






大家好,小编来为大家解答以下问题,python仿站软件官网,python 仿真模型库,现在让我们一起来看看吧!
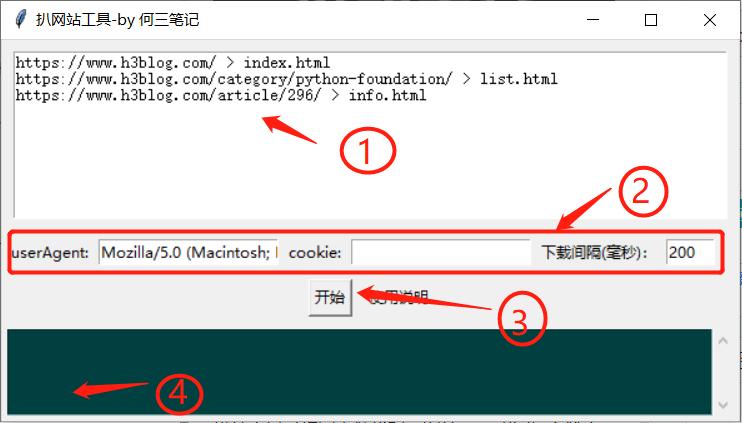
Source code download: 本文相关源码
import requests
import re
import xlrd
import xlwt
import time
from bs4 import BeautifulSoup
myfile=xlwt.Workbook(encoding='utf-8')
#定义excel中sheet,宽度等
table1=myfile.add_sheet(u"百度风云实时热点",cell_overwrite_ok=True)
table1.write(0,0,u"实时热点排行")
table1.col(0).width = 6666
table1.write(0,1,u"搜索指数")
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = { 'User-Agent' : user_agent }
list = []
target='http://top.baidu.com/buzz?b=1&c=513&fr=topbuzz_b11_c513'
req=requests.get(url=target,headers=headers)
req.encoding='gb2312'
html=req.text
class sousuo():
def __init__(self,url,table):
self.url=url
self.table=table
def chaxun(self):
url = self.url
r=requests.get(url,headers=headers)
soup=BeautifulSoup(html)
#获取热搜名称
i=1
for tag in soup.find_all('a',class_='list-title'):
if tag.string is not None:
print (tag.string)
self.table.write(i,0,tag.string)
i+=1
#获取热搜关注数 百度有3中热搜表示方式
j=1
for tag in soup.find_all(class_="icon-rise"):#上升指数
if tag.string is not None:
list.append(tag.string) #使用list数组总结
j+=1
for tag in soup.find_all(class_="icon-fall"):#下降指数
if tag.string is not None:
list.append(tag.string) #使用list数组总结
j+=1
for tag in soup.find_all(class_="icon-fair"):#持平指数
if tag.string is not None:
list.append(tag.string) #使用list数组总结
j+=1
list.sort(reverse=True) #使用sort排序,reverse表示降序
j=1 #从第一行开始写入
k=0 #从数组的第一个元素开始取出数据
for paixu in list:
if list[k] is not None:
self.table.write(j,1,list[k])
j+=1
k+=1
s1=sousuo('http://top.baidu.com/buzz?b=1&fr=topindex',table1)
s1.chaxun()
#print(list[0])
print(list)
filename="baidu-hot-top"+str(time.strftime('%Y%m%d%H%M',time.localtime()))+".xls"
myfile.save(filename)















 1267
1267











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









