







文章目录
P5是个分水岭,大家多加小心
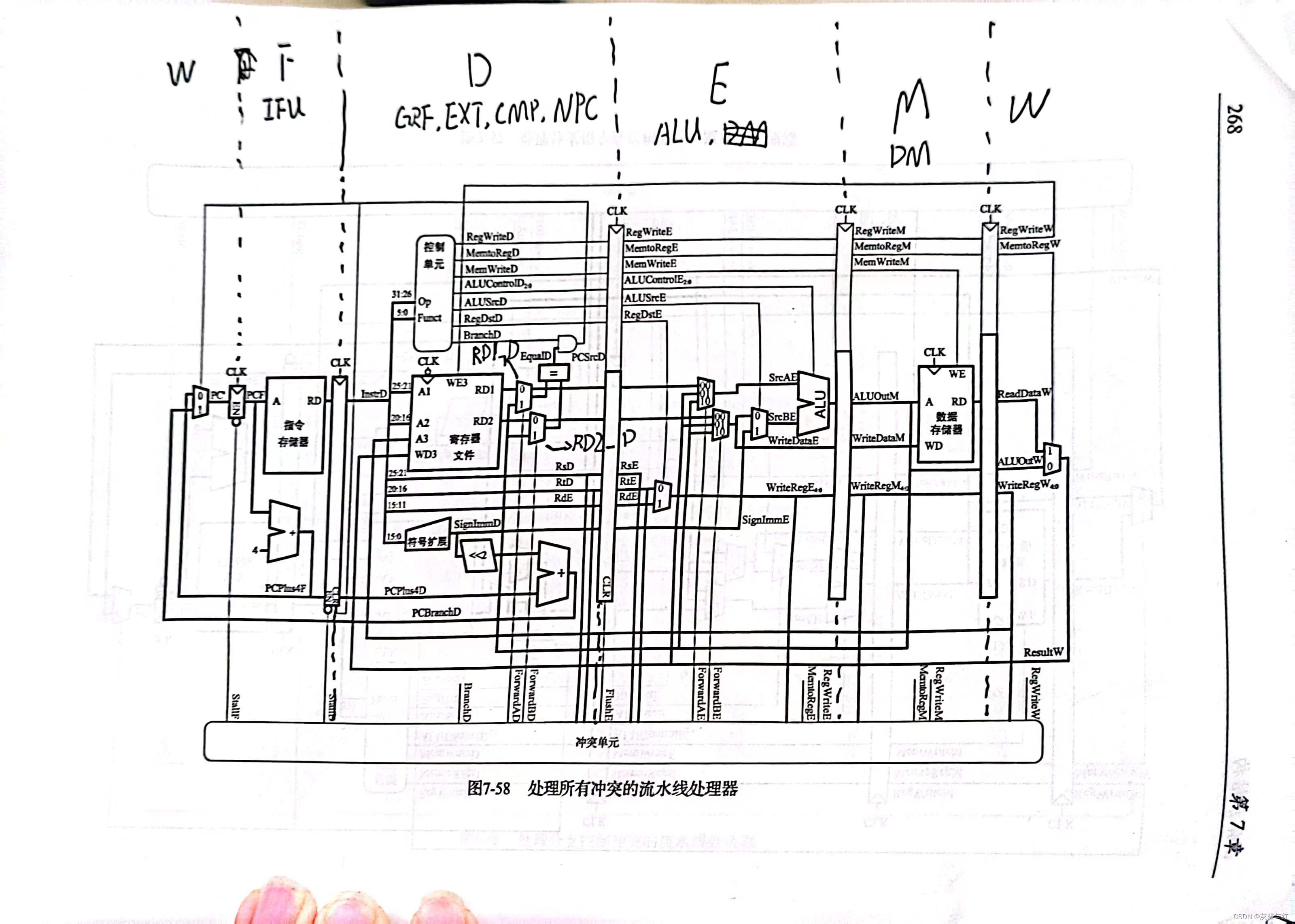
这个图的转发关系有问题!这个图的转发关系有问题!它缺了一些数据通路!!!
但是逻辑关系是正确的。看后面讲解时最好时时比对,建议分屏。
P5感到无从下手是正常的情况,我的建议是在看完理论之后,照着电路说明一步一步做。P5的各个环节是一环扣一环的循环,在任何一个环节都会出现顺着这个循环走更靠后的问题,所以不要想着能走完这个循环,看完理论有个大概理解后直接以力破法先写后思考就行
约定所有信号中reset最优先,如果reset拉高则清空,否则才进行别的逻辑
理论阐释
从流水线开始
阅读完P5教程,是否感到无处下手?这很正常。感到无处下手是因为P5的复杂性让整体统筹非常困难。首先,我们先分析一下P5的理论基础
什么是流水线?这么想,现在有一个生产汽车的工厂,它有五个工作岗位,每个工作岗位负责完成一定的工作,假设第一个岗位负责完成车的骨架,第二个岗位负责加装引擎,第三个岗位负责封装车的外壳,第四个岗位负责喷漆,第五个岗位负责修缮车的内饰。显而易见,每个工作环节所需要的时间不同,因此每个周期等待的时间就是耗时最长的那个时间。那么对每辆车而言,一辆车进入流水线后,需要依次经过五个步骤,最终出流水线;而对整个流水线而言,开动五个周期后,每个环节都有一辆车等待进行当前这个环节的操作,并在进行完这个操作后,所有车都进入下一个环节(或者出流水线)
这就是流水线的基本思想,将“生产一个完整的车”拆分成若干个环节,保证每个时间周期内每个环节都能发挥自己的作用,而不是让所有的环节在一个周期内伺候一辆车,生产完毕后再进入下一个周期,生产下一辆车。
流水线CPU也一样。每个环节都有一个指令等待被处理,每个周期结束后,这条指令都会进入下一个环节(或者出流水线),持续下去。当然,对于一些指令而言可能不需要某几个环节,当它们流水到这个环节的时候就相当于什么也没干的nop。
具体划分成环节,分为F/D/E/M/W五段,我们搭建的也叫做五段全速转发流水线cpu。
| 段 | 功能 |
|---|---|
| F段 | 负责读取指令 |
| D段 | 负责计算NPC、执行跳转的逻辑并读取寄存器文件(DM) |
| E段 | 负责ALU计算 |
| M段 | 负责内存读写 |
| W段 | 负责写寄存器文件 |
冒险:阻塞和转发
P5的核心难点并不在于流水线,而在于冲突。冲突是什么意思呢?
一、数据冲突
刚才的汽车流水线中,某一辆汽车安装引擎并不需要知道它前面的那一辆车内饰是什么配置,但是在流水线CPU中,一切就不一样了。某个指令的执行依赖于前面指令的结果,但前面的指令可能还没到出结果的时候。
比如说,
lw $t1 0($0)
add $t2 $t1 $0
让我们看看会发生什么:
| F | D | E | M | W | |
|---|---|---|---|---|---|
| 指令 | lw | ||||
| 指令 | add | lw | |||
| 指令 | add | lw | |||
| 指令 | add | lw | |||
| 指令 | add | lw |
根据我们刚才的功能表,lw在M段才会进行读取数据的操作,在W段才会进行写寄存器的操作。但是,等到lw到W段的时候,add已经在M段了,而add在E段进行ALU运算并得到结果,也就是说,add得到的E段结果使用的是旧的、没被lw更新的$t1寄存器的值。这显然是不对的
这种情况被称为数据冲突。第一次学到这里的人很容易踏入一个怪圈,数据冲突的种类非常多,很容易把人吓住,想要理清楚所有的可能,但是这是不可能的。先知道什么是数据冲突,然后看解决办法,最后再试着理清可能。
二、控制冒险
什么是控制冒险?试想,按照我们刚才的流水线,如果是
beq $0 $0 end
lui $t1 123
end:
lui $t2 123
会发生什么事情?
(以下讨论先不管end后面的lui指令)
| F | D | E | M | W | |
|---|---|---|---|---|---|
| 指令 | beq | ||||
| 指令 | lui $t1 123 | beq | |||
| 指令 | lui $t1 123 | beq | |||
| 指令 | lui $t1 123 | beq | |||
| 指令 | lui $t1 123 | beq |
根据我们的设置,beq在D段才能判断出来应该跳转,并计算出来相应的NPC。但是这个时候lui $t1 123已经进入流水线了。
怎么办呢?我们约定一个叫延迟槽的东西,即,在流水中跟在分支跳转指令后面的指令,无论是否跳转,都一定执行,不会撤回,称之为延迟槽。
如何实现?不用管,往下看。
三、结构冒险
不用管,跟咱没关系
电路讲解
在开始之前,先申明我的建议。我建议舍弃掉你P4的顶层电路,只借取模块的电路,重新连接顶层电路。
加了什么
总体结构
流水线cpu被划分五段,因此不同的部件也就归在了不同的段之内,不同的段之间的数据流通依靠流水寄存器进行,这会导致一些设计上的转变。
流水线寄存器
流水线寄存器是不同段流水的分界线(对比开头的电路图),它负责承载每个时钟上跳沿将指令和当前段的结果送到下一段中的功能。
从F/D到M/W,一共需要四个流水线寄存器。很不幸,每个寄存器都需要写单独的模块。其中F/D流水寄存器需要额外接受使能信号,D/E寄存器需要额外接受清空信号,这是为之后实现阻塞做准备。不同的寄存器要流水的东西是不一样的。
| 阶段 | 流水的东西 |
|---|---|
| F/D | 流水指令、PC值 |
| D/E | 流水指令、PC值、rs和rt的寄存器读取结果、立即数 |
| E/M | 流水指令、PC、ALU结果、写入数据(写入DM的)、写入寄存器的地址 |
| M/W | 流水指令、PC、DM读取结果、写入寄存器的数据、写入寄存器的地址 |
F/D的使能:F/D需要实现一个使能,就是只有当使能为高(或低,看你的设计,见冲突的实际解决部分–阻塞)时,F/D寄存器才允许正常工作。
D/E段的清除:D/E段除了reset之外还需额外实现一个清除(必须分开哦,不然之后(P7)会有麻烦的),这个清除在P5的表现和reset一样。
为什么要流水PC值?这是为了完成jal指令的写入,在W段供GRF选择究竟要写入哪个数据。注意,因为延迟槽,我们要写入PC+8.
以上就是寄存器的实际内容,每个周期更新一次值即可。可以看出,F/D(不含)以后的流水寄存器流水的东西都是不一定的,需要根据指令类型、转发情况进行选择的。
比较器
为什么需要比较器而不是直接在顶层电路里比较?因为在课上可能会增加新的跳转指令,实现一个比较器有助于降低新增这种指令的难度。
比较器很简单,判断输入的两个数据是否相等,然后输出。但是在P6,新增bne指令后,比较器需要扩展它的逻辑。
冲突处理核心(Core)和冲突计算单元(TCompute)
这个是实现阻塞和转发的部分,具体的阐释见下节冲突的实际解决。
冲突的实际解决(转发和阻塞的实现)
玩原神去了,回来再更喵
回来了,我们那维莱特玩家太有手法了
我们如何解决冲突呢?首先明确一点,想要穷尽数据冲突的种类并加以控制是不现实的。等到P6扩展指令集后,这么做无疑是自寻死路。我们解决冲突只需要两个步骤:识别冲突->进行转发/阻塞。
识别冲突:谨慎转发法(AT法)和懒惰转发法
识别冲突一般有两种方法,教程给的是谨慎转发法,通过确定Tuse和Tnew来确定是否有冲突的存在,以及该如何解决。这两种方法各有优劣,我推荐使用谨慎转发法,理由如下:
- 谨慎转发法是教程给的方法,可以保证之后的测试中输出更贴近标准实现。
- 谨慎转发法缺点在于构建基础困难,代码量大,优点是扩展性极强,根据“苦一苦课下”原则,保证添加指令的简易性是非常重要的。
- 谨慎转发法的理论基础非常显然的正确,而懒惰转发法在部分指令中是“错误的”,需要通过多流水一些控制信号解决。
基于此,我只对懒惰转发法给出一句话概述:懒惰转发法的思想是“先判阻塞,不阻塞则能转就转”,因为早先的错误转发必定会被之后的正确转发抹去。
谨慎转发法的描述教程已经写的比较详细了,我这里只讲具体怎么做:
阻塞处理
那么阻塞该怎么处理呢?课程组的要求是暴力阻塞,即所有阻塞发生在D段。阻塞的实现方式其实前文已经提到了,就是F/D流水寄存器和D/E流水寄存器的两个额外信号。当阻塞发生时,在时钟上跳沿我们清空D/E寄存器,并使F/D寄存器不能更新。想想这么做为什么是对的:当阻塞发生时,我们想要在下个时钟周期种,令E段的指令进入下一级,D段指令不会进入E级,E级成为一个nop空泡。而这么做就能达到这个效果。无需担心空泡会带来什么影响,作为nop,它的各种写使能都应该为0,这样就不会造成什么实质的影响了。
至于如何判断阻塞发生,见下文。
数据链路
为了实现转发,需要新增数据链路。这部分建议时时比对开头的电路图。
数据链路分为接受端和发送端。只有D、E是接收端。只有M、W是发送端。为了方便,建议将M、W段所有可能转发的数据统合成ResultM(或ResultW)。当然,在P5中,M段只有一个需要被转发。
ResultW的计算方式:
always @*
begin
if(LinkLable_ControllerW==1'b1)//jal
ResultW=PCPlus8W_RegM_W;//写入PC+8,这是延迟槽的要求
else
if(MemtoReg_ControllerW==1'b1)//load类
ResultW=ReadDataW_RegM_W;
else
ResultW=ALUResultW_RegM_W;//其他
end
而在接受段,则根据冲突处理核心的输出,判断选择哪一个作为自己的输入。以比较器的输入为例子:
if(Sel_D_EqualIn1_Core==2'b10)
EqulaIn1_CMP_Temp= ALUResultM_RegE_M;//对,这个就是M段要转的那个数据
else
if(Sel_D_EqualIn1_Core==2'b01)
EqulaIn1_CMP_Temp=ResultW;
else
EqulaIn1_CMP_Temp=AD1_GRF;
其他的输入都类似。不确定有哪些输入需要接受转发就去看开头的电路图。开头的电路图缺失了D段的一条接受转发的数据通路。这些控制选择的信号将由下文的冲突处理核心给出。
冲突计算单元(TCompute)
首先,需要一个冲突计算单元来计算Tuse和Tnew的值。它接受D、E、M、W四段的指令,并返回Tuse_rs、Tuse_rt、TnewE、TnewM、TnewW。
| 指令 | Tuse_rs | Tuse_rt | TnewE | TnewM | TnewW |
|---|---|---|---|---|---|
| cal_r | 1 | 1 | 1 | 0 | 0 |
| cal_i | 1 | 3 | 1 | 0 | 0 |
| load | 1 | 3 | 2 | 1 | 0 |
| store | 1 | 1 | 0 | 0 | 0 |
| beq | 0 | 0 | 0 | 0 | 0 |
| jal | 3 | 3 | 2 | 1 | 0 |
| jr | 0 | 3 | 0 | 0 | 0 |
Tuse_rs、Tuse_rt由D段指令给出,TnewE、TnewM、TnewW分别由E、M、W段指令给出
冲突处理核心(Core)
冲突处理核心用于做出阻塞/转发的决定。它接受所有Tuse和Tnew,接受D段的rsrt,E段的rsrtrd,M段、W段的rd并给出接受段的多路选择信号和阻塞信号。
基于AT法的冲突处理核心枯燥而乏味(而且简单)。教程给的实例就足够好了,我举个我的例子:
Stall_rs0_TnewE2 = (Tuse_rs==2'b00) & (TnewE == 2'b10) & (A1D == A3E) & (A1D != 5'd0) & RegWriteE;
枚举所有可能的情况即可。按我举例的写法,一共有8种情况。
重定向也很简单:
Sel_D_EqualIn1=(A1D == A3M && A1D != 5'd0 && TnewM == 2'b00 && RegWriteM == 1'b1) ? 2'b10 :
(A1D == A3W && A1D != 5'd0 && TnewW == 2'b00 && RegWriteW == 1'b1) ? 2'b01 : 2'b00;
改了什么
Controller(看之前先看教程)
分布式译码和集中式译码建议选择分布式译码。先讲为什么,分布式译码的模块电路也是只写一个controller,但是实例化四次,分布在D-W段分别发挥作用。它的好处是
- 增添控制信号容易,因为你添加控制信号只需要修改controller本身和实例化中的接口,不需要修改流水寄存器,让流水寄存器流水新的控制信号
- 扩展性强。采用分布式译码意味着流水寄存器流水的是指令,这在之后的debug中,能直接查看每一段究竟是哪条指令是很有用的,而且也方便之后一些“奇怪”指令的扩展
分布式译码也有缺点,它的缺点是耗费晶体管。不过这和我们仿真的有什么关系呢?
如何做分布式译码呢?
四个译码器的代码都是一样的,输入一个指令,输出对应的控制信号。这和P4很像。区别在于,这四个译码器分散在四段之间,它们的连接关系就是(看开头的电路图)从D-E寄存器开始横亘在相邻的寄存器之间,它的输入来自上一个寄存器的输出指令,它的输出流向这一段内需要控制信号的部件。这就是分布式译码。
NPC
我不清楚大家的NPC怎么做的,但我P4是没有写NPC的。现在NPC设立在D段,接受来自D段的跳转分支相关控制信号,以及接受判断器的判断信号),并计算出来对应的输出。需要注意的是NPC的计算逻辑。还记得之前说控制冒险不用管吗?这是因为既然假定延迟槽存在,那就不用考虑清空的事,直接计算NPC,让延迟槽的下一条指令是跳转后的指令就行了。
if(StartBranch==1'b1)//beq特供,也是以后的bne特供。这个信号是比较器输出和beq控制信号的与。
NextPC={Imm[29:0],2'b00}+PCPlus4D;
else
if(LinkLable==1'b1)//jal特供
begin
NextPC=(PCPlus4D-32'h00000004);
NextPC={NextPC[31:28],instr_index,2'b00};
end
else
if(JrLable==1'b1)//jr特供
begin
NextPC=GPR_rs;
end
else//正常NPC
NextPC=PCPlus4F;
PCPlus4D代表D段指令PC+4,PCPlus4F代表F段指令PC+4.
延迟槽
还记得我们之前说控制冒险不用管吗?事实上,在上一个部分已经实现延迟槽了。因为NPC在D段,所以计算出来下一个PC也是在D段,所以只要我们不管,就已经实现延迟槽了。只是需要注意一点,jal指令要将PC+8写入$31。
未竟内容
本来还想写一些jal和jr的具体实现的,想了想,人生总是需要一点波折,善留其余也未尝不可,我们P6见。
以及,我们那维莱特玩家一只手就能暴杀深渊

















 1384
1384











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











