







表的运算
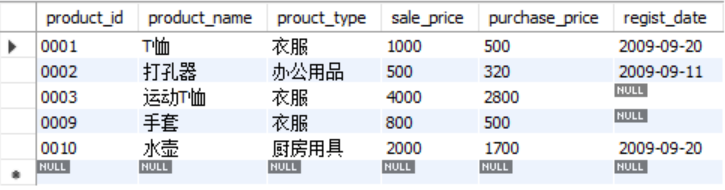
新建立的product2表格如下:
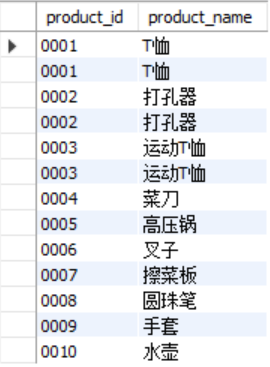
对记录取并集,在两个select语句之间用union连接,如果想包含重复行就用union all连接。注意连接的两个表要列数相同、类型一致,且order by只能在末尾用一次。取交集在mysql中可以使用关联子查询:
-- 取并集union(行方向)
select product_id,product_name from product union
select product_id,product_name from product2;
-- 输出10个不同的商品记录
select product_id,product_name from product union all
select product_id,product_name from product2 order by product_id;
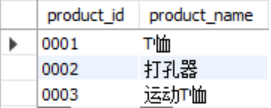
-- 取交集intersect、减法except在mysql中不可用,可按照关联子查询方式取交集:
select product_id,product_name from product as p1 where product_id= (select
product_id from product2 as p2 where p1.product_id=p2.product_id);
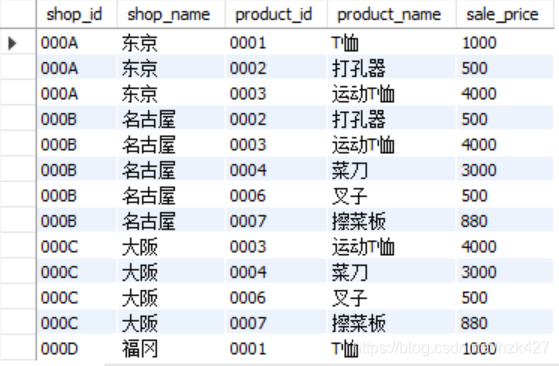
以列为单位的表联结
内联结:inner join…on…,on之后指定两张表联结所使用的联结键,联结条件一般都是“=”。注意on子句要写在from和where子句之间。比如想将shopproduct表格中的商品id找出对应于product表格中的商品名称和售价,那么联结键就是product_id:
-- 内联结:inner join
select sp.shop_id,sp.shop_name,sp.product_id,p.product_name,p.sale_price from
shopproduct as sp inner join product as p on sp.product_id=p.product_id;
如果只展示名古屋商店的结果,可以在末尾加入where语句:
-- on要写在from和where之间:
select sp.shop_id,sp.shop_name,sp.product_id,p.product_name,p.sale_price from
shopproduct as sp inner join product as p on sp.product_id=p.product_id
where sp.shop_id='000B';
外联结:left/right outer join…on…,left/right规定联结的主表,选择不同结果一般也不同,最后呈现的行数为主表的行数。比如上述事务中,将shopproduct作为主表的外联结结果和之前的内联结结果一样,将product作为主表则会多出两行:
select sp.shop_id,sp.shop_name,sp.product_id,p.product_name,p.sale_price from
shopproduct as sp left outer join product as p on sp.product_id=p.product_id;
-- 结果与内联结结果相同
select sp.shop_id,sp.shop_name,p.product_id,p.product_name,p.sale_price from
shopproduct as sp right outer join product as p on sp.product_id=p.product_id;
-- 多出两行记录
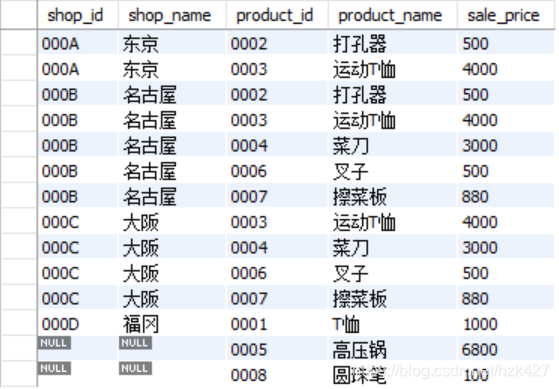
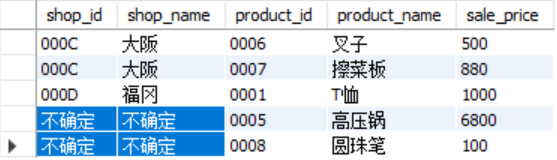
注意在规定外联结的主表时,联结键需要是主表的,这样才能呈现最多的信息。比如在上述右侧外联结中,如果选择的是sp.product_id,那么展示出高压锅和圆珠笔的product_id也是null了。对于null值可以用之前学过的coalesce函数来填充:
select coalesce(sp.shop_id,'不确定') as shop_id,coalesce(sp.shop_name,'不确定')
as shop_name,p.product_id,p.product_name,p.sale_price from shopproduct
as sp right outer join product as p on sp.product_id=p.product_id;
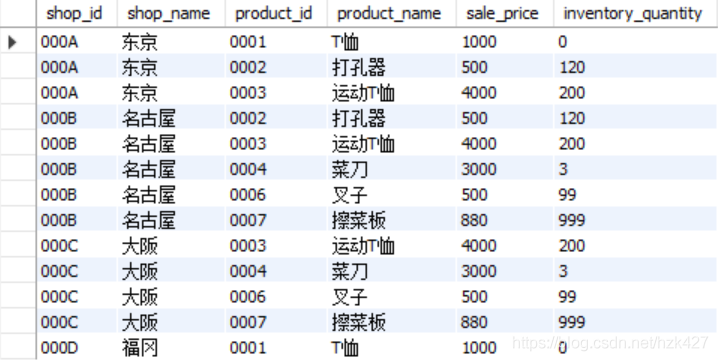
多表联结:先联结两个表,将此作为一个整体再以同样的方式联结第三个表,如此类推。比如有一个管理库存商品的表InventoryProduct包含inventory_id(仓库编号)、product_id和inventory_quantity(库存数量)三列,取出保存在S001仓库中的商品数量,添加到之前内联结的结果中:
select sp.shop_id,sp.shop_name,sp.product_id,p.product_name,p.sale_price,
ip.inventory_quantity from shopproduct as sp inner join product as p
on sp.product_id=p.product_id
-- 上述语句作为一个整体
inner join InventoryProduct as ip on sp.product_id=ip.product_id where
inventory_id='S001';
窗口函数
也称为在线分析处理数据函数,格式为 <窗口函数> () over (partition by < columns > order by < columns >),partition by分组后的记录集合称为窗口,order by决定了排序的规则,语句最后还可以再加一个order by。能够作为窗口函数的有:
- 聚合函数(SUM、AVG、COUNT、MAX、MIN);
- RANK、DENSE_RANK、ROW_NUMBER等专用窗口函数。
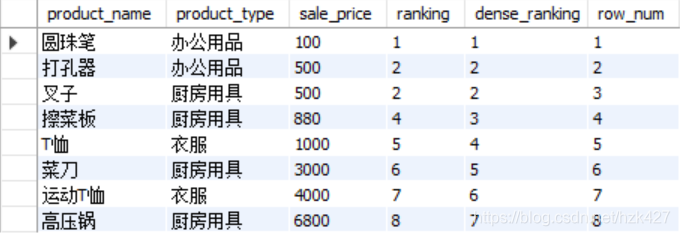
比如想根据商品种类分组,每组按照商品售价由低到高排序:
select product_name,product_type,sale_price,rank () over
(partition by product_type order by sale_price) as ranking from product;
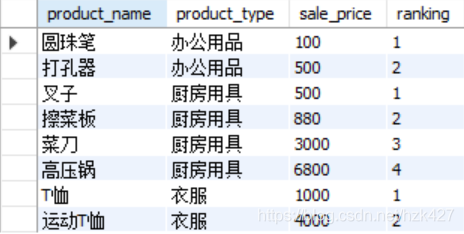
如果不使用partition by就是将整个表看作一个窗口,按照所有商品的售价排序。
- RANK函数:计算排序时,如果存在相同位次的记录,则会跳过之后的位次。 比如有 3 条记录排在第 1 位时:1 位、1 位、1 位、4 位……
- DENSE_RANK函数:即使存在相同位次的记录,也不会跳过之后的位次。有 3 条记录排在第 1 位时:1 位、1 位、1 位、2 位……
- ROW_NUMBER函数:赋予唯一的连续位次。有 3 条记录排在第 1 位时:1 位、2 位、3 位、4 位……
下面看一下它们的区别:
select product_name,product_type,sale_price,rank () over(order by sale_price) as ranking,
dense_rank () over (order by sale_price) as dense_ranking-- 有相同位次也不会跳过之后的位次
,row_number () over (order by sale_price) as row_num from product;-- 唯一的连续位次
聚合函数也可以作为窗口函数,比如按照id升序计算当前商品为止的累积售价之和:
select product_id,product_name,sale_price,sum(sale_price) over
(order by product_id) as cum_sum from product;

计算移动平均时,在order by子句之后加入rows between m preceding and n following语句。假定3行为汇总对象,分别进行3行向前移动平均、3行向后移动平均、前后共3行移动平均:
SELECT product_id, product_name, sale_price,
AVG(sale_price) OVER (ORDER BY product_id ROWS 2 PRECEDING) AS f_MA3,
-- 截止到之前2行(加上自身3行)
AVG(sale_price) OVER (ORDER BY product_id rows between 0 preceding and 2 following) AS b_MA3,
-- 截止到之后2行(加上自身3行)
AVG(sale_price) OVER (ORDER BY product_id ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS m_MA3
-- 包含前一行和后一行(加上自身3行)
FROM product;
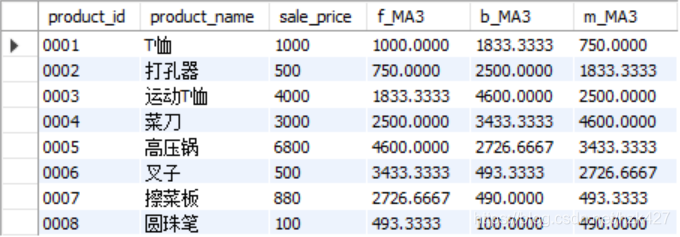
注意数据不够3行时会按照前1行或2行的平均来算。
grouping运算符
使用grouping运算符可以方便的生成小计和合计行。比如mysql在group by子句之后加上with rollup就可以得到每一类的小计和总合计行:
select product_type,sum(sale_price) as sum_price from product
group by product_type with rollup;
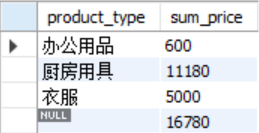
相当于同时执行了group by()(即全部数据为一组的“超级分组纪录”)和group by product_type。
也可以基于多个聚合键分组合计:
select product_type,regist_date,sum(sale_price) as sum_price from product
group by product_type,regist_date with rollup;

相当于同时执行了①group by()、②group by product_type和③group by product_type,regist_date。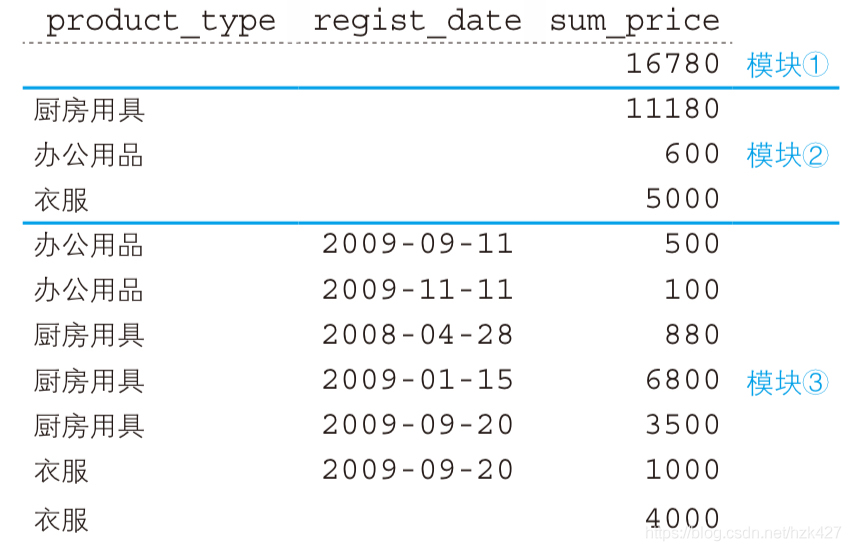
cube函数可以汇总所有可能的合计组合,但是mysql貌似还不支持。
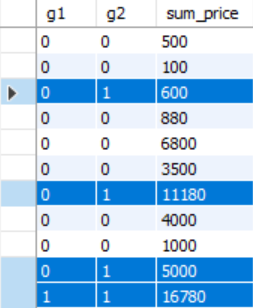
grouping函数:让原数据的null和超级分组纪录的null更加容易分辨,超级分组纪录产生的null返回1(总合计记录行所有展示的列均为1),原始数据null返回0:
select grouping(product_type) as g1,grouping(regist_date)
as g2,sum(sale_price) as sum_price from product
group by product_type,regist_date with rollup;
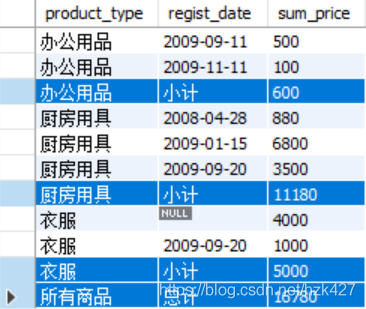
合计行的null看起来很奇怪,下面指定合计行的字符串说明,比如每一类的合计称为“小计”,所有商品的合计称为“总计”:
SELECT CASE WHEN grouping(product_type) = 1
THEN '所有商品'
ELSE product_type END AS product_type,
CASE WHEN grouping(regist_date) = 1 and grouping(product_type) = 0
THEN '小计'
WHEN grouping(regist_date) = 1 and grouping(product_type) = 1
THEN '总计'
ELSE regist_date END AS regist_date,
SUM(sale_price) AS sum_price
FROM Product
GROUP BY product_type, regist_date with rollup;
















 1446
1446











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









