







第二章 算法
1 讲算法更好的理解数据结构,相辅相成的关系
2 算法提高计算效率,那些公式是很必要的,是重要算法
算法定义:解决特定问题求解步骤的描述,在计算机中表现为指令的有限序列,并且每条指令表示一个或多个操作。
五个基本特征:输入,输出,有穷性,确定性和可行性
2.6 算法设计要求:
1 正确性:
无语法错误;
合法输入有满足要求输出;
非法输入有满足规格说明输出;
对于精心选择甚至刁难的数据有满足要求的输出结果
算法一般无法用程序证明,而是用数学方法证明,代价昂贵;一般到第三层次就可以了。
2 可读性
便于阅读、理解和交流
3 健壮性
当输入数据不合法时,算法也能做相关处理,而不是产生一场或者莫名其妙的结果
4 时间效率高和存储量低
2.7 算法效率的度量方法
1 事后统计
先写好算法,测试,统计时间
2 事前分析评估
消耗时间取决于四个因素:
1 算法采用的策略、方法;
2 编译产生的代码质量; 软件支持
3 问题的输入规模;
4 机器执行指令的速度 硬件性能
刨去软硬件因素,一个程序的运行时间取决于,算法的好坏和问题的输入规模
2.8 函数的渐进增长:增长趋势,忽略小量输入
对于给定的两个函数f(n) 和g(n),如果存在一个整数N,使得对所有的n>N,f(n) 总是比g(n)大,那么我们说f(n) 的增长渐进快于g(n)
2.9 时间量度
T(n) =O(f(n)) 随着问题规模n的增大,算法执行时间的增长率和f(n)的增长率相同,称作算法的渐进时间复杂度,简称时间复杂度。 O(1)常数阶,线性阶,平方阶,对数阶(比如二分法)

2.11 最坏情况和平均情况
最坏情况运行时间是一种保证,那就是运行时间将不会再坏了,通常我们提到的运行时间都是最坏情况的运行时间。
平均运行时间是所有情况中最有意义的,因为它是期望的运行时间。
2.12 算法空间复杂度

存储程序本身的 指令、常数、变量、和输入数据、 还需要存储对数据操作的存储单元。 后面这个可能是指 临时存储
第三章 线性表 List “表”
零个或多个数据元素的有限序列:序列(前驱和后继)、有限
在较复杂的线性表中, 一个数据元素可以由若干个数据项组成。
基本操作: 初始化,判断是否为空,清空,获取/定位,删除/插入,长度
其他复杂操作可以由这些基本操作组合而成
3.4 顺序存储结构
定义:用一段地址连续的存储单元依次存储线性表的数据元素
顺序存储结构需要三个属性:
- 存储空间起始位置:数组data的存储位置
- 最大存储容量: 数组的长度 Maxsize
- 线性表当前长度:length
由于存储位置是编号的,连续的,我们对每个线性表位置的存入或者取出数据,对于计算来说都是相等的时间,
存取时间性能为O(1). 我们把这种存储结构称为随即存储结构。
- 插入/删除时间复杂度O(n)
比较适合元素个数不太变化,存取数据的应用

3.6 线性表的链式存储结构
除了存储数据元素信息,还要存储它后继元素的存储地址,即 逻辑关系。
- 我们把存储数据元素的域称为数据域,把存储直接后继位置的域称为指针域。
- 指针域中存储的信息称作 指针 或链 ;
这两部分信息组成数据元素的存储映像,称为节点(Node).
第一个节点的存储位置称为头指针;最后一个节点指针为空。
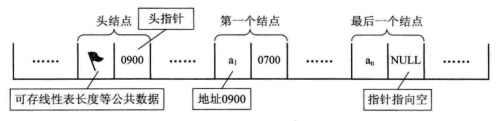
为了方便,常在第一个结点前附设一个结点,称为头结点。
3.7 单链表的读取
获取第i个元素 就是从头开始找; O(n)
3.8 单链表的插入和删除
3.9 单链表的创建
一个动态生成链表的过程,从空表的初始状态起,依次建立各元素节点
有两种方式:头插法和尾插法
3.10 单链表的整表删除

经验性结论:
- 若线性表需要频繁查找,很少需要插入和删除是,宜采用顺序存储结构,反之用单链表结构;
- 当线性表中元素个数变化较大或者根本不知道有多大是,最好用单链表
3.12 静态链表
有些语言没有指针,该怎么实现链表呢?
用数组实的现: 数组的元素有两个数据域组成,data和cul,cul相当于单链表中的next指针,存放该元素大的后继在数组中的下标
这种用数组描述的链表叫做静态链表,游标实现法。!!!
3.13 循环链表
对于单链表,每个结点存储了向后的指针,前驱结点找不到
* 将单链表中终端结点的指针端由空指针改为头指针,整个链表就形成一个环* 循环链表
判断条件,p - next 不等于头结点,则循环未结束
用尾指针表示循环列表,这样查找头指针和终端指针都很方便,这样也很方便两个链表的合并
3.14 双向链表
在单链表的每个结点中,再设置一个指向其前驱结点的指针域
第四章 栈与队列
* 栈 限定 仅在 表尾 进行插入和删除操作的线性表*
* 队列 只允许 在一段进行插入操作 另一端进行删除操作的线性表*
4.2 栈的定义
允许插入和删除的一端称为栈顶 top ,另一端称为 栈底 bottom : 先进后出的线性表 Last in First out LIFO
插入: 进栈 压栈 入栈
删除: 出栈 弹栈
栈:stack
插入:push ;弹出:pop 特殊 不同于单链表
由于栈本身是一个线性表,那么前面讨论的线性表的顺序存储和链式存储 也是适用的
4.4 栈的顺序存储结构及实现
顺序栈,定义一个top 变量来指示栈顶元素在数组中的位置 空栈 top = -1 数组首元素为0
进栈和出栈 操作都挺简单,时间复杂度O(1)
4.5 两栈共享空间
因为当空间不够用时,数组的扩展很麻烦;
定义一个数组, 里面存储两个类型相同的栈
top1和top2 是栈1和栈2的栈顶指针,可以想象只要它两不见面,两个栈可以一直使用。
top1 +1 = top2 时为栈满。
通常是当两个栈的空间需求有相反关系时使用,比如股票买卖,一方出,一方进。
4.6 栈的链式存储结构及实现
链栈
链表有头指针,栈顶指针也是必须的,可以把栈顶放在单链表的头部,对于链栈来说,是不需要头结点的。
* 不存在栈满的情况,链栈为空就是top = NULL *
链栈的操作绝大部分和单链表类似,只是在插入和删除上特殊一些
push 和 pop 操作都很简单,没有任何循环操作,时间复杂度均为 O(1)
* 对比: *
顺序栈存取是定位方便,但是可能存在空间浪费;链栈要求每个元素都要有指针域,也会增加内存开销,长度无限制。
4.7 栈的作用
引入简化了程序设计的问题,划分了不同关注层次,使得思考范围缩小,更加聚焦于我们要解决问题的可信,如果总是使用素族,要分散精力去考虑数组的下标增减等细节问题,反而容易掩盖问题的本质。 高级语言都有栈结构的封装,可以直接使用。
注:这里提到的观点,是我学习中一直存在的问题,过于关注原理,而不是聚焦于问题的解决,容易拖延进度和受挫,毕竟还没有到真正天才的地步。 不管怎样站在前人肩膀上都是不错的。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 208
208

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









