







简单的Hadoop伪分布式架构

1. 修改主机名(方便区分):# vim /etc/sysconfig/network

2. 编辑:# vim /etc/hosts
3. 最低的要求JDK版本要大于1.7
4. 配置免密登陆:
(1)生成密钥:`# ssh-keygen` 一直回车就行,底层是通过非对称加密来做的
(2)发送密钥: `# ssh-copy-id root@hadoop01`

5. 修改配置文件Hadoop的所有配置文件都存在etc/hadoop下
(1).`# vim hadoop-env.sh`
配置JDK安装路径 `export JAVA_HOME=/usr/local/java/jdk-11.0.2`
配置hadoop的配置文件路径:`export HADOOP_CONF_DIR=/home/software/hadoop-2.7.1/etc/hadoop`
(2).`# vim core-site.xml`
指定namenode服务器的IP地址和通信端口号
<!--指定namenode服务器的ip地址和通信端口-->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop01:9000</value>
</property>
<!--指定namenode存放元数据的目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/software/hadoop-2.7.1/tmp</value>
</property>
</configuration>
(3).配置副本数量:# vim vim hdfs-site.xml
<!--用于配置副本数量-->
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
(4). 配饰存数据块的服务器 # vim slaves

6 最后,进入bin目录,进行格式化hadoop
sh hadoop namenode -format
应看到如下字样则为格式化成功,如果没有,则检查以上配置:

7.接下来进入sbin目录,可以启动hadoop了
有如下图进程则为启动成功
root@hadoop01 sbin]# sh start-dfs.sh
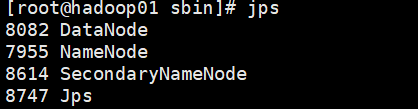
也可以通过访问浏览器验证是否成功:ip+端口(50070)

如果没有启动成功过,可以去指定的log里面查看错误;或者先停止 sh stop-dfs.sh进程,然后删除tmp目录,在进行一次格式化操作,启动之前必须确保格式化成功;然后在进行启动操作;
8 配置指令操作环境变量:
vim /etc/profile
9.配置插件操作文件系统(eclipse)
10 、edits文件
- 当执行格式化指令时,会在制定的tmp目录下,生成dfs/name目录;此目录时namenode存储元数据的目录;
- 当格式化后,启动HFDS之前,会生成一个最初的fsimage文件;
- dfs/data目录下,是datanode节点存储数据块的目录;
- 演数据的存储目录和数据节点的目录路径可以分开指定;
- 在dfs/name/
- 当启动hdfs时,会生成Edits文件;
- hdfs有事务ID的概念,当hdfs没接受一个事务操作(比如mkdir,put,mv等)会分配到响应的事务id,然后写道Edits文件中;
- 每生成一个新的Edits文件,Edits文件中都会以BegingLog开头,当一个Edits文件写完后,会以endlog结尾,即在begin log和endlog中介存储的是Edits文件所有的事务记录;

















 9327
9327











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











