







本文是关于正则表达式基础语法的最后一篇文章,关于正则表达式比较特殊的特性,譬如:递归等高级特性依据不同开发环境与编程语言而异。所以笔者不在赘述这些特殊化的性质。
最后将介绍记录正则表达式中的另一语法基础:反向引用与断言。
还记得元字符 \ 有一个作用吗?那就是反向引用。是这样描述的:\n如果该\n之前至少有n个匹配分组并被命名,则\n代表的是“反向引用”。否则\n代表的就是转义字符,参考与ASCII码表。
一、反向引用
反向引用:当一个正则表达式被分组之后,每一个组将自动被赋予一个组号,该组号可以代表该组的表达式。其中组号的编制规则为:从左到右、以分组的左括号“(”为标识,第一个分组的组号为1,第二个分组的组号为2,依此类推。
从这句话中,笔者可以看到,如果要引用某一段正则表达式,则必须将该段表达式用“()”双括号括起来,以便使正则表达式引擎将之分组编号待用。例如:^([0-9A-Fa-f])ccc\1{2}$ 可以匹配0ccc00 acccaa AcccAA 但是不能匹配AcccBB 或者AcccBC 。原因在于:反向引用\n所匹配的字符必须和其引用的部分正则表达式所匹配到字符串一致。
类似与编程语言中,前面定义了一个变量并赋值为X,后面再使用该变量时,其值仍为X 。
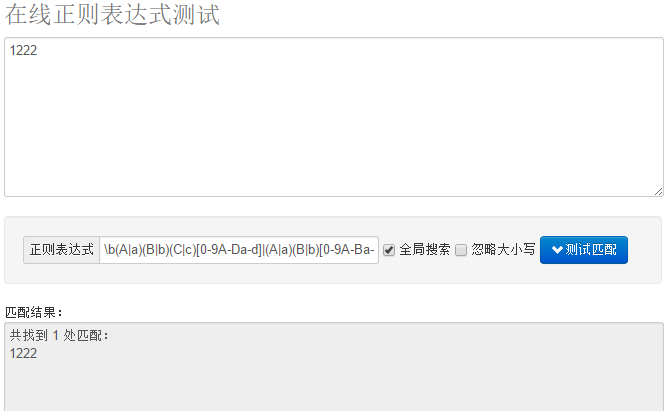
笔者初次在使用引用时,由于没有注意这个引用的特性,导致出现了一个错误。在前面的博文中,提到过十六进制数0-ABCD的正则表达式:
\b(A|a)(B|b)(C|c)[0-9A-Da-d]|(A|a)(B|b)[0-9A-Ba-b][0-9A-Fa-f]|(a|A)[0-9][0-9A-Fa-f]{2}|[1-9][0-9A-Fa-f]{3}|[1-9A-Fa-f][1-9A-Fa-f]{0,2}|0\b
笔者将自己的错误描述一下,希望诸位能够以此为戒。笔者在写完此正则表达式之后,看到表达式段[0-9A-Fa-f]多次出现。所以懂了歪脑筋,将[0-9A-Fa-f]用括号括起来进行了分组编号,认为将之化简了。
\b(A|a)(B|b)(C|c)([0-9A-Da-d])|(A|a)(B|b)[0-9A-Ba-b]\4|(a|A)[0-9]\4{2}|[1-9]\4{3}|[1-9A-Fa-f][1-9A-Fa-f]{0,2}|0\b
此图为未“化简”正则表达式运行之后的结果图:
此图为“化简”之后的正则表达式运行之后的结果图:
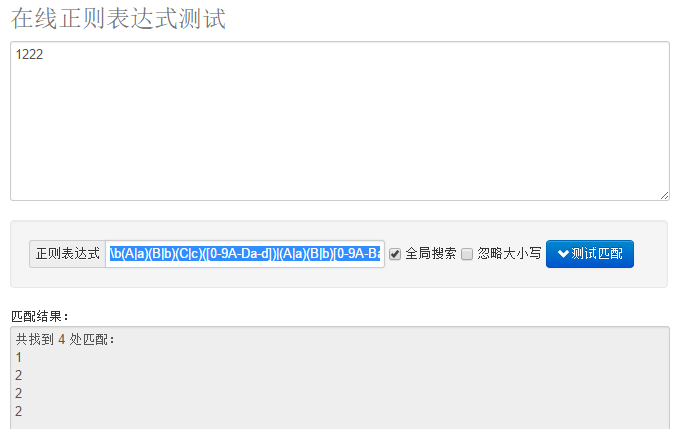
看到了吗?是错哒~为何,笔者试图从运算符优先级的角度进行理解,无奈不能解释的通。但是笔者经过测试实验,得到了一套说法:
在反向引用\n和“或”操作同时使用时,需要注意的是:
1、分组编号依然照旧:从左到右,以左括号为标识依次编号1、2、3……
2、“或”操作将表达式分割开来,导致\n反向引用和分组(experssion)必须位于 | 同一侧。
譬如说:
a(b)(c)|(d)(e)\1 × 不能越界引用,甚至导致逻辑混乱
a(b)(c)|(d)(e)\2 × 不能越界引用,甚至导致逻辑混乱
a(b)(c)|(d)(e)\3 √ 匹配abc或者ded
a(b)(c)|(d)(e)\4 √ 匹配abc或者dee
这部分最后笔者想说的是:(experssion)反向引用是不容易使用的,所以使用的时候一定要慎重。
附:分组形式(?<name>experssion)和反向引用\k<name>的使用道理与(experssion)和\n的使用道理一样。还有一个分组形式(?:experssion)只匹配,但不对其进行编号,所以笔者觉得这是个可有可无的东西,比较愚蠢的还没有发现其巨大的作用。读者如果对此有感想,欢迎留言。谢谢。
二、断言
关于断言,有正预测先行断言和回顾后发断言。笔者一一将其列出来。
(?=experssion) 匹配字符串experssion前面的位置。
(?!experssion) 匹配后面不是experssion的位置。
(?<=experssion) 匹配字符串experssion后面的位置。
(?<!experssion) 匹配前面不是experssion的位置。
(?>experssion) 只匹配字符串experssion一次。(知道现在笔者觉得这个好无厘头啊,只匹配一次需要用这么复 杂的结构吗?)
可能不是很好理解,看几个例子就懂了:

这里的正则表达式abc(?=dddd)中的断言部分相当于“条件”。如同编程语言中的if语句一样,这样解释:如果字符串abc的后面是dddd,则该字符串abc是可以被匹配的。

请注意颜色变化,颜色加深的部分,为匹配出来的。这里正则表达式abc(?!dddd)中的断言部分也是相当与条件。不过是这样解释的:如果字符串abc的后面不是dddd,则该字符串abc是可以被匹配的。
请注意(?!experssion)和(?=experssion)两个断言都是先行断言,也就是说只能放在要匹配的字符串的后面。相对应的,有只能放在要匹配的字符串的前面的断言,叫做后发断言(?<=experssion)和(?<!experssion) 。依然是进行测试:


仍有先行断言与后发断言结合起来,形如:(?<=dddd)abc(?=dddd)这样的双重条件,前后都有要求。再次提醒,断言优先级依然比“或”操作 | 优先级要高,所以断言只影响到位于 | 同侧的字符,读者自行理解。














 223
223











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









