






iamlaosong文
最近在用SQL实现一个查询功能时接触到了分析函数,如同发现了新大陆,很多功能可以用分析函数轻松搞定,速度还快,真是一个超级牛叉的功能。
先说一下要实现的功能吧,总部下发的结算数据居然有重复,悲催的是他们下发的数据他们不管,让我们财务找出重复的,对于重复的数据,要求保留封发日期最大的那个,封发日期相同的,保留金额最大的那个。总部需要我们将需要删除的数据(不是保留的)报上去以便扣除。这个功能用一般的SQL实现比较麻烦,需要多个子查询,可是用分析函数就简单了,而且一次完成,不需要子查询。下面是查询语句:
select * from (
select t.*, count(*)over(partition by mail_num ) nn,
row_number()over(partition by mail_num order by deal_date,deal_fee) mm
from tb_international_costs t )
where mm<nn and nn>1
其中字段nn是统计每个邮件号码包含的记录数,字段mm则是对记录编号,记录按封发日期和金额排序。查询条件nn>1表示有重复,而mm<nn表示取除最后一条外所有记录。
- 分析函数和聚合函数的不同之处:
分析函数和聚合函数很多是同名的,意思也一样,只是聚合函数用group by分组,每个分组返回一个统计值,而分析函数采用partition by分组,并且每组每行都可以返回一个统计值。简单的说就是聚合函数返回统计结果,分析函数返回明细加统计结果。
- 分析函数带有一个开窗函数over(),包含三个分析子句:
排序(order by)
窗口(rows)
前两个好理解,最后一个窗口则是表示分析函数的作用范围,默认范围是组内所有记录,即:
SUM(SAL) OVER(PARTITION BY E.DEPTNO
ORDER BY E.SAL)
相当于
SUM(SAL) OVER(PARTITION BY E.DEPTNO
ORDER BY E.SAL
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)
- 其它表示范围的写法还有:
第一行至当前行:
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
当前行至最后一行:
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING
当前行的上一行(rownum-1)到当前行:
ROWS BETWEEN 1 PRECEDING AND CURRENT ROW
当前行的上一行(rownum-1)到当前行的下辆行(rownum+2):
ROWS BETWEEN 1 PRECEDING AND 2 FOLLOWING
- 此外,over中条件不同,结果也不同,以sum函数求薪水之和为例,注意over(…)条件的不同:
sum(sal) over (partition by deptno order by ename) 按部门“连续”求总和
sum(sal) over (partition by deptno) 按部门求总和
sum(sal) over (order by deptno,ename) 不按部门“连续”求总和
sum(sal) over () 不按部门,求所有员工总和,效果等同于sum(sal)。
例句:
select deptno,
ename,
sal,
sum(sal) over(partition by deptno order by ename) 部门连续求和, --各部门的薪水"连续"求和
sum(sal) over(partition by deptno) 部门总和, -- 部门统计的总和,同一部门总和不变
100 * round(sal / sum(sal) over(partition by deptno), 4) "部门份额(%)",
sum(sal) over(order by deptno, ename) 连续求和, --所有部门的薪水"连续"求和
sum(sal) over() 总和, -- 此处sum(sal) over () 等同于sum(sal),所有员工的薪水总和
100 * round(sal / sum(sal) over(), 4) "总份额(%)"
from emp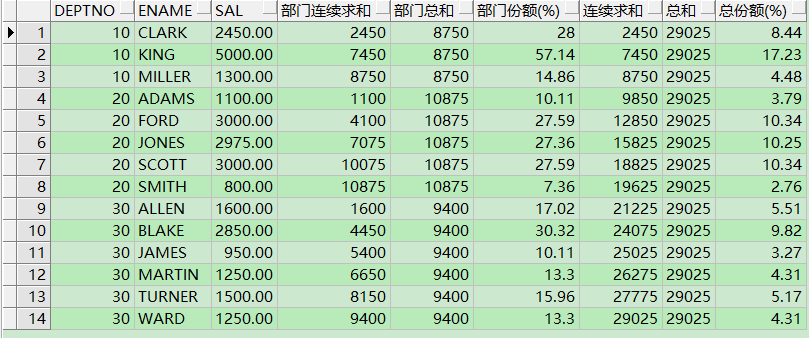
这样的连续求和意义并不大,所以写over中的条件时应按需要决定是否需要order by语句,搞不好变成了画蛇添足了。其他函数也是如此,比如count函数,没有order by是正常的计数,有了order by变成连续计数,其结果和row_number是一样了。例如:
select deptno,
ename,
sal,
count(*) over(partition by deptno order by sal) rowcount,
row_number() over(partition by deptno order by sal) rownumb
from emp;查询结果中rowcount和rownumb内容是相同的。
- 常用的分析函数如下所列:
row_number() over(partition by ... order by ...)
rank() over(partition by ... order by ...)
dense_rank() over(partition by ... order by ...)
count() over(partition by ... order by ...)
max() over(partition by ... order by ...)
min() over(partition by ... order by ...)
sum() over(partition by ... order by ...)
avg() over(partition by ... order by ...)
first_value() over(partition by ... order by ...)
last_value() over(partition by ... order by ...)
lag() over(partition by ... order by ...)
lead() over(partition by ... order by ...)
这些都是分析函数,基本上都是要带参数的,参数可以是字段名,也可以是字段名构成的表达式。
row_number()和rownum差不多,功能更强一点(可以在各个分组内从1开时排序)。
rank()是跳跃排序,有两个第二名时接下来就是第四名(同样是在各个分组内)。
dense_rank()是连续排序,有两个第二名时仍然跟着第三名,相比之下row_number是没有重复值的。
。。。















 4101
4101

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









