






《Stable Diffusion 2025高清生成指南》将彻底解决您的画质困扰。本教程从底层原理出发,深度解析高清图像生成机制,并提供经过商业项目验证的参数优化方案。针对"细节缺失"、“边缘模糊”、"分辨率不足"等核心问题。
1. Mj与SD在生成高清图片上的差别
首先我们来看一下Mj和SD在生成高清图片上的一些差别。
- Mj:默认生成的图像,单张图就是1024x1024,单张图就是1M像素的图片。Mj本身不提供更大分辨率放大的功能。
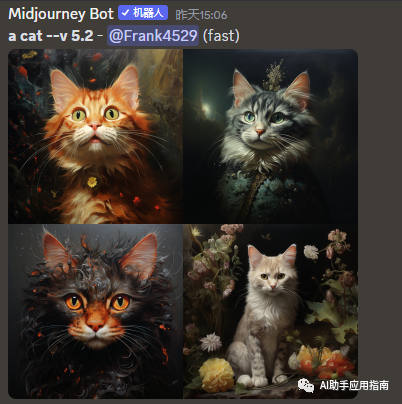
Mj:默认生成4张1024x1024子图
- SD:基础模型默认生成的图片都是512x512,画面幅度明显偏小。但是提供了更高清图片的增强功能。
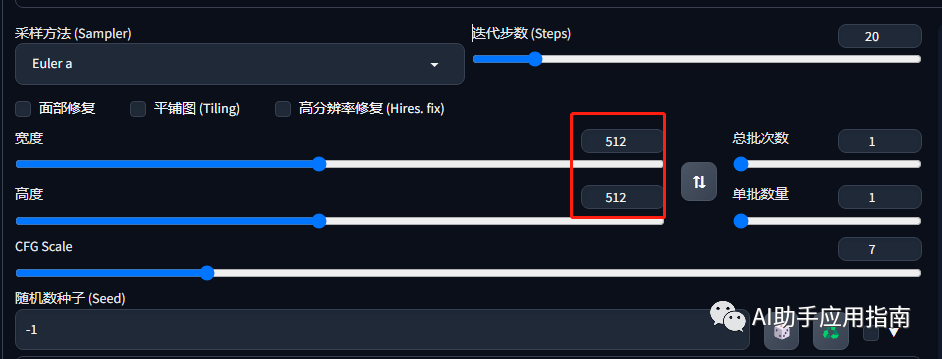
SD:默认512x512,子图数量可设置
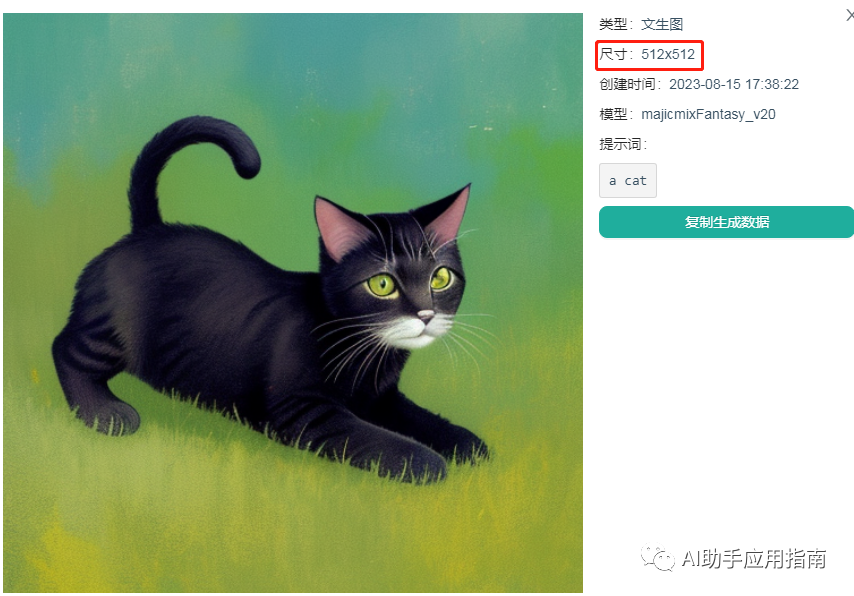
SD:图片效果
512x512的像素,在我们日常使用中,属于非常低清晰度的画面、完全无法展示出清晰的细节,发朋友圈都不够用,更不用说业务上使用。因此图片的放大增强,是非常必要的操作。
2、SD中直接设置高分辨率的绘图问题
在SD中直接设置高分辨率的绘图会出现一系列的问题。这是一个SD特有的问题,其实关键的原因就在于它默认的模型是适配于512x512
的图片大小的,按照这样的一个尺寸来训练的。
那在这种情况下我们直接要求它生成一个1024x1024,甚至2048x2048的图像,一方面会带来一个非常大的GPU计算资源的压力
,另外一方面由于画面设置的过大,对原来的模型来说,它可能会认为你这个画面对应的是多张图片 ,它会拥有类似于拼接或者生成多个物体的方式来进行绘制。
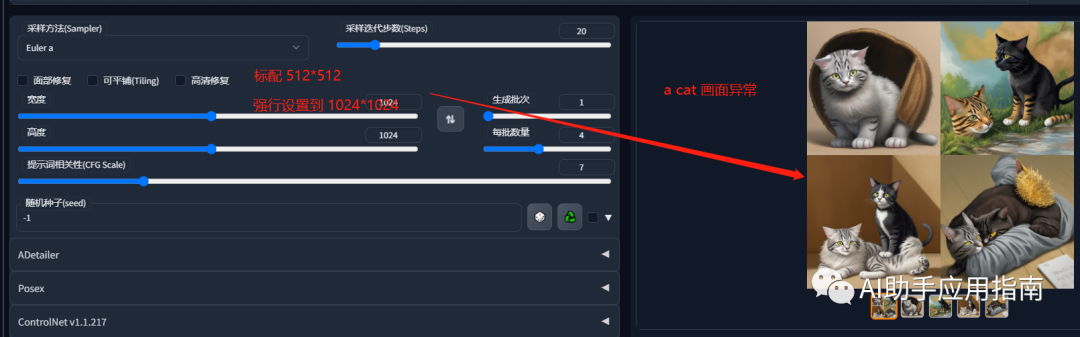
具体来看,绘制的图片出现了严重的缺陷:
-
图2:一只猫双尾巴,一只猫没身体只露头
-
图3:两只猫(绘图要求是
a cat) -
图4:双头猫

要解决这个问题,我们就需要用到一个关键技巧——高清修复 。
3. 高清修复功能:小图定轮廓,大图出高清
设置方式
高清修复(Highres-fix) ——这个技术看起来是比较复杂,但是其实逻辑很简单。
在它绘制的过程中,实际上分了两步:
-
第一步,按照一个小图来绘制,比如512x512。
-
第二步,将小图按照一定的倍数放大成一个大图,比如说我们将放大倍数设置为2 ,它就可以将512的图放大到1024。(设置方式也可以是直接指定尺寸)
值得注意的是,【放大】的过程,实际上是【重绘】的操作,但是在这个过程中,它会尽可能的遵循原来图像画面,然后通过重绘的技术,将在更大的像素上,把我们画制出更加清晰的细节。
基本的设定非常简单:
-
高清修复 :需要开启√
-
重绘幅度 :也就是参考小图 画面的程度,经验值03~0.7之间是较为稳妥的参数
-
放大倍率 :取决于最终想要的输出质量,比如,从512到1024对应的放大比例是2。经验:最终出图尺寸,避免超过2k x 2,放大幅度过大,画面可能出现变形。
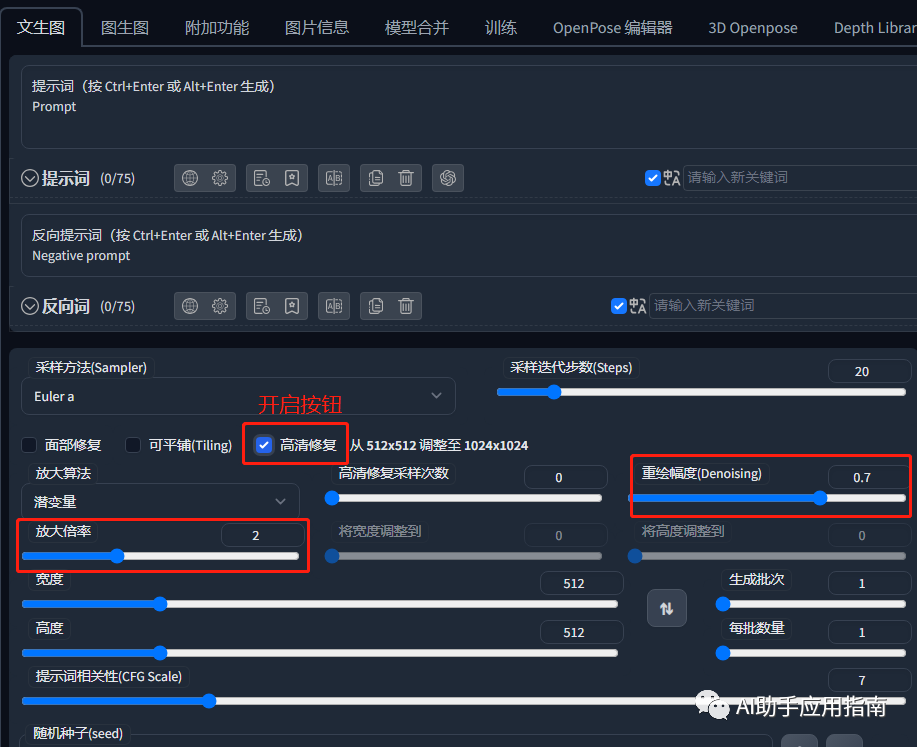
SD文生图:高清修复
关于放大算法
,这一块其实我们可以不用投入太多的精力,因为我看了很多网上教程,不动设置哪一种,基本上都可以得到一个比较好的结果,按系统的默认设置 即可。
放大算法选项
3. 实操效果
2倍放大
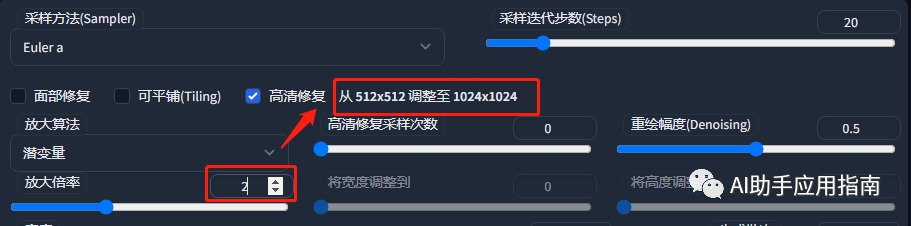
看整体,放大后的图像,猫脖子处毛发有明显变化。

看局部,放大后的图片,猫脸细节纹理明显更加细腻:

3倍放大
看整体:3倍放大后,图像有一些明显的变异,猫鼻子、耳朵、眼睛变红,整体脸型变得突出。

看细节:大图上,猫眼的细节神态非常清晰,炯炯有神。

4倍放大
计算资源受限,GPU爆显存:
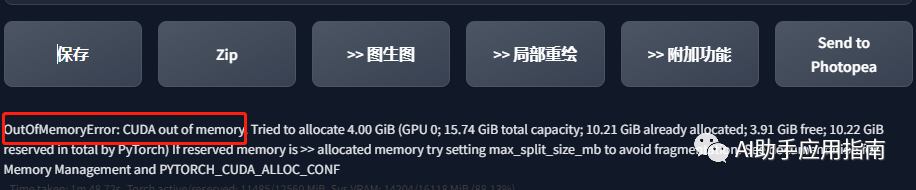
报错的含义是:OutOfMemoryError:CUDA内存不足。尝试分配4.00 GiB(GPU 0;总容量15.74 GiB;已分配10.21
GiB;剩余3.91 GiB;PyTorch总共保留了10.22
GiB)如果保留的内存远大于分配的内存,请尝试设置max_split_size_mb以避免碎片化。
工作流小结
从爆显存 的例子可以看出,AI绘图对计算资源消耗很大,即使硬件可以承担,更大的画面要求也意味着更长等待时间。
比较高效的工作流思路是:
第一步:用小图快速迭代
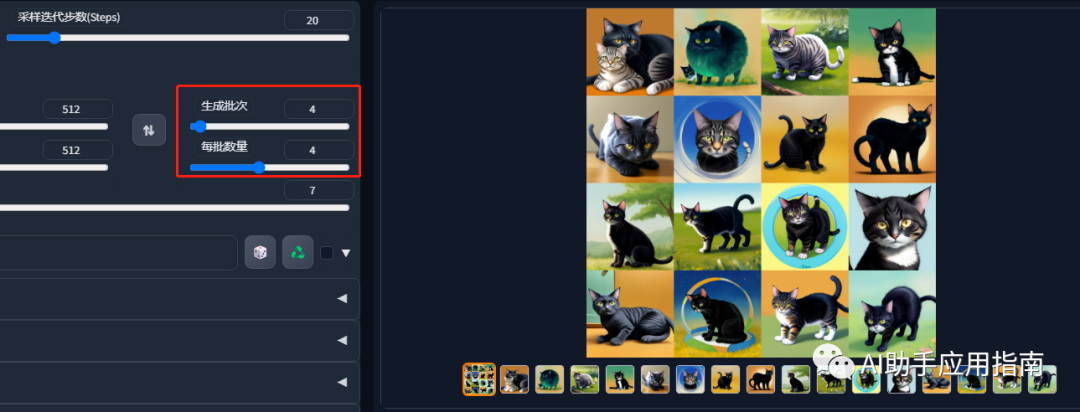
先用小图(512x512)开始绘制,快速迭代多个版本,在生成的系列图中,找到画面布置符合要求的。这是一个海选的过程。
设置批次数量,可以一次生成大量的底图,供筛选:4x4,就是一次输出16个效果。
第二步:放大生成高清
文章使用的AI工具SD整合包、各种模型插件、提示词、AI人工智能学习资料都已经打包好放在网盘中了,无需自行查找,有需要的小伙伴文末扫码自行获取。
3e078ab2dc68c8728d78e9a1901e18b.png)
第二步:放大生成高清
文章使用的AI工具SD整合包、各种模型插件、提示词、AI人工智能学习资料都已经打包好放在网盘中了,无需自行查找,有需要的小伙伴文末扫码自行获取。
这是一位SD资深大神整理的,100款Stable Diffusion超实用插件,涵盖目前几乎所有的,主流插件需求。
这份完整版的SD整合包已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

全文超过4000字。
我把它们整理成更适合大家下载安装的【压缩包】,无需梯子,并根据具体的内容,拆解成一二级目录,以方便大家查阅使用。
单单排版就差不多花费1个小时。
希望能让大家在使用Stable Diffusion工具时,可以更好、更快的获得自己想要的答案,以上。
如果感觉有用,帮忙点个支持,谢谢了。
想要原版100款插件整合包的小伙伴,可以来点击下方插件直接免费获取
100款Stable Diffusion插件:
面部&手部修复插件:After Detailer
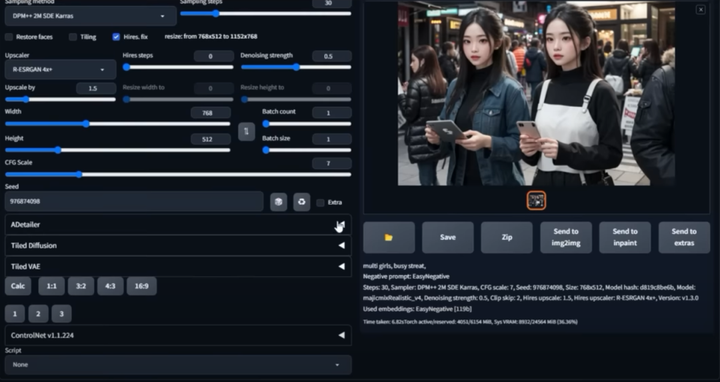
在我们出图的时候,最头疼的就是出的图哪有满意,就是手部经常崩坏。只要放到 ControlNet 里面再修复。
现在我们只需要在出图的时候启动 Adetailer 就可以很大程度上修复脸部和手部的崩坏问题
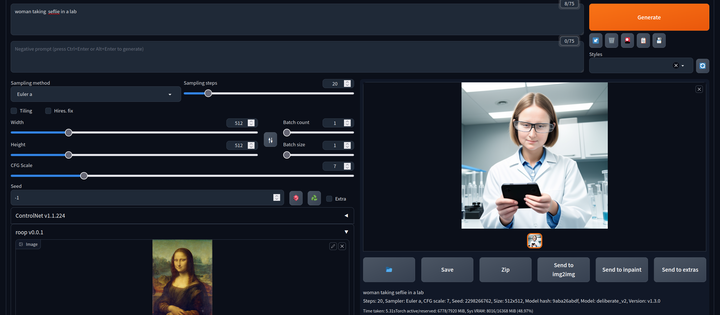
AI换脸插件:sd-webui-roop
换脸插件,只需要提供一张照片,就可以将一张脸替换到另一个人物上,这在娱乐和创作中非常受欢迎。
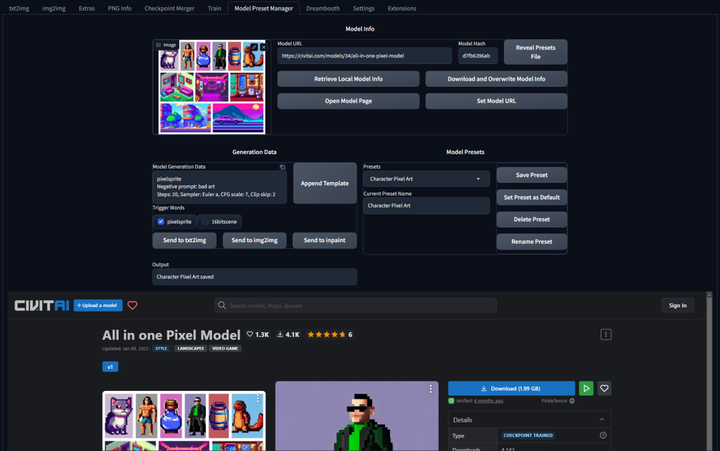
模型预设管理器:Model Preset Manager
这个插件可以轻松的创建、组织和共享模型预设。有了这个功能,就不再需要记住每个模型的最佳 cfg_scale、实现卡通或现实风格的特定触发词,或者为特定图像类型产生令人印象深刻的结果的设置!
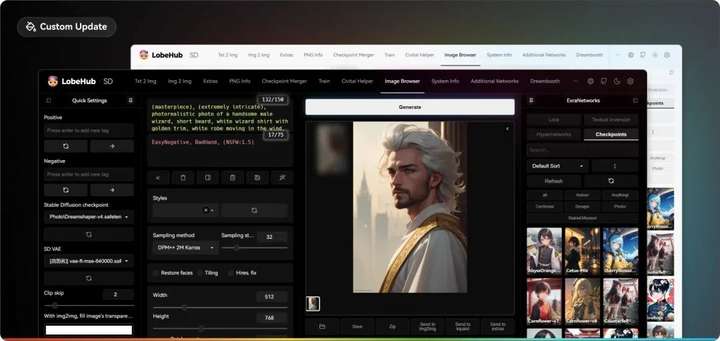
现代主题:Lobe Theme
已经被赞爆的现代化 Web UI 主题。相比传统的 Web UI 体验性大大加强。
提示词自动补齐插件:Tag Complete
使用这个插件可以直接输入中文,调取对应的英文提示词。并且能够根据未写完的英文提示词提供补全选项,在键盘上按↓箭头选择,按 enter 键选中

提示词翻译插件:sd-webui-bilingual-localization
这个插件提供双语翻译功能,使得界面可以支持两种语言,对于双语用户来说是一个很有用的功能。
提示词库:sd-webui-oldsix-prompt
提供提示词功能,可能帮助用户更好地指导图像生成的方向。
上千个提示词,无需英文基础快速输入提示词,该词库还在不断更新。
以后再也不担心英文写出不卡住思路了!
这份完整版的SD整合包已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









