







首先来说说两者的区别,接着给出得出这些区别的原因,最后从HashMap和HashSet实现的角度谈谈这两个集合类对hashCode和equals的使用,其实说白了,个人认为这两个区别也只是在HashMap和HashSet中体现的比较明显点;
两者的关系:
(1):两个对象如果equals,那么他们的hashCode也相等
(2):两个对象如果hashCode相等,但他们不一定equals
(3):两个对象hashCode值不等,他们一定不equals
(4):两个对象不equals,他们的hashCode值不一定不等
也就是说我们在判断两个对象等不等的时候,首先判断两者的hashCode值等不等,不等的话两个对象直接就不等了,相等的话再去看equals,这点我们可以从HashMap的使用中体现出来;
首先我们通过实例来具体看下这两者的区别:
首先来印证结论(2):
public class Test {
@Override
public int hashCode() {
System.out.println("执行了hashCode方法");
return 1;
}
@Override
public boolean equals(Object obj) {
System.out.println("执行了equals方法");
return false;
}
public static void main(String[] args) {
HashMap<Test, String> map = new HashMap<>();
Test test1 = new Test();
Test test2 = new Test();
map.put(test1, "test1");
map.put(test2, "test2");
System.out.println("map的长度: "+map.size());
}
}
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}可以看到,put方法首先调用的是hashCode,随后在找到对应hash值在数组中的存储位置之后才会执行equals方法找链表中有没有将要插入的键值对的key值的,为了方便,我们可以这样理解,hashCode找对应hash值在数组中的位置,equals找当前key值在该数组位置相应链表中位置的,直观点就是下面这幅图;
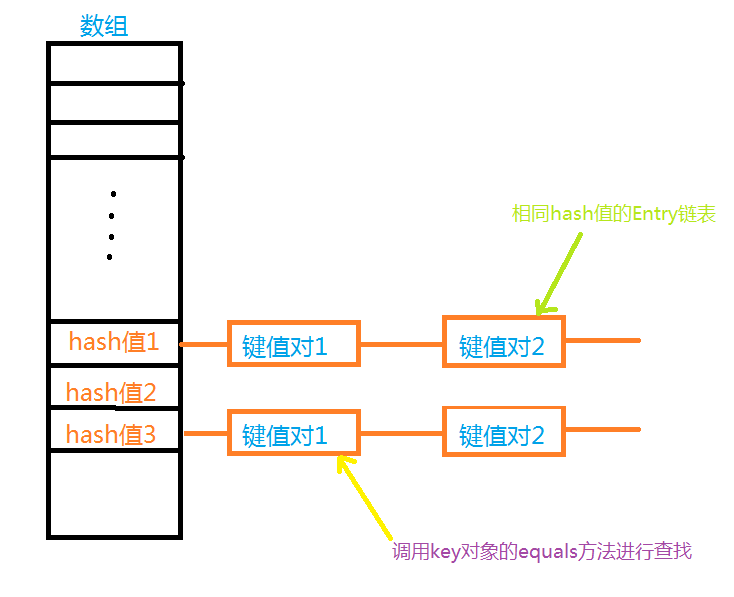
在测试中我们将Test类作为了HashMap的key值,随后调用了HashMap的put方法,接下来我们看看输出结果:
执行了hashCode方法
执行了hashCode方法
执行了equals方法
map的长度: 2我们修改上面的测试代码,将Test类中的equals方法的返回值修改为true,也就是修改成如下代码:
public class Test {
@Override
public int hashCode() {
System.out.println("执行了hashCode方法");
return 1;
}
@Override
public boolean equals(Object obj) {
System.out.println("执行了equals方法");
return true;
}
public static void main(String[] args) {
HashMap<Test, String> map = new HashMap<>();
Test test1 = new Test();
Test test2 = new Test();
map.put(test1, "test1");
map.put(test2, "test2");
System.out.println("map的长度: "+map.size());
}
}
执行了hashCode方法
执行了hashCode方法
执行了equals方法
map的长度: 1如果我们把测试代码修改成下面这样:
public class Test {
public static int count = 0;
@Override
public int hashCode() {
System.out.println("执行了hashCode方法");
count++;
return count;
}
@Override
public boolean equals(Object obj) {
System.out.println("执行了equals方法");
return true;
}
public static void main(String[] args) {
HashMap<Test, String> map = new HashMap<>();
Test test1 = new Test();
Test test2 = new Test();
map.put(test1, "test1");
map.put(test2, "test2");
System.out.println("map的长度: "+map.size());
}
}
执行了hashCode方法
执行了hashCode方法
map的长度: 2 从上面的三个测试可以看出来,HashMap在put时候首先调用的是hashCode方法,如果发现当前hash值对应的数组位置处的链表为空的话是不会执行equals的,也就是hashCode方法先于equals方法执行;















 4685
4685

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









