









描述
在一个排序的链表中,存在重复的结点,请删除该链表中重复的结点,重复的结点不保留,返回链表头指针。 例如,链表 1->2->3->3->4->4->5 处理后为 1->2->5

例如输入{1,2,3,3,4,4,5}时,对应的输出为{1,2,5},对应的输入输出链表如下图所示:
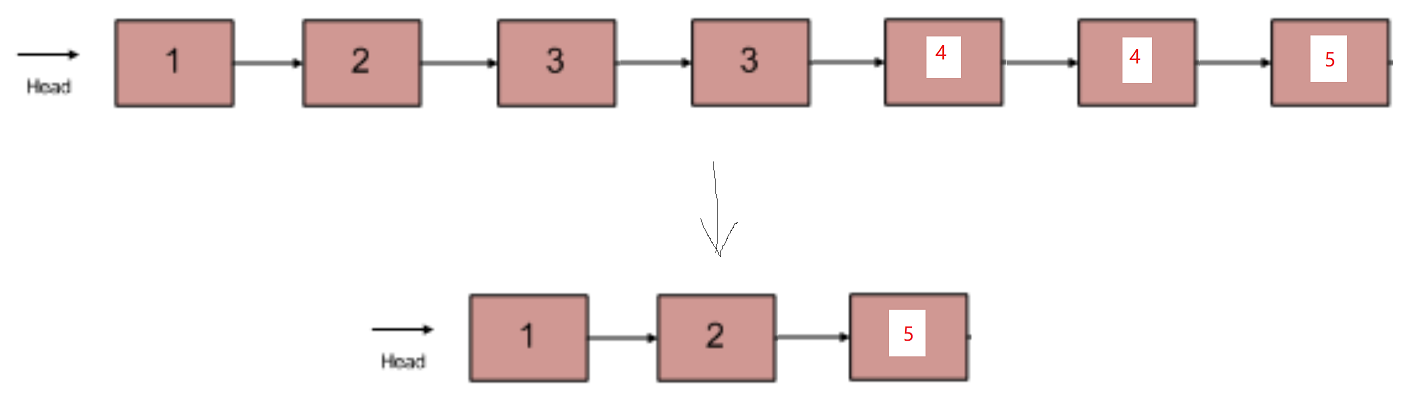
示例1
输入:
{1,2,3,3,4,4,5}
复制返回值:
{1,2,5}
复制
示例2
输入:
{1,1,1,8}
复制返回值:
{8}
我的做法,Hash (没注意到一定是个升序链表 此法因而也适合乱序链表了)
public ListNode deleteDuplication(ListNode pHead) {
int[] Hash= new int[1010];//也默认是0 不错
ListNode ans=new ListNode(-1);
ans.next=pHead;//加个头结点
while (pHead!=null) {
Hash[pHead.val]++;//统计每个节点出现此处
pHead=pHead.next;
}
//出现次数大于1的都删除
pHead=ans;//注意ans是带头结点的链表
while (pHead.next!=null){
if(Hash[pHead.next.val]>1) pHead.next=pHead.next.next;
else pHead=pHead.next;
}
return ans.next;
}空间O(1) (用到了链表升序的性质)
public class Solution {
public ListNode deleteDuplication(ListNode pHead) {
//空链表
if(pHead == null)
return null;
ListNode res = new ListNode(0);
//在链表前加一个表头
res.next = pHead;
ListNode cur = res;
while(cur.next != null && cur.next.next != null){
//遇到相邻两个节点值相同
if(cur.next.val == cur.next.next.val){
int temp = cur.next.val;
//将所有相同的都跳过
while (cur.next != null && cur.next.val == temp)
cur.next = cur.next.next;
}
else
cur = cur.next;
}
//返回时去掉表头
return res.next;
}
}














 5335
5335











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









