







1.整型以什么样的形式存储到内存中
1.1 整型的种类
通常在C语言中,我们认为的整型类型有short,int,long,long long4种,其实还应该加上char类型,因为char在存取的时候任然是使用整型的方式,以ASCII值得形式进行存储的,故而char类型本质上也是整型类型中的一种,只不过它得值可以以固定的字符形式呈现,在ASCII中规定了char类型从0~127值的字符形式,因此char通常的应用范围也在0~127之间,但是char类型占1字节的空间,无论是有符号还是无符号,char理论上可以表示256个不同字符。
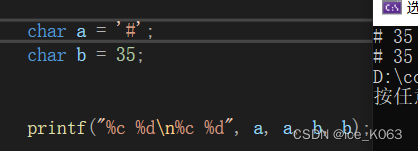
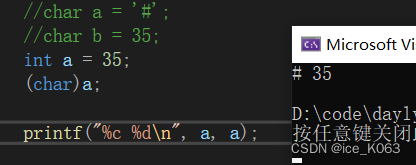
以上两段代码充分说明了,char是按照整型的方式进行存储的,char本质上也是整型,只不过char只能使用1个字节的空间,比short还要小。
1.2 整型的存取
那整型到底以何种方式存储到内存当中呢?
我们都知道数据是以二进制的形式存储到计算机存储器里面的,也就是0和1,既然都是0和1那怎么去区分每一个值呢?
就比如:101010111101010111010101011101010001000001110100000101这样一段源码,假如没有一定的存取方式,它就代表无数种组合的可能。(这也让我想起了黑客帝国里面跳出程序的人读代码的方式,他们就是在那里看0和1的源码,本质上这是根本不可行的,靠人脑绝对做不到,只要稍微改变一下数据类型,或者存取的方式,得到的信息就是驴头不对马嘴,根本不可能正确。)
这里,就不得不提到存储空间的概念。1字节等于8bit,每个bit对应一个二进制位。char占1个字节,short占2个字节,int占4个字节......每个数据之间再以某个大小的间隔(视编译器决定)分开,这样就对01组成的源码进行了读取规范,我们就能保证编译器存取数据的时候按照某种规范去存取,从而获得有效信息。否则,面对01组成的各种排列组合,没有规范的话,信息根本就无法传递,这就是密码学或者说数据学的魔力。
有了这种理念,就不难理解整型的存取了。
整型数据又分为有符号的整型signed和无符号的整型unsigned。有符号的整型二进制最高位表示符号位,1表示负数,0表示正数。无符号整型所有二进制位表示的值就是它本身。
整型数据再内存中存储的是它的二进制补码。正数的源码、反码、补码相同。负数的补码等于源码按二进制位取反加1。
例如int 的1 和 -1 在内存中的存储分别为:
00000000 00000000 00000000 00000001 ——> 1的源码、反码、补码
10000000 00000000 00000000 00000001——> -1的源码 11111111 111111111 111111111 111111110——> -1的反码 11111111 111111111 111111111 111111111——> -1的补码
在进行数据运算的时候就是用补码进行的,例如1 + -1得到一个33位的二进制补码 1 00000000 00000000 00000000 00000000,而一个int类型存不下33位,多出来的最高位就被截断了,故只余下00000000 00000000 00000000 00000000,其值为0,符合运算的逻辑。而在计算机中只有加法器,补码的形式转换了减法运算为加法。最终再输出数据的时候,负数的补码转源码同样可以通过取反加1得到源码,而不必逆运算。
11111111 111111111 111111111 111111111——> -1的补码 10000000 00000000 00000000 00000000——> -1补码取反 10000000 00000000 00000000 00000001—— > -1补码取反加1 结果为 -1
这样巧妙的利用二进制特性把复杂逻辑变成单调数学问题,不得不感叹创造者的智慧。
2. 编译器扮演的角色
其实数据的存取我们都是委托编译器去完成的,再写代码的时候我们人只是把我们的想法告诉了编译器,我们需要实现什么样的功能,编译器才是去指挥操控硬件完成任务的指挥者。所以很大程度上一个程序员的得分,取决于在什么样的程度上把握住编译器。
就比如上面1 + -1这个运算,补码运算过后,得到1 00000000 00000000 00000000 00000000编译器就主动把多出来的最高位1给截断了。
同样的,当我们把一个较大的整型放到一个较小的整型时,就会发生截断。
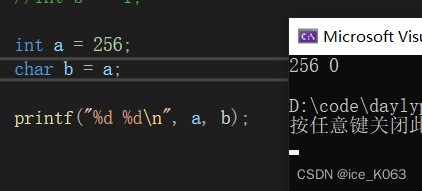
int a 有32位:00000000 00000000 00000001 00000000,而char b只能放下8位,于是编译器把a的低位的8位放到b里面得到0。
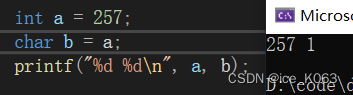
上面结果印证了我们的想法。
3. 总结
在了解整型数据的存取后,在进行程序设计之时,应当充分了解当前编译器的特性,其次,对我们程序数据的取值需求应该做充分的考虑,选取适当的数据类型,从而避免程序bug。
对数据的边界应该做到充分了解,对可能越界的数据要提前做好防范,以防止数据发生不可逆的改变。















 904
904











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









