






2024年悄然过去一半,回顾行情,大盘五月下跌0.58%,六月跌幅扩大至3.87%,已有五穷六绝之相,七月又当如何?不用想不用猜,各个投资群里,肯定不少人说着同一句朗朗上口的股市谚语,相互取暖,相互打气。
这句谚语就是『五穷六绝七翻身』,不能说大伙儿都耳熟能详吧,肯定都略有耳闻。从字面上的意思就能看出来,说的是股市每逢每年的五月和六月都会出现下跌,到了七月,下跌趋势终止,开始回升走出低谷,打一个漂亮的翻身仗。

真的是这样吗?看回2023年行情,大盘五月下跌3.57%,六月下跌0.08%,七月上涨2.78%,果然应了五穷六绝七翻身之语。再看多一年,2022年,大盘五月大涨4.57%,六月接着大涨6.66%,七月下跌4.28%,恰好跟五穷六绝七翻身是反着来的。
那实际到底是什么样子,请容我刨根问底,细细道来~
目前主流的观点认为,『五穷六绝七翻身』这种说法最早起源于香港股市,在上世纪80年代至90年代的时候港岛特别流行,据说是当时的经济研究员,在参考过历年香港股市的涨跌情况后,统计总结得出的结论。
类似的说法,不单单中国股市有,国外股市也存在,最著名的莫过于美国华尔街流传已久的“Sell in May”(在五月份卖出),但最早的出处却是在英国。完整的句子应该是“Sell in May and go away, come back at St.Leger's Day”,St.Leger's Day指的就是英国每年九月份在南约克郡举行的秋季赛马比赛。所以整句话翻译过来就是说,在五月份的时候大伙儿都卖出清仓离开吧,等到秋季赛马比赛后再回来。

为啥要在五月份离开呢?因为夏天到了太TM热了,要离开伦敦市区去郊外避暑,就跟清朝皇帝一到夏天就跑到承德避暑山庄消夏一样,等到秋天转凉了再屁颠屁颠跑回来。所以嘛,那群英国贵族、银行家和投资家都跑出去避暑了,清仓不玩了,那时候还没现在远程炒股的便利,股市可不就寡淡没有行情嘛,等到他们九月末回来之后,行情才会有起色。后来这句话被投资者们念叨着跨过大西洋,带到了北美大陆,成为了如今华尔街金融人士口口相传的一句谚语。
同样都是五月卖出/下跌,一个来自于香港,一个来自于欧美,那跟咱的大A行情规律吻合吗?今年五月已经跌了0.58%,六月份接力跌了3.87%,真的是又穷又绝,接下来的七月咱能翻身不?
要看咱大A股符不符合“五穷六绝七翻身”这个规律,靠瞎说可不行,要有数据统计结果,邓爷爷教育道“实践是检验真理的唯一标准”,咱就撸起袖子开干。
要总结规律,那数据时间范围当然越长越好,挑来挑去,觉得还是先选择『上证指数』较为合适,它在1991年就发布了(沪深300指数还要14年后才发布),基本跟上交所深交所同龄,数据长度够长,基本全覆盖了A股发展历程,更何况股民日常说的3000点、3200点什么的,指的就是上证指数的点位。首先咱就来获取上证指数的历史行情数据,这里使用的是股票量化开源库qstock,直接使用“pip install qstock”就可以安装,基本的功能无需注册便可以使用,对萌新来说非常方便,详情请见:https://github.com/tkfy920/qstock
import numpy as np
import pandas as pd
import qstock as qs
# 获取1991年6月以来的全部月度数据,并展示最后10条
symbol = '上证指数'
df = qs.get_data(symbol, start='19910601', end='20240628', freq='M').sort_index()
df.tail(10)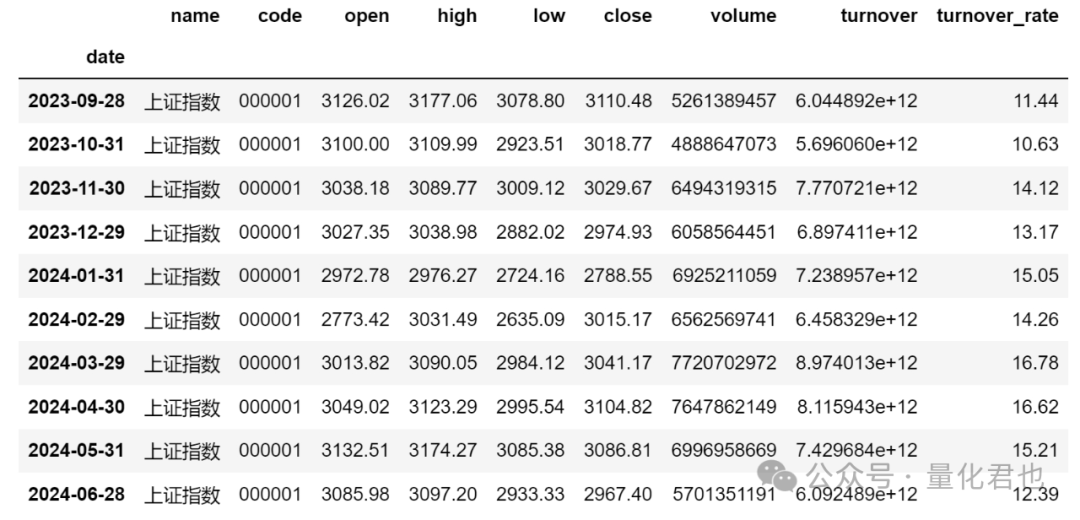
在这里咱就获取了上证指数从1991年6月至2024年6月的全部月度行情数据,结合当月的收盘价和上个月的收盘价(close)就可以计算出当月的涨跌幅(pct),为了方便后续统计,咱还需要将日期索引(date,对应的是每个月最后的交易日)转换为对应的月份数值(month)。
# 计算月度涨跌幅
df['pct'] = 100 * (df['close'] / df['close'].shift(1) - 1.0)
# 将日期转化为月份数值
df['month'] = df.index
df['month'] = df['month'].apply(lambda x: int(x.strftime('%m')))
data = df[['month', 'close', 'pct']].dropna()
# 输出最前的10条数据
data.head(10)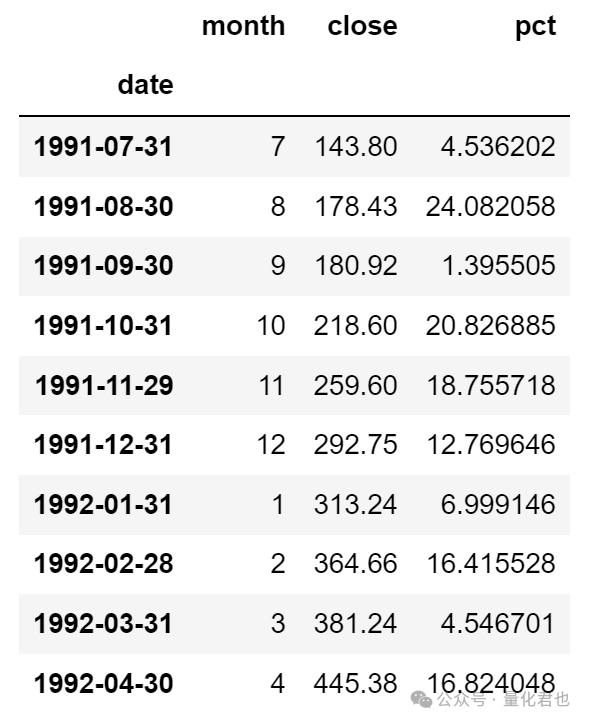
至此,咱就获取到了1991年7月至2024年6月这33年之间每个月的涨跌幅数据,这样的日期范围设置的原因是,平衡每个月份数的分布,保证每个月都出现的次数相同,都是33次。
数据整理完毕后,就可以开始统计了,在这里咱要统计的是每个月的上涨次数(win_num)、下跌次数(lose_num)、胜率(win_rate)、涨跌幅的均值(pct_avg)、涨跌幅的中位数(pct_med)、涨跌幅的最小值(pct_min)和涨跌幅的最大值(pct_max)。
实现的原理是,按月份数值(month)进行循环,分月份进行统计,那每一个月份就有33个涨跌幅(pct)数值,若涨跌幅为正数记为上涨,负数记为下跌,胜率(单位百分比)则为“100*上涨次数/33”,其余的4个指标就分别对应着这33个涨跌幅数值序列当中的均值、中位数、最小值和最大值,具体细节请看下方代码。
stats = pd.DataFrame(np.nan, index=sorted(data['month'].unique().tolist()),
columns=['win_num', 'lose_num', 'win_rate', 'pct_avg', 'pct_med', 'pct_min', 'pct_max'])
stats.index.name = 'month'
for month,clip in data.groupby('month'):
pct_srs = clip['pct']
# 上涨次数
stats.loc[month,'win_num'] = pct_srs[pct_srs>0].shape[0]
# 下跌次数
stats.loc[month,'lose_num'] = pct_srs[pct_srs<0].shape[0]
# 胜率
stats.loc[month,'win_rate'] = 100 * pct_srs[pct_srs>0].shape[0] / pct_srs.shape[0]
# 涨跌幅的均值
stats.loc[month,'pct_avg'] = pct_srs.mean()
# 涨跌幅的中位数
stats.loc[month,'pct_med'] = pct_srs.median()
# 涨跌幅的最小值
stats.loc[month,'pct_min'] = pct_srs.min()
# 涨跌幅的最大值
stats.loc[month,'pct_max'] = pct_srs.max()
stats.to_excel(f'月度涨跌幅数据统计_{symbol}.xlsx') #将统计数据保存为本地Excel文件
stats.round(2) # 为了方便观察,只保留小数点后两位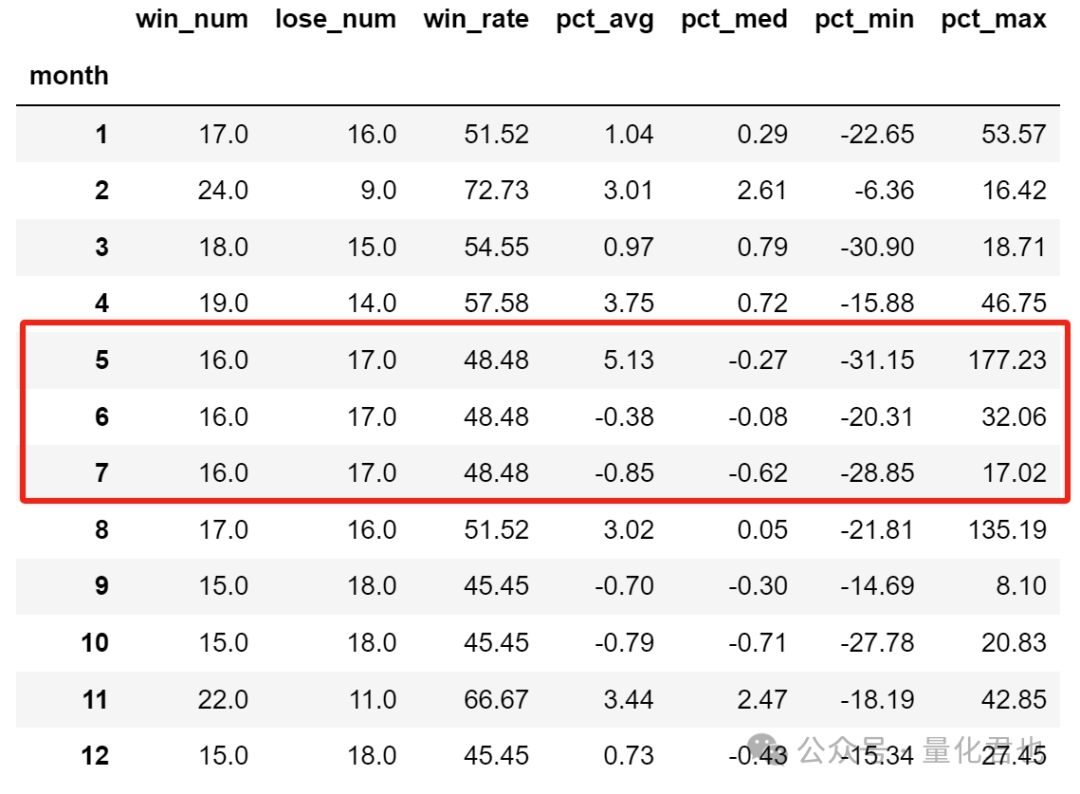
现在统计结果就一目了然了,五六七月份的胜率都是一样的,基本是五五开(48.48%),33年时间里都是上涨16次,下跌17次,再看涨跌幅均值,这3个月份的涨跌幅均值分别为5.13%、-0.38%和-0.85%,而且七月份的涨跌幅均值是一年12个月里面最差的,涨跌幅中位数是第二差。
因此结果显而易见,七月份在胜率方面没有优势,并且涨跌幅均值/中位数,七月份都要比五月份和六月份的差,如果还要坚持说五六月份还是“五穷六绝”的话,那整句话就该改为“五穷六绝七地狱”,地狱还可能是十八层的那种。
为了降低选择代表性指数时的片面性,咱把市场上主流的那几个指数都逐个统计一遍,只要把第一段代码中的变量symbol再分别逐次修改为深证成指、上证50、沪深300、中证500、中证1000、创业板指和中证全指,时间范围也做对应的调整,挨个重新run一遍,就可以统计出相应指数的月份涨跌幅数据,每次的统计结果都会保存为以指数名称为文件名后缀的Excel文件,汇总这些统计文件,就可以看到所有指数的全貌,统计结果如下所示,点击图片可放大查看。
主流指数所有月份胜率数据表:

主流指数所有月份涨跌幅均值数据表:

从胜率表当中看出,五六七月份的总体胜率均值分别是51.36%、51.93%和51.61%,七月份并没有显著优势;五六七月份的总体涨跌幅均值分别是1.93%、-1.09%和1.19%,虽然七月份翻身了一丢丢,但也没有体现出“五穷”的感觉。
综上所述,至少在主流指数概况当中,“五穷六绝七翻身”这种说法并不成立,根本站不住脚,今年的七月翻身仗,翻不翻得了基本是五五开,但从总体涨跌幅均值来看,还是“优势在我”。

论证已经完毕了,但是在过程当中还有两个有趣的发现,也可以顺便说一下,眼尖的小伙伴可能已经发现了。
第一个就是存在着“五穷六绝七翻身”的指数,它就是上证50指数,它五六七月份的胜率分别是42.86%、38.1%和55.0%,涨跌幅均值是-0.88%、-1.65%和1.45%,这样一看,是不是完美契合这句谚语了。
其实吧,只要你把各种市场指数、行业指数、风格指数、概念指数和板块指数统统都统计一遍,肯定能找出不少符合这种规律的指数,只不过占比不高,并不是主流,只要林子足够大,什么鸟儿都会有。
第二个发现其实我已经在上面的表格当中标注出来了,那就是在所有月份当中,二月份的胜率和涨跌幅均值出奇的高,如果还没有感觉的话,咱把它转化为柱状图展示就直观了。
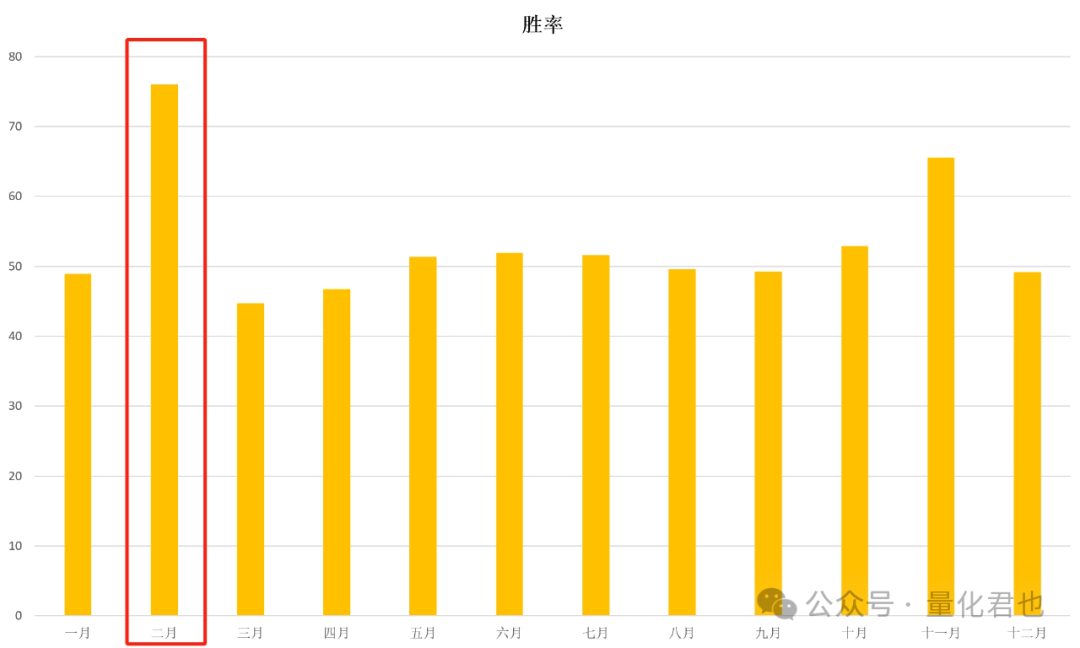
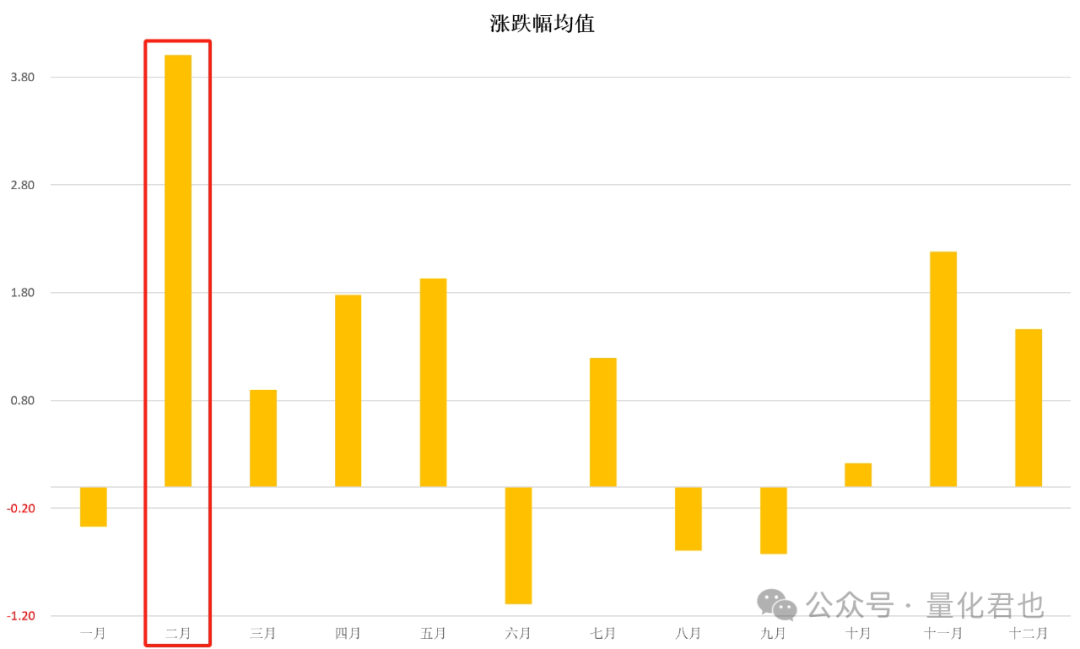
特别是看二月份的涨跌幅均值,简直就是谷子地里窜高粱——硬生生高出一大截来,并且没有任何一个指数的二月份涨跌幅均值出现负数,二月份的胜率均值为76%,也是没有任何一个指数的二月份胜率低于60%。
如果拿枪指着我的脑袋,让我硬是选一个月份翻身,我会毫不犹豫选择二月份,谁会跟概率过不去嘛。
其实上面的这些统计研究,在量化交易或金融工程里面有一个确切的术语,叫做『日历效应』,也就是研究那些与日期存在关联的非正常收益和非正常波动的数据特征现象。
如果大伙儿对我国股市的日历效应感兴趣,特别是想了解清楚本次统计中二月份的胜率和收益为什么这么高,背后的金融逻辑是什么,推荐大家去看国海金工去年出的深度金工研报《日历效应背后的择时策略探究》,在里面作者列举和解释了A股中各种各样与日期节假日相关的Alpha场景,并利用其中的原理构建指数择时和行业轮动策略。
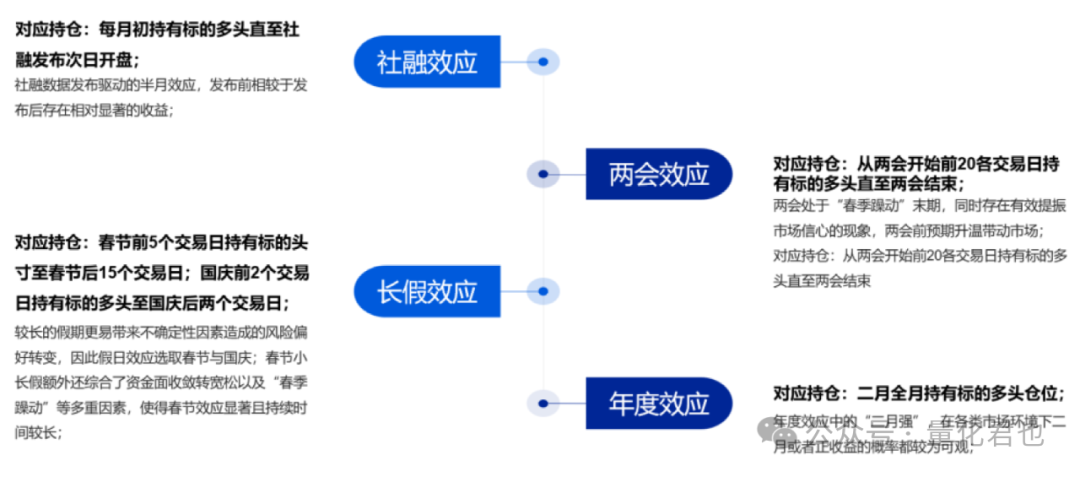
这次就先唠到这儿,噢~对了,差点忘记说,找研报不方便的小伙伴,可在GZH后台回复暗号『日历效应』,就可以直接保存和下载那篇日历效应的研报,如果对你有帮助的话,可以点个充满鼓励的『赞』告诉我,让我动力满满继续肝~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









