







前段时间一直在用易读看天涯社区的连载小说,但是更新得太慢,往往天涯上面晚上更了,易读第二天早上才刷出来。严重怀疑是手动更新的。技痒,决定自己写一个易读网。原理很简单——启动一个线程定时抓取指定帖子的网页文本,通过正则表达式提出出有用的信息,并:(1)存储入数据库备用(2)格式化输出为网页,实现只看楼主的功能。
先用Python写了一个小脚本,实现了抓取网页,正则表达式提取内容和格式化输出的功能,服务器也是使用python自带的服务器。寥寥不到100行。写完后感觉不是很爽,感觉Python也不过如此。遂决定用一直心仪已久的common lisp来重写。
基本环境如下:惠普笔记本+win7操作系统。lisp环境是clisp for windows。
考虑到需要进行web编程,clisp需要一大堆七七八八的库。在这个网址发现了很多好东西:http://weitz.de/ 。一个德国老教授的主页,很多实用的lisp包都在里面。
其中,hunchentoot用来做服务器兼框架,cl-ppcre用来进行正则分析,drakma用来抓取网页内容。
首先按照http://blog.csdn.net/albert_lee/article/details/5953369安装quicklisp这个不错的包管理器。然后将以下这一坨单独整理为一个文件init.lisp,以加载相关的库:
(ql:quickload "hunchentoot")
(ql:quickload "drakma")
(ql:quickload "cl-ppcre")
在接下来的web编程中就能调用这三个包里面的函数了。
现在把生成网页的代码,单独放在getpage.lisp里面。每次用vim修改完代码,使用clisp的命令行重新load一下就行了。
第一步,当然是抓取网页文本。两步搞定:
(setq entry "http://bbs.tianya.cn/post-16-798295-1.shtml")
(setq text (drakma:http-request entry))第一行代码,指定了入口地址。首先我们由简入繁,只分析一个帖子的第一页。entry就是这第一页的url。 drakma:http-request函数只需要一个参数,也就是需抓取的网页的url。返回值就是抓取的内容,现在把它保存进text里面。
接下来,要获取四大信息:各层楼的内容,各层楼的发布时间,各层楼的作者,各层楼的楼号;还有整个帖子的发布作者。参考德国老教授的主页里关于cl-ppcre的文档,跌跌撞撞地使用了正则表达式搞定:
;;匹配各层楼的内容
(setq sections (cl-ppcre:all-matches-as-strings "((?<=div class=\\\"bbs-content\\\">).*(?=</div>)|(?<=div class=\\\"bbs-content clearfix\\\">).*(?=</div>))" text))
;;匹配各层楼的发布时间
(setq times (cl-ppcre:all-matches-as-strings "(?<=replytime=\\\")([^\\\"]+)" text))
;;匹配各层楼的作者
(setq authors (cl-ppcre:all-matches-as-strings "(?<=author=\\\")([^\\\"]+)" text))
;;匹配各层楼
(setq layers (cl-ppcre:all-matches-as-strings "(?<=class=\\\"bbs-layer\\\">)([^<]+)" text))
;;匹配标题
(setq page-title (concatenate 'string
"<BR><CENTER><font face=\"微软雅黑\" size=\"4\">"
(car (cl-ppcre:all-matches-as-strings "(?<=<title>)[^_]*" text))
"</font></CENTER><BR><BR>")) 现在需要这么一个列表,每个列表的元素是一个字符串,每个字符串对应于我们的网站的每一楼。也就是说每个字符串必须包含内容,发言人,发言时间,楼层,必要的html标记等等。而且,最重要的,只能是楼主的发言内容才能出现。
;;将每一段加上字体和段落标记
(setq sections
(let ((index 0) (master (car authors)))
(mapcar #'(lambda(x)
(progn
;;构造段落
(setq x
(if (equal master (nth index authors))
(concatenate 'string
"<BR><CENTER><font face=\"微软雅黑\" size=\"2\" color=\"#333388\">"
(if (equal index 0) "" (nth (- index 1) layers)) " " (nth index times) " " (nth index authors) "</font></CENTER><BR>"
"<div class=\"style1\"><font face=\"微软雅黑\" size=\"2\">" x "</font></div>")
""))
(incf index)
x))
sections)))所有的新元素组成的列表,又一次性地放入sections表里面。这时新的sections表,与旧的sections表长度同样。但内容已经不同了。旧的sections表每个元素对应于每层楼的正文部分,而新的sections表的每个元素则表现为——其要么是上面组合来的一大坨东西(楼主层)以求直接输出为网页,要么是一个“”字符串(非楼主层)以不输出任何东西。
要输出网页,还需要构造“头”和“尾巴”,其中头部还包括了简单的CSS样式表。这里使用了比较粗糙的方法:
;;构造头部
(setq page-head
"<HTML><HEAD><TITLE>第1页</TITLE></HEAD><BODY>
<style>div.style1 {
margin-top:0;
margin-left:200;
margin-right:200;
margin-bottom:0;
padding-top:30;
padding-left:50;
padding-right:50;
padding-bottom:50;
background-color:#eeeeee;
}</style>")
;;构造尾部
(setq page-tail "</BODY></HTML>") (hunchentoot:define-easy-handler (greet :uri "/zhikanlouzhu") ()
(format nil "~{~A~}" `(,page-head ,page-title ,@sections ,page-tail)))
;;启动服务器
(hunchentoot:start (make-instance 'hunchentoot:easy-acceptor :port 8080))现在(1)载入写好的文件:
(2)并通过火狐访问http://localhost:8080/zhikanlouzhu:
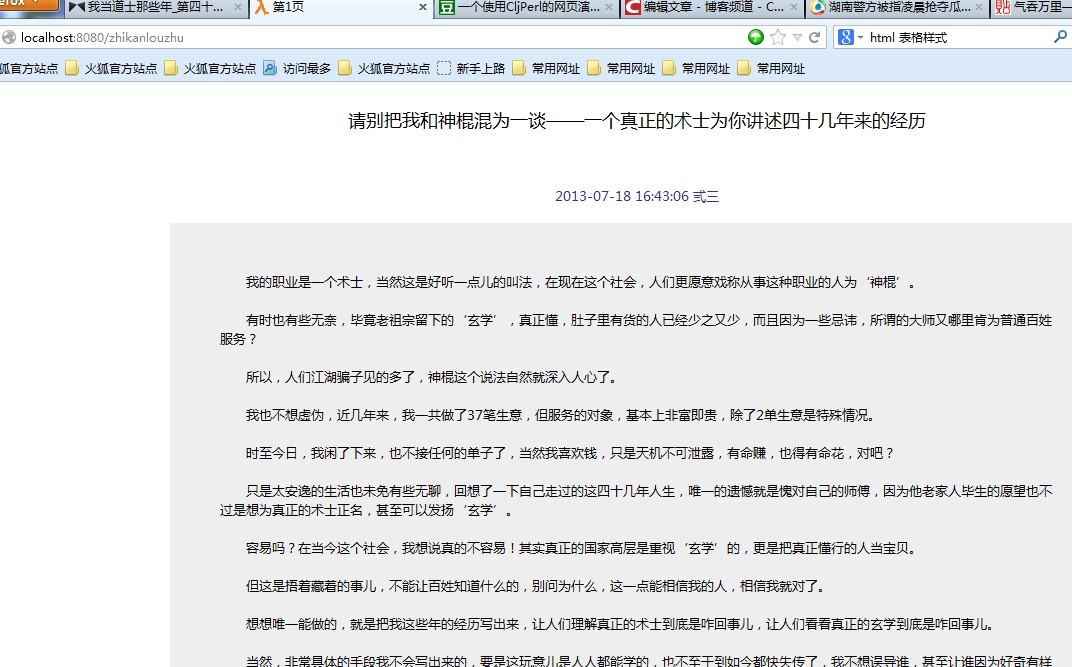
现在可以看到lisp输出的网页了。左上角的λ字样表示这是使用了lisp的东东的服务器在工作~~~~














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









