







一、什么是MQ?
MQ全称为Message Queue,也就是消息队列,是应用程序和应用程序之间的通信方法。
二、MQ能用来干什么?
能用来干什么,也就是MQ的适用场景。
在微服务盛行的当下,MQ被使用的也是越来越多,一般常用来进行业务异步解耦、解耦微服务、流量削峰填谷、消息分发、分布式事务的数据一致性,我们分别来看一下。
1、业务异步解耦
在正常业务流程中,比较耗时而且不需要即时返回结果的操作。将这些操作可以做为异步处理,这样可以大大的加快请求的响应时间。
最常见的场景就是用户注册之后,需要发送注册短信、邮件通知,以告知相关信息。
正常做法,是要经过三大步处理:用户信息处理、发送邮件、发送短信,等这三步全部都完成之后,才返回前端,告诉你注册成功了。
使用MQ,只需要在处理完用户信息之后,给MQ发送两个消息即可,邮件服务、短信服务监听MQ的任务消息,根据消息进行发送即可。
2、解耦微服务
还是用户注册的例子,将用户注册、邮件/短信发送理解为两个独立的微服务,就非常好理解。
3、流量削峰填谷
控制流量,也是MQ比较常用的一个场景,一般在秒杀、搞活动中使用广泛。这个时候一般用户请求量会激增,可能会远超当前系统的最大处理量,如果不做任何处理,系统可能就会宕掉。
使用MQ,可以将需要处理的消息全部放入其中,系统按照最大处理能力,去获取消息进行消费,这样就可以将一瞬间过来的请求,分散到一段时间内进行处理,避免了系统的崩溃。
4、消息分发
这个也挺常用。多个系统对同一个数据感兴趣,只需要监听同一类消息即可。
例如付款系统,在付款成功之后,正常做法是通知外围系统这个单子付款成功了,或者是外围系统定时来拉取付款结果,使用MQ后,付款系统可以在付款成功之后,将消息放到MQ里面,想知道这个结果的系统订阅这个主题的消息即可,非常方便,也不需要定时去拉取数据了。
5、分布式事务的数据一致性
先说明下,现在有一个专门处理分布式事务的开源框架Seata。在Seata出来之前,涉及到的分布式事务一般都通过消息中间件进行处理。
Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案。
目前主流的MQ框架,都支持分布式事务消息,好多小伙伴可能在初次接触的时候,会很有疑惑,到底是如何保证事务一致性的呢?下图来自阿里云,说的很明白,有点复杂的流程图,静下心来看或者略过不看
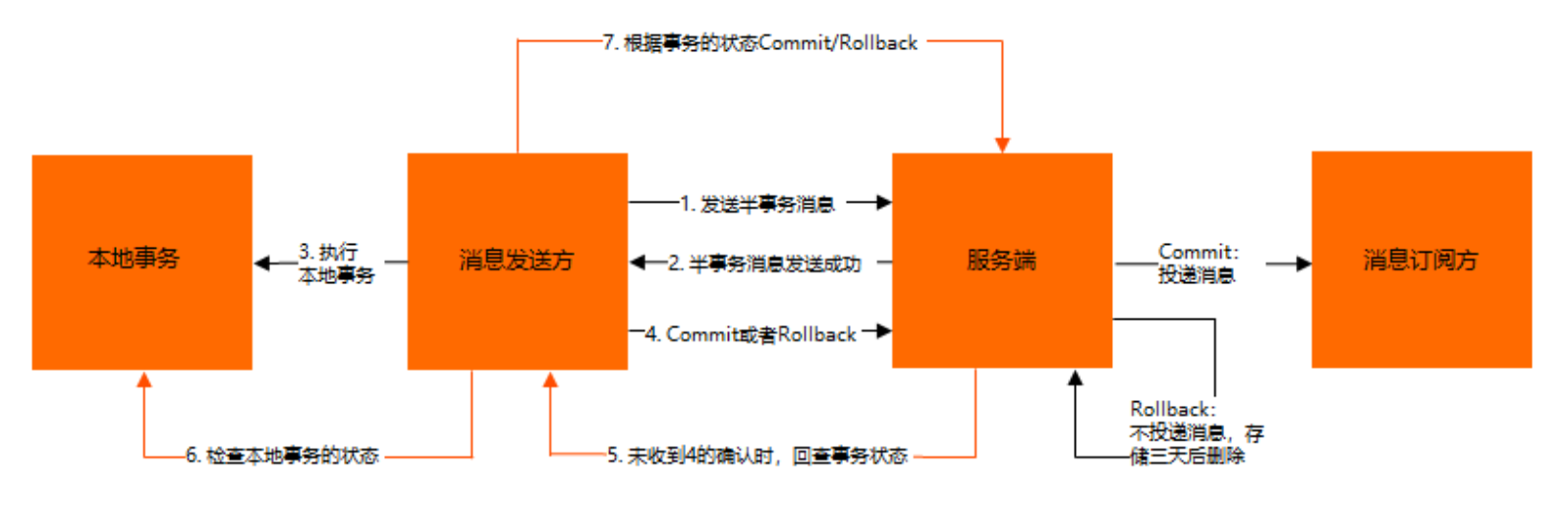
事务消息发送步骤如下:
- 发送方将半事务消息发送至消息队列RocketMQ。
- 消息队列RocketMQ将消息持久化成功之后,向发送方返回Ack确认消息已经发送成功,此时消息为半事务消息。
- 发送方开始执行本地事务逻辑。
- 发送方根据本地事务执行结果向服务端提交二次确认(Commit或是Rollback),服务端收到Commit状态则将半事务消息标记为可投递,订阅方最终将收到该消息;服务端收到Rollback状态则删除半事务消息,订阅方将不会接受该消息。
事务消息回查步骤如下:
- 在断网或者是应用重启的特殊情况下,上述步骤4提交的二次确认最终未到达服务端,经过固定时间后服务端将对该消息发起消息回查。
- 发送方收到消息回查后,需要检查对应消息的本地事务执行的最终结果。
- 发送方根据检查得到的本地事务的最终状态再次提交二次确认,服务端仍按照步骤4对半事务消息进行操作。
三、有啥缺点
1、系统可用性降低
系统可用性在某种程度上降低。在加入MQ之前,你不用考虑消息丢失或者说MQ挂掉等等的情况,但是,引入MQ之后你就需要去考虑了!
2、系统复杂性提高
加入MQ之后,首先就是你要具备有消息队列的相关知识,需要保证消息没有被重复消费、处理消息丢失的情况、保证消息传递的顺序性等等问题!
3、一致性问题
从上面的使用场景来看,消息队列带来的异步确实可以提高系统响应速度。但是,万一消息的真正消费者并没有正确消费消息怎么办?这样就会导致数据不一致的情况了!
四、总结
MQ的优点很多,但也存在缺点,所以大家还是要根据具体的业务场景来分析是否有必要使用消息中间件。有时候使用简单的技术可能效果会更好。
目前市面上比较流行的MQ有挺多的,例如:kafka、RocketMQ、RabbitMQ,那他们都有什么优缺点,到底该如何选择呢?关注公众号「Hugh的白板」,下篇文章给出答案。














 264
264











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









