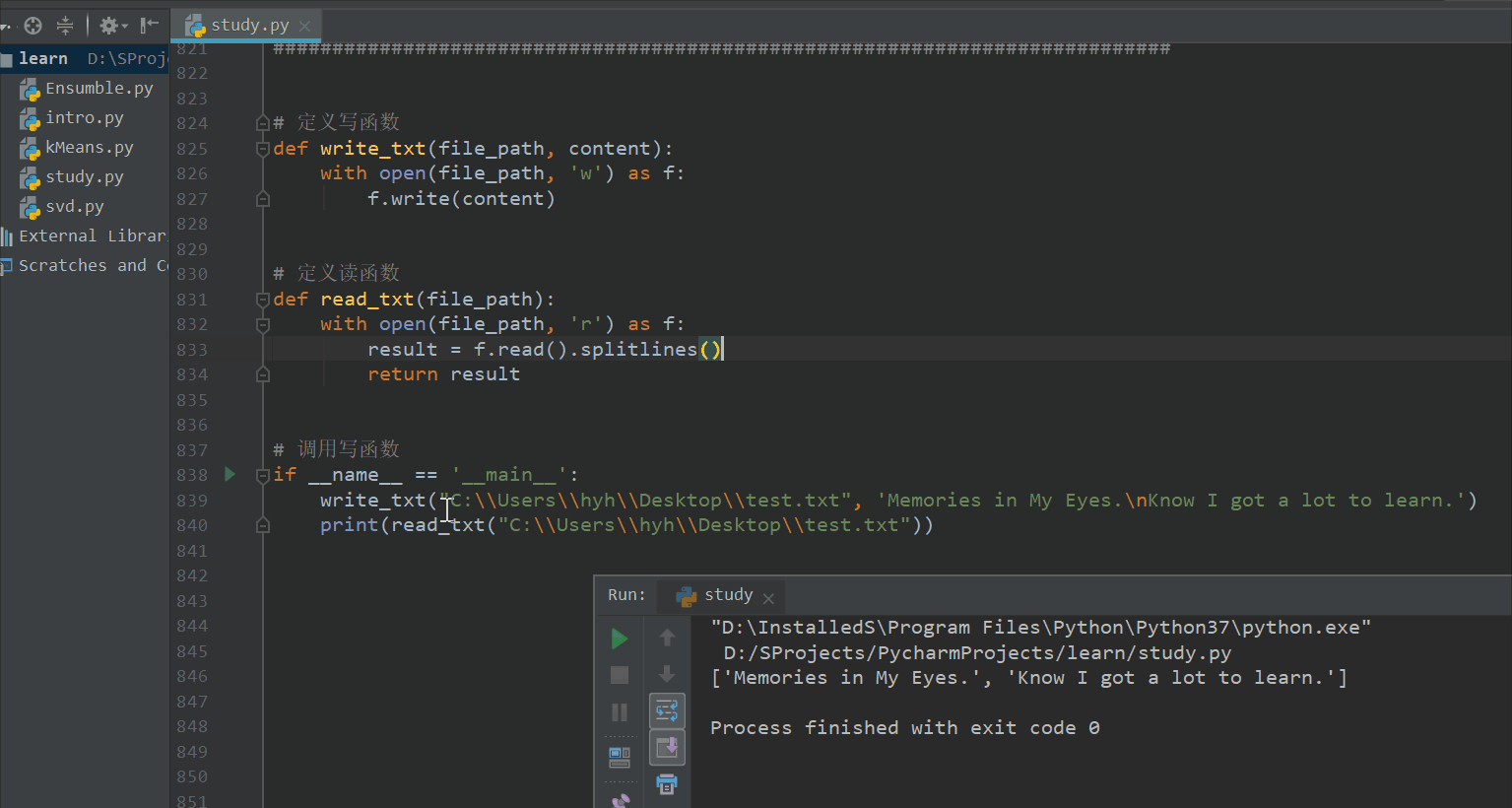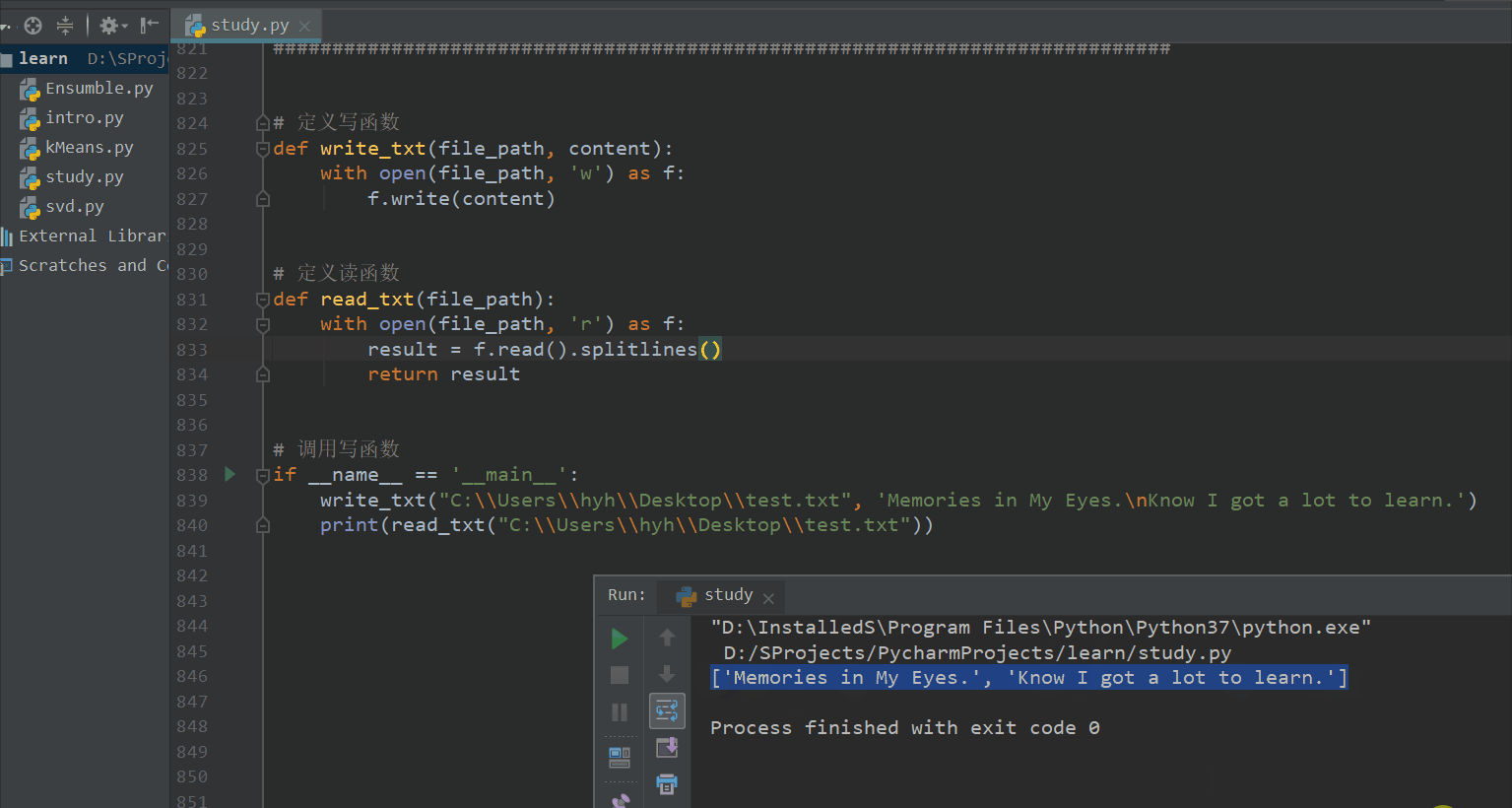
定义读写函数
eg:
# 定义写函数
def write_txt(file_path, content):
with open(file_path, 'w') as f:
f.write(content)
# 定义读函数
def read_txt(file_path):
with open(file_path, 'r') as f:
result = f.read().splitlines()
return result
# 调用写函数
if __name__ == '__main__':
write_txt("C:\\Users\\hyh\\Desktop\\test.txt", 'Memories in My Eyes.\nKnow I got a lot to learn.')
print(read_txt("C:\\Users\\hyh\\Desktop\\test.txt"))
5.2 csv文件读写
csv-逗号分隔值文件格式
逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。纯文本意味着该文件是一个字符序列,不含必须像二进制数字那样被解读的数据。CSV文件由任意数目的记录组成,记录间以某种换行符分隔;每条记录由字段组成,字段间的分隔符是其它字符或字符串,最常见的是逗号或制表符。通常,所有记录都有完全相同的字段序列。通常都是纯文本文件。建议使用WORDPAD或是记事本来开启,再则先另存新档后用EXCEL开启,也是方法之一。
1)测试时,csv通常用来存储测试数据。
2).csv文件占用空间比.xlsx文件小的多,在windows中csv文件默认Excel打开,也可以选择使用记事本。
eg:
1)桌面新建一个excel表 test.xlsx
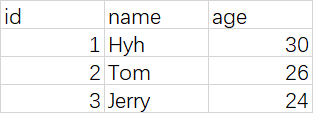
2)表中写上内容:
3)将test.xlsx另存为csv的格式

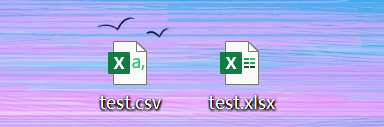
4)我们查看这两个文件的详细信息,发现这两个文件的大小不同,进入csv文件(csv文件默认使用excel打开),发现其内容与在Excel中显示没什么区别


5)这个test.csv文件也可以用记事本打开,但是如果我们用记事本打开test.xlsx文件时,会发现都是乱码,说明test.xlsx不是纯文本文件。


import csv
# 写.csv文件
with open("C:\\Users\\hyh\\Desktop\\test.csv", 'a') as f:
obj = csv.writer(f)
obj.writerow(['4', 'Carlo', 45]) # 向csv文件中写入一条记录
import csv
# 读.csv文件
with open("C:\\Users\\hyh\\Desktop\\test.csv", 'r', encoding='utf8') as f:
obj = csv.reader(f)
for i in obj:
print(i)

定义读写函数
import csv
# 写csv文件
def write_csv(file_path, content): # content是一个数组
with open(file_path, 'a', encoding='utf8', newline='') as f:
obj = csv.writer(f)
obj.writerow(content)
# 读csv文件
# 注意一下文件内容返回的方式!
def read_csv(file_path):
result = [] # 用来存放csv文件中的每一行内容
with open(file_path, 'r', encoding='utf8') as f:
obj = csv.reader(f)
for i in obj:
result.append(i)
return result
if __name__ == "__main__":
write_csv('C:\\Users\\hyh\\Desktop\\test.csv', ['5', 'Ivan', 24])
result = read_csv('C:\\Users\\hyh\\Desktop\\test.csv')
print(result)

5.3 excel文件
测试时,cexcel通常用来存储测试数据。
有很多python的第三方的库支持excel文件,比如xlrd。
安装xlrd
将xlrd的版本1.2.0,xlrd的2.0以上版本不支持后缀名.xlsx文件的读取,只支持.xls文件的读取,所以用老版本1.2.0。

xlrd安装成功

eg:
读桌面上的excel表

import xlrd
# 读excel文件
# file_path:文件路径,index:打开哪个工作表
def read_excel(file_path, index):
excel = xlrd.open_workbook(file_path) # 打开excel文件
sheet = excel.sheets()[index] # 得到表单对象
return sheet
if __name__ == '__main__':
table = read_excel('C:\\Users\\hyh\\Desktop\\test.xlsx', 0) # 得到索引为0的表单
for i in range(table.nrows): # nrows:表单的行数
rows = table.row_values(i) # 得到指定行的所有内容,以列表形式返回
print(rows)

eg:
5.4 xml文件读
xml:可扩展标记语言,通常用来配置文件。
桌面新建一个配置文件,用Visual Studio Code打开编辑,或者用记事本编辑等
<?xml version="1.0" encoding="utf-8"?>
<config>
<browser>1</browser><!--浏览器类型:1-firefox,2-chrome,3-IE-->
<username>admin</username>
<password>123456</password>
</config>

eg:
方式一:通过DOM方式(文档对象模型,document object model),这种方式不推荐,比较麻烦(略)。
方式二:通过ElementTree的方式
import xml.etree.ElementTree as ET # 导入模块并重命名
# 读XMl文件
def read_xml(file_path, node_name):
datas = []
tree = ET.parse(file_path) # 得到元素树
root = tree.getroot() # 得到根
for i in root.iter(node_name): # 循环遍历指定名称的所有节点
datas.append(i.text)
return datas
if __name__ == '__main__':
username = read_xml(r'C:\Users\hyh\Desktop\配置.xml', 'username')
password = read_xml(r'C:\Users\hyh\Desktop\配置.xml', 'password')
print("username:%s password:%s" % (username, password)) # username:['admin'] password:['123456']

5.5 不同运行环境(操作系统)下,文件的读写 os
使在不同的运行环境(eg:linux,windows等)下,代码不改变,使文件的读写依然成立。
我们以读csv文件为例
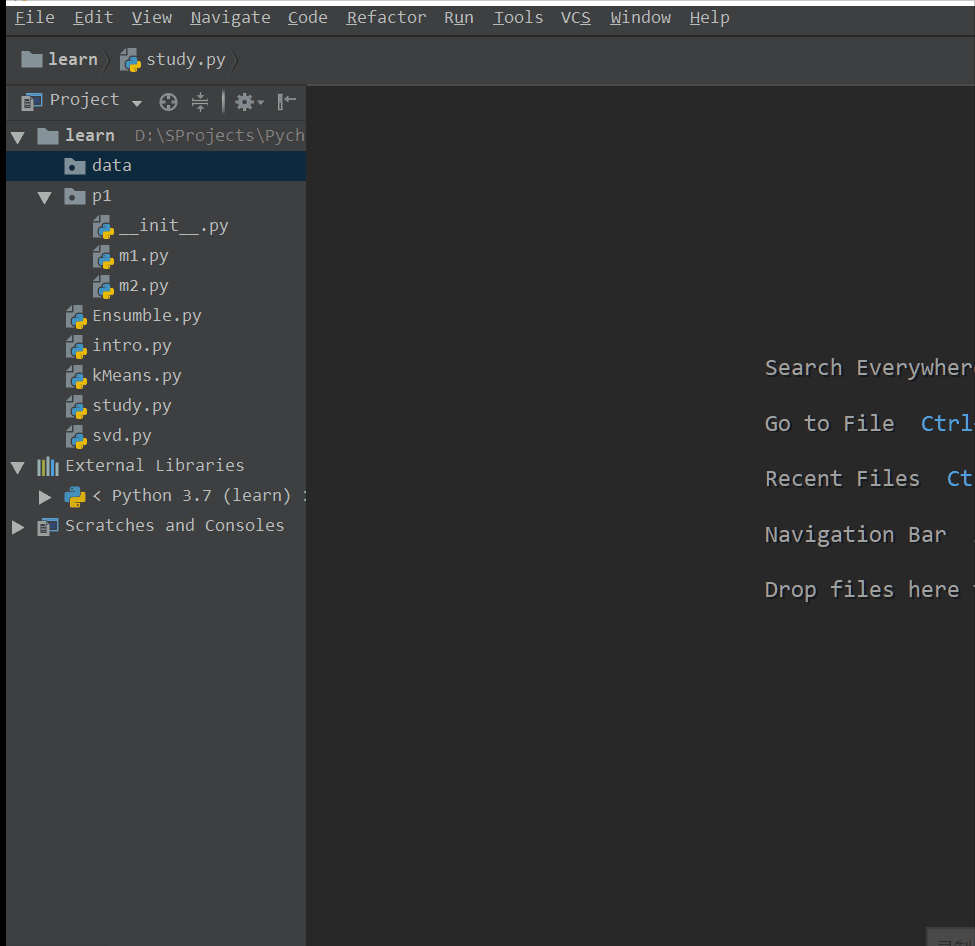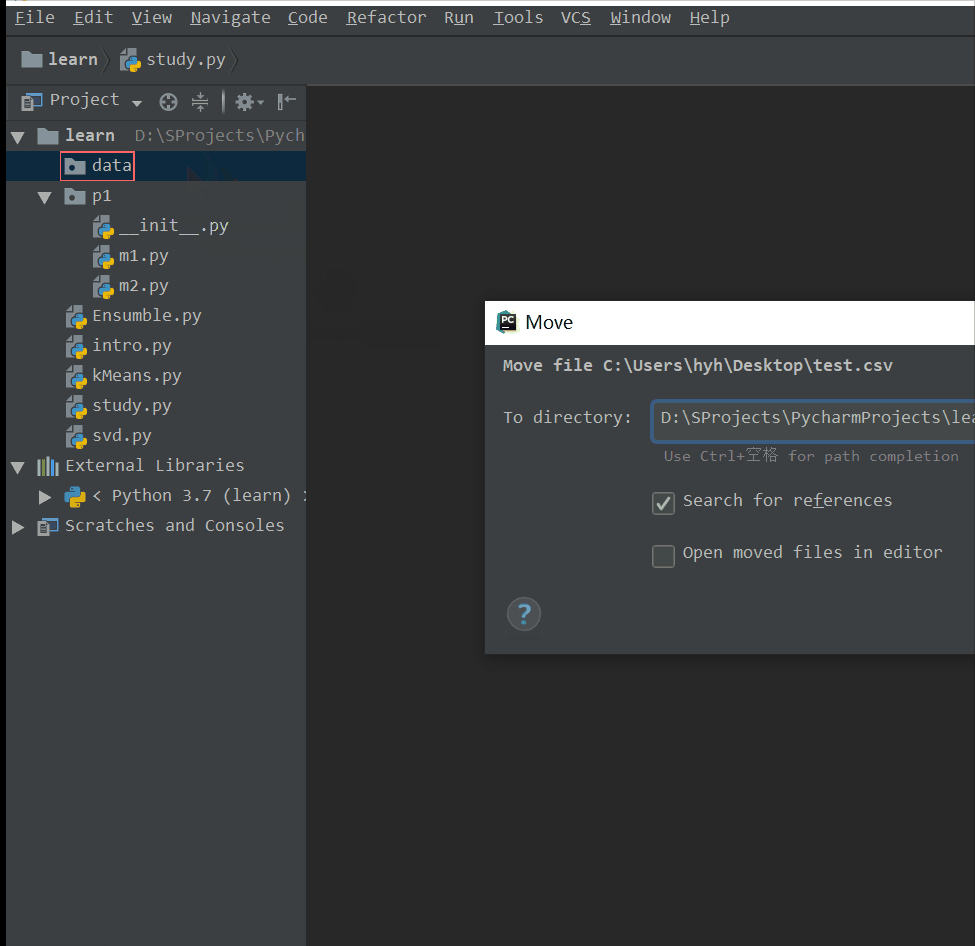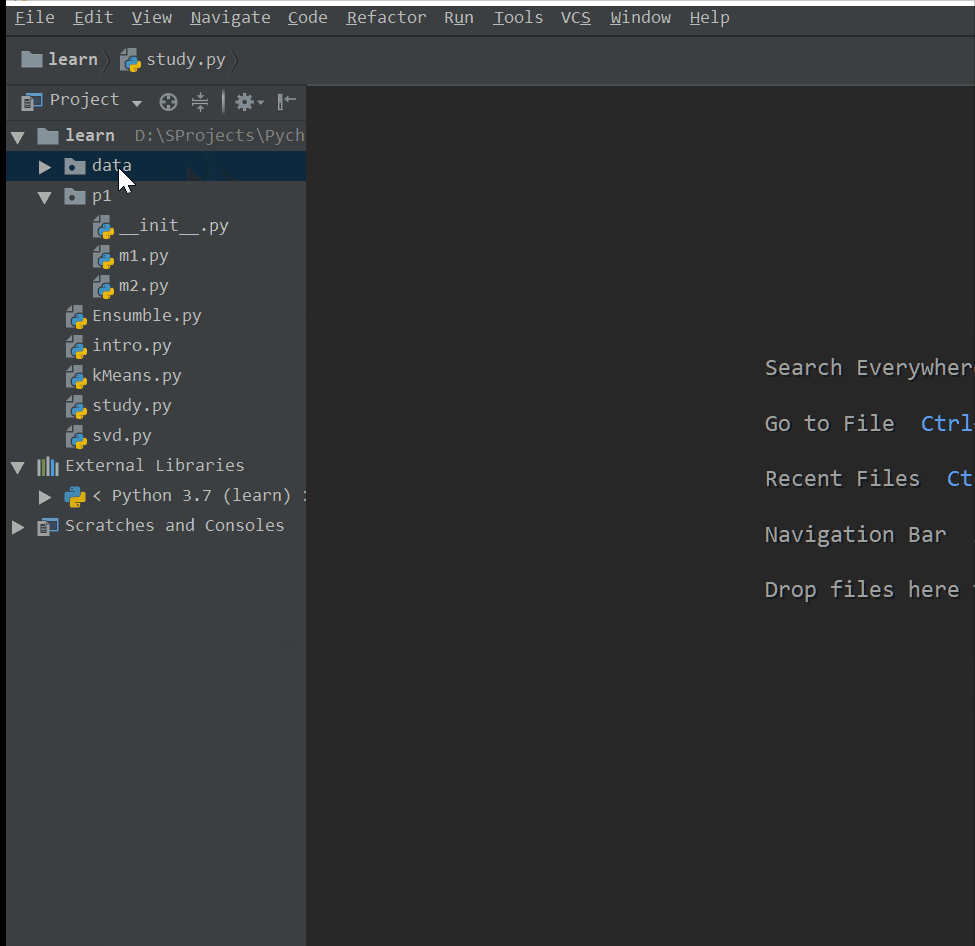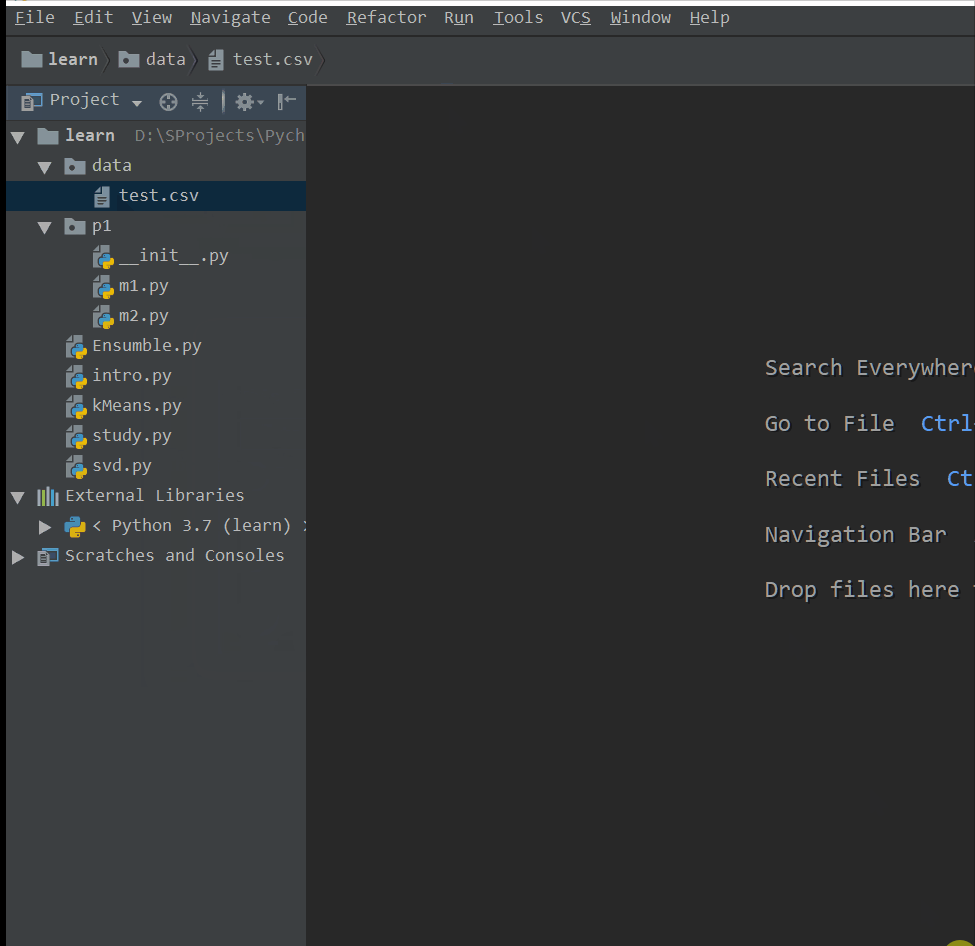
1)建立目录data
2)将上面5.2节我们建的test.csv文件拖进来
study.py中使用test.csv文件
import csv
import os
# 写csv文件
def write_csv(file_path, content): # content是一个数组
with open(file_path, 'a', encoding='utf8', newline='') as f:
obj = csv.writer(f)
obj.writerow(content)
# 读csv文件
# 注意一下文件内容返回的方式!
def read_csv(file_path):
result = [] # 用来存放csv文件中的每一行内容
with open(file_path, 'r', encoding='utf8') as f:
obj = csv.reader(f)
for i in obj:
result.append(i)
return result
if __name__ == "__main__":
# 方式一
path = os.getcwd() # 获取当前执行文件的绝对路径
result = read_csv(path + '/data/test.csv')
print(result)
# 方式二
# path2 = os.path.abspath('.') # 获取当前执行文件的绝对路径
# result = read_csv(path2 + '/data/test.csv')
# print(result)


6. 面向对象
6.1 简介
面向过程(Procedure Oriented,简称PO):就是分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现,使用的时候一个一个依次调用就可以了。==
面向对象(Object Oriented,简称OO):把构成问题的事务分解成各个对象,建立对象的目的不是为了完成一个步骤,而是为了描述某个事务在整个解决问题的步骤中的行为。
类:是对现实生活中一类具有共同特征的事物的抽象;类是属性和方法的集合。
对象:类的实例化可以得到一个对象,对象就具备了类的属性和方法。
属性:对象的属性特征。
方法:对象所具有的能力动作。
面向对象的三大特征:封装、继承、多态。
6.2 封装
隐藏对象的属性和实现细节,仅对外公开接口,控制在程序中属性的读取和修改的访问级别。
将数据和操作封装为一个有机的整体,由于类中私有成员都是隐藏的,只向外部提供有限的接口,所以能够保证内部的高内聚性和与外部的低耦合性。使用者不必了解具体的实现细节,而只是通过外部接口,以特定的访问权限来使用类的成员,能够增强安全性和简化编程。
eg:
# 定义类Person
# 私有化的属性和方法,在类的外部不能访问,只能在类的内部方法访问
# 类内部,无论私有化或非私有化属性和方法,想在类的内部访问调用的话,必须使用关键字self
# 实例化类,自动执行构造方法和析构方法
# 两个下划线__,表示私有化属性、方法
class Person:
# id = ''
# name = ''
# __password = '' # 私有化属性 __属性名
# age = 18
def __init__(self, p_id, name, age, password): # 构造方法:类的内置方法,通常用来初始化一些对象,调用类的自定义方法之前运行一次
self.p_id = p_id
self.name = name
self.age = age
self.__password = password
print(self.p_id, "构造方法")
def study(self): # 这个 def 方法名(self) 是固定格式
print('study')
def sleep(self):
print('sleep')
def __job(self): # 私有化方法 __方法名
print('job')
def info(self): # 私有化方法 __方法名
print('name:%s age:%s' % (self.name, self.age))
self.study()
self.__job() # 私有化的方法,只能在类的内部方法访问
def set_password(self, new_password):
self.__password = new_password # 私有化的属性,只能在类的内部方法访问
def __set__info(self, name, age): # 私有化方法 __方法名
self.name = name
self.age = age
def __del__(self): # 析构方法:类的内置方法,通常用来回收对象,释放资源,调用类的自定义方法之后运行一次
print(self.p_id, "析构方法")
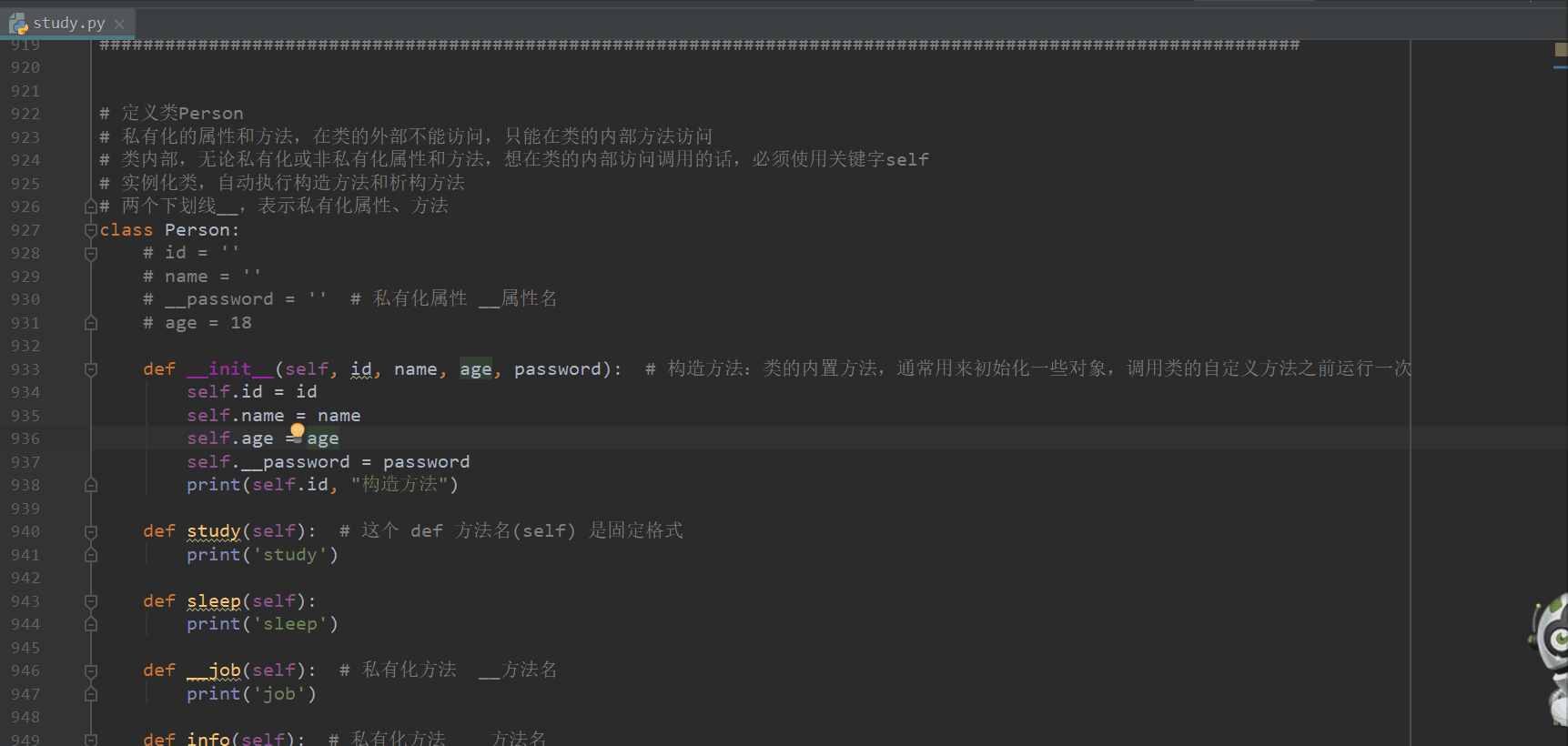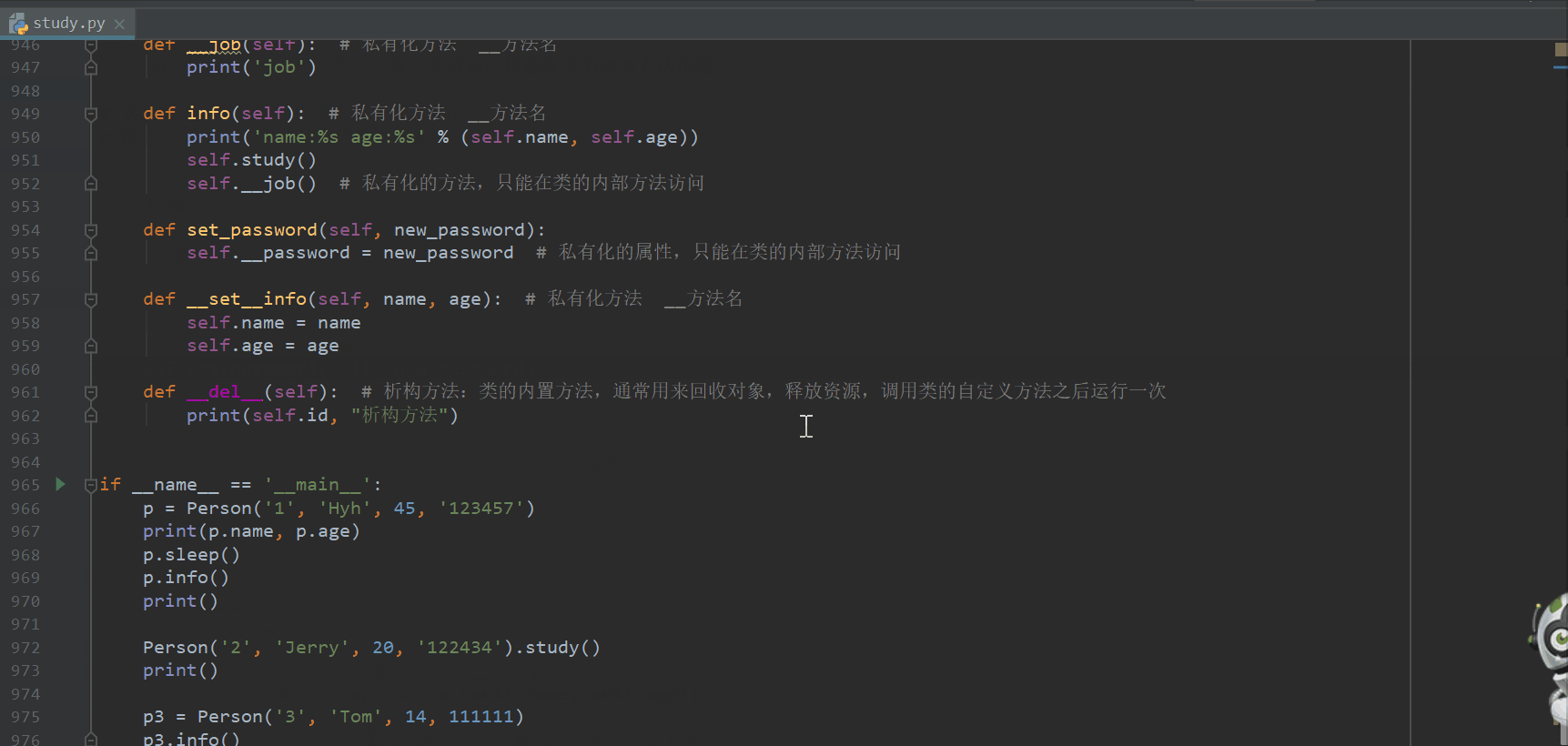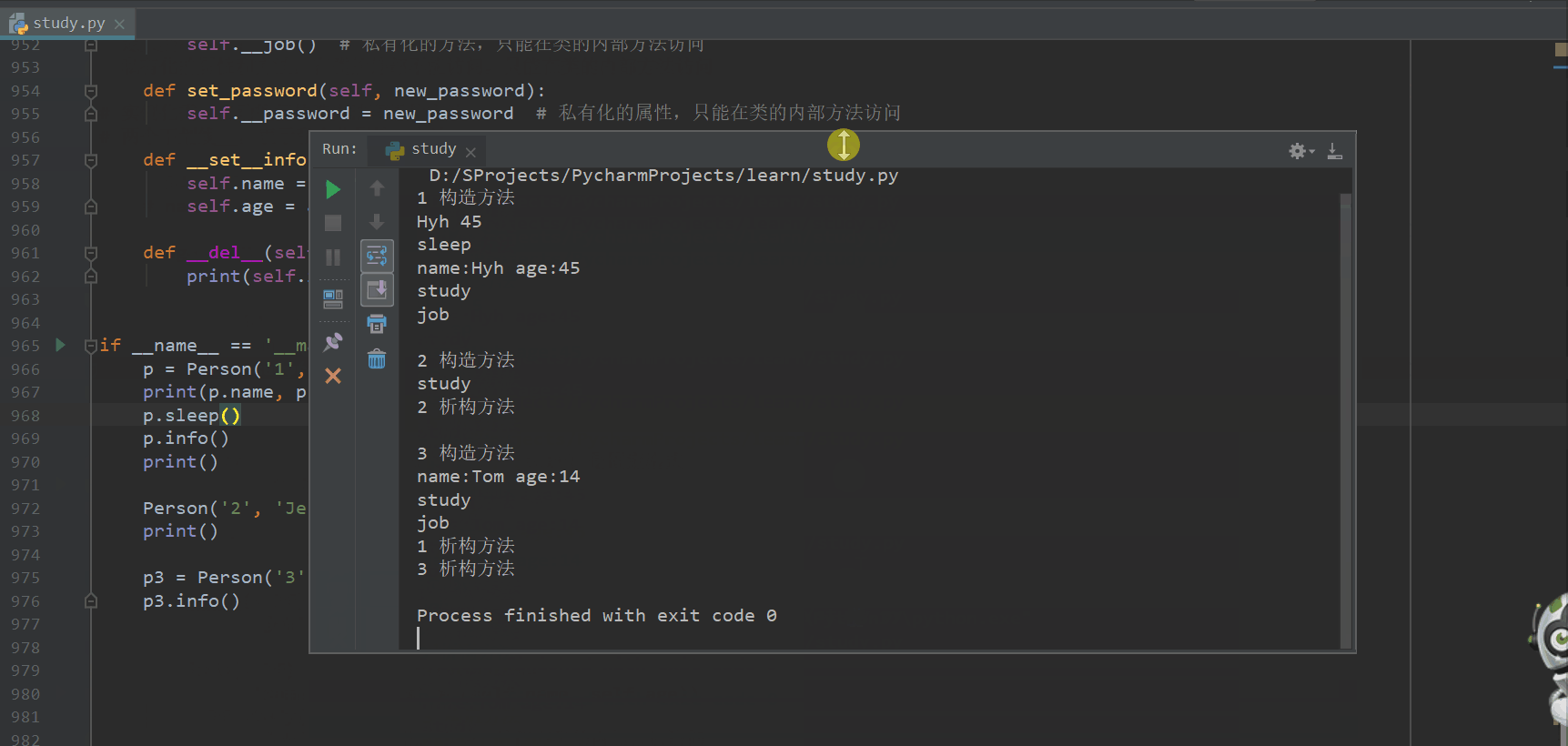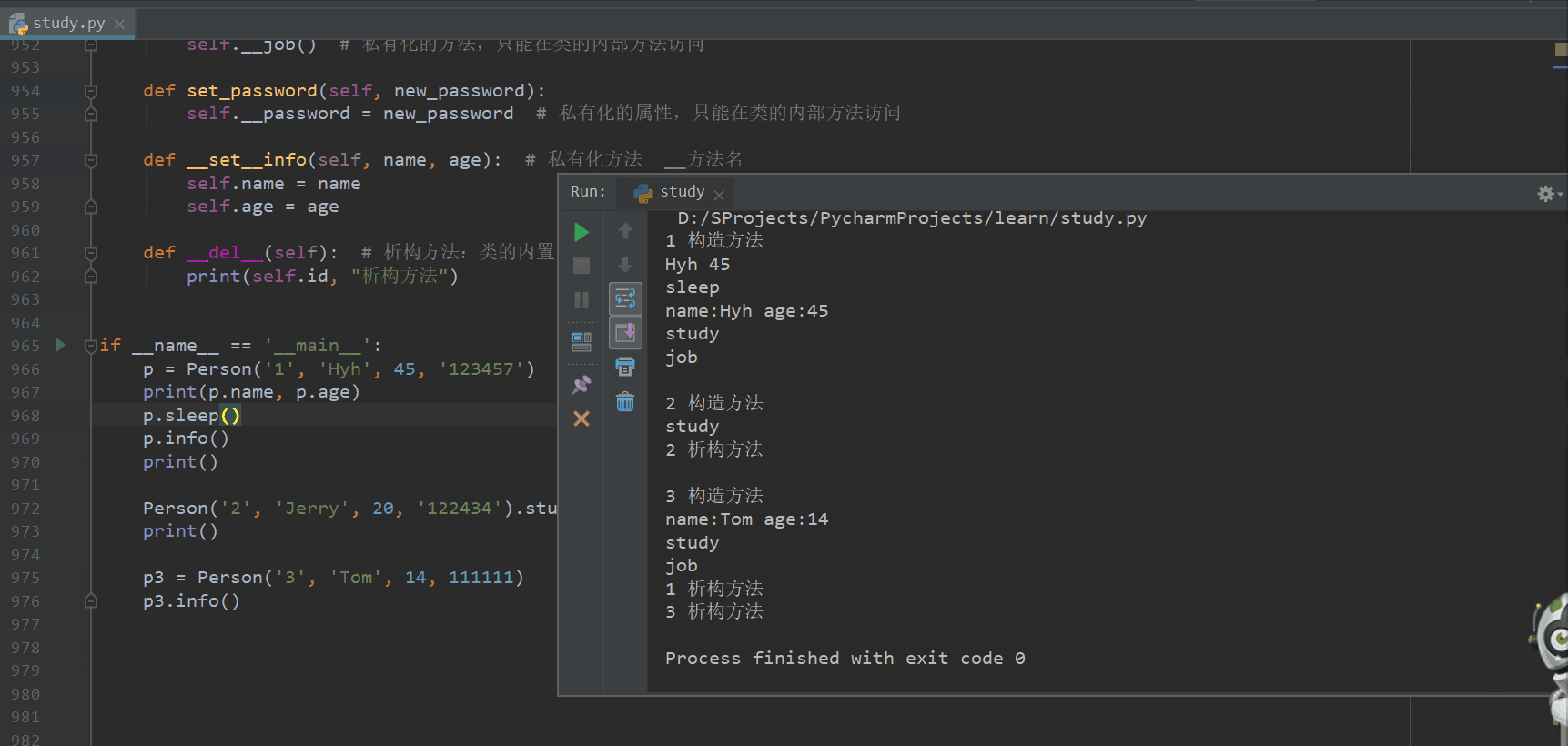
if __name__ == '__main__':
p = Person('1', 'Hyh', 45, '123457')
print(p.name, p.age)
p.sleep()
p.info()
print()
Person('2', 'Jerry', 20, '122434').study()
print()
p3 = Person('3', 'Tom', 14, 111111)
p3.info()
6.3 继承
继承是通过扩展已有的类,并继承该类的属性和行为,来创建一个新的类。
1)继承更符合认知规律,使程序更易于理解,同时省略不必要的重复代码,类和类之间才能继承。
2)子类又称派生类,或者衍生类。
3)父类又称基类,或者超类。
4)子类继承的父类的属性和方法,可以直接拿过来用。
5)python支持多继承,调用顺序:先深度(纵向)再广度(横向)的原则。
6)如果只是想使用一个类的部分方法,并不推荐继承这种方式,建议导包使用。
7)父类一定要定义在子类的前面。
eg:
# 重写:如果父类方法不能满足子类的需求,在子类中可重新定义同名的父类方法,也叫重写
class GrandFather:
def __init__(self, gf_id, name):
self.gf_id = gf_id
self.name = name
print(self.gf_id, "GrandFather构造方法")
def money(self):
print("GrandFather花钱")
def __del__(self):
print(self.gf_id, "GrandFather析构方法")
# 对于Son类是父类,对于GrandFather是子类
class Father(GrandFather):
def __init__(self, gf_id, name, job):
super().__init__(gf_id, name)
self.job = job
print(self.gf_id, "Father构造方法")
def sports(self):
print(self.name, "Father在锻炼")
def eat(self):
print(self.name, "Father在吃饭")
def money(self):
super().money() # 调用父类的money()方法
print("Father花钱")
def __del__(self):
print(self.gf_id, "Father析构方法")
# 对于Son类是父类
class Father2:
def __init__(self, tel):
self.tel = tel
print("Father2构造方法")
def relax(self):
print("Father2在休息")
def money(self):
print("Father2花钱")
def __del__(self):
print("Father2析构方法")
# 子类
class Son(Father, Father2): # 子类Son继承父类Father,Father2,python支持多继承,多重继承和多继承要区分开,很多语言都支持多重继承
def __init__(self, gf_id, name, age, job):
super().__init__(gf_id, name, job)
self.age = age
print(self.gf_id, "Son构造方法")
# def money(self):
# print("Son花钱")
def sports(self):
print(self.name, "Son在锻炼")
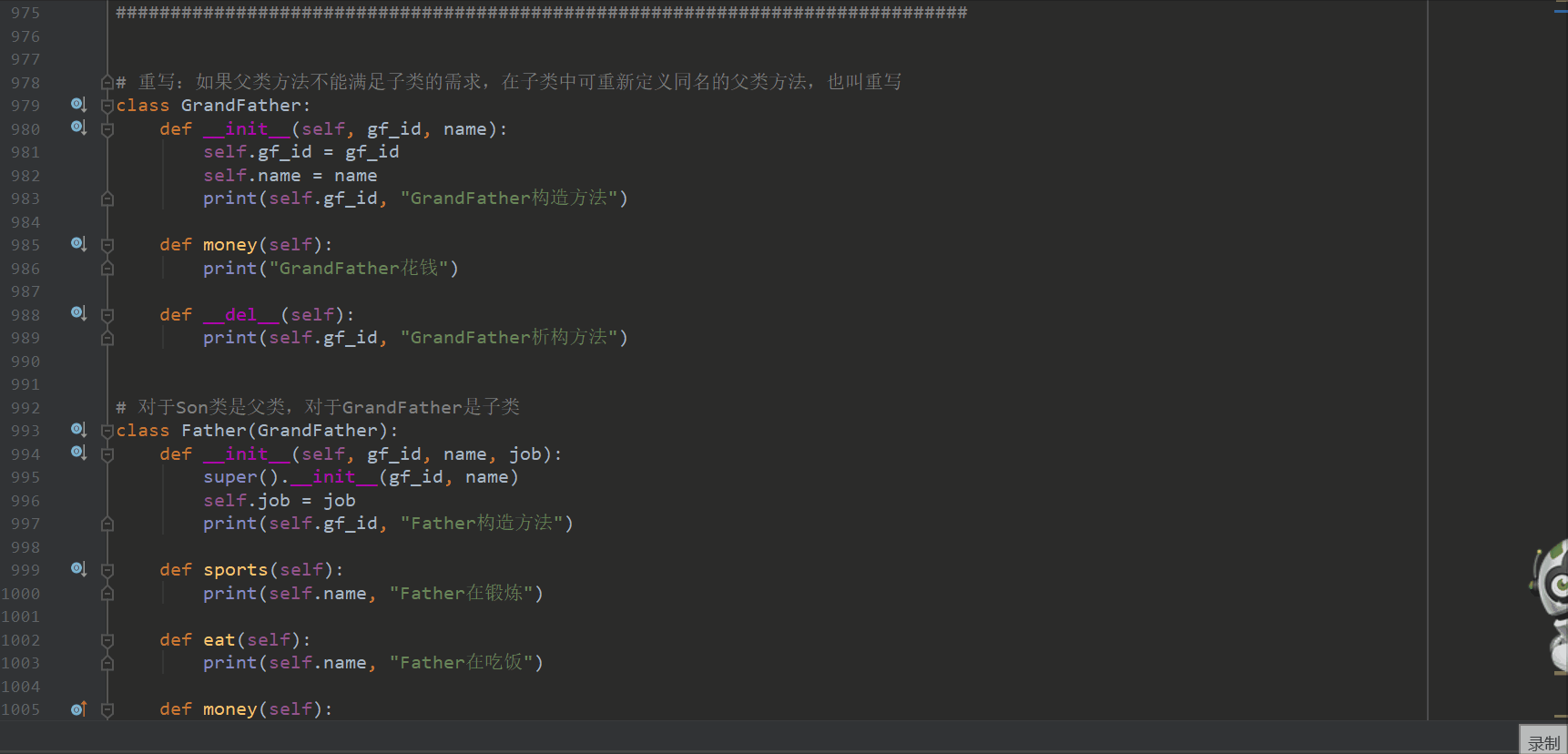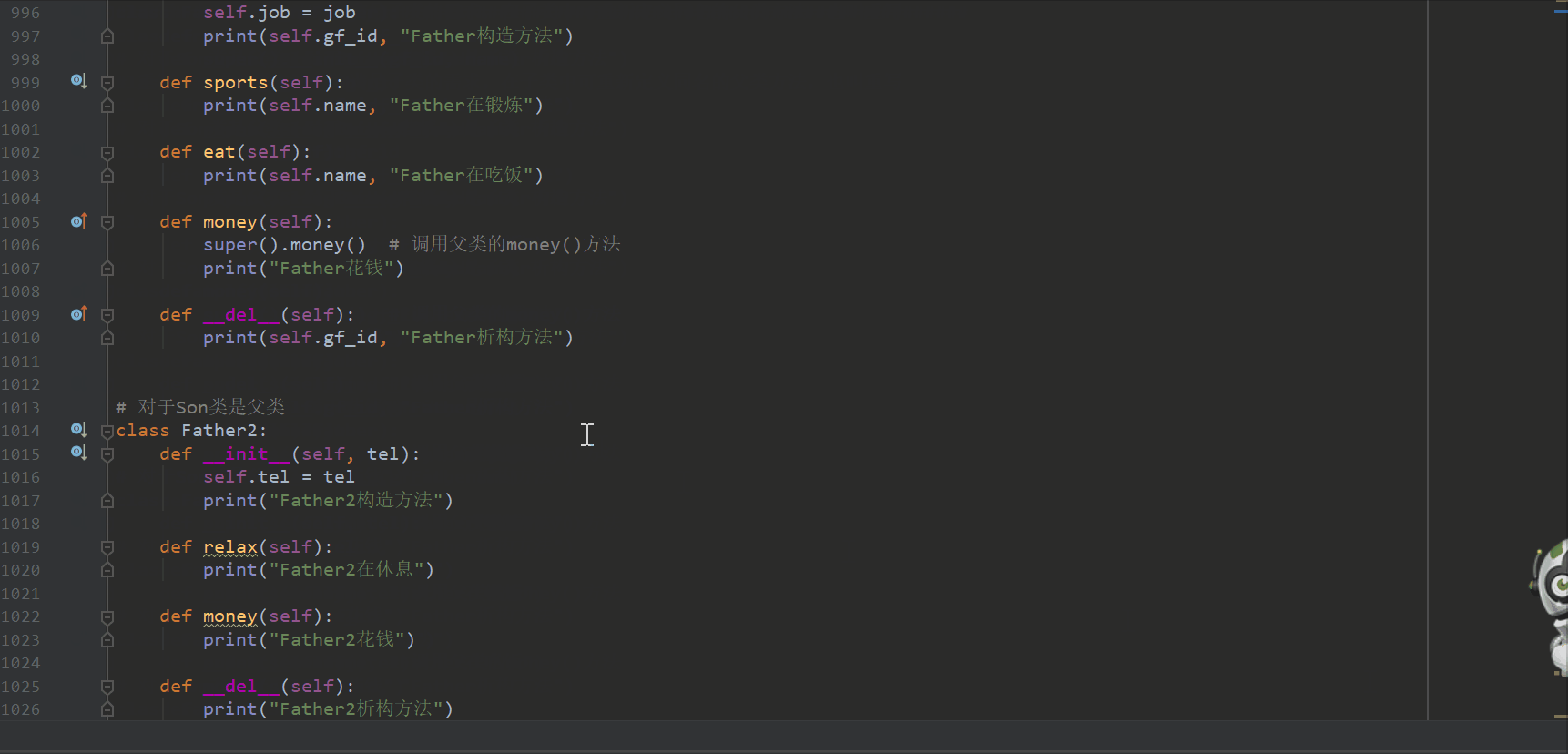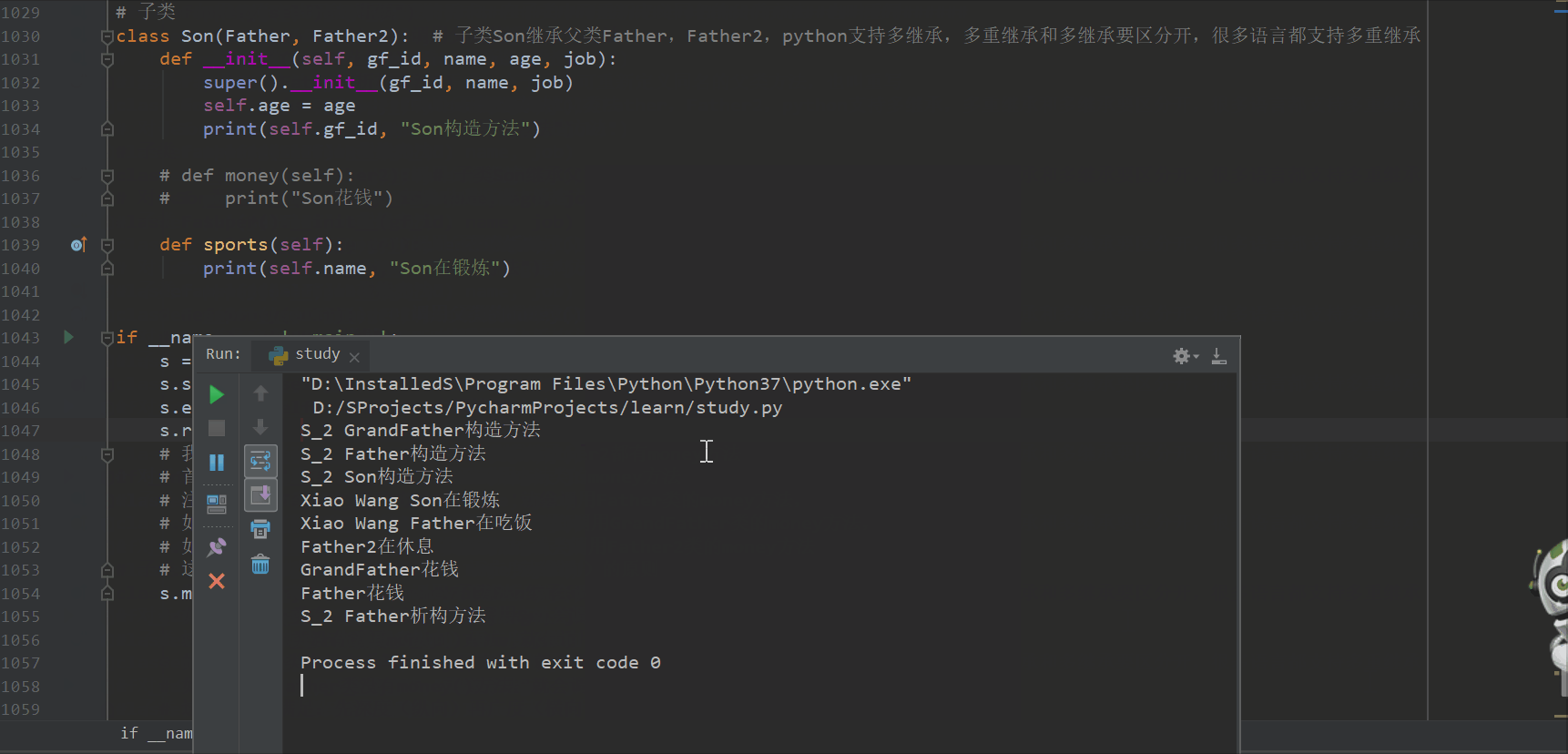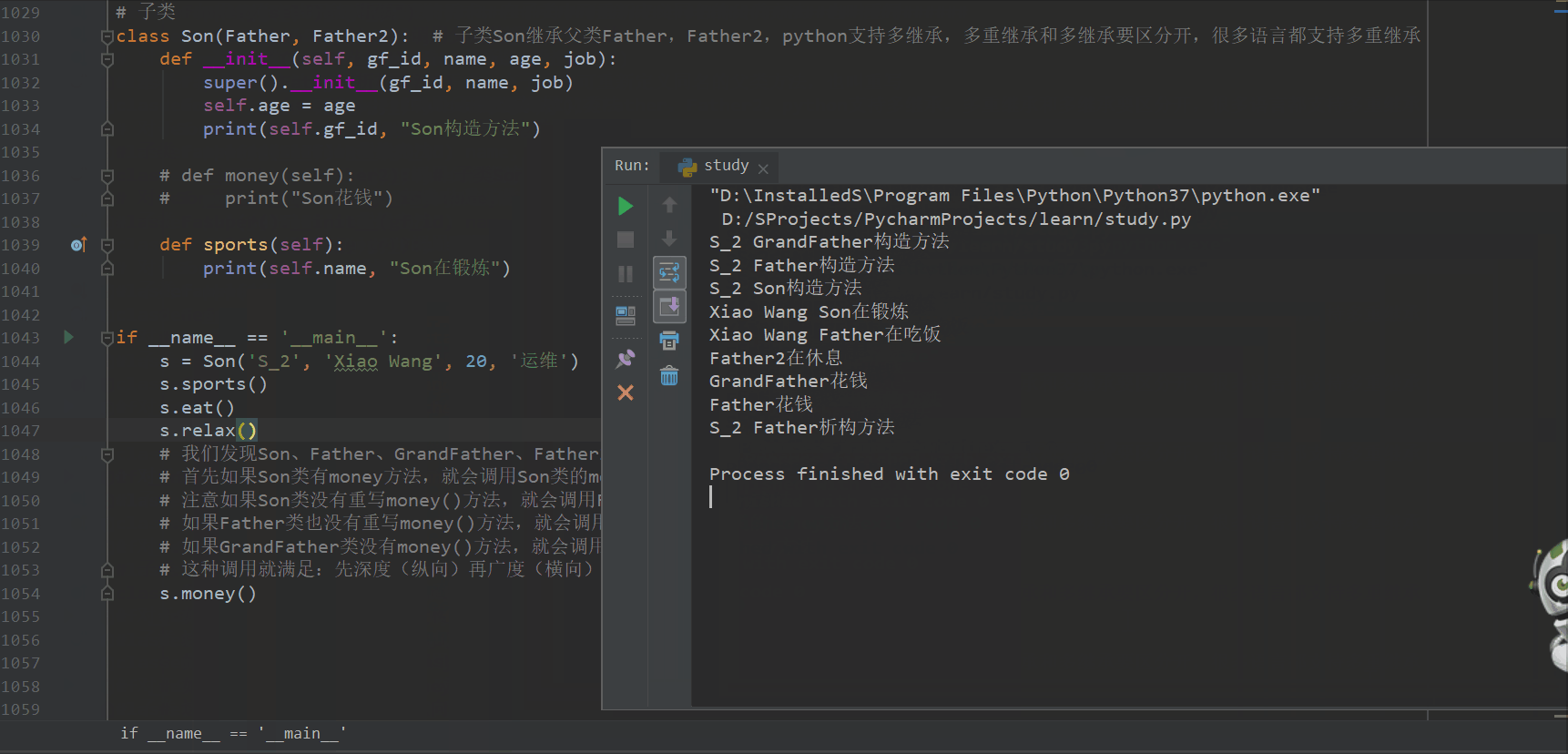
if __name__ == '__main__':
s = Son('S_2', 'Xiao Wang', 20, '运维')
s.sports()
s.eat()
s.relax()
# 我们发现Son、Father、GrandFather、Father2都有money方法
# 首先如果Son类有money方法,就会调用Son类的money方法
# 注意如果Son类没有重写money()方法,就会调用Father类的money方法,
# 如果Father类也没有重写money()方法,就会调用GrandFather类的money方法,
# 如果GrandFather类没有money()方法,就会调用Father2类的money方法
# 这种调用就满足:先深度(纵向)再广度(横向)的原则
s.money()
6.4 多态
接口的多种不同的实现方式即为多态。
同一操作作用于不同对象,可以有不同的解释,产生不同的执行结果,让具有不同功能的方法可以使用相同的名字,这样就可以同一个名字调用不同的内容(功能)的方法。
要和C++和Java的区分开,C++和Java的多态的前提都是三个,而Python是两个
python多态的条件:
继承:多态一定是发生在子类和父类之间;
重写:子类重写了父类的方法。
eg:
# 多态的前提:1.继承、2.方法重写
class A:
def study(self):
print("A:study")
class B(A):
def study(self):
print("B:study")
class C(A):
def study(self):
print("C:study")
if __name__ == "__main__":
def method(obj):
obj.study()
# 多态:调用相同名称的方法,传入不同对象,展现出不同的结果
method(A())
method(B())
method(C())

7. 异常处理
7.1 错误和异常
错误:一般指代码中的语法错误。
异常:即使Python程序的语法都是正确的,在运行它的时候,也会发生错误,运行期间检测到的错误被称为异常,大多数异常都不会被程序处理,都以错误信息的形式出现;异常以不同的类型出现,这些类型都作为信息的一部分打印出来,常见的异常类型,比如:ZeroDivisionError,NameError和TypeError。
出现了异常,后面的语句就不会执行了。
eg:
# ZeroDivisionError
print(1/0)
# NameError
name
print(name)
# TypeError
print(1 + 'hyh')
7.2 异常捕获
7.2.1 异常处理
要想代码出现异常后,仍然继续执行,就要使用异常捕获。
try:认为有异常的代码块放到try子句中。
except:try中代码块有异常时,才会执行。
else:try中代码块没有异常时,才会执行。
finally:不管有没有异常都会执行
1)except语句不是必须的,finally语句也不是必须的,但是二者必须要有一个,否则就没有try的意义了。
2)except语句可以有多个,python会按照except语句的顺序一次匹配你指定的异常,如果异常已经处理就不会进入后面的except语句。
3)except语句可以以元组形式同时指定多个异常
4)except语句如果不指定异常类型,则默认捕获所有类型,你可以通过sys模块获取当前所有捕获的异常
5)如果要捕获异常后,重新抛出,使用raise
6)不建议捕获一个异常后,不做处理,你又继续抛出这个异常,这样做的意义不大,考虑重构代码。
7)不建议在不清楚的情况下捕获所有异常,而你将它们全部捕获,有可能你的代码中会隐藏很严重的问题。
格式:
try:
代码块(可能会出现异常)
except Exception as e:
异常处理(代码块有异常)
else:
无异常处理(代码块无异常)
finally:
不管有没有异常都会执行
如:
try:
print(1/0)
except Exception as e:
print(e)
else: # 因为try里的代码块有异常,所以else里的语句不执行
print('无异常处理...')
finally:
print('...........')
eg:
方式一:分别捕获异常,不推荐
# 方式一:分别捕获异常,不推荐
try:
print(1/0)
print(name)
print(1 + 'hyh')
except ZeroDivisionError as e:
print(e)
except NameError as e:
print(e)
except TypeError as e:
print(e)
方式二:同时捕获指定的多个异常,不推荐
# 方式二:同时捕获指定的多个异常,不推荐
try:
print(1/0)
print(name)
print(1 + 'hyh')
except (ZeroDivisionError, NameError, TypeError) as e:
print(e)
方式三:捕获所有已知和未知的异常信息,不推荐,因为这种捕获方式会隐藏更深层次的问题
# 方式三:捕获所有已知和未知的异常信息,不推荐,因为这种捕获方式会隐藏更深层次的问题
import sys
try:
print(1/0)
print(name)
print(1 + 'hyh')
except:
print(sys.exc_info())
方式四:捕获所有已知异常,推荐
# 方式四:捕获所有已知异常,推荐
try:
print(1/0)
print(name)
print(1 + 'hyh')
except Exception as e:
print(e)
# 通常处理异常,会调用写好的截图和写日志的方法
# pass 也可以不打印异常信息,直接跳过处理
7.2.2 自定义异常
eg:
# 但一般下面这种情况不使用异常处理,这里只是为了举一个例子
# 循环打印1~10,等于5的时候不打印(等于5时作为异常处理)
for i in range(1, 11):
if i == 5:
try:
raise Exception("等于5了") # raise用于继续抛出异常
except Exception as e:
print(e)
# 或 continue
# 或 pass
else:
print(i, "", end="")
















 535
535











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









