







hadoop搭建集群
1.生成密钥对(NameNode和DataNode都需要)
[root@sql ~]#ssh-keygen -t rsa -P ''
2.查看密钥对
[root@gg1 ~]# cd .ssh/
[root@gg1 .ssh]# ls
id_rsa id_rsa.pub
3.删除DataNode的密钥对,NameNode的不可以删!!!
[root@gg1 .ssh]# rm -rf id_rsa.pub
[root@gg1 .ssh]# ls
id_rsa
[root@gg1 .ssh]# rm -rf id_rsa
[root@gg1 .ssh]#ls
4.把NameNode的公钥复制给DataNode
[root@sql .ssh]#scp id_rsa.pub root@DataNode虚拟机ip地址:/root/.ssh

5. 读公钥内容复制到密钥库authorized_keys中(系统只能识别authorized_keys) ,再赋权,NameNode和DataNode都需要
[root@gg1 .ssh]# cat id_rsa.pub >> authorized_keys
[root@gg1 .ssh]# ls
authorized_keys id_rsa.pub
[root@gg1 .ssh]# ll
total 8
-rw-r--r--. 1 root root 390 Dec 2 05:35 authorized_keys
-rw-r--r--. 1 root root 390 Dec 2 05:25 id_rsa.pub
[root@gg1 .ssh]# chmod 600 authorized_keys
[root@gg1 .ssh]# ll
total 8
-rw-------. 1 root root 390 Dec 2 05:35 authorized_keys
-rw-r--r--. 1 root root 390 Dec 2 05:25 id_rsa.pub
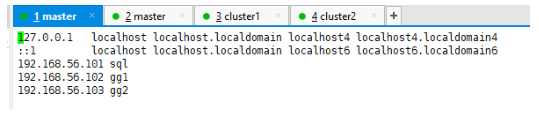
6.在NameNode的hosts文件中,将DataNode的ip地址和他们的hostname进行绑定
[root@sql .ssh]# vi /etc/hosts
7.NameNode连接DataNode,无需密码,第一次需要yes一下
[root@sql .ssh]# ssh gg1
The authenticity of host 'gg1 (192.168.56.102)' can't be established.
ECDSA key fingerprint is b4:ed:3c:3f:23:4f:6b:bf:d3:01:0f:6e:74:cd:eb:72.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'gg1' (ECDSA) to the list of known hosts.
Last login: Mon Dec 2 05:41:04 2019 from 192.168.56.101
[root@gg1 ~]# exit
logout
Connection to gg1 closed.
[root@sql .ssh]# ssh gg2
The authenticity of host 'gg2 (192.168.56.103)' can't be established.
ECDSA key fingerprint is 95:97:5b:45:f3:57:1b:fb:0c:b2:a7:1c:10:1c:dd:ba.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'gg2' (ECDSA) to the list of known hosts.
Last login: Thu Dec 5 20:20:01 2019 from 192.168.56.101
[root@gg2 ~]# exit
logout
Connection to gg2 closed.
[root@sql .ssh]# ssh gg1
Last login: Mon Dec 2 05:53:01 2019 from 192.168.56.101
[root@gg1 ~]# exit
logout
Connection to gg1 closed
8.使用xshell中xftp工具把hadoop安装包上传到虚拟机opt目录下,解压
[root@sql opt]tar -zxvf hadoop-2.6.0-cdh5.14.2.tar.gz
[root@sql opt]# mv hadoop-2.6.0-cdh5.14.2 soft/hadoop260
9.修改配置文件hadoop-env.sh, core-site.xml,
[root@sql opt]# cd soft/hadoop260/
[root@sql hadoop260]# cd etc/hadoop
[root@sql hadoop]# pwd
/opt/soft/hadoop260/etc/hadoop
[root@sql hadoop]# echo $JAVA_HOME
/opt/soft/jdk180
[root@sql hadoop]# vi hadoop-env.sh
文件中修改JAVA_HOME=[具体的jdk路径]
# The java implementation to use.
export JAVA_HOME=/opt/soft/jdk180
[root@sql hadoop260]# mkdir tmp
[root@sql hadoop]# vi core-site.xml
文件末尾在configuration中添加配置如下:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.56.101:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/soft/hadoop260/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
[root@sql hadoop]# vi hdfs-site.xml
文件末尾在configuration中添加配置如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
- 拷贝mapred-site.xml.template 并把后缀名删除,配置mapred-site.xml文件 启动运行框架yarn(resourcemanager,nodemanager)
[root@sql hadoop]# cp mapred-site.xml.template mapred-site.xml
[root@sql hadoop]# vi mapred-site.xml
文件末尾在configuration中添加配置如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
11.yarn-site.xml文件添加配置
[root@sql hadoop]# vi yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.56.101</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- Site specific YARN configuration properties -->
</configuration>
12.在主机中添加hadoop访问站点
[root@sql hadoop]# vi slaves
把localhost改为DataNode的hostname
gg1
gg2
13.拷贝主机中hadoop及其配置文件到DataNode中
[root@sql hadoop]# scp -r /opt/soft/hadoop260/ root@192.168.56.102:/opt/soft/
[root@sql hadoop]# scp -r /opt/soft/hadoop260/ root@192.168.56.103:/opt/soft/
到DataNode中查看是否拷贝成功:
[root@gg1 .ssh]# cd /opt/soft
[root@gg1 soft]# ls
elasticsearch622 elasticsearchhead hadoop260 jdk180 kibana622 node11
-
修改配置文件,并激活(NameNode和DataNode都需要修改激活)
[root@gg1 soft]# vi /etc/profile 在文件末尾jdk配置下再添加下方配置: export HADOOP_HOME=/opt/soft/hadoop260 export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_INSTALL=$HADOOP_HOME 激活: [root@gg soft]# source /etc/profile -
格式化硬盘(在NameNode上)
[root@sql hadoop]# hdfs namenode -format -
启动hadoop
[root@sql hadoop]# start-all.sh出错修改(NameNode和DataNode都需要):
[root@sql soft]#vi hadoop260/etc/hadoop/yarn-site.xml [root@sql soft]# vi hadoop260/etc/hadoop/core-site.xml把这两个配置文件中的ip地址都改为hostname
[root@sql .ssh]# vi /etc/hosts
添加所有的ip地址和hostname
修改秘钥库的权限
[root@sql hadoop]# cd /root/.ssh/
[root@sql .ssh]# ls
id_rsa id_rsa.pub known_hosts
[root@sql .ssh]# cat id_rsa.pub >> authorized_keys
[root@sql .ssh]# chmod 600 authorized_keys
[root@sql .ssh]# ssh sql
修改完重新启动hadoop,输入命令jps查看:
[root@sql hadoop]# jps
1904 NameNode
2245 ResourceManager
2089 SecondaryNameNode
3594 Jps
搭建伪分布式
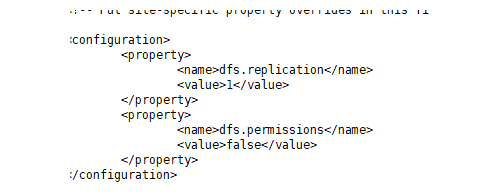
1.修改hdfs_site.xml文件
[root@gg2 hadoop]# vi /opt/soft/hadoop260/etc/hadoop/hdfs-site.xml
value改为1
2.修改slaves文件
[root@sql hadoop]# vi slaves
改为localhost
3.格式化硬盘
[root@sql hadoop]# hdfs namenode -format
4.启动hadoop
[root@sql hadoop]# start-all.sh
5.启动完输入jps命令查看
[root@sql hadoop]# jps
1904 NameNode
4308 Jps
2245 ResourceManager
4182 NodeManager
3864 DataNode
2089 SecondaryNameNode
四、命令代码
[root@sql hadoop]# cd /opt/soft/
[root@sql soft]# vi a.txt
[root@sql soft]# cat a.txt
hello.world
how are you
gugang
[root@sql soft]# ls
a.txt hadoop260 jdk180 node11 tomcat8
[root@sql soft]# hdfs dfs -mkdir -p /data
19/11/28 04:38:18 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[root@sql soft]# hdfs dfs -put a.txt /data/
19/11/28 04:39:36 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[root@sql soft]# hdfs dfs -ls -R /
19/11/28 04:40:32 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
drwxr-xr-x - root supergroup 0 2019-11-28 04:39 /data
-rw-r--r-- 1 root supergroup 31 2019-11-28 04:39 /data/a.txt
网页上看自己创的文件:
192.168.56.101:50070















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









