







实际postings list 存储在最小分片单位下的分段segment内存中。
segment每隔一段时间合并同步磁盘
1.性能优化的杀手锏——filesystem cache (即 os cache,操作系统的缓存)
一般给es系统内存的50% 剩下的50% lucene会自动调用操作系统文件内存filesystem cache
es的搜索引擎严重依赖于底层的filesystem cache,
你如果给filesystem cache更多的内存,尽量让内存可以容纳所有的indx segment file索引数据文件,那么你搜索的时候就基本都是走内存的,性能会非常高。
比如说,你一共要在es中存储1T的数据,那么你的多台机器留个filesystem cache的内存加起来综合,至少要到512G,
至少半数的情况下,搜索是走内存的,性能一般可以到几秒钟,2秒,3秒,5秒
如果最佳的情况下,filesystem cache 的大小 大于 ES所需要搜索的数据大小。
一般情况下ES中只写入需要索引的那几个字段,不要把整条记录都写到 ES中。
比如说,ES就写入 id name age三个字段就可以了,然后你可以把其他的字段数据存在hbase或mysql中。
从es中根据name和age去搜索,拿到的结果可能就20个doc id,然后根据doc id到hbase里去查询每个doc id对应的完整的数据,给查出来,再返回给前端。
你往 es 里写的数据,实际上都写到磁盘文件里去了,查询的时候,操作系统会将磁盘文件里的数据自动缓存到 filesystem cache 里面去。
为什么说是一般情况下,因为这种方式是最节省内存和最最利用filesystem cache的。但是缺点显而易见,那就是多了一次io查询hbase或者mysql。如果有钱能查一次就查到当然最好了。当然正常公司都没钱。那么如何判断一个索引需要加多少字段。
比如1张表20个字段,如果搜索条件就占了50%以上,也就是10个字段以上。那么其实可以考虑全表都加到es中。如果为了偶尔查询的那么几个mysql的字段,还要去mysql中回表一次,得不偿失。
如果一个表,搜索字段只有3个-5个。但是需要的字段有20个。可以考虑只把搜索字段加入es索引之中。以这种方式权衡利弊。
当然要特别注意一些大字段,text 等字段。
2.segment介绍
一个segment是一个完备的lucene倒排索引,而倒排索引是通过词典 (Term Dictionary)到文档列表(Postings List)的映射关系,快速做查询的。 由于词典的size会很大,全部装载到heap里不现实,
因此Lucene为词典做了一层前缀索引(Term Index),这个索引在Lucene4.0以后采用的数据结构是FST (Finite State Transducer)。 这种数据结构占用空间很小,Lucene打开索引的时候将其全量装载到内存中,加快磁盘上词典查询速度的同时减少随机磁盘访问次数。
segments为前缀索引FST做了缓存,为了加速查询,FST 永驻堆内内存,无法被 GC 回收。该部分内存无法设置大小,长期占用 50% ~ 70% 的堆内存。所以一个索引就算没用,他只要存在即占用堆内存,只能通过delete index,close index以及force-merge index释放内存。
解释下FST:
ES 底层存储采用 Lucene(搜索引擎),写入时会根据原始数据的内容,分词,然后生成倒排索引。查询时,先通过 查询倒排索引找到数据地址(DocID)),再读取原始数据(行存数据、列存数据)。但由于 Lucene 会为原始数据中的每个词都生成倒排索引,数据量较大。所以倒排索引对应的倒排表被存放在磁盘上。这样如果每次查询都直接读取磁盘上的倒排表,再查询目标关键词,会有很多次磁盘 IO,严重影响查询性能。为了解磁盘 IO 问题,Lucene 引入排索引的二级索引 FST [Finite State Transducer] 。原理上可以理解为前缀树,加速查询。
ES的data node存储数据并非只是耗费磁盘空间的,为了加速数据的访问,每个segment都有会一些索引数据驻留在heap里。因此segment越多,瓜分掉的heap也越多,并且这部分heap是无法被GC掉的! 理解这点对于监控和管理集群容量很重要,当一个node的segment memory占用过多的时候,就需要考虑删除、归档数据,或者扩容了。
对索引进行优化的操作
1查询所有segment语句
http://localhost:9200/_cat/segments
http://localhost:9200/_cat/segments?v&h=index,shard,segment,size,size.menory
2指定查询索引segment语句
http://localhost:9200/_cat/segments/fast_test?v&h=index,shard,segment,size,size.menory
3关闭开启索引
post index/_close
post index/_open
4强制合并索引segments。max_num_segments指定合并后的最大文件数量
此请求过程会阻塞,文件大的话耗时比较长,对写入和查询有性能影响.同时会把标记为删除的文件正式删除。
因为新的segments里不会带上旧的被删除的segments。
post index/_forcemerge?max_num_segments=1&only_expunge_deletes=false
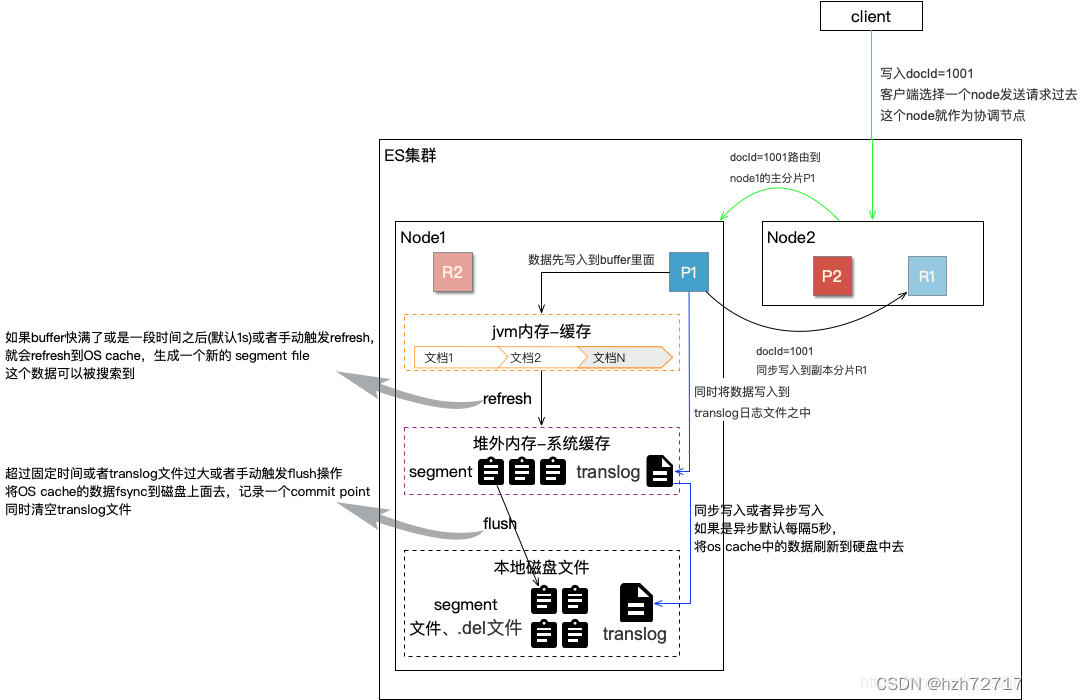
3.ES数据刷盘
segment合并的必要性
因为每一个segment都会占用文件句柄,内存资源,cpu资源,更加重要的是每一个搜索请求都必须访问每一个segment,这就意味着存在的segment越多,搜索请求就会变的更慢。
那么elaticsearch是如何解决这个问题呢? 有一个后台进程专门负责segment的合并,它会把小segments合并成更大的segments,然后反复这样。
刷盘顺序盘点
1数据被添加后优先加到es的java应用buffer缓存中。
2每1秒会执行刷新refresh到操作系统缓存os cache 和生成segment file(这是在内存中的.但是已经可以被搜索)
3实时写入translog内存。每5秒会把数据写入到translog文件。防止数据丢失。(由于每5秒还是有可能丢失。也可以设置成同步写入)
4每30分钟或者translog满了就会进行commit flush操作。把数据写入磁盘。translog实际上保存了所有segment。
5segment数据有很多存在内容中。如果满了会执行merge合并把segment合并到segment file(生成文件)。
6删除旧的缓存segment数据
总结:buffer缓存->refresh到cache->commit或者merge合并
segment file是用来数据直接进行搜索的和加载数据缓存的。而translog文件主要是用来持久化和备份的
4.减少内存的办法
• 删除不用的索引。delete index
• 关闭索引(文件仍然存在于磁盘,只是释放掉内存),需要的时候可重新打开。close index
• 定期对不再更新的索引做force merge















 2997
2997











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









