






 本文介绍使用Python编写爬虫,爬取某城市某天的天气信息。通过分析http://www.tianqihoubao.com网站,发现历史天气页面地址规律,用格式化字符串控制访问界面。使用正则表达式筛选最高、最低温度,还处理了获取“天气状况”时遇到的符号问题。
本文介绍使用Python编写爬虫,爬取某城市某天的天气信息。通过分析http://www.tianqihoubao.com网站,发现历史天气页面地址规律,用格式化字符串控制访问界面。使用正则表达式筛选最高、最低温度,还处理了获取“天气状况”时遇到的符号问题。
老规矩,先上代码:
import re
import requests
def go_this_time(city,time):
url = "http://www.tianqihoubao.com/lishi/{0}/{1}.html".format(city,time)
response = requests.get(url).content.decode("gbk").replace('\n','').replace('\t','').replace(' ','').replace('\r','')
res1 = r'<b>(.*?)</b>'
res2 = r'<td>(.*?)</td>'
res3 = r'alt=\'(.*?)\''
wendu_list = re.findall(res1,response) # 获取温度
tianqi_list = re.findall(res2,response) # 获取天气
height = wendu_list[2] # 该天最高温度
low = wendu_list[3] # 该天最低温度
night_weather = re.findall(res3,tianqi_list[2]) # 夜晚天气
daytime_wind = tianqi_list[5] # 白天风力
day_weather = re.findall(res3,tianqi_list[1]) # 白天天气
night_wind = tianqi_list[6] # 夜晚风力
print("该天最高温度:" + height)
print("该天最低温度:" + low)
print("白天风力:"+daytime_wind)
print("夜晚风力:"+night_wind)
return height,low,daytime_wind,night_wind,day_weather[0],night_weather[0]
print(go_this_time("chengdu","20201010"))-----------------------------------------------------------------------------------------------------------------------------------
好!我们现在开始分析,先清楚需求:这个爬虫的目的是爬取某城市的某天的天气信息。
从需求上看,要有2个变量:城市,日期。
那么我们要爬那个网站的数据呢?http://www.tianqihoubao.com
进入网站主页
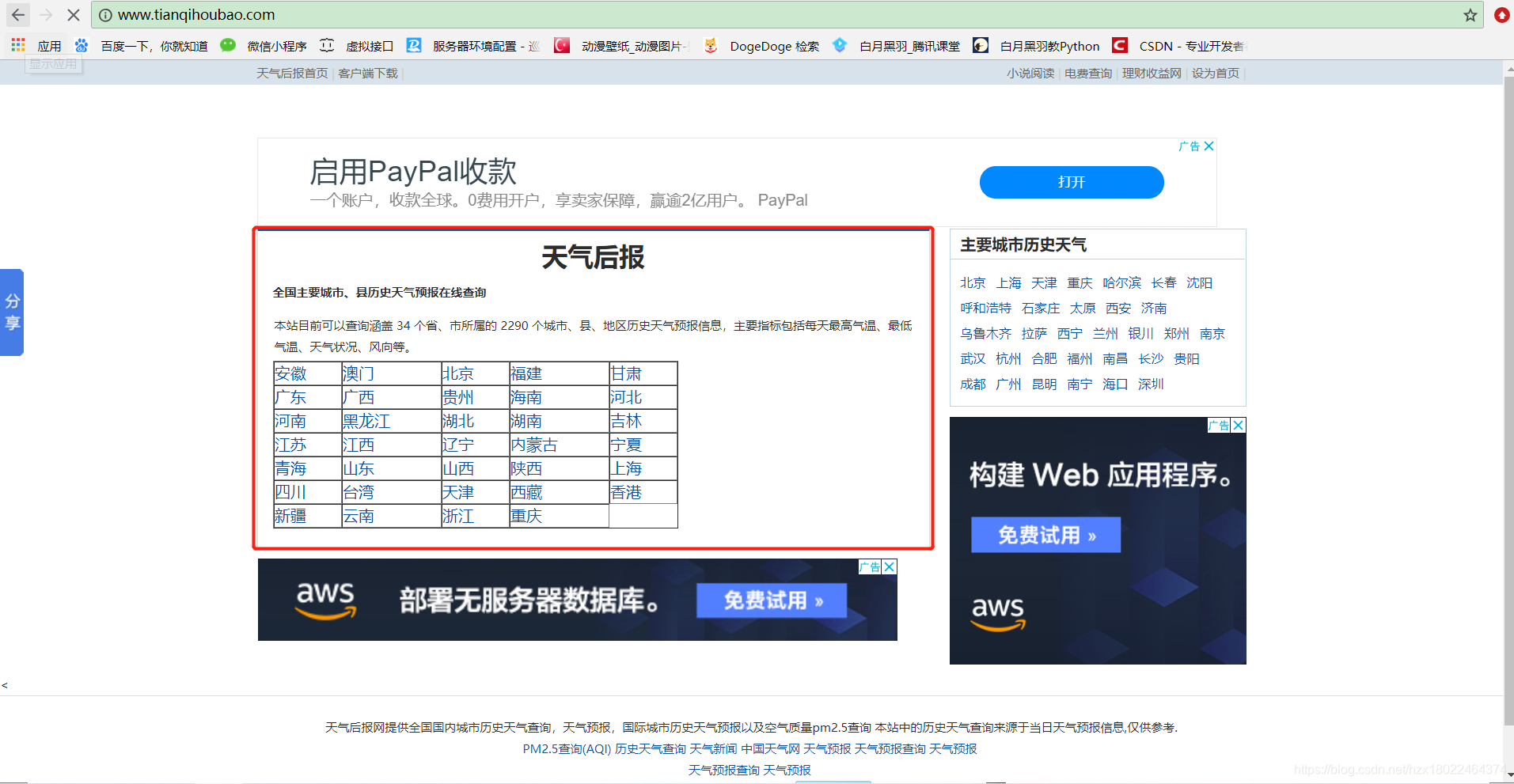
例如我要查看成都11月12日的历史天气:
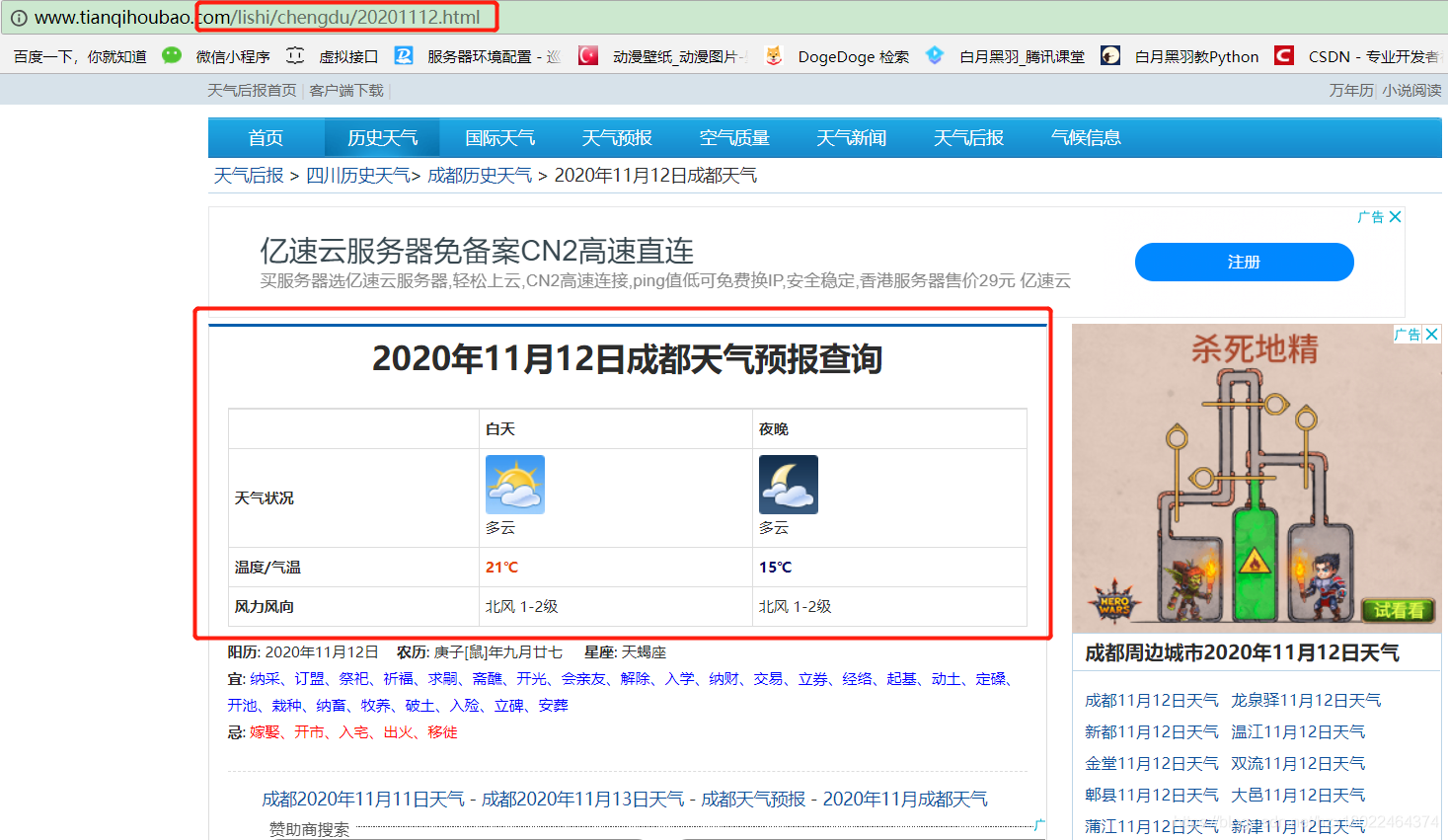
我们可以发现一个规律,历史天气页面的地址变化的只有城市的拼音和日期。如:chengdu/20201112,换言之,我要是想进入北京11月12日的历史天气页面只需要更改url为:beijing/20201112.于是代码中才会出现:url = "http://www.tianqihoubao.com/lishi/{0}/{1}.html".format(city,time)
目的就是通过接受不同的城市和日期来控制我们想进入的历史界面。
只要进入想进入的历史界面事情就好办了,我们现在来获取页面的数据:
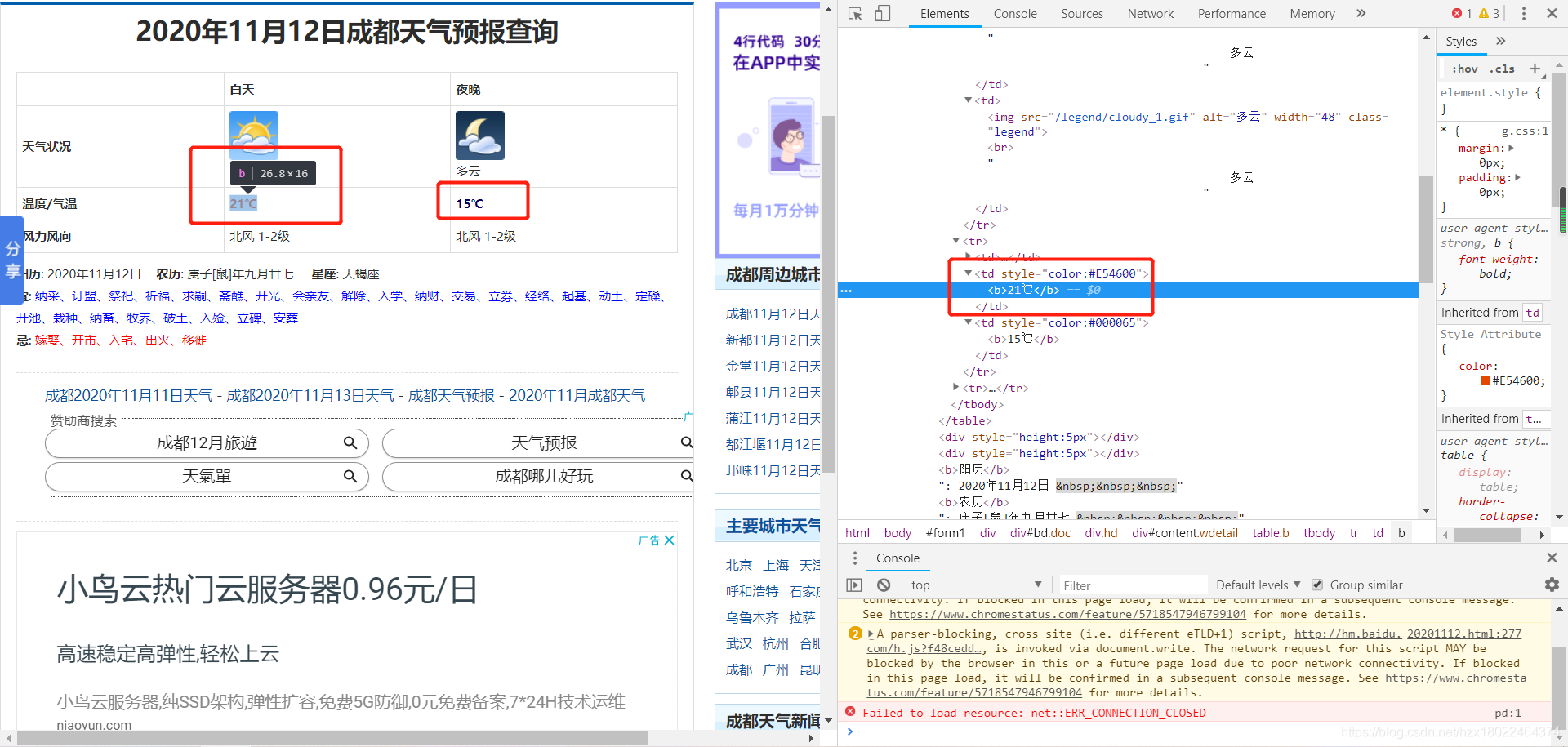
按f12,发现页面上的最高 温度和最低温度都是在<b></b>里面,所以用正则表达式:
res1 = r'<b>(.*?)</b>'wendu_list = re.findall(res1,response) # 获取温度筛选出所有<b></b>里面的内容(也就是最高温度和最低温度),以list形式输出。
打印这个list得知最高温度和最低温度是webdu_llist[2]和wendu_list[3],所以:
height = wendu_list[2] # 该天最高温度
low = wendu_list[3] # 该天最低温度
获取“天气状况”的时候,遇到一个问题
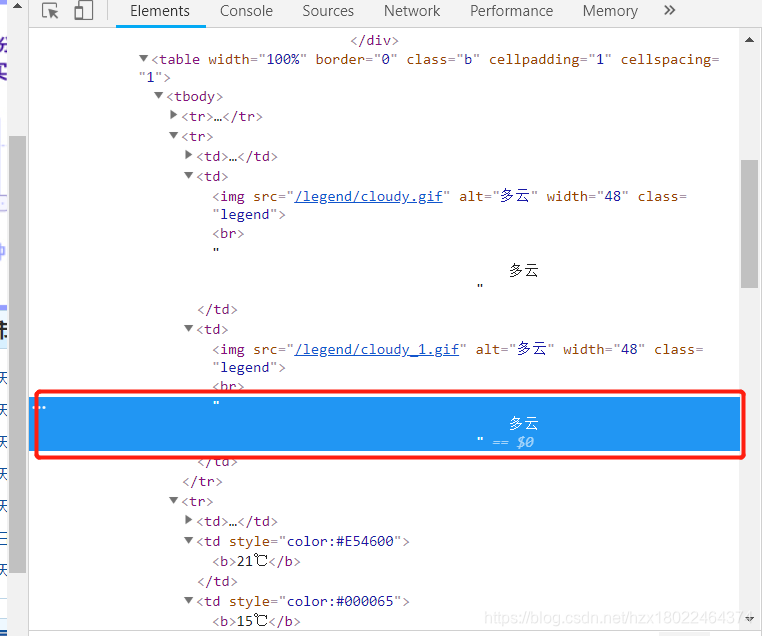
“多云”的文本和正常的文本不大一样,我猜测是空格符,于是用了
response = requests.get(url).content.decode("gbk").replace('\n','').replace('\t','').replace(' ','')企图去除多余的符号。
问题还是出现了,最后分割alt="多云"”,并不能把“多云”分割出来。原因是我去除了空格符但是截出来的文本中出现了“\r”,也就是回车符。
于是修改成
response = requests.get(url).content.decode("gbk").replace('\n','').replace('\t','').replace(' ','').replace('\r','')把回车符也去除掉。分割终于正常了。

















 496
496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









