






一、前言
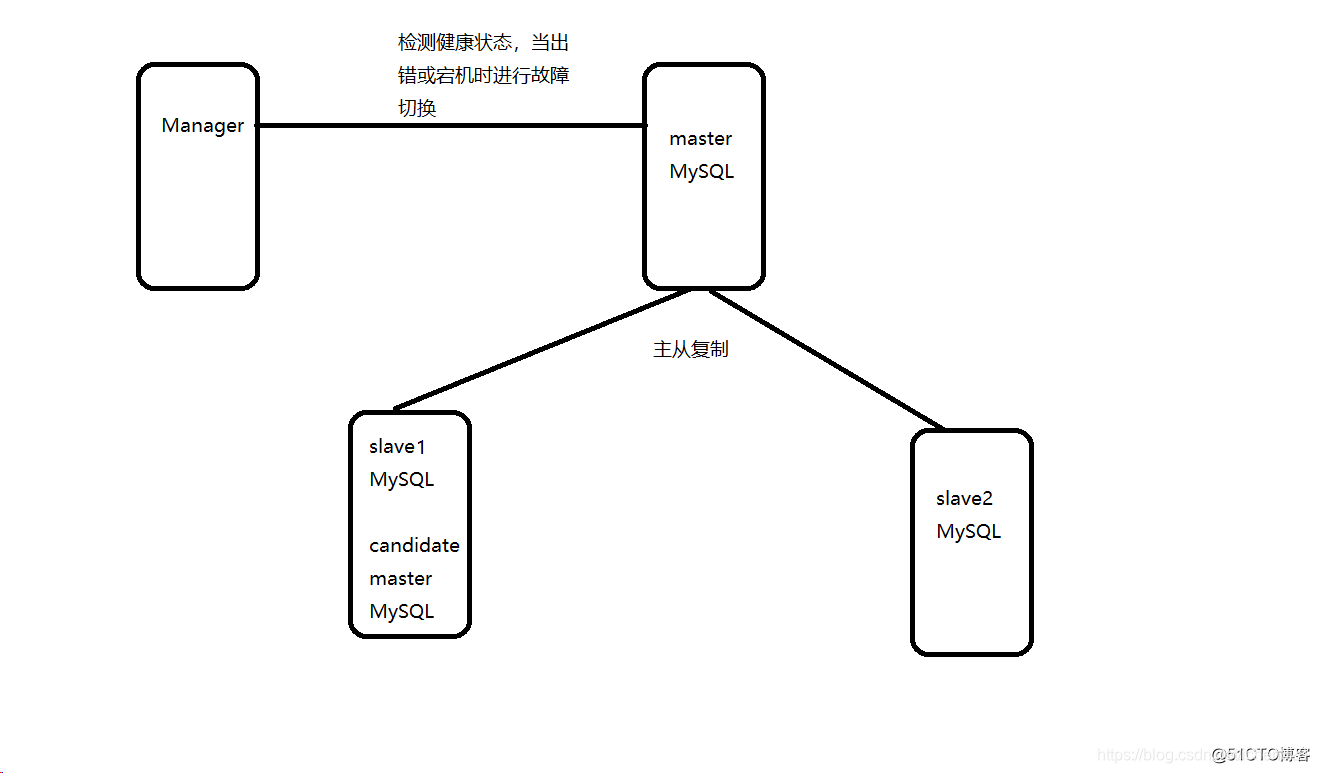
MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司 youshimaton(现就职于Facebook公司)开发,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升 的高可用软件。在MySQL故障切换过程中,MHA能做到在0~30秒之内自动完成数据库的故障切换操作,并且 在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。 MHA里有 两个角色一个是MHA Node(数据节点)另一个是MHA Manager(管理节点)。 MHA Manager可以单独部署 在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。MHA Node运行在每台 MySQL服务器上,MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新 数据的slave提升为新的master,然后将所有其他的slave重新指向新的master。整个故障转移过程对应用程序完 全透明。
1.1What‘s MHA?——原理简介
MHA——Master High Availability,目前在MySQL高可用方面是一个相对成熟的解决方案,是一套优秀的MySQL故障切换和主从提升的高可用软件。
MHA自动故障切换过程中,MHA试图从宕机的主服务器上保存二进制日志,最大程度的保证数据的不丢失,但 这并不总是可行的。例如,如果主服务器硬件故障或无法通过ssh访问,MHA没法保存二进制日志,只进行故 障转移而丢失了最新的数据。使用MySQL 5.5的半同步复制,可以大大降低数据丢失的风险。MHA可以与半同 步复制结合起来。如果只有一个slave已经收到了最新的二进制日志,MHA可以将最新的二进制日志应用于其他 所有的slave服务器上,因此可以保证所有节点的数据一致性。
注:从MySQL5.5开始,MySQL以插件的形式支持半同步复制。
如何理解半同步呢?
首先我们来看看异步,全同步的概念: 异步复制(Asynchronous replication) MySQL默 认的复制即是异步的,主库在执行完客户端提交的事务后会立即将结果返给给客户端,并不关心从库是否已经 接收并处理,这样就会有一个问题,主如果crash掉了,此时主上已经提交的事务可能并没有传到从上,如果此 时,强行将从提升为主,可能导致新主上的数据不完整。 全同步复制(Fully synchronous replication) 指当主 库执行完一个事务,所有的从库都执行了该事务才返回给客户端。因为需要等待所有从库执行完该事务才能返 回,所以全同步复制的性能必然会收到严重的影响。 半同步复制(Semisynchronous replication) 介于异步复 制和全同步复制之间,主库在执行完客户端提交的事务后不是立刻返回给客户端,而是等待至少一个从库接收 到并写到relay log中才返回给客户端。相对于异步复制,半同步复制提高了数据的安全性,同时它也造成了一 定程度的延迟,这个延迟最少是一个TCP/IP往返的时间。所以,半同步复制最好在低延时的网络中使用。
总结:异步与半同步异同 默认情况下MySQL的复制是异步的,Master上所有的更新操作写入Binlog之后 并不确保所有的更新都被复制到Slave之上。异步操作虽然效率高,但是在Master/Slave出现问题的时 候,存在很高数据不同步的风险,甚至可能丢失数据。 MySQL5.5引入半同步复制功能的目的是为了保 证在master出问题的时候,至少有一台Slave的数据是完整的。在超时的情况下也可以临时转入异步复 制,保障业务的正常使用,直到一台salve追赶上之后,继续切换到半同步模式。
工作原理 相较于其它HA软件,MHA的目的在于维持MySQL Replication中Master库的高可用性,其最大特点是 可以修复多个Slave之间的差异日志,最终使所有Slave保持数据一致,然后从中选择一个充当新的Master,并 将其它Slave指向它。 -从宕机崩溃的master保存二进制日志事件(binlogevents)。 -识别含有最新更新的slave。 -应用差异的中继日志(relay log)到其它slave。 -应用从master保存的二进制日志事件(binlogevents)。 -提升一 个slave为新master。 -使其它的slave连接新的master进行复制。
这里我们提到了两个个关键点:“高可用”,“故障切换“。我们逐一简单介绍一下这两者的含义。
1.1.1何为高可用?
高可用就是可用性强,在一定条件下(某个服务器出错或宕机)可以保证服务器可以正常运行,在一定程度上不会影响业务的运行。
1.1.2故障切换
当主服务器出现错误时,被manager服务器监控到主库mysqld服务停止后,首先对主库进行SSH登录检查(save_binary_logs -command=test),然后对mysqld服务进行健康检查(PING(SELECT)每个3秒检查一次,持续3次),最后作出Master is down!的判断,master failover开始进行对应的处理,具体的过程可以参考网上的博客,这里给出一个链接:https://www.cnblogs.com/xiaoboluo768/p/5210820.html 大家可以参考这位朋友的文章,讲的非常详细。
二、MHA高可用架构部署实例
2.1部署环境与基础配置要求
在虚拟机环境下,需要四台Centos7服务器(这里我使用的是Centos7,所以使用的mha版本是0.57的)
其中一台作为mha服务器(manager)来监控管理下面的MySQL服务器;
其余三台一主两从,其中从服务器中的其中一台作为储备主服务器,当主服务器宕机或出错时提升为主服务器。(这里就是主从提升了)
主从复制在上一篇文章中已介绍了MySQL5.7.17版本的配置实例,MySQL5.6.36的配置原理及思路一致,只不过细节上有些许差别。
首先,分配一下ip,私网下为了做实验验证就自己定义就行
MHA服务器——manager:192.168.68.136
MySQL主服务器——master:192.168.68.129
MySQL储备主服务器(起初是从服务器)——slave1:192.168.68.132
MySQL从服务器——slave2:192.168.68.133
相关软件包链接:
链接:https://pan.baidu.com/s/1VNdEIYvT1g_xKbrhzYNI-A
提取码:wmyg
2.2配置流程
2.2.1概述配置流程
安装编译环境——安装MySQL5.6.36数据库——配置时间同步(可以参考上篇博客的实验)——配置主从复制与储备MySQL服务器——安装node工具——配置mha服务器——测试验证
2.2.2配置步骤细解
2.2.2.1首先我们先对MySQL服务器进行配置——安装MySQL5.6.36
MySQL服务器配置如下:
#1.安装编译环境
yum install -y ncurses-devel gcc-c++ perl-Module-Install
#2.安装gmake编译环境
tar zxf cmake-2.8.6.tar.gz -C /opt/
cd /opt/cmake-2.8.6/
./configure
gmake && gmake install
安装MySQL5.6.36数据库
tar zxf mysql-5.6.36.tar.gz -C /opt/
cd /opt/mysql-5.6.36/
cmake \
-DCMAKE_INSTALL_PREFIX=/usr/local/mysql \
-DDEFAULT_CHARSET=utf8 \
-DDEFAULT_COLLATION=utf8_general_ci \
-DWITH_EXTRA_CHARSETS=all \
-DSYSCONFDIR=/etc
make
make install
相关优化配置
cp support-files/my-default.cnf /etc/my.cnf #主配置文件
cp support-files/mysql.server /etc/rc.d/init.d/mysqld
chmod +x /etc/rc.d/init.d/mysqld
chkconfig --add mysqld
echo "PATH=$PATH:/usr/local/mysql/bin" >> /etc/profile
source /etc/profile
useradd -M -s /sbin/nologin mysql
chown -R mysql.mysql /usr/local/mysql
/usr/local/mysql/scripts/mysql_install_db \
--basedir=/usr/local/mysql \
--datadir=/usr/local/mysql/data \
--user=mysql
这边我们就不做防火墙规则了,直接进行关闭
systemctl stop firewalld.service
setenforce 0
接着我们分别对三个MySQL数据库进行主配置文件配置
1.MySQL主服务器配置——vim /etc/my.cnf
[mysqld]
server-id = 1
log_bin = master-bin
log-slave-update = true
2.MySQL从服务器slave1、slave2配置——vim /etc/my.cnf
[mysqld]
server-id = 2
#开启二进制日志
log_bin = master-bin
#使用中继日志进行同步
relay-log = relay-log-bin
relay-log-index = slave-relay-bin.index
[mysqld]
server-id = 3
#开启二进制日志
log_bin = master-bin
#使用中继日志进行同步
relay-log = relay-log-bin
relay-log-index = slave-relay-bin.index
3.master、slave1、slave2分别做两个软链接
ln -s /usr/local/mysql/bin/mysql /usr/sbin/
ln -s /usr/local/mysql/bin/mysqlbinlog /usr/sbin/
4.启动MySQL服务
/usr/local/mysql/bin/mysqld_safe --user=mysql &
5.查看验证端口
[root@master mysql-5.6.36]# netstat -natp | grep 3306
tcp6 0 0 :::3306 :::* LISTEN 103231/mysqld
2.2.2.2配置主从复制
MySQL服务器上配置——根据自己的网段设置
在所有数据库节点上授权两个用户,一个是从库同步使用用户myslave,另一个是manager 使用用户mha
#进入所有的服务器数据库,进行授权设置
mysql> grant replication slave on *.* to 'myslave'@'192.168.68.%' identified by '123456';
Query OK, 0 rows affected (0.00 sec)
mysql> grant all privileges on *.* to 'mha'@'192.168.68.%' identified by 'manager';
Query OK, 0 rows affected (0.00 sec)
#补充由于mha相关特性避免一些问题产生进行的配置
mysql>grant all privileges on *.* to 'mha'@'master' identified by 'manager';
Query OK, 0 rows affected (0.00 sec)
mysql>grant all privileges on *.* to 'mha'@'slave1' identified by 'manager';
Query OK, 0 rows affected (0.00 sec)
mysql>grant all privileges on *.* to 'mha'@'slave2' identified by 'manager';
Query OK, 0 rows affected (0.00 sec)
mysql>flush privileges;
Query OK, 0 rows affected (0.00 sec)
注意:该步骤在所有MySQL服务器上都要配置
查看MySQL主服务器的同步位置并且进行记录
show master status;
mysql> show master status;
+-------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+-------------------+----------+--------------+------------------+-------------------+
| master-bin.000001 | 120 | | | |
+-------------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
MySQL从服务器上设置同步
#设置同步配置命令
mysql> change master to master_host='192.168.68.129',master_user='myslave',master_password='123456',master_log_file='master-bin.000001',master_log_pos=120;
Query OK, 0 rows affected, 2 warnings (0.01 sec)
mysql> start slave;
Query OK, 0 rows affected (0.00 sec)
#查看两个线程是否为yes
mysql> show slave status\G
*************************** 1. row ***************************
...//省略部分内容
Master_Log_File: master-bin.000001
Read_Master_Log_Pos: 120
Relay_Log_File: relay-log-bin.000002
Relay_Log_Pos: 284
Relay_Master_Log_File: master-bin.000001
Slave_IO_Running: Yes #说明同步成功
Slave_SQL_Running: Yes
Replicate_Do_DB:
Master_SSL_CA_File:
在主服务器上创建一个数据库,在从服务器上验证是否存在同一数据库;
注意!!!必须设置两个从库为只读模式
mysql> set global read_only=1;
Query OK, 0 rows affected (0.00 sec)
以上就是MySQL5.6.36数据库的手工编译安装与主从复制的流程,下面我们开始进行mha的相关配置
2.2.2.3配置mha
1.所有服务器上都安装MHA依赖的环境,首先安装epel源。
yum -y install epel-release --nogpgcheck
yum -y install perl-DBD-MySQL \
perl-Config-Tiny \
perl-Log-Dispatch \
perl-Parallel-ForkManager \
perl-ExtUtils-CBuilder \
perl-ExtUtils-MakeMaker \
perl-CPAN
2.MHA软件包对于每个操作系统版本不一样,这里是centos7.4必须选择0.57版本,在所有服务器上必须安装node组件,最后在MHA-manager节点上安装manager组件,因为manager依赖node组件,下面都是在master上操作演示安装node组件
tar zxf mha4mysql-node-0.57.tar.gz
cd mha4mysql-node-0.57
perl Makefile.PL
make && make install
3.在MHA-manager上安装manager组件
tar -zxvf mha4mysql-manager-0.57.tar.gz
cd mha4mysql-manager-0.57
perl Makefile.PL
make && make install
manager 安装后在/usr/local/bin 下面会生成几个工具,主要包括以下几个:
masterha_check_ssh 检查MHA的SSH的配置状况
masterha_check_repl 检查MySQL复制状况
masterha_manager 启动manager脚本
masterha_check_status 检查当前MHA运行状态
masterha_master_monitor 检测master是否宕机
masterha_master_switch 控制故障转移(自动或者手动)
masterha_conf_host 添加或删除配置的server信息
masterha_stop 关闭manager
[root@manager mha4mysql-manager-0.57]# cd /usr/local/bin/
[root@manager bin]# ls
apply_diff_relay_logs masterha_check_status mysql mysql_embedded mysql_upgrade
filter_mysqlbinlog masterha_conf_host mysqladmin mysqlimport mysqlxtest
innochecksum masterha_manager mysqlbinlog mysql_install_db perror
libmysqlclient.a masterha_master_monitor mysqlcheck mysql_plugin pkgconfig
libmysqlclient.so masterha_master_switch mysql_client_test mysqlpump plugin
libmysqlclient.so.20 masterha_secondary_check mysql_client_test_embedded mysql_secure_installation purge_relay_logs
libmysqlclient.so.20.3.4 masterha_stop mysql_config mysqlshow replace
libmysqld.a myisamchk mysql_config_editor mysqlslap resolveip
libmysqlservices.a myisam_ftdump mysqld mysql_ssl_rsa_setup resolve_stack_dump
lz4_decompress myisamlog mysqld_pre_systemd mysqltest save_binary_logs
masterha_check_repl myisampack mysqldump mysqltest_embedded zlib_decompress
masterha_check_ssh my_print_defaults mysqldumpslow mysql_tzinfo_to_sql
[root@manager bin]#
node安装后也会在/usr/local/bin 下面会生成一下几个脚本(这些工具通常由MHA manager
的脚本触发,无需人为操作)主要如下:
save_binary_logs 保存和复制master的二进制日志
apply_diff_relay_logs 识别差异的中继日志事件并将其差异的事件应用于其他的slave
filter_mysqlbinlog 去除不必要的ROLLBACK事件(MHA已不再使用这个工具)
purge_relay_logs 清除中继日志(不会阻塞SQL线程)
[root@slave2 mha4mysql-node-0.57]# cd /usr/local/bin/
[root@slave2 bin]# ls
apply_diff_relay_logs ccmake cmake cpack ctest filter_mysqlbinlog purge_relay_logs save_binary_logs
4.配置无密码认证
4.1在 manager 上配置到所有数据库节点的无密码认证
方法一:
[root@manager ~]# ssh-keygen -t rsa //一路按回车键
[root@manager ~]# ssh-copy-id 192.168.68.129
[root@manager ~]# ssh-copy-id 192.168.68.132
[root@manager ~]# ssh-copy-id 192.168.68.133
4.2在 Mysql1 上配置到数据库节点Mysql2和Mysql3的无密码认证
[root@master ~]# ssh-keygen -t rsa
[root@master ~]# ssh-copy-id 192.168.68.132
[root@master ~]# ssh-copy-id 192.168.68.133
[root@master ~]# ssh-copy-id 192.168.68.136
4.3在 Mysql2 上配置到数据库节点Mysql1和Mysql3的无密码认证
[root@slave1 ~]# ssh-keygen -t rsa
[root@master ~]# ssh-copy-id 192.168.68.136
[root@slave1 ~]# ssh-copy-id 192.168.68.129
[root@slave1 ~]# ssh-copy-id 192.168.68.133
4.4在 Mysql3 上配置到数据库节点Mysql1和Mysql2的无密码认证
[root@slave2 ~]# ssh-keygen -t rsa
[root@master ~]# ssh-copy-id 192.168.68.136
[root@slave2 ~]# ssh-copy-id 192.168.68.129
[root@slave2 ~]# ssh-copy-id 192.168.68.132
方法二:
**#建立ssh无交互登录环境**
#Manager主机:
[root@manager ~]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Created directory '/root/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
1c:cb:2d:4f:b1:80:ea:80:35:3b:89:48:5f:09:eb:2e root@manager
The key's randomart image is:
+--[ RSA 2048]----+
| . |
| o .. |
| .o. o. o . |
|o+o+.. o = o |
|+ =o. S + |
| .+ + |
| E .. . |
| . |
| |
+-----------------+
[root@manager ~]# for i in manager master slave1 slave2;do ssh-copy-id -i $i;done
**# 分发到其他主机**
#master主机
[root@master ~]# ssh-keygen -t rsa
[root@master ~]# for i in manager master slave1 slave2;do ssh-copy-id -i $i;done
#slave1主机
[root@slave1 ~]# ssh-keygen -t rsa
[root@slave1 ~]# for i in manager master slave1 slave2;do ssh-copy-id -i $i;done
#slave2主机
[root@slave2 ~]# ssh-keygen -t rsa
[root@slave2 ~]# for i in manager master slave1 slave2;do ssh-copy-id -i $i;done
**#配置hosts环境**
[root@manager ~]# for i in master manager slave1 slave2;do ssh $i hostname;done
master
manager
slave1
slave2
[root@manager ~]# ssh master
[root@master ~]# ssh slave1
[root@slave1 ~]# ssh slave2
**#配置hosts环境**
[root@manager ~]# vim /etc/hosts
192.168.171.150 manager
192.168.171.151 master
192.168.171.152 slave1
192.168.171.153 slave2
[root@manager ~]# scp /etc/hosts root@192.168.171.151:/etc/
[root@manager ~]# scp /etc/hosts root@192.168.171.152:/etc/
[root@manager ~]# scp /etc/hosts root@192.168.171.153:/etc/
5.配置MHA脚本
1.在 manager 节点上复制相关脚本到/usr/local/bin 目录。
[root@manager ~]# cp -ra /root/mha/mha4mysql-manager-0.57/samples/scripts /usr/local/bin
//拷贝后会有四个执行文件
[root@managers ~]# ll /usr/local/bin/scripts/
总用量 32
-rwxr-xr-x 1 mysql mysql 3648 5 月 31 2015 master_ip_failover #自动切换时 VIP 管理的脚本
-rwxr-xr-x 1 mysql mysql 9872 5 月 25 09:07 master_ip_online_change #在线切换时 vip 的管理
-rwxr-xr-x 1 mysql mysql 11867 5 月 31 2015 power_manager #故障发生后关闭主机的脚本
-rwxr-xr-x 1 mysql mysql 1360 5 月 31 2015 send_report #因故障切换后发送报警的脚本
2.复制上述的自动切换时 VIP 管理的脚本到/usr/local/bin 目录,这里使用脚本管理 VIP.
[root@manager bin]# cd scripts/
[root@managerscripts]# ls
master_ip_failover master_ip_online_change power_manager send_report
[root@manager scripts]# cp master_ip_failover /usr/local/bin/
修改该配置文件如下:
建议源文件进行备份,直接把下面代码复制粘贴。
#!/usr/bin/env perl
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
my (
$command, $ssh_user, $orig_master_host, $orig_master_ip,
$orig_master_port, $new_master_host, $new_master_ip, $new_master_port
);
my $vip = '192.168.68.200/24'; # Virtual IP
my $key = "1";
my $ssh_start_vip = "/sbin/ifconfig ens33:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfig ens33:$key down";
GetOptions(
'command=s' => \$command,
'ssh_user=s' => \$ssh_user,
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' => \$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'new_master_host=s' => \$new_master_host,
'new_master_ip=s' => \$new_master_ip,
'new_master_port=i' => \$new_master_port,
);
exit &main();
sub main {
print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n";
if ( $command eq "stop" || $command eq "stopssh" ) {
# $orig_master_host, $orig_master_ip, $orig_master_port are passed.
# If you manage master ip address at global catalog database,
# invalidate orig_master_ip here.
my $exit_code = 1;
eval {
print "Disabling the VIP on old master: $orig_master_host \n";
&stop_vip();
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
# all arguments are passed.
# If you manage master ip address at global catalog database,
# activate new_master_ip here.
# You can also grant write access (create user, set read_only=0, etc) here.
my $exit_code = 10;
eval {
print "Enabling the VIP - $vip on the new master - $new_master_host \n";
&start_vip();
$exit_code = 0;
};
if ($@) {
warn $@;
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK \n";
`ssh $ssh_user\@$orig_master_host \" $ssh_start_vip \"`;
exit 0;
}
else {
&usage();
exit 1;
}
}
# A simple system call that enable the VIP on the new master
sub start_vip() {
`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;
}
# A simple system call that disable the VIP on the old_master
sub stop_vip() {
`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}
sub usage {
print
"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";
}
6.创建 MHA 软件目录并拷贝配置文件。
[root@manager scripts]# mkdir /etc/masterha
[root@manager scripts]# cd ~/mha/mha4mysql-manager-0.57/
[root@manager mha4mysql-manager-0.57]# ls
AUTHORS blib debian lib Makefile.PL META.yml README samples tests
bin COPYING inc Makefile MANIFEST pm_to_blib rpm t
[root@manager mha4mysql-manager-0.57]# cd samples/
[root@manager samples]# cd conf/
[root@manager conf]# ls
[root@manager conf]# cp app1.cnf /etc/masterha/
编辑修改app1.cnf
[root@manager conf]# vim /etc/masterha/app1.cnf
[server default]
manager_log=/var/log/masterha/app1/manager.log##manager工作目录
manager_workdir=/var/log/masterha/app1#manager日志
master_binlog_dir=/usr/local/mysql/data#master保存binlog的位置,这里的路径要与master里配置的binlog的路径一致,以便mha能找到
master_ip_failover_script=/usr/local/bin/master_ip_failover#设置自动failover时候的切换脚本,也就是上边的哪个脚本
master_ip_online_change_script=/usr/local/bin/master_ip_online_change#设置手动切换时候的切换脚本
password=manager#设置mysql中root用户的密码,这个密码是前文中创建监控用户的那个密码
ping_interval=1#设置监控主库,发送ping包的时间间隔,默认是3秒,尝试三次没有回应的时候自动进行railover
remote_workdir=/tmp#设置远端mysql在发生切换时binlog的保存位置
repl_password=123#设置复制用户的密码
repl_user=myslave#设置复制用户的用户
secondary_check_script=/usr/local/bin/masterha_secondary_check -s 192.168.68.132 -s 192.168.68.133
shutdown_script=""#设置故障发生后关闭故障主机脚本(该脚本的主要作用是关闭主机放在发生脑裂,这里没有使用)
ssh_user=root#设置ssh的登录用户名
user=mha#设置监控用户root
[server1]
hostname=192.168.68.129
port=3306
[server2]
candidate_master=1#设置为候选master
check_repl_delay=0
hostname=192.168.68.132
port=3306
[server3]
hostname=192.168.68.133
port=3306
2.2.2.4测试验证
测试 ssh 无密码认证,如果正常最后会输出 successfully,如下所示。
[root@manager conf]# masterha_check_ssh -conf=/etc/masterha/app1.cnf
Tue Jan 14 16:44:58 2020 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Tue Jan 14 16:44:58 2020 - [info] Reading application default configuration from /etc/masterha/app1.cnf..
Tue Jan 14 16:44:58 2020 - [info] Reading server configuration from /etc/masterha/app1.cnf..
Tue Jan 14 16:44:58 2020 - [info] Starting SSH connection tests..
Tue Jan 14 16:45:00 2020 - [debug]
Tue Jan 14 16:44:58 2020 - [debug] Connecting via SSH from root@192.168.68.129(192.168.68.129:22) to root@192.168.68.132(192.168.68.132:22)..
Tue Jan 14 16:44:59 2020 - [debug] ok.
Tue Jan 14 16:44:59 2020 - [debug] Connecting via SSH from root@192.168.68.129(192.168.68.129:22) to root@192.168.68.133(192.168.68.133:22)..
Tue Jan 14 16:45:00 2020 - [debug] ok.
Tue Jan 14 16:45:01 2020 - [debug]
Tue Jan 14 16:44:59 2020 - [debug] Connecting via SSH from root@192.168.68.133(192.168.68.133:22) to root@192.168.68.129(192.168.68.129:22)..
Tue Jan 14 16:45:00 2020 - [debug] ok.
Tue Jan 14 16:45:00 2020 - [debug] Connecting via SSH from root@192.168.68.133(192.168.68.133:22) to root@192.168.68.132(192.168.68.132:22)..
Tue Jan 14 16:45:01 2020 - [debug] ok.
Tue Jan 14 16:45:01 2020 - [debug]
Tue Jan 14 16:44:59 2020 - [debug] Connecting via SSH from root@192.168.68.132(192.168.68.132:22) to root@192.168.68.129(192.168.68.129:22)..
Tue Jan 14 16:45:00 2020 - [debug] ok.
Tue Jan 14 16:45:00 2020 - [debug] Connecting via SSH from root@192.168.68.132(192.168.68.132:22) to root@192.168.68.133(192.168.68.133:22)..
Tue Jan 14 16:45:00 2020 - [debug] ok.
Tue Jan 14 16:45:01 2020 - [info] All SSH connection tests passed successfully.
健康检查如下:
[root@manager conf]# masterha_check_repl -conf=/etc/masterha/app1.cnf
Tue Jan 14 16:45:21 2020 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Tue Jan 14 16:45:21 2020 - [info] Reading application default configuration from /etc/masterha/app1.cnf..
Tue Jan 14 16:45:21 2020 - [info] Reading server configuration from /etc/masterha/app1.cnf..
Tue Jan 14 16:45:21 2020 - [info] MHA::MasterMonitor version 0.57.
Creating directory /var/log/masterha/app1.. done.
Tue Jan 14 16:45:22 2020 - [info] GTID failover mode = 0
Tue Jan 14 16:45:22 2020 - [info] Dead Servers:
Tue Jan 14 16:45:22 2020 - [info] Alive Servers:
Tue Jan 14 16:45:22 2020 - [info] 192.168.68.129(192.168.68.129:3306)
Tue Jan 14 16:45:22 2020 - [info] 192.168.68.132(192.168.68.132:3306)
Tue Jan 14 16:45:22 2020 - [info] 192.168.68.133(192.168.68.133:3306)
Tue Jan 14 16:45:22 2020 - [info] Alive Slaves:
Tue Jan 14 16:45:22 2020 - [info] 192.168.68.132(192.168.68.132:3306) Version=5.6.36-log (oldest major version between slaves) log-bin:enabled
Tue Jan 14 16:45:22 2020 - [info] Replicating from 192.168.68.129(192.168.68.129:3306)
Tue Jan 14 16:45:22 2020 - [info] Primary candidate for the new Master (candidate_master is set)
Tue Jan 14 16:45:22 2020 - [info] 192.168.68.133(192.168.68.133:3306) Version=5.6.36-log (oldest major version between slaves) log-bin:enabled
Tue Jan 14 16:45:22 2020 - [info] Replicating from 192.168.68.129(192.168.68.129:3306)
Tue Jan 14 16:45:22 2020 - [info] Current Alive Master: 192.168.68.129(192.168.68.129:3306)
Tue Jan 14 16:45:22 2020 - [info] Checking slave configurations..
Tue Jan 14 16:45:22 2020 - [warning] relay_log_purge=0 is not set on slave 192.168.68.132(192.168.68.132:3306).
Tue Jan 14 16:45:22 2020 - [warning] relay_log_purge=0 is not set on slave 192.168.68.133(192.168.68.133:3306).
Tue Jan 14 16:45:22 2020 - [info] Checking replication filtering settings..
Tue Jan 14 16:45:22 2020 - [info] binlog_do_db= , binlog_ignore_db=
Tue Jan 14 16:45:22 2020 - [info] Replication filtering check ok.
Tue Jan 14 16:45:22 2020 - [info] GTID (with auto-pos) is not supported
Tue Jan 14 16:45:22 2020 - [info] Starting SSH connection tests..
Tue Jan 14 16:45:25 2020 - [info] All SSH connection tests passed successfully.
Tue Jan 14 16:45:25 2020 - [info] Checking MHA Node version..
Tue Jan 14 16:45:26 2020 - [info] Version check ok.
Tue Jan 14 16:45:26 2020 - [info] Checking SSH publickey authentication settings on the current master..
Tue Jan 14 16:45:26 2020 - [info] HealthCheck: SSH to 192.168.68.129 is reachable.
Tue Jan 14 16:45:26 2020 - [info] Master MHA Node version is 0.57.
Tue Jan 14 16:45:26 2020 - [info] Checking recovery script configurations on 192.168.68.129(192.168.68.129:3306)..
Tue Jan 14 16:45:26 2020 - [info] Executing command: save_binary_logs --command=test --start_pos=4 --binlog_dir=/usr/local/mysql/data --output_file=/tmp/save_binary_logs_test --manager_version=0.57 --start_file=master-bin.000001
Tue Jan 14 16:45:26 2020 - [info] Connecting to root@192.168.68.129(192.168.68.129:22)..
Creating /tmp if not exists.. ok.
Checking output directory is accessible or not..
ok.
Binlog found at /usr/local/mysql/data, up to master-bin.000001
Tue Jan 14 16:45:26 2020 - [info] Binlog setting check done.
Tue Jan 14 16:45:26 2020 - [info] Checking SSH publickey authentication and checking recovery script configurations on all alive slave servers..
Tue Jan 14 16:45:26 2020 - [info] Executing command : apply_diff_relay_logs --command=test --slave_user='mha' --slave_host=192.168.68.132 --slave_ip=192.168.68.132 --slave_port=3306 --workdir=/tmp --target_version=5.6.36-log --manager_version=0.57 --relay_log_info=/usr/local/mysql/data/relay-log.info --relay_dir=/usr/local/mysql/data/ --slave_pass=xxx
Tue Jan 14 16:45:26 2020 - [info] Connecting to root@192.168.68.132(192.168.68.132:22)..
Checking slave recovery environment settings..
Opening /usr/local/mysql/data/relay-log.info ... ok.
Relay log found at /usr/local/mysql/data, up to relay-log-bin.000002
Temporary relay log file is /usr/local/mysql/data/relay-log-bin.000002
Testing mysql connection and privileges..Warning: Using a password on the command line interface can be insecure.
done.
Testing mysqlbinlog output.. done.
Cleaning up test file(s).. done.
Tue Jan 14 16:45:44 2020 - [info] Executing command : apply_diff_relay_logs --command=test --slave_user='mha' --slave_host=192.168.68.133 --slave_ip=192.168.68.133 --slave_port=3306 --workdir=/tmp --target_version=5.6.36-log --manager_version=0.57 --relay_log_info=/usr/local/mysql/data/relay-log.info --relay_dir=/usr/local/mysql/data/ --slave_pass=xxx
Tue Jan 14 16:45:44 2020 - [info] Connecting to root@192.168.68.133(192.168.68.133:22)..
Checking slave recovery environment settings..
Opening /usr/local/mysql/data/relay-log.info ... ok.
Relay log found at /usr/local/mysql/data, up to relay-log-bin.000002
Temporary relay log file is /usr/local/mysql/data/relay-log-bin.000002
Testing mysql connection and privileges..Warning: Using a password on the command line interface can be insecure.
done.
Testing mysqlbinlog output.. done.
Cleaning up test file(s).. done.
Tue Jan 14 16:46:08 2020 - [info] Slaves settings check done.
Tue Jan 14 16:46:08 2020 - [info]
192.168.68.129(192.168.68.129:3306) (current master)
+--192.168.68.132(192.168.68.132:3306)
+--192.168.68.133(192.168.68.133:3306)
Tue Jan 14 16:46:08 2020 - [info] Checking replication health on 192.168.68.132..
Tue Jan 14 16:46:08 2020 - [info] ok.
Tue Jan 14 16:46:08 2020 - [info] Checking replication health on 192.168.68.133..
Tue Jan 14 16:46:08 2020 - [info] ok.
Tue Jan 14 16:46:08 2020 - [info] Checking master_ip_failover_script status:
Tue Jan 14 16:46:08 2020 - [info] /usr/local/bin/master_ip_failover --command=status --ssh_user=root --orig_master_host=192.168.68.129 --orig_master_ip=192.168.68.129 --orig_master_port=3306
IN SCRIPT TEST====/sbin/ifconfig ens33:1 down==/sbin/ifconfig ens33:1 192.168.68.200===
Checking the Status of the script.. OK
Tue Jan 14 16:46:08 2020 - [info] OK.
Tue Jan 14 16:46:08 2020 - [warning] shutdown_script is not defined.
Tue Jan 14 16:46:08 2020 - [info] Got exit code 0 (Not master dead).
MySQL Replication Health is OK.
2.2.3配置步骤小结
本实验涉及的内容还是比较多的,配置过程中出现的问题主要有如下几点:
主从复制:需要先进行服务器的时间同步;
秘钥推送:IP地址要注意是否准确;
MHA的两个配置文件的关键之处是否正确;
这些都是最容易出错的地方,大家需要格外注意。
2.2.4启动MHA命令
[root@manager conf]# nohup masterha_manager --conf=/etc/masterha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/masterha/app1/manager.log 2>&1 &
[1] 104076
–remove_dead_master_conf 该参数代表当发生主从切换后,老的主库的 ip 将会从配置文件中移除。
–manger_log 日志存放位置。
–ignore_last_failover 在缺省情况下,如果 MHA 检测到连续发生宕机,且两次宕机间隔不足 8 小时的话,则不会进行 Failover,之所以这样限制是为了避免 ping-pong 效应。该参数代表忽略上次 MHA 触发切换产生的文件,默认情况下,MHA 发生切换后会在日志记目录,也就是上面设置的日志 app1.failover.complete 文件,下次再次切换的时候如果发现该目录下存在该文件将不允许触发切换,除非在第一次切换后收到删除该文件,为了方便,这里设置为–ignore_last_failover。
2.2.5查看 MHA 状态
可以看到当前的master是主服务节点,ip地址是192.168.68.129
[root@manager conf]# masterha_check_status --conf=/etc/masterha/app1.cnf
app1 (pid:104076) is running(0:PING_OK), master:192.168.68.129
#或者查看日志,也可以发现主服务器节点ip地址
[root@manager conf]# tail -2 /var/log/masterha/app1/manager.log
Tue Jan 14 17:12:48 2020 - [info] Starting ping health check on 192.168.68.129(192.168.68.129:3306)..
Tue Jan 14 17:12:48 2020 - [info] Ping(SELECT) succeeded, waiting until MySQL doesn't respond..
2.2.6验证主服务器宕机
当然第一次配置需要手动配置VIP(virtual ip)
[root@master bin]# /sbin/ifconfig ens33:1 192.168.68.200/24
[root@master bin]# ifconfig
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.68.129 netmask 255.255.255.0 broadcast 192.168.68.255
inet6 fe80::bdab:b59b:d041:d8b0 prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:e6:6d:eb txqueuelen 1000 (Ethernet)
RX packets 775098 bytes 1083035145 (1.0 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 413307 bytes 31715433 (30.2 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
ens33:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.68.200 netmask 255.255.255.0 broadcast 192.168.68.255
ether 00:0c:29:e6:6d:eb txqueuelen 1000 (Ethernet)
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1 (Local Loopback)
RX packets 20 bytes 1568 (1.5 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 20 bytes 1568 (1.5 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
virbr0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 192.168.122.1 netmask 255.255.255.0 broadcast 192.168.122.255
ether 52:54:00:43:58:6e txqueuelen 1000 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
使用pkill -9 mysql模拟主服务器宕机情况查看mysql从服务器slave1是否获取vip 地址
[root@slave1 bin]# ifconfig
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.68.132 netmask 255.255.255.0 broadcast 192.168.68.255
inet6 fe80::4d95:1de7:d0a5:25c4 prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:0d:06:80 txqueuelen 1000 (Ethernet)
RX packets 766652 bytes 1074024643 (1.0 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 379004 bytes 29740586 (28.3 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
ens33:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.68.200 netmask 255.255.255.0 broadcast 192.168.68.255
ether 00:0c:29:0d:06:80 txqueuelen 1000 (Ethernet)
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1 (Local Loopback)
RX packets 146 bytes 12570 (12.2 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 146 bytes 12570 (12.2 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
virbr0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 192.168.122.1 netmask 255.255.255.0 broadcast 192.168.122.255
ether 52:54:00:95:86:1a txqueuelen 1000 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
我们可以进入slave1的数据库中查看其状态
mysql> show slave status\G
Empty set (0.00 sec)
mysql> show master status
-> ;
+-------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+-------------------+----------+--------------+------------------+-------------------+
| master-bin.000001 | 1213 | | | |
+-------------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
表明从数据库已经成功切换为主服务了。














 1189
1189











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









