







1.HashMap实现原理
(1)JDK1.7以前
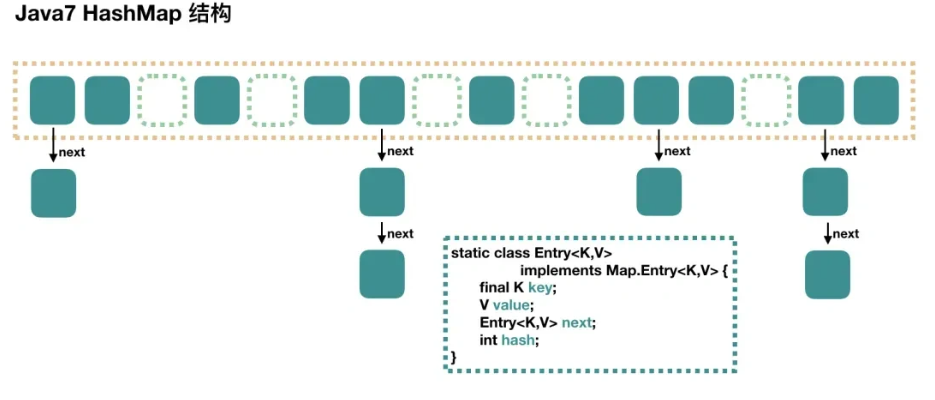
在JDK1.7版本之前,HashMap底层数据结构采用的是
数组+链表的形式当向HashMap中添加数据时,会采用哈希算法,将元素的key映射到底层数组对应的位置,我们称之为槽位(Bucket)
众所周知,
哈希算法对于不同key的计算结果可能相同,所以当不同的key映射到数组上的同一个槽位时,它们就会以链表的形式存储到同一个槽位上由于链表的查询速度时O(n),所以冲突很严重,当一个索引上的链表非常长时,查询效率就会很低
(2)JDK1.7以后
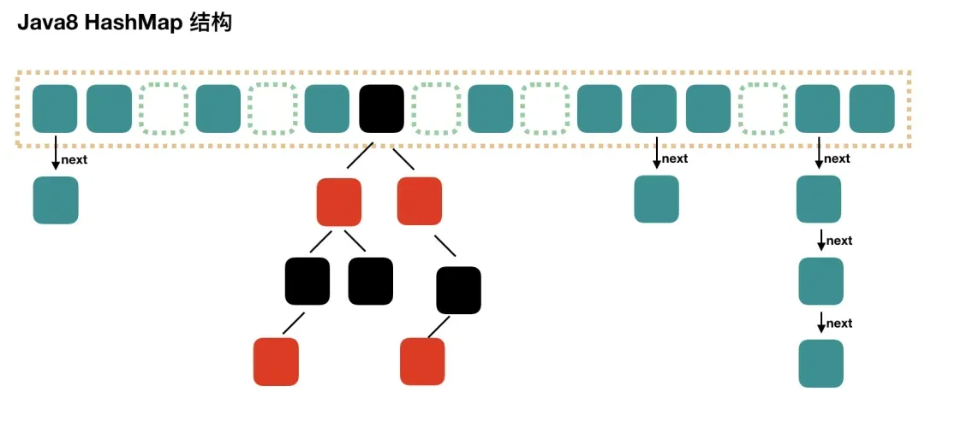
所以在JDK1.8版本的时候做了优化,HashMap采用
数组+链表和数组+红黑树两种方法相结合的方式存储数据当链表长度达到规定的阈值(默认为8)时,会将链表转化为红黑树存储,提高查询效率,时间复杂度降低到O(logn)
同时,在数量小于6时,会将红黑树转化为链表
2.HashMap的put(key,value)方法(JDK1.8版本)
- HashMap采用put(key,val)方法存储对象,调用hashCode()方法计算哈希值,获取对应bucket的位置
- 如果该bucket上没有存放元素,则直接插入
- 如果该bucket上存放着元素,则
比较key值- 如果key值相同,则直接覆盖value
- 如果key值不同,则需要遍历链表或者红黑树来查询是否有相同的key
- 查询到相同的key,则覆盖value
- 查询不到相同的key,对于链表采取尾插法插入数据,对于红黑树则插入到树的末尾
- 存放数据完毕后,检查链表长度是否超过阈值(默认为8)
- 如果链表长度超过阈值,同时
HashMap底层数组的长度超过64,则将链表转化为红黑树,以提高查询效率
- 如果链表长度超过阈值,同时
- 检查负载因子是否超过阈值(默认为0.75)
- 如果超过阈值,则进行
扩容操作(负载因子概念和扩容机制详细看第3大点)
- 如果超过阈值,则进行
- 需要扩容的话完成扩容操作,数据添加到此结束
3.HashMap的扩容机制
(1)负载因子
负载因子是衡量哈希表使用情况的重要指标,定义如下:负载因子 = 数组中存储的元素个数 / 数组大小
负载因子太低会导致大量的空桶浪费空间,负载因子太高会导致大量的碰撞,降低性能
0.75的负载因子在这两个因素之间取得了良好的平衡。
(2)扩容机制
HashMap默认的负载因子为0.75,即如果HashMap中的元素个数超过了总容量的75%,则会触发扩容机制:
- 将哈希表(底层数组)扩大到原来的两倍,创建一个新的数组
- 将旧数组中的数据移到新数组中
4.HashMap在多线程下存在的问题
JDK1.7中的HashMap使用头插法插入元素,在多线程的环境下,扩容的时候有可能导致环形链表的出
现,形成死循环。因此,JDK1.8使用尾插法插入元素,在扩容时会保持链表元素原本的顺序,不会出现
环形链表的问题。
多线程同时执行put操作,如果计算出来的索引位置是相同的,那会造成前一个key被后一个key覆
盖,从而导致元素的丢失。此问题在DK1.7和DK1.8中都存在。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









