







环境:见上一篇博客
这次以http://beautyimg001.lofter.com/该用户的图片为例,如有侵权,请及时联系我。
上次我们能够爬下单独网页上面的图片,以这个为基础,我们准备爬取他主页里的所有图片。(有点不厚道~~~~)
工具,这次用了selenium包里的webdriver。具体介绍大家可以去找一下,主要功能能模拟我们点击网页上的按钮。话不多说上码
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
import os
import random
import re
import time
chromepath = os.path.abspath("/Users/xxxx/Downloads/chromedriver")#使用selenium时注意要下载浏览器驱动,把他的路径写对。
headers = {
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)',
# 'Referer': 'http://www.lofter.com'
}
def get_img_url(url):
response = requests.get(url,headers=headers)
soup = BeautifulSoup(response.text,'html.parser')
title = soup.title.string
img_list = soup.select('img')
print(img_list)
src = [i.get('src') for i in img_list]
return src,title
def get_img(src,title):
index = 0
for i in src:
current_time = time.time()
random_tag = random.randint(0,200)
finnal_tag = str(current_time)[6:-7]+ str(random_tag)#主要是防止每次调用get_img()时,会把同一个title的照片给重写了,每个图片名字打个独一无二的名字
res = requests.get(i,headers= headers)
f = open("/Users/xxxx/Desktop/craw/images/" + title + finnal_tag + "%d.jpg" % index,'wb')#注意这里路径要写对
f.write(res.content)
f.close()
index += 1
return 0
def get_type2_user_all_url_list(base_url,page):#这里是最关键的,叫type2是因为LOFTER上面,每个人的主页格式不同,这个适合上文提到的那个人的主页类型
all_page_url_list = []
all_page_url_list.append(base_url)#先把第一页的网址给list
browser = webdriver.Chrome(chromepath)
browser.get(base_url)#模拟打开该人的主页
browser.find_element_by_xpath('/html/body/div[3]/div[11]/div[2]/a').click()#让浏览器点击下一页
browser.find_element_by_xpath('/html/body/div[5]/div/div[3]/a').click()#这里是最关键也是耗费我很长时间才用明白的地方。这个在下文中专门作解释,这个操作的功能是,由于我们没有登录账号,第二页会弹出一个框,让你登录,不过你不把这个框叉掉,这就后面对浏览器就无法操作。
all_page_url_list.append(browser.current_url)
time.sleep(2)#这个主要是根据网速而定,因为如果第二页没有加载完全,你后面点击下一页那块没加载出来,程序会报错,说找不到点击下一页那个element
while page-2>0:
browser.find_element_by_xpath('/html/body/div[3]/div[11]/div[2]/a').click()
time.sleep(0.5)
all_page_url_list.append(browser.current_url)
page -= 1
return all_page_url_list#这样就获取了你想要的page内的所有page的url
page = input("Please enter how many page you want to craw:")
base_url = "http://beautyimg001.lofter.com/"
url_list = get_type2_user_all_url_list(base_url,int(page))
for url in url_list:
src,title = get_img_url(url)
get_img(src,title)
讲一下具体怎么找到那个点击下一页的操作(浏览器源码大概知道一些,但是不熟),所以如果你觉得我的方法很low,那请移步至比较吊的人那。
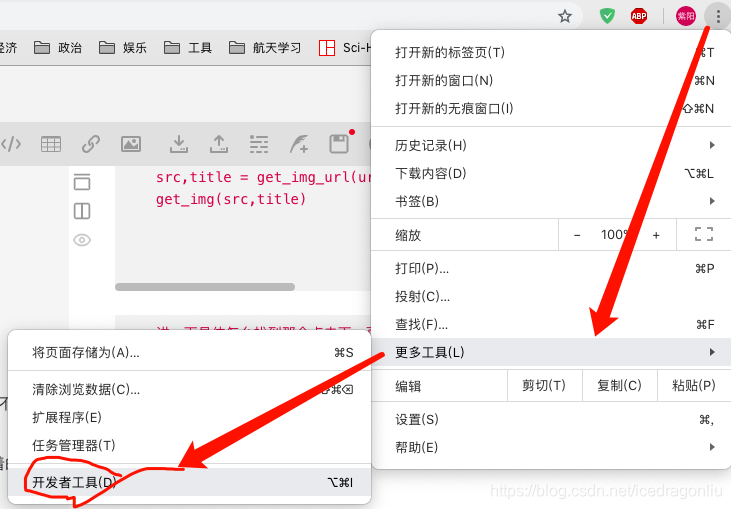
我用的Chrome,给大家讲一下Chrome的步骤,点击chrome窗口右上角的数着的省略号(学名:自定义及控制),然后选择"更多工具",在选择“开发者工具”,如下图所示:
` 然后就会弹出如下图所示:
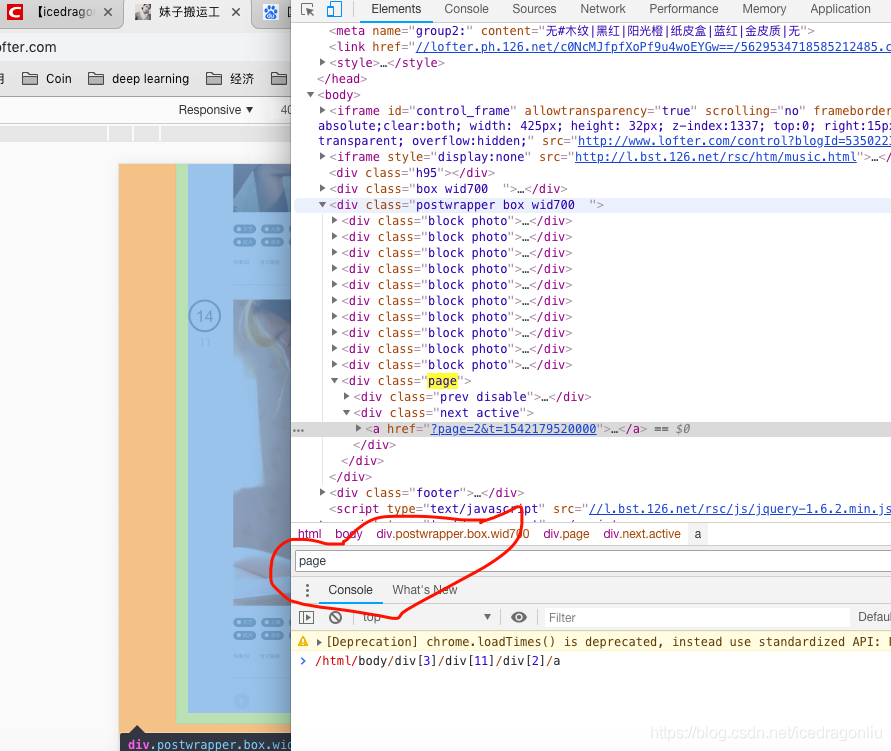
在html里查找page,你就会发现class=“next active”,这个右键点击在那一行,然后copy,copy时有选项,选择xpath,然后用find_element_by_xpath(‘你复制的xpath’).click()。运用类似思路可以解决因为我们没有登录LOFTER导致在刷第二页时,弹出登录对话框。在源码里找‘close’你会搜到close的那个xpath,然后实现点掉弹出对话框的目的。
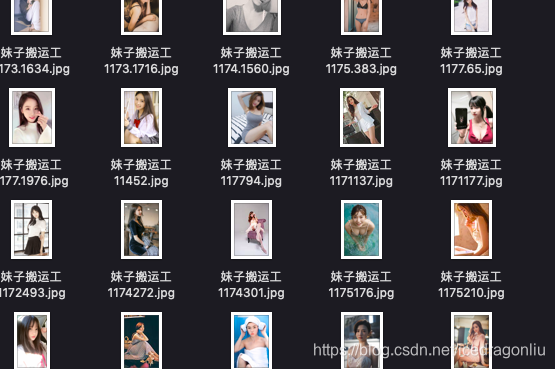
run,等结果,看下结果:(如有侵权(图片的),请及时联系删除)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









