







我们都知道java中关于List的实现有两种方式:ArrayList与LinkedList,那么今天我们来看看两者在使用过程中的一些注意事项;
首先来看看两者的类结构图:
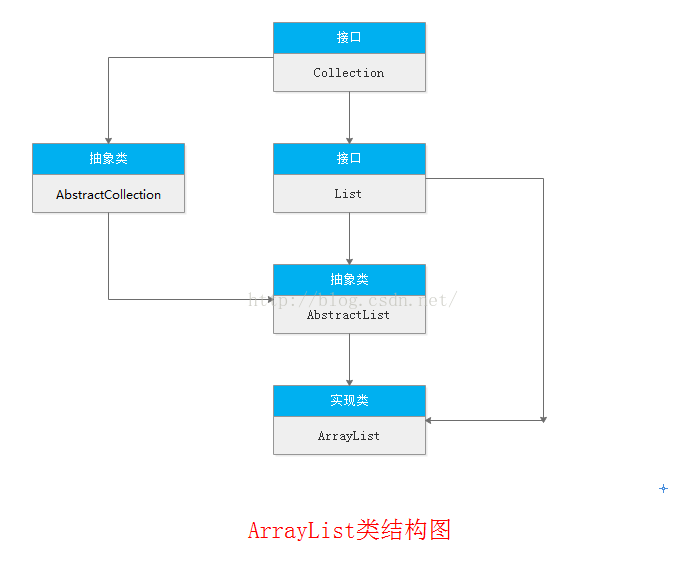
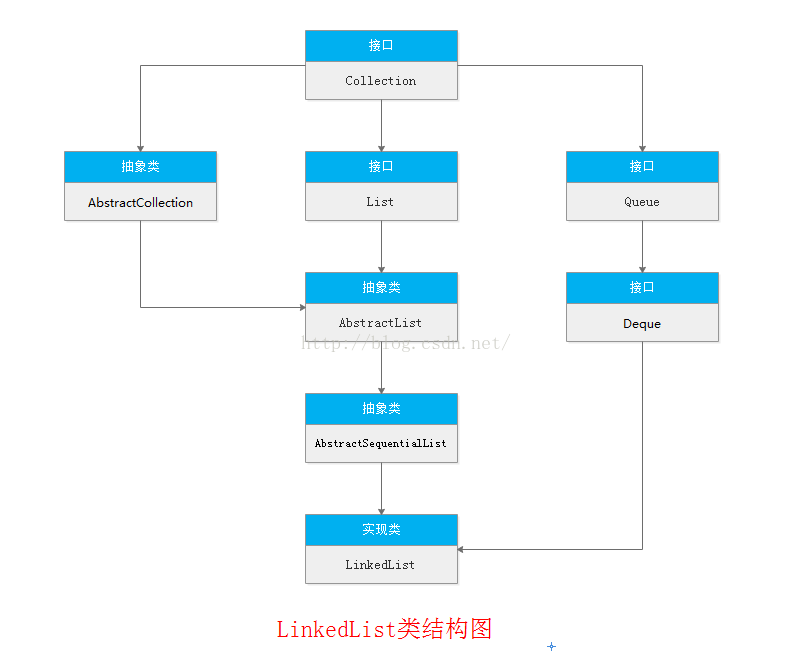
接下来我们对两者做出总结:
ArrayList学习总结:
(1):ArrayList的默认容量大小是10;
(2):不同于Vector,ArrayList不是线程安全的,可以使用CopyOnWriteArrayList来代替;
(3):ArrayList底层是由数组实现的,它继承自AbstactList,实现了List接口、RandAccess接口、Cloneable接口、Serializable接 口,所以它支持随机访问,实现了writeObject来进行序列化、实现了clone来进行浅拷贝;
(4):ArrayList实现序列化writeObject方法首先将"容量"写入输出流,接着再依次写入"每一个元素",因此在放序列化方法readObject
中应该首先出输入流中读出"容量",接着再读出"每一个元素";
(5):当ArrayList容量不足的时候会自动进行扩容,而最新的容量和原油容量的关系是:
int newCapacity = oldCapacity + (oldCapacity >> 1);(也就是原有容量*3)/2
(6):源码中要注意一个叫trimToSize的方法,这个方法是用于将当前数组的大小修剪为当前实际元素的个数大小,什么意思呢? 就是当数组大小不足以存放当前元素的时候,我们是通过(原有容量*3)/2的方式增大数组大小的,但是有时候这样做会导致数组实际大小远远大于实际元素个数的情况,而trimToSize方法就是用于将当前数组的大小修剪成当前元素个数的,这样的话减少了数组空间的浪费;
(7):源码中的clear方法也需要注意一点的就是,执行该方法之后只会将数组元素删除同时将数组元素个数置位0,但是数组大小是不会发生变化的,可以这么理解,我辛辛苦苦扩充的容量怎么能随随便便让你释放掉呢?说不准后面还要用,如果实在不用了的话,就执行trimToSize方法将数组大小也置位为0;
(8):我们可以使用迭代器Iterator或者索引来遍历ArrayList取得里面的所有数组,相对来说的话,通过索引的随机访问效率更高一些;
(9):另外要提的一点就是ArrayList在动态增长的过程当中伴随着的是数组元素的拷贝,这点会影响效率问题,所以如果我们在使用的时候已经能够预知到它的大小,那最好能够直接创建一个固定大小的ArrayList出来,你可以想一想,如果采用默认大小的话,最初都是10,而现在你已经知道你想要创建一个容量大小为100的,那么从10自动扩容到100是需要6次扩容过程,每次都有数组元素的拷贝过程,效率自然不高啦;
(10):ArrayList里面有两个方法toArray()以及toArray(T[] a),允许你将当前ArrayList转换为数组,但是第一种方法只能转换为Object类型的数组,如果你想转换为其他类型的数组,是会报java.lang.ClassCastException错误的,原因就在于java是不允许你向下转型的,所以这个时候呢,我们就应该采用第二种方法啦,传入的参数就是你想要转换成什么样类型的数组了,当然这个数组大小是需要你自己提前设置的了;
(11):需要注意的是ArrayList里面有一个叫modCount的变量,这个变量比较关键,他在ArrayList的结构或者内容发生变化的时候都会加1,而正是因为modCount的变化,所以会导致我们经常遇到的一个异常的发生:ConcurrentModificationException,原因可以查看我的上一篇博客;
LinkedList学习总结:
(1):LinkedList底层是由双向链表实现的
(2):LinkedList继承自AbstractSequentialList,而AbstractSequentialList是继承自AbstractList的,所以LinkedList算是间接继承自
AbstractList了,对于AbstractSequentialList,从官方注释上面可以看出他是为了连续访问而提供的List接口的骨干实现,如果你的操
作是频繁的进行随机访问的话,官方建议你还是选择AbstractList,LinkedList同时实现了List、Deque、Cloneable以及Serializable,实现了List那么可以用于队列,实现了Deque那么可以用于双端队列,实现了Cloneable所以能进行克隆,但是这里的克隆是浅拷贝,也就是说如果LinkedList里面存放的对象包含别的对象的话,对这个对象是浅拷贝的,即只拷贝他的引用而已,实现Serializable表示他是可以序列化的;
(3):因为LinkedList里面提供了getFirst、removeFirst以及peekFirst所以他也同样适用于栈操作,三个方法和栈操作中的方法对应关系是:getFirst----->push,removeFirst----->pop,removeFirst----->peek,和栈操作中的pop与peek的区别一样,removeFirst会返回并且删除掉第一个元素,而peekFirst仅仅是返回第一个元素;
(4):LinkedList可以用于FIFO(先进先出)队列,他们方法的对应关系是:左边是队列操作,右边是链表操作
add----->addLast
remove----->removeFirst
offer----->offerLast
poll----->pollFirst
element----->getFirst
peek----->peekFirst
很多人会问既然已经有addLast了,为什么还要有offerLast呢?其实两者的区别仅仅在于addLast在队列已经满的时候会抛出异常,而offerLast只是会返回false,removeFirst与pollFirst的区别也是一样的了;
(5):因为LinkedList是采用双向链表实现的,那么他自然适合于顺序访问,但是对随机访问效率不是很高;
(6):和ArrayList一样,LinkedList也不能用于多线程环境中,原因和ArrayList是一样的,在此情况下,我们可以用ConcurrentLinkedQueue来替代LinkedList,另一种解决方法是我们通过这样的方式来定义LinkedList,List<String> linkedList = Collections.synchronizedList(new LinkedList<String>());
(7):LinkedList是采用链表实现的,所以理论上他的长度是不受限制的;
ArrayList与LinkedList的对比:
(1)ArrayList适用于随机访问,LinkedList适用于顺序访问;
(2)LinkedList更加适用于插入、删除大量元素的情形;
(3)两者都是线程不安全的,如果需要线程安全版本,ArrayList对应的是CopyOnWriteArrayList,LinkedList对应的是ConcurrentLinkedQueue;
(4)ArrayList的主要控件开销在需要在List列表的结尾预留一定的空间,而LinkedList的控件开销在于需要存储结点信息以及结点指针信息;

















 139
139

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









