







一、HPA(Horizontal Pod Autoscaling水平缩放)介绍
1、背景
弹性伸缩是根据用户的业务需求和策略,自动“调整”其“弹性资源”的管理服务。通过弹
性伸缩功能,用户可设置定时、周期或监控策略,恰到好处地增加或减少“弹性资源”,并完
成实例配置,保证业务平稳健康运行。在实际工作中,我们常常需要做一些扩容缩容操作,如:电商平台在 618 和双十一搞秒
杀活动;由于资源紧张、工作负载降低等都需要对服务实例数进行扩缩容操作。
2、扩缩容种类
1、Node 层面:
对 K8s 物理节点扩容和缩容,根据业务规模实现物理节点自动扩缩容,仅支持云主机。2、Pod 层面:
我们一般会使用Deployment中的replicas参数,设置多个副本集来保证服务的高可用,但是这是一个固定的值,比如我们设置 10 个副本,就会启 10 个 pod 同时 running 来提供服务。如果这个服务平时流量很少的时候,也是 10 个 pod 同时在 running,而流量突然暴增时,又可能出现 10 个 pod 不够用的情况。针对这种情况怎么办?就需要扩容和缩容。
3、通过哪些指标决定扩缩容?
HPA v1 版本可以根据 CPU 使用率来进行自动扩缩容:
但是并非所有的系统都可以仅依靠 CPU 或者 Memory 指标来扩容,对于大多数 Web应用的后端来说,基于每秒的请求数量进行弹性伸缩来处理突发流量会更加的靠谱,所以对于一个自动扩缩容系统来说,我们不能局限于 CPU、Memory 基础监控数据,每秒请求数 RPS 等自定义指标也是十分重要。HPA v2 版本可以根据自定义的指标进行自动扩缩容
注意:hpa v1 只能基于 cpu 做扩容所用,hpa v2 可以基于内存和自定义的指标做扩容和缩容
4、如何采集资源指标?
metrics-server 是一个集群范围内的资源数据集和工具,同样的,metrics-server 也只是显示数据,并不提供数据存储服务,主要关注的是资源度量 API 的实现,比如 CPU、文件描述符、内存、请求延时等指标,metric-server 收集数据给 k8s 集群内使用,如 kubectl,hpa,scheduler 等.
5、如何实现自动扩缩容?
K8s 的 HPA controller 已经实现了一套简单的自动扩缩容逻辑,默认情况下,每 30s 检测一次指标,只要检测到了配置 HPA 的目标值,则会计算出预期的工作负载的副本数,再进行扩缩容操作。同时,为了避免过于频繁的扩缩容,默认在 5min 内没有重新扩缩容的情况下,才会触发扩缩容。 HPA 本身的算法相对比较保守,可能并不适用于很多
场景。例如,一个快速的流量突发场景,如果正处在 5min 内的 HPA 稳定期,这个时候根据 HPA 的策略,会导致无法扩容
二、HPA基于cpu自动扩缩容
1、这是我准备的一个java项目,已经通过Dockerfile打包好发送到harbor仓库
我们来编辑一个k8s.yaml文件,最主要是定义好cpu和memory限制,pod中需要有resource和limits字段,否则hpa会采集不到内存指标
apiVersion: apps/v1
kind: Deployment
metadata:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: website
name: website
namespace: xxxxx
spec:
replicas: 1
selector:
matchLabels:
app: website
template:
metadata:
creationTimestamp: null
labels:
app: website
spec:
imagePullSecrets:
- name: dockerhub
containers:
- name: website
image: xxxxx/xxxxx:v1
resources:
requests:
cpu: 0.1
memory: 50Mi
limits:
cpu: 0.2
memory: 1000Mi
ports:
- containerPort: 8888
name: website
---
apiVersion: v1
kind: Service
metadata:
name: website
namespace: xxxxx
spec:
type: NodePort
selector:
app: website
ports:
- nodePort: 888
port: 8888
protocol: TCP
targetPort: 8888
sessionAffinity: None
type: NodePort2、应用k8s.yaml,并创建HPA,我设置的副本数为1,

--cpu-percent=50:表示cpu使用率不超过10%
--min:最少一个pod
--max:最多10个pod
kubectl autoscale deployment website --cpu-percent=10 --min=1 --max=10 -n mark3、通过kubectl get hpa -n mark查看HPA状态
这里要注意k8s必须要安装metrics-server组件,否则TARGFTS会显示<unknown>/10%

4、通过加压工具ab对pod进行加压测试
ab -c 20 -n 10000 http://192.168.31.231:8888/help-c 20 -n 10000 代表并发数20,进行10000次请求
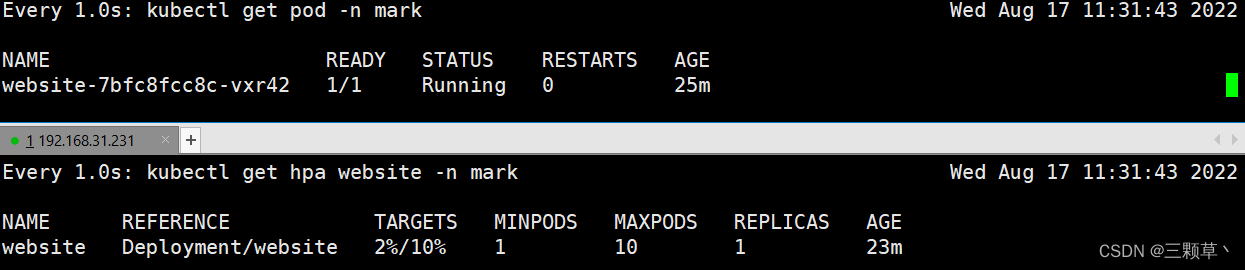
5、查看HPA和pod状态
可以看到加压后因为CPU超过限制,HPA 自动创建了10个pod来应对,当CPU利用率下来后,会自动缩减pod
加压前:

加压后:

5分钟后,当HPA检测CPU正常会告知deployment缩减pod
三、HPA基于内存自动扩缩容
1、通过编写yaml资源清单文件创建内存hpa
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: website-hpa
namespace: mark
spec:
maxReplicas: 10 # 最大副本数
minReplicas: 1 # 最小副本数
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment # 关联需要绑定的deployment
name: website
metrics:
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 60 # 不能超过60%的使用率2、应用hpa后内存使用率已经超过限制deployment自动扩展pod
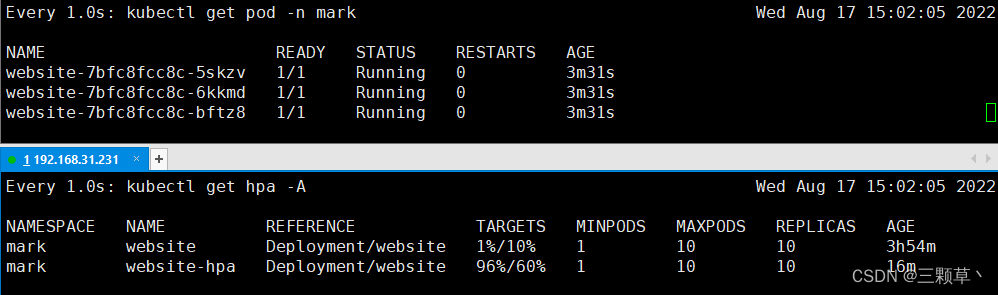
















 6944
6944











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











