









一、Storm集群架构


- Nimbus和Supervisors之间所有的协调工作是通过Zookeeper集群。
- Nimbus进程和Supervisor进程是无法直接连接或无状态的;所有的状态维持在Zookeeper中或保存在本地磁盘上这就意味着我们kill -9 Nimbus或Supervisors进程,而不需要做备份。这种设计使Storm集群具有更好的稳定性,即无耦合性。
二、Storm的工作原理
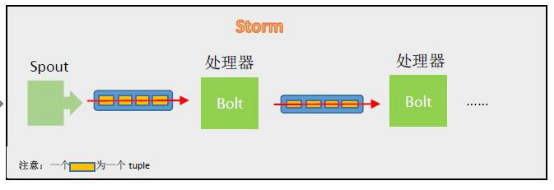
- 在Storm中有对于流stream的抽象,流是一个不间断的无界的连续tuple。
- Storm在建模事件流时,把流中的事件抽象为tuple,即元组。
- Storm认为每个stream都有一个源,也就是原始元组的源头,叫做Spout(管口)。
- 处理Stream内的tuple,抽象为Bolt;bolt可以消费任意数量的输入流,只要将流方向导向该bolt,同时它也可以发送新的流给其他bolt使用,这样一来,只要打开特定的Spout,再将Spout中流出的tuple导向特定bolt,然后bolt对导入的流做处理后再导向其他的bolt或者目的地。
- 简单理解:可以认为Spout就是水龙头,并且每个水龙头里流出的水是不同的,我们想拿到哪种水就拧开哪个水龙头,然后使用管道将水龙头的水导向到一个水处理器(bolt),水处理器处理后再使用管道导向另一个处理器或者存入容器。
- 为了增大水处理效率,我们很自然就想到在同个水源处接上多个水龙头并使用多个水处理器,这样可以提高效率。
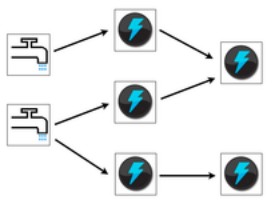
上图是一张有向无环图,Storm将这个图抽象为Topology(拓扑),topology就是Storm的Job抽象概念,一个拓扑就是一个流转换图。
三、Spout类和Bolt类的介绍
1、Spout
- spout是storm中数据流的源头,因此担当的角色是数据的发送者。
- IRichSpout接口有以下重要的方法:
open:提供Spout以及spout的执行环境。executors会运行这个方法来初始化spout。
public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector){}
nextTuple:通过收集器发送产生的数据。
public void nextTuple() {}
Close:关闭Spout时调用close方法。
declareOutputFields:声明输出元组的schema。
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("bytes"));
}
2、bolt
- bolt是一个元组作为输入。处理元组后产生新的元组作为输出的组件。
- IrichBolt接口有如下方法:
Prepare:准备提供bolt以及bolt的执行环境。
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector){}
Execute:处理输入的单个tuple。
public void execute(Tuple tuple) {}
Cleanup:要关闭bolt时被调用。
DeclareOutputFields:声明输出元组的schema.
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("myresult"));
}
四、Storm的安装及遇到的问题
前提:先安装zookeeper集群;
- 将压缩包复制到/opt/softWare/storm文件夹下:
- 解压安装包:tar –zxvf apache-storm-1.1.1.tar.gz
![]()
- vim /opt/softWare/storm/apache-storm-1.1.1/conf/storm.yaml

(1)‘ :’之后要加空格
(2)要修改默认的8080端口,直接在storm.yaml中加ui.port: 8089(注意 :后面的空格,只在nimbus中修改这个端口)
(3)开头也要加空格
4、启动numbus: nohup ./storm nimbus &
5、启动supervisor: nohup ./storm supervisor &
6、启动ui: nohup ./storm ui &
五、Storm小事例之WordCount
总体流程:





六、Storm的并发机制
1、集群中运行的topology的四个主要组成部分
Nodes(服务器):一个Storm集群可以包括一个或者多个工作node;
Workers(JVM虚拟机):指一个node上相互独立运行的JVM进程。每个node可以配置运行一个或者多个worker。一个topology会分配到一个或者多个worker上运行。
Executeor(线程):指一个worker的JVM进程中运行的java线程。多个task可以指派给同一个executer来执行。除非是明确指定。Storm默认会给每个executer分配一个task。
Task(bolt/spout实例):task是spout和bolt的实例。它们的nextTuple()和execute()方法会被executors线程调用执行。
2、给topology增加worker
Config config = new Config();
config.setNumWorkers(2); //可以增加topology的计算资源。
3、配置executor和task
(1)builder.setSpout(“wcSpout”,new WordCountSpout(),2);
设置WordCountSpout并发为两个task,每个task指派各自的executor线程。
(2)builder.setBolt(“splitBolt”,new SplitBolt(),2).setNumTask(4)
.shufferGrouping(“wcSpout”);
设置4个task和两个executor。每个executor线程指派2个task来执行(4/2=2)
(3)builder.setBolt(“countBolt” , new CountBolt(),4)
.fieldsGrouping(“splitBolt”,new Fields(“word”));
运行4个task,每个task由一个executor线程执行。
注意:当topology执行在本地模式时,增加worker的数量不会达到提高速度的效果。因为topology在本地模式下是在同一个JVM进程中执行的,所以只有增加task和executor的并发配置才会有效。
4、最终示意图

七、数据流分组
Storm定义了七种内置数据流分组的方式:
1、Shuffle grouping(随机分组)
这种方式会随机分发tuple给bolt的各个task,每个bolt实例接收到相同数量的tuple。
2、Fields grouping(按字段分组)
根据指定字段的值进行分组。比如说,一个数据流根据“word”字段进行分组,所有具有相同“word”字段值的tuple会路由到同一个bolt的task中。
3、All grouping(全复制分组)
将所有的tuple复制后分发给所有bolt task.每个订阅数据流的task都会接收到tuple的拷贝。
4、Globle grouping(全局分组)
这种分组方式将所有的tuples路由到唯一一个task上。Storm按照最小的task ID来选取接受数据的task。注意当使用全局分组时,设置bolt的task并发度时没有意义的,因为所有的task都会转发到同一个task。因为所有的tuple都会转发到一个JVM实例上,可能会引起Storm集群中某个JVM或者服务器出现性能瓶颈或者崩溃。
5、None grouping(不分组)
在功能上和随机分组相同,是为将来预留的。
6、Direct grouping(指向型分组)
数据源会调用emitDirect()方法来判断一个tuple应该由哪个Storm组件来接收。只能在声明了是指向型的数据流上使用。
7、Local or shuffle grouping(本地或随机分组)
和随机分组类似,但是,会将tuple分发给同一个worker内的bolt task(如果worker内有接收数据的bolt task)。其他情况下,采用随机分组的方式。取决于topology的并发度,本地或随机分组可以减少网络传输,从而提高topology性能。
八、Storm的进程和组件总结
1、storm的进程
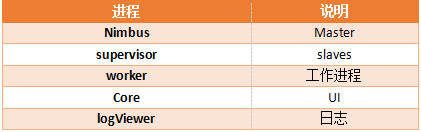
2、storm的组件

















 238
238











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











