









sigmoid s i g m o i d
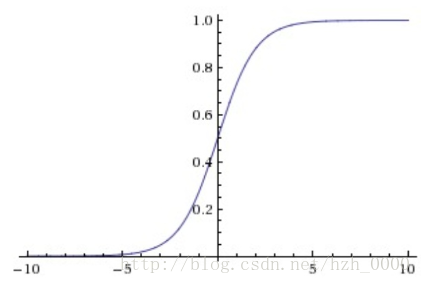
sigmoid非线性函数的数学公式是:
σ(x)=11+e−x
σ
(
x
)
=
1
1
+
e
−
x
.
缺点:
- Sigmoid函数饱和使梯度消失。当神经元的激活在接近0或1处时会饱和:在这些区域,梯度几乎为0。
- Sigmoid函数的输出不是零中心的。
tanh t a n h
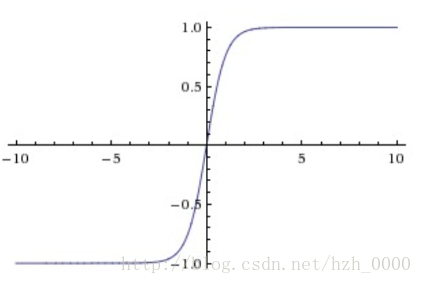
tanh
t
a
n
h
非线性函数
tanh(x)=2σ(2x)−1
t
a
n
h
(
x
)
=
2
σ
(
2
x
)
−
1
。它将实数值压缩到[-1,1]之间。和sigmoid神经元一样,它也存在饱和问题,但是和sigmoid神经元不同的是,它的输出是零中心的。因此,在实际操作中,tanh非线性函数比sigmoid非线性函数更受欢迎。
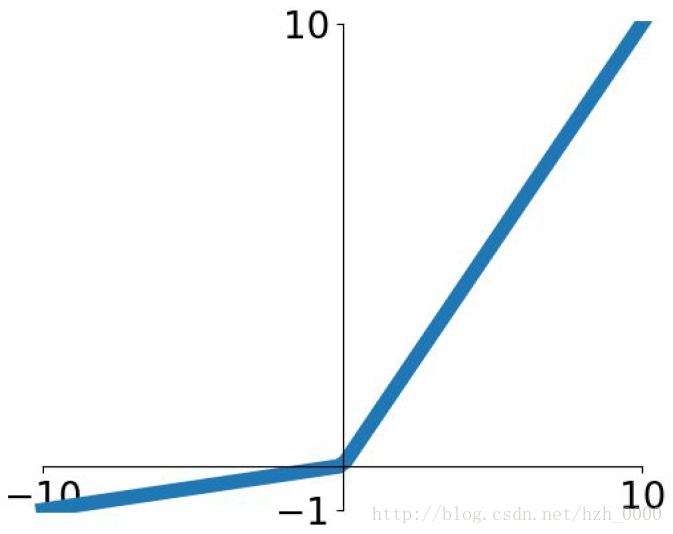
ReLU R e L U
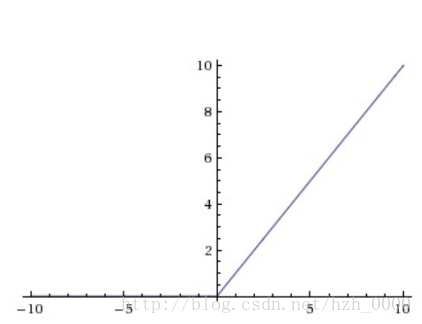
ReLU(x)=max(0,x)
R
e
L
U
(
x
)
=
m
a
x
(
0
,
x
)
优点:
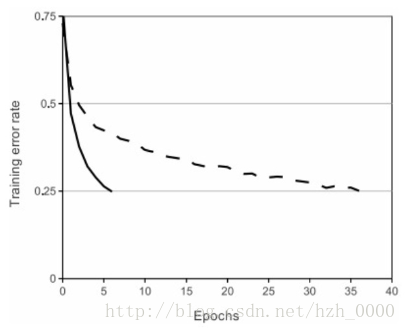
- 相较于sigmoid和tanh函数,ReLU对于随机梯度下降的收敛有巨大的加速作用( Krizhevsky 等的论文指出有6倍之多,如下图所示)。据称这是由它的线性,非饱和的公式导致的。
- sigmoid和tanh神经元含有指数运算等耗费计算资源的操作,而ReLU可以简单地通过对一个矩阵进行阈值计算得到。
缺点:
- 在训练的时候,ReLU单元比较脆弱并且可能“死掉”。举例来说,当一个很大的梯度流过ReLU的神经元的时候,可能会导致梯度更新到一种特别的状态,在这种状态下神经元将无法被其他任何数据点再次激活。如果这种情况发生,那么从此所以流过这个神经元的梯度将都变成0。也就是说,这个ReLU单元在训练中将不可逆转的死亡,因为这导致了数据多样化的丢失。例如,如果学习率设置得太高,可能会发现网络中40%的神经元都会死掉(在整个训练集中这些神经元都不会被激活)。通过合理设置学习率,这种情况的发生概率会降低。
Leaky ReLU L e a k y R e L U
Leaky ReLU(x)=max(0.01x,x)
L
e
a
k
y
R
e
L
U
(
x
)
=
m
a
x
(
0.01
x
,
x
)
,该激活函数是为了解决“ReLU死亡”问题。
Maxout M a x o u t
Maxout(x)=max(wT1x+b1,wT2x+b2)
M
a
x
o
u
t
(
x
)
=
m
a
x
(
w
1
T
x
+
b
1
,
w
2
T
x
+
b
2
)
Maxout
M
a
x
o
u
t
是对
ReLU
R
e
L
U
和
Leaky ReLU
L
e
a
k
y
R
e
L
U
的一般化归纳。这样
Maxout
M
a
x
o
u
t
神经元就拥有
ReLU
R
e
L
U
单元的所有优点(线性操作和不饱和),而没有它的缺点(死亡的
ReLU
R
e
L
U
单元)。然而和
ReLU
R
e
L
U
对比,它每个神经元的参数数量增加了一倍,这就导致整体参数的数量激增。















 1576
1576

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









