







 这篇博客详细介绍了2021年8月13日进行的Hadoop完全分布式安装过程,包括HDFS组件、YARN组件的组成,MapReduce架构以及HDFS操作命令。在安装过程中,重点讲述了如何实现三台Centos7虚拟机之间的免密登录,配置JDK,安装并配置Hadoop,解决启动过程中的报错问题,最终成功启动所有服务。
这篇博客详细介绍了2021年8月13日进行的Hadoop完全分布式安装过程,包括HDFS组件、YARN组件的组成,MapReduce架构以及HDFS操作命令。在安装过程中,重点讲述了如何实现三台Centos7虚拟机之间的免密登录,配置JDK,安装并配置Hadoop,解决启动过程中的报错问题,最终成功启动所有服务。
前言
- 时间:2021.8.13
- 内容:
- HDFS 组件的组成
- YARN 组件的组成
- MapReduce 架构
- HDFS 操作命令
- 完全分布式安装
1 HDFS组件的组成

[hyidol@centos7 hadoop-3.3.1]$ sbin/start-dfs.sh
Starting namenodes on [centos7]
Starting datanodes
Starting secondary namenodes [centos7]
[hyidol@centos7 hadoop-3.3.1]$ jps
1442 NameNode
1554 DataNode
1892 Jps
1740 SecondaryNameNode
- 架构:主从架构,主的去管理从的。
- NameNode 和 DataNode 是一对多关系。
- 1 NameNode-》1000 DataNode
- 进程:
- NameNode: 存储元信息(文件的描述信息)。文件大小,创建时间,创建人,最后修改时间,都是文件的描述信息。
- SecondaryNameNode:复制和备份 NameNode 的数据。
- DataNode: 存储数据信息(文件)。
- 文件块:
- dfs.replication = 1 (文件块默认128MB)
2 YARN组件的组成

- 架构:主从架构。
- 进程:
- ResourceManager:是主节点,管理其他的所有 NodeManagers
- NodeManagers:是从节点,管理本地资源。容器,任务管理…
- 其他(这个不太明白)
- ApplicationMaster:针对MR每个请求job的抽象封装。
- Container:将来运行在YARN上的每一个任务都会给其分配资源,Container就是当前任务所需资源的抽象封装。
- 容器:Docker,启动一个进程/线程,就是操作系统
3 MapReduce架构

- Map阶段:就是把需要计算的数据安装需求分成多个MapTask任务来执行。(分)
- Reduce极端:把Map阶段处理完的结果拷贝过来,根据需求进行汇总计算。(合)
4 HDFS 操作命令

-
语法: hdfs 子命令 -命令 参数
-
操作:$HADOOP_HOME/…
- bin/hdfs dfs

-
上传一个文件到 HDFS 的根目录下的 input 目录。
bin/hdfs dfs –mkdir /input //在 hdfs 中创建一个目录 input

```
bin/hdfs dfs –put /home/hadoop/user /input/ //user 文件上传到 hdfs 的/input/
```

-
查看目录下的子目录,及子目录下的文件,递归查看。
in/hdfs dfs –ls –R /

-
查看文件内容。
bin/hdfs dfs –cat /input/user -
查看 HDFS 文件系统的根目录下有多少个文件或目录。
bin/hdfs dfs -ls / -
基于 YARN 的 MapReduce 计算:

- 运行结束,查看 HDFS 目录结构:
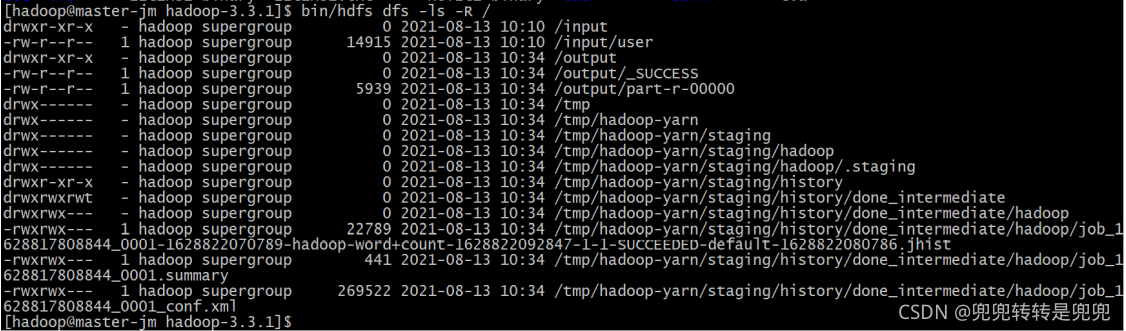
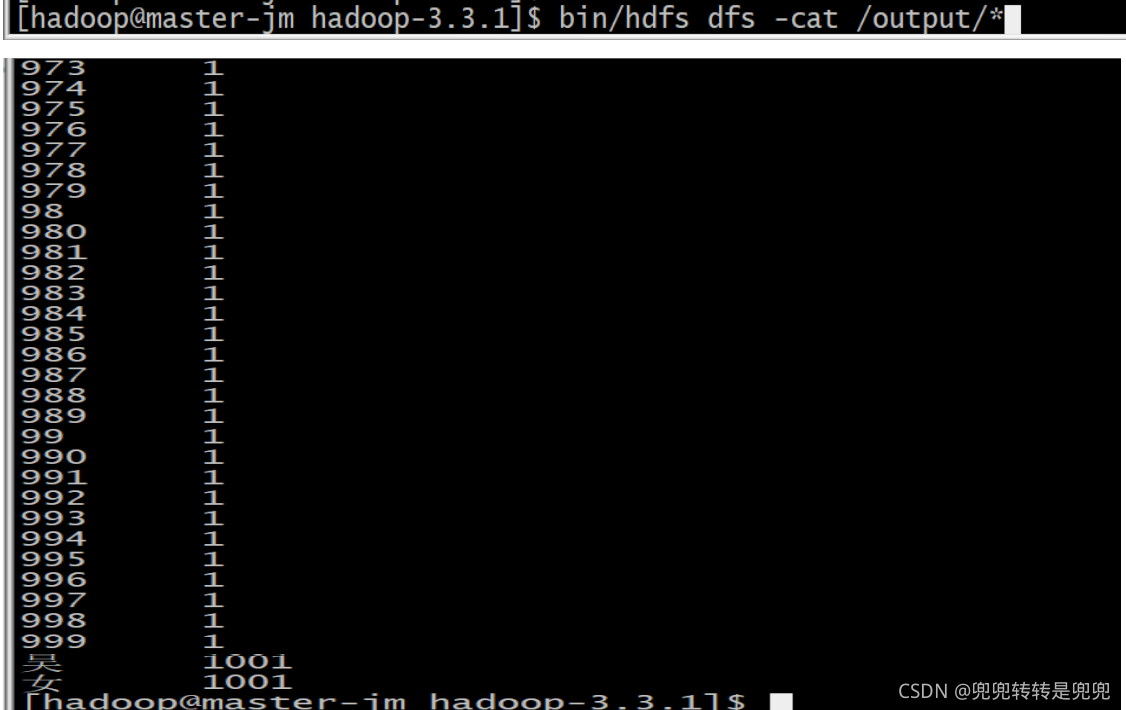
- 查看运行结果目录的内容:
5 ⭐完全分布式安装
5-1 免密互通+JDK
| ip | 主机名 | 用户名 | 软件 |
|---|---|---|---|
| 192.168.137.110 | master-yh | hyidol | JDK |
| 192.168.137.111 | slave1-yh | hyidol | JDK |
| 192.168.137.112 | slave2-yh | hyidol | JDK |
-
虚拟机创建三个 Centos7 系统的虚拟机。
-
更改/etc/sysconfig/network-scripts/ifcfg-enp0s3文件,重启网络,连通可ping上外网。
BOOTPROTO=static #dchp好像也行 ONBOOT=yes #开机自启 IPADDR=192.168.137.110 #主机地址 NETMASK=255.255.255.0 #子网掩码 GATEWAY=192.168.137.1 #网关 DNS1=192.168.43.1 #外机网络地址 [hyidol@master-yh ~]$ service network restart #重启网络 -
实现三台机子之间可以直接进行免密登录。(一定要是普通用户下进行)
[hyidol@master-yh ~]$ ssh-keygen -t rsa [hyidol@master-yh ~]$ ssh-copy-id -i 主机名 [hyidol@master-yh ~]$ ssh 主机名 //测试用 -
配置好 IP 地址映射,在/etc/hosts 文件中添加 ip 地址和主机名。(需要切换到root操作,远程传输时更方便,不用一个个赋权限)
192.168.137.110 master-yh 192.168.137.111 slave1-yh 192.168.137.112 slave2-yh [root@master-yh ~]$ scp /etc/hosts root@slave1-yh:/etc/ -
配置好 JDK,远程传输。
[hyidol@master-yh ~]$ tar –zxvf jdk-8vcccc.tar.gz [hyidol@master-yh ~]$ mv jdk1.8.0_301 jdk-1.8.0 [hyidol@master-yh ~]$ sudo mv jdk-1.8.0/ /usr/java/ [hyidol@master-yh ~]$ vi .bashrc export JAVA_HOME=/usr/java/jdk-1.8.0 export PATH=$PATH:$JAVA_HOME/bin [hyidol@master-yh ~]$ source .bashrc [hyidol@master-yh ~]$ java [hyidol@master-yh ~]$ javac -
关闭防火墙,禁用防火墙。
[hyidol@master-yh ~]$ su
[hyidol@master-yh ~]$ service firewalld stop
[hyidol@master-yh ~]$ systemctl disable firewalld
-
备注:如果因前面不是在root下进行的造成一些权限障碍,增加权限也是可以的。【以下为详细传输流程】
-
---------下方是master-jm 主机操作---------
-
创建/usr/java/目录。
-
赋予权限: chmod –R 777 java/
-
解压 jdk 移动 java 目录下。
-
配置环境变量.bashrc。
-
通过 master-jm 主机 ssh 登录到其他三台主机,进行如下操作:
-
---------下方是其他机子的操作----------
-
创建/usr/java/目录 (如果是sudo 就可以忽略后面赋权限)
-
赋予权限:chmod –R 777 java(以slave1为例)
[hyidol@master-yh java]$ ssh slave1-yh [hyidol@slave1-yh ~]$ sudo mkdir /usr/java [hyidol@slave1-yh ~]$ exit -
---------下方是主机远程传输给其他机子------
-
master-jm 主机。把 jdk-1.8.0 目录,远程传送到其他三台主机:(以slave1为例)
[hyidol@master-yh ~]$ cd /usr/java [hyidol@master-yh java]$ scp jdk-1.8.0/ @slave1-yh:/usr/java/ jdk-1.8.0: not a regular file [hyidol@master-yh java]$ scp -r jdk-1.8.0/ @slave1-yh:/usr/java/ scp: /usr/java//jdk-1.8.0: Permission denied [hyidol@master-yh java]$ sudo scp -r jdk-1.8.0/ @slave2-yh:/usr/java/ -
环境变量配置好之后,传送到其他三台主机:
[hyidol@master-yh ~]$ cd [hyidol@master-yh ~]$ scp .bashrc hyidol@slave1-yh:~/ [hyidol@master-yh ~]$ scp .bashrc hyidol@slave2-yh:~/
-
5-2 安装hadoop
-
上传、解压,删掉暂时无用的share/doc文件。
-
配置环境变量。注意改完要:source .bashrc
export HADOOP_HOME=/usr/java/hadoop-3.3.1 export HADOOP_MAPRED_HOME=/usr/java/hadoop-3.3.1 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin -
其他配置:位置$HADOOP_HOME/etc/hadoop/
hadoop-3.2.0/etc/hadoop/core-site.xml hadoop-3.2.0/etc/hadoop/hdfs-site.xml hadoop-3.2.0/etc/hadoop/mapred-site.xml hadoop-3.2.0/etc/hadoop/yarn-site.xml参考:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/ClusterSetup.html
-
core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master-yh:9000</value> </property> </configuration> -
hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/opt/hdfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/opt/hdfs/data</value> </property> </configuration> -
mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.application.classpath</name> <value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value> </property> </configuration> -
yarn-site.xml
<configuration> <!-- Reducer获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME</value> </property> <!-- 指定启动YARN的ResourceManager的主机地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>master-yh</value> </property> </configuration>
-
-
需要的目录/opt/hdfs/name 和/opt/hdfs/data 两个目录需要手动创建,并赋予权限。 配置 HDFS 需要 name 目录和 data 目录。
[hyidol@master-yh hadoop]$ cd /opt/ [hyidol@master-yh opt]$ sudo mkdir hdfs [sudo] hyidol 的密码: [hyidol@master-yh opt]$ ll 总用量 0 drwxr-xr-x. 2 root root 6 9月 29 07:43 hdfs [hyidol@master-yh opt]$ su 密码: [root@master-yh opt]# chmod -R 777 hdfs/ [root@master-yh opt]# exit exit [hyidol@master-yh opt]$ cd hdfs [hyidol@master-yh hdfs]$ mkdir name [hyidol@master-yh hdfs]$ mkdir data [hyidol@master-yh hdfs]$ ll 总用量 0 drwxrwxr-x. 2 hyidol hyidol 6 9月 29 07:45 data drwxrwxr-x. 2 hyidol hyidol 6 9月 29 07:45 name每一台主机,都需要操作!!比如slave1-yh:
[hyidol@master-yh hdfs]$ ssh slave1-yh Last login: Wed Sep 29 04:04:39 2021 from master-yh [hyidol@slave1-yh ~]$ cd /opt/ [hyidol@slave1-yh opt]$ sudo mkdir hdfs [sudo] hyidol 的密码: [hyidol@slave1-yh opt]$ su 密码: [root@slave1-yh opt]# chmod -R 777 hdfs/ [root@slave1-yh opt]# exit exit [hyidol@slave1-yh opt]$ cd hdfs [hyidol@slave1-yh hdfs]$ mkdir name [hyidol@slave1-yh hdfs]$ mkdir data汇总下:
cd /opt/ sudo mkdir hdfs (密码是hyidol) su (密码是root) chmod -R 777 hdfs/ exit cd hdfs mkdir name mkdir data -
配置worker。注意worker 是设置DataNode节点的,所以不用把master加上。
[hyidol@master-yh hadoop]$ vi /usr/java/hadoop-3.3.1/etc/hadoop/workers slave1-yh slave2-yh -
把 hadoop-3.3.1 目录传送到其他三台主机。
[hyidol@master-yh java]$ scp -r /usr/java/hadoop-3.3.1/ hyidol@slave1-yh:/usr/java/-
(已解决)出现如下权限问题的时候,有可能不是说源文件的权限不够,而是需要复制的位置没有权限,不能写入文件:
[root@master-yh java]# scp -r hadoop-3.3.1/ hyidol@slave1-yh:/usr/java/ scp: /usr/java//hadoop-3.3.1: Permission denied [hyidol@master-yh java]$ ssh slave1-yh [hyidol@slave1-yh usr]$ su [root@slave1-yh usr]# chmod -R 777 java [root@slave1-yh usr]# exit
-
-
环境变量配置也要传送。
[hyidol@master-yh java]$ cd [hyidol@master-yh ~]$ scp .bashrc hyidol@slave1-yh:~/ [hyidol@master-yh ~]$ scp .bashrc hyidol@slave2-yh:~/ -
格式 HDFS。
[hyidol@master-yh ~]$ cd /usr/java/hadoop-3.3.1/ [hyidol@master-yh hadoop-3.3.1]$ bin/hdfs namenode -format-
去这个目录下看看是否有东西,有东西就成功了。
[hyidol@master-yh /]$ cd /opt/hdfs/name/current/ [hyidol@master-yh current]$ ls fsimage_0000000000000000000 fsimage_0000000000000000000.md5 seen_txid VERSION
-
-
启动 hadoop 所有服务。这里的没日志警告不用管,再启动就会发现它自己给创建了,没创的话给个权限就行。
[hyidol@master-yh ~]$ start-all.sh WARNING: Attempting to start all Apache Hadoop daemons as hyidol in 10 seconds. WARNING: This is not a recommended production deployment configuration. WARNING: Use CTRL-C to abort. Starting namenodes on [master-yh] Starting datanodes slave1-yh: WARNING: /usr/java/hadoop-3.3.1/logs does not exist. Creating. slave2-yh: WARNING: /usr/java/hadoop-3.3.1/logs does not exist. Creating. Starting secondary namenodes [master-yh] Starting resourcemanager Starting nodemanagers-
master
[hyidol@master-yh hadoop-3.3.1]$ jps 15249 SecondaryNameNode 15060 NameNode 15492 ResourceManager 15789 Jps -
slave1
[hyidol@slave1-yh hadoop-3.3.1]$ jps 18497 DataNode 18594 NodeManager 18710 Jps -
slave2
[hyidol@slave2-yh hadoop-3.3.1]$ jps 3015 DataNode 3112 NodeManager 3228 Jps
-
5-3 报错
-
一开始jps跑出来的节点都正常(master4个slave3个),9870网页也能显示这些节点,但是8088页面就显示不出来哎(那个active node总是0个)
-
小伙伴说是我集群搭的不规范,按这个搭更好,写个脚本更方便。但是我翻了记录,之前这种搭建方法也是能成功的呀(困惑,先学会一种嘛~

-
然后找到一个类似的博客:hadoop启动 datanode的live node为0 这里说看下datanode的日志,确实跟那个端口有关系的亚子,然后我就跟着做了一遍增加8031和9000和端口权限的事儿。想不到我这憨批远程连接忘退出了,在slave里各种start-all,结果当然…乱七八糟的。
-
后来小伙伴说:“dd会上报dn节点状态是否活着 那个页面都没显示到dd active说明上报有问题 查下dd日志针对具体问题解决下 可能是配置问题dd没起来。”虽然每太明白这句话,但是仿佛找到了个切入点,之前看日志都不知道从哪里去看问题,这回也倒好,一开就看到问题了。(一直都是报同个问题,只是我的潜意识刻意去回避了,假装它是对的)
Retrying connect to server: 0.0.0.0/0.0.0.0:8031. Already tried 0 time(s); -
百度之后一堆答案,加上老师此时跟我说:“差一个resourcemanager.hostname的配置。”我突然就悟了,去看了下site文件,噢是没写…加上还是错,才发现自己笔记漏了一小段…是由于yarn-site.xml没写完导致的…
-
这里附个前辈的笔记,超级详细,我看的时候感觉自己又懂了一些以前模棱两可的东西呢~
-
如果是节点跑的不对,可以去日志里排查。比如报了错误:
- $HADOOP_HOME/logs/ DataNode 没有启动:查看 hadoop-hadoop-datanode-slave1-jm.log
- NodeManager 没有启动:查看 hadoop-hadoop-nodemanager-slave1-jm.log
- NameNode 没有启动:查看 hadoop-hadoop-namenode-master-jm.log
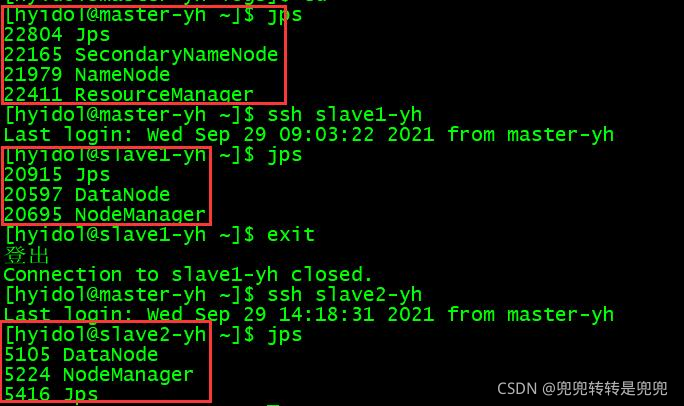
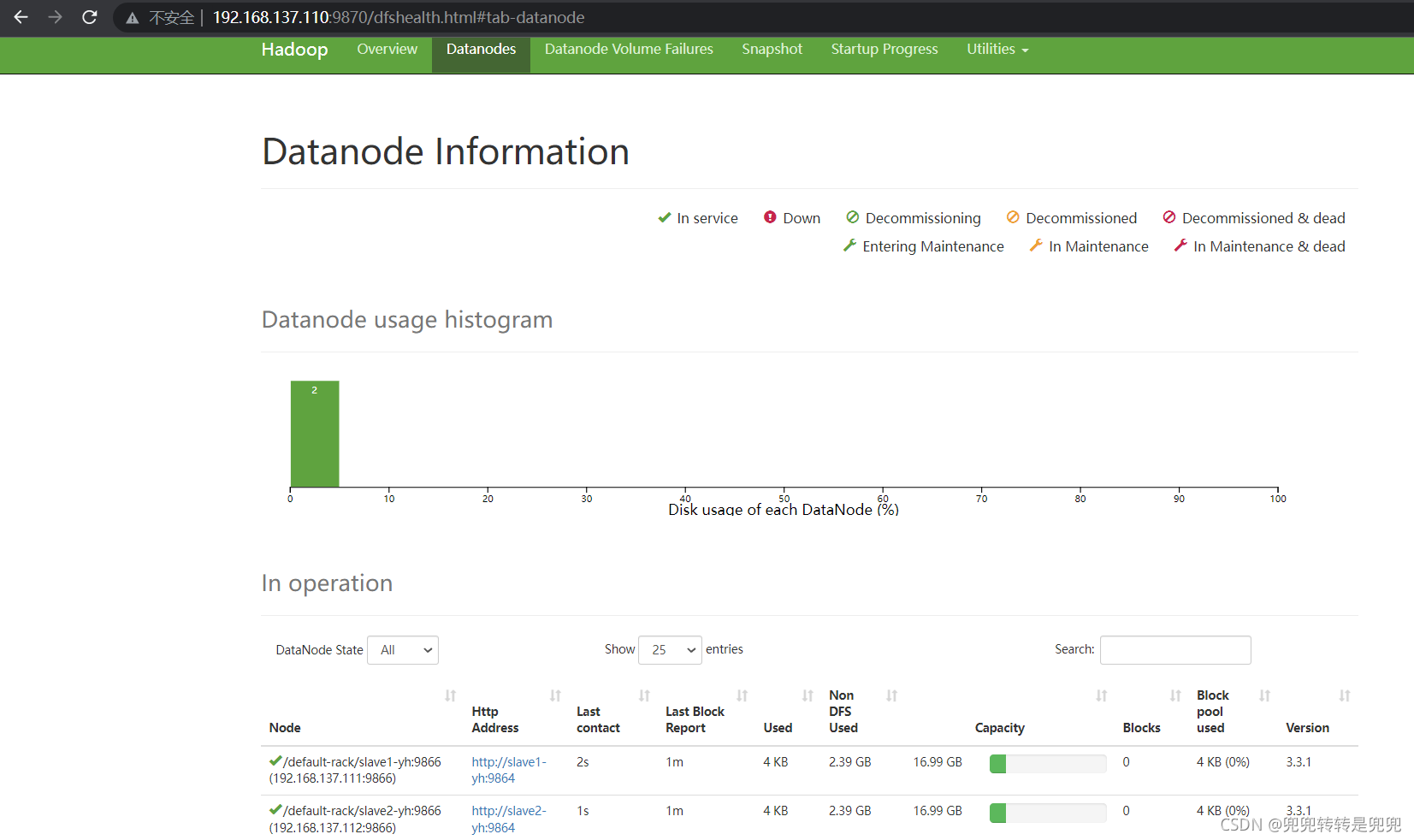
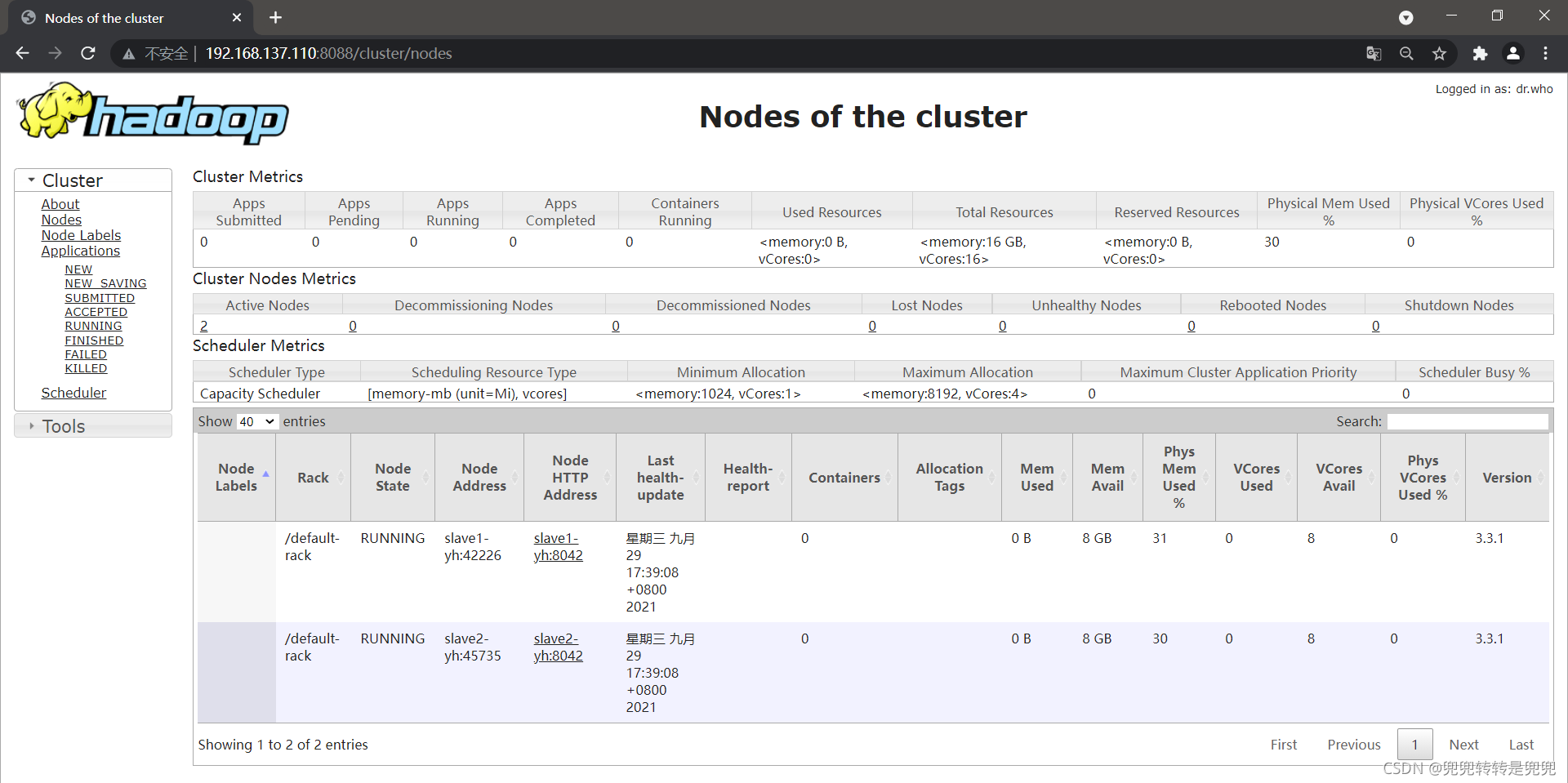
5-4 成功


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









