






持续更新…
自动化测试
- 0. 前言
- 1. 自动化测试
- 2. Selenium测试集成开发工具
- 2.1 Selenium概述
- 2.2 Selenium组成
- 2.3 Selenium测试环境搭建
- 2.4 搭建第一个工程
- 2.5 一个完整的测试用例
- 2.6 katalon
- 2.7 Selenium测试环境搭建
- 2.8 WebDriver API
- 2.8.1 页面元素定位
- 2.8.1.1 id定位 `find_element_by_id("id属性值")`
- 2.8.1.2 name定位 `find_element_by_name("name属性值")`
- 2.8.1.3 class name定位 `find_element_by_class_name("id值")`
- 2.8.1.4 tag name `find_element_by_tag_name("标签名")`
- 2.8.1.5 link text定位 `find_element_by_link_text("链接的显示文本")`
- 2.8.1.6 partial link text定位 `find_element_by_partical_link_text("部分链接的显示文本")`
- 2.8.1.7 xpath定位 `find_element_by_xpath("xpath")`
- 2.8.1.8 css定位 `find_element_by_css_selector("")`
- 2.8.2 页面元素操作
- 2.8.3 浏览器操作
- 2.8.4 多窗口操作、句柄操作
- 2.8.5 鼠标、键盘操作
- 2.8.6 警告窗口处理
- 2.8.7 多窗口、多表单处理
- 2.8.8 设置元素等待
技术线:python->selenium->unittest
技术点:python技术点
selenium:组成、api方法、线性、模块化等脚本开发。
unittest单元测试框架:测试用例(脚本中的用例)维护,执行和报告生产。
0. 前言
测试的直接目标:找出软件中潜在的各种缺陷和错误。
测试的商业目标:规避软件发布后由于各种潜在的软件缺陷和错误造成的商业风险。
投入产出比要求:投入最少的人力、物力和时间,找到尽可能多的问题。
1. 自动化测试
手工测试的局限性:
1)覆盖性:无法覆盖所有的代码路径。
2)时效性:短时间无法完成大量测试用例的执行工作。
3)重复性:回归测试具有一定的机械性、重复性、工作量往往比较大。
等…
自动化测试的优势:
1)对回归测试更方便。
2)测试具有一致性和可重复性,自动化的明显的好处是可以在较少的时间内运行更多的测试。
3)有效的利用人力物力资源,提高测试工作效率。
4)将繁琐重复任务自动化,可以提高准确性和测试人员的积极性,可以让测试人员专注于手工测试部分,提高手工测试的效率。
自动化测试的劣势:
1)自动化测试是工具执行,没有思维,无法进行主观判断,对界面色彩、布局和系统的崩溃现象无法发现,这些错误通过人眼很容易发现。
2)自动化测试工具本身是一个产品,在不同的系统平台或硬件平台可能会受影响,在运行时可能影响被测程序的测试结果。
3)对于需求变更频繁的软件,测试脚本的维护和设计比较困难。
4)自动化测试是机器执行,发现的问题比手工测试要少很多,通过测试工具没有发现缺陷,并不能说明系统不存在缺陷,只能通过工具评判测试结果和预期效果之间的差距。
5)自动化测试要编写测试脚本,设计场景,这些对测试人员的要求比较高,测试的设计直接影响测试的结果。
一般未稳定的软件版本不建议使用自动化测试,使用手工测试更合适,复杂的测试最好也由手工测试来完成,自动化测试主要是完成重复的测试任务。
自动化测试的核心目的:提高测试效率。
自动化测试的演变
自动化测试的演变史其实就是测试人员与繁琐测试工作的长期斗争史,是许多代测试人员智慧的结晶。
- 萌芽期:出于“偷懒”的想法,把一些重复性,简单,没有技术含量的工作交给代码完成。
- 发展期:以商业测试工具为代表,自动化测试模型4阶段进化出现,1.线性测试 2.模块化驱动测试 3.数据驱动测试 4.关键字驱动测试。
- 爆发期:随着移动互联网技术,Develops、敏捷、Docker等新理念技术的提出与应用,同时开源测试软件、开源测试框架也层出不穷,CI/CD(持续集成/持续开发)闭环成为趋势。
- 未来:Al-测试终结者。
1.1 自动化测试概述
自动化测试是把以人为驱动的测试行为转化为机器执行的一种过程,即模拟手工测试通过执行测试脚本自动地测试软件。
通常,在设计了自动化测试用例并通过评审之后,由测试人员根据测试用例中描述的步骤编写脚本并执行测试,得到实际结构与预期结果的比较。在此过程中,为了节省时间或硬件资源,提高测试效率,便引入了自动化测试的概念。
简单的说,自动化测试就是用程序(脚本)测试程序。
1.2 自动化测试工具
从所支持的系统架构上,目前可以划分为两大阵营:
1)支持C/S(Client/Server,客户端/服务器)和B/S(Browser/Server,浏览器/服务器)架构-uft
uft原名qtp,是做功能自动化测试的工具,商用的自动化测试工具,惠普开发。
2)只支持B/S架构-selenium
testbed:可做单元测试,集成测试,静态代码测试。输入数据,通过分析设计数据,录入工具testbed直接输出xxx类型(语句覆盖、条件覆盖等)的覆盖率。
selenium
从收费模式上,目前可以划分三大阵营:
1)商业化工具
2)开源工具
3)自主开发工具(一般由测试开发岗位开发,对测试工具进行二次开发)
web功能自动化测试工具Selenium(WebDriver),超过一半,其次是自主开发工具。
手工测试至少执行一轮,开发也对缺陷进行修复了,软件比较稳定了,这时候才满足自动化测试的条件。
1.3 自动化测试流程

自动化测试并不比手工测试高大上;自动化测试不是一劳永逸的;自动化测试只适合回归测试阶段;自动化测试的核心目的是提高测试效率,并不是为了发现bug;测试工具不是万能的;版本迭代越频繁,自动化测试效率越好。
2. Selenium测试集成开发工具
2.1 Selenium概述
Selenium是一个测试集成开发工具,是一款基于Web应用程序的开源测试工具,Selenium测试直接运行在浏览器中,就像真正的用户在操作一样,支持Firefox、IE、Chrome等众多浏览器,同时支持Java、C#、Ruby、Python、PHP、Perl、JS等众多主流语言。
selenium特点:
- 容易在页面上进行录制
- 自动通过id,name和xpath来定位页面元素
- 自动执行selenium命令
- 能够进行调试和设置断点
- 录制生成的脚本能够转换成各种语言(katalon recoder)
- 在每个录制的脚本中能够加入断言(用判断预期和实际结果是否一致的一种方法或技术)
2.2 Selenium组成
- selenium 1.0:selenium IDE,selenium rc,selenium grid
- selenium 2.0:selenium IDE,selenium rc,webdriver(由谷歌开发,代替rc的功能),selenium grid
- selenium 3.0:selenium IDE,selenium webdriver,selenium grid
| 工具 | 描述 |
|---|---|
| selenium IDE | selenium集成开发环境,可以让测试人员通过操作浏览器的操作来进行脚本录制,回放等功能。 |
| selenium RC(Remote Control) | selenium远程控制为第一代测试框架,它允许多个简单的浏览器动作和线性执行,它使用的编程语言,如java,C#,php,python和Ruby和Perl的强大功能来创建更复杂的测试。 |
| Webdriver | selenium的前身是selenium rc,可以直接发送命令给浏览器,并检索结果 |
| selenium Grid | 利用Grid可以在不同的主机建立主节点(hub)和分支节点(node),可以使主节点上的测试用例在不同的分支节点上运行;对于不同的节点来说,可以搭建不同的测试环境(操作系统、浏览器),从而使得一份测试用例可以在不同环境下的测试执行结果 |
selenium IDE:UI界面的脚本录制工具,但能够处理的逻辑有限,对于复杂的脚本来做处理起来比较麻烦。采用的是关键字驱动的方式进行脚本开发。
webdriver:包(各种模块),对浏览器的api(对浏览器中元素的操作),它慢慢替代掉rc的原因就是webdriver对浏览器的调度效率提高了好多。
2.3 Selenium测试环境搭建
我们可以在firefox或chrome,microsoft edge等浏览器上的安装扩展工具Selenium IDE来安装该扩展工具。
比如我在microsoft edge上安装的selenium ide扩展。



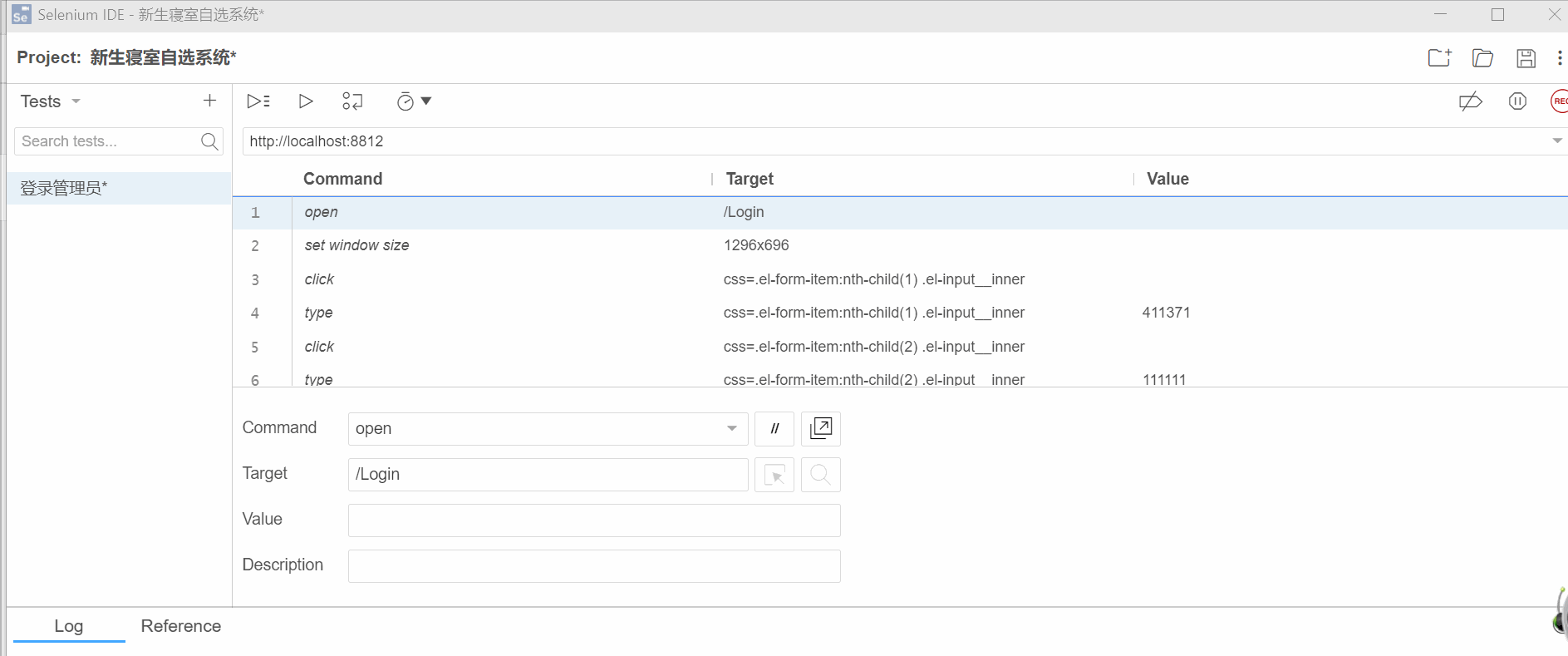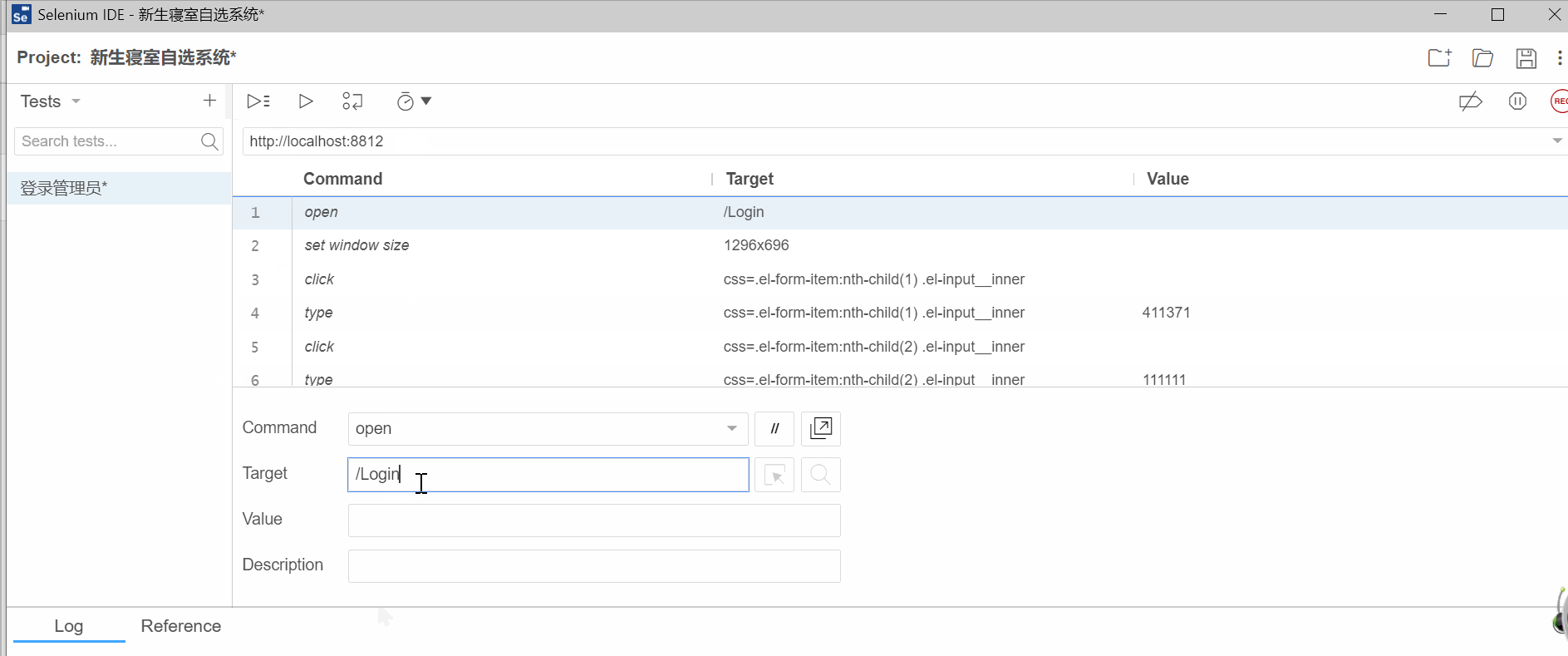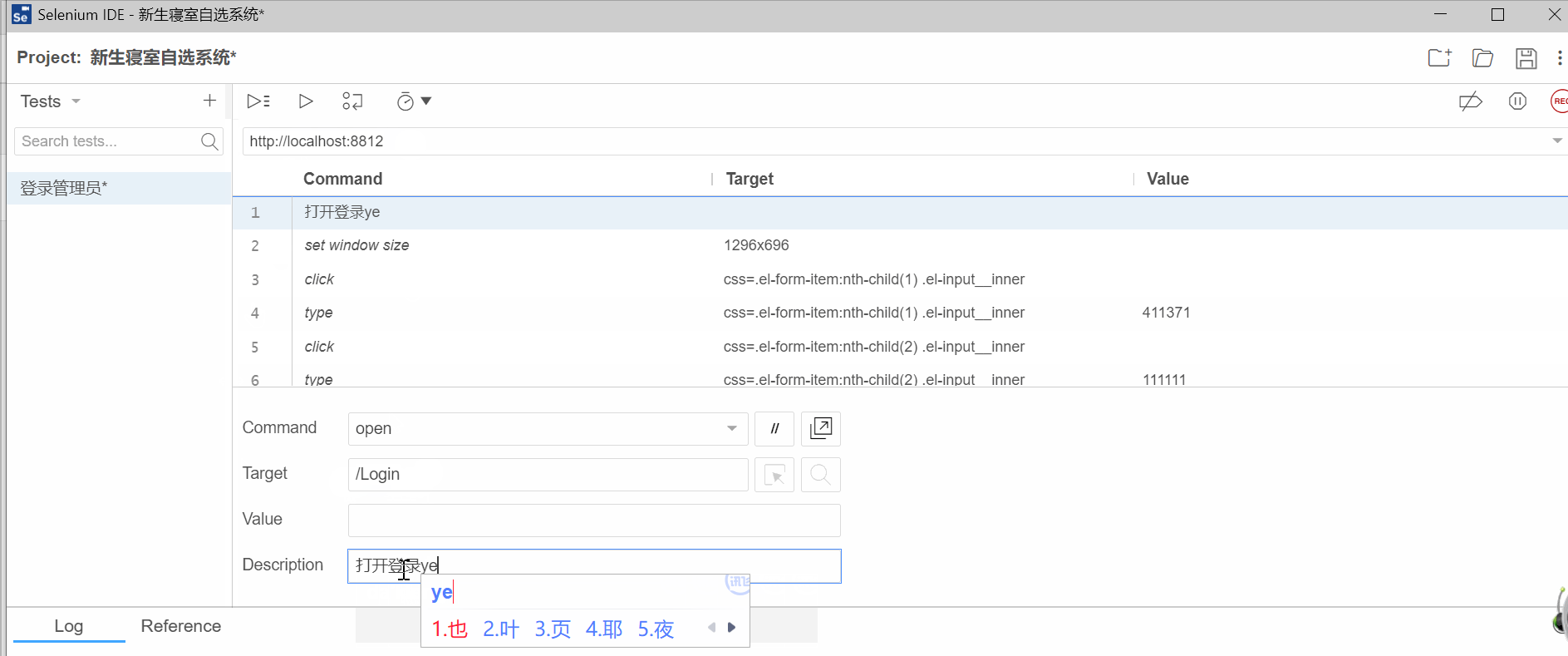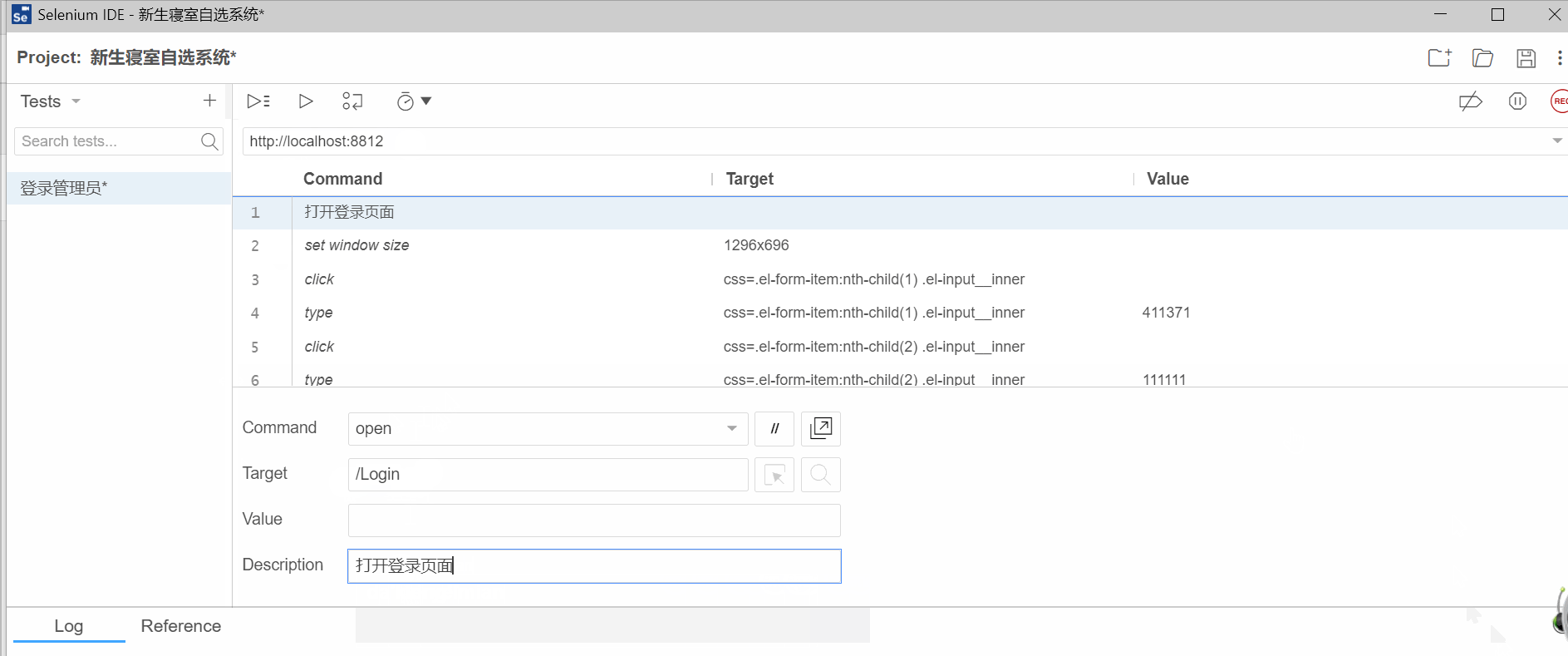
2.4 搭建第一个工程

Target:对谁进行操作,即对属性进行定位
command:找到后,要做什么
value:键入值
比如:http://localhost:8812是基地址,即base url
command:open,就会打开target中的地址:与基地址连接起来http://localhost:8812/Login
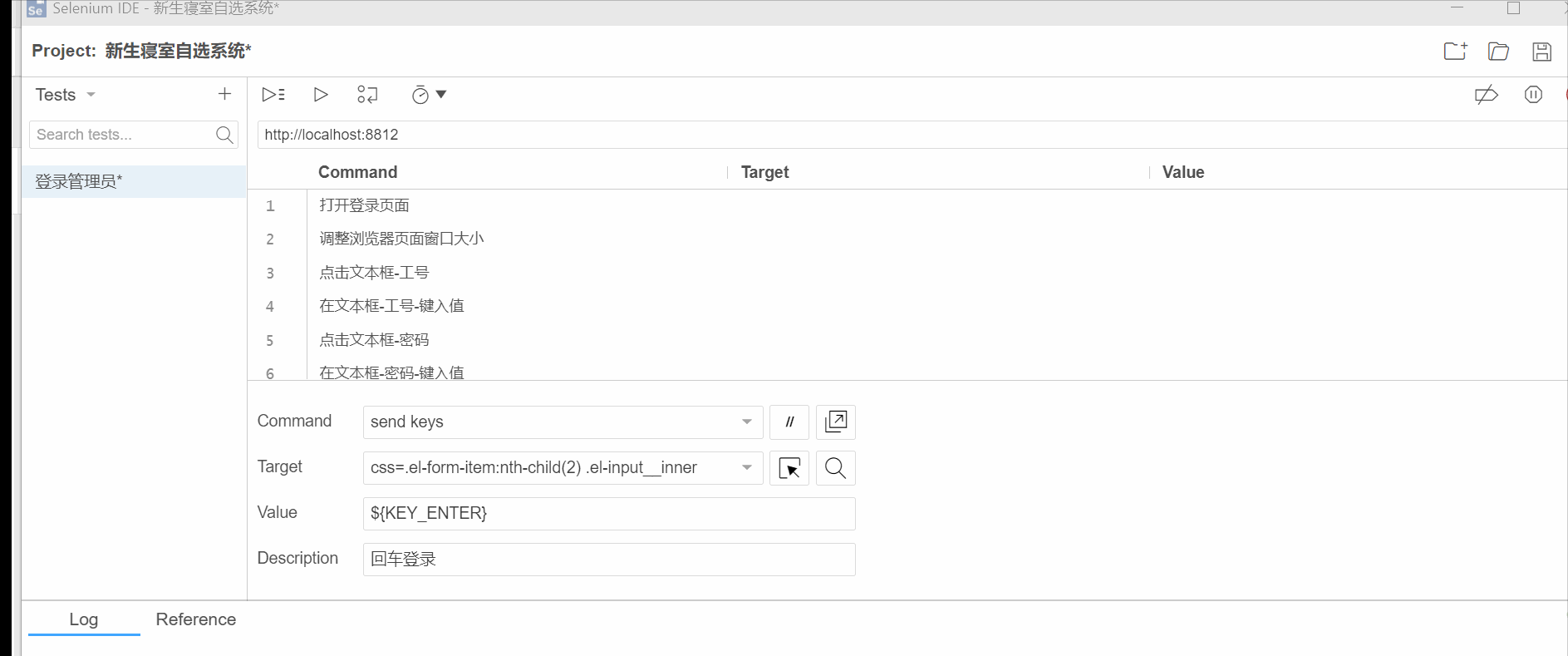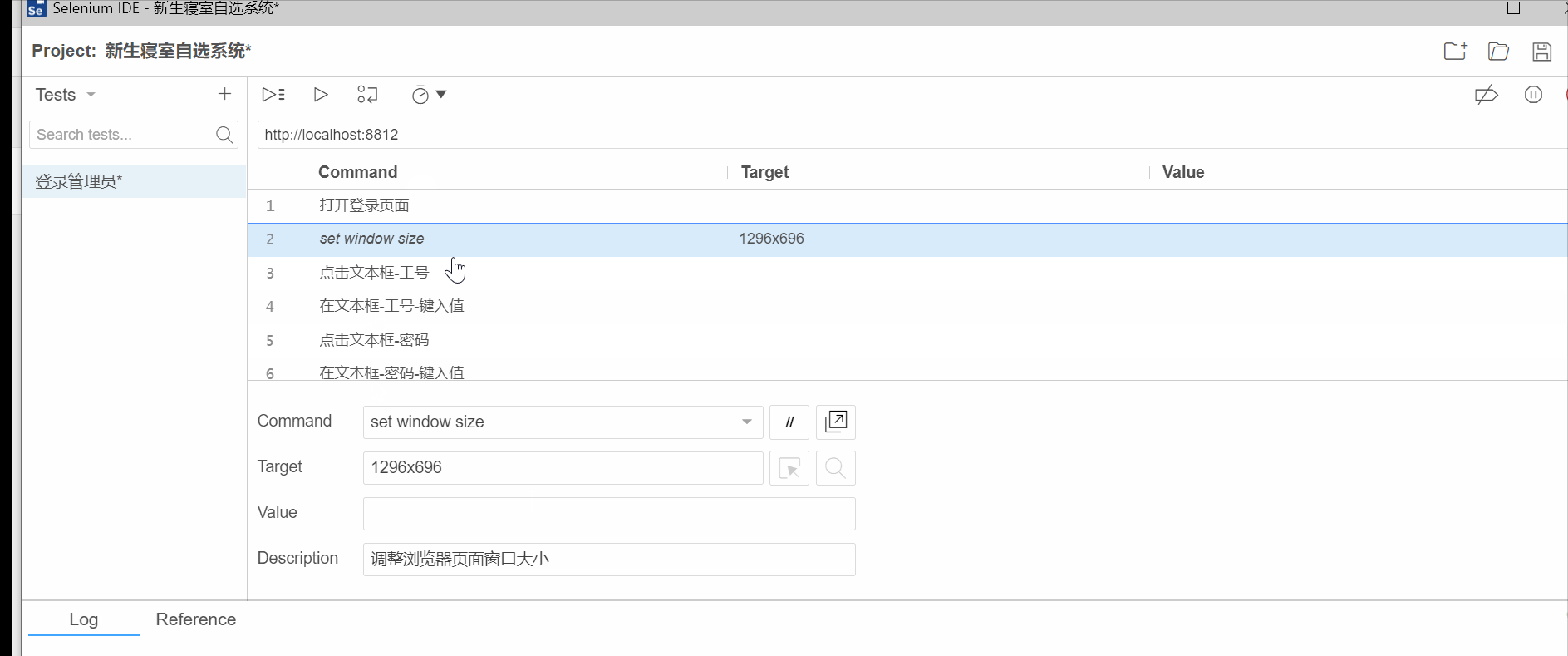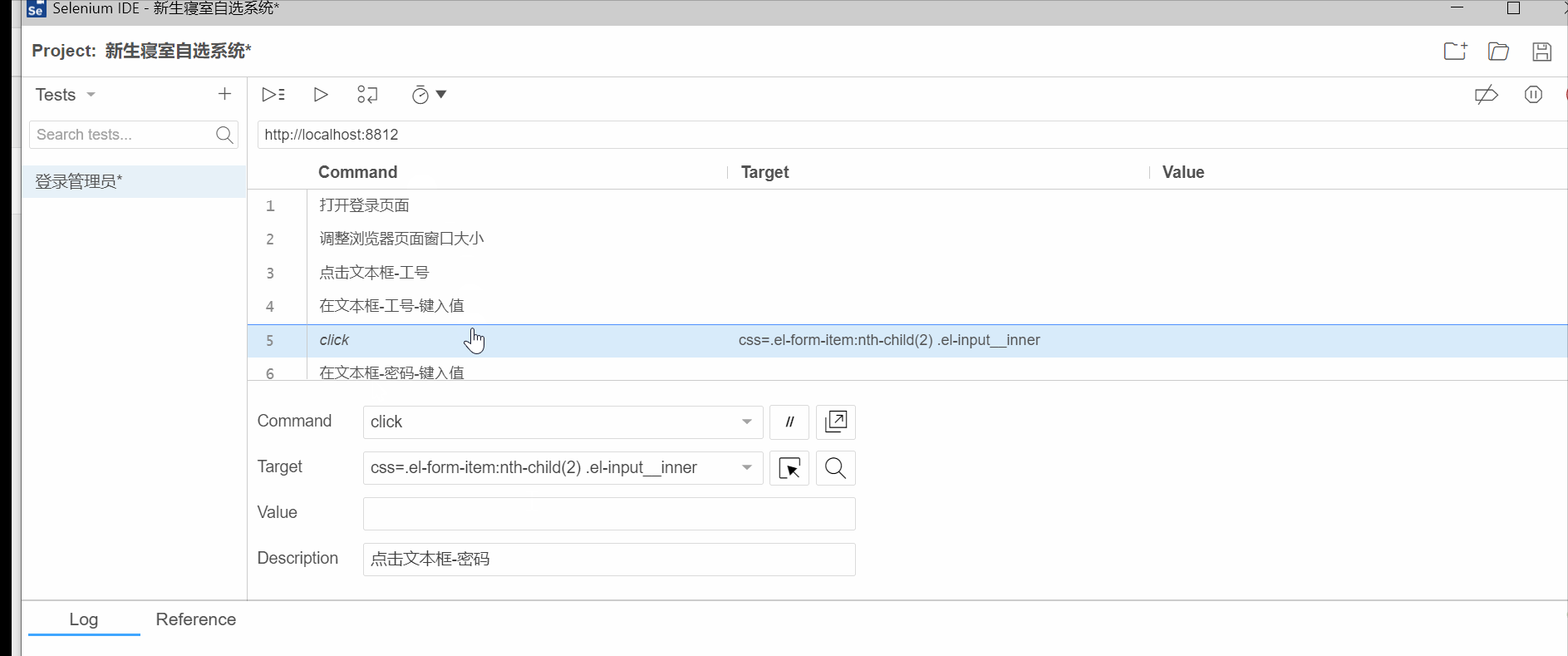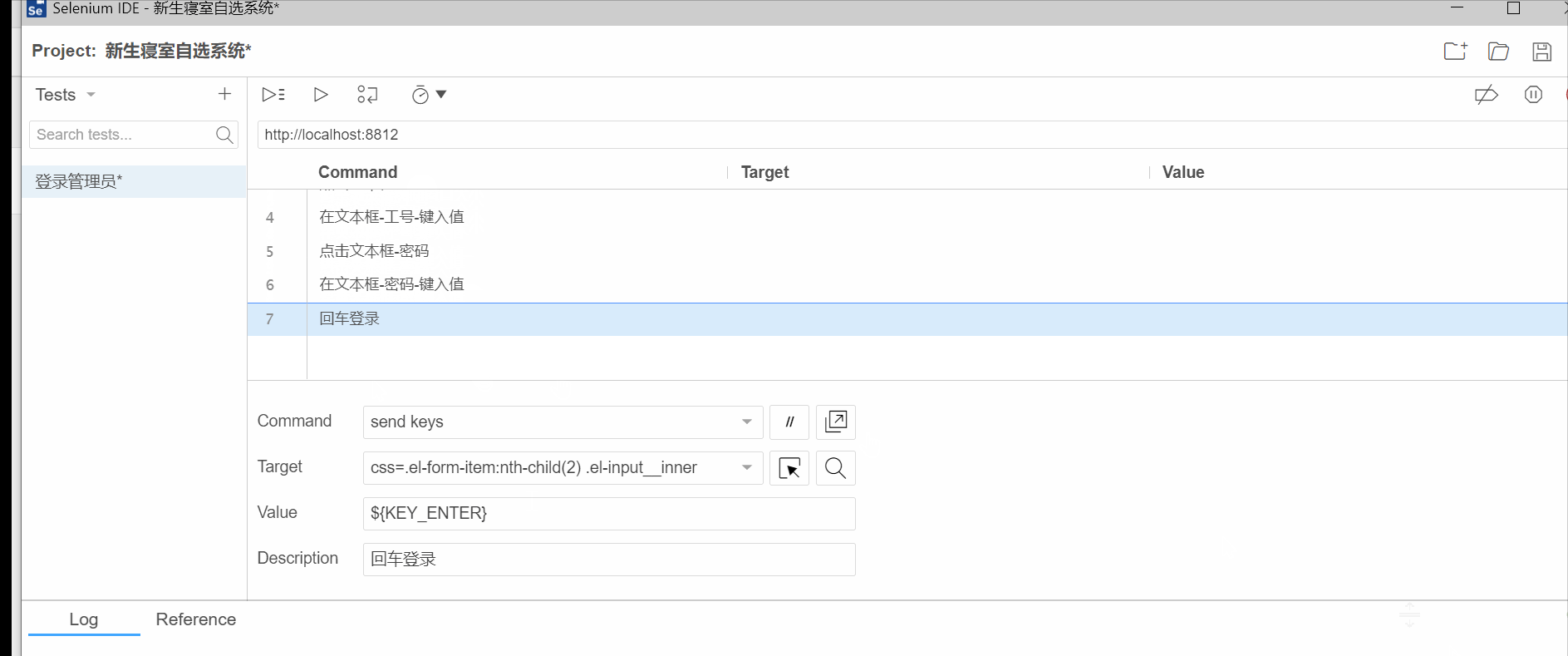
回放脚本

录制完之后,可以把不需要的步骤删除,比如调整窗口大小,点击文本框等。
删除后就留下4个步骤:

删除不必要的步骤后,回放脚本
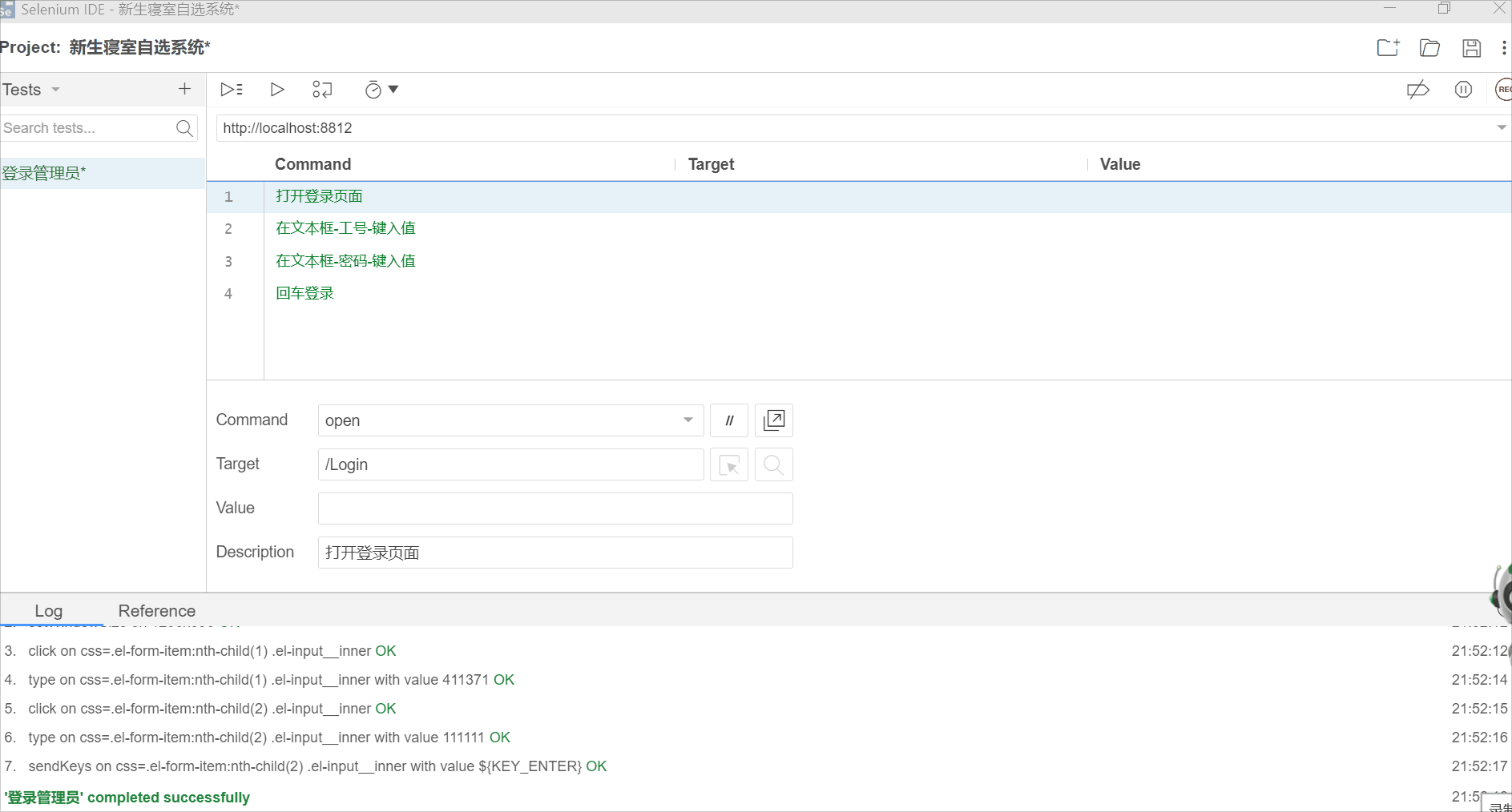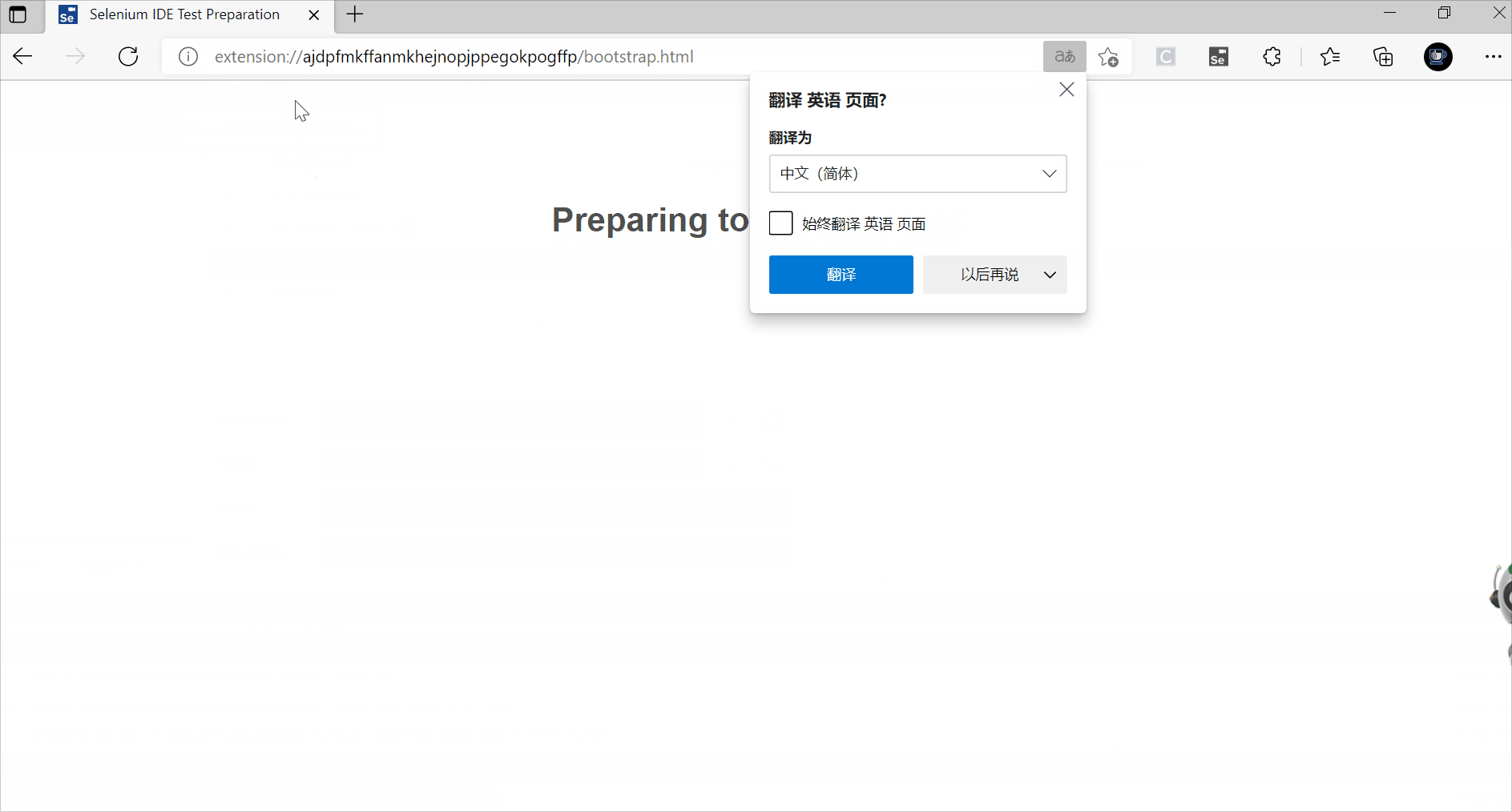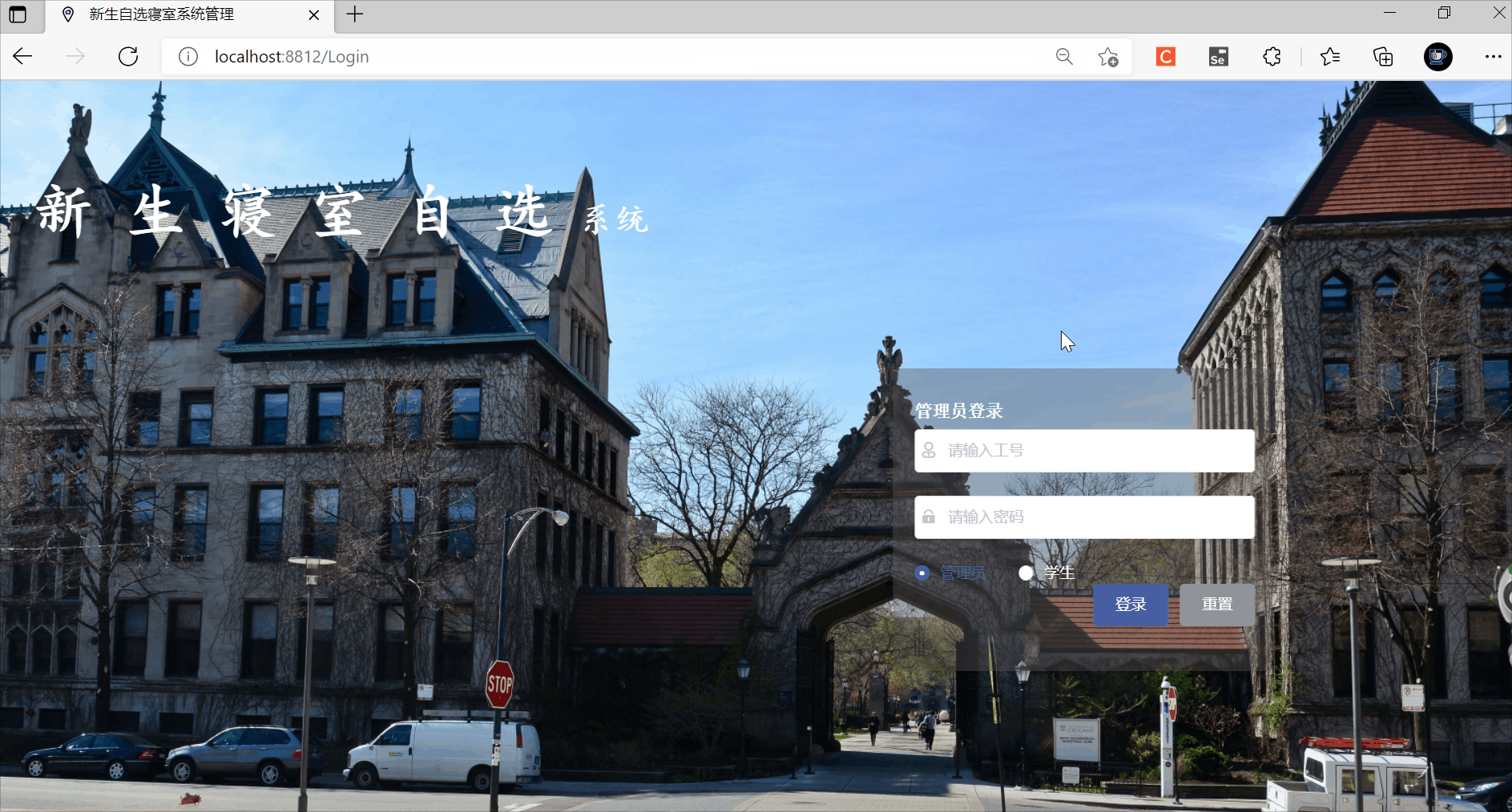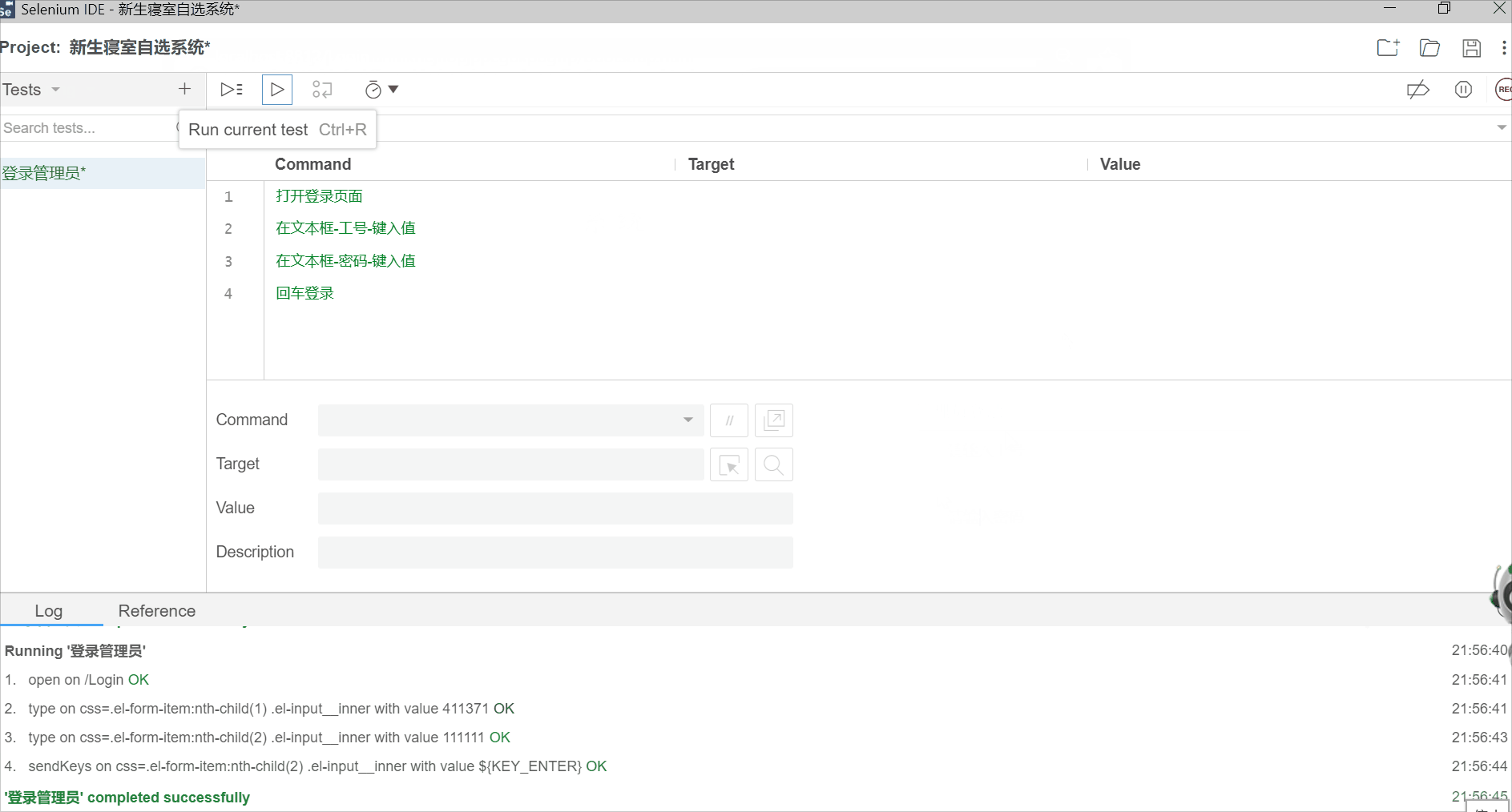
2.5 一个完整的测试用例
一个完整的测试用例,需要步骤(command,target,value),断言(预期和实际的对比)。
断言的要求:只要是唯一确定你的脚本是通过的即可。
eg:
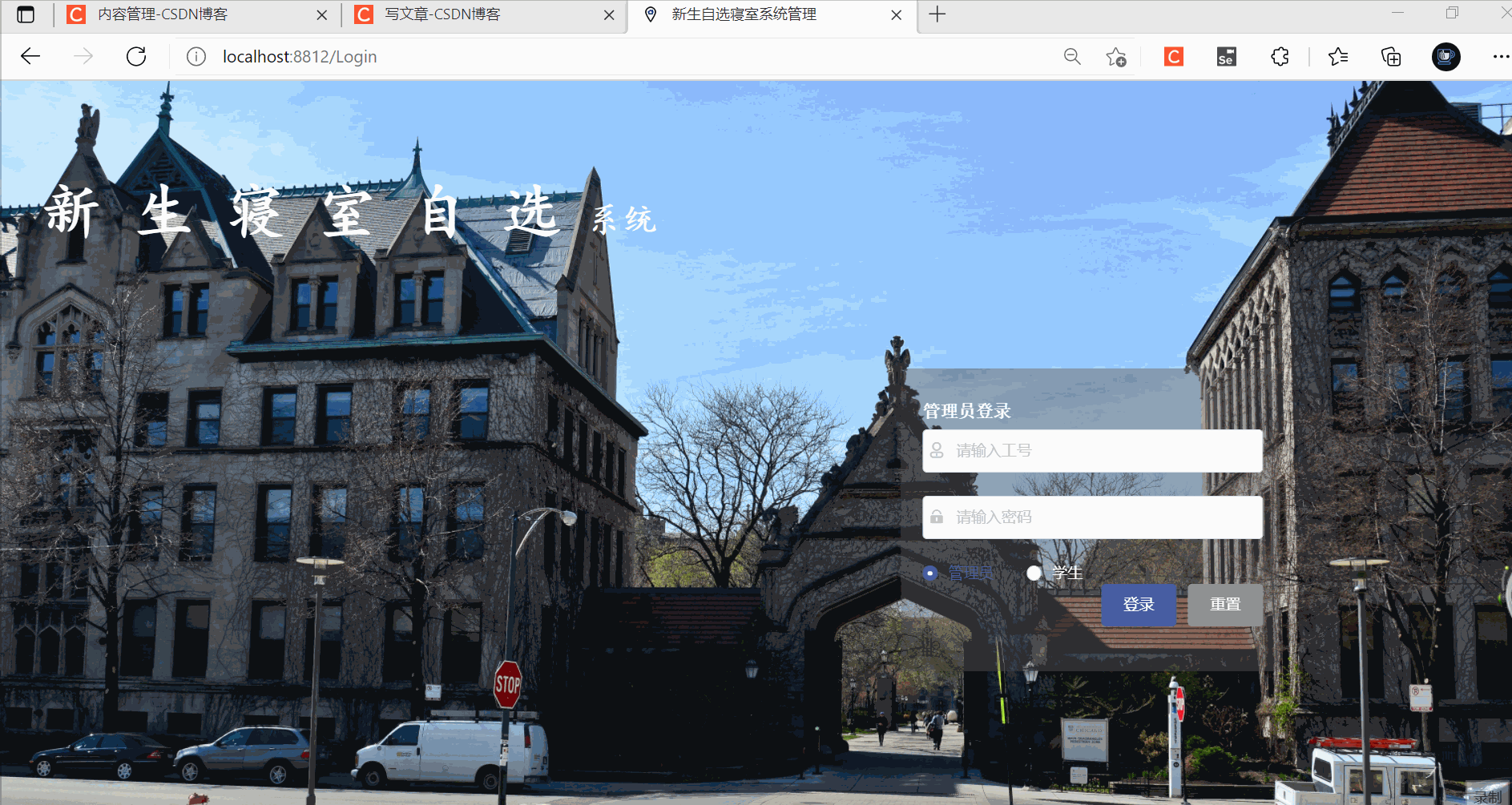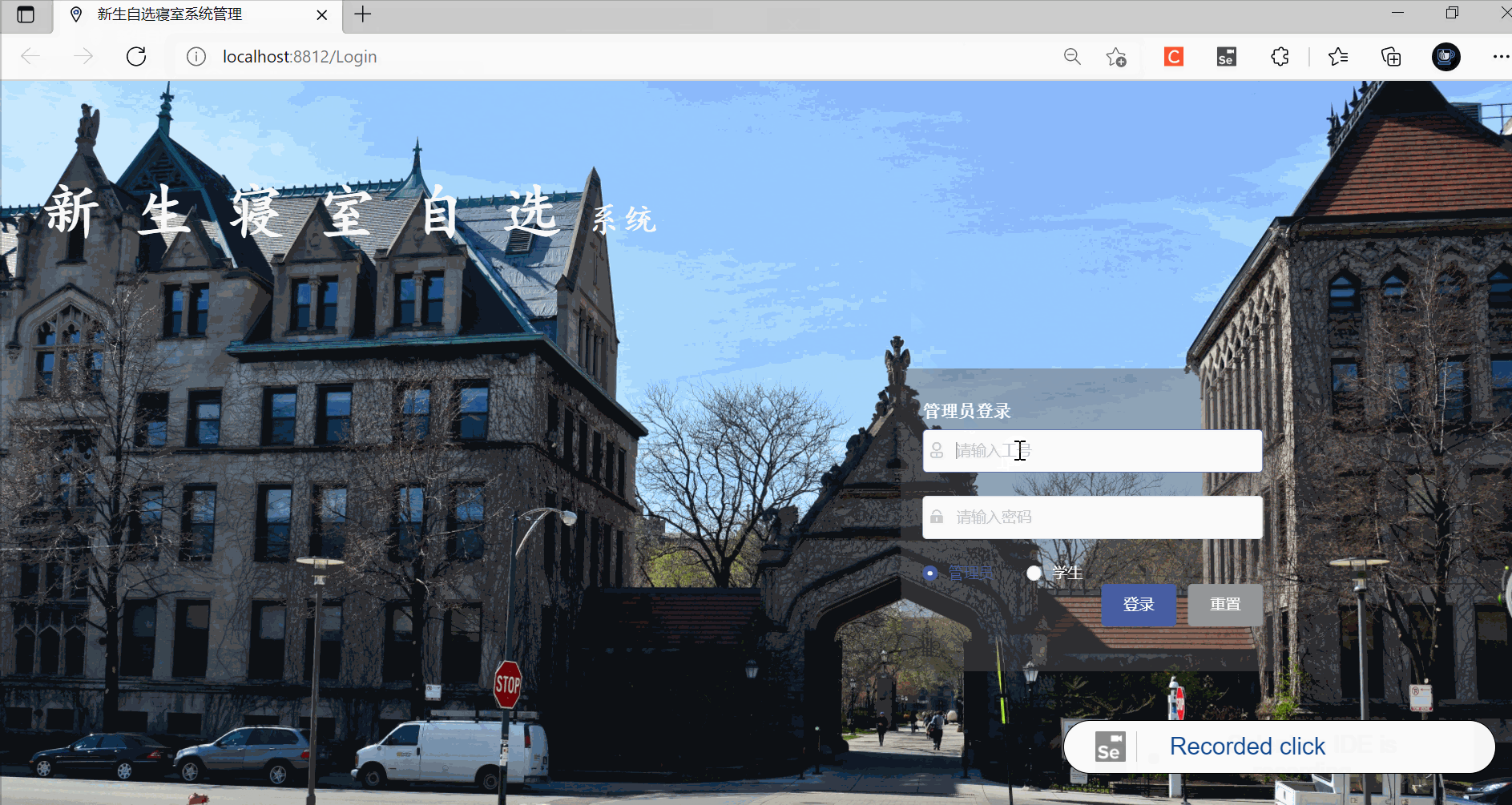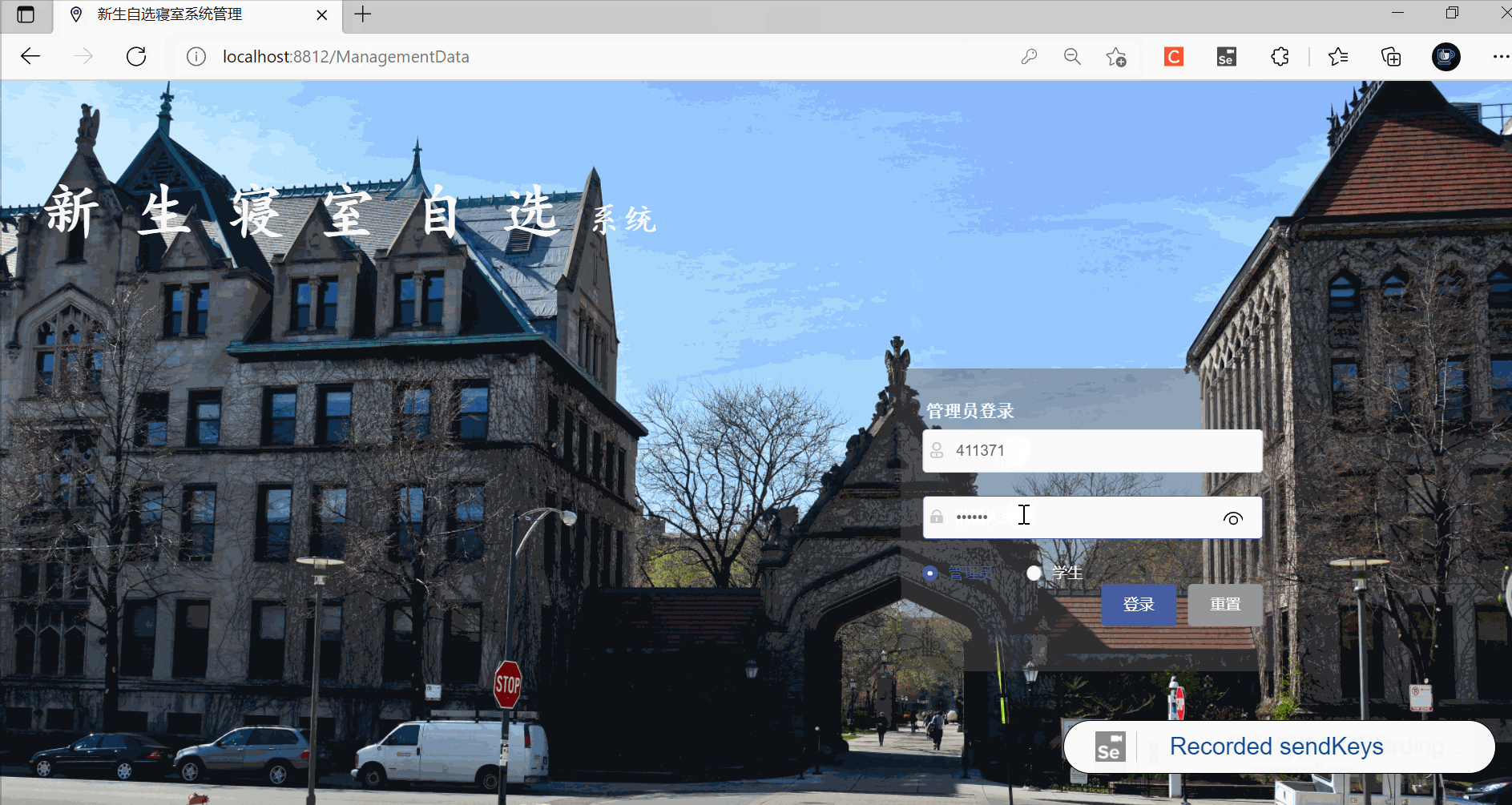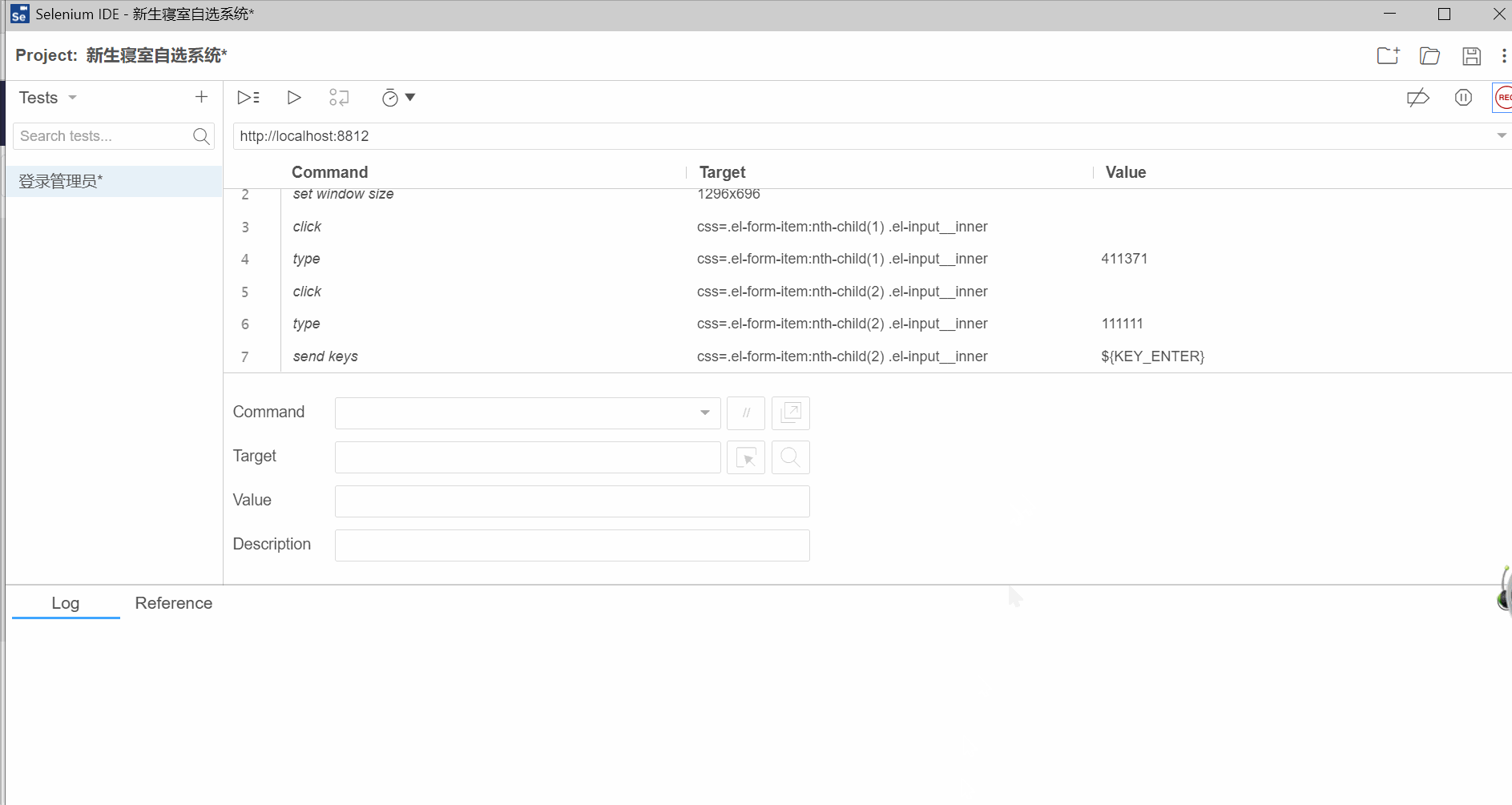
我们还以新生寝室自选系统登录为例
在我们的<登录管理员>脚本的最后添加一个步骤(即断言)

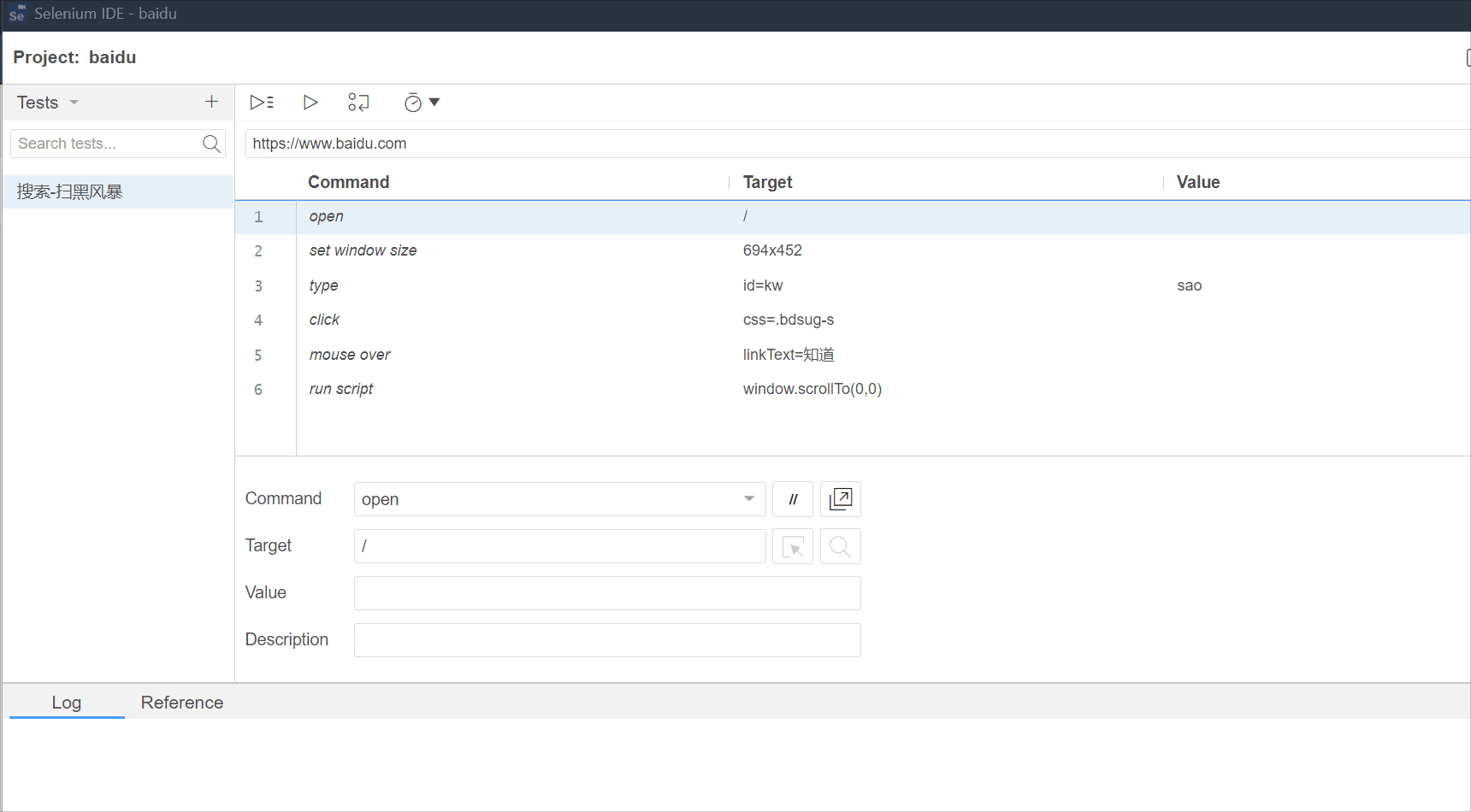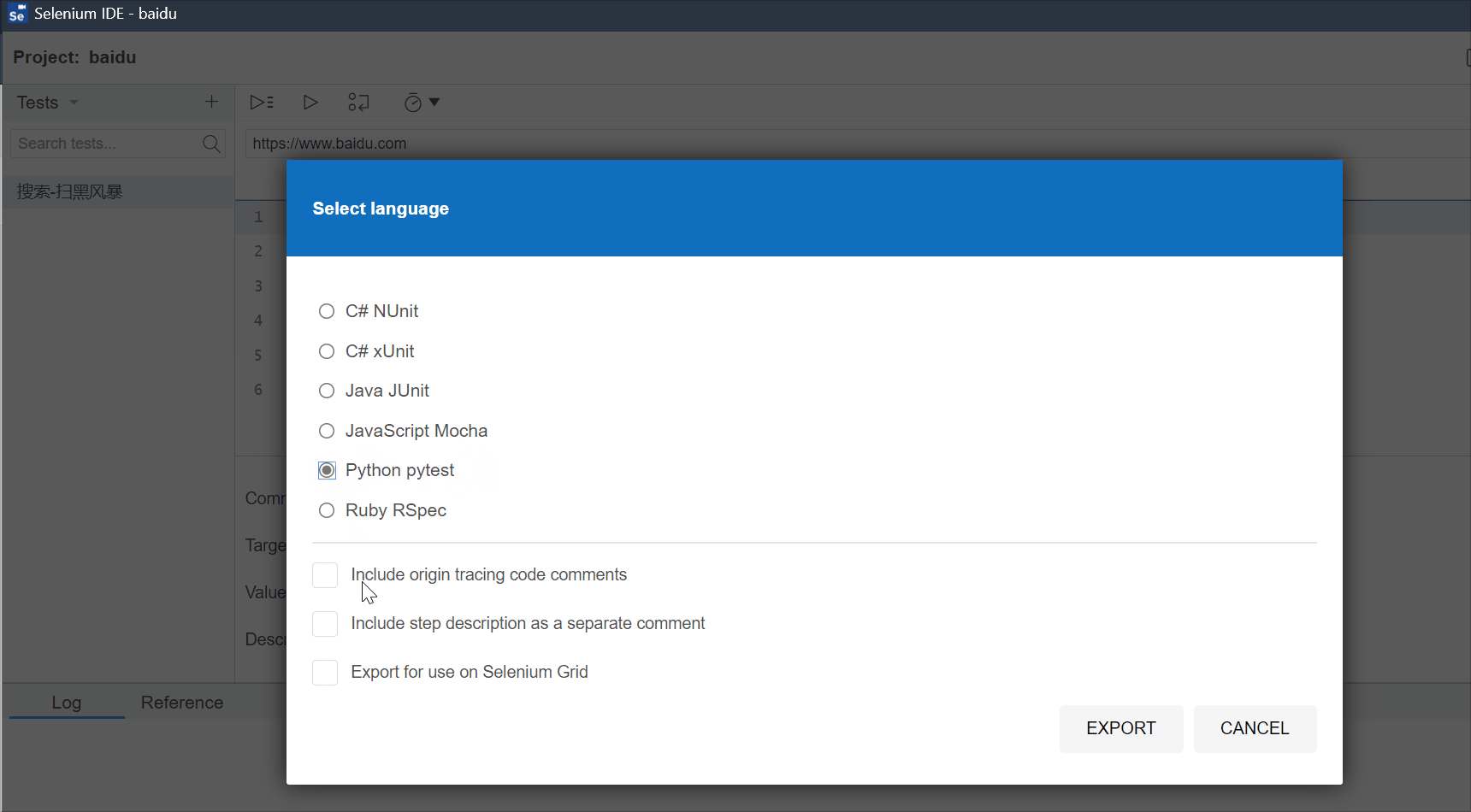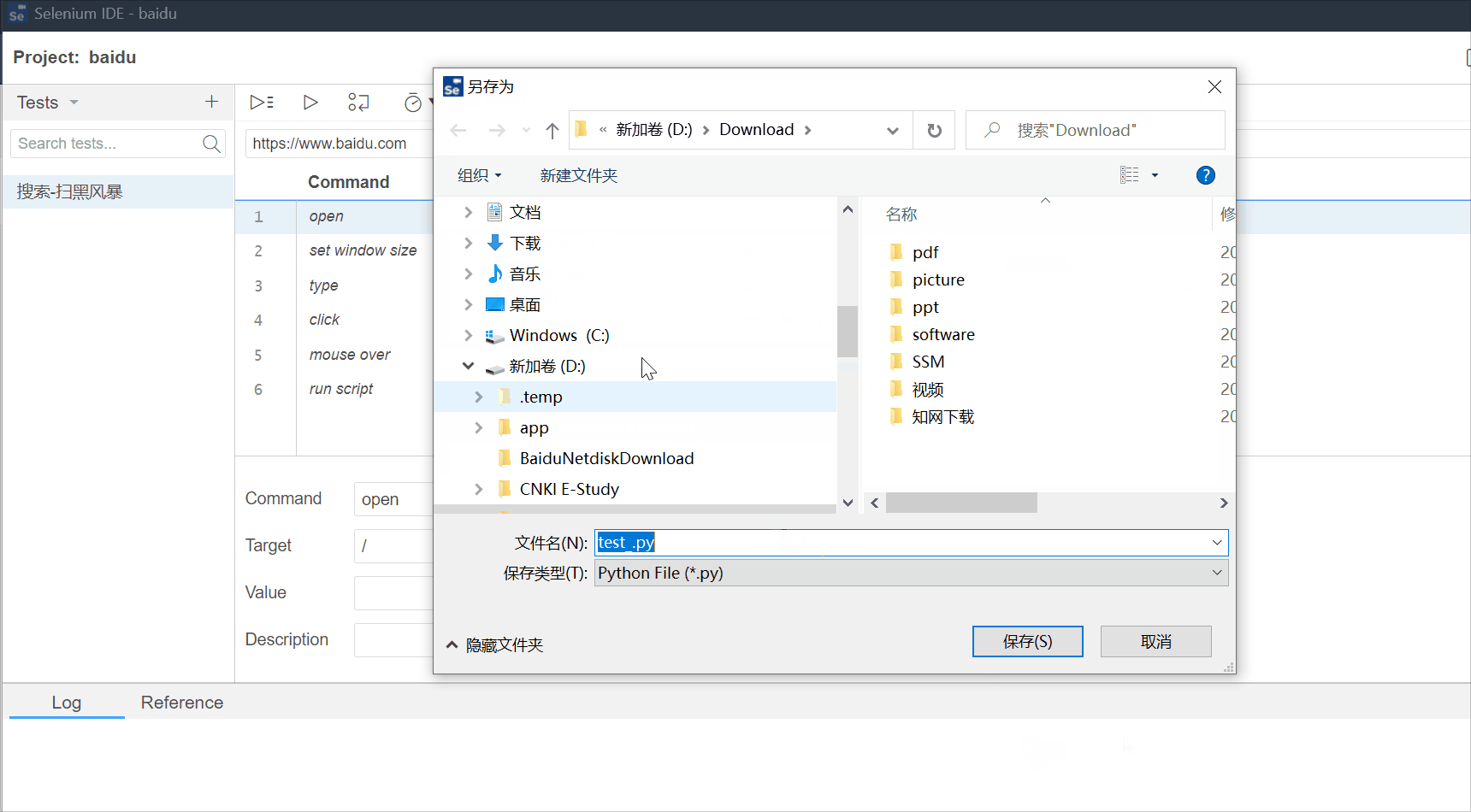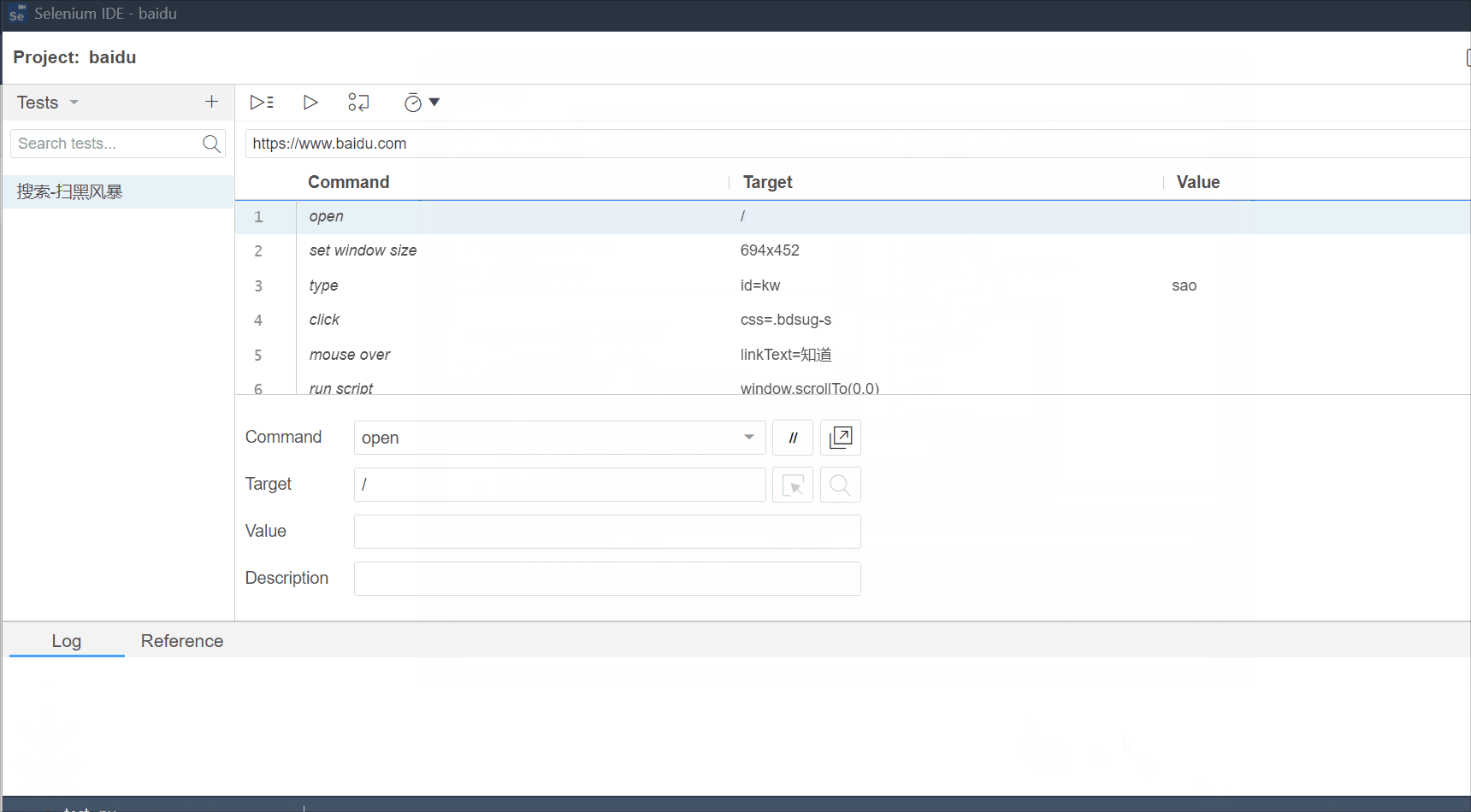
除了用selenium去录制脚本以外,我们还可以使用它开发脚本,手动的编写脚本,即我们自己编写脚本的每一个步骤。

导出脚本,以python+pytest
打开该脚本

# Generated by Selenium IDE
import pytest
import time
import json
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
class Test():
def setup_method(self, method):
self.driver = webdriver.Firefox()
self.vars = {}
def teardown_method(self, method):
self.driver.quit()
def test_(self):
self.driver.get("http://localhost:8812/Login")
self.driver.find_element(By.CSS_SELECTOR, ".el-form-item:nth-child(1) .el-input__inner").send_keys("411371")
self.driver.find_element(By.CSS_SELECTOR, ".el-form-item:nth-child(2) .el-input__inner").send_keys("111111")
self.driver.find_element(By.CSS_SELECTOR, ".el-form-item:nth-child(2) .el-input__inner").send_keys(Keys.ENTER)
# 是否登录到管理员411371
assert self.driver.find_element(By.CSS_SELECTOR, ".animate__animated > span").text == "411371"
保存工程,它是以后缀名为.side的形式保存的

2.6 katalon
跟selenium IDE功能类似,但是katalon可以python+unittest的方式导出脚本


后面添加两个步骤,断言和关闭页面,然后运行该脚本,就跟selenium IDE没什么区别
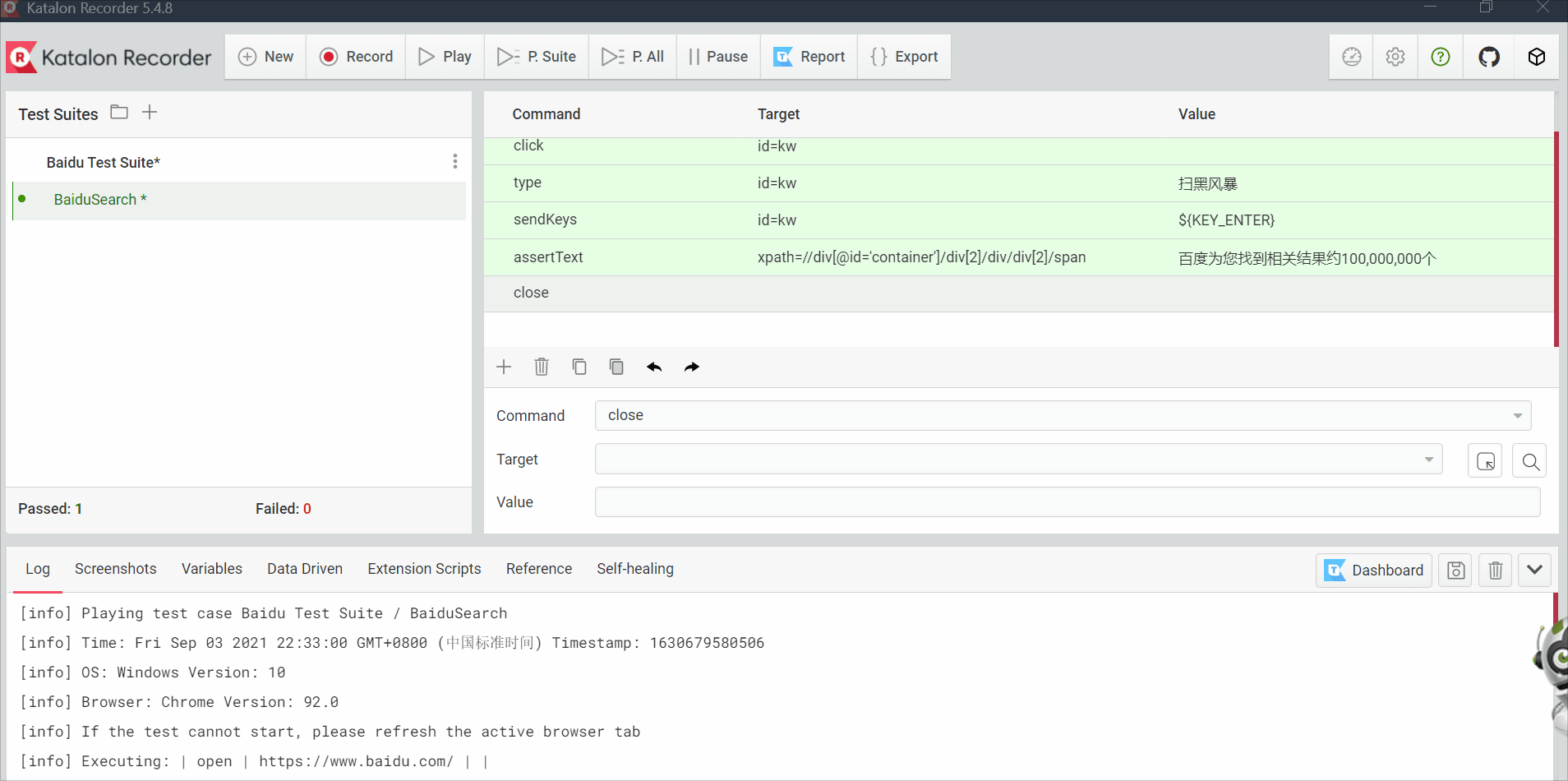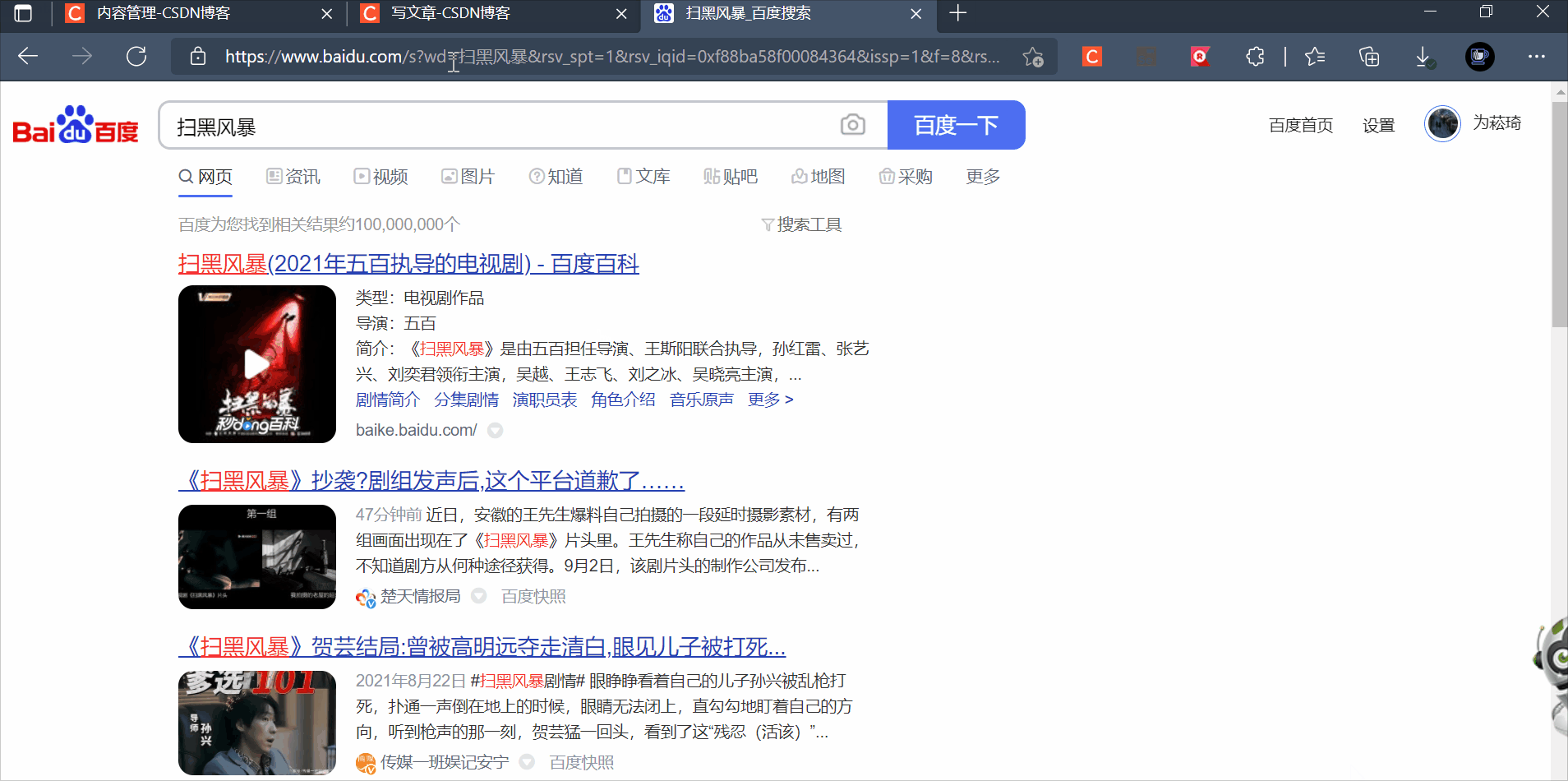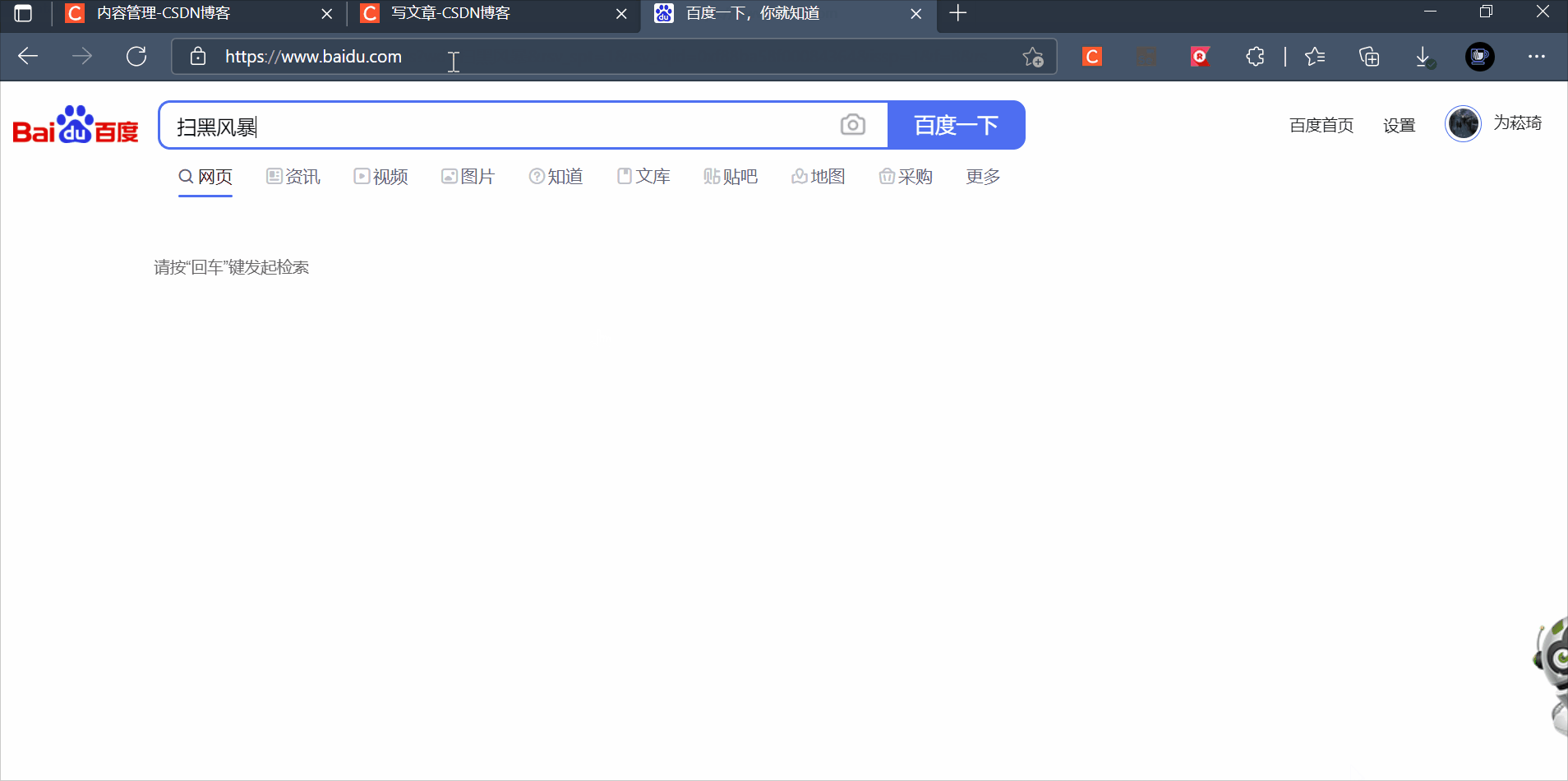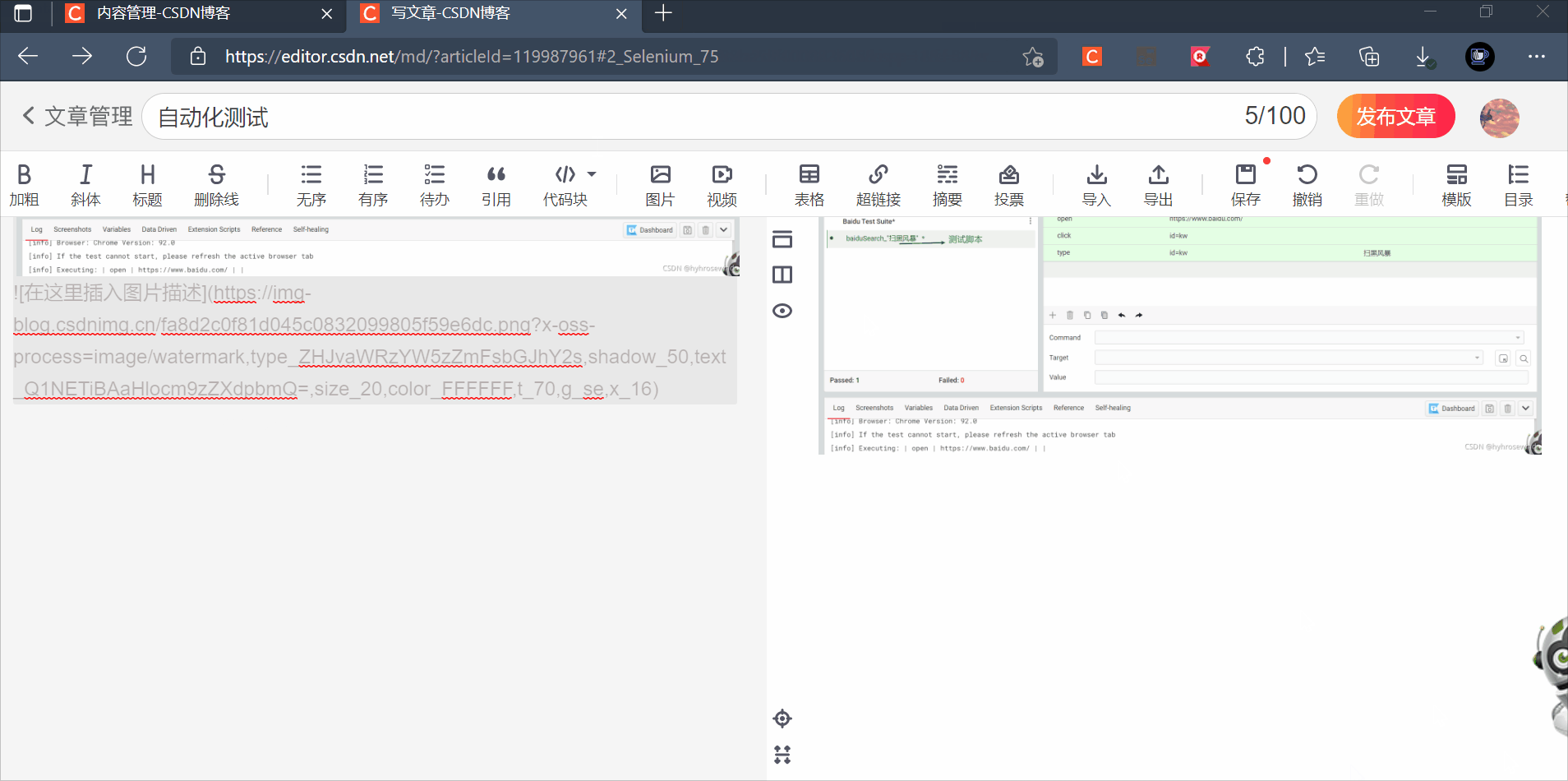
导出脚本以python+unittest的方式
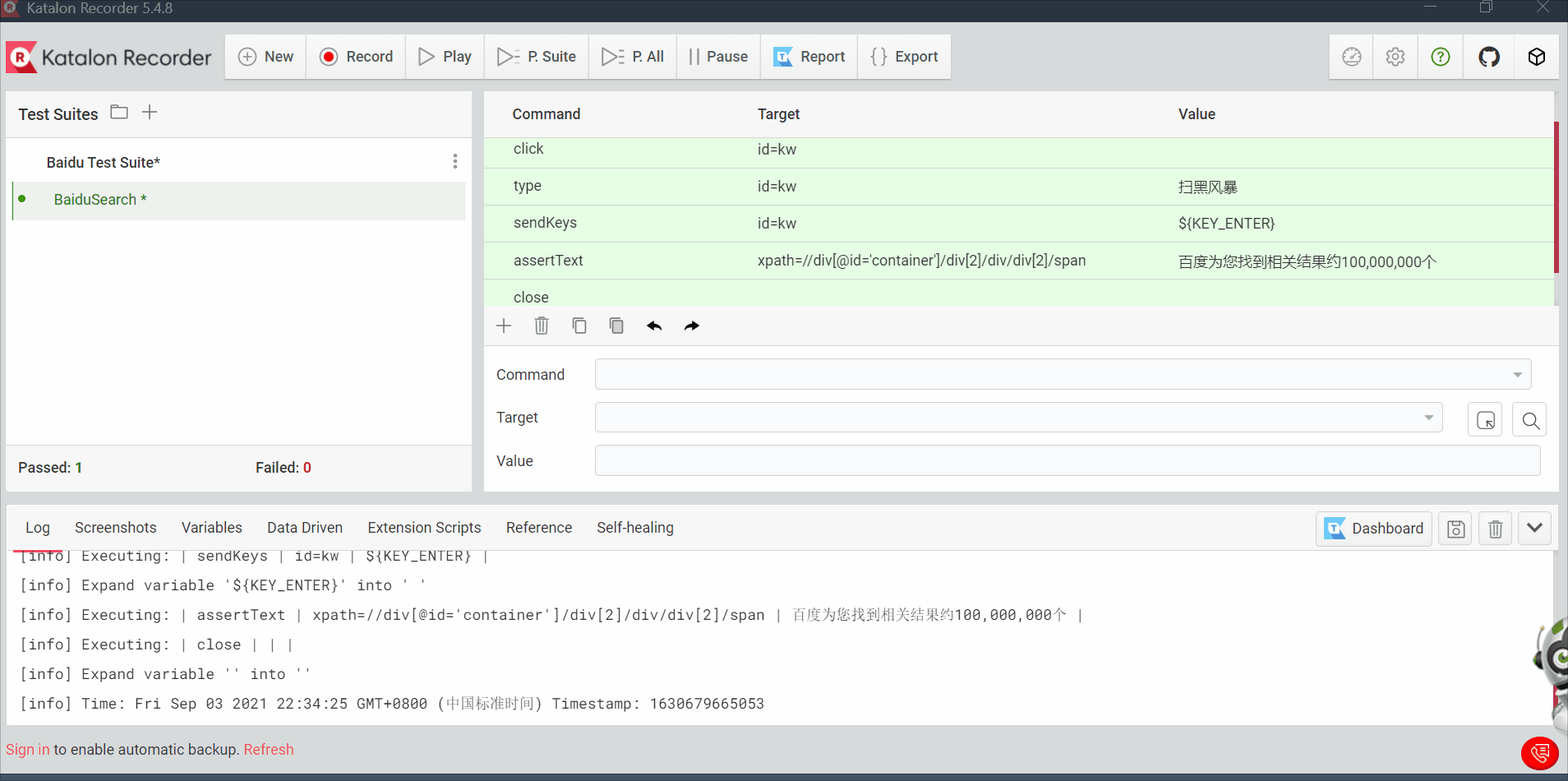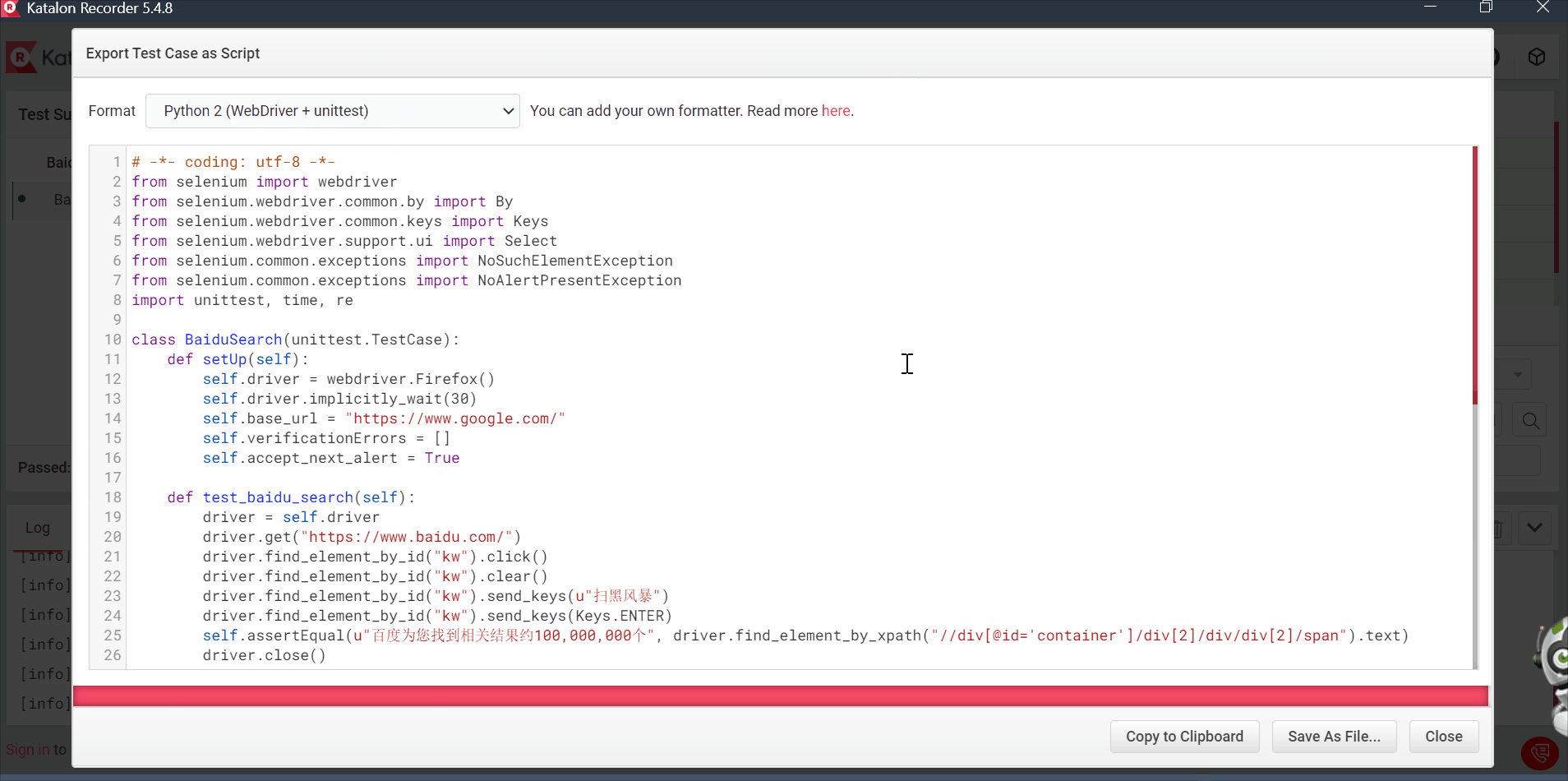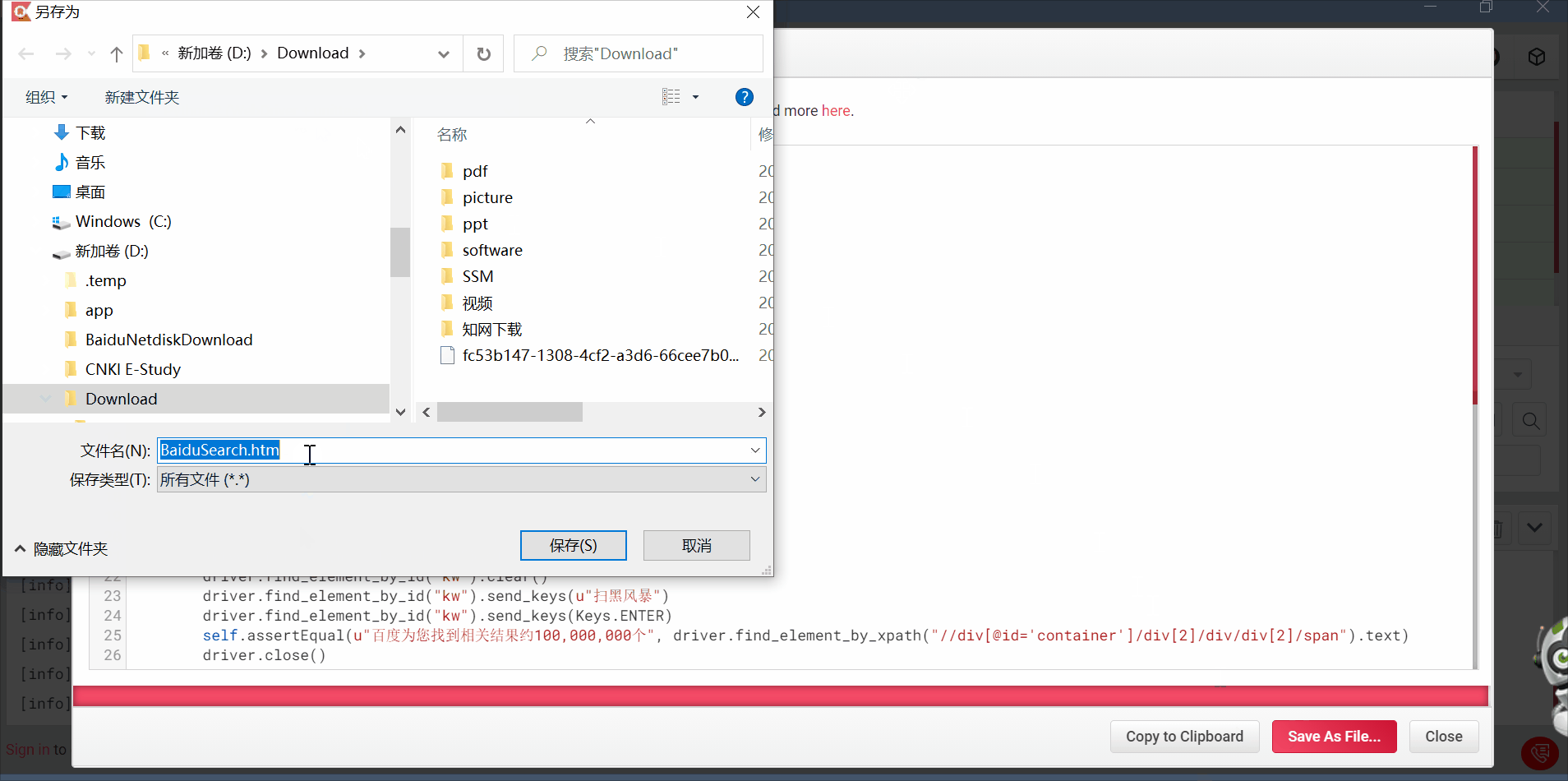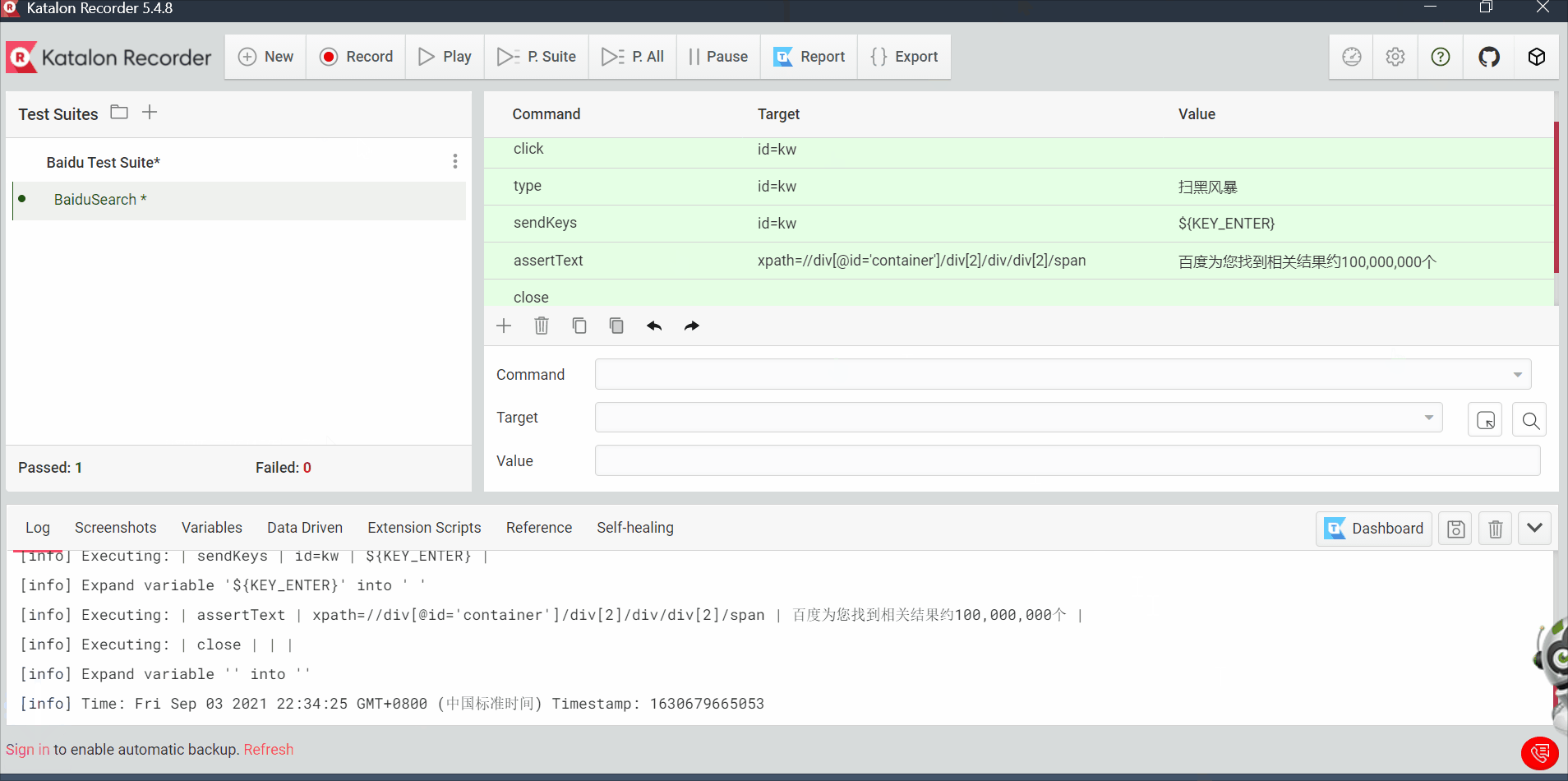
打开该脚本,删除一些不需要的代码

留下一部分必要的代码
# -*- coding: utf-8 -*-
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import Select
from selenium.common.exceptions import NoSuchElementException
from selenium.common.exceptions import NoAlertPresentException
import unittest, time, re
class BaiduSearch(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Firefox()
self.driver.implicitly_wait(30)
self.base_url = "https://www.google.com/"
self.verificationErrors = []
self.accept_next_alert = True
def test_baidu_search(self):
driver = self.driver
driver.get("https://www.baidu.com/")
driver.find_element_by_id("kw").click()
driver.find_element_by_id("kw").clear()
driver.find_element_by_id("kw").send_keys(u"扫黑风暴")
driver.find_element_by_id("kw").send_keys(Keys.ENTER)
self.assertEqual(u"百度为您找到相关结果约100,000,000个", driver.find_element_by_xpath("//div[@id='container']/div[2]/div/div[2]/span").text)
driver.close()
def tearDown(self):
self.driver.quit()
self.assertEqual([], self.verificationErrors)
if __name__ == "__main__":
unittest.main()
2.7 Selenium测试环境搭建
根据市场需求,我们选择Python+selenium的组合,来搭建测试环境。
1)python3安装并配置环境变量
2)selenium安装:pip3 install selenium
3)驱动器安装:执行的脚本需要浏览器驱动来驱动浏览器
WebDriver支持Firefox、IE、Opera、Chrome等浏览器。
浏览器驱动的下载地址:
https://www.selenium.dev/documentation/getting_started/installing_browser_drivers/
进入上面的网址,下载对应的浏览器驱动

我使用的edge,所以下载edge的浏览器驱动:
解压后,将里面的msedgedriver.exe放到你安装python的目录下

可以使用指令查找python所在目录where python


验证浏览器驱动是否搭建成功
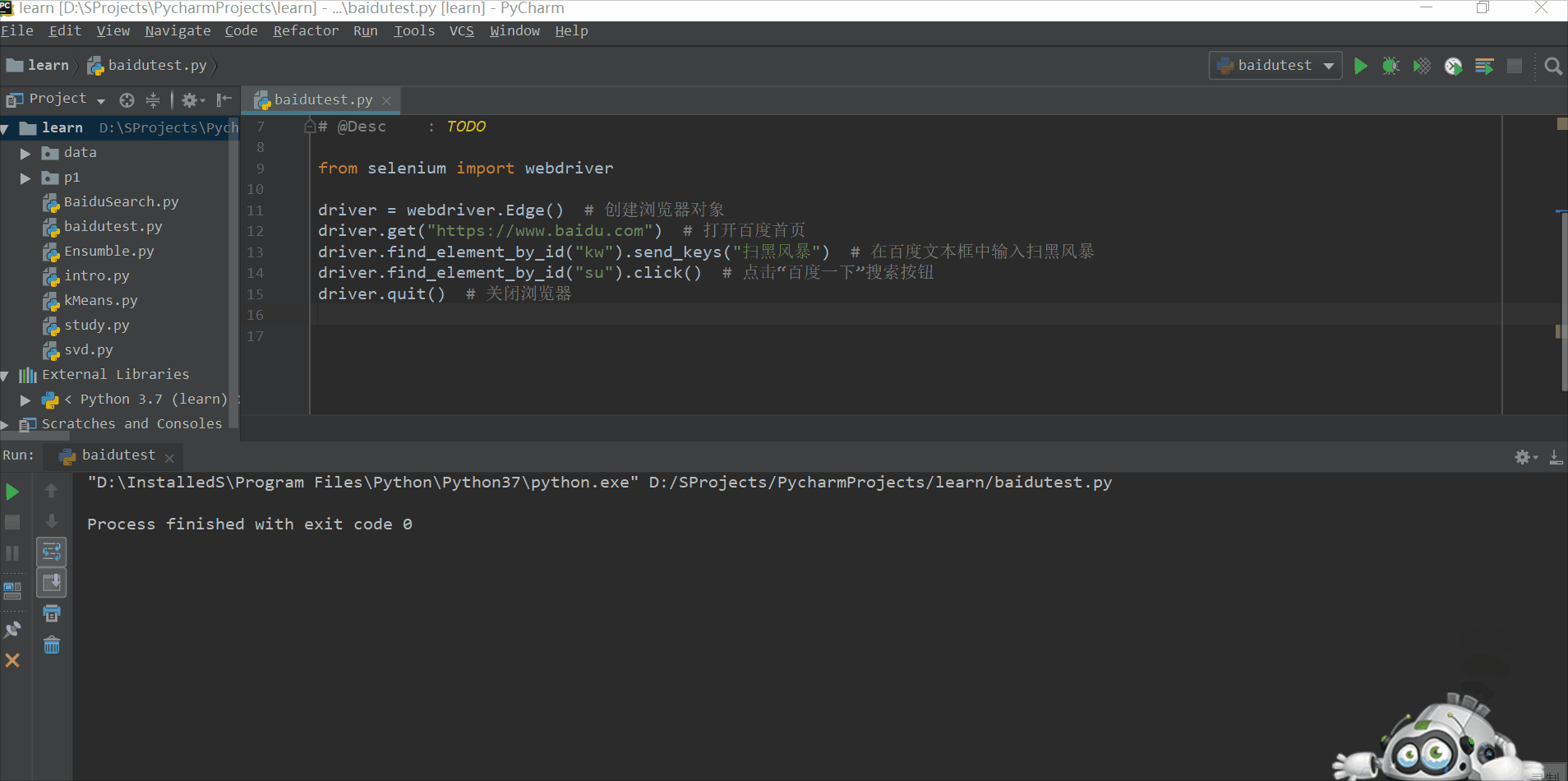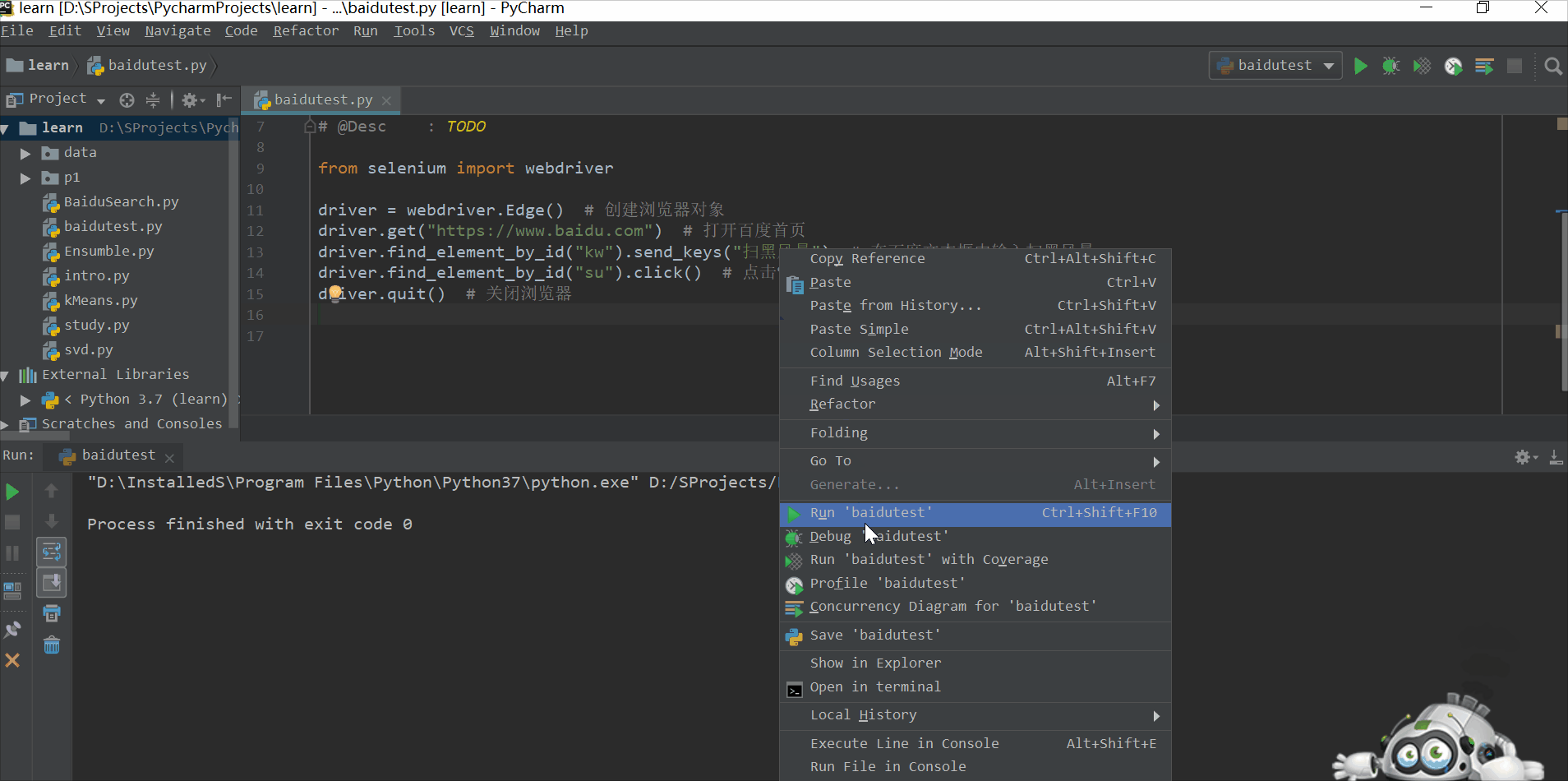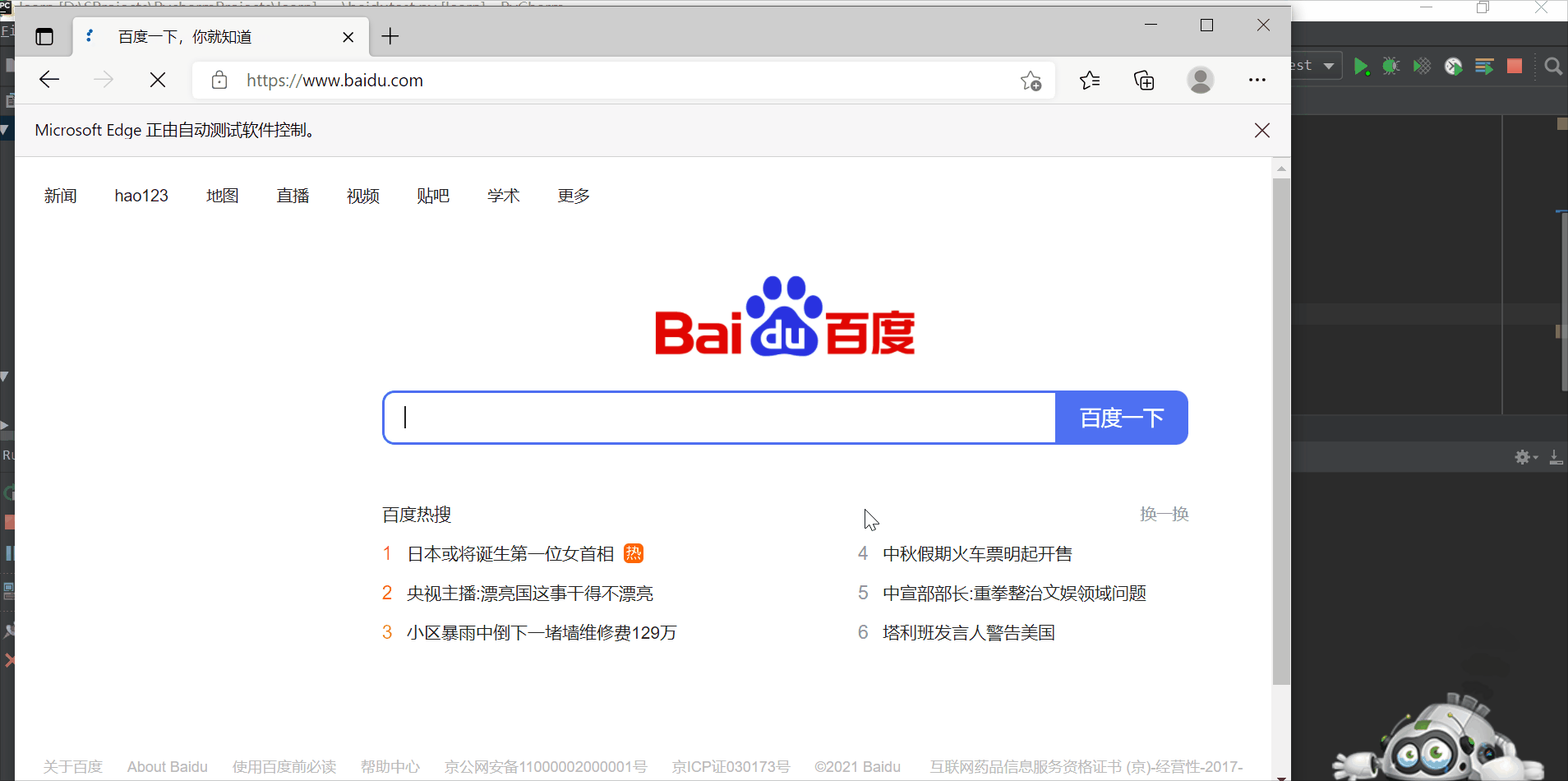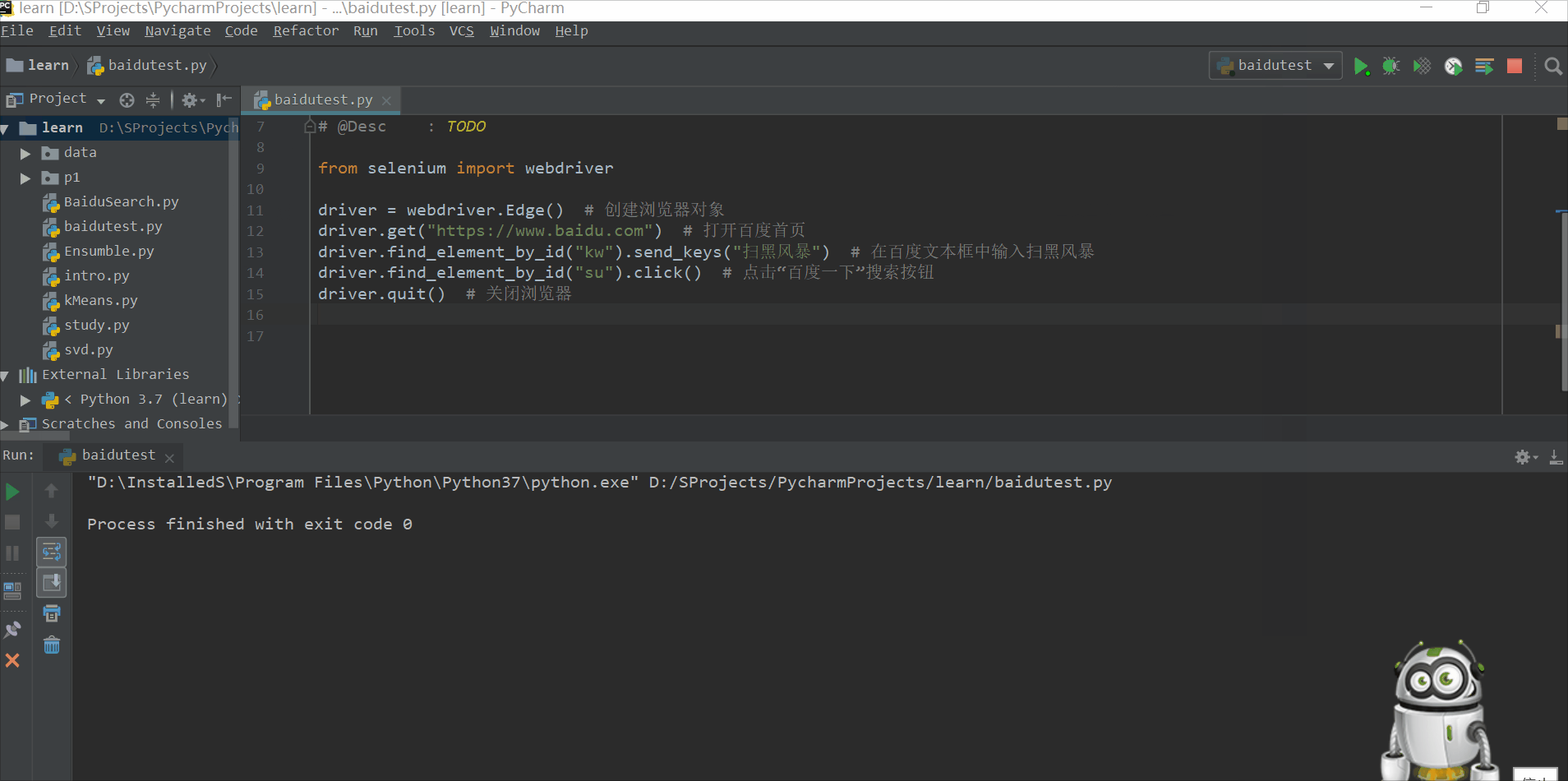
在learn项目中新建一个baidutest.py文件

#!/usr/bin/env python
# -*- coding:utf8 -*-
# python3.7
# @Time : 2021/09/04 14:39
# @Author : hyh
# @Version : 1.0
# @Desc : TODO
from selenium import webdriver
driver = webdriver.Edge() # 创建浏览器对象
driver.get("https://www.baidu.com") # 打开百度首页
driver.find_element_by_id("kw").send_keys("扫黑风暴") # 在百度文本框中输入扫黑风暴
driver.find_element_by_id("su").click() # 点击“百度一下”搜索按钮
driver.quit() # 关闭浏览器
运行,发现出现找不到驱动路径的问题

将msedgedriver.exe重命名为MicrosoftWebDriver.exe
再次运行,成功
2.8 WebDriver API
2.8.1 页面元素定位
自动化其实就是用代码去控制页面上的元素,按照脚本设计逻辑执行。
自动化测试的主要步骤:
1)通过某些方式定位到我们要执行的对象、目标(target)
2)然后对定位到的这个对象要执行什么操作(command)
3)通过操作对定位到的元素赋值(value)
4)添加断言(判断预期结果与实际结果是否符合)
WebDriver提供了8种元素的定位方式:
| WebDriver元素定位方式 | 对应的python方法 |
|---|---|
| id | find_element_by_id("id属性值") |
| name | find_element_by_name("name属性值") |
| class name | find_element_by_class_name("id值") |
| tag name | find_element_by_tag_name("标签名") |
| link text | find_element_by_link_text("链接的显示文本") |
| partical link text | find_element_by_partical_link_text("部分链接的显示文本") |
| xpath | find_element_by_xpath("xpath") |
| css selector | find_element_css_selector("css") |
2.8.1.1 id定位 find_element_by_id("id属性值")
id定位:HTML规定id属性在HTML文档中必须是唯一的,有些id是动态的,这就需要测试人员与开发进行商量。
eg:
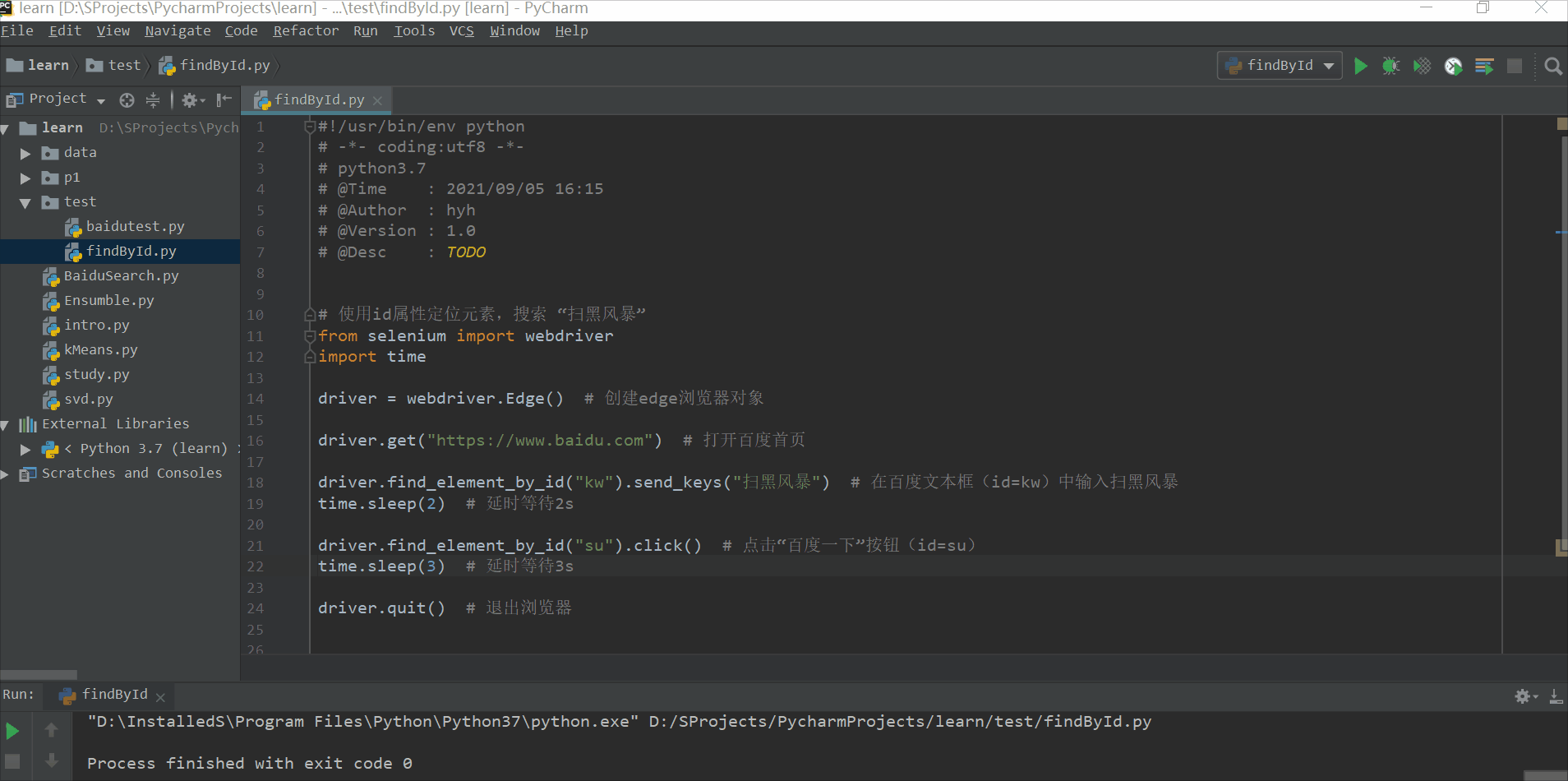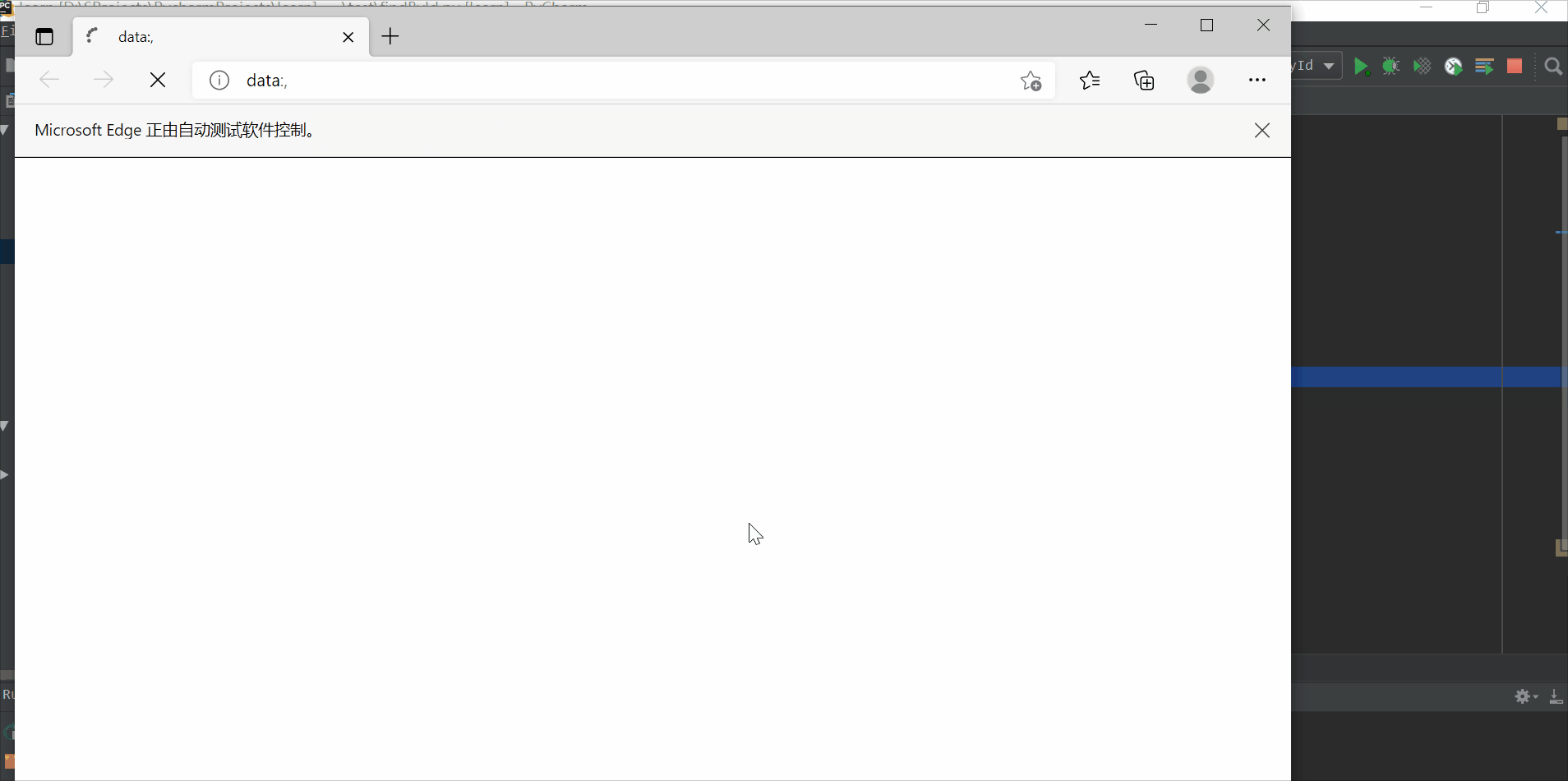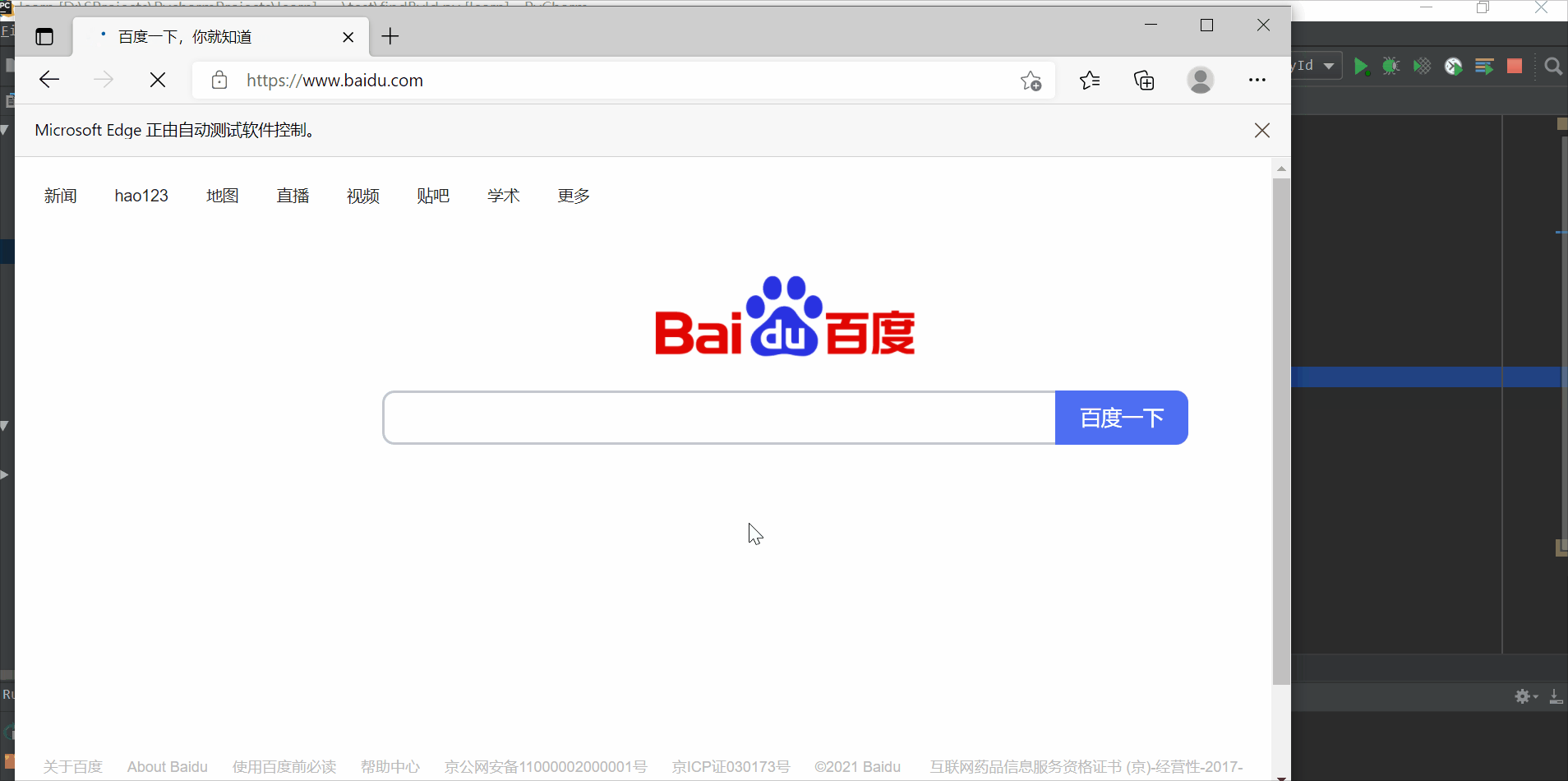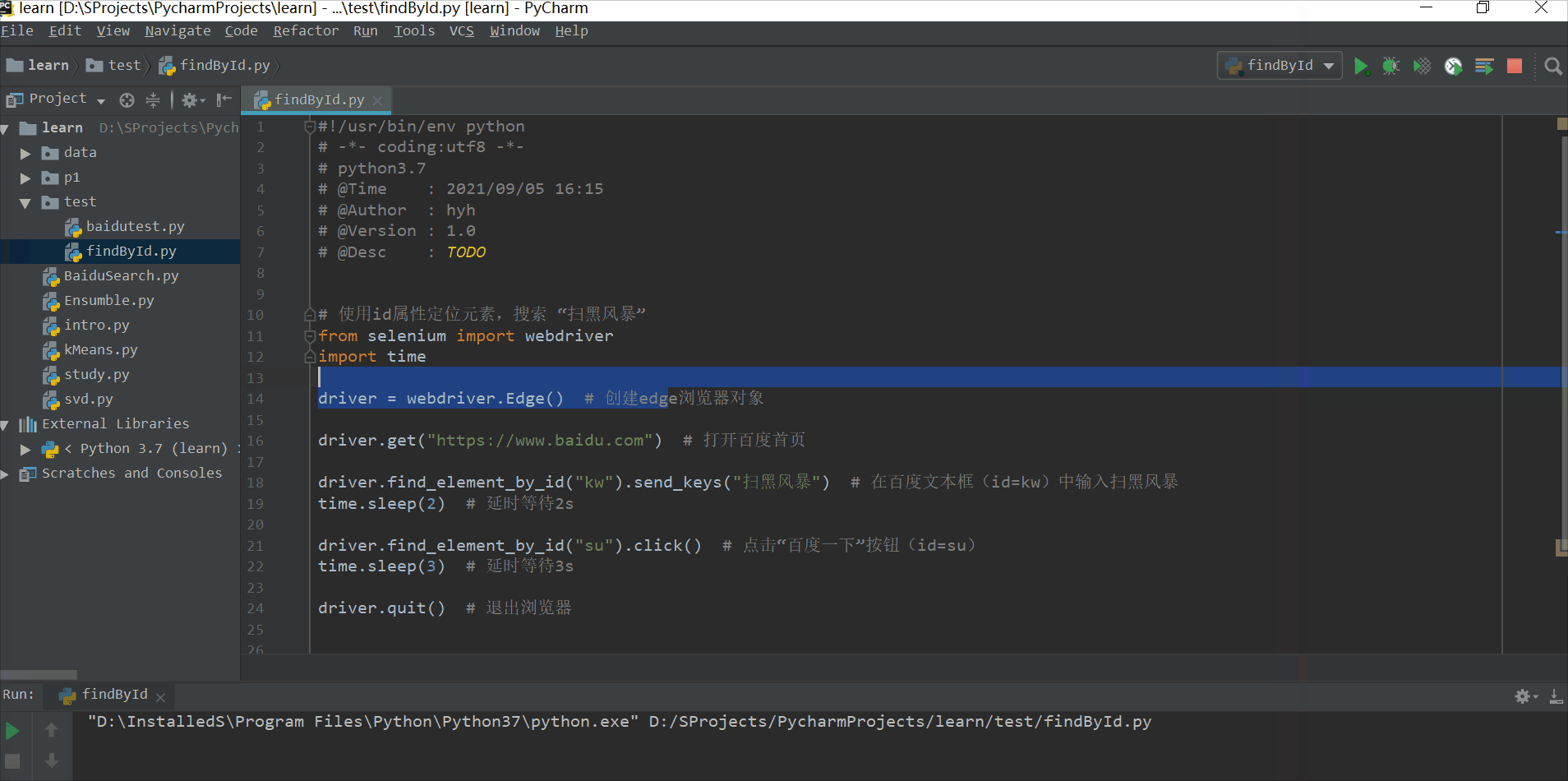
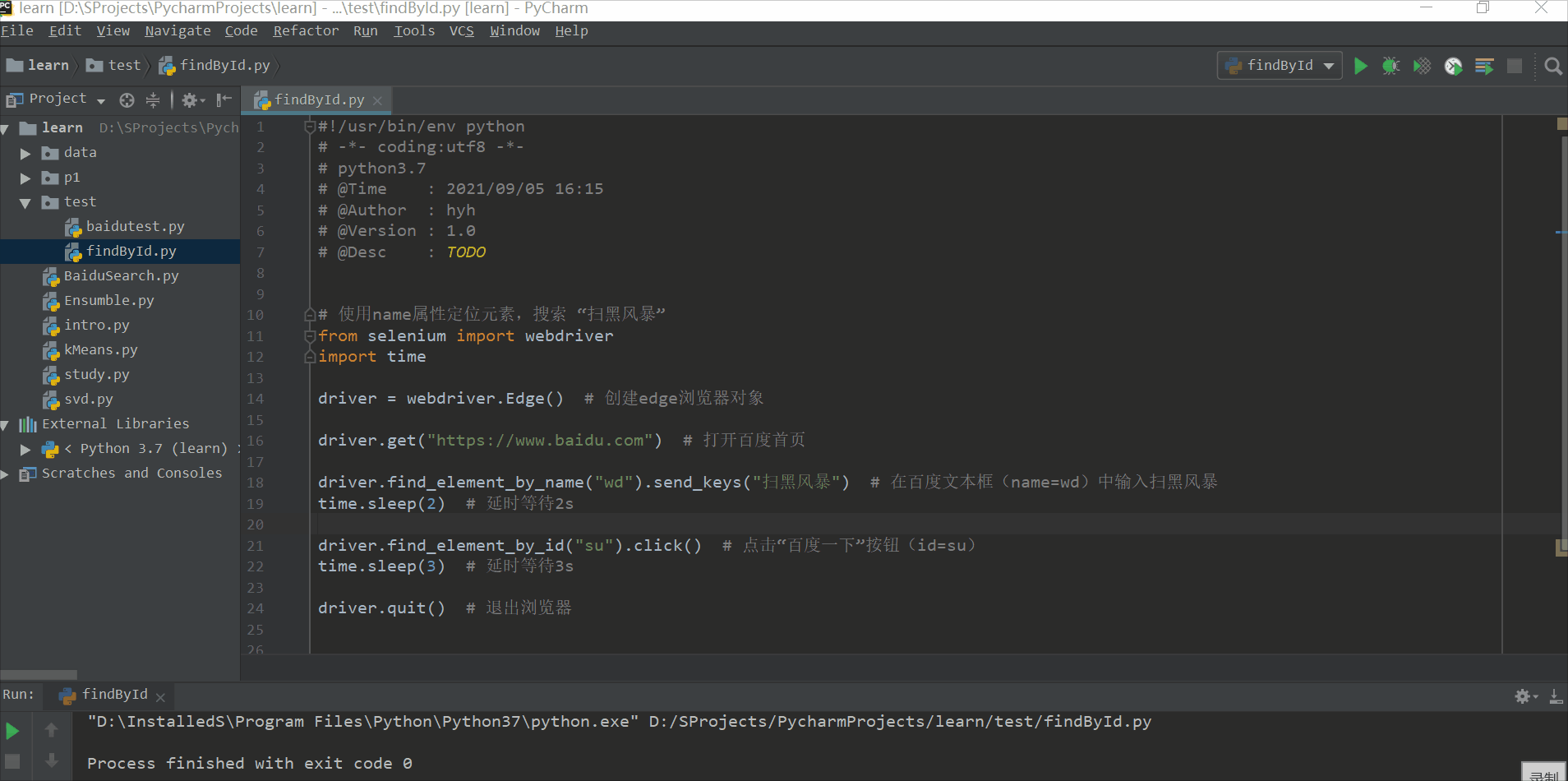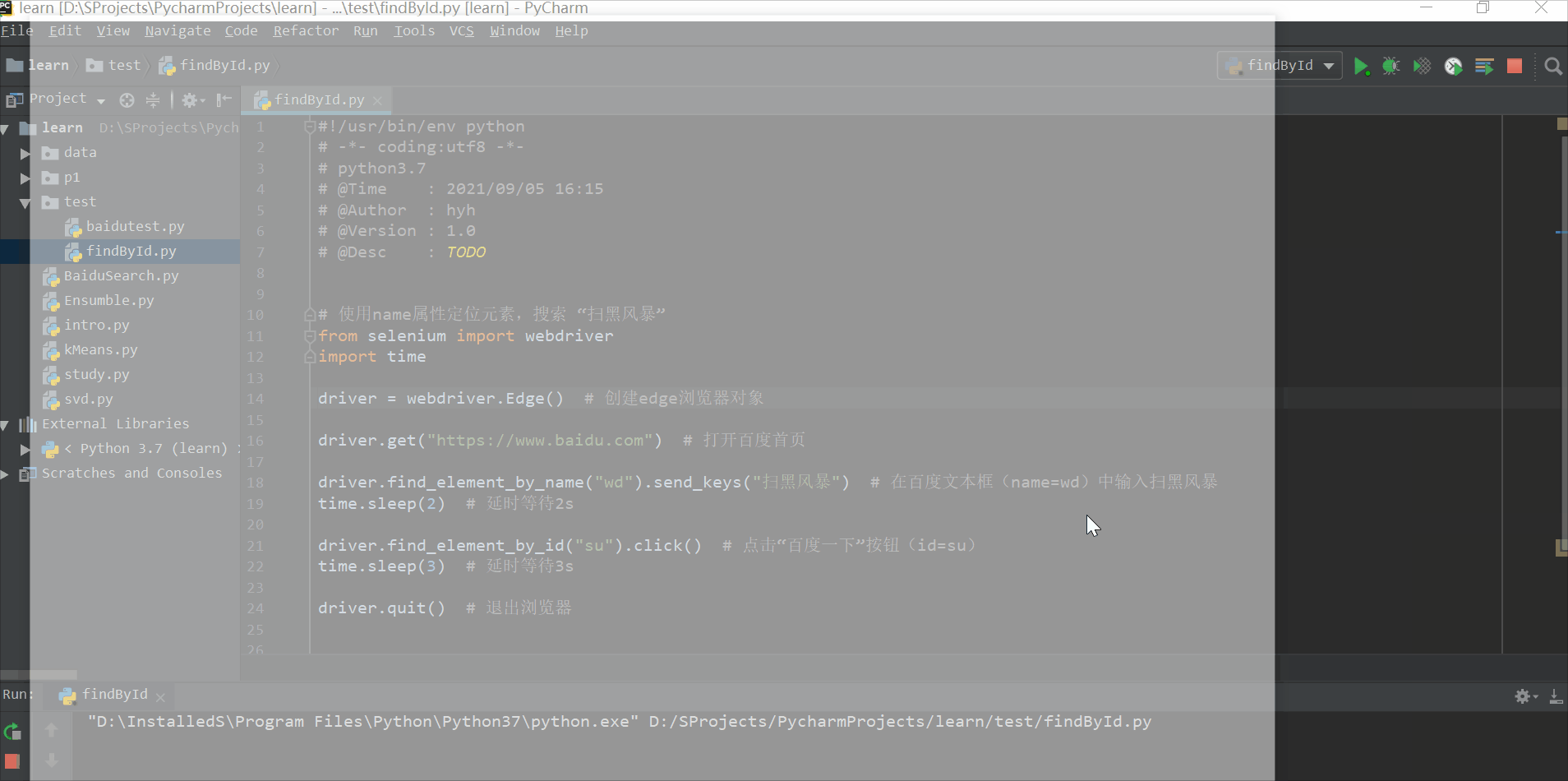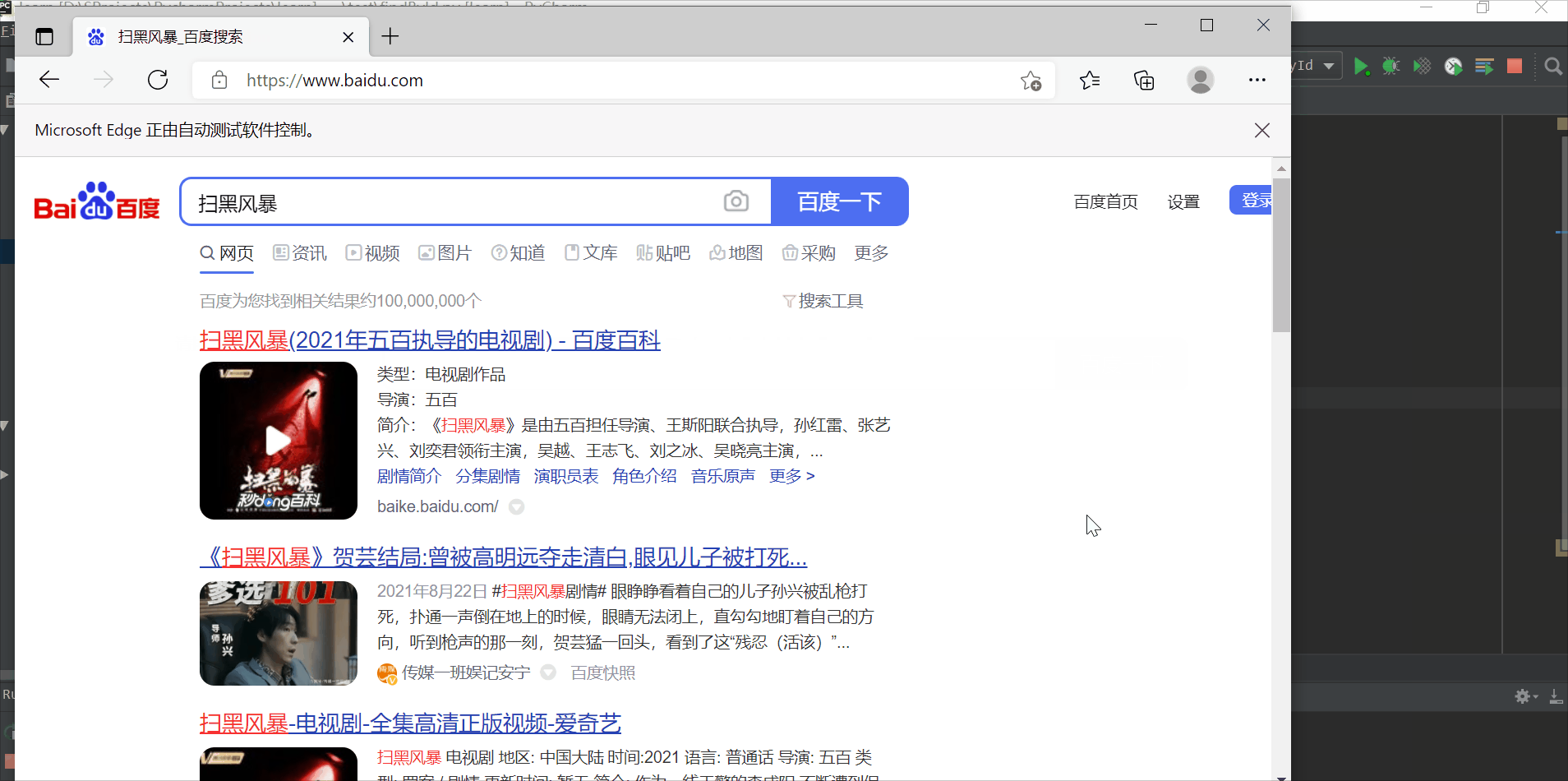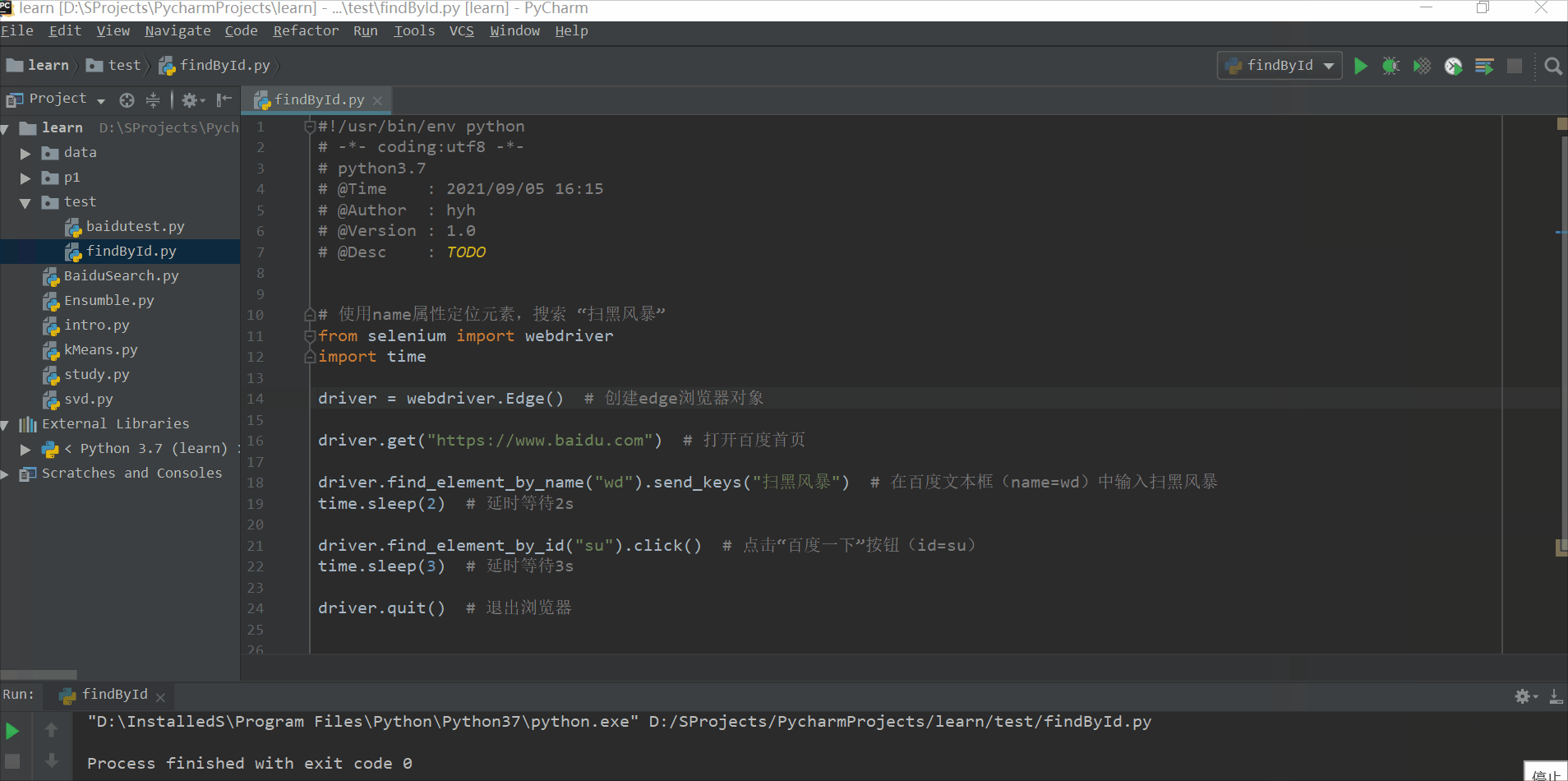
使用百度搜索,用id属性定位元素,搜索 “扫黑风暴”
#!/usr/bin/env python
# -*- coding:utf8 -*-
# python3.7
# @Time : 2021/09/05 16:15
# @Author : hyh
# @Version : 1.0
# @Desc : TODO
# 使用id属性定位元素,搜索 “扫黑风暴”
from selenium import webdriver
import time
driver = webdriver.Edge() # 创建edge浏览器对象
driver.get("https://www.baidu.com") # 打开百度首页
driver.find_element_by_id("kw").send_keys("扫黑风暴") # 在百度文本框(id=kw)中输入扫黑风暴
time.sleep(2) # 延时等待2s
driver.find_element_by_id("su").click() # 点击“百度一下”按钮(id=su)
time.sleep(3) # 延时等待3s
driver.quit() # 退出浏览器
2.8.1.2 name定位 find_element_by_name("name属性值")
name定位:HTML规定name来指定元素名称,name属性在页面中可以不唯一。
eg:
查看百度搜索框的name属性

发现百度的搜索框有name属性,按钮没有name属性
#!/usr/bin/env python
# -*- coding:utf8 -*-
# python3.7
# @Time : 2021/09/05 16:15
# @Author : hyh
# @Version : 1.0
# @Desc : TODO
# 使用name属性定位元素,搜索 “扫黑风暴”
from selenium import webdriver
import time
driver = webdriver.Edge() # 创建edge浏览器对象
driver.get("https://www.baidu.com") # 打开百度首页
driver.find_element_by_name("wd").send_keys("扫黑风暴") # 在百度文本框(name=wd)中输入扫黑风暴
time.sleep(2) # 延时等待2s
driver.find_element_by_id("su").click() # 点击“百度一下”按钮(id=su)
time.sleep(3) # 延时等待3s
driver.quit() # 退出浏览器
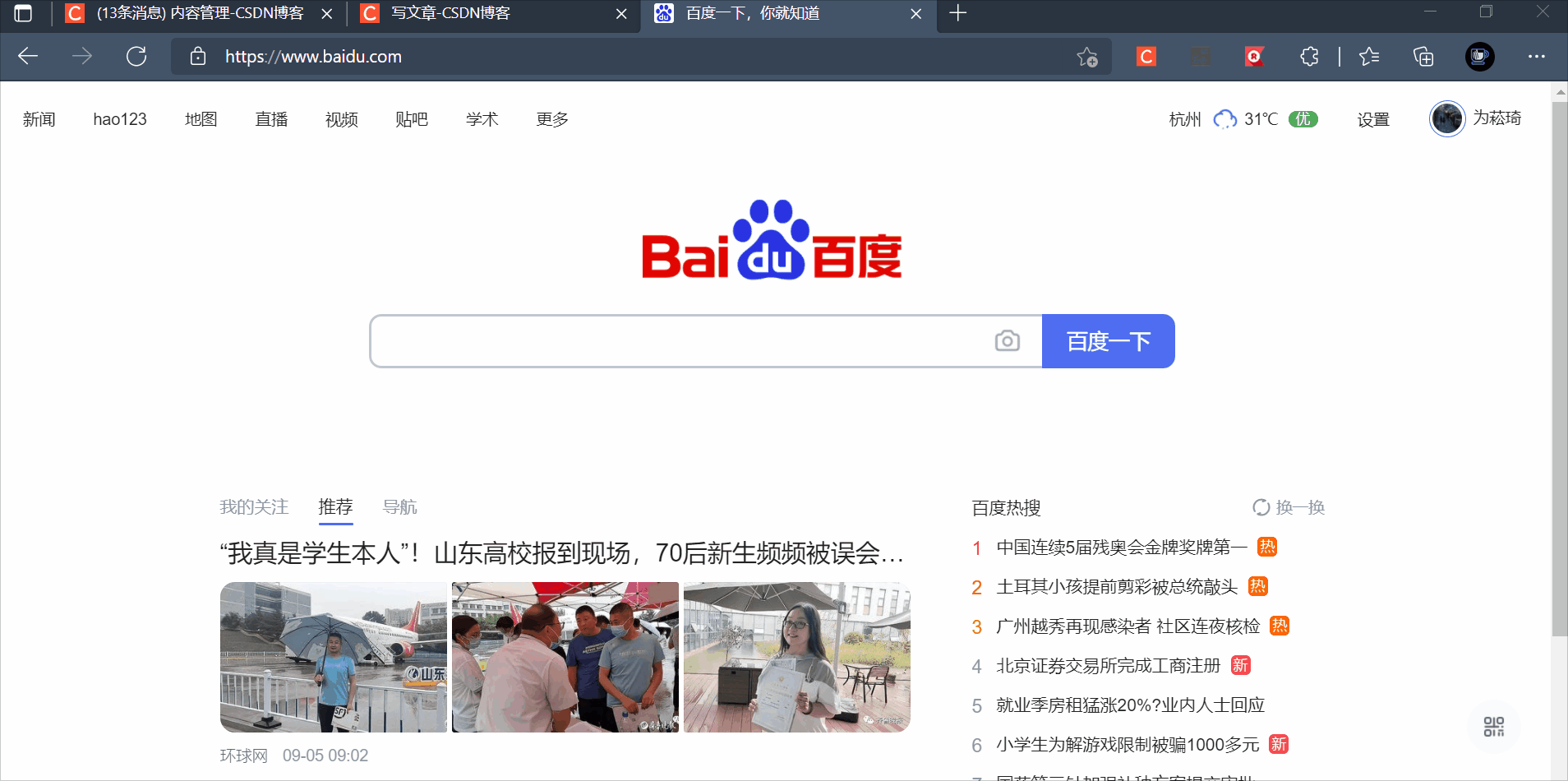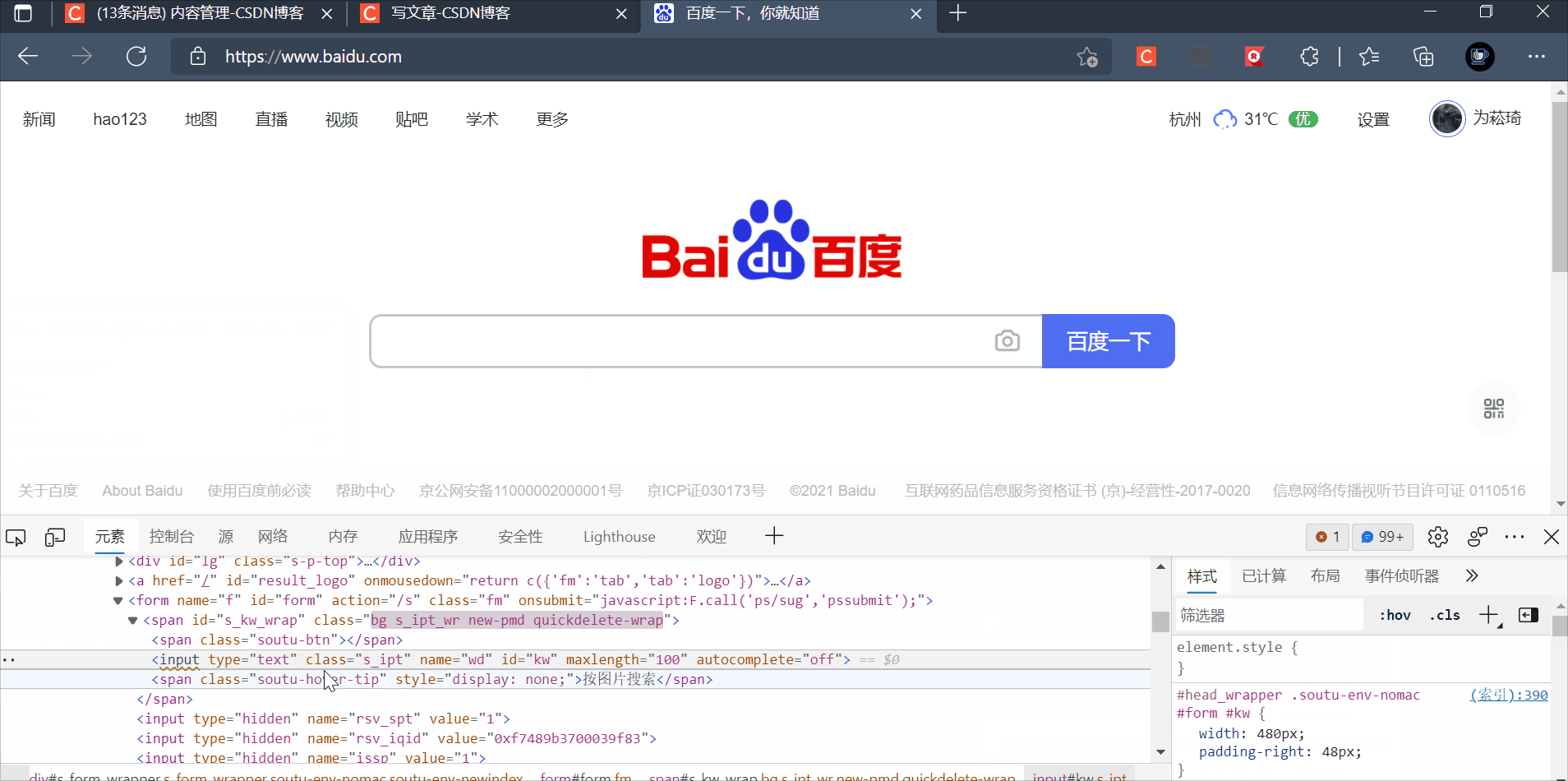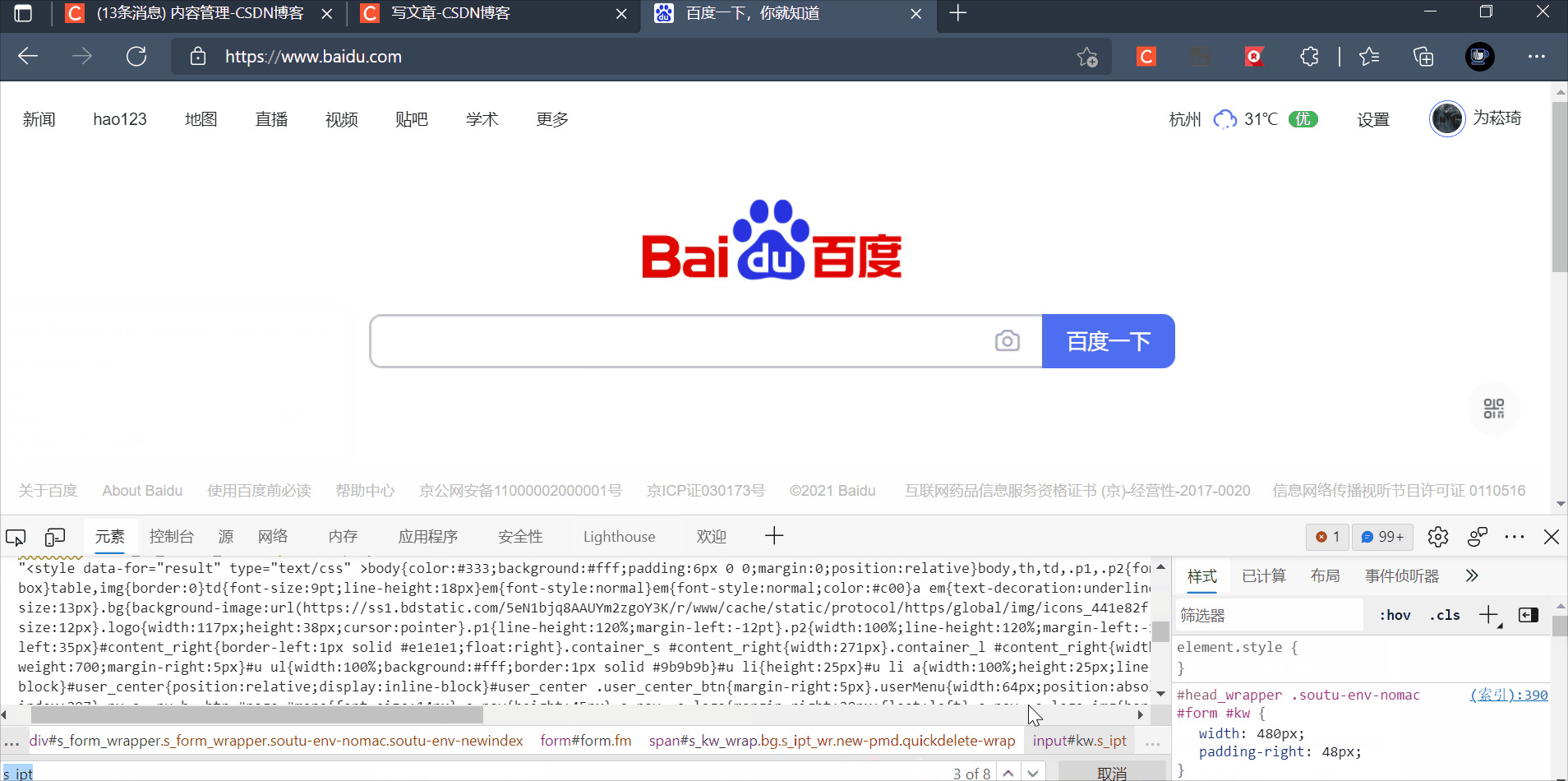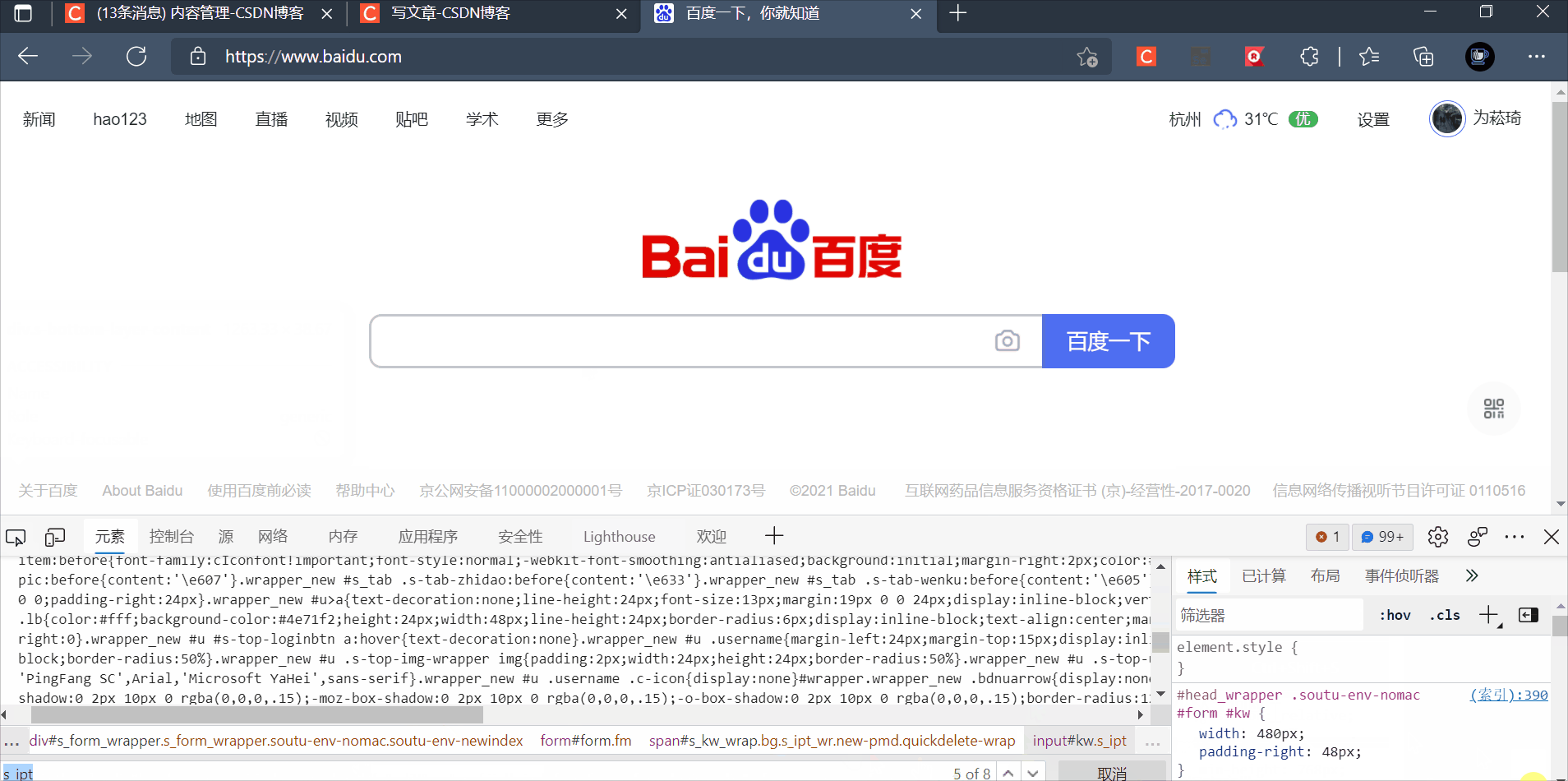
2.8.1.3 class name定位 find_element_by_class_name("id值")
class name定位:HTML规定class来指定元素的类名,通过class属性来定位,一般用的比较少
eg:
查看文本框的class属性
按钮的class属性

#!/usr/bin/env python
# -*- coding:utf8 -*-
# python3.7
# @Time : 2021/09/05 16:42
# @Author : hyh
# @Version : 1.0
# @Desc : TODO
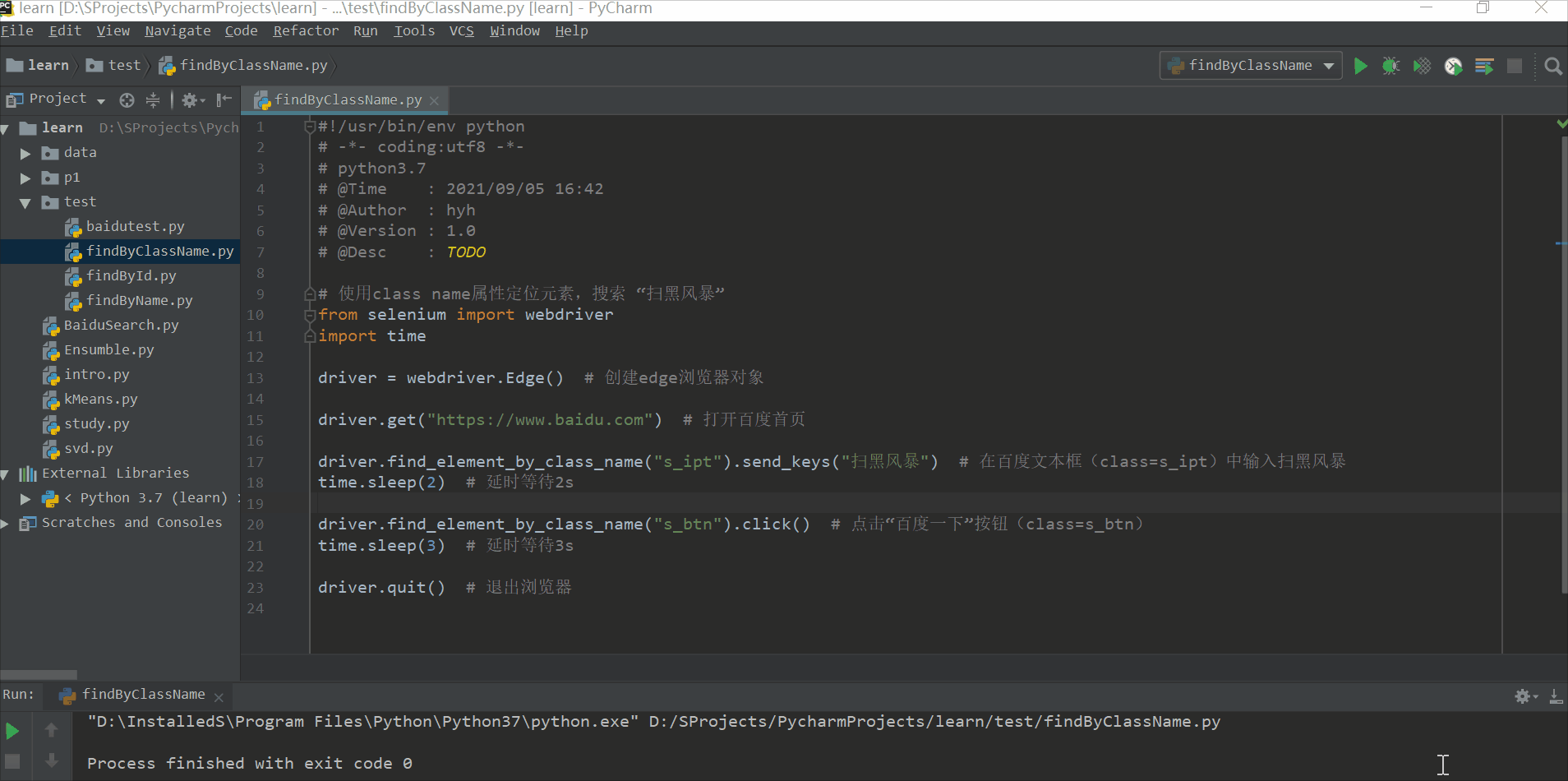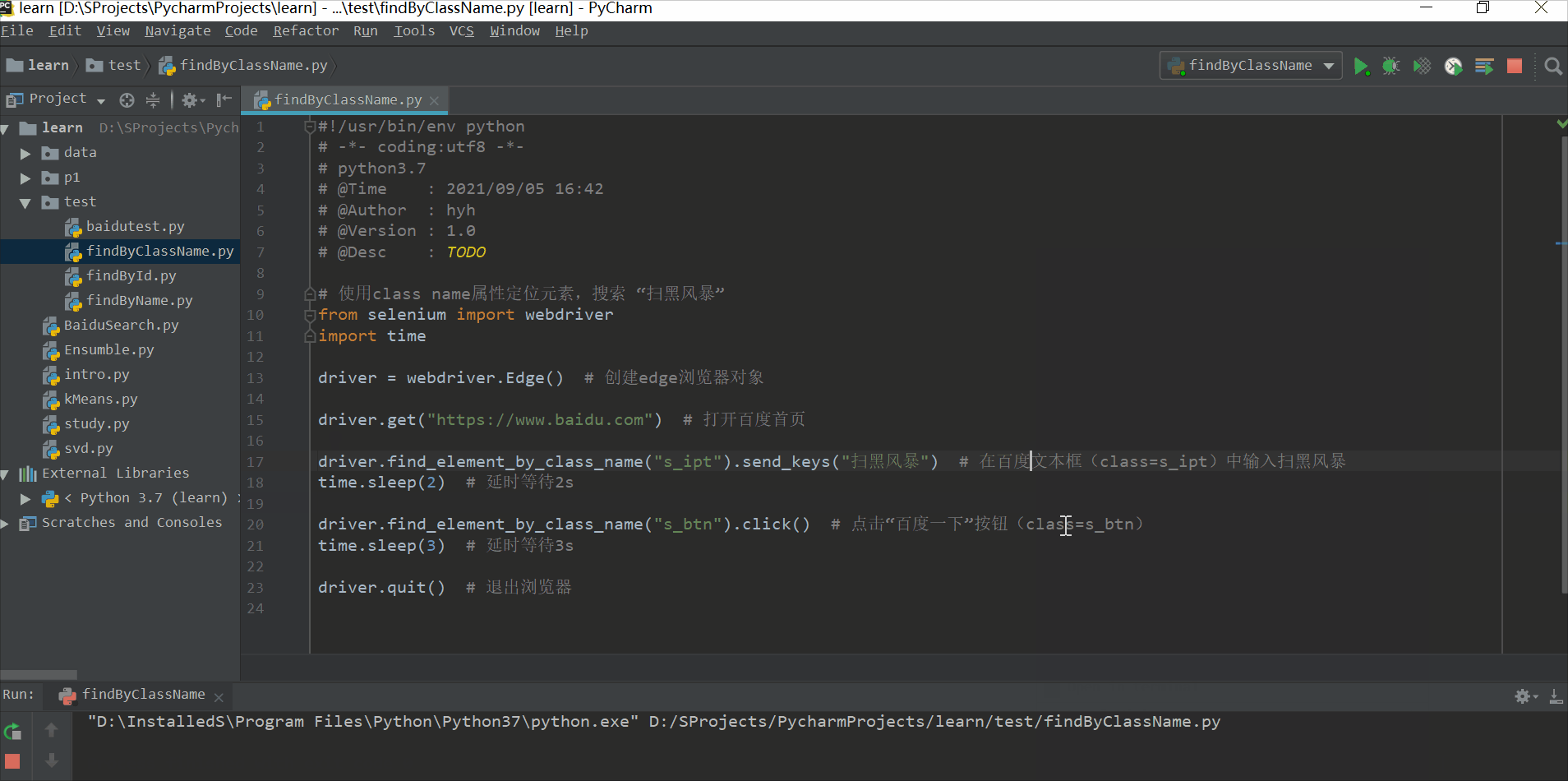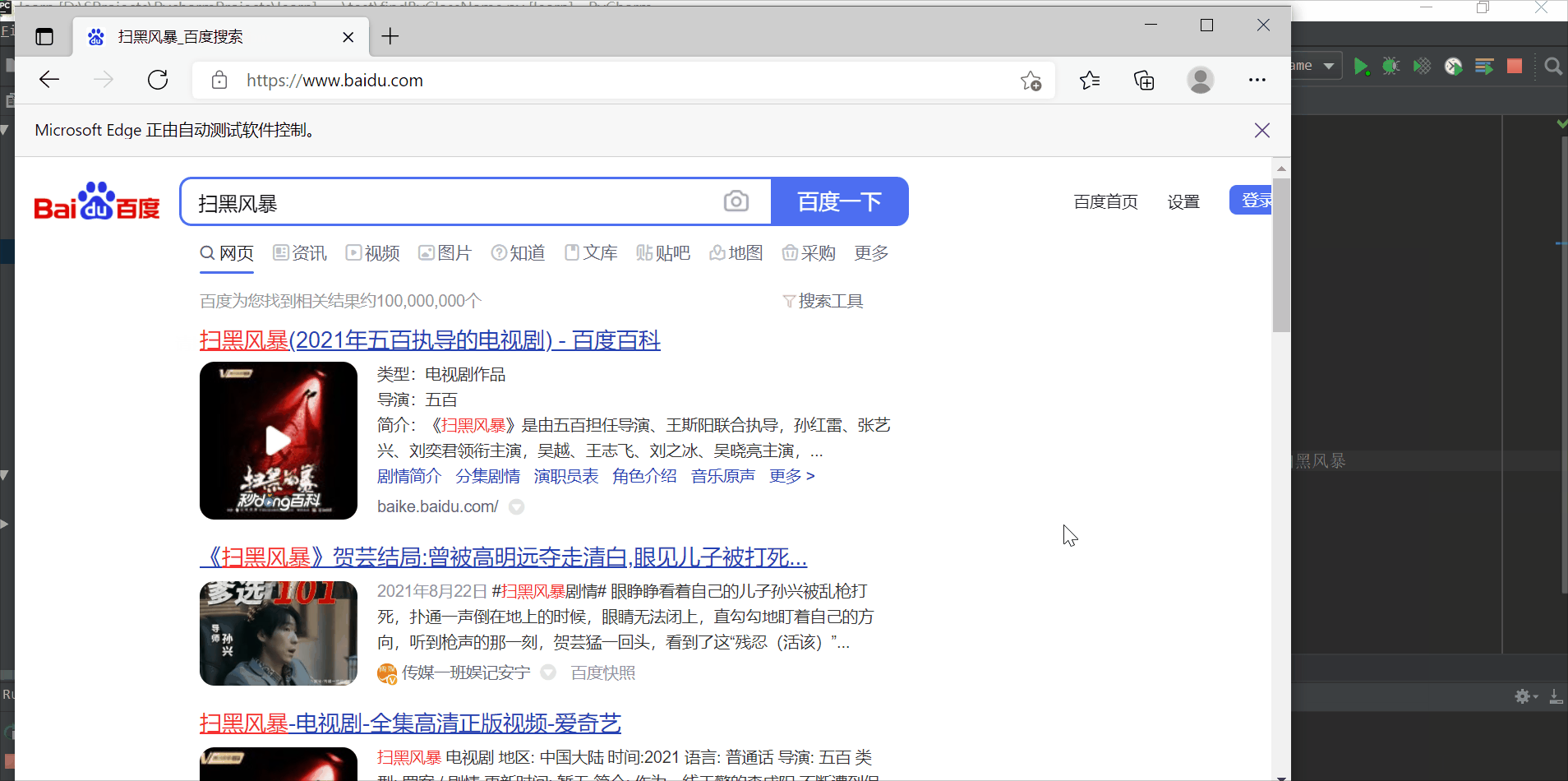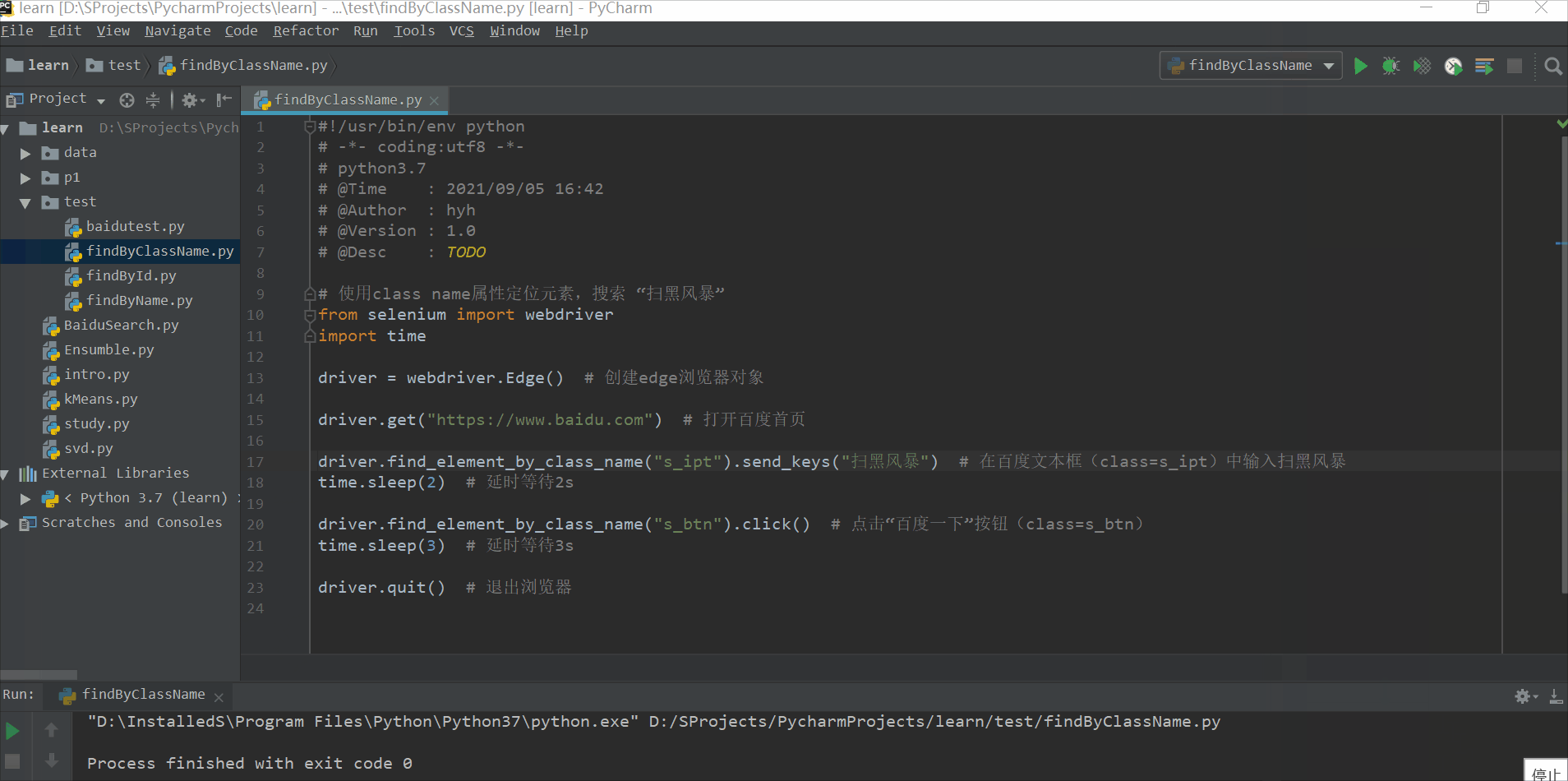
# 使用class name属性定位元素,搜索 “扫黑风暴”
from selenium import webdriver
import time
driver = webdriver.Edge() # 创建edge浏览器对象
driver.get("https://www.baidu.com") # 打开百度首页
driver.find_element_by_class_name("s_ipt").send_keys("扫黑风暴") # 在百度文本框(class=s_ipt)中输入扫黑风暴
time.sleep(2) # 延时等待2s
driver.find_element_by_class_name("s_btn").click() # 点击“百度一下”按钮(class=s_btn)
time.sleep(3) # 延时等待3s
driver.quit() # 退出浏览器
2.8.1.4 tag name find_element_by_tag_name("标签名")
tag定位:HTML的本质就是通过tag来定义实现不同的功能,每一个元素本质上也是一个tag,但tag往往用来定义一类功能,页面中可能会有多个同名标签,所以通过tag识别某个元素的概率很低。
eg: 略
2.8.1.5 link text定位 find_element_by_link_text("链接的显示文本")
Link text定位:是定位标签文本信息的一种方式。
eg:
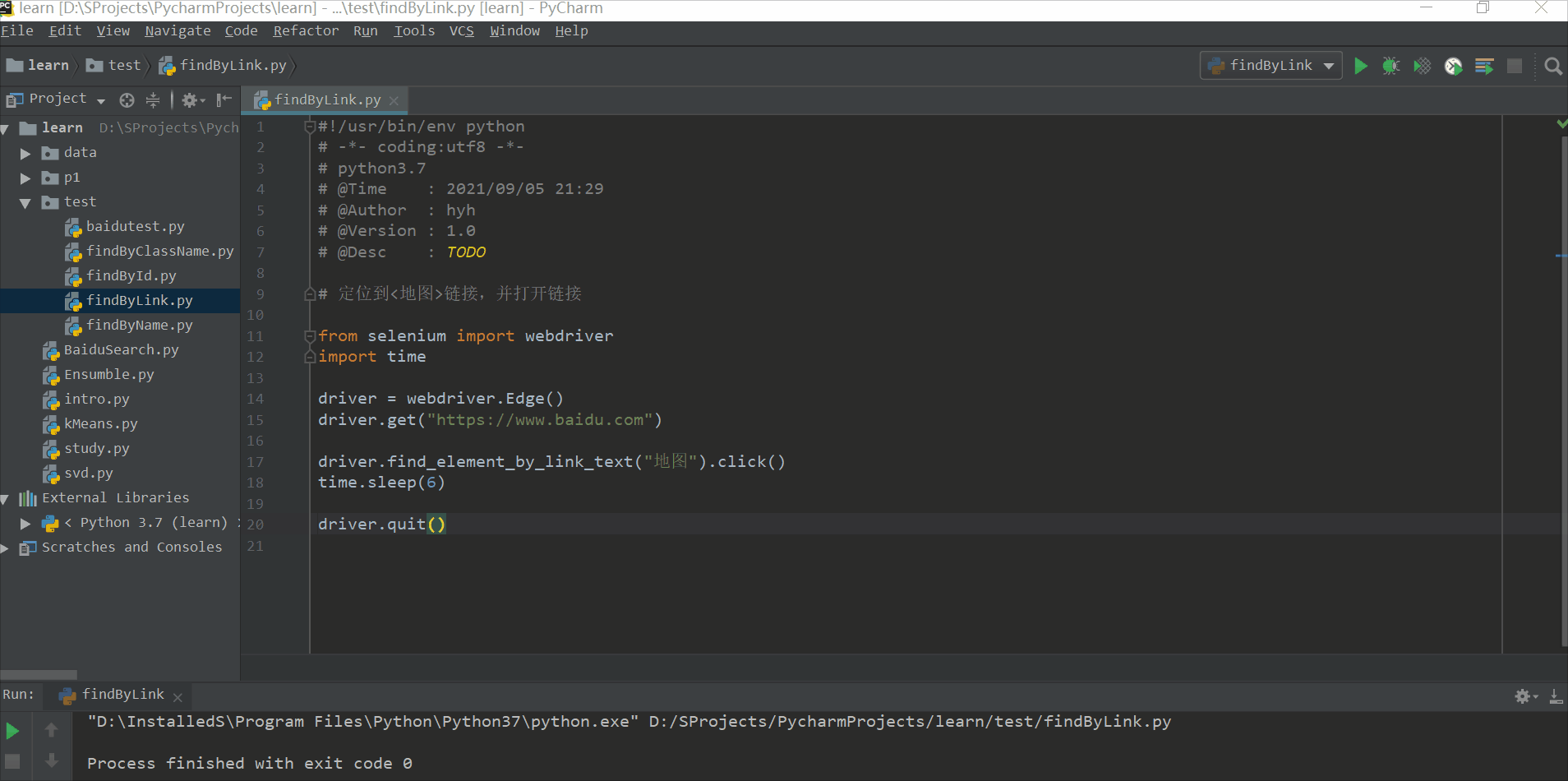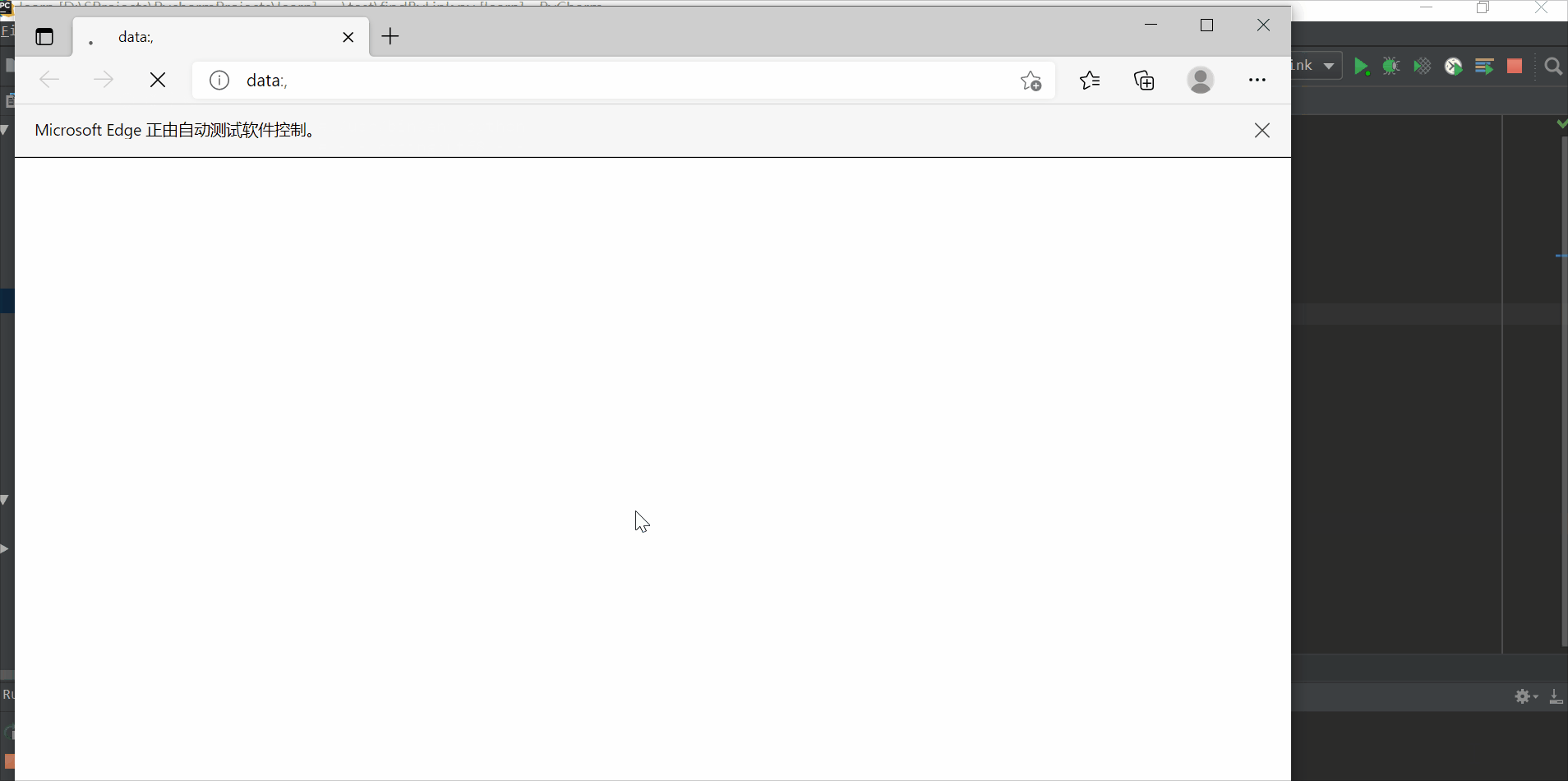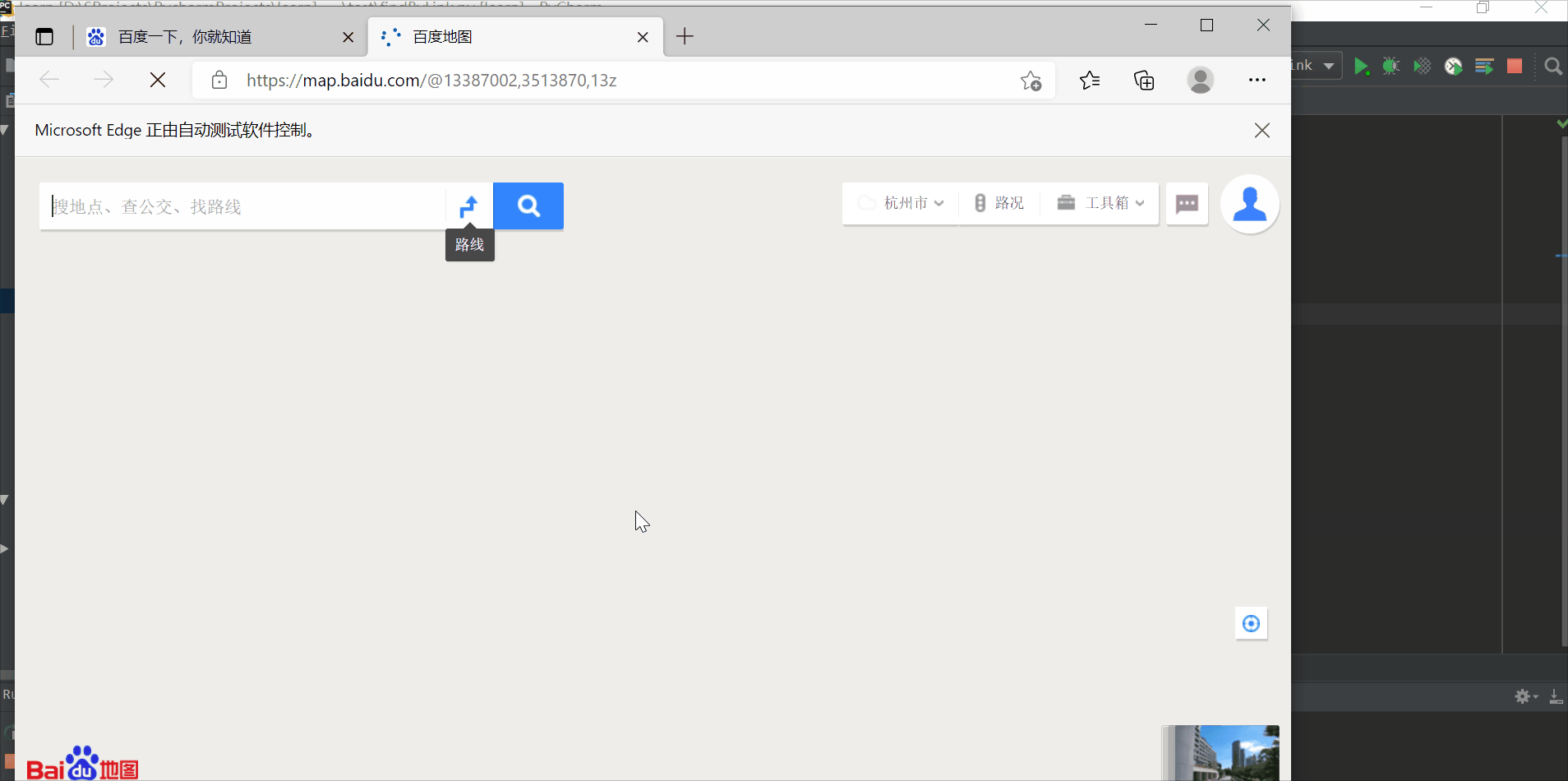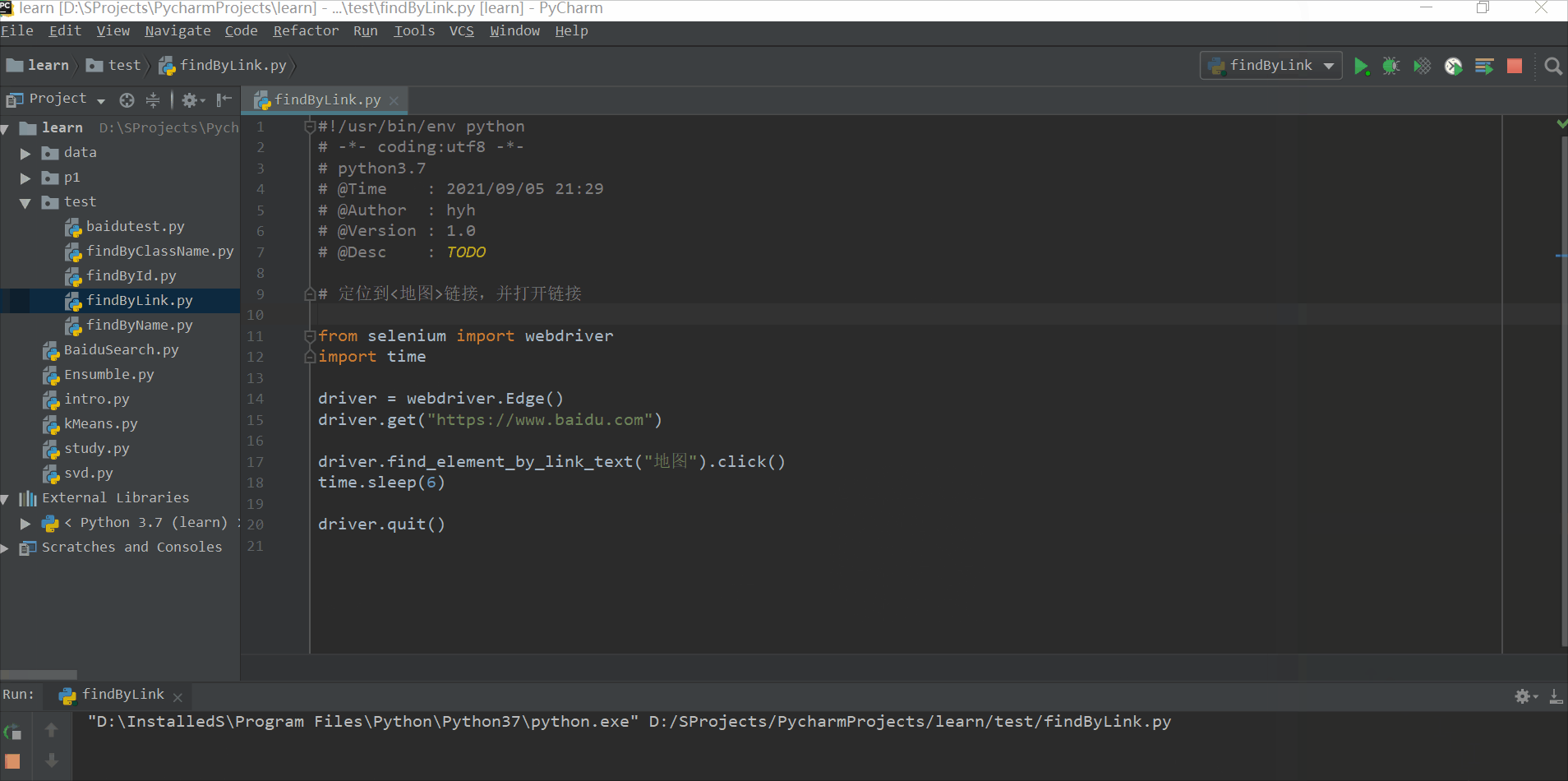
定位到<地图>链接,并打开链接

#!/usr/bin/env python
# -*- coding:utf8 -*-
# python3.7
# @Time : 2021/09/05 21:29
# @Author : hyh
# @Version : 1.0
# @Desc : TODO
# 定位到<地图>链接,并打开链接
from selenium import webdriver
import time
driver = webdriver.Edge()
driver.get("https://www.baidu.com")
driver.find_element_by_link_text("地图").click()
time.sleep(6)
driver.quit()
2.8.1.6 partial link text定位 find_element_by_partical_link_text("部分链接的显示文本")
partial link text定位:是对link定位的一种补充,有些文本链接比较长,这时候我们可以取用文本链接的一部分定位,只要这部分信息可以唯一的识别这个链接,如果重复,会取第一个定位到的元素。
适用于链接的文本太长的情况
eg:
定位到<学术>链接,并打开它

#!/usr/bin/env python
# -*- coding:utf8 -*-
# python3.7
# @Time : 2021/09/05 21:36
# @Author : hyh
# @Version : 1.0
# @Desc : TODO
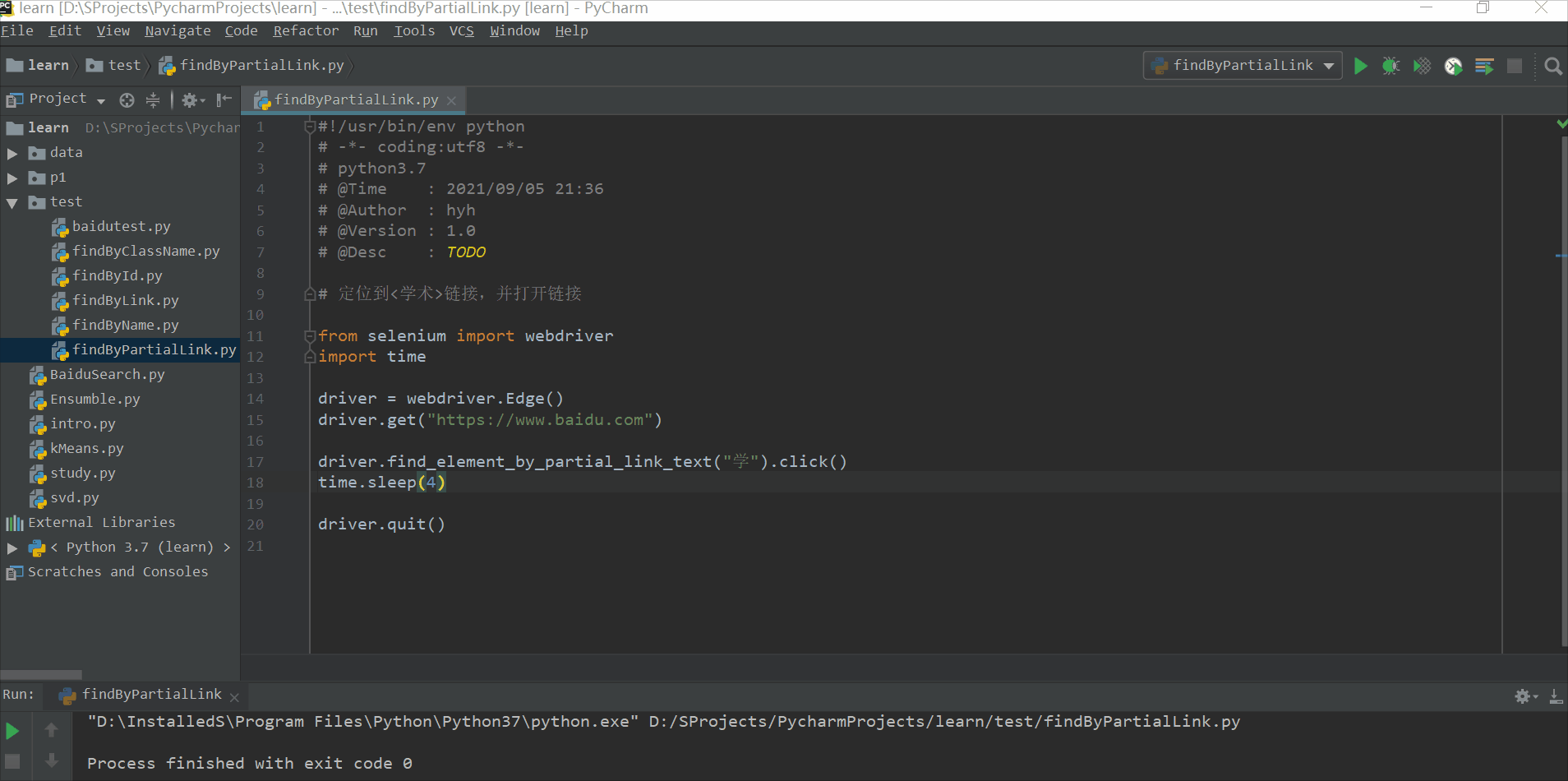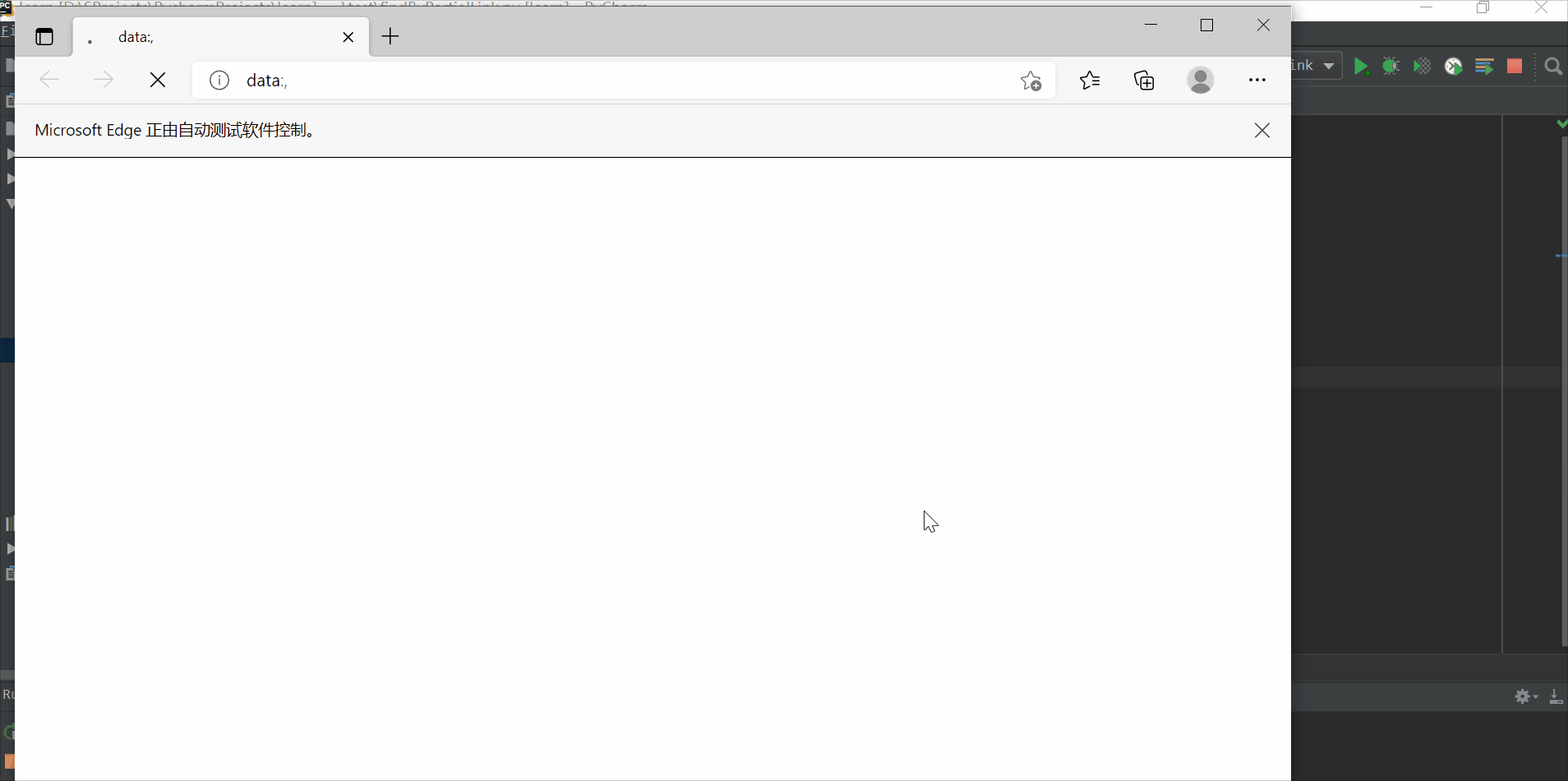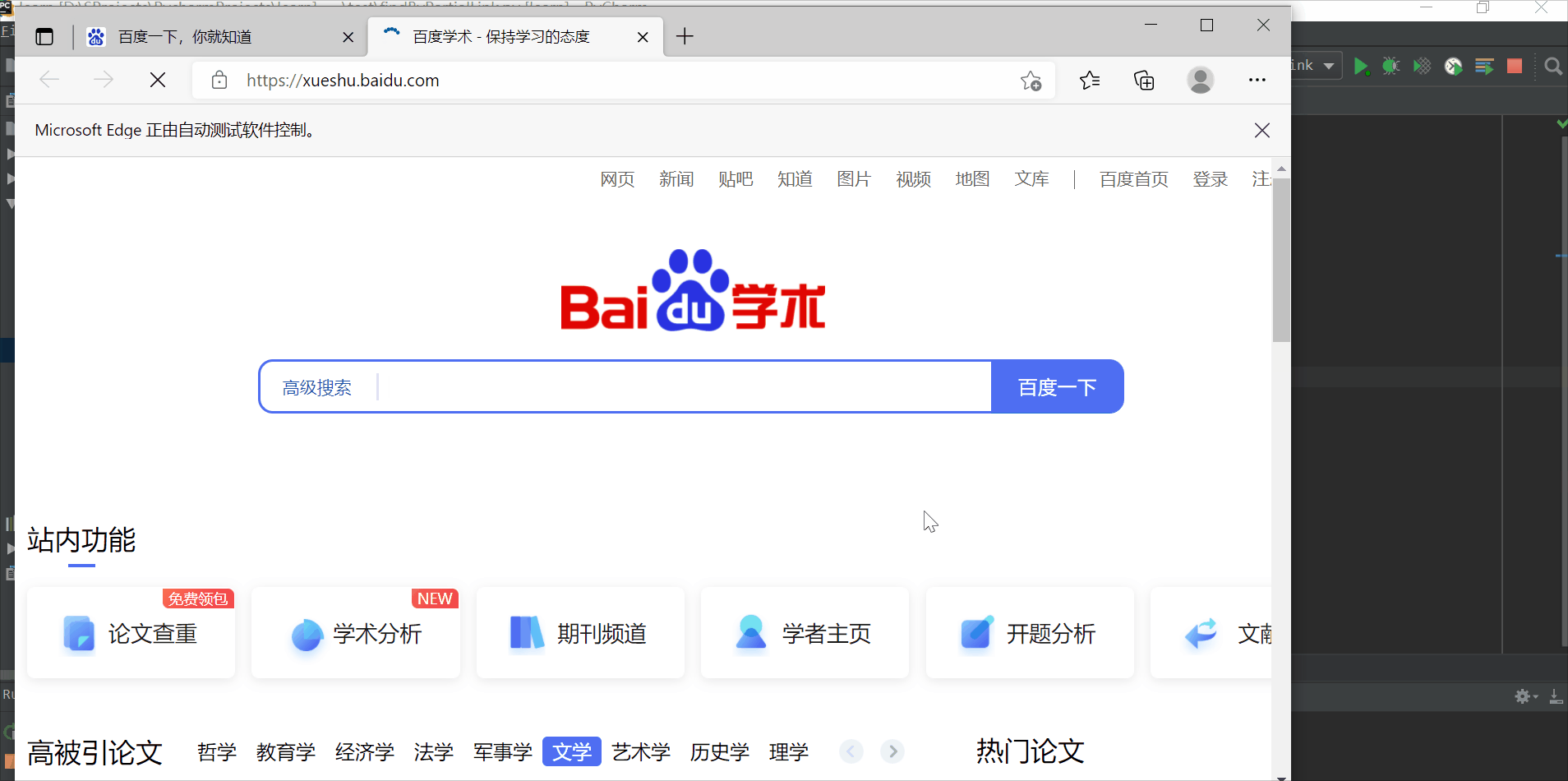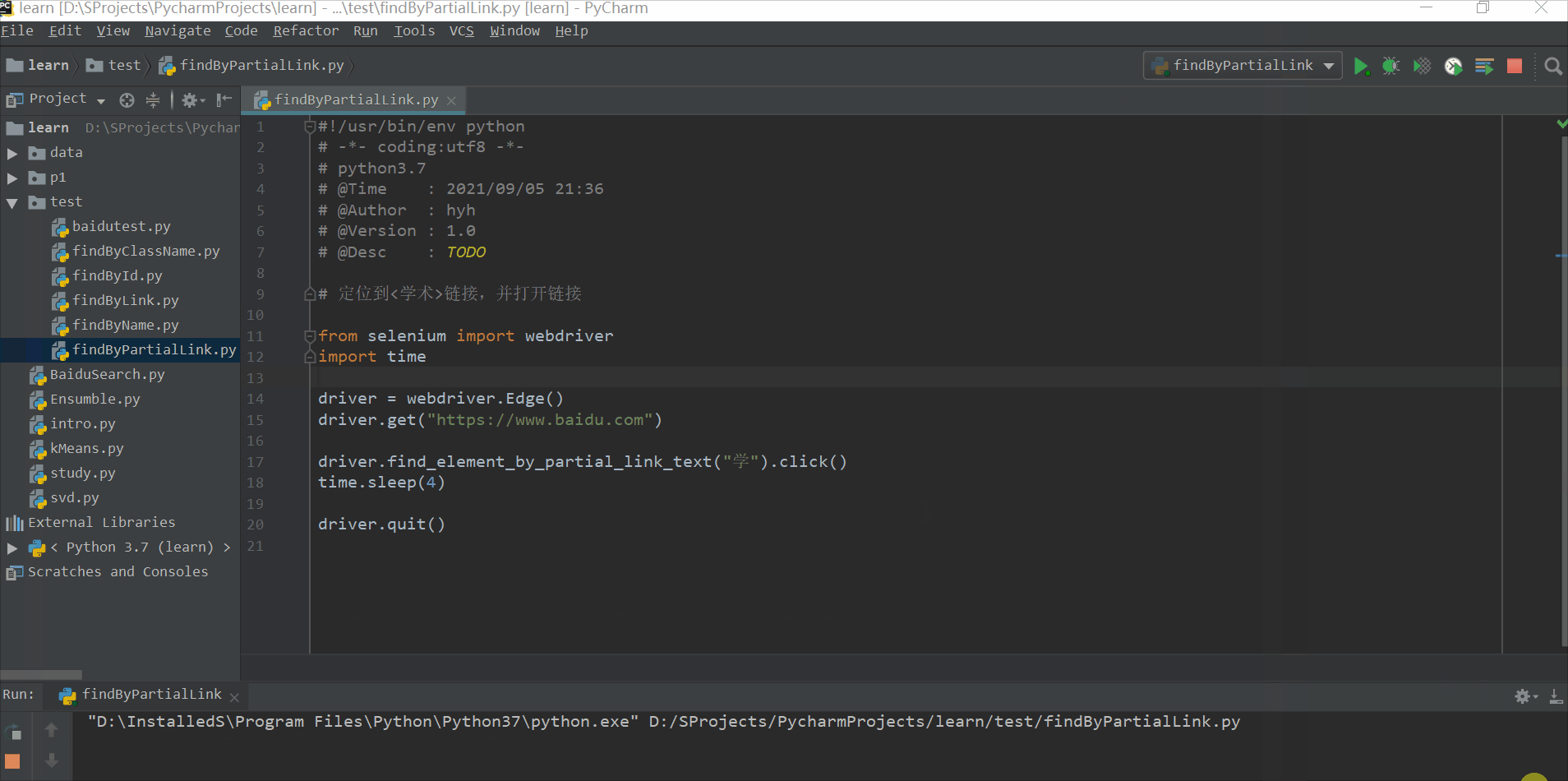
# 定位到<学术>链接,并打开链接
from selenium import webdriver
import time
driver = webdriver.Edge()
driver.get("https://www.baidu.com")
driver.find_element_by_partial_link_text("学").click()
time.sleep(4)
driver.quit()
2.8.1.7 xpath定位 find_element_by_xpath("xpath")
xpath定位:xpath是一种在XML(HTML)文档中定位元素的语言,因为HTML可以看作XML的一种实现,所以Selenium用户可以使用这种强大的语言在web应用中定位元素。(标签树型结构定位,类似于路径定位)
符号:
根节点:/
相对节点://
父子节点:/
兄弟节点:[n],n[1,+∞),1也可以不用写
xpath多种定位方式
1)绝对路径定位 /
2)利用元素属性定位 @id或@class或@name
3)层级与属性结合定位
4)使用逻辑运算符 and或or
快捷获取xpath,*表示通配符,如果能确定是哪个标签,就直接写标签名,否则就直接*,提高定位效率。

或者获取全部路径

eg:
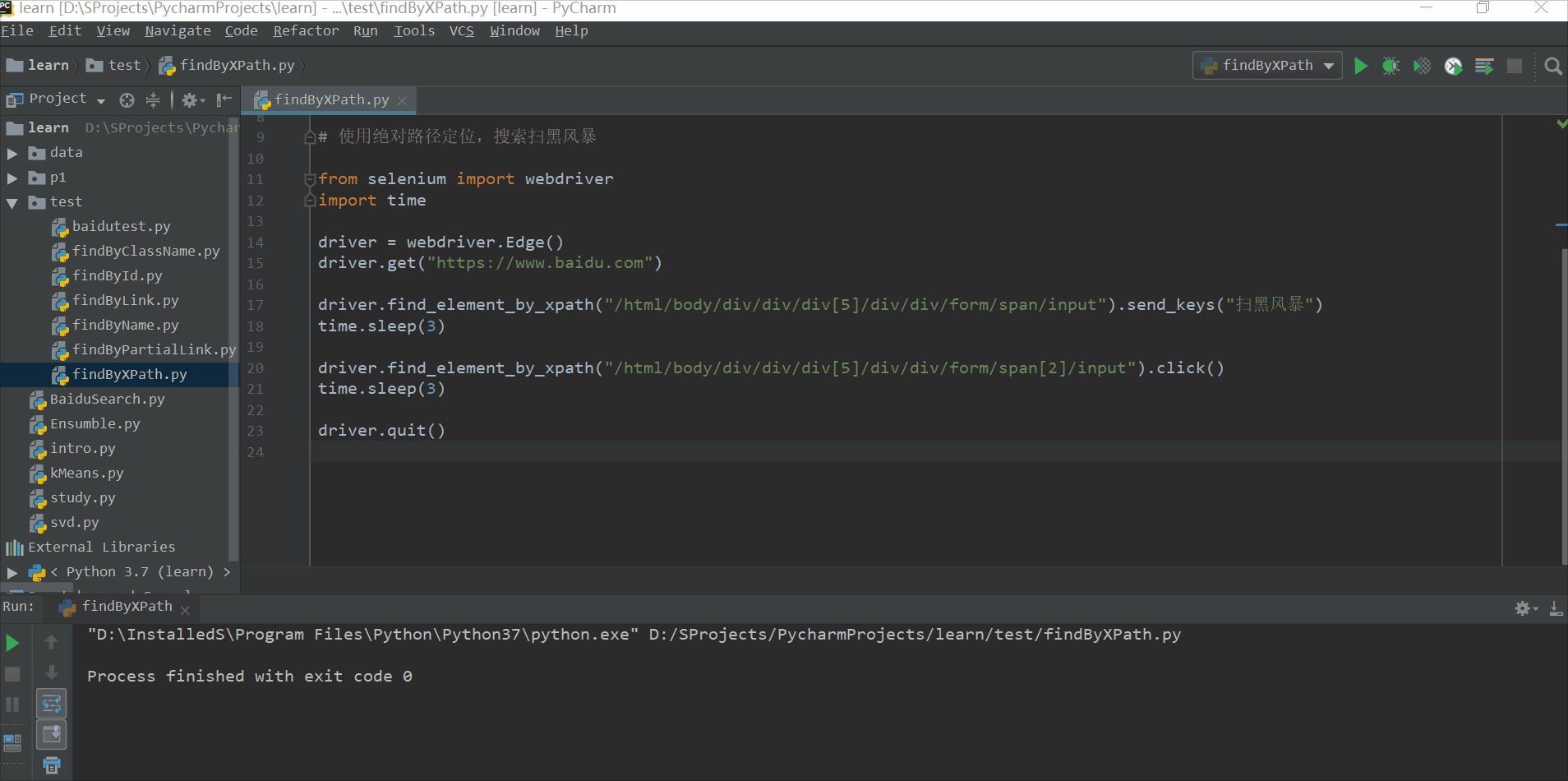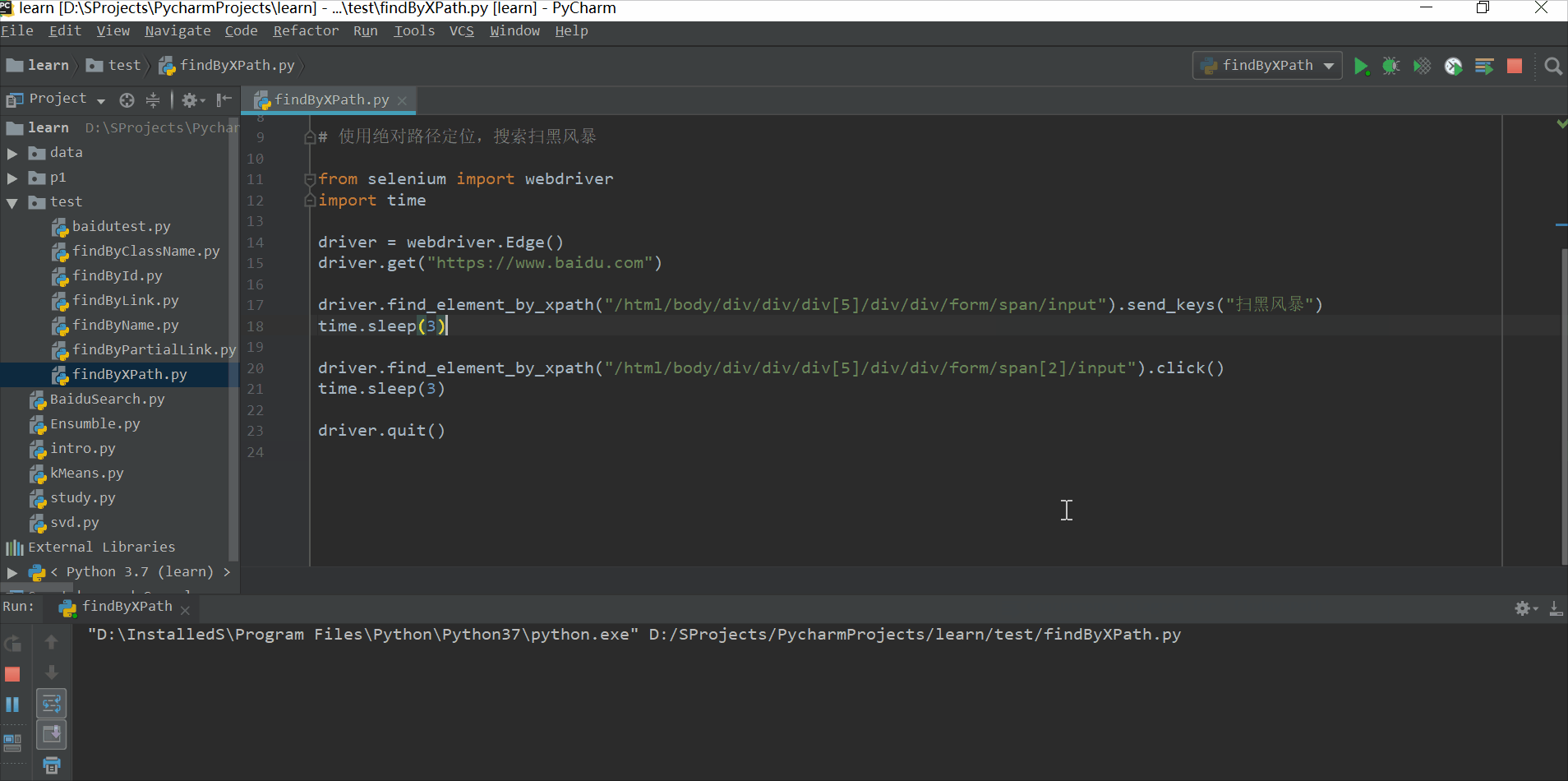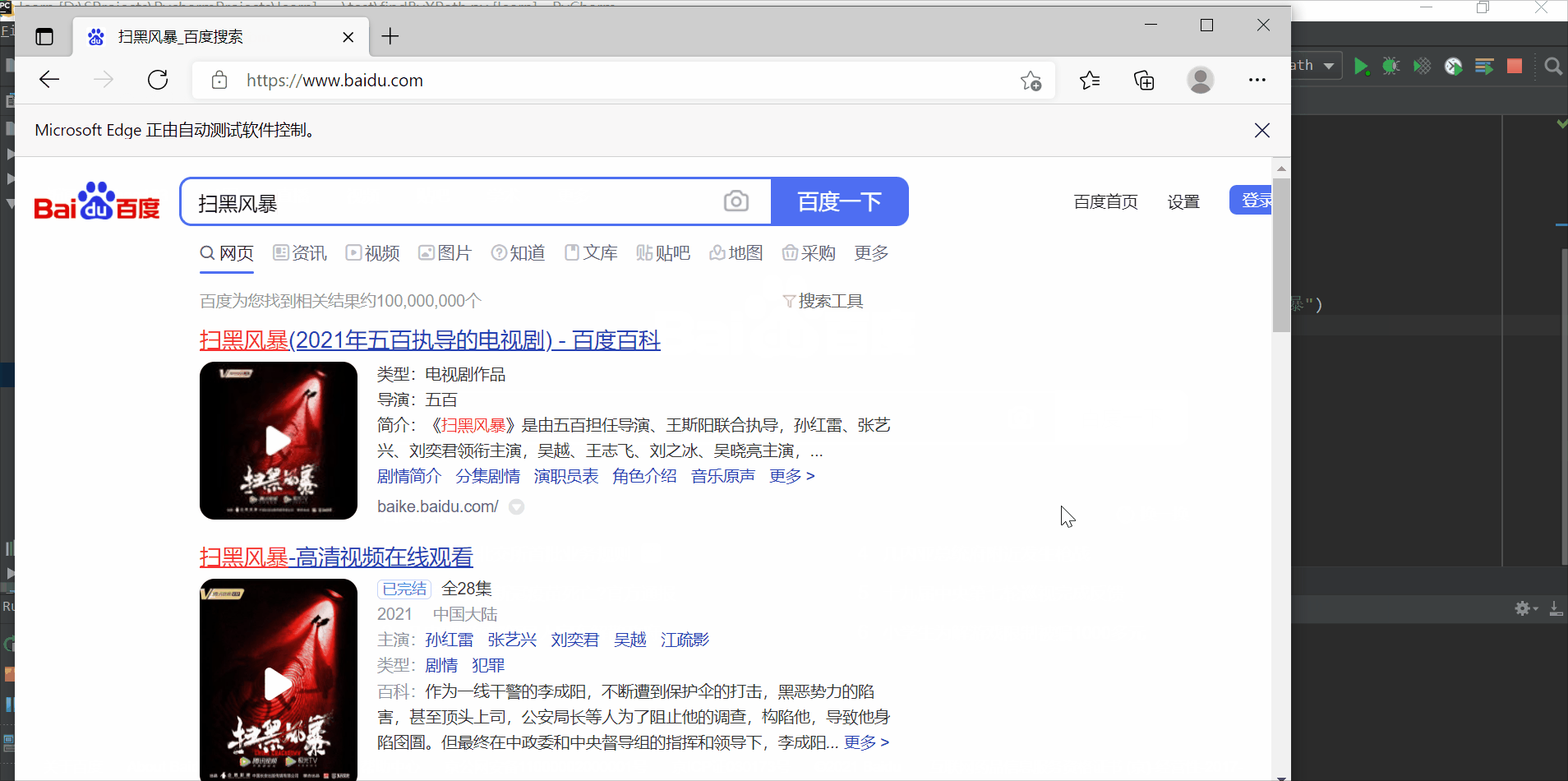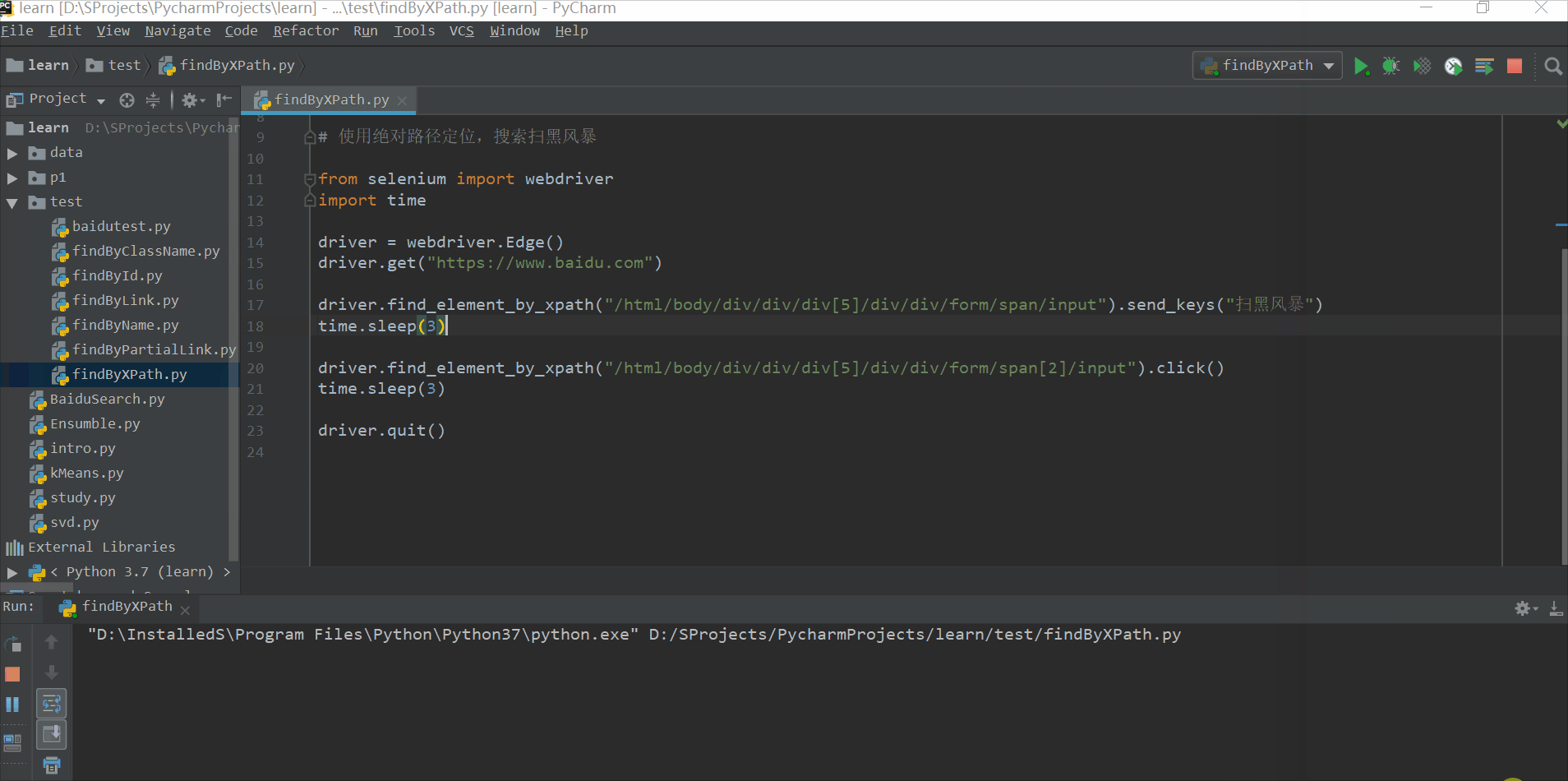
使用绝对路径定位,搜索扫黑风暴
#!/usr/bin/env python
# -*- coding:utf8 -*-
# python3.7
# @Time : 2021/09/05 22:02
# @Author : hyh
# @Version : 1.0
# @Desc : TODO
# 使用绝对路径定位,搜索扫黑风暴
from selenium import webdriver
import time
driver = webdriver.Edge()
driver.get("https://www.baidu.com")
driver.find_element_by_xpath("/html/body/div/div/div[5]/div/div/form/span/input").send_keys("扫黑风暴")
time.sleep(3)
driver.find_element_by_xpath("/html/body/div/div/div[5]/div/div/form/span[2]/input").click()
time.sleep(3)
driver.quit()
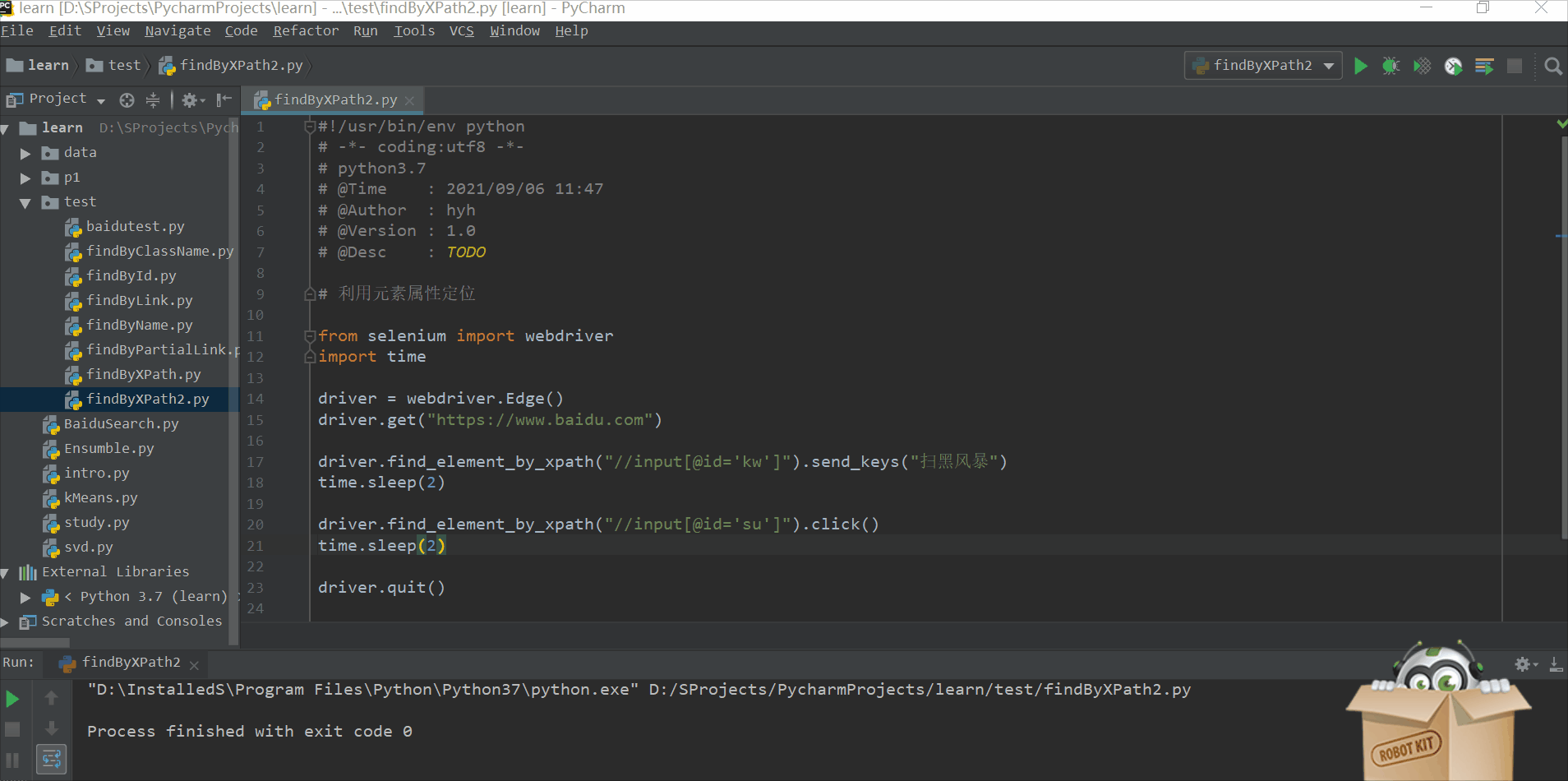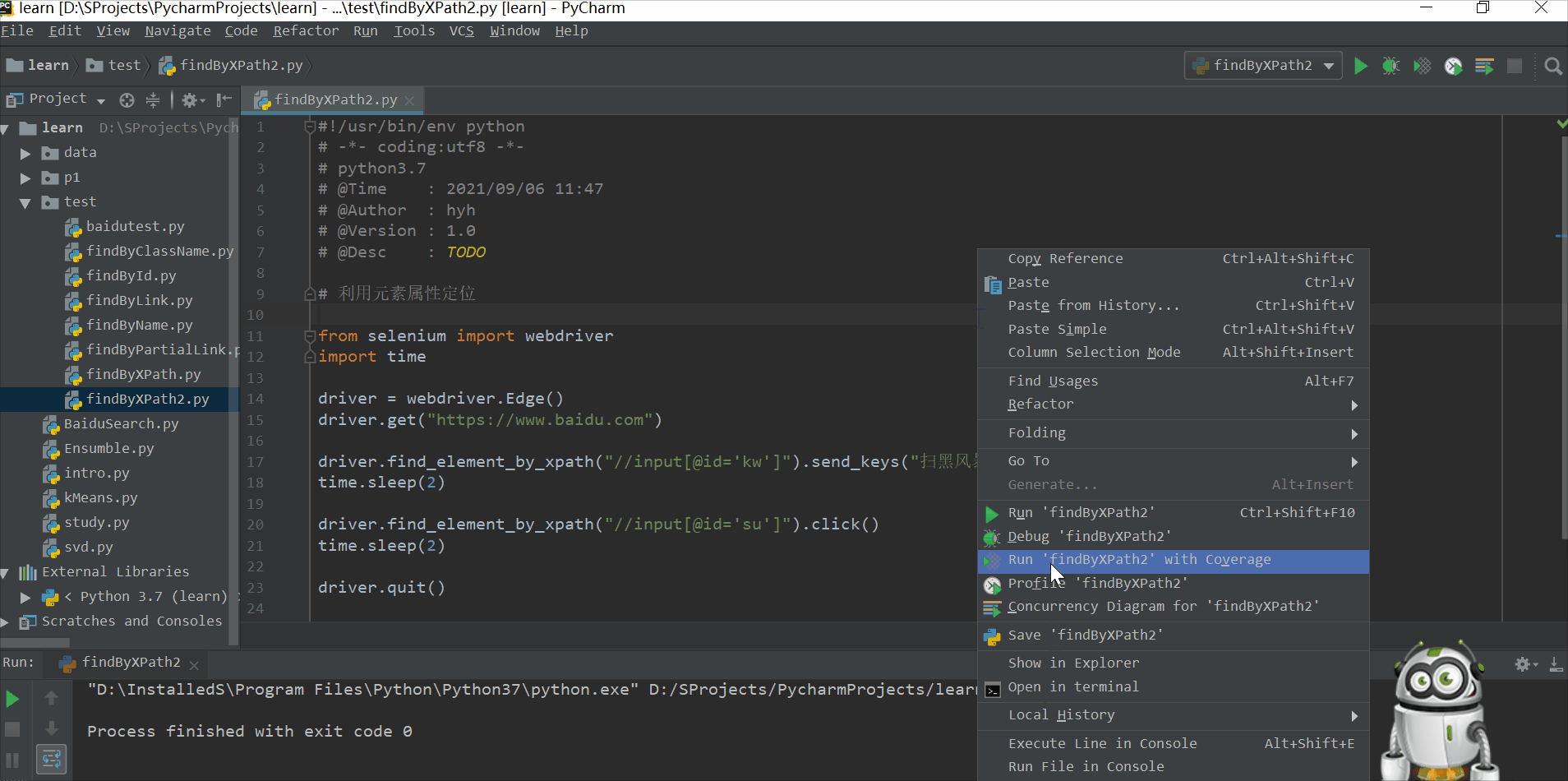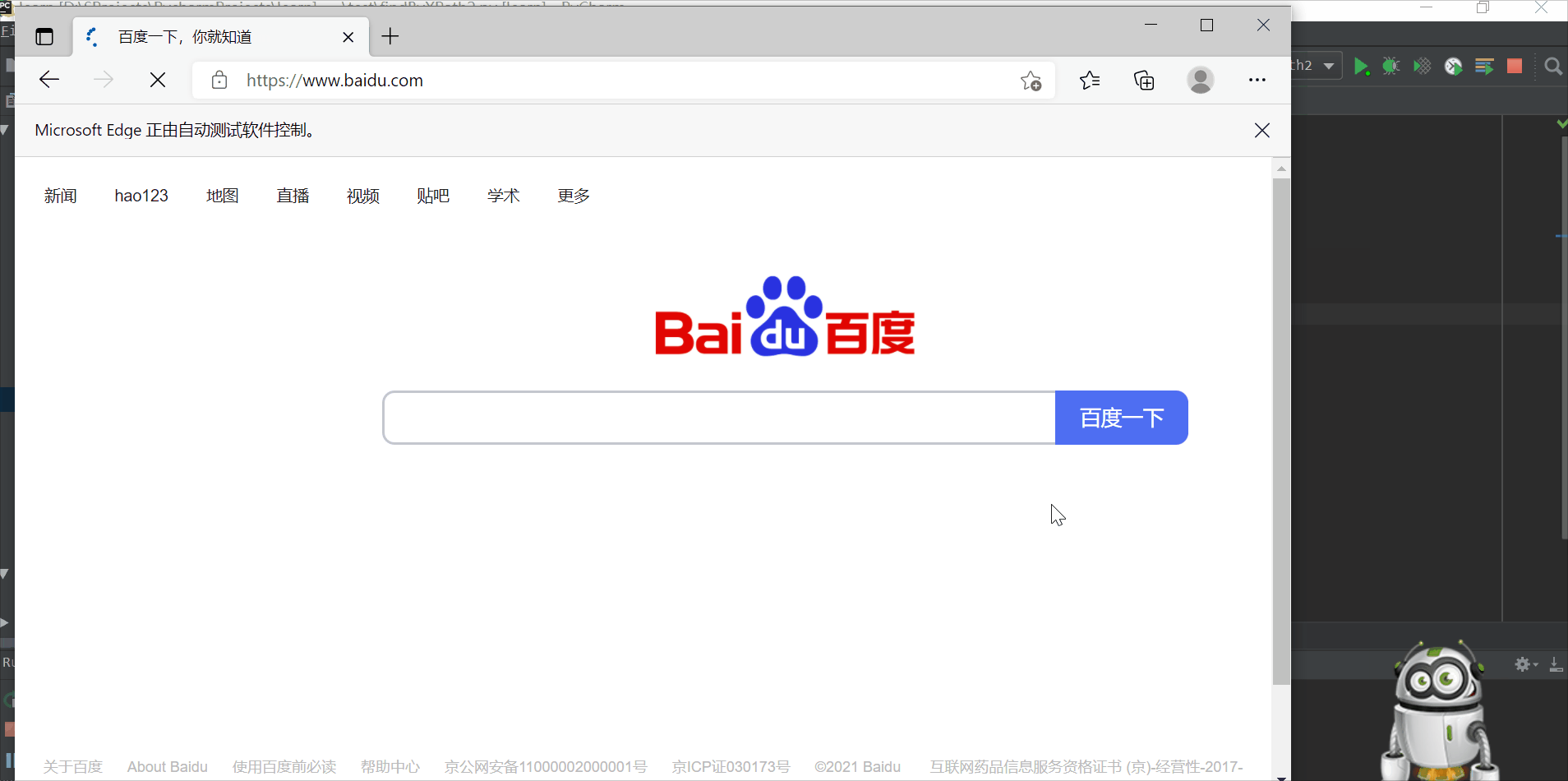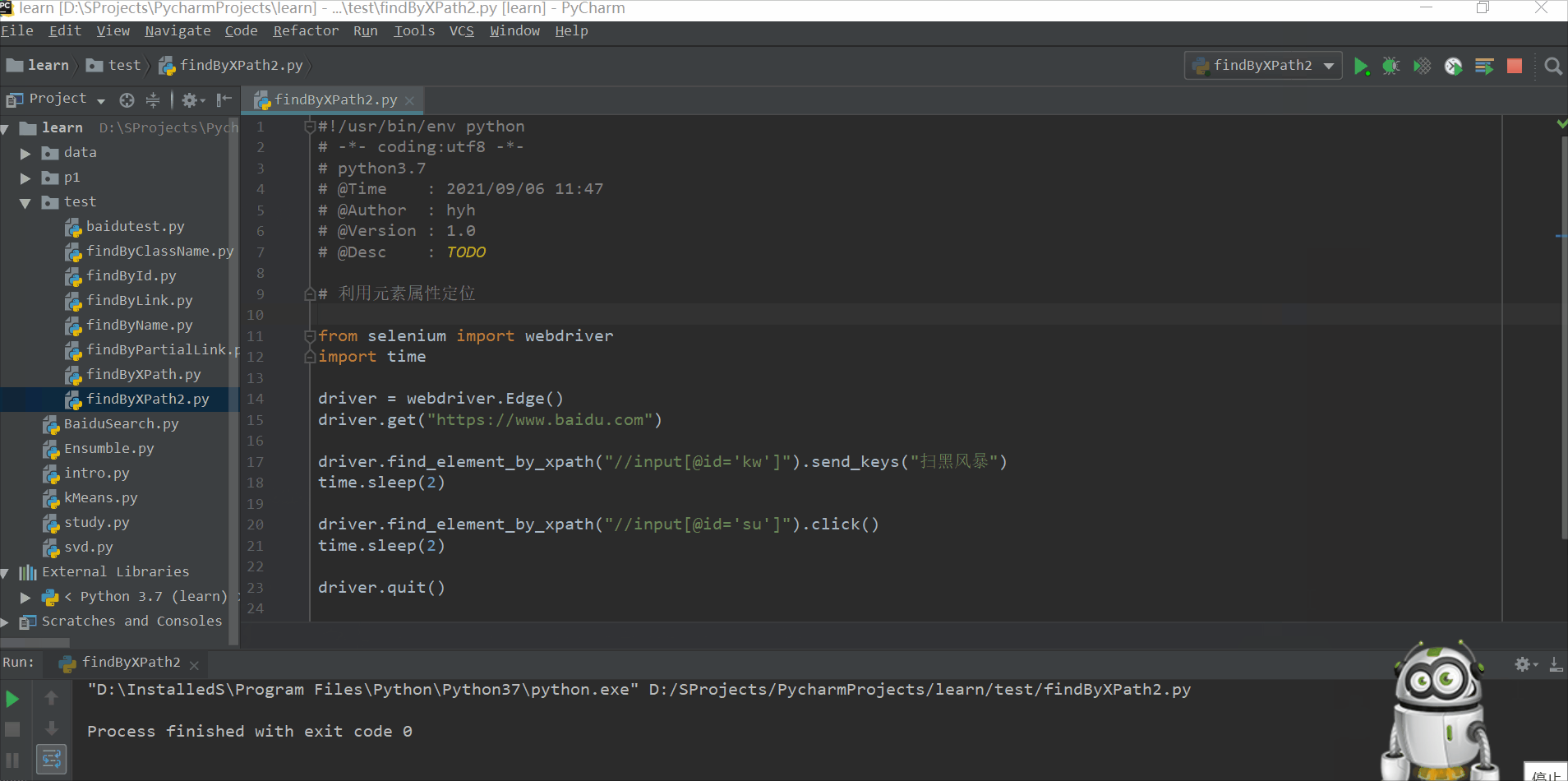
利用元素属性定位(比如id)
#!/usr/bin/env python
# -*- coding:utf8 -*-
# python3.7
# @Time : 2021/09/06 11:47
# @Author : hyh
# @Version : 1.0
# @Desc : TODO
# 利用元素属性定位
from selenium import webdriver
import time
driver = webdriver.Edge()
driver.get("https://www.baidu.com")
driver.find_element_by_xpath("//input[@id='kw']").send_keys("扫黑风暴")
time.sleep(2)
driver.find_element_by_xpath("//input[@id='su']").click()
time.sleep(2)
driver.quit()
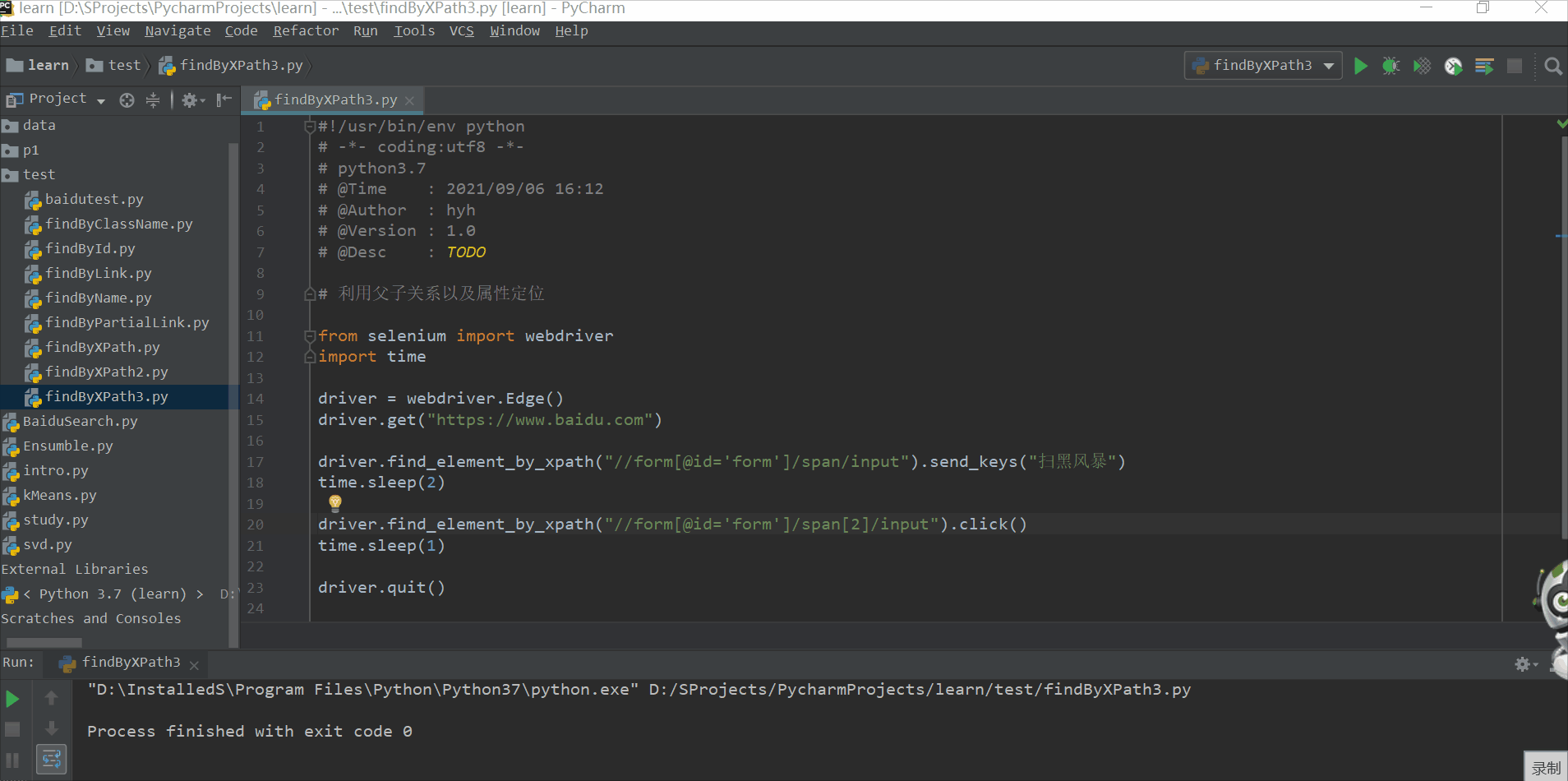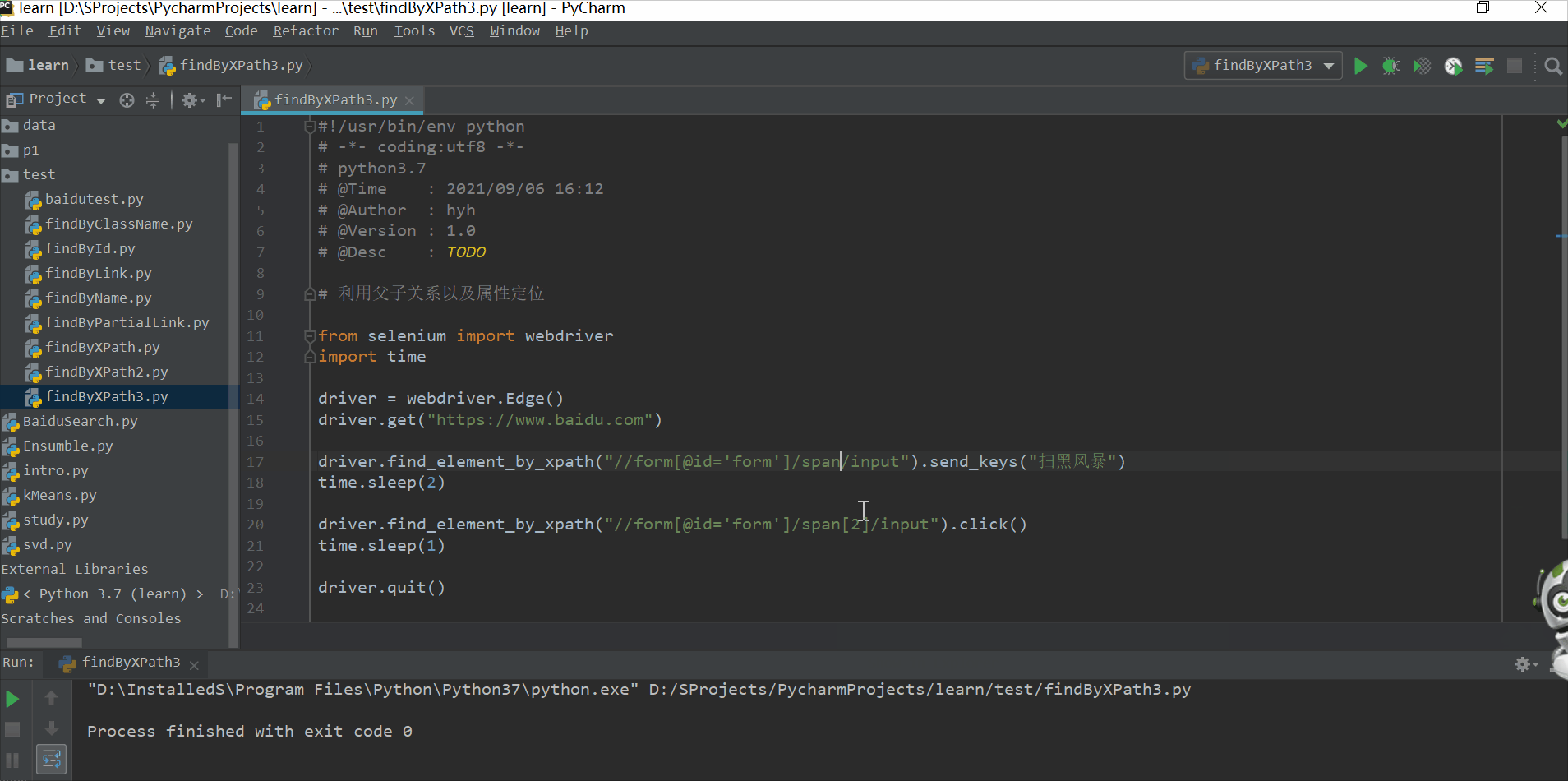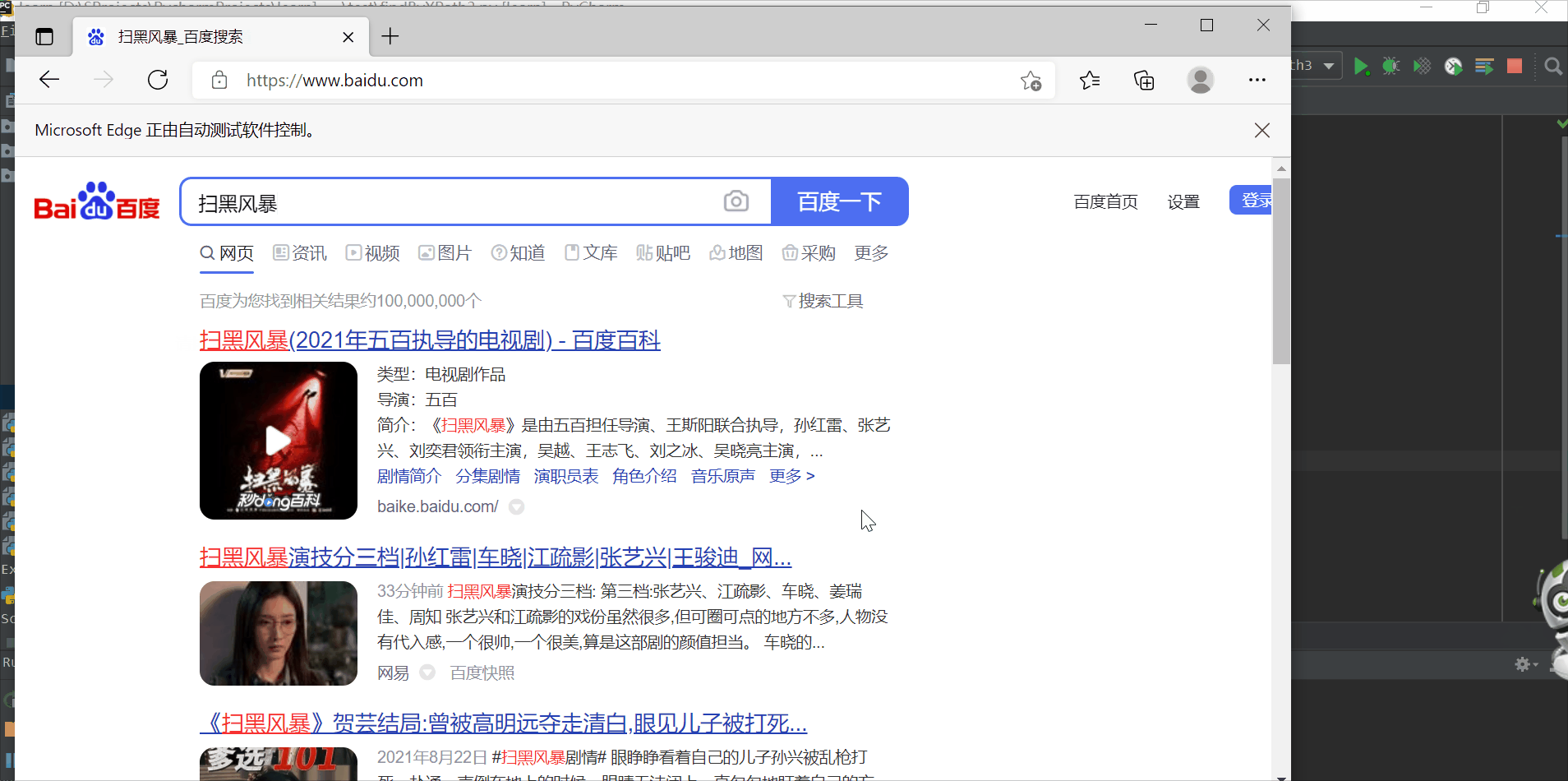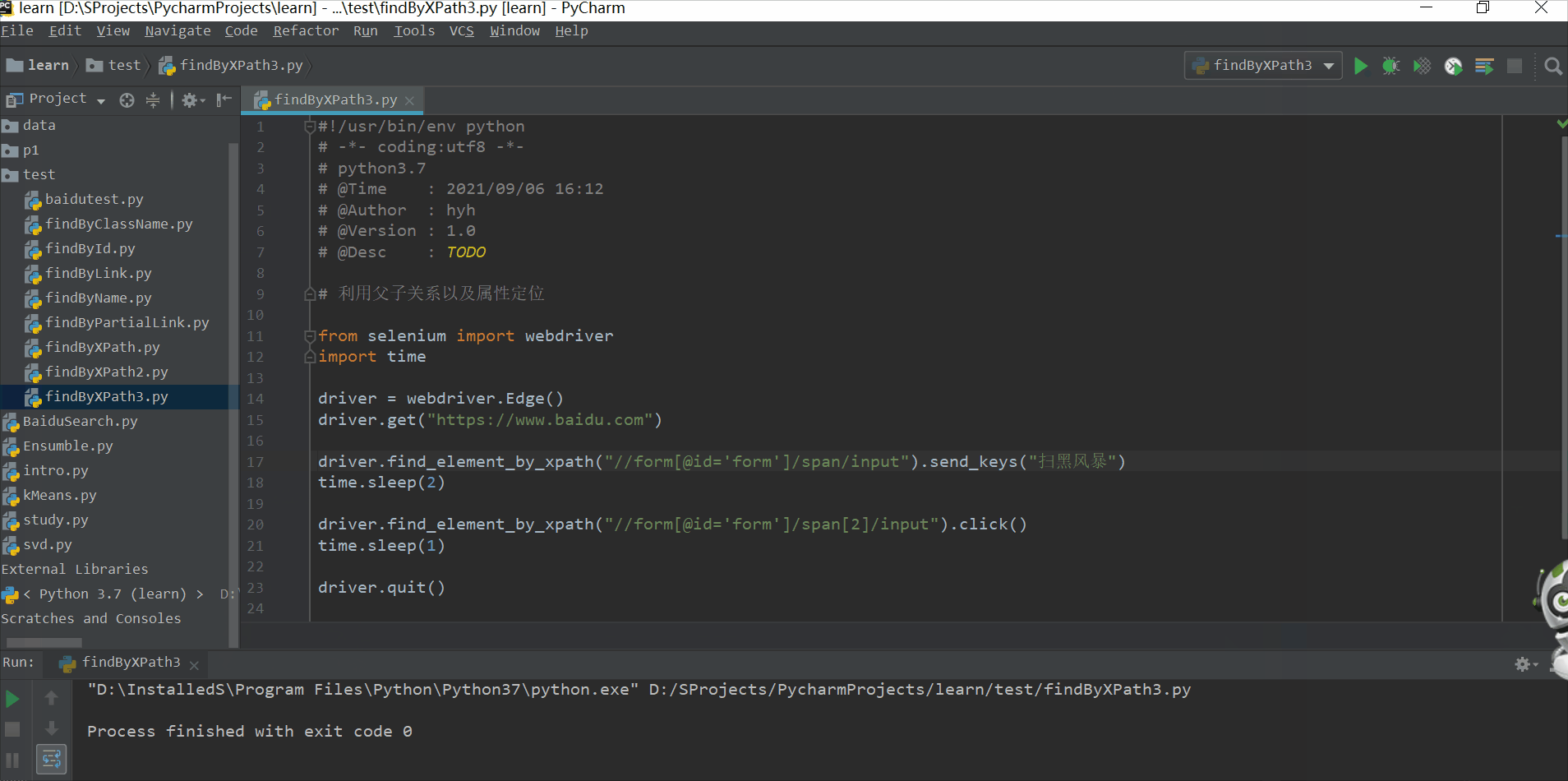
利用父子关系(层级)以及属性定位
#!/usr/bin/env python
# -*- coding:utf8 -*-
# python3.7
# @Time : 2021/09/06 16:12
# @Author : hyh
# @Version : 1.0
# @Desc : TODO
# 利用父子关系以及属性定位
from selenium import webdriver
import time
driver = webdriver.Edge()
driver.get("https://www.baidu.com")
driver.find_element_by_xpath("//form[@id='form']/span/input").send_keys("扫黑风暴")
time.sleep(2)
driver.find_element_by_xpath("//form[@id='form']/span[2]/input").click()
time.sleep(1)
driver.quit()
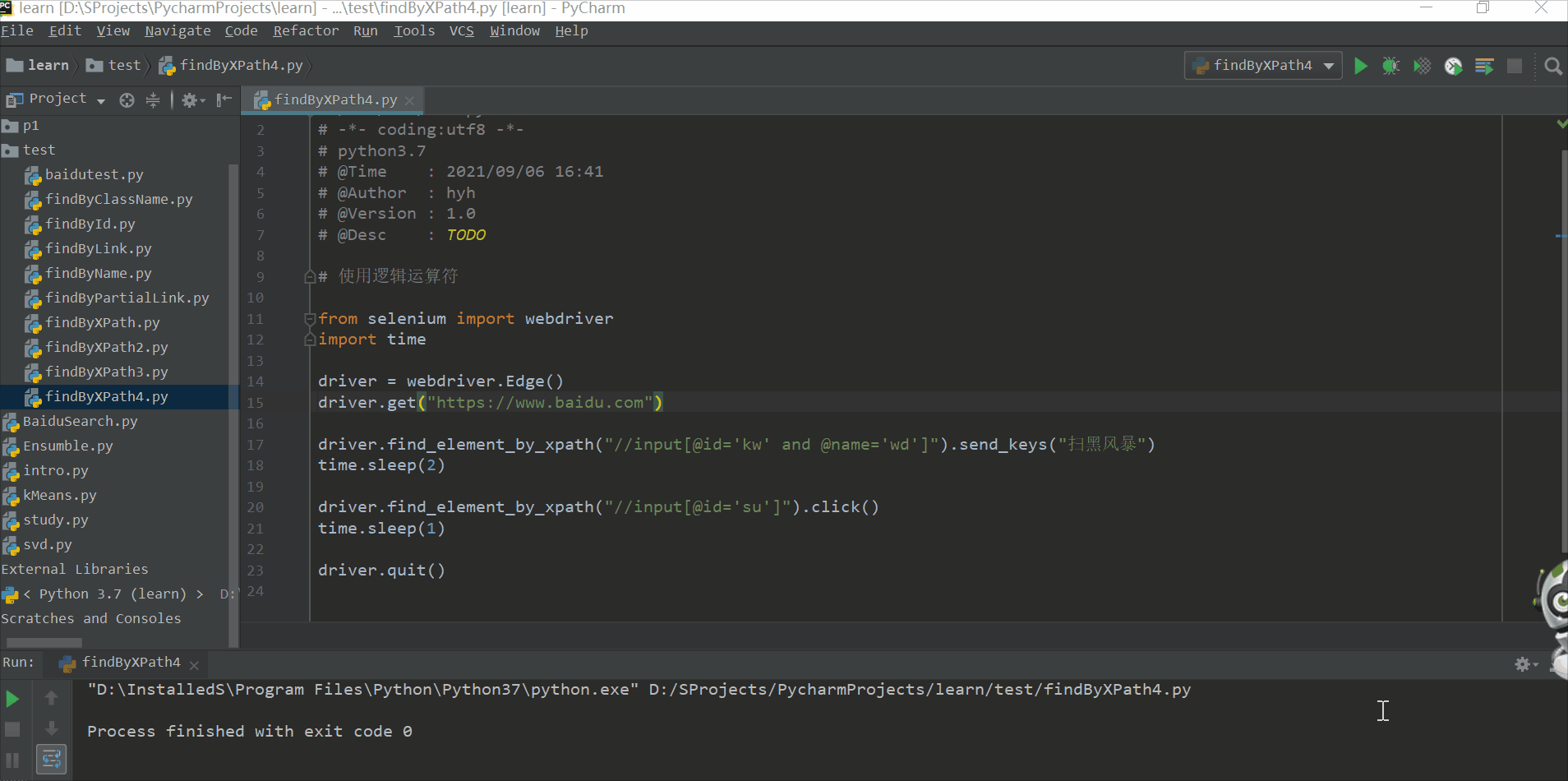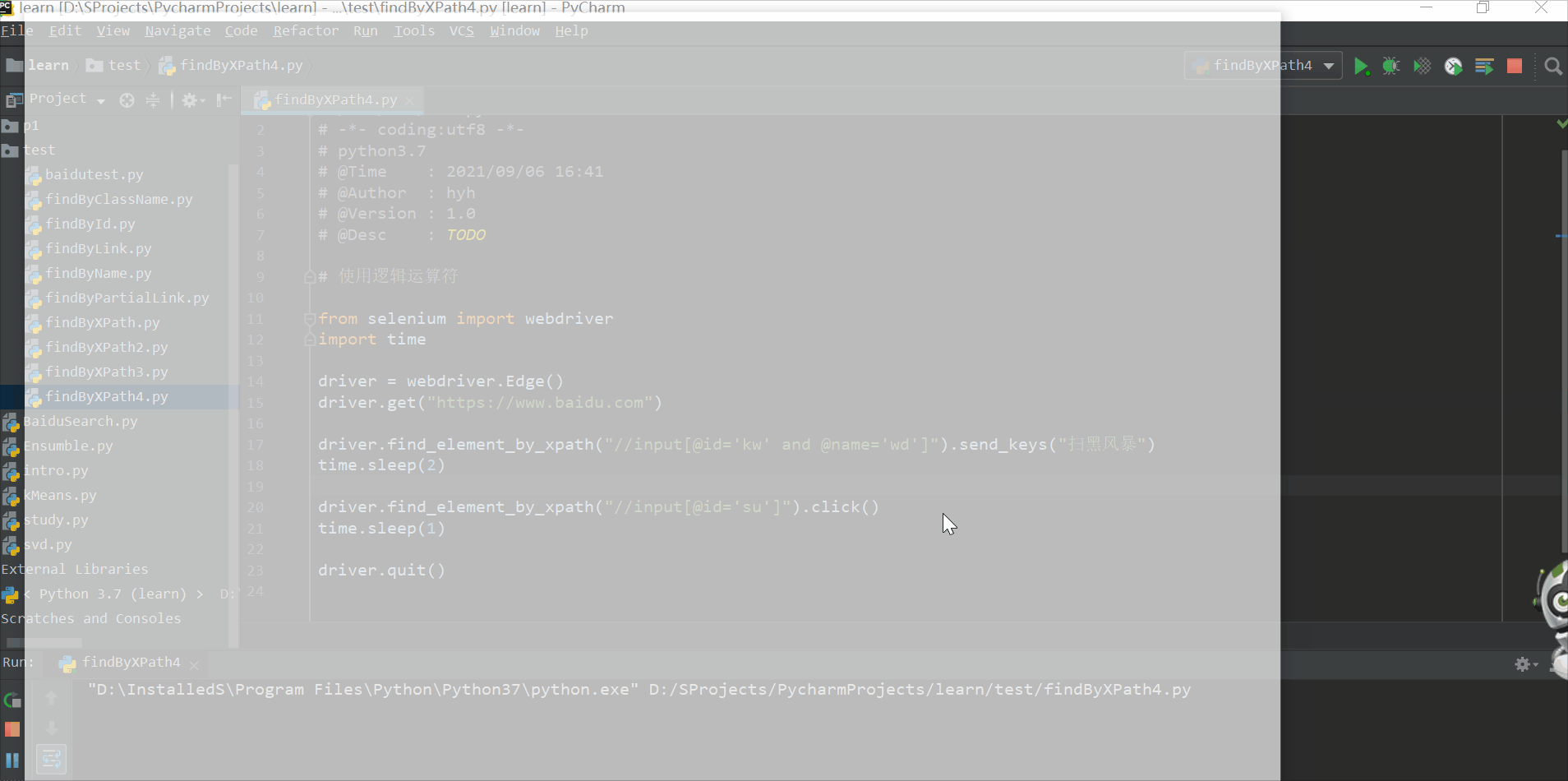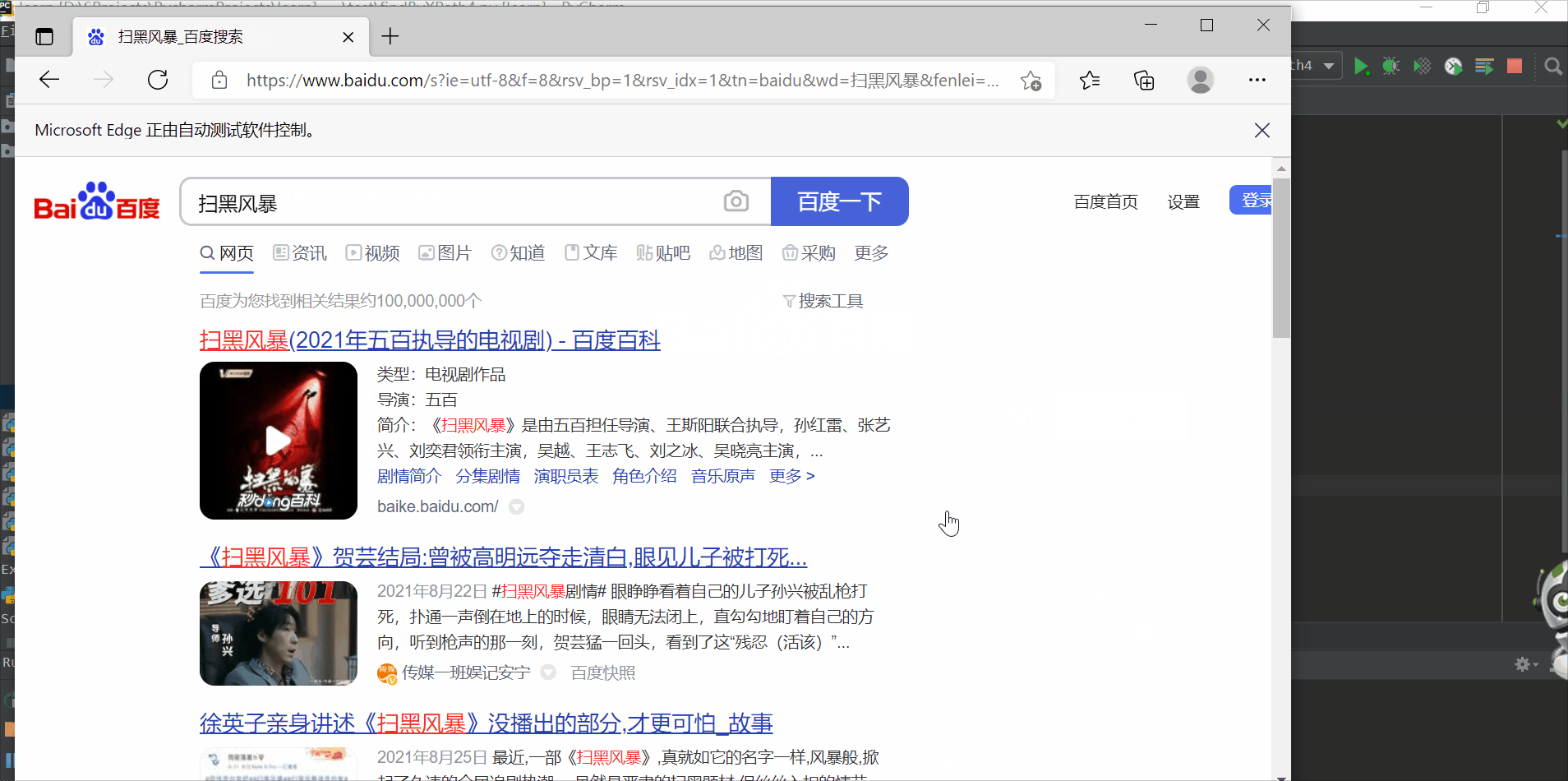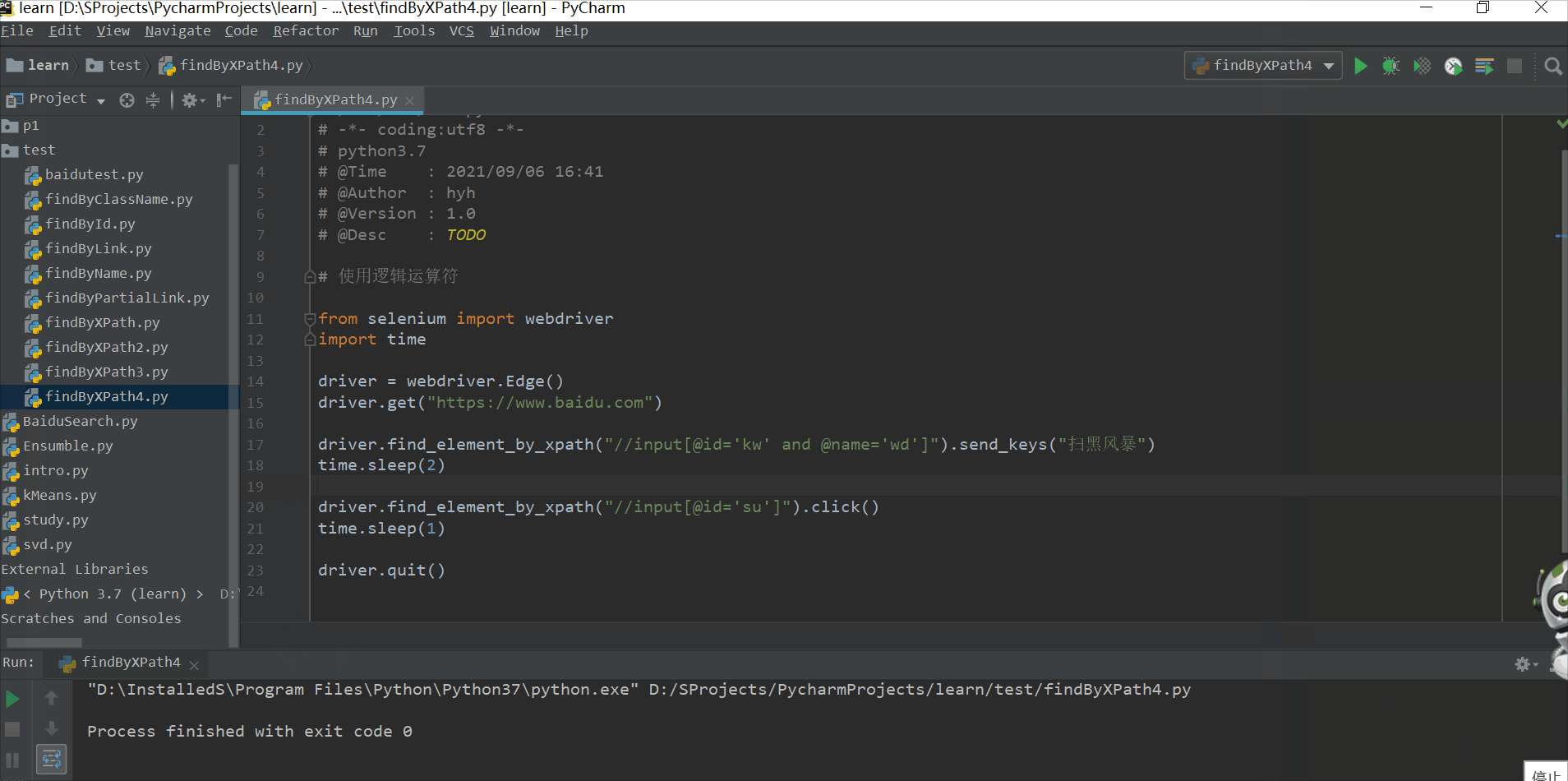
使用逻辑运算符定位,比如通过一个元素无法定位,可以再加一个条件
#!/usr/bin/env python
# -*- coding:utf8 -*-
# python3.7
# @Time : 2021/09/06 16:41
# @Author : hyh
# @Version : 1.0
# @Desc : TODO
# 使用逻辑运算符
from selenium import webdriver
import time
driver = webdriver.Edge()
driver.get("https://www.baidu.com")
driver.find_element_by_xpath("//input[@id='kw' and @name='wd']").send_keys("扫黑风暴")
time.sleep(2)
driver.find_element_by_xpath("//input[@id='su']").click()
time.sleep(1)
driver.quit()
2.8.1.8 css定位 find_element_by_css_selector("")
css可以较为灵活的选择控件的任意属性,一般情况定位速度要比xpath快。
css选择器定位常见语法:
| 选择器 | eg | 描述 |
|---|---|---|
| .class | .intro | class选择器,选择class="intro"的所有元素 |
| #id | #firstname | id选择器,选择id="firstname"的所有元素 |
| * | * | 选择所有元素 |
| element | p | 所有 元素或者标签名 |
| element > element | div > input | 选择父元素为<div>的所有<input>元素 |
| element + element | div + input | 选择同一级中紧接在<div>元素之后的所有<input>元素 |
| [attribute=value] | [target=_blank] | 选择target="_blank"的所有元素 |
eg:
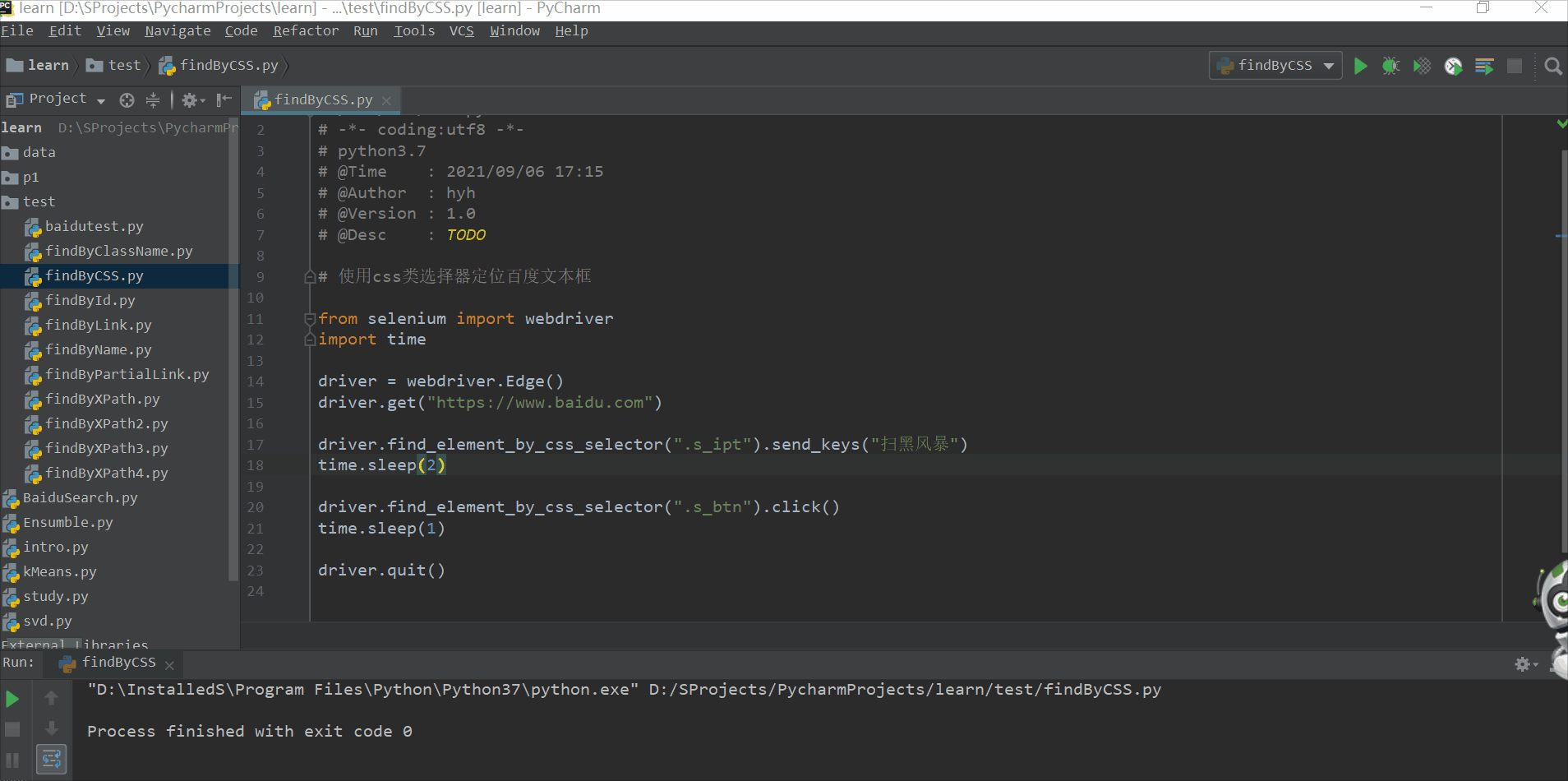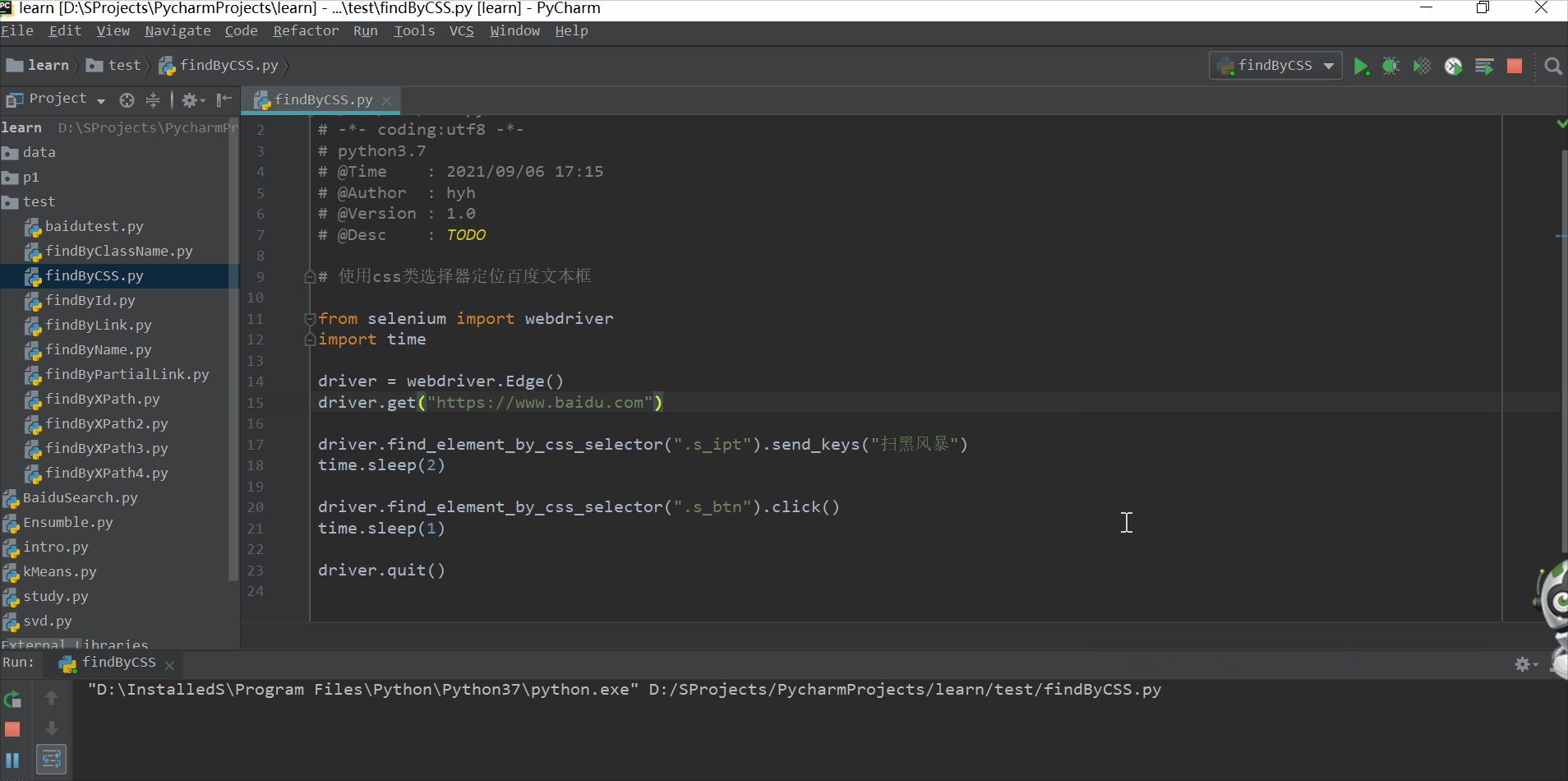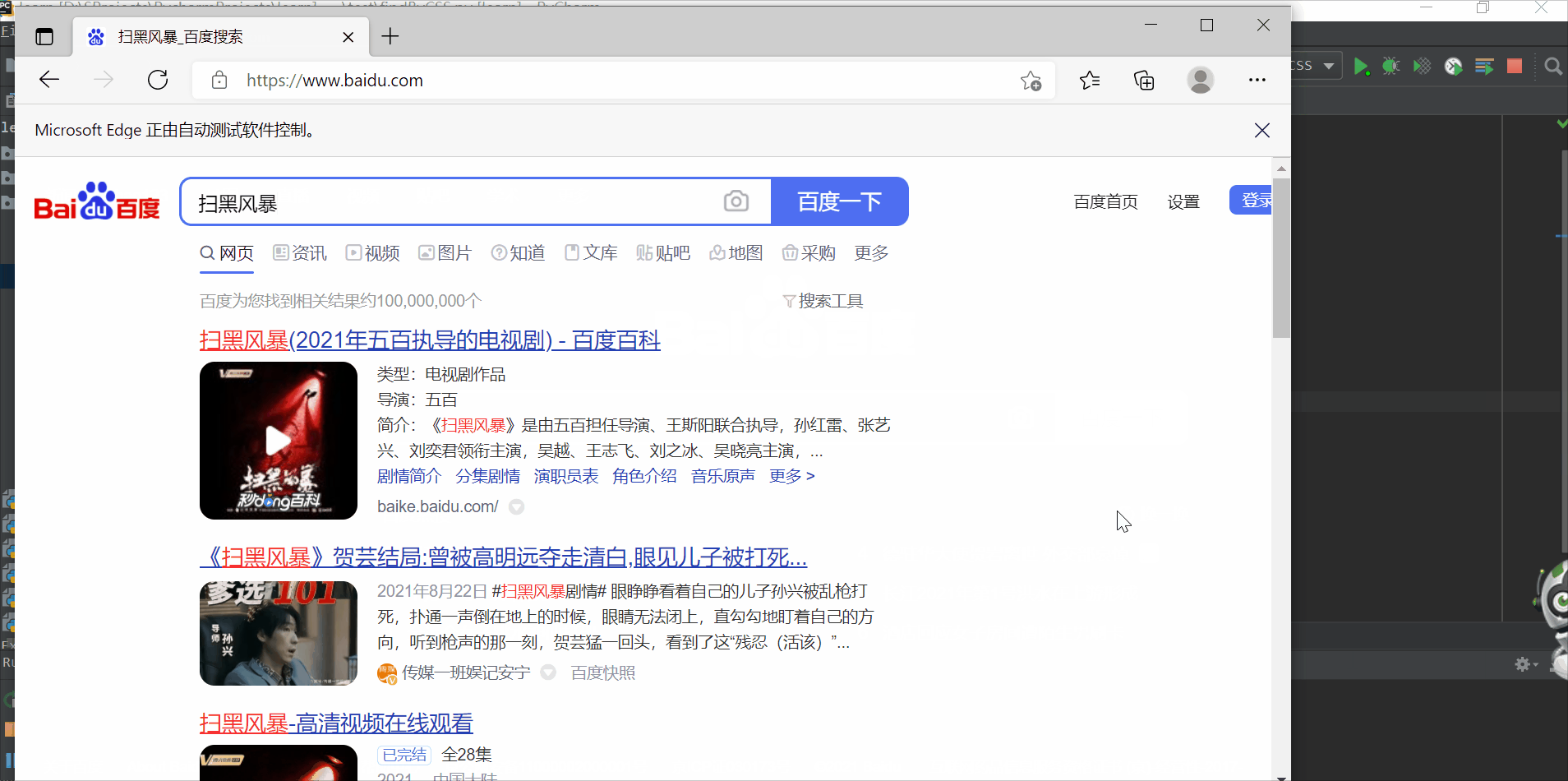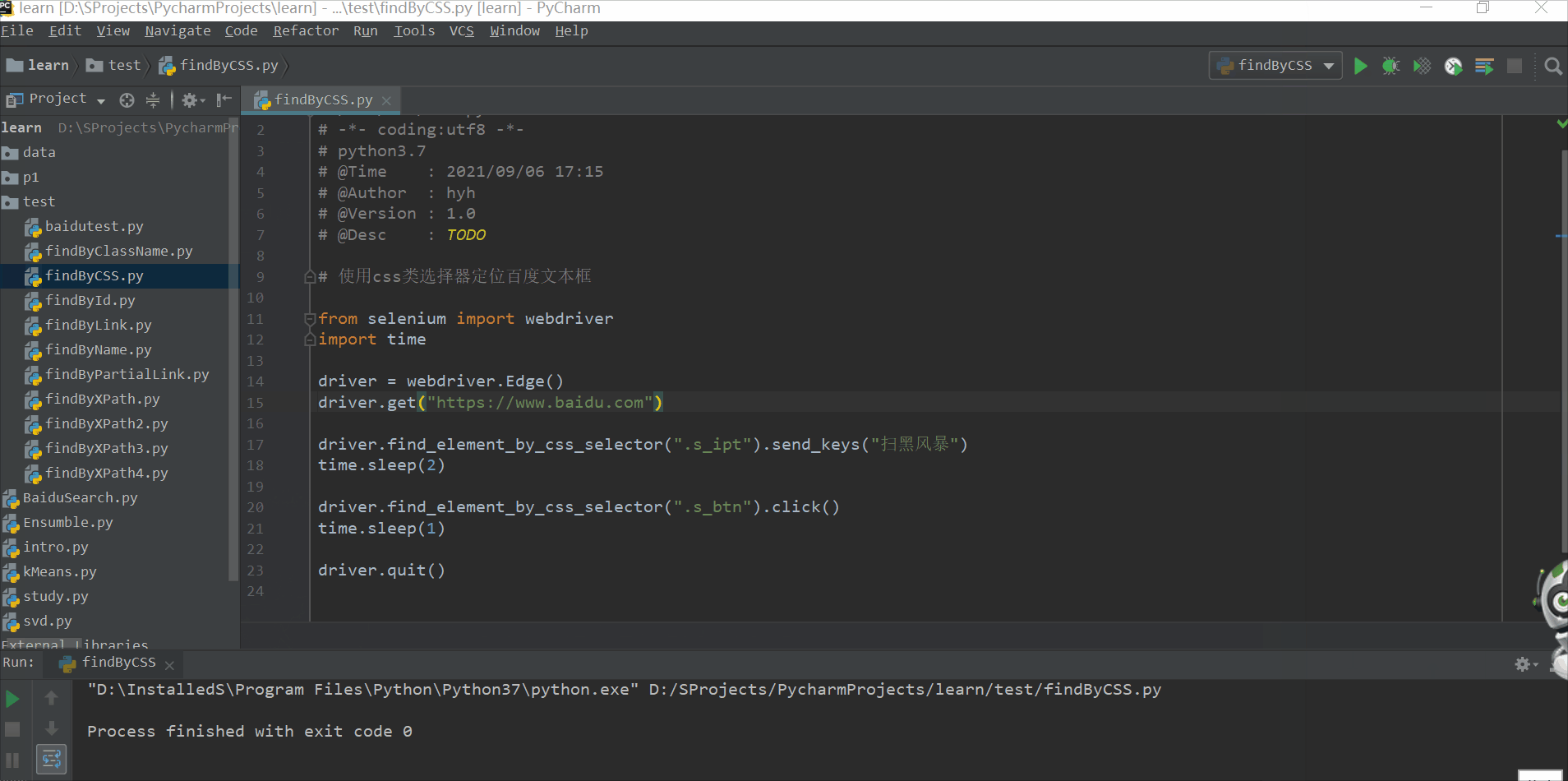
使用类选择器定位百度文本框
#!/usr/bin/env python
# -*- coding:utf8 -*-
# python3.7
# @Time : 2021/09/06 17:15
# @Author : hyh
# @Version : 1.0
# @Desc : TODO
# 使用css类选择器定位百度文本框
from selenium import webdriver
import time
driver = webdriver.Edge()
driver.get("https://www.baidu.com")
driver.find_element_by_css_selector(".s_ipt").send_keys("扫黑风暴")
time.sleep(2)
driver.find_element_by_css_selector(".s_btn").click()
time.sleep(1)
driver.quit()
使用id选择器
#!/usr/bin/env python
# -*- coding:utf8 -*-
# python3.7
# @Time : 2021/09/06 17:23
# @Author : hyh
# @Version : 1.0
# @Desc : TODO
# 使用id选择器定位百度文本框
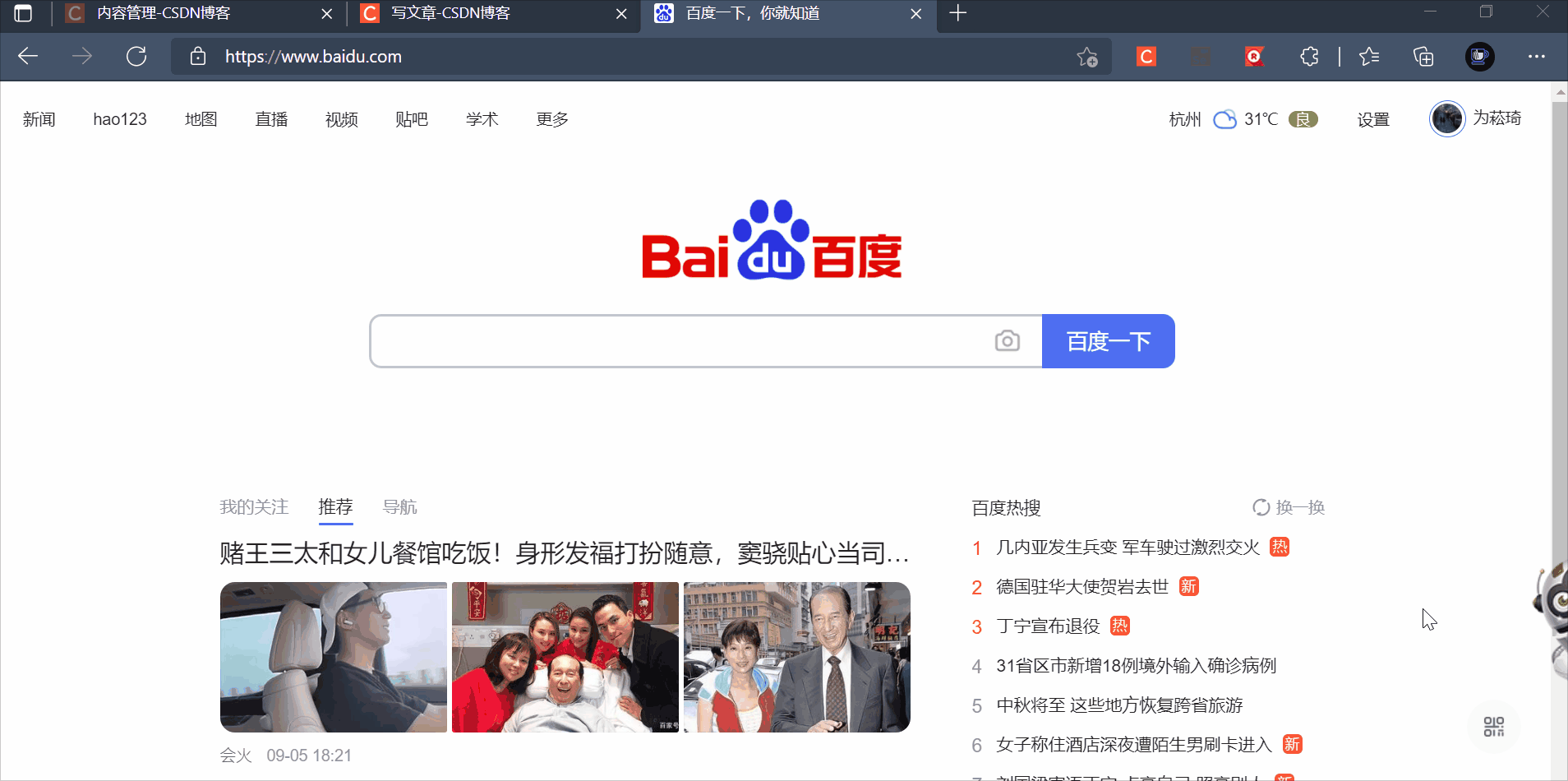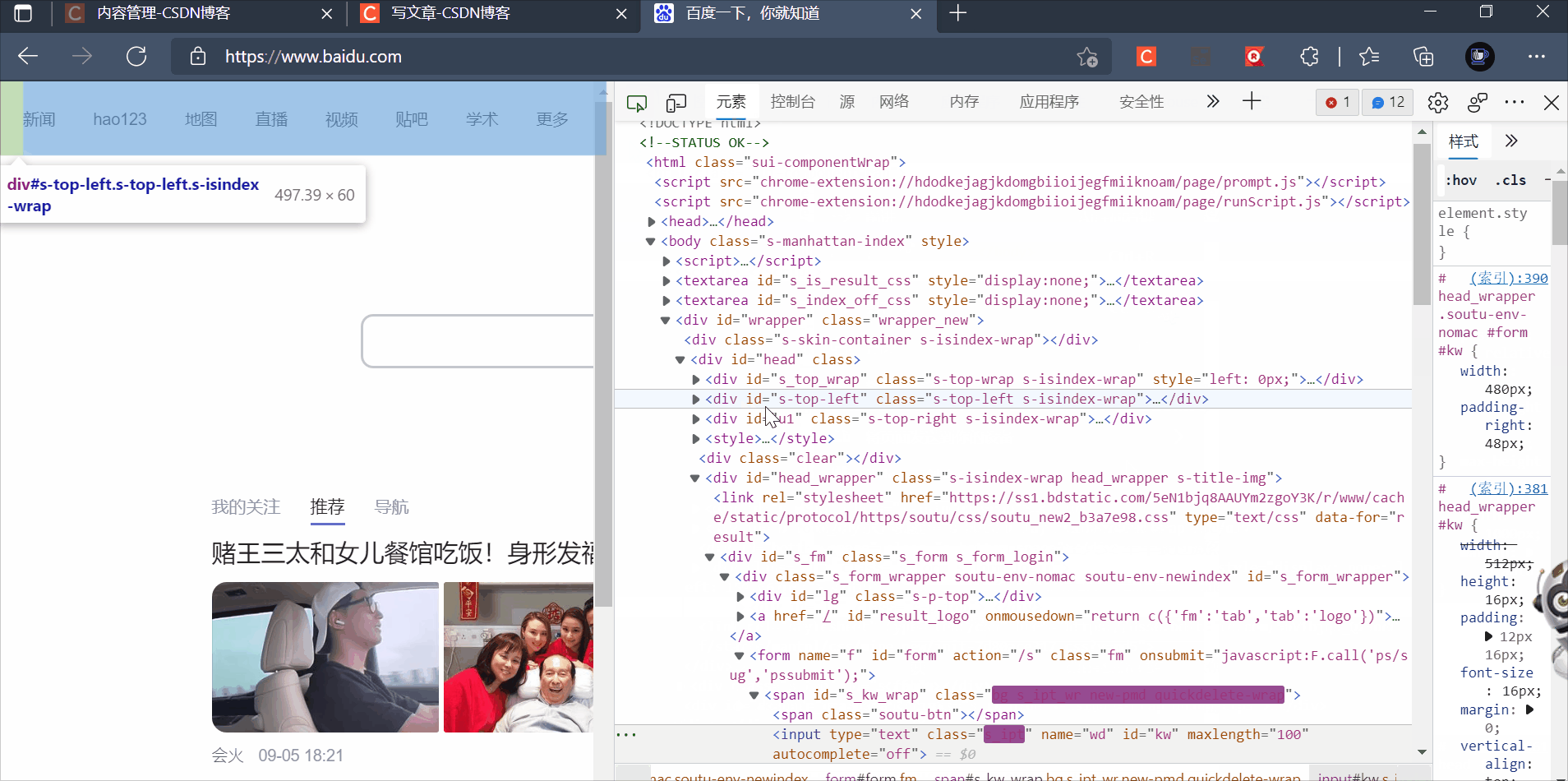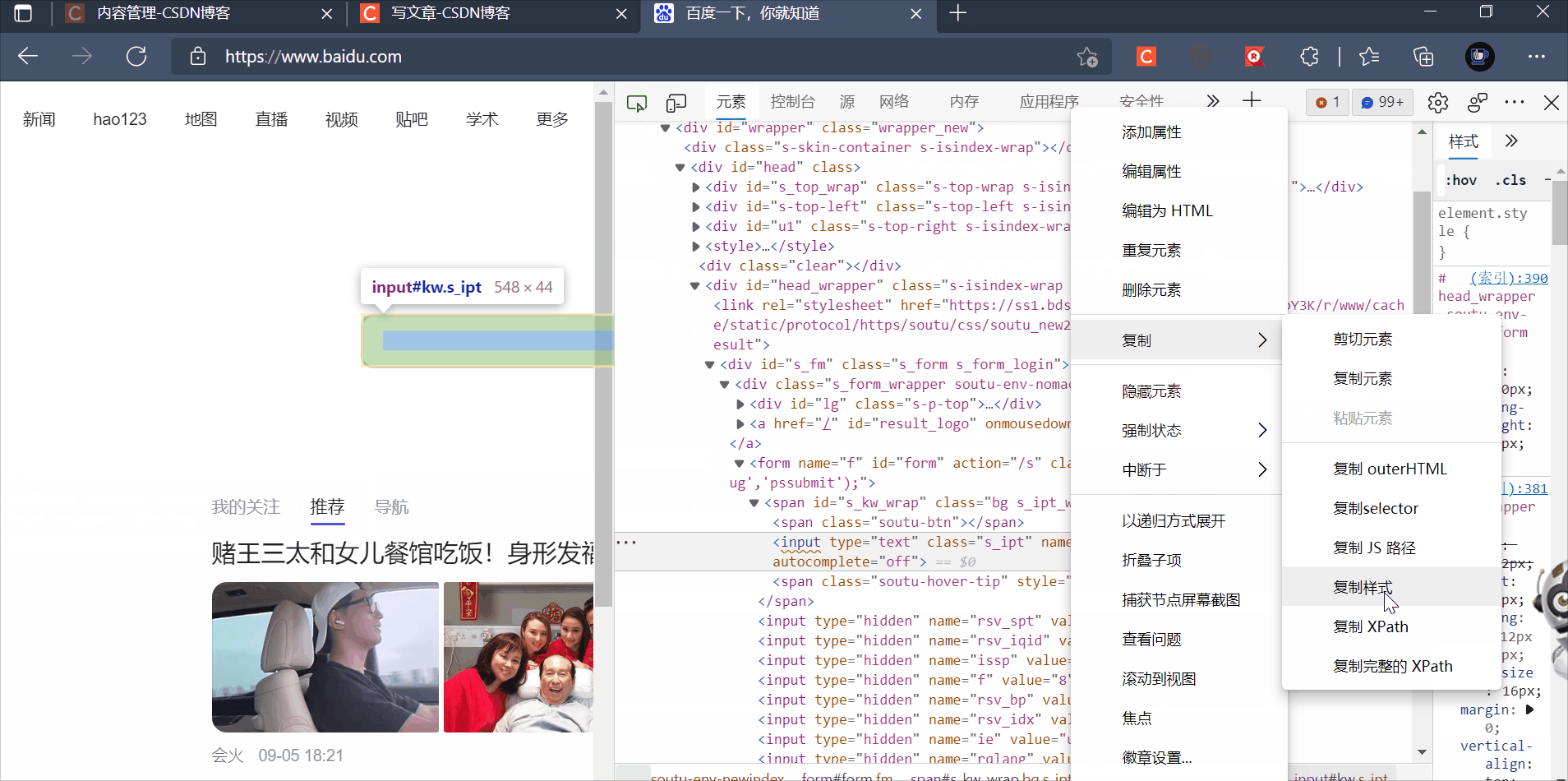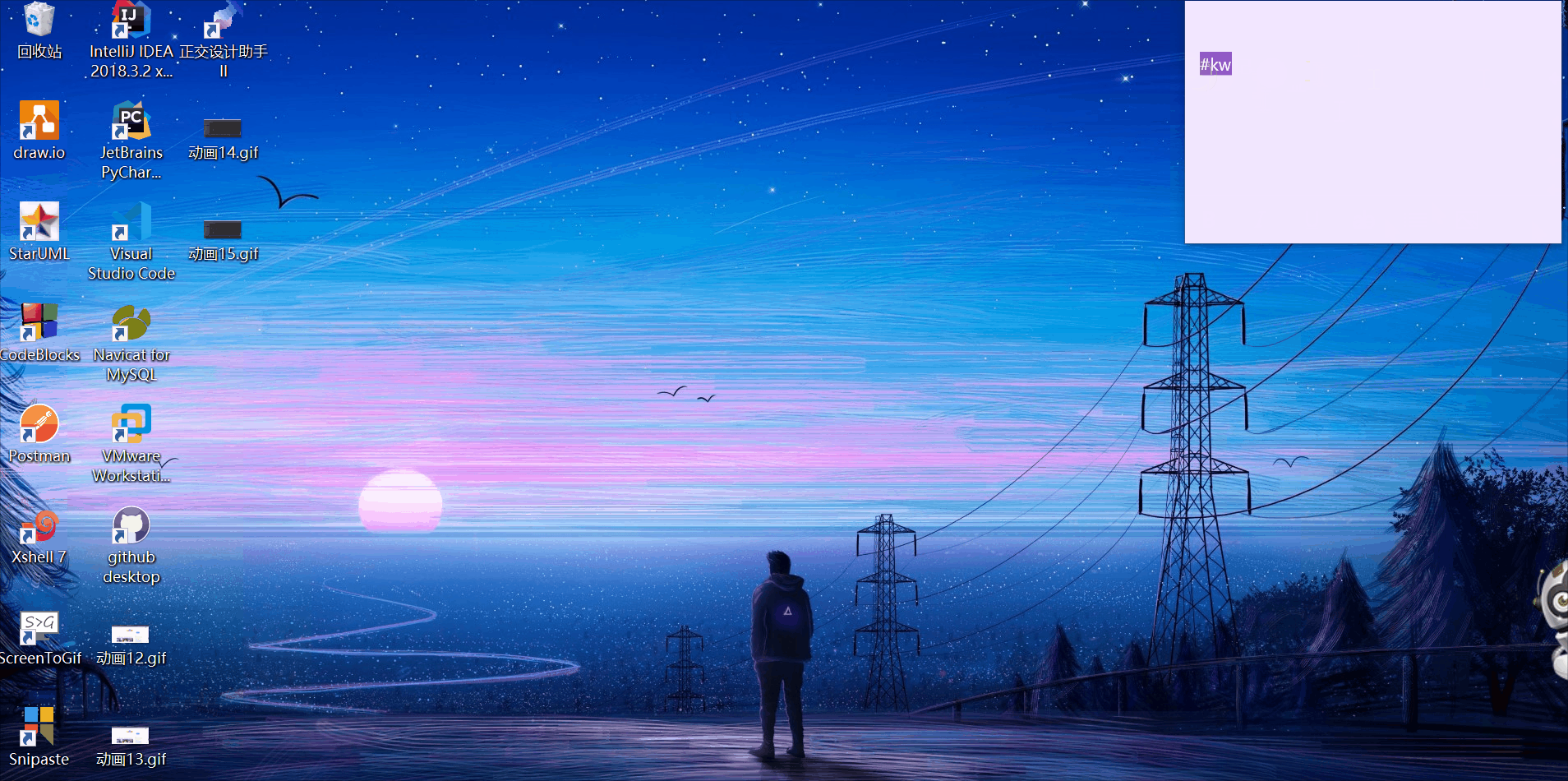
from selenium import webdriver
import time
driver = webdriver.Edge()
driver.get("https://www.baidu.com")
driver.find_element_by_css_selector("#kw").send_keys("扫黑风暴")
time.sleep(2)
driver.find_element_by_css_selector("#su").click()
time.sleep(1)
driver.quit()
2.8.2 页面元素操作
在对页面上的元素定位之后,就需要对这个元素进行操作。
WebDriver中常用的几个成员方法和成员变量:
| 常用方法 | 描述 |
|---|---|
| clear() | 清除文本 |
| send_keys() | 模拟按键输入(输入各种字母,文字,符号,也可以发送快捷键) |
| click() | 单击元素 |
| current_url | 返回当前页面的url地址(只能返回driver对象能够控制的页面) |
| title | 返回当前页面的title(只能返回driver对象能够控制的页面) |
| text | 获取页面(提示框、警告框)显示的文本,或者是一些页面元素上的显示文本 |
| get_attribute(属性名) | 获取属性值,比如文本框的值就是value属性值,name属性值,class属性值等 |
| is_displayed() | 该元素是否用户可见,true或false |
| is_enabled() | 判断是否可用 |
| is_selected() | 判断是否选中,一般用于复选框和单选框的判断 |
eg:
清除文本
#!/usr/bin/env python
# -*- coding:utf8 -*-
# python3.7
# @Time : 2021/09/06 22:09
# @Author : hyh
# @Version : 1.0
# @Desc : TODO
# 清除文本clear()
# 注意如果使用两次send_keys()是追加,而不是覆盖,所以如果重写文本框里的内容,需要先做清除clear()
from selenium import webdriver
import time
driver = webdriver.Edge()
driver.get("https://www.baidu.com")
driver.find_element_by_css_selector("#kw").send_keys("扫黑风暴")
time.sleep(2)
driver.find_element_by_css_selector("#kw").clear()
time.sleep(1)
driver.find_element_by_xpath("//input[@id='kw']").send_keys("海上钢琴师")
time.sleep(2)
driver.find_element_by_css_selector("#su").click()
time.sleep(1)
driver.quit()
判断进入的网址是否正确
#!/usr/bin/env python
# -*- coding:utf8 -*-
# python3.7
# @Time : 2021/09/06 22:27
# @Author : hyh
# @Version : 1.0
# @Desc : TODO
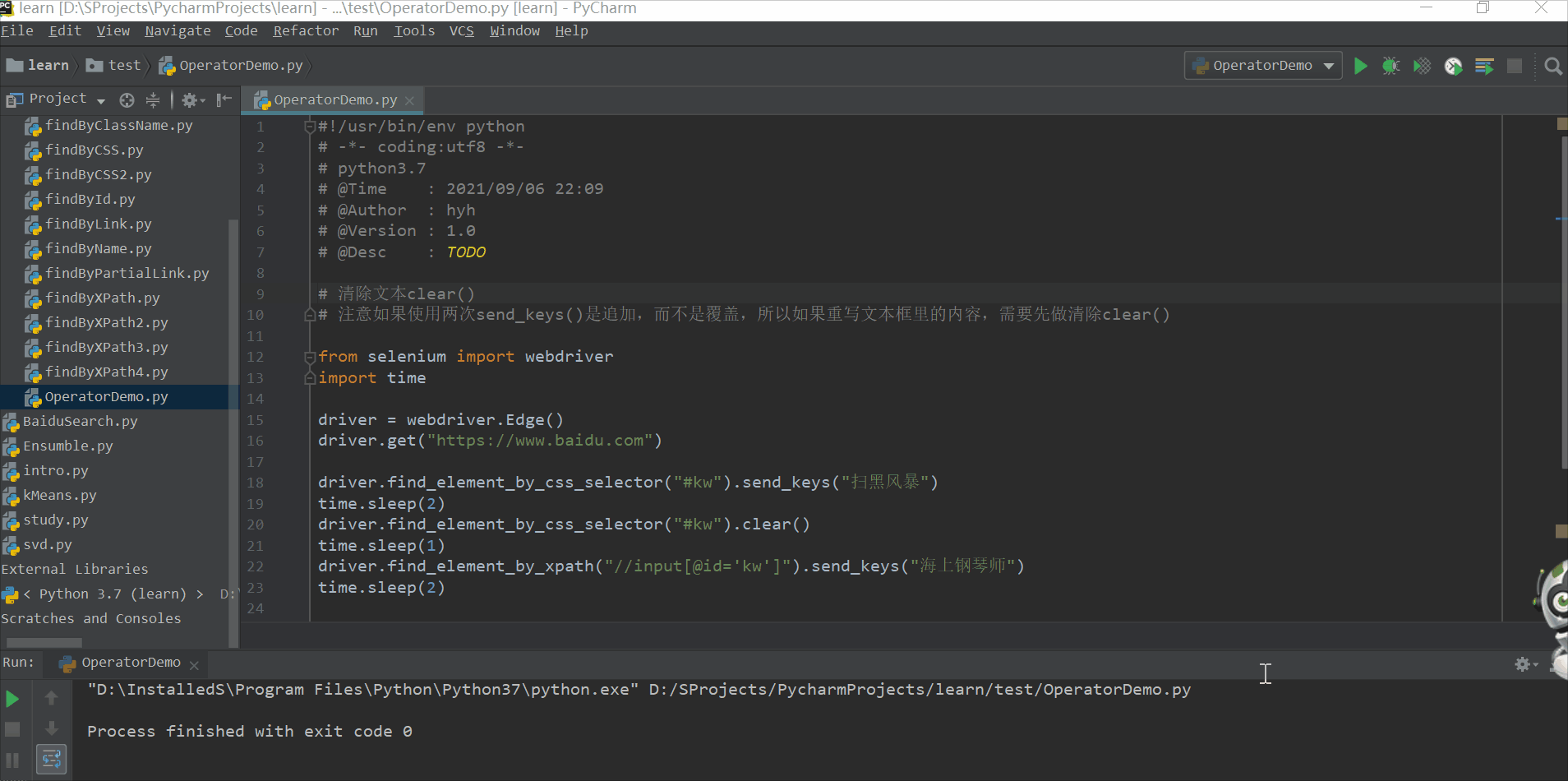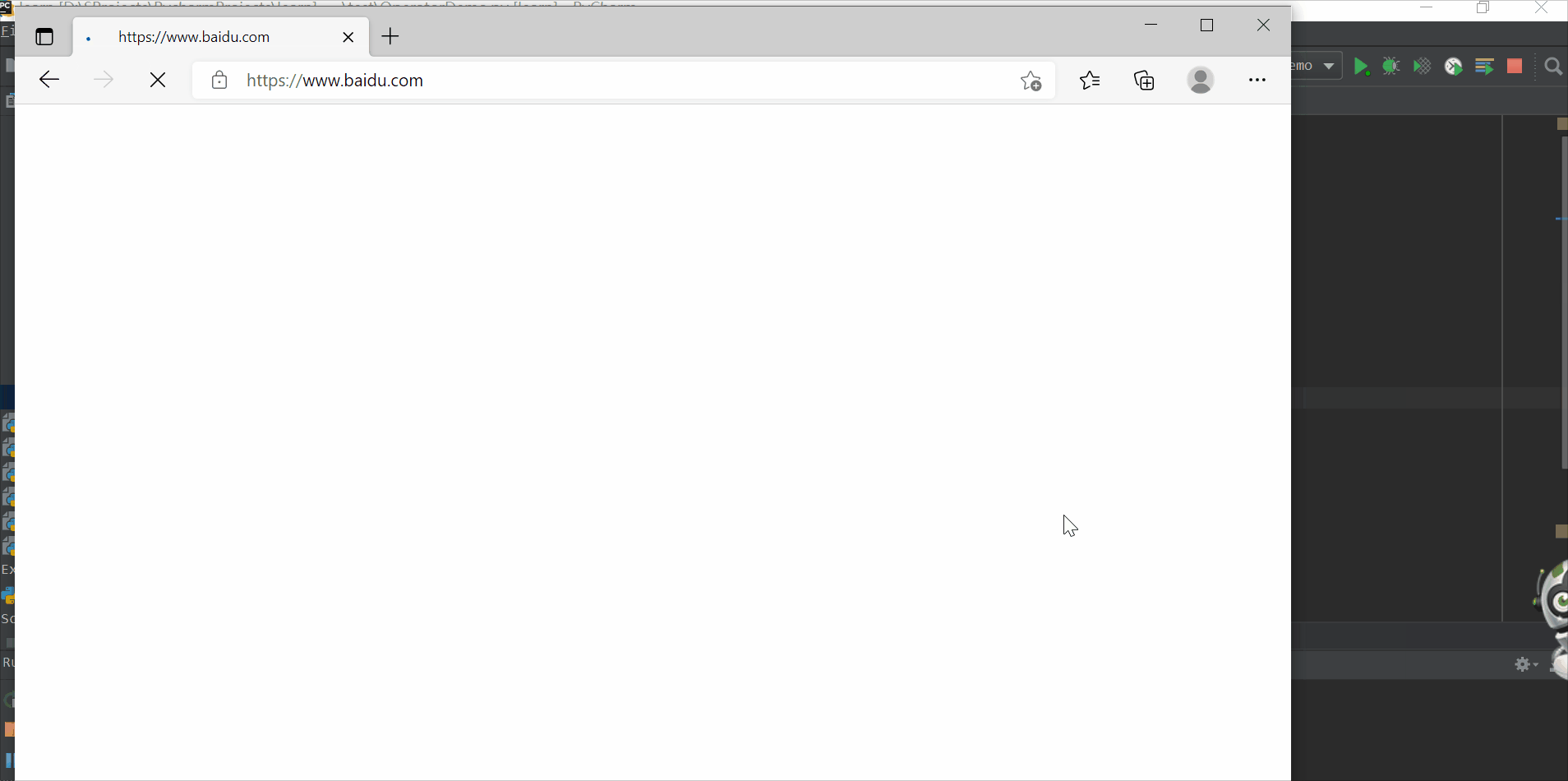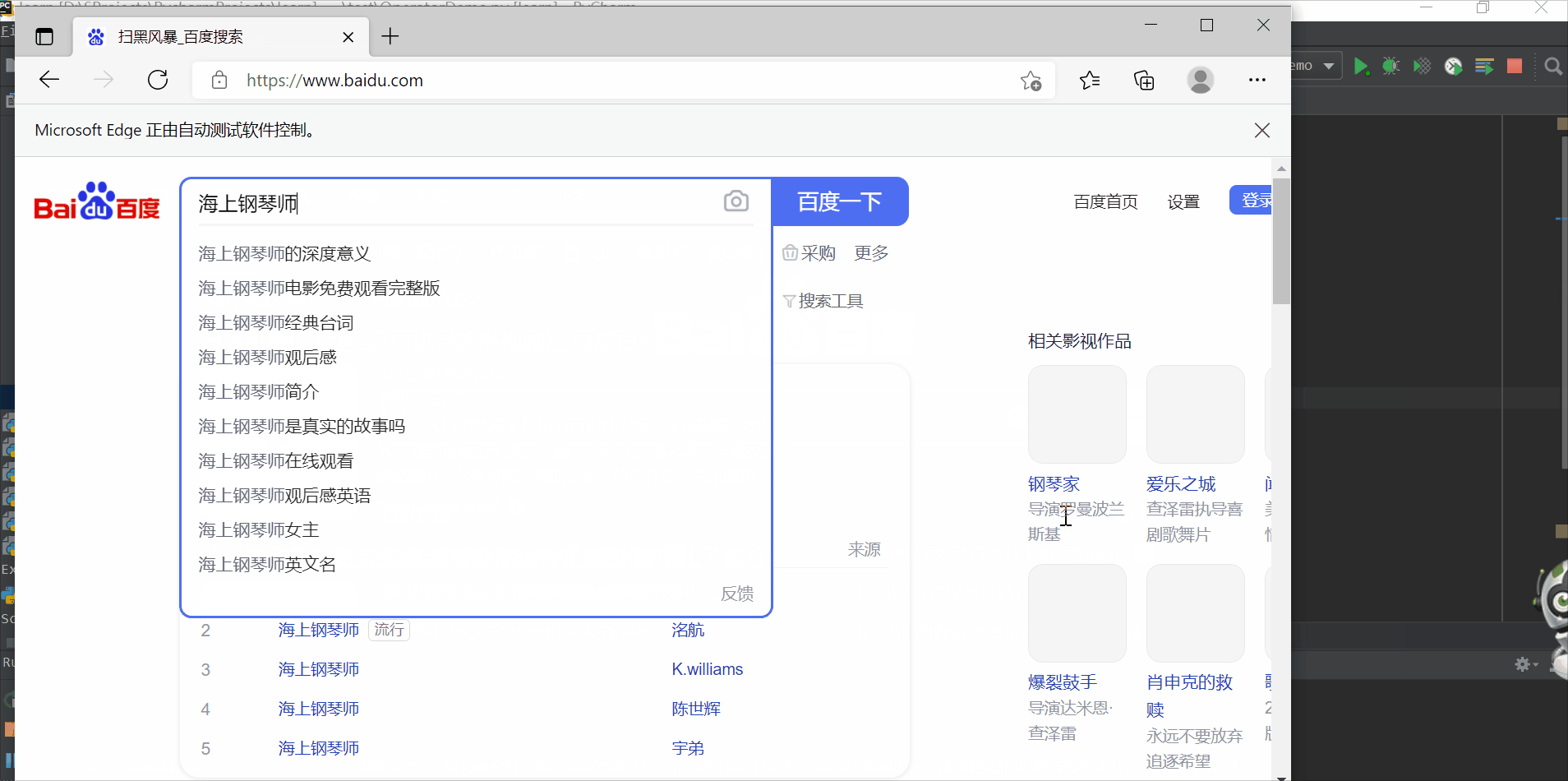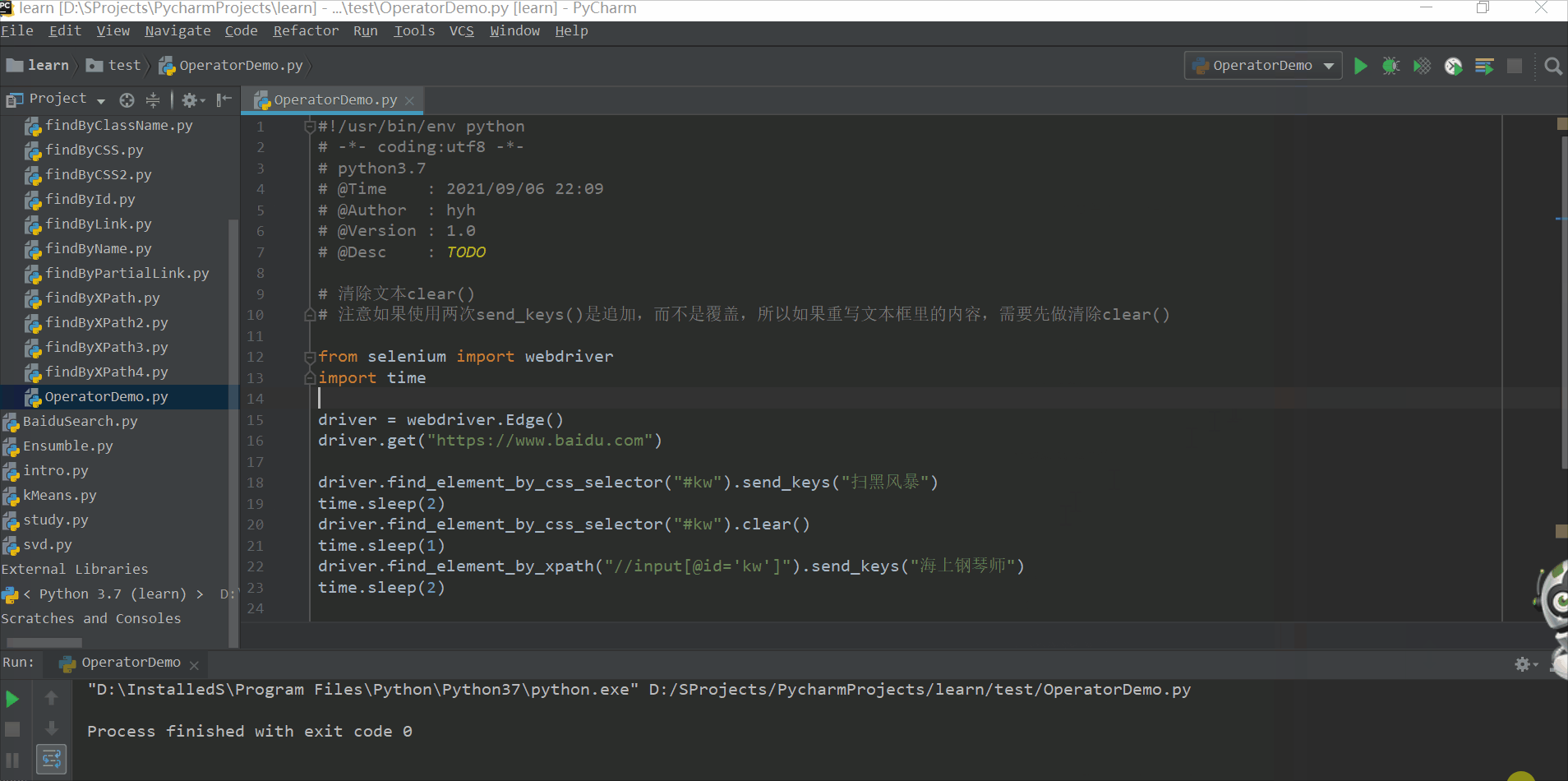
from selenium import webdriver
driver = webdriver.Edge()
driver.get("http://www.baidu.com/")
url = driver.current_url
print(url)
# 断言
if url == "https://www.baidu.com/":
print("页面地址正确")
else:
print("页面地址错误")
driver.quit()
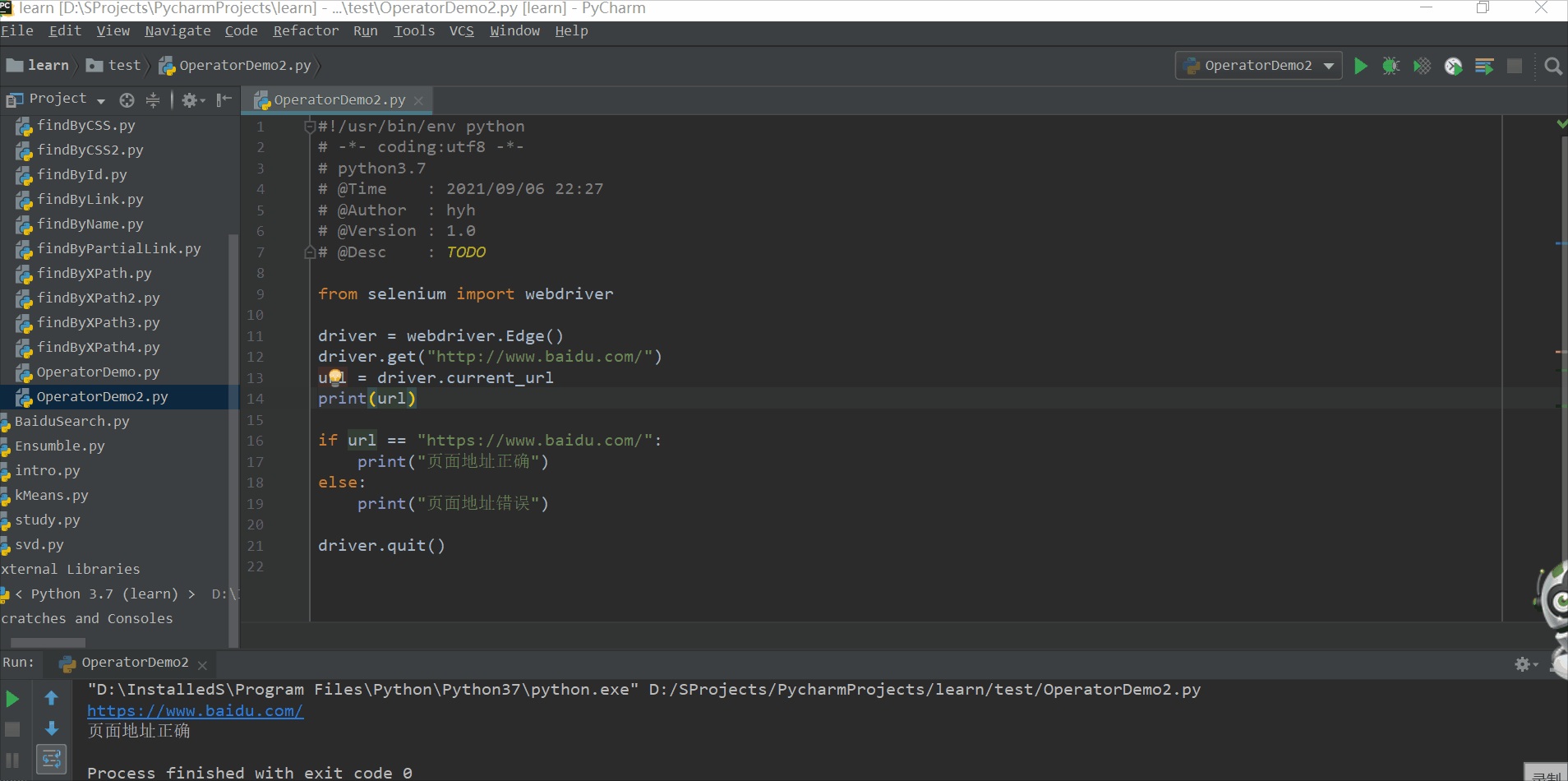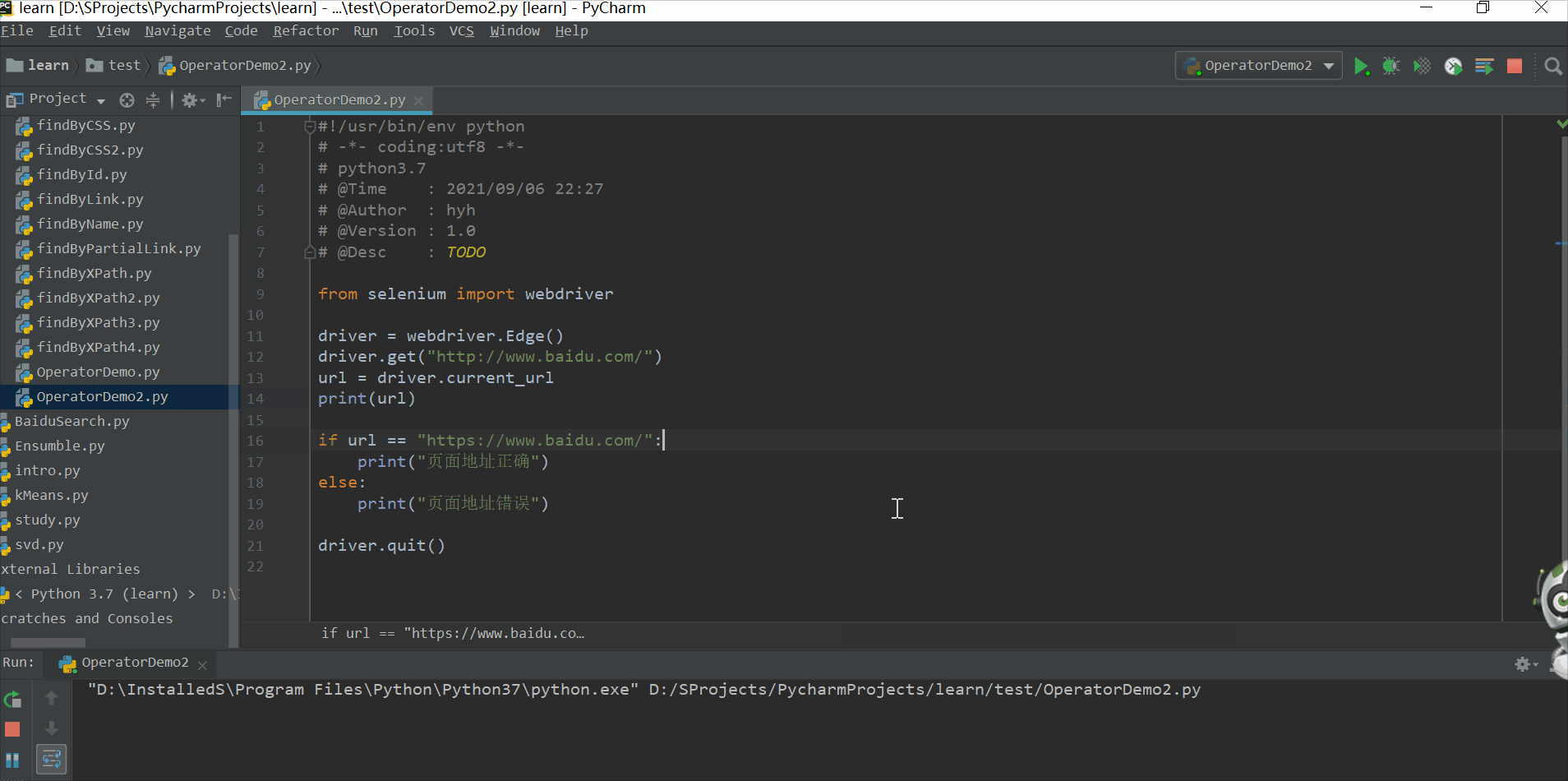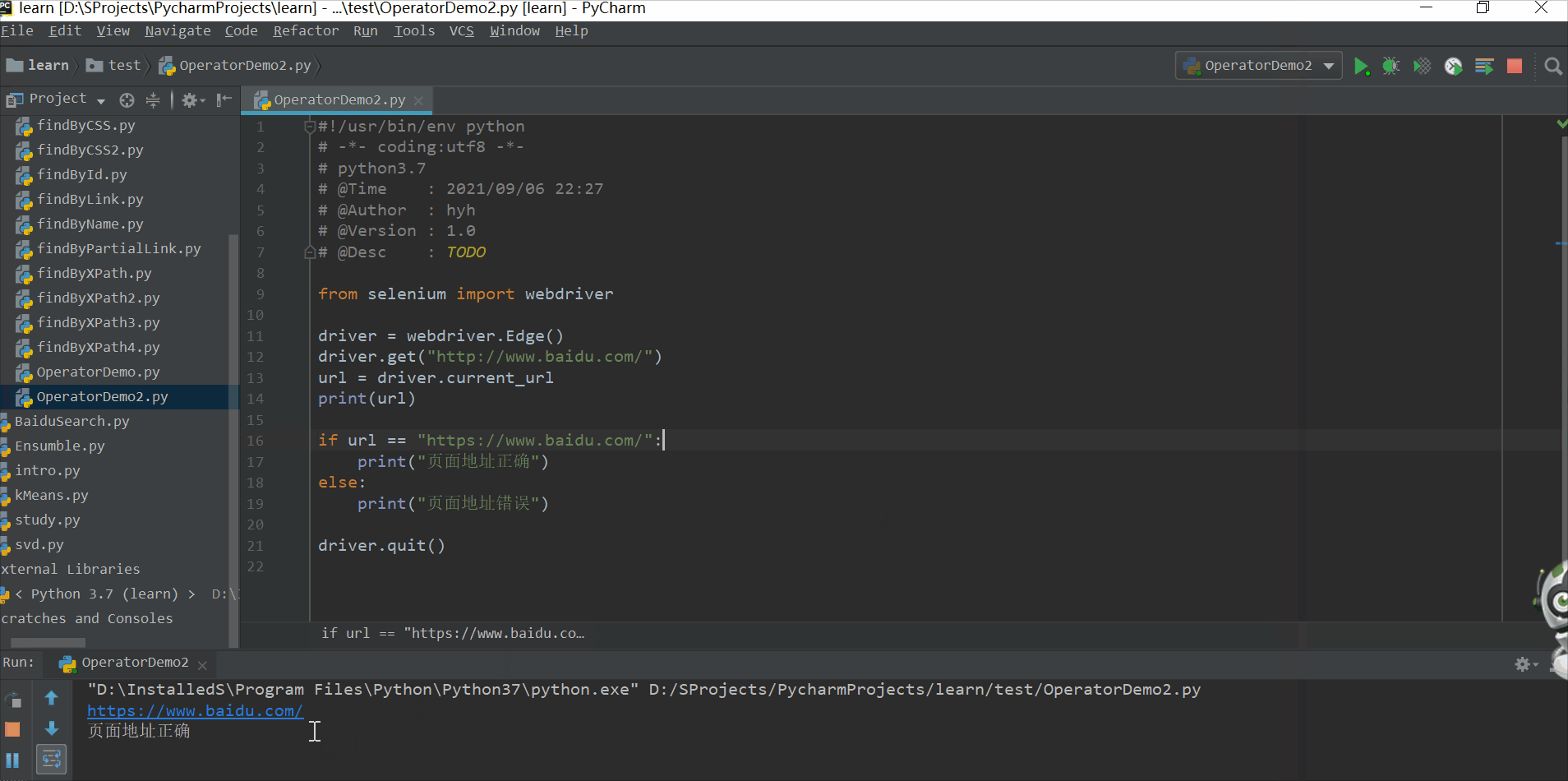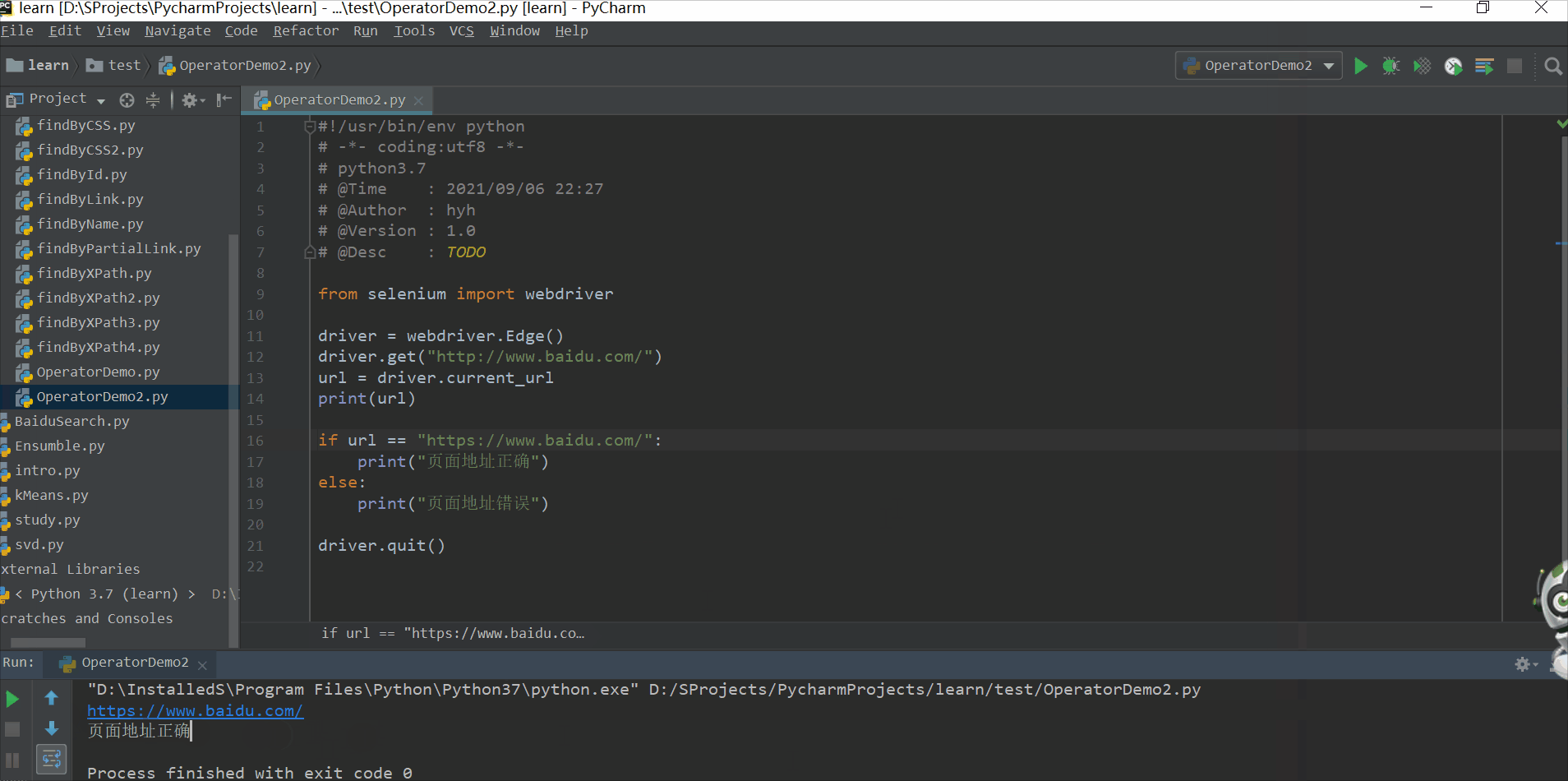
在百度首页获取title,并打印
#!/usr/bin/env python
# -*- coding:utf8 -*-
# python3.7
# @Time : 2021/09/06 22:49
# @Author : hyh
# @Version : 1.0
# @Desc : TODO
from selenium import webdriver
driver = webdriver.Edge()
driver.get("https://www.baidu.com/")
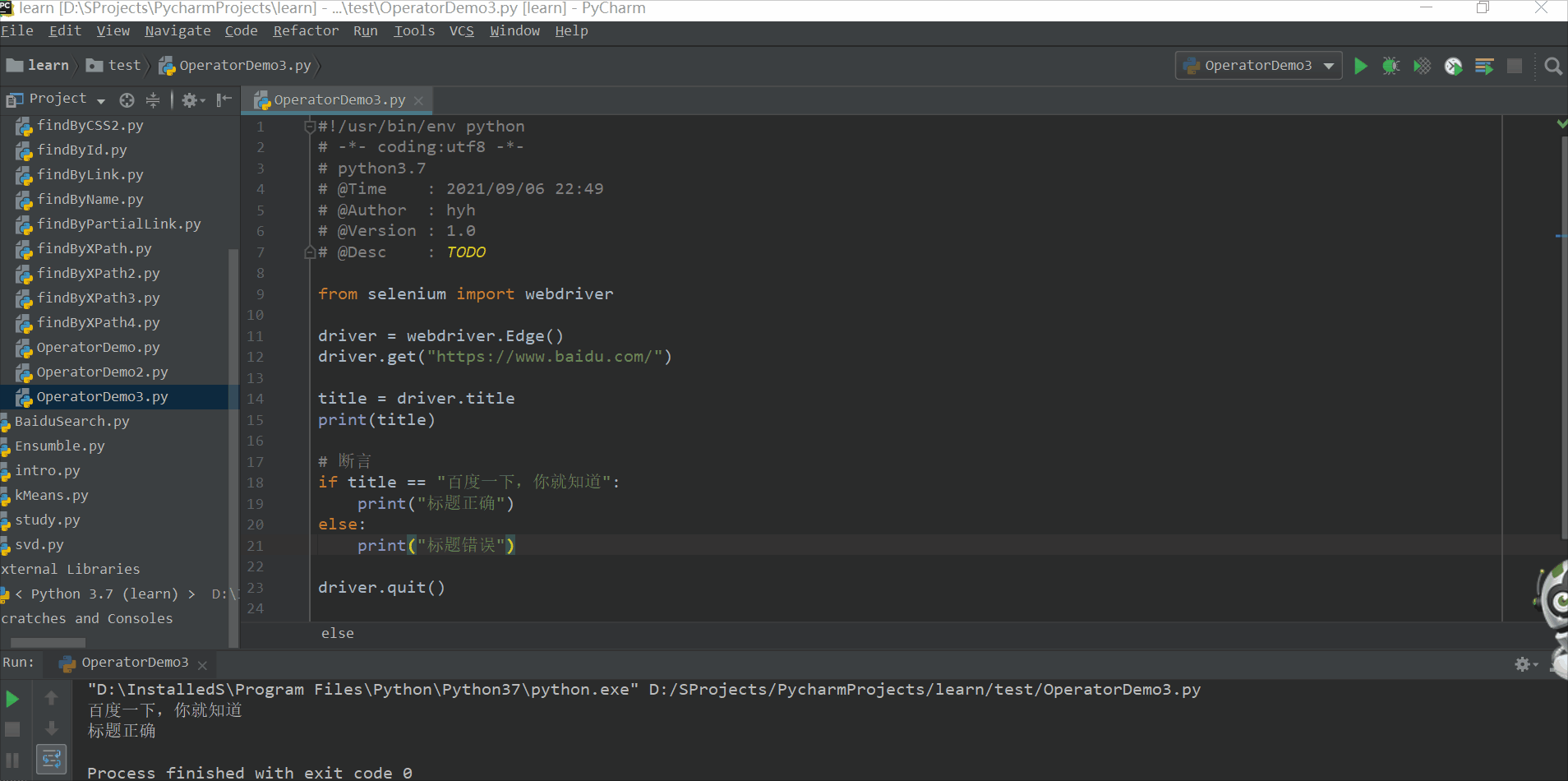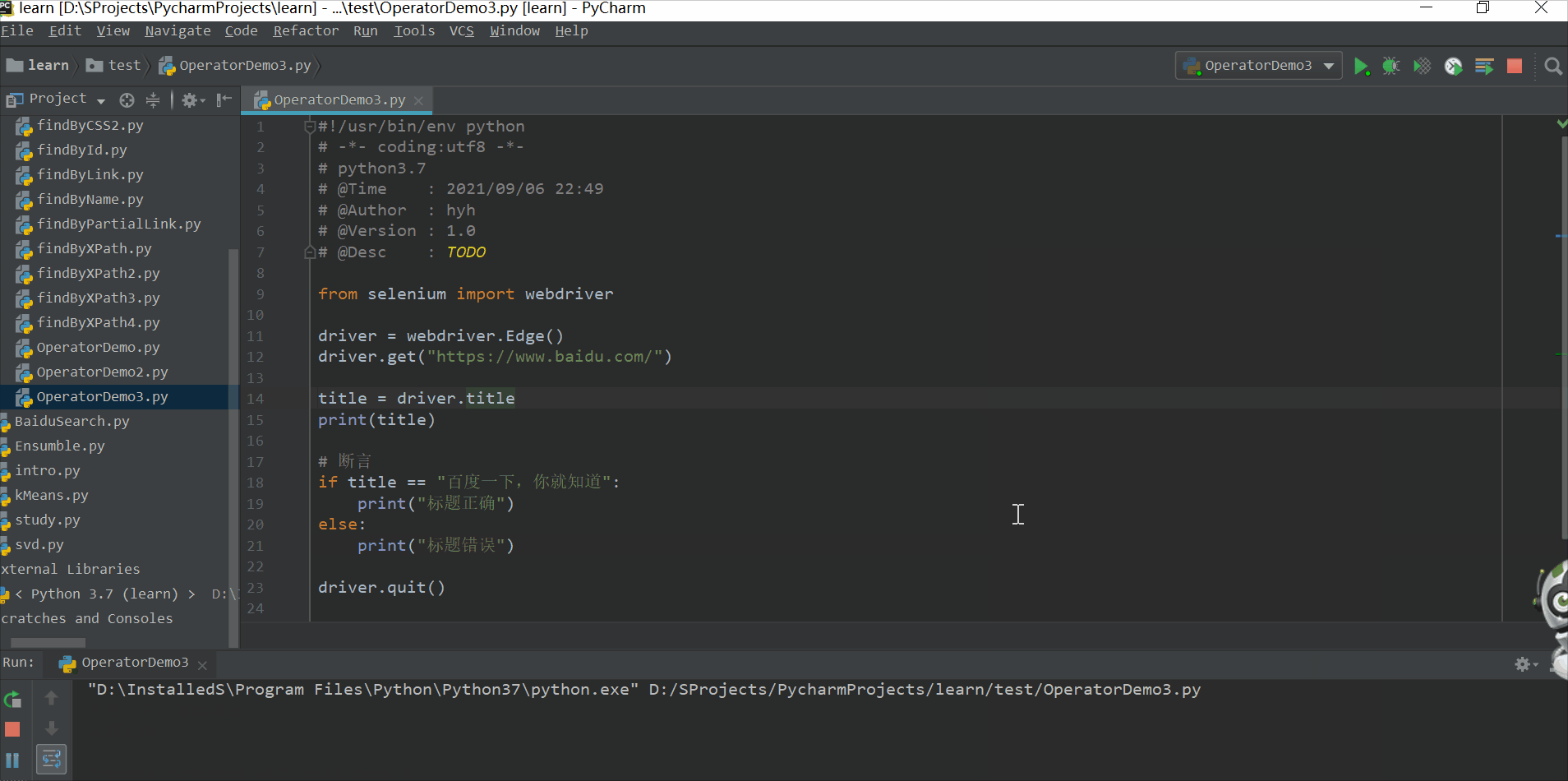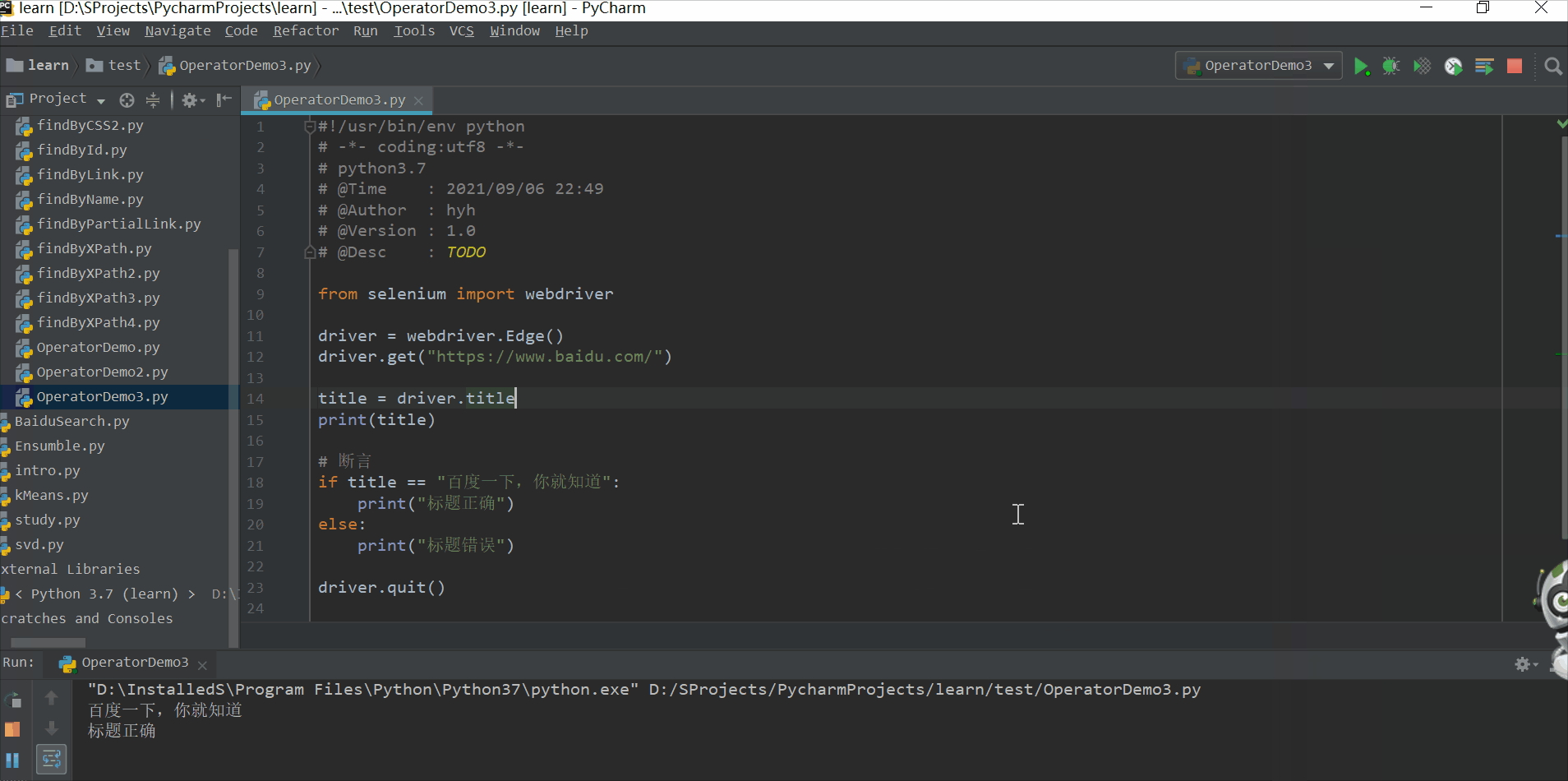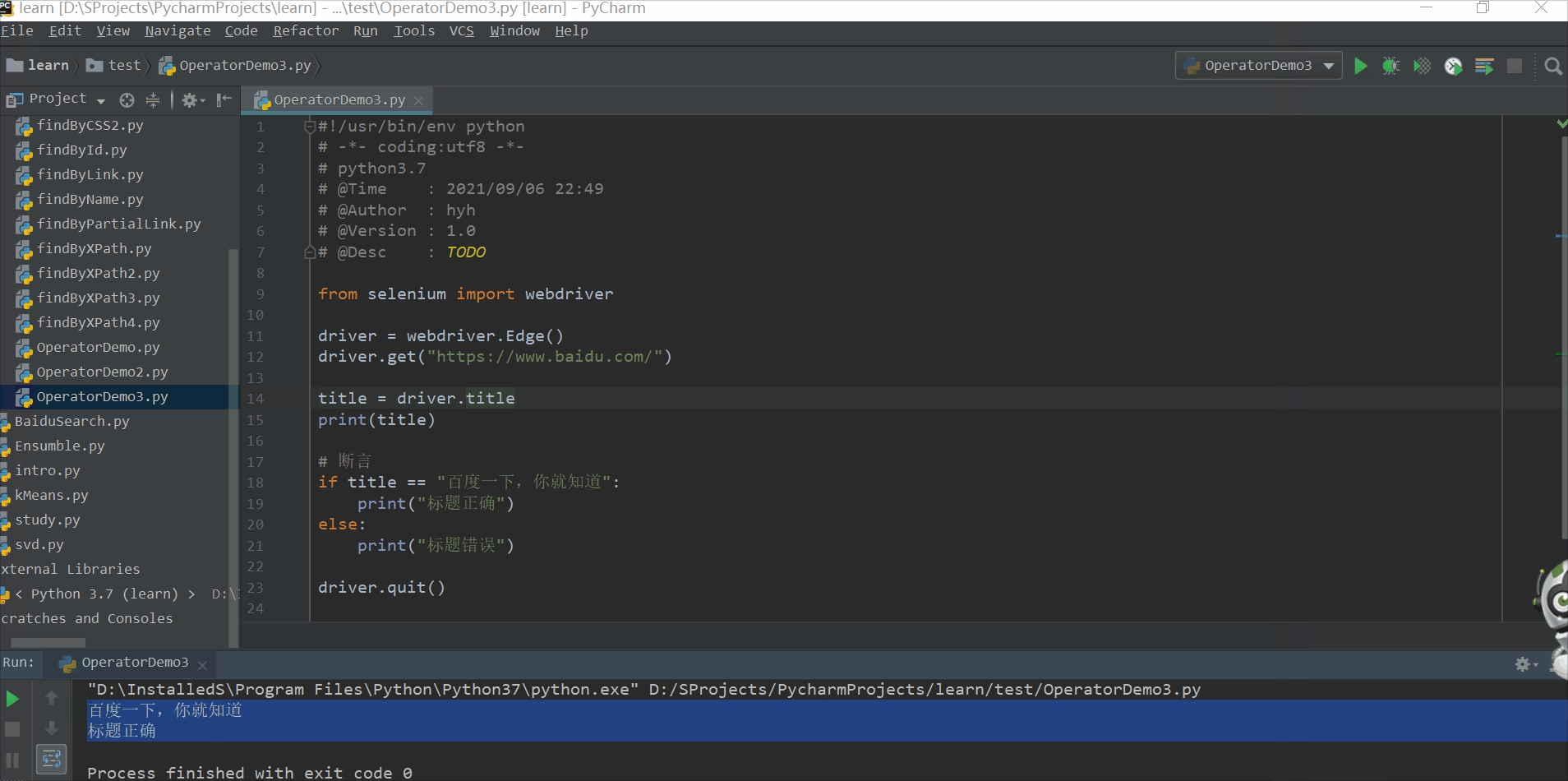
title = driver.title
print(title)
# 断言
if title == "百度一下,你就知道":
print("标题正确")
else:
print("标题错误")
driver.quit()
获取百度首页的页脚的文字
#!/usr/bin/env python
# -*- coding:utf8 -*-
# python3.7
# @Time : 2021/09/07 20:08
# @Author : hyh
# @Version : 1.0
# @Desc : TODO
# 获取百度首页的页脚的文字
from selenium import webdriver
driver = webdriver.Edge()
driver.get("https://www.baidu.com")
text = driver.find_element_by_xpath("//*[@id='bottom_layer']/div/p[8]/span").text
print(text)
driver.quit()
获取百度搜索框的name属性
#!/usr/bin/env python
# -*- coding:utf8 -*-
# python3.7
# @Time : 2021/09/07 23:11
# @Author : hyh
# @Version : 1.0
# @Desc : TODO
# 获取百度搜索框的name属性
from selenium import webdriver
driver = webdriver.Edge()
driver.get("https://www.baidu.com")
print(driver.find_element_by_id("kw").get_attribute("name"))
driver.quit()
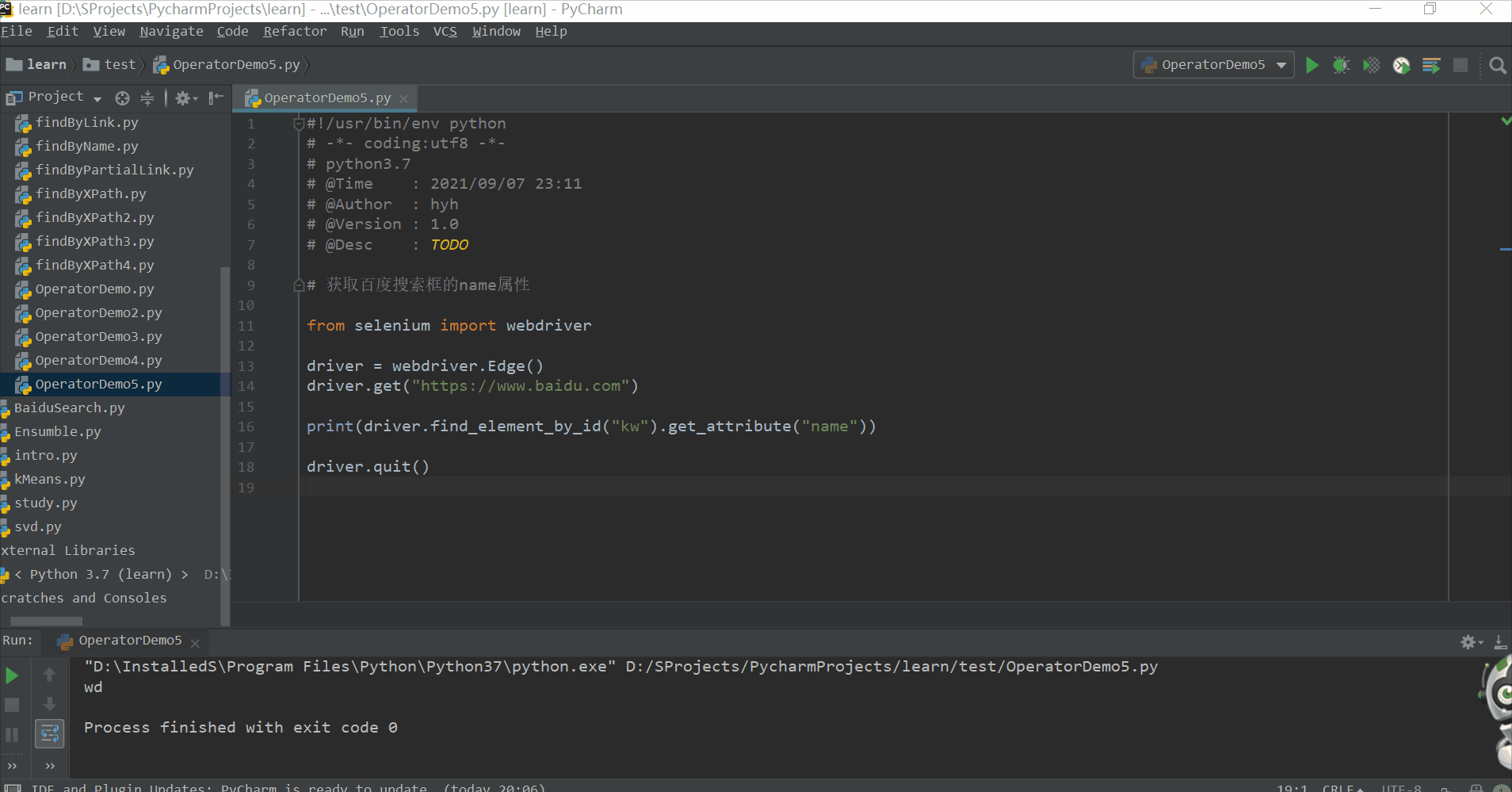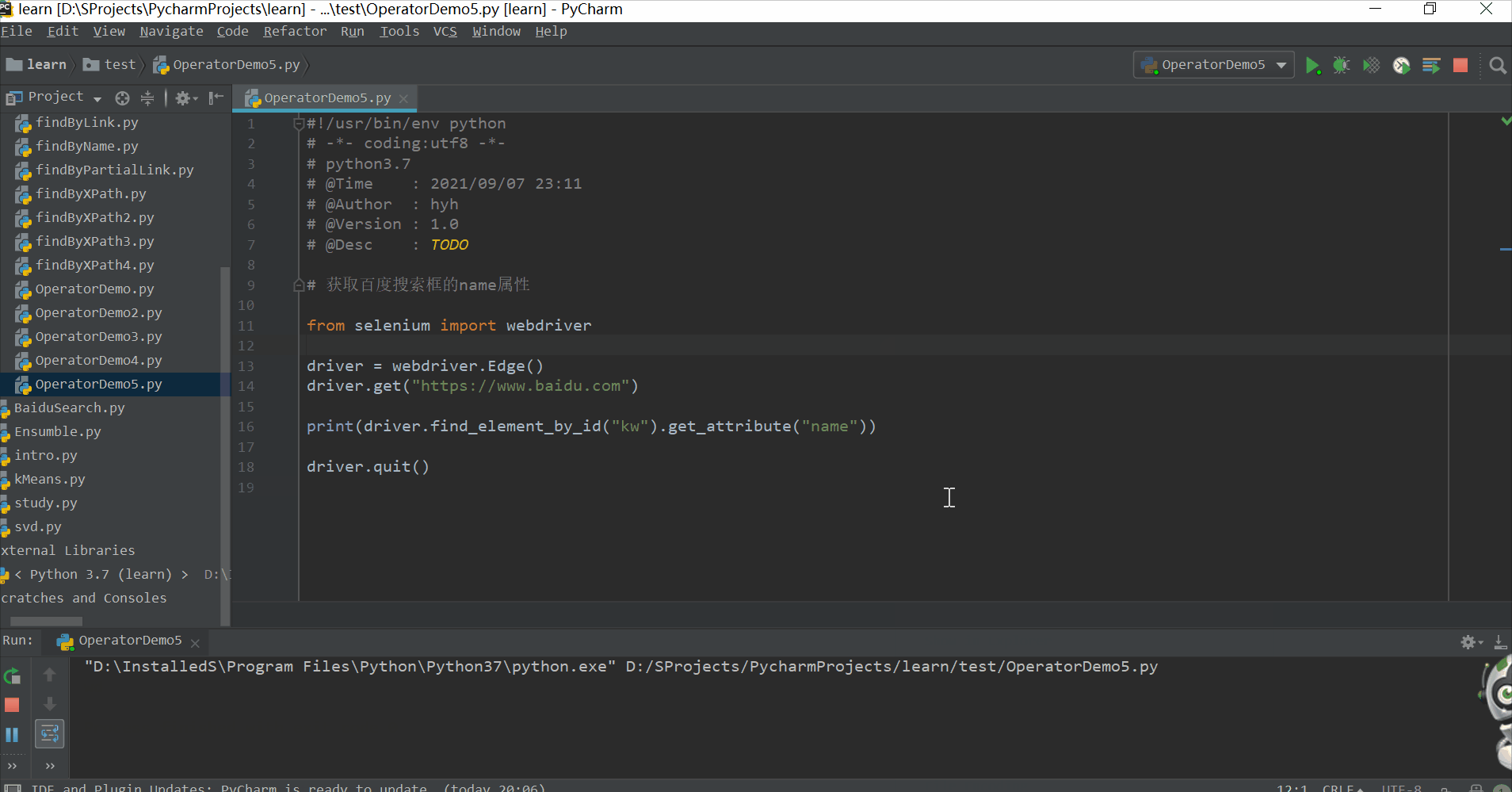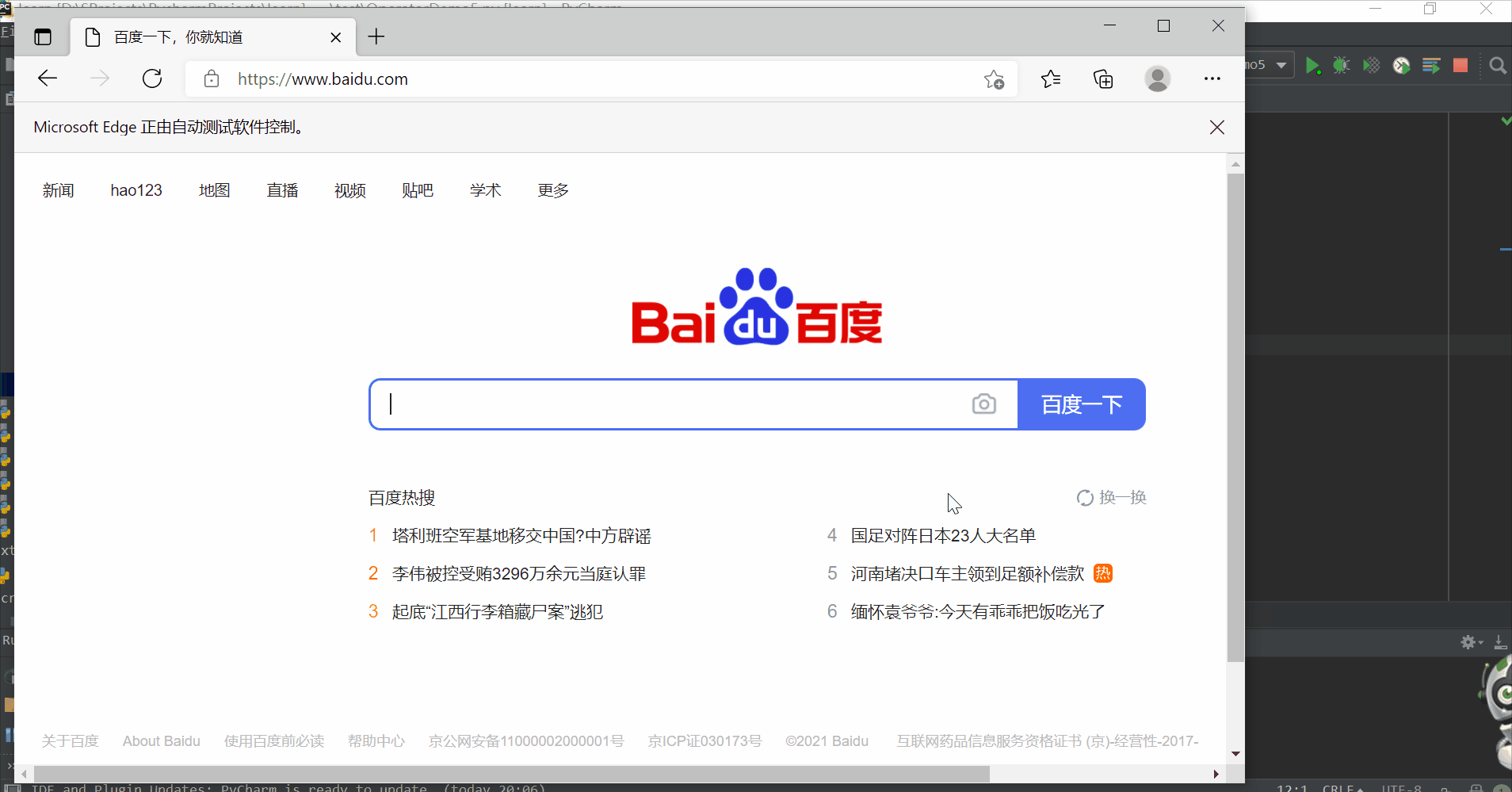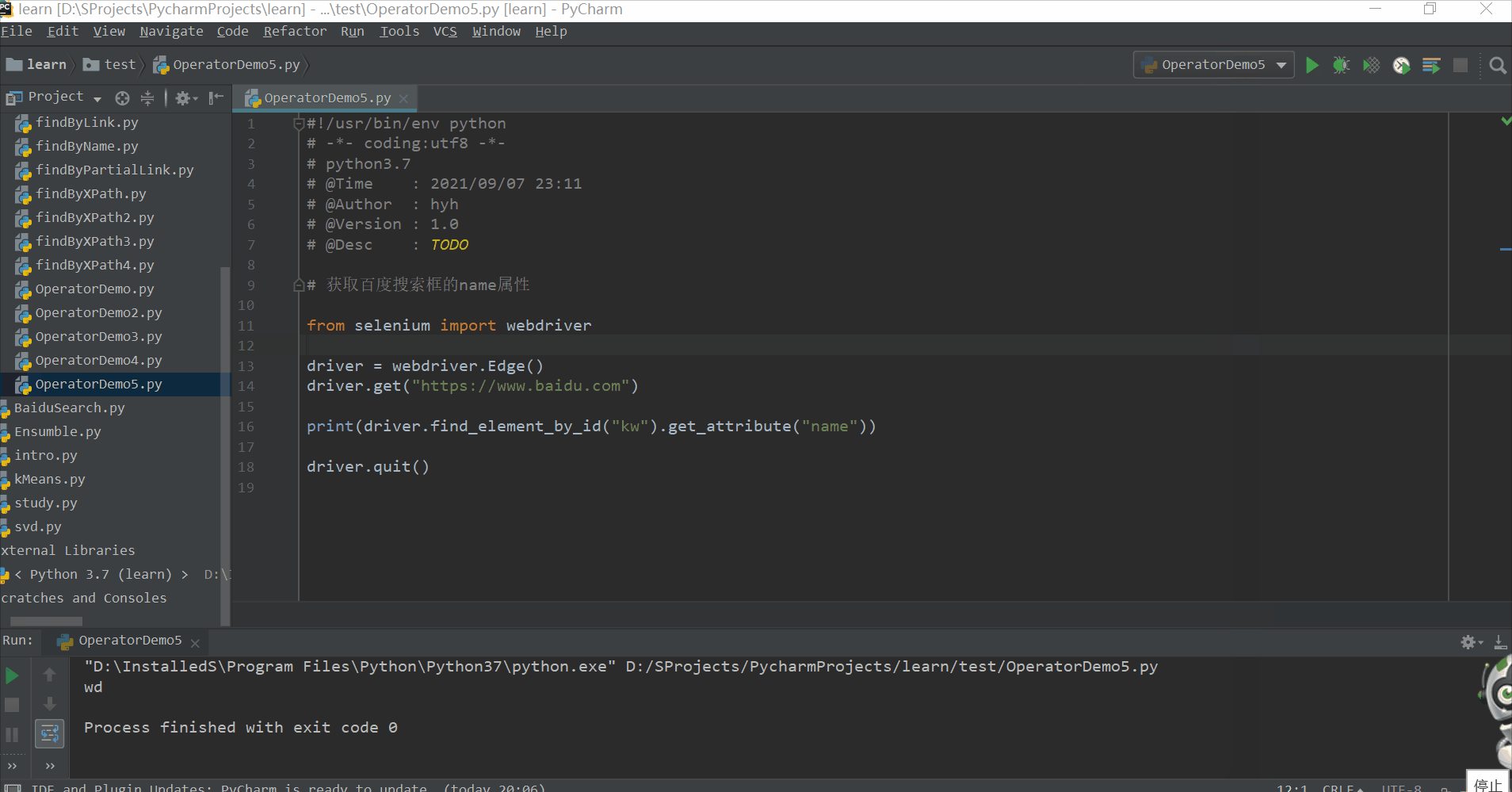
判断“百度一下”,这个按钮是否显示出来了
#!/usr/bin/env python
# -*- coding:utf8 -*-
# python3.7
# @Time : 2021/09/07 23:17
# @Author : hyh
# @Version : 1.0
# @Desc : TODO
# 判断“百度一下”,这个按钮是否显示出来了
from selenium import webdriver
driver = webdriver.Edge()
driver.get("https://www.baidu.com")
print(driver.find_element_by_id("su").is_displayed())
driver.quit()
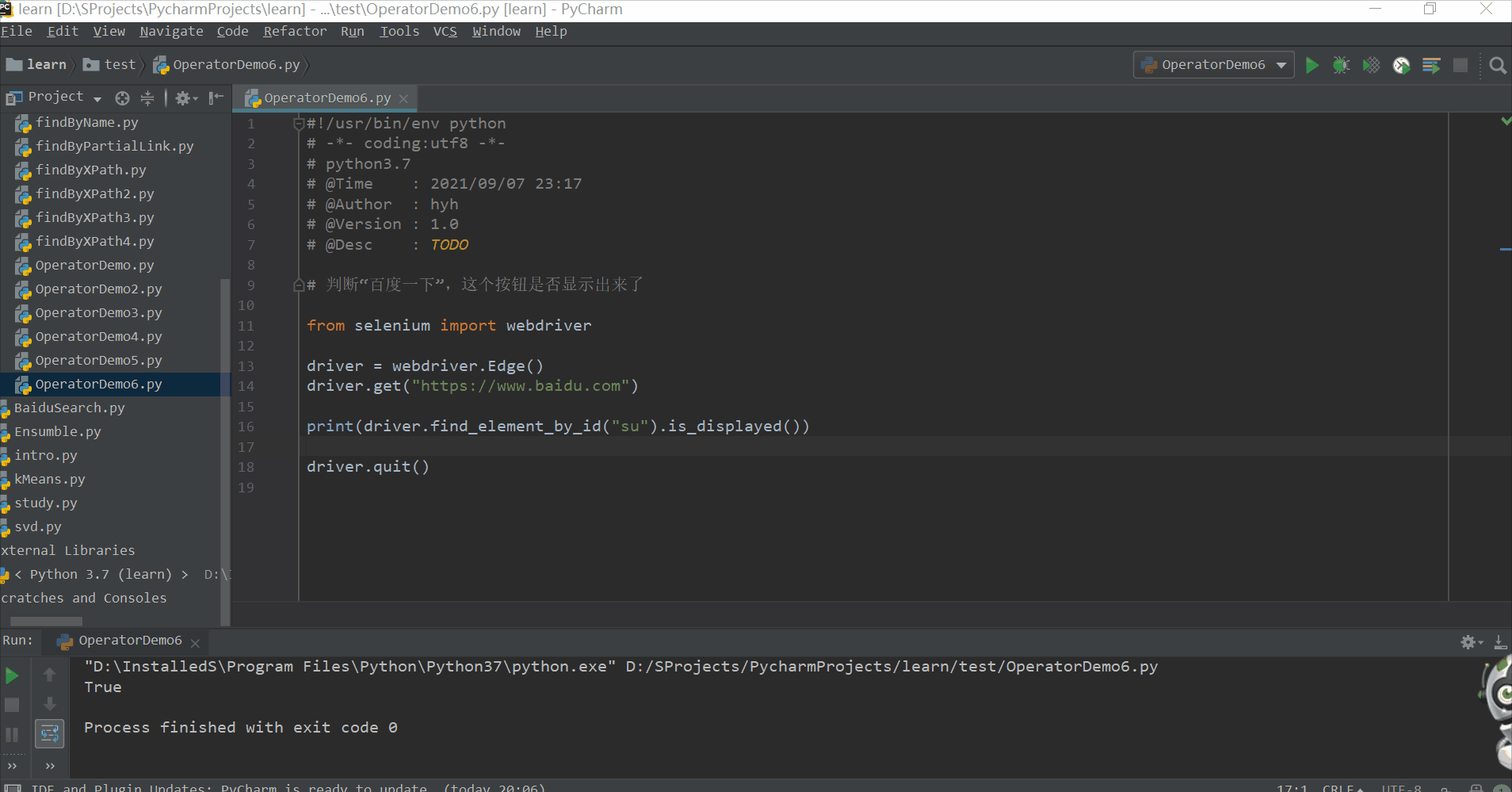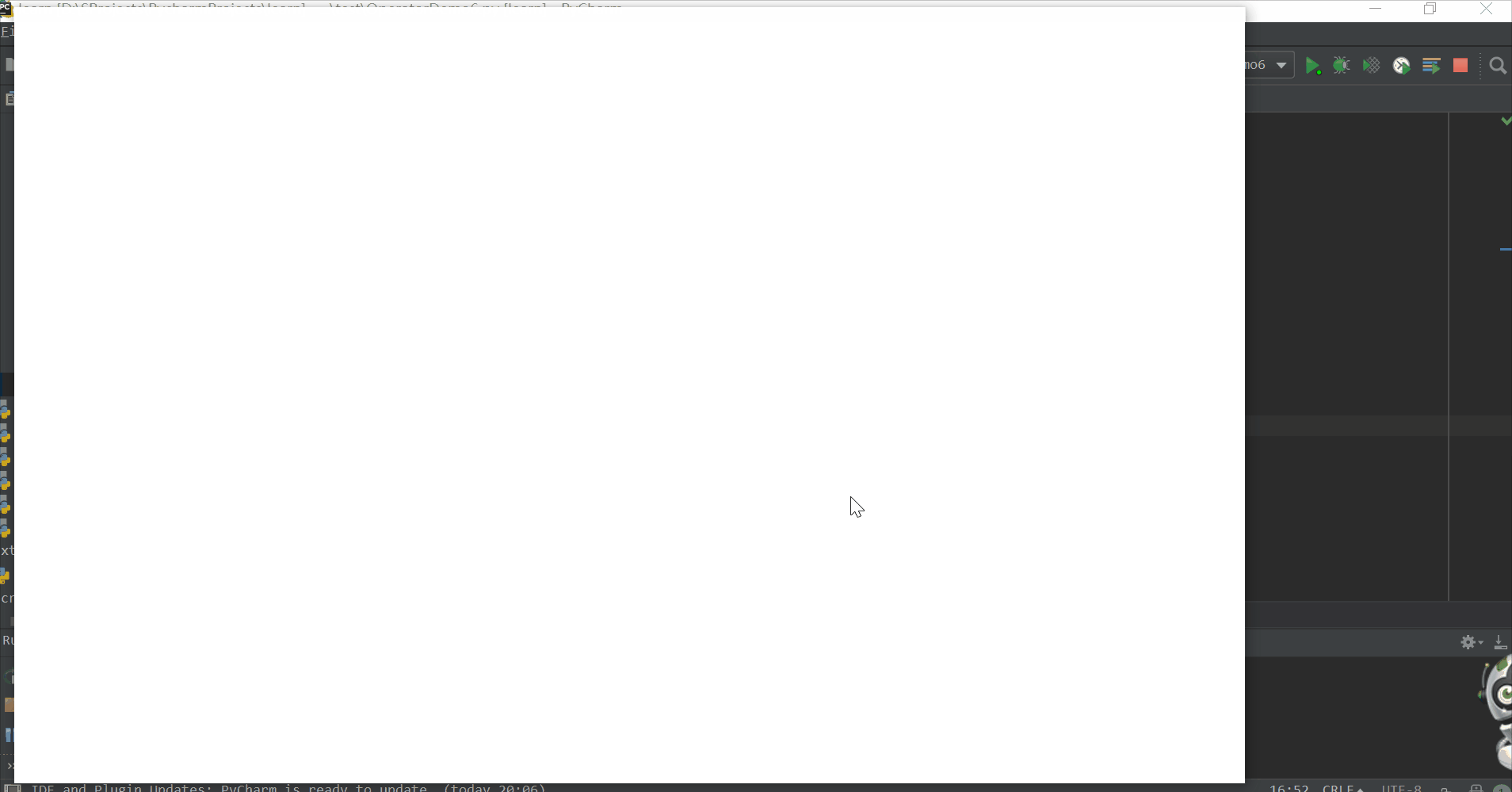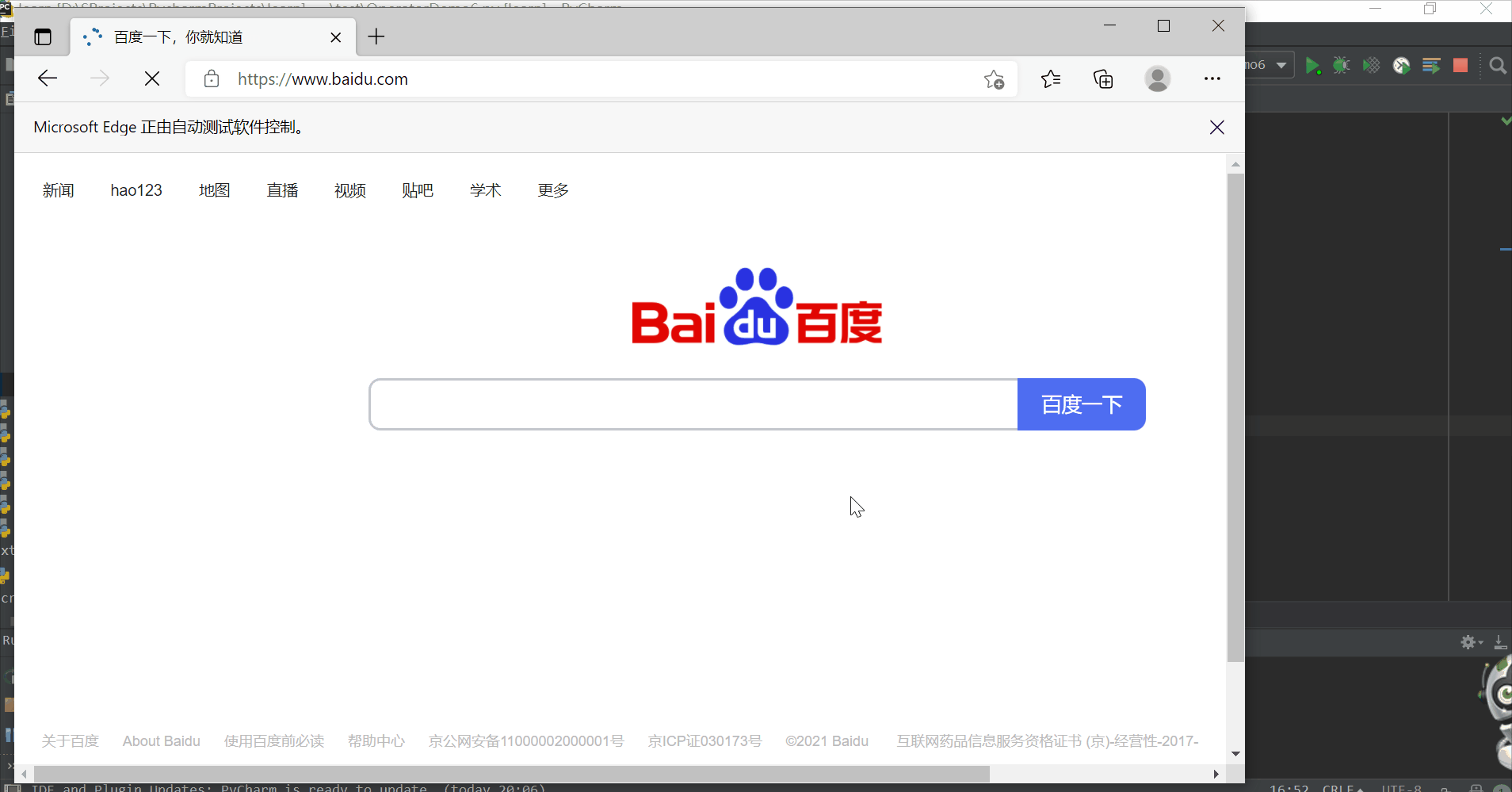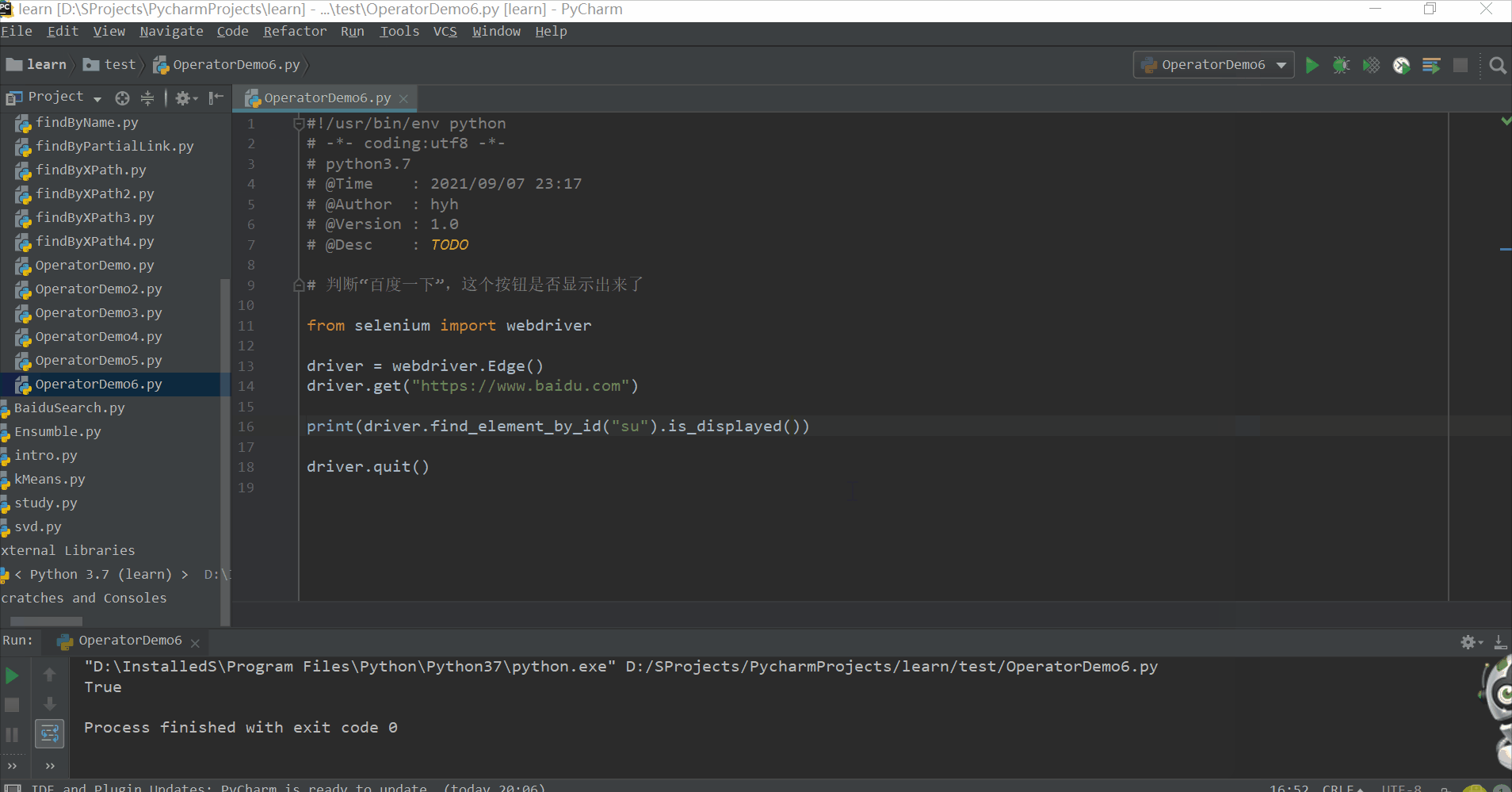
2.8.3 浏览器操作
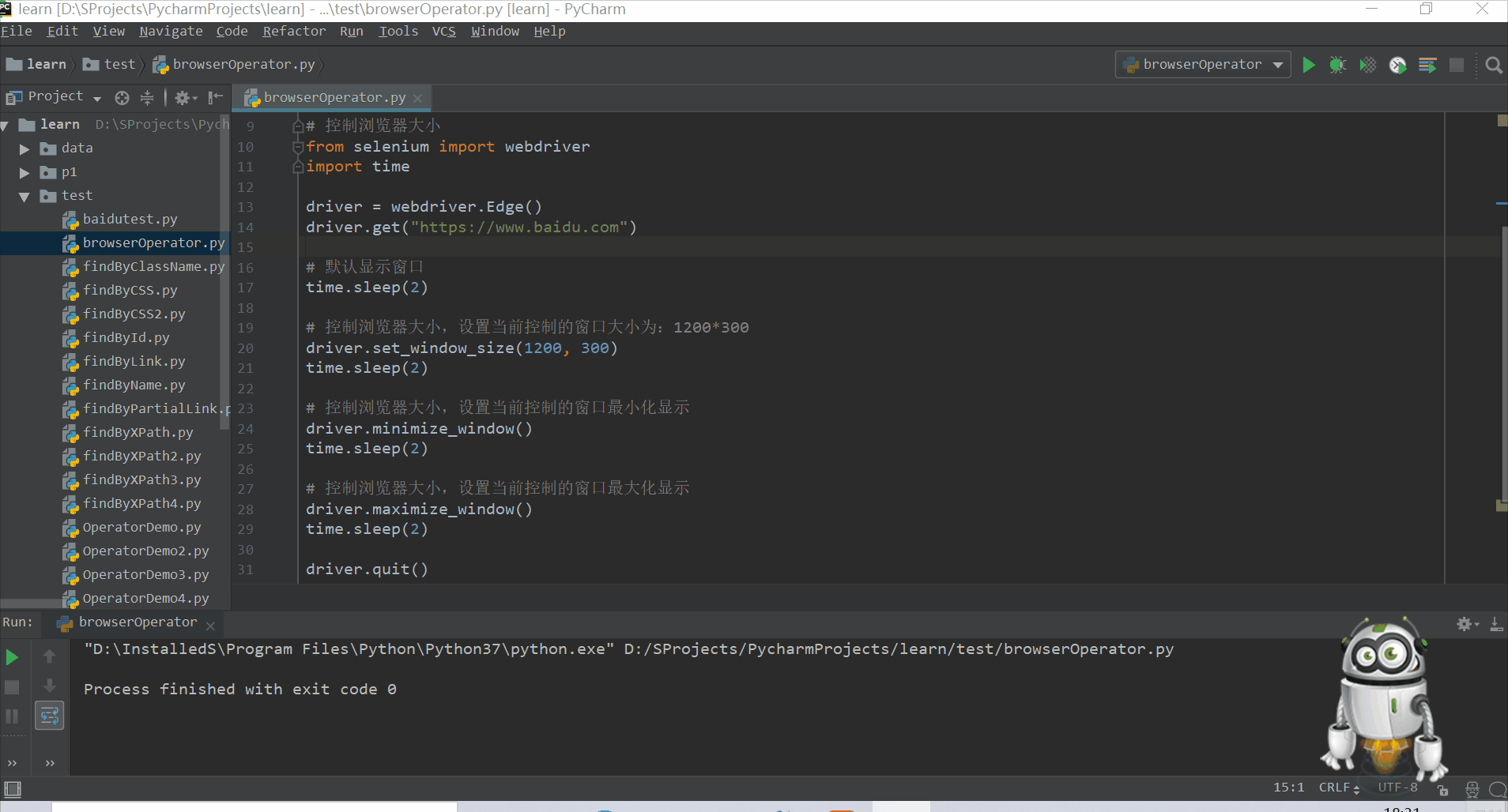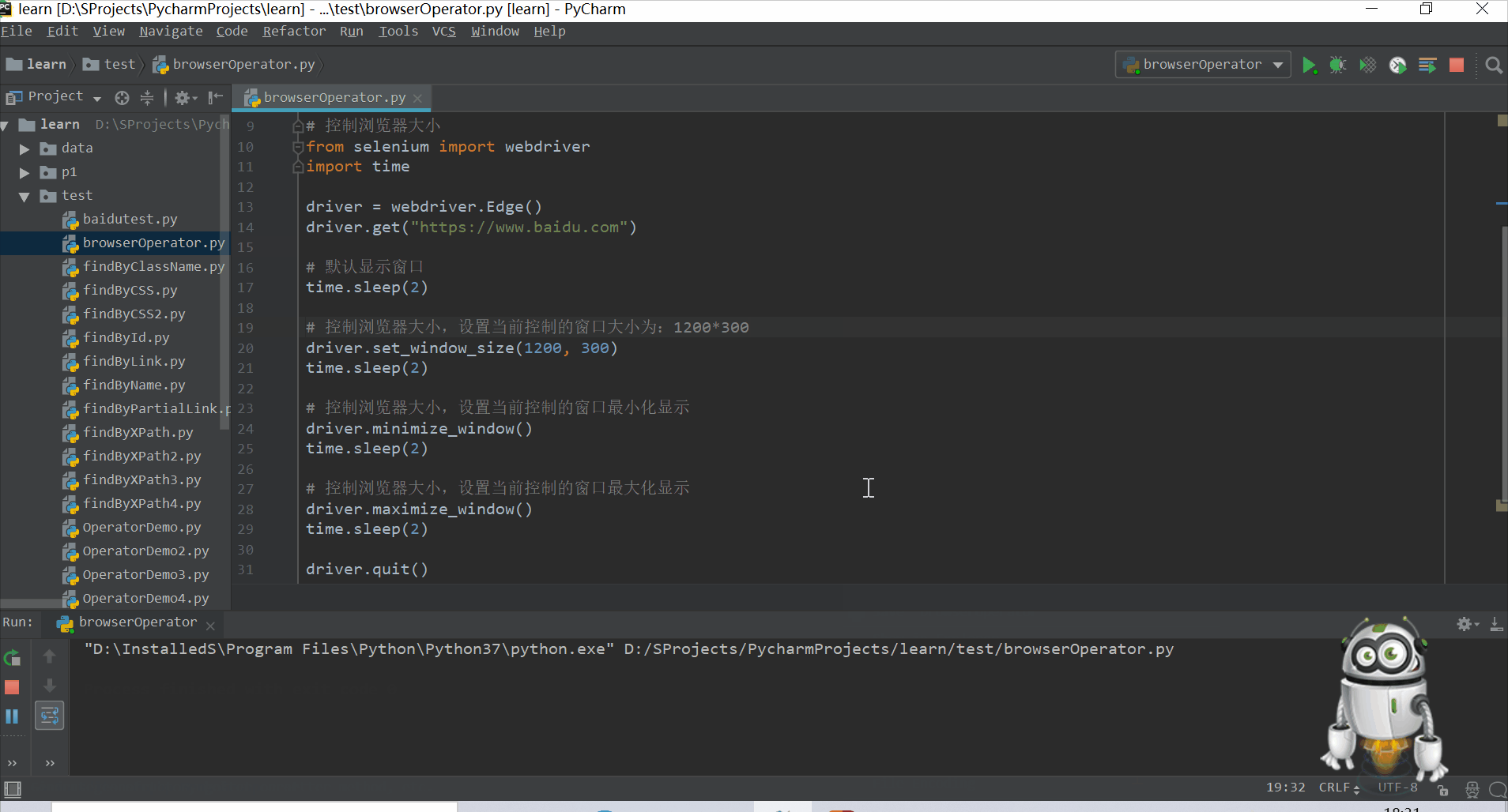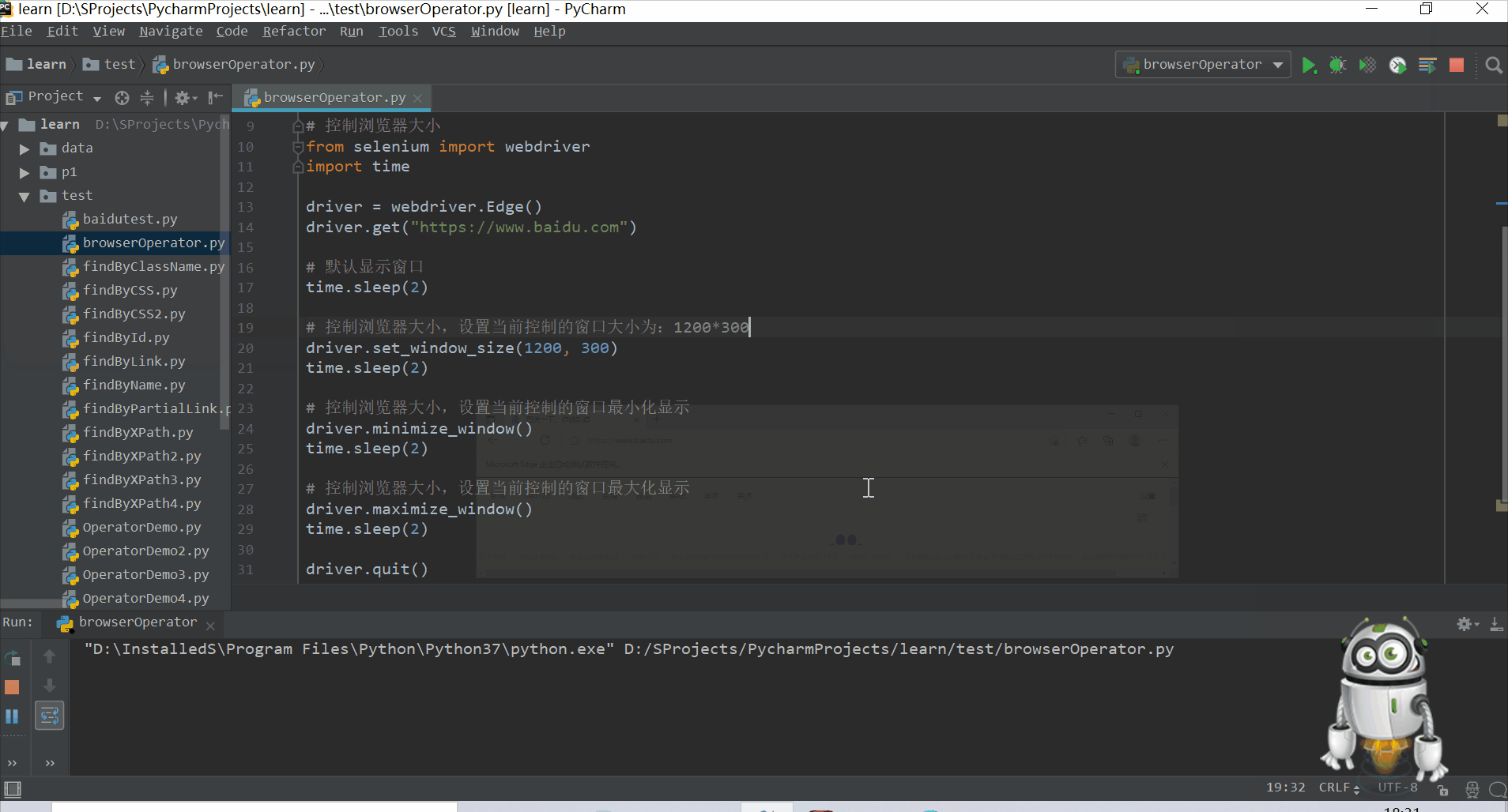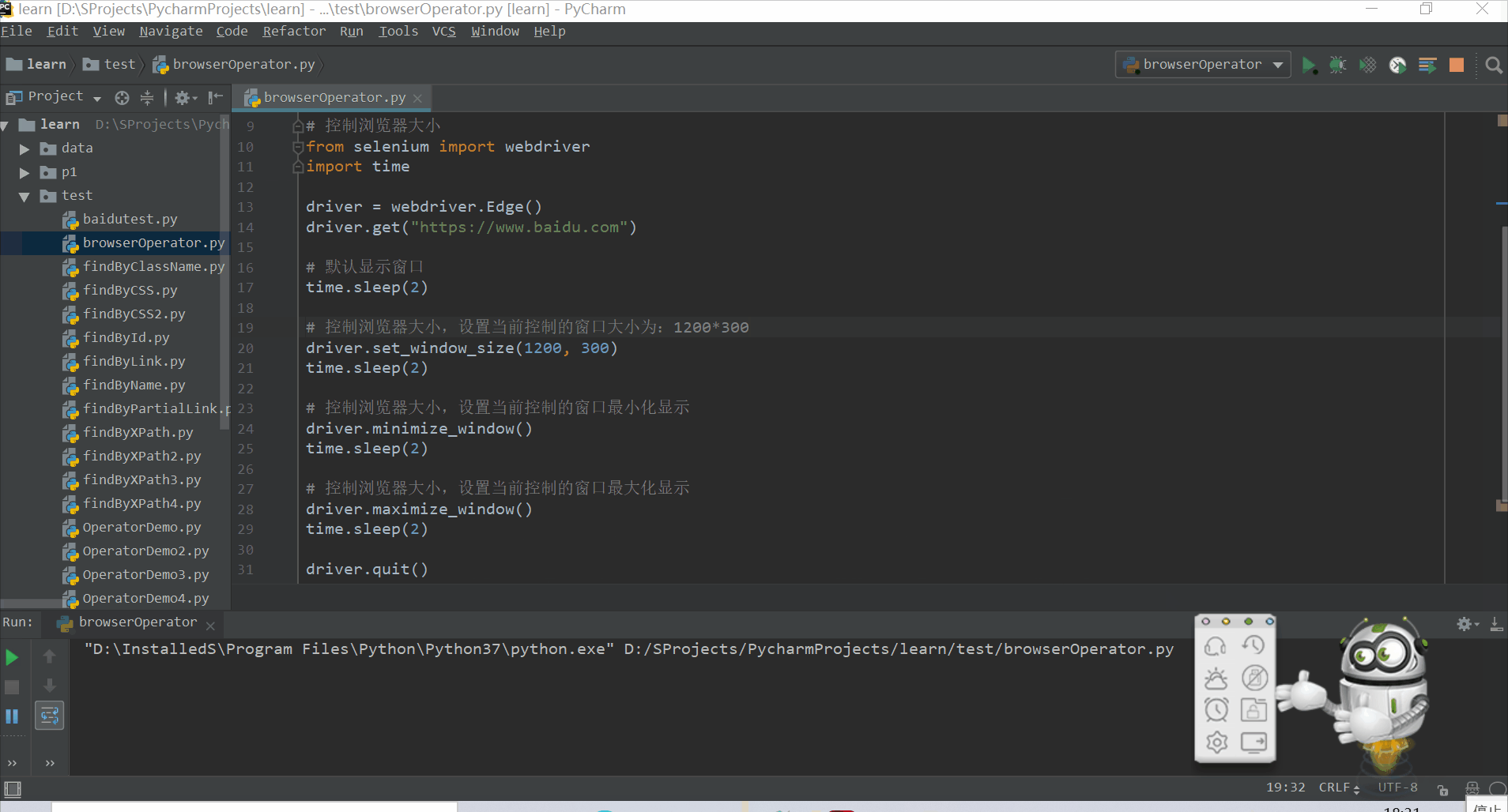
WebDriver主要提供了操作页面上的各种元素的方法,但它也提供了操作浏览器的一些方法,比如:控制浏览器的大小,操作浏览器的前进和后退。
- 控制浏览器的大小:希望浏览器以某种尺寸打开,让访问的网页在这种尺寸下运行,WebDriver提供了
set_window_size()方法来设置浏览器的大小。
maximize_window()窗口最大化
minimize_window()窗口最小化 - 控制浏览器后退,前进:可使用WebDriver提供的
back()和forward()方法来模拟后退和前进按钮。 - 模拟浏览器刷新:WebDriver提供了
refresh()方法来刷新页面。 - 截屏操作:将运行的页面截图保存在本地,推荐使用png格式:
driver.save_screenshot("保存位置")。 - 模拟浏览器关闭:WebDriver提供两种关闭的方法,
close()关闭单个页面和quit()关闭所有页面。
eg:
1)控制当前显示页面的大小
#!/usr/bin/env python
# -*- coding:utf8 -*-
# python3.7
# @Time : 2021/09/16 18:17
# @Author : hyh
# @Version : 1.0
# @Desc : TODO
# 控制浏览器大小
from selenium import webdriver
import time
driver = webdriver.Edge()
driver.get("https://www.baidu.com")
# 默认显示窗口
time.sleep(2)
# 控制浏览器大小,设置当前控制的窗口大小为:1200*300
driver.set_window_size(1200, 300)
time.sleep(2)
# 控制浏览器大小,设置当前控制的窗口最小化显示
driver.minimize_window()
time.sleep(2)
# 控制浏览器大小,设置当前控制的窗口最大化显示
driver.maximize_window()
time.sleep(2)
driver.quit()
2)浏览器回退,前进

#!/usr/bin/env python
# -*- coding:utf8 -*-
# python3.7
# @Time : 2021/09/16 18:37
# @Author : hyh
# @Version : 1.0
# @Desc : TODO
# 浏览器后退,前进
from selenium import webdriver
import time
driver = webdriver.Edge()
driver.get("https://www.baidu.com")
time.sleep(1)
driver.find_element_by_link_text("学术").click()
time.sleep(1)
# 页面后退
driver.back()
time.sleep(2)
# 页面前进
driver.forward()
time.sleep(2)
driver.quit()
由于我的浏览器的设置是在新窗口打开网页而不是覆盖,所以这里体现不出效果。

3)刷新(略)
4)截图,百度首页跳转到地图页面,截图保存到桌面
#!/usr/bin/env python
# -*- coding:utf8 -*-
# python3.7
# @Time : 2021/09/16 19:52
# @Author : hyh
# @Version : 1.0
# @Desc : TODO
# 截图
from selenium import webdriver
import time
driver = webdriver.Edge()
driver.get("https://www.baidu.com")
driver.find_element_by_link_text("地图").click()
time.sleep(3)
# 第一种截图方式
driver.save_screenshot("C:\\Users\\hyh\\Desktop\\图片.png")
# 第二种截图方式 会截图第一个页面
driver.get_screenshot_as_file("C:\\Users\\hyh\\Desktop\\图片2.png")
# 使用占位的方式截图 会截图第二个页面
driver.get_screenshot_as_file("{}.{}".format("C:\\Users\\hyh\\Desktop\\图片3", "png"))
driver.quit()
上述代码无法做到截第二张网页的图(无论是用Edge还是Chrome)…这是由于driver绑定句柄的问题,这个后面再说…
5)页面关闭(略)
2.8.4 多窗口操作、句柄操作
2.8.4.1 多窗口操作
eg:
1.首先打开github
2.进入仓库evej

3.返回github主页
#!/usr/bin/env python
# -*- coding:utf8 -*-
# python3.7
# @Time : 2021/09/17 10:42
# @Author : hyh
# @Version : 1.0
# @Desc : TODO
"""
多窗口操作
1.首先打开github
2.进入仓库evej
3.返回github主页
"""
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("https://github.com/")
time.sleep(1)
driver.find_element_by_link_text("Sign in").click()
driver.find_element_by_css_selector("#login_field").send_keys("你的用户名")
driver.find_element_by_css_selector("#password").send_keys("你的密码")
driver.find_element_by_name("commit").click()
time.sleep(2)
driver.find_element_by_xpath("//*[@id='repos-container']/ul/li[2]/div/a/span[2]").click()
time.sleep(2)
driver.back()
time.sleep(2)
driver.close()

重点来了:
句柄(handler):每一个页面都有一个唯一的值,作为页面的唯一标识,driver会绑定句柄,这就意味着driver只能控制它绑定句柄的页面,如果你单单只是在一个窗口上操作,那么可以不用考虑切换控制的问题,但如果你想在打开的新窗口上操作就得使用切换控制的句柄来达到目的。
2.8.4.2 句柄操作 driver.current_window_handle、driver.window_handles、driver.switch_to_window("句柄值")
操作句柄,能够解决前面遇到的打开新窗口不能操纵的问题,实际上究其原因就是driver没有控制那个新打开的页面。
获得当前driver操控窗口的句柄
driver.current_window_handle
获得浏览器中打开窗口的所有句柄
# 列表的形式
driver.window_handles
driver绑定句柄
driver.switch_to_window("句柄值")
eg:
截图百度地图
1.进入百度首页 2.点击“地图”链接 3.设置driver操纵的句柄 4.截取屏幕
#!/usr/bin/env python
# -*- coding:utf8 -*-
# python3.7
# @Time : 2021/09/17 21:17
# @Author : hyh
# @Version : 1.0
# @Desc : TODO
# 1.进入百度首页 2.点击“地图”链接 3.设置driver操纵的句柄 4.截取屏幕
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.find_element_by_link_text("地图").click()
time.sleep(3)
# 查看所有句柄
print(driver.window_handles) # ['CDwindow-89962ED02556B0FA920ABEA6AD1F7C20', 'CDwindow-7050CABF408BFC41447382C349EA5193']
# 查看当前操控的句柄
print(driver.current_window_handle) # CDwindow-89962ED02556B0FA920ABEA6AD1F7C20
# 将地图页面的句柄绑定到driver
driver.switch_to.window(driver.window_handles[1])
# 截屏地图页面
driver.save_screenshot(r"C:\Users\hyh\Desktop\百度地图.png")
driver.quit()

2.8.5 鼠标、键盘操作
2.8.5.1 鼠标操作ActionChains move_to_element()、context_click()、drag_and_drop()、double_click()…
鼠标事件:前面有讲过click(),这个就是模拟鼠标进行单击的操作。现在的web产品中提供了更加丰富的交互方式,比如鼠标右击,双击,悬停,甚至是鼠标拖动等。在WebDriver中,这些方法被封装在ActionChains类中,需要导入如下的包:
from selenium.webdriver.common.action_chains import ActionChains
常用的方法:
perform()执行所有ActionChains中存储的行为context_click()右击double_click()双击drag_and_drop()拖拽move_to_element()鼠标悬停- …
eg:
百度首页在设置链接上鼠标悬停
#!/usr/bin/env python
# -*- coding:utf8 -*-
# python3.7
# @Time : 2021/09/17 23:25
# @Author : hyh
# @Version : 1.0
# @Desc : TODO
# 鼠标操作ActionChains
# 鼠标悬停
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import time
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.maximize_window()
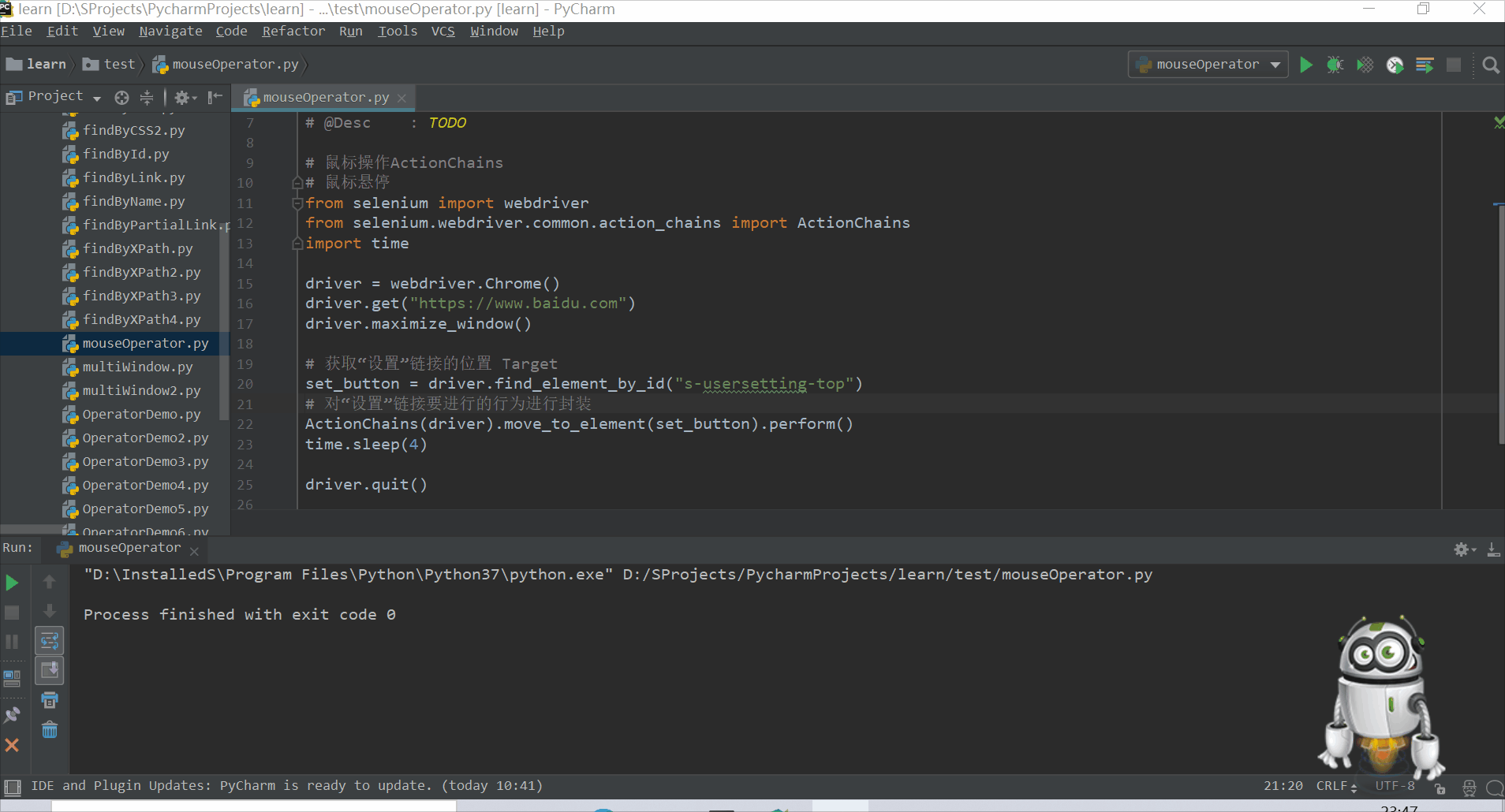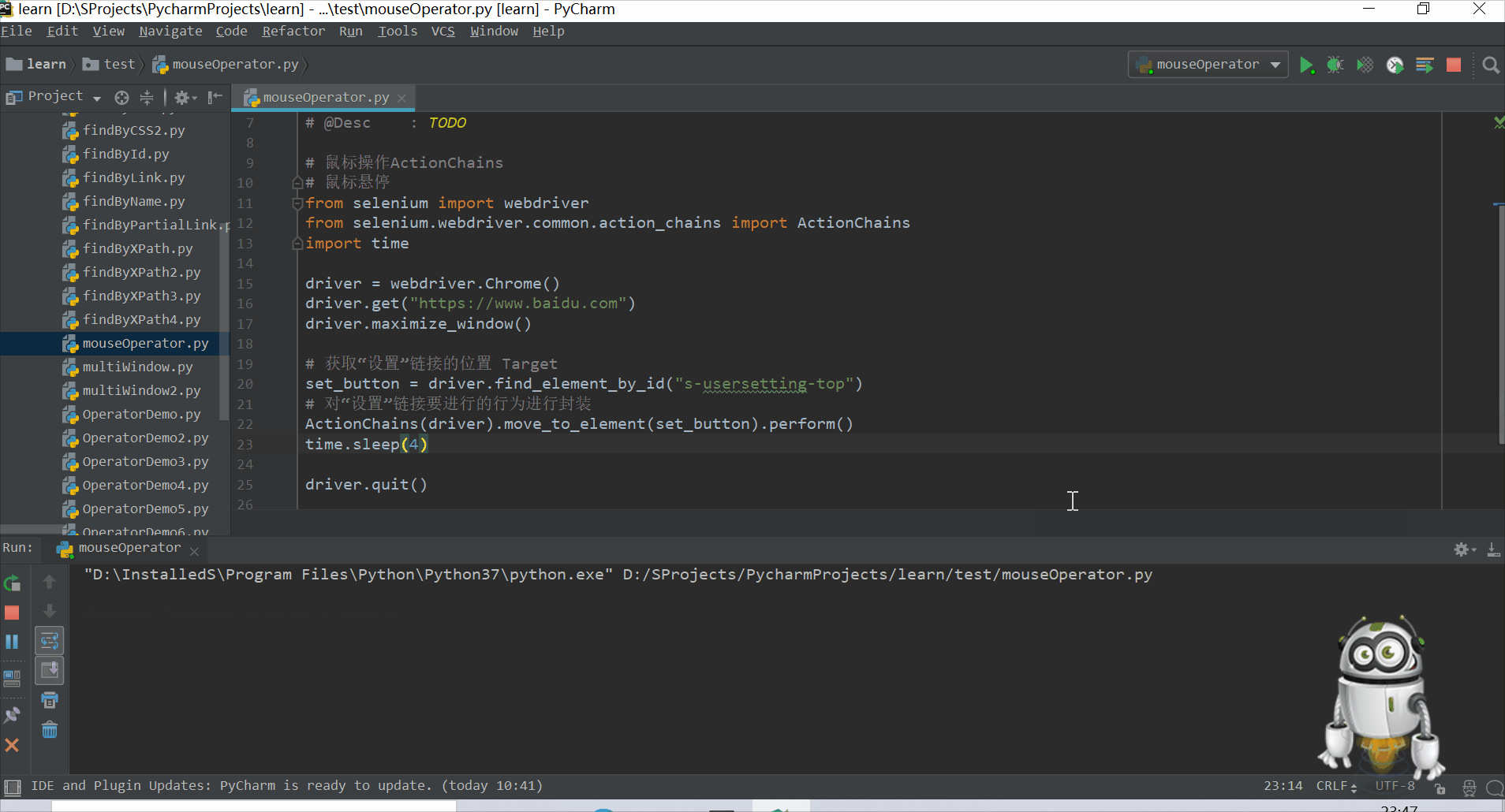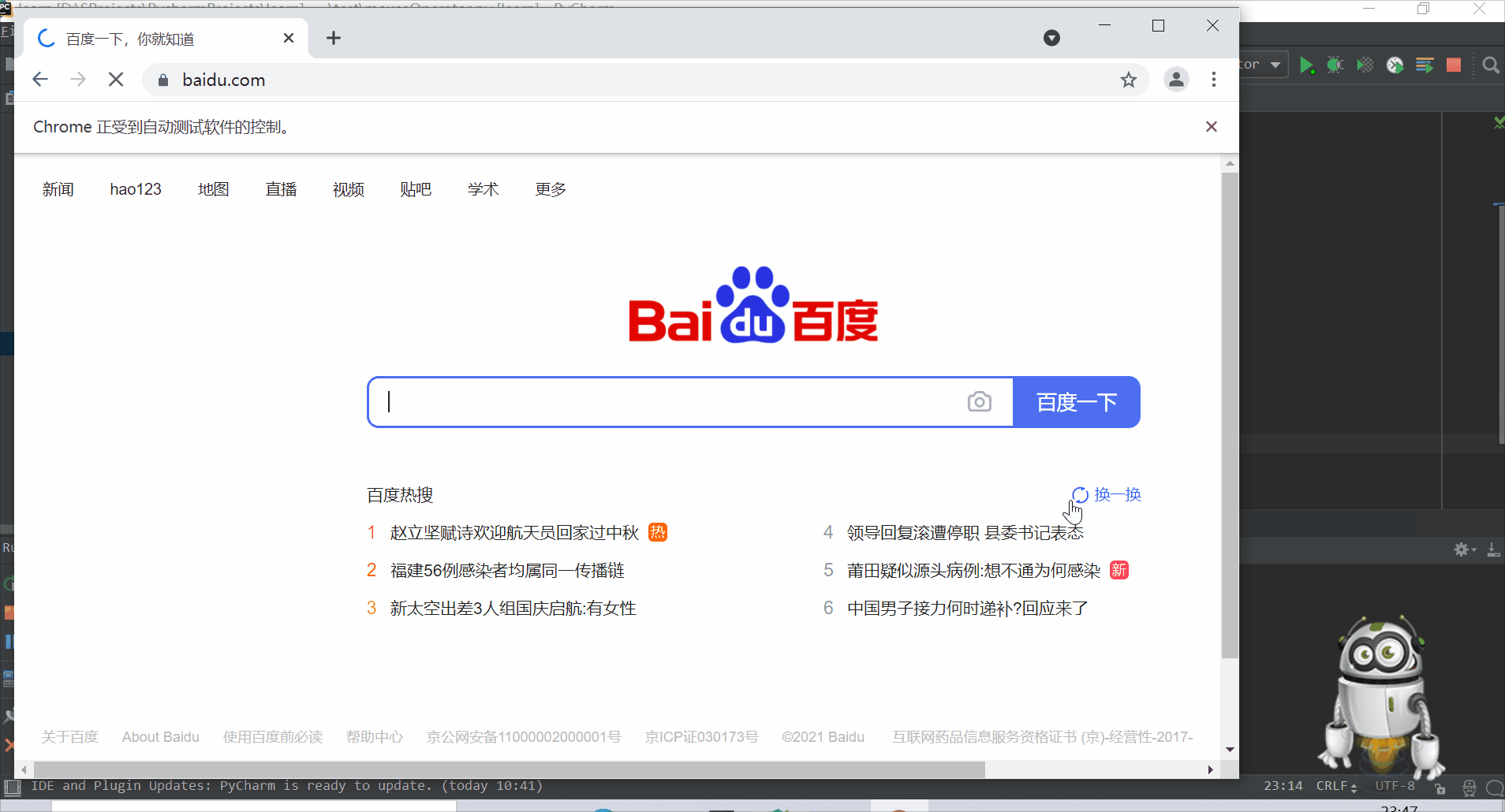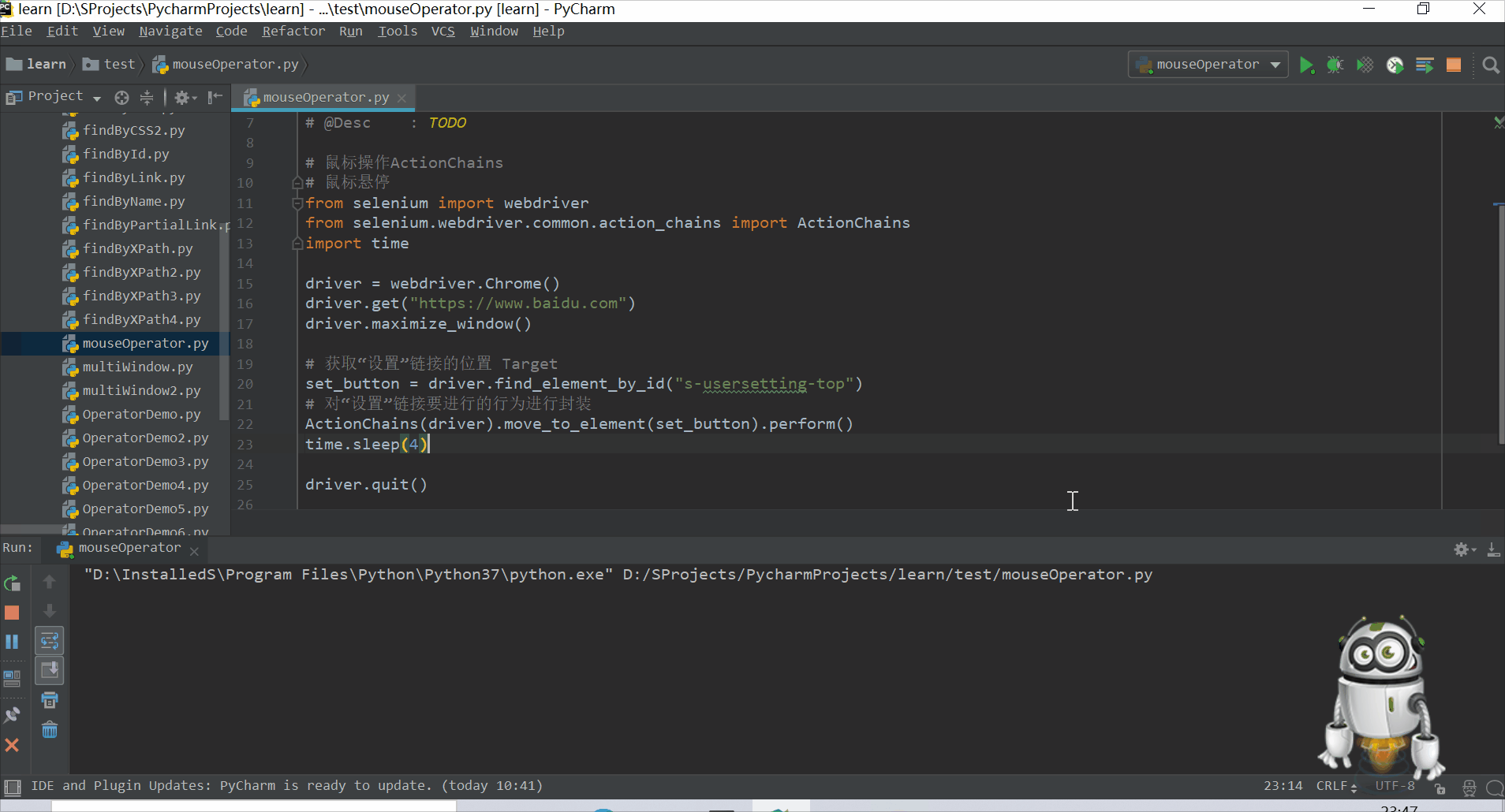
# 获取“设置”链接的位置 Target
set_button = driver.find_element_by_id("s-usersetting-top")
# 对“设置”链接要进行的行为进行封装
ActionChains(driver).move_to_element(set_button).perform()
time.sleep(4)
driver.quit()
百度首页鼠标右击
#!/usr/bin/env python
# -*- coding:utf8 -*-
# python3.7
# @Time : 2021/09/17 23:50
# @Author : hyh
# @Version : 1.0
# @Desc : TODO
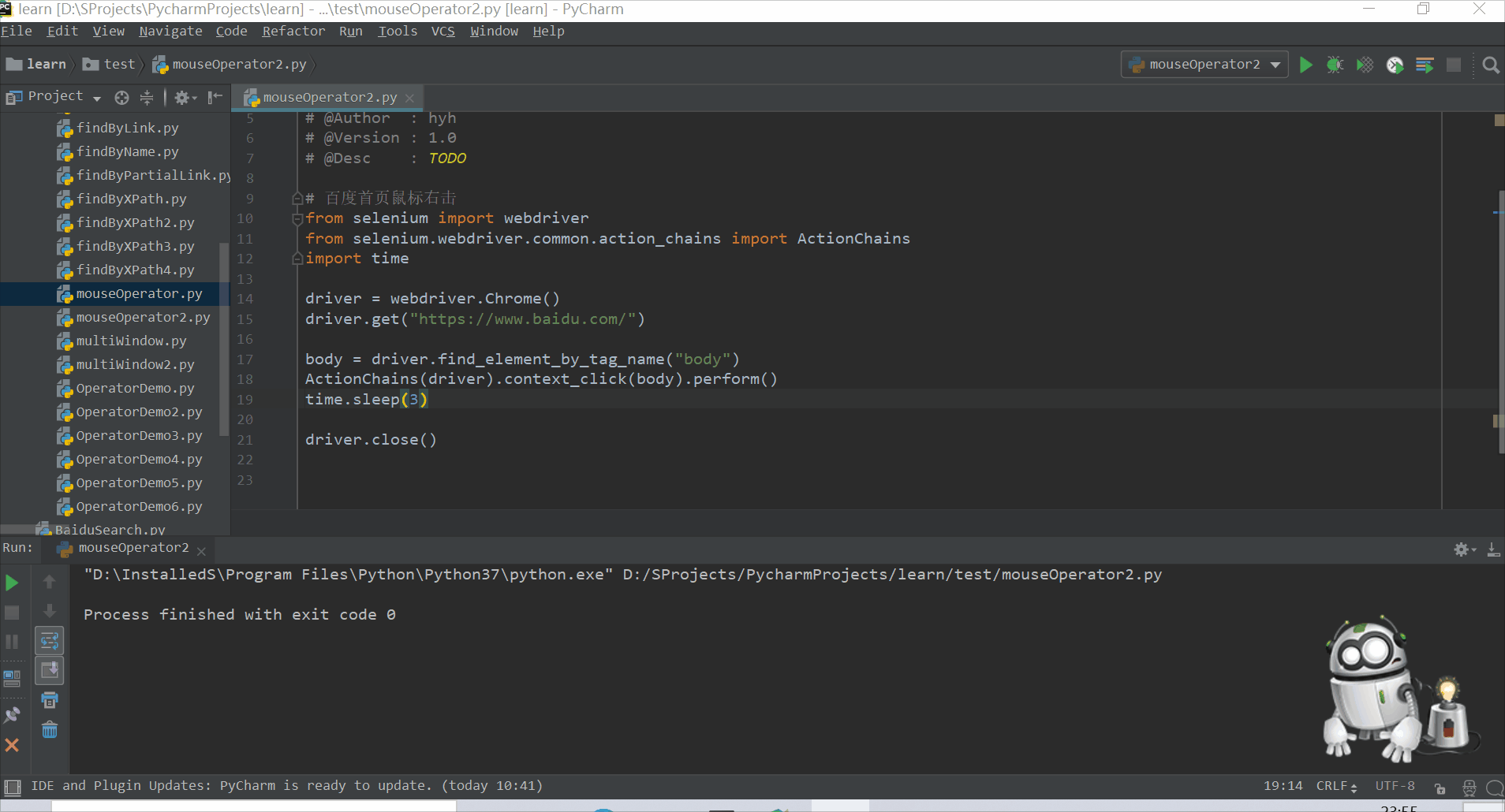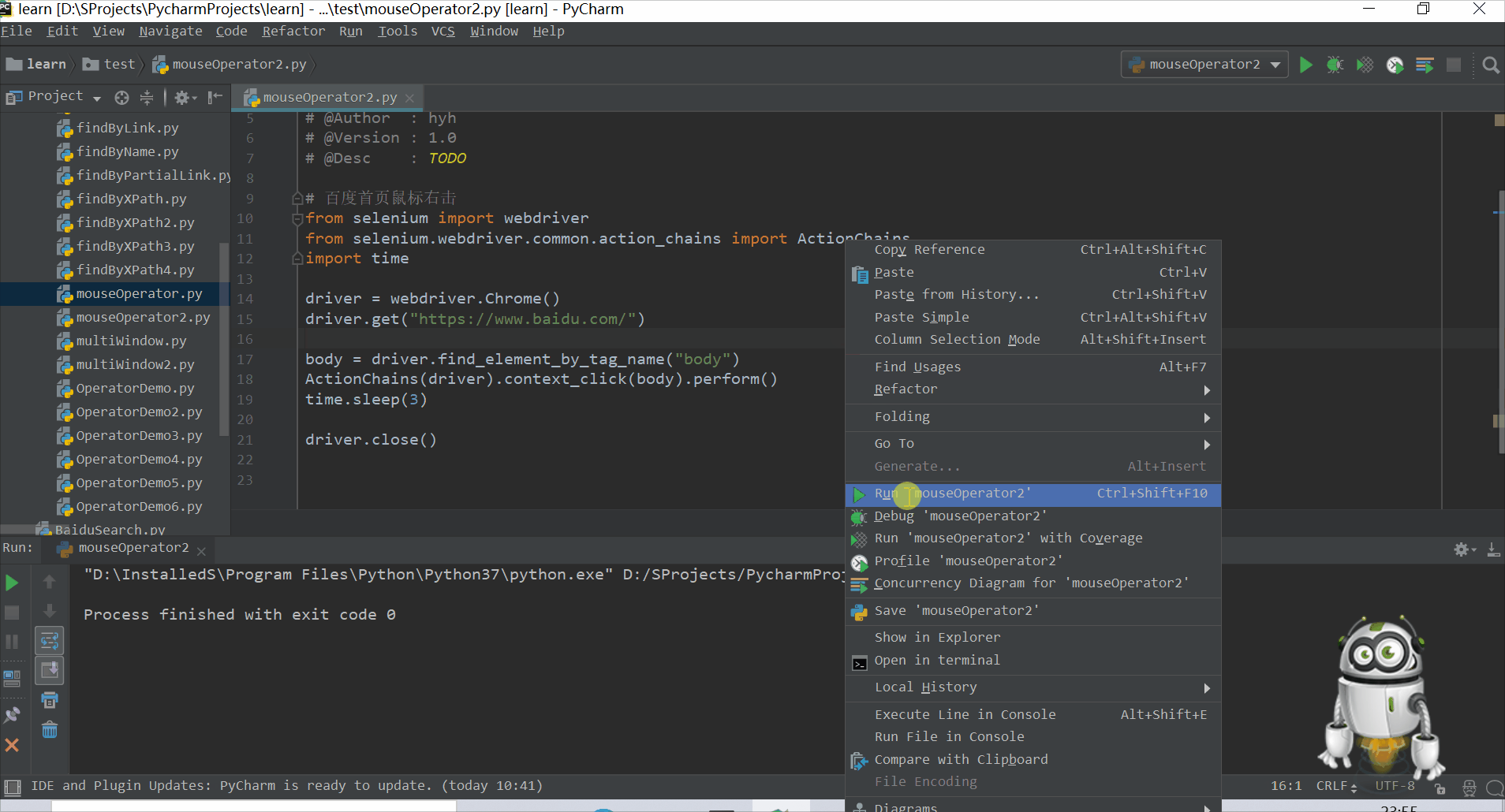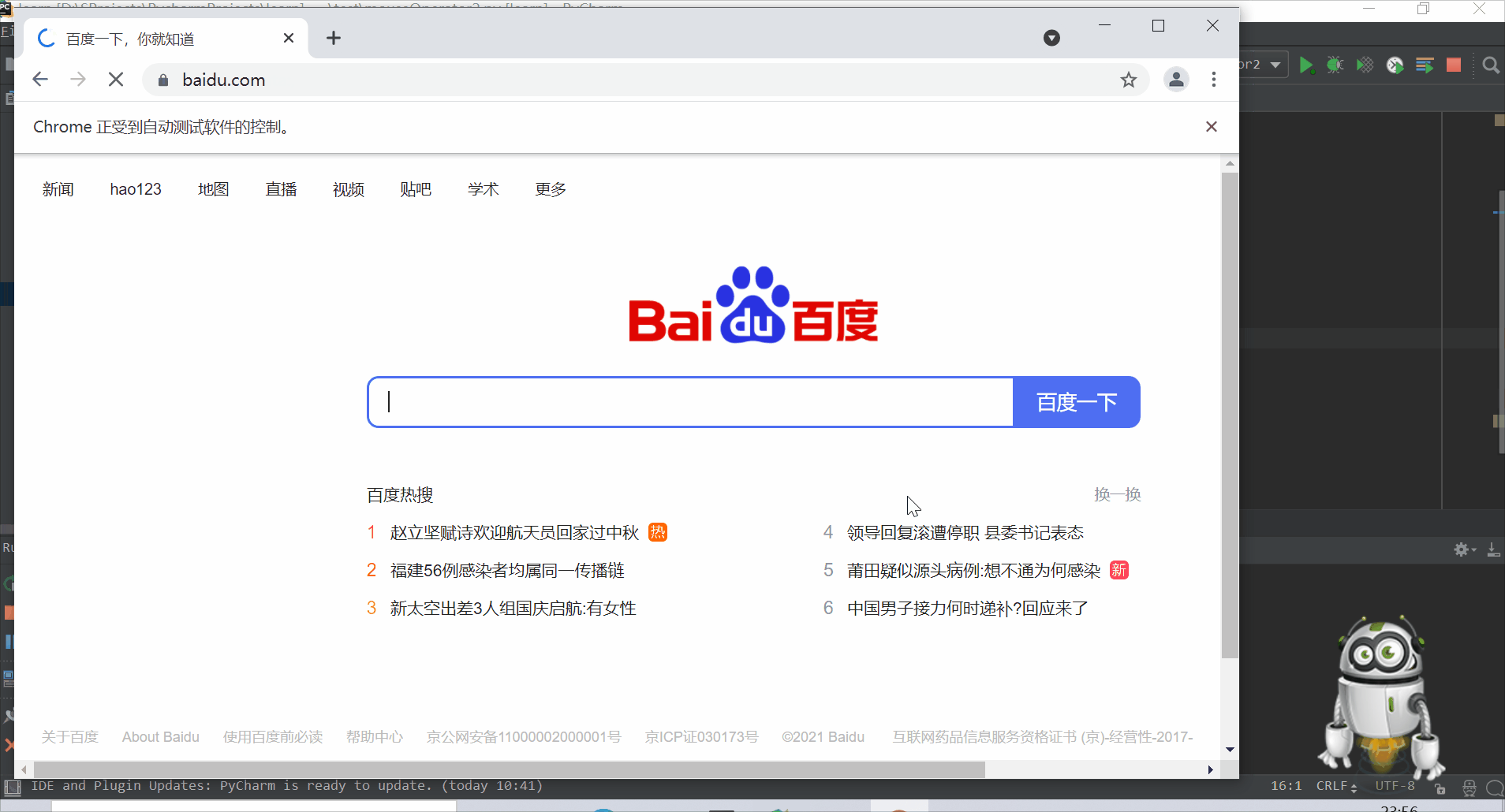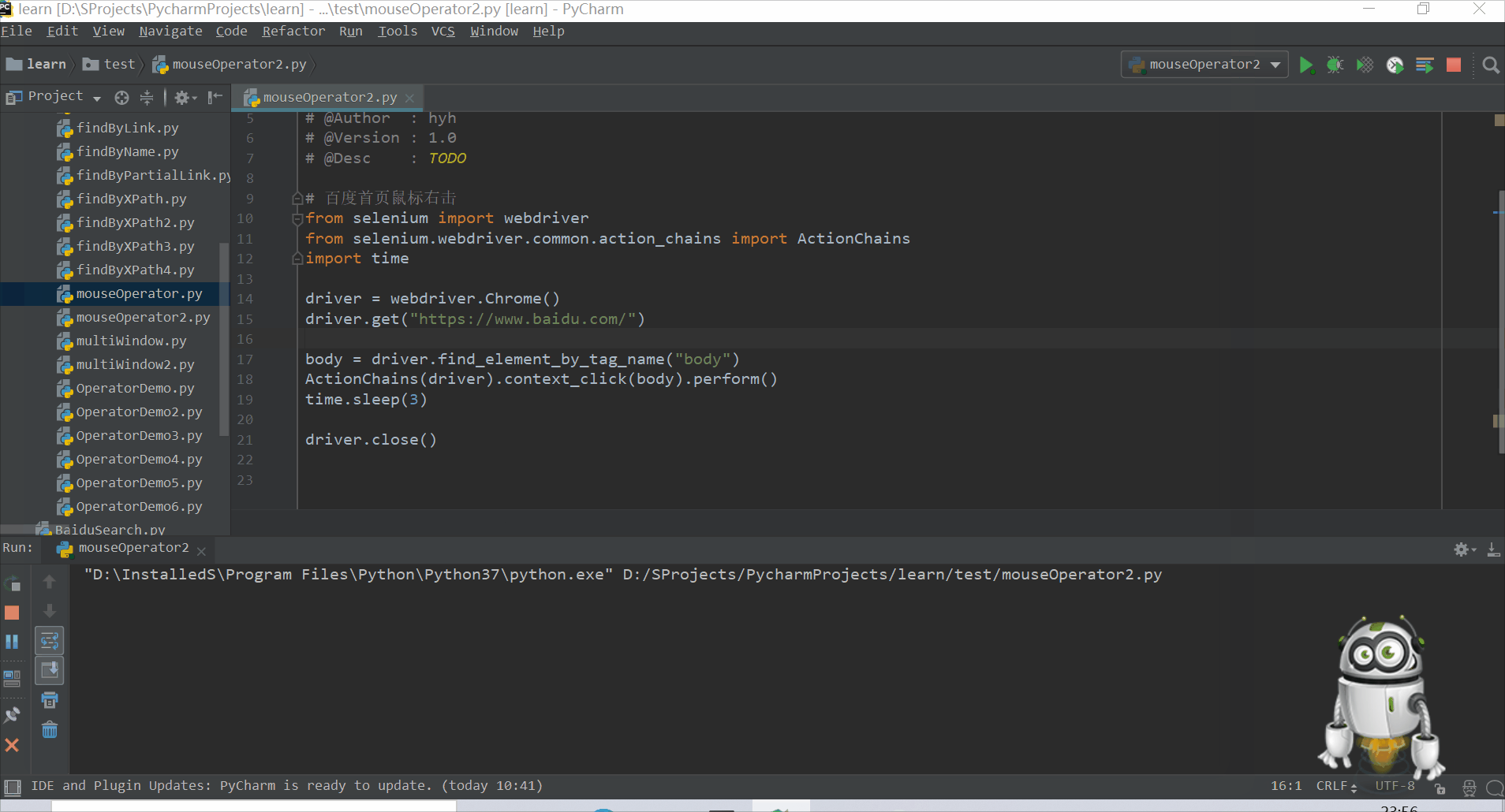
# 百度首页鼠标右击
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import time
driver = webdriver.Chrome()
driver.get("https://www.baidu.com/")
body = driver.find_element_by_tag_name("body")
ActionChains(driver).context_click(body).perform()
time.sleep(3)
driver.close()
2.8.5.2 键盘操作keys
键盘事件:keys类提供了键盘上几乎所有的按键的方法,比如send_keys()方法可以用来模拟键盘输入,除此之外,我们还可以用它来输入键盘上的按键,甚至是组合键,如Ctrl+C等,需要导入以下包:
from selenium.webdriver.common.keys import keys



常用的按键:
Send_keys(Keys.Back_SPACE)删除键Send_keys(Keys.SPACE)空格键Send_keys(Keys.TAB)制表键Send_keys(Keys.ESCAPE)esc键Send_keys(Keys.ENTER)回车键Send_keys(Keys.CONTROL,"a")全选Send_keys(Keys.CONTROL,"c")复制Send_keys(Keys.CONTROL,"x")剪切Send_keys(Keys.CONTROL,"v")粘贴
eg:
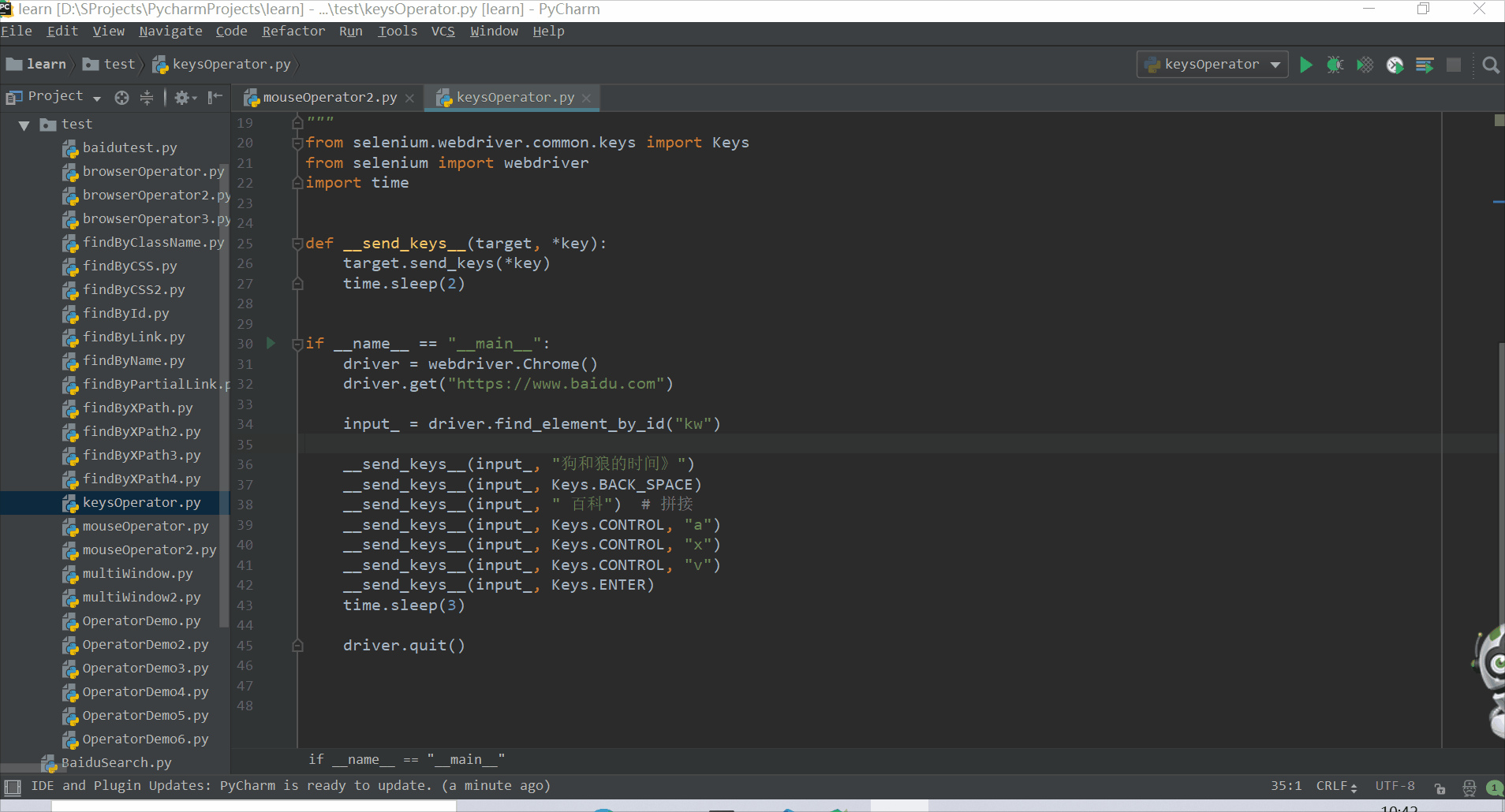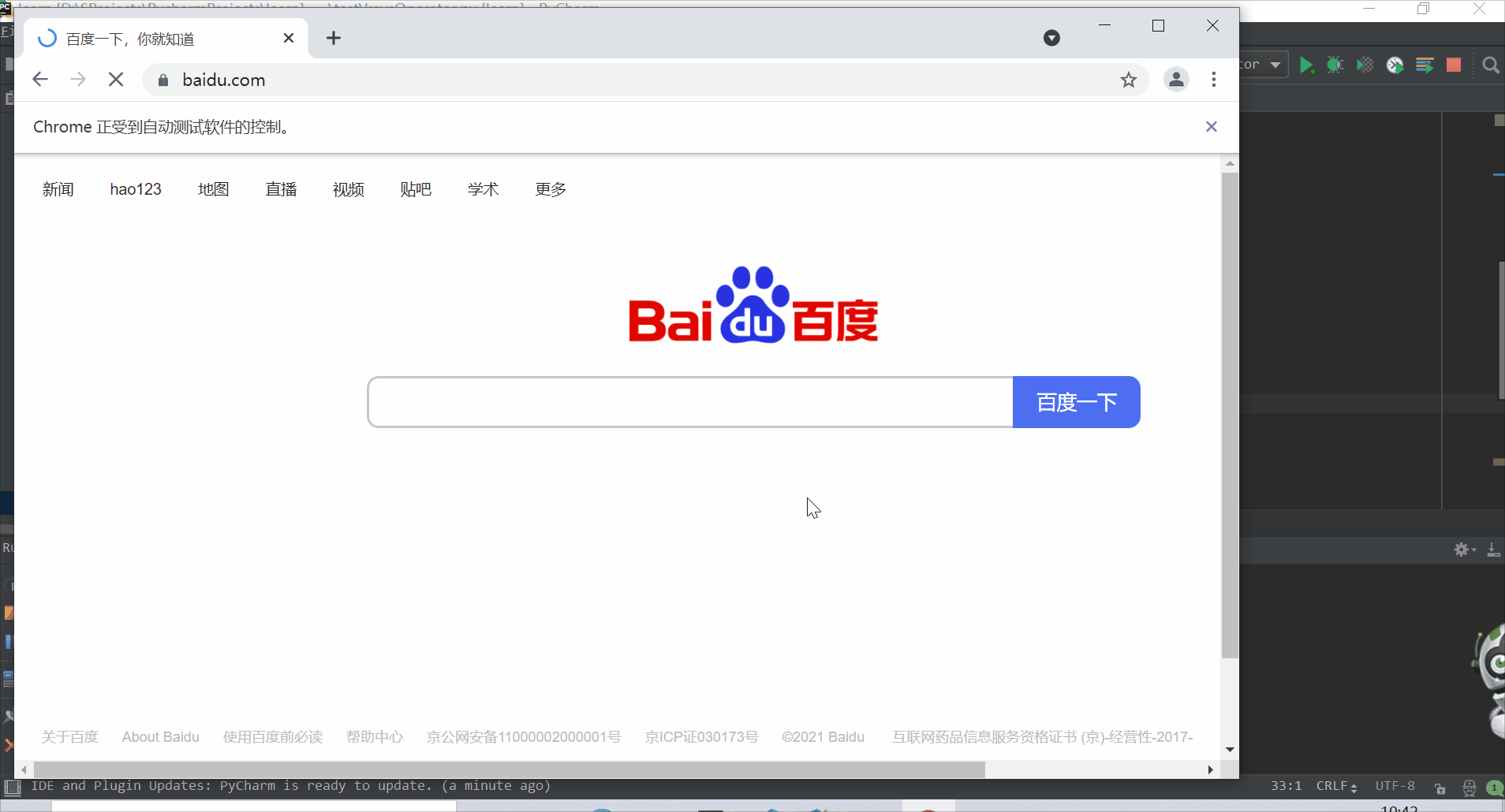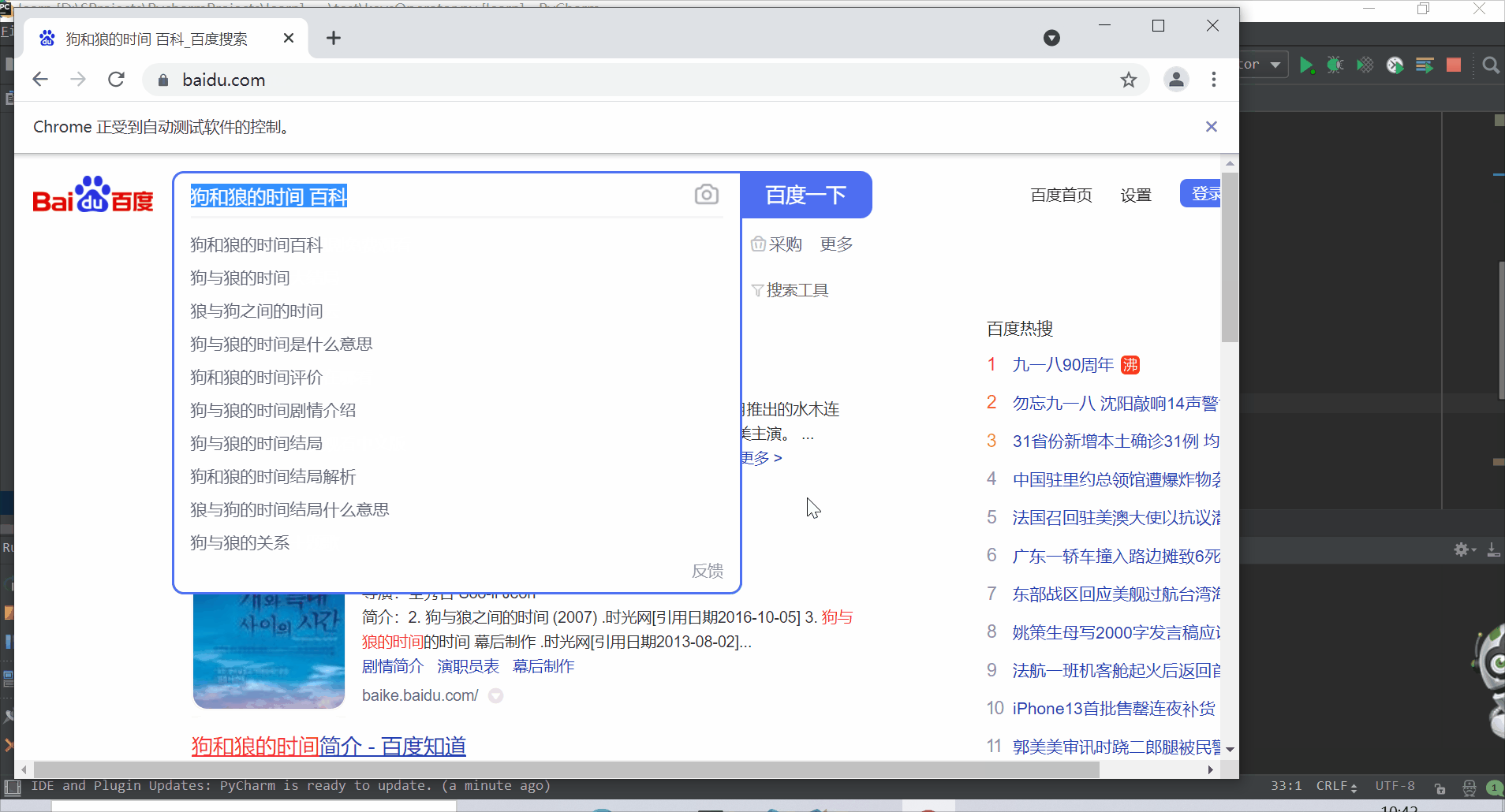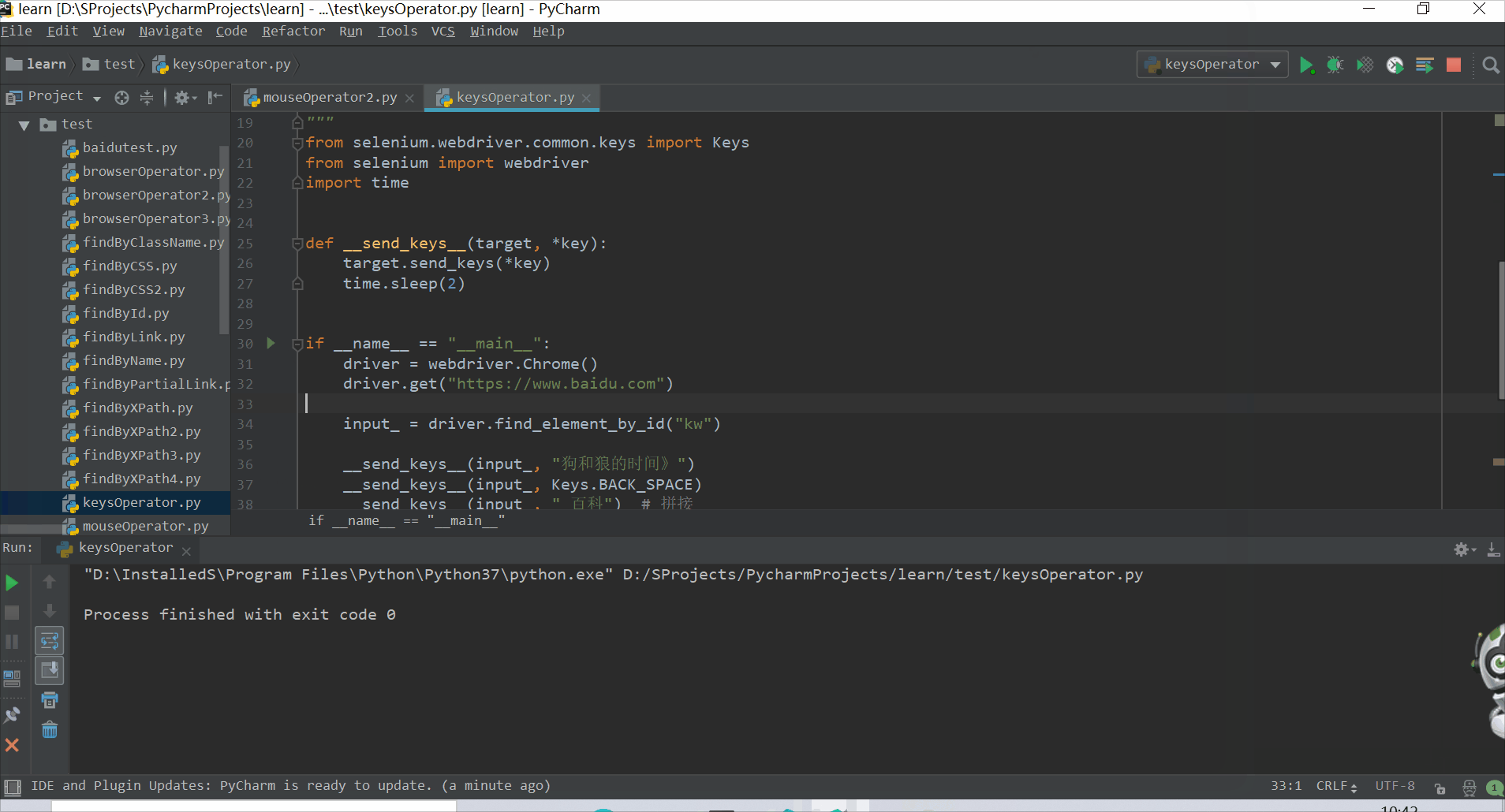
1.在百度文本框中输入 “狗和狼的时间》”
2.删除最后的 “》”
3.再次在文本框中输入 “ (空格)百科”
4.ctrl + a,全选文本框内容
5.ctrl + x,剪切选择的内容
6.ctrl + v,粘贴复制的内容
7.回车,完成搜索
8.退出浏览器
#!/usr/bin/env python
# -*- coding:utf8 -*-
# python3.7
# @Time : 2021/09/18 10:22
# @Author : hyh
# @Version : 1.0
# @Desc : TODO
"""
键盘操作
1.在百度文本框中输入 “狗和狼的时间》”
2.删除最后的 “》”
3.再次在文本框中输入 “ (空格)百科”
4.ctrl + a,全选文本框内容
5.ctrl + x,剪切选择的内容
6.ctrl + v,粘贴复制的内容
7.回车,完成搜索
8.退出浏览器
"""
from selenium.webdriver.common.keys import Keys
from selenium import webdriver
import time
def __send_keys__(target, *key):
target.send_keys(*key)
time.sleep(2)
if __name__ == "__main__":
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
input_ = driver.find_element_by_id("kw")
__send_keys__(input_, "狗和狼的时间》")
__send_keys__(input_, Keys.BACK_SPACE)
__send_keys__(input_, " 百科") # 拼接
__send_keys__(input_, Keys.CONTROL, "a")
__send_keys__(input_, Keys.CONTROL, "x")
__send_keys__(input_, Keys.CONTROL, "v")
__send_keys__(input_, Keys.ENTER)
time.sleep(3)
driver.quit()
注意:其实延时效果非常重要,如果有些操作没有加延时,那么很容易就会出错。
2.8.6 警告窗口处理
模式窗口:只能对这个窗口进行操作,如果这个窗口不关闭,页面其他的操作一概进行不了。
非模式窗口:不用关闭窗口,也可以在页面上进行其他的操作。
在webdriver中处理js所生成的alert/confirm/prompt,我们需要使用switch_to.alert,定位到alert/confirm/prompt,然后使用:
text返回(获取)alert/confim/prompt中文字信息accept()接受现有警告框,点击“确定”按钮dismiss()放弃现有警告框,点击“取消”按钮send_keys(keysToSend)发送文本至警告框
eg:
我们如何操作警告框呢?
首先,我们要知道,driver这个对象是在当前页面窗口内的,不在alert上,并且我们没有办法去定位窗口上的元素,这时候我们就可以使用driver.switch_to.alert暂时将浏览器对象交给alert使用。
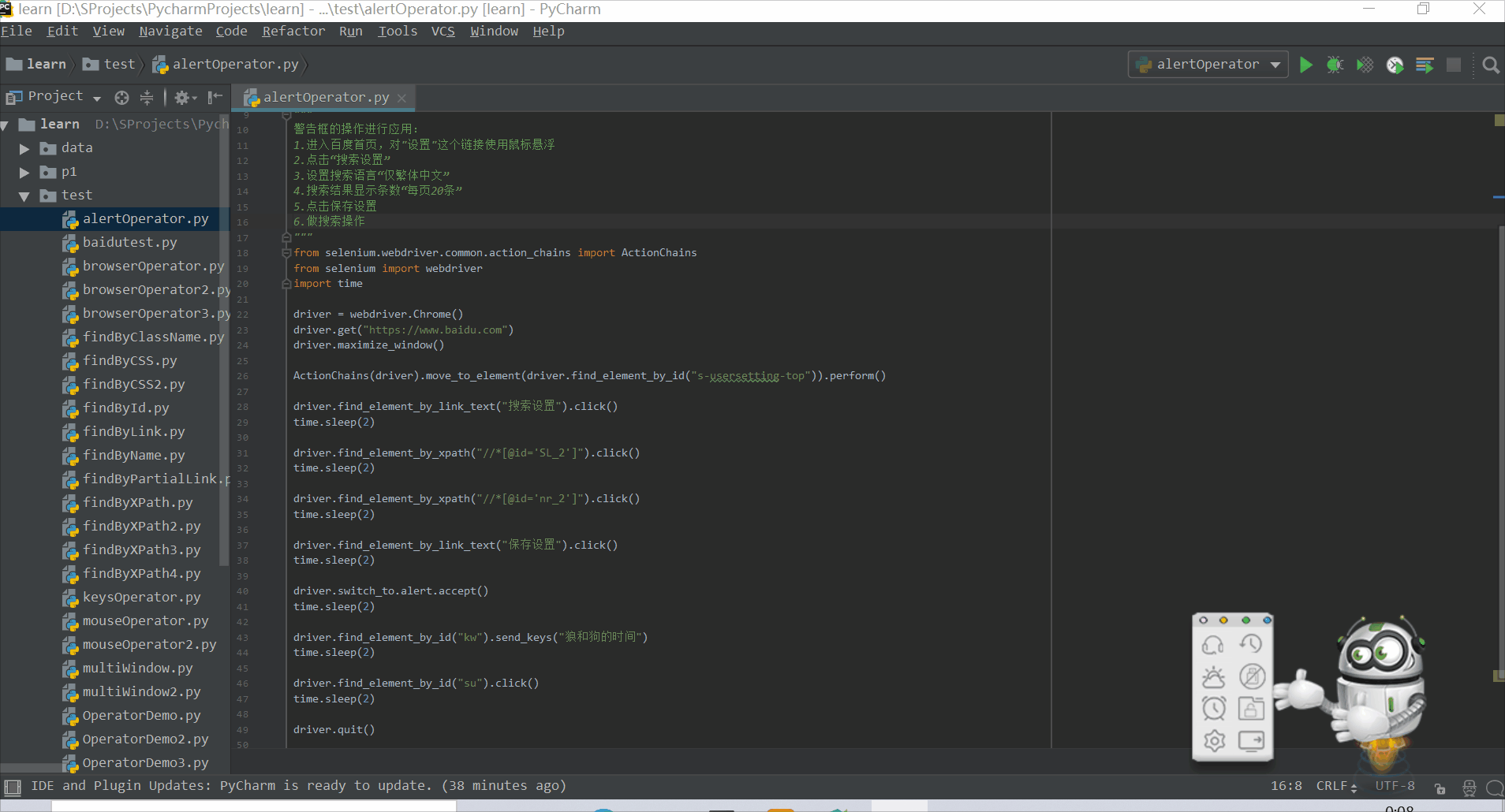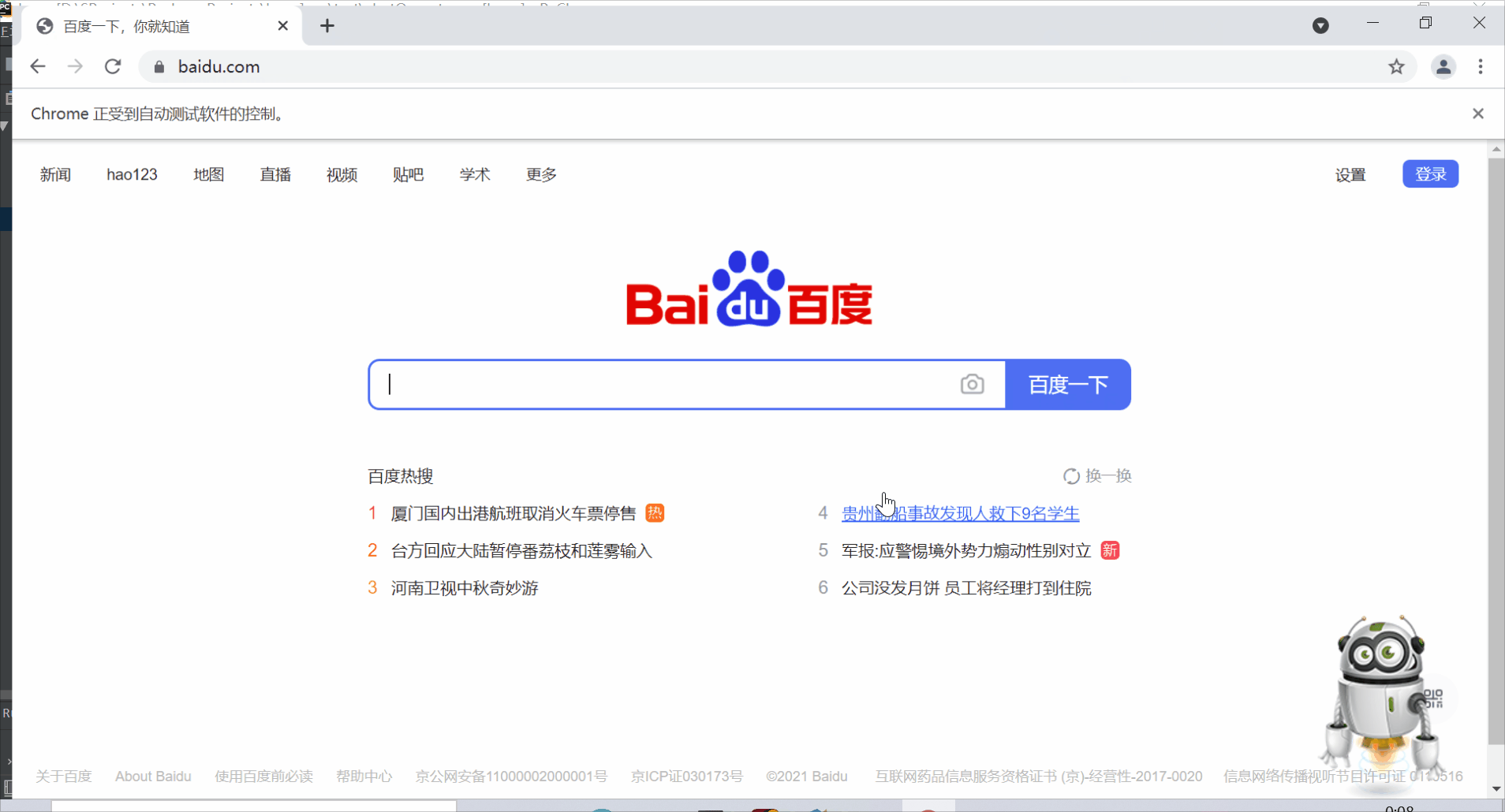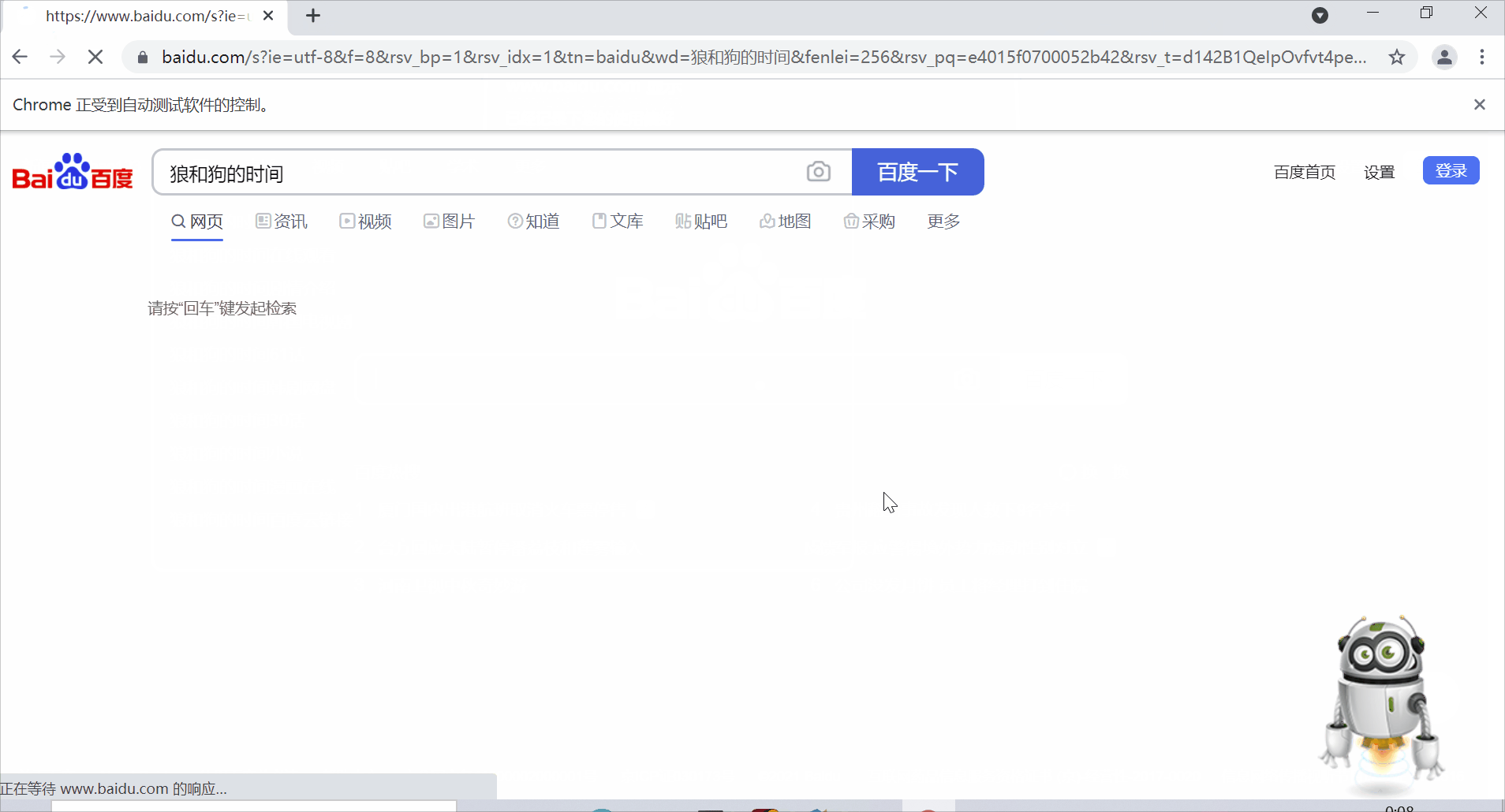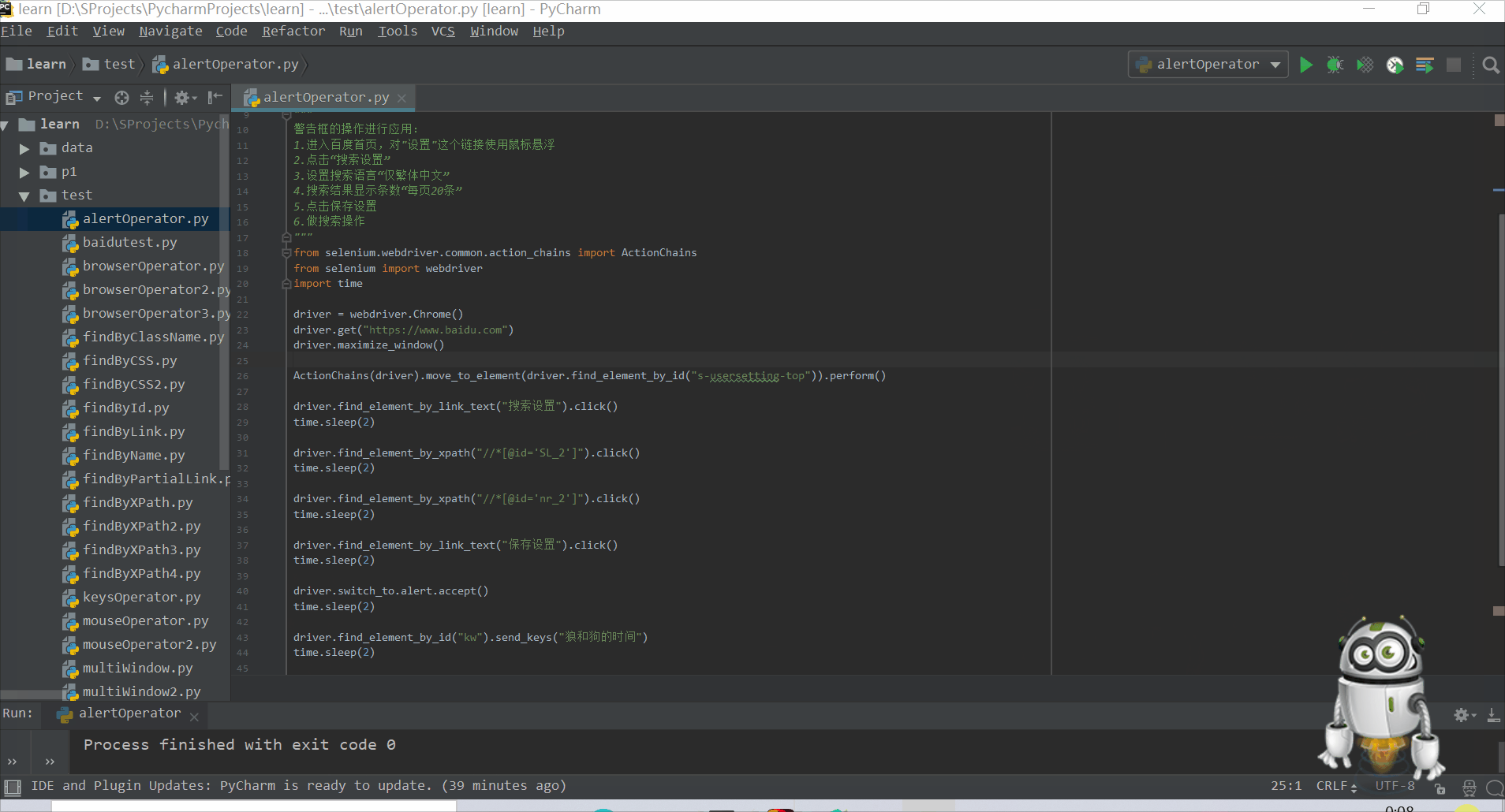
下面就对警告框的操作进行应用:
1.进入百度首页,对"设置"这个链接使用鼠标悬浮
2.点击“搜索设置”
3.设置搜索语言“仅繁体中文”
4.搜索结果显示条数“每页20条”
5.点击保存设置
6.做搜索操作
#!/usr/bin/env python
# -*- coding:utf8 -*-
# python3.7
# @Time : 2021/09/19 23:48
# @Author : hyh
# @Version : 1.0
# @Desc : TODO
"""
警告框的操作进行应用:
1.进入百度首页,对"设置"这个链接使用鼠标悬浮
2.点击“搜索设置”
3.设置搜索语言“仅繁体中文”
4.搜索结果显示条数“每页20条”
5.点击保存设置
6.做搜索操作
"""
from selenium.webdriver.common.action_chains import ActionChains
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.maximize_window()
ActionChains(driver).move_to_element(driver.find_element_by_id("s-usersetting-top")).perform()
driver.find_element_by_link_text("搜索设置").click()
time.sleep(2)
driver.find_element_by_xpath("//*[@id='SL_2']").click()
time.sleep(2)
driver.find_element_by_xpath("//*[@id='nr_2']").click()
time.sleep(2)
driver.find_element_by_link_text("保存设置").click()
time.sleep(2)
driver.switch_to.alert.accept()
time.sleep(2)
driver.find_element_by_id("kw").send_keys("狼和狗的时间")
time.sleep(2)
driver.find_element_by_id("su").click()
time.sleep(2)
driver.quit()















 2343
2343











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









