







Hadoop
一、Hadoop 是什么?
- Hadoop 是 Apache 旗下的一套开源软件平台。
- Hadoop 可以利用计算机集群,根据用户自定义的业务逻辑对海量数据进行分布式处理。
- 通常我们说的 Hadoop 是指一个更广泛的概念--Hadoop 生态圈。
二、Hadoop 生态圈
Hadoop 生态圈是指以 Hadoop 为基础发展出来的一系列技术。这些技术都是为了解决大数据处理过程中不断出现的新问题而产生的。
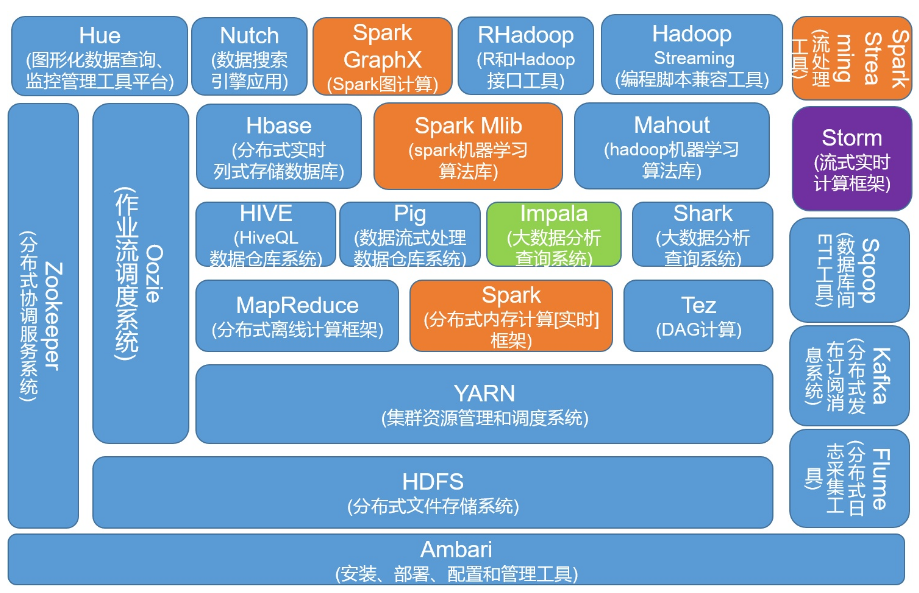
2.1 最新大数据生态圈技术
图中包含目前最流行的两个大数据处理框架 Hadoop 和 Spark。蓝色部分是 Hadoop 的生态圈组件,黄色部分是 Spark 生态圈组建。这两个框架之间的关系并不是互斥的,它们之间既有合作,补充又有竞争。比如 Spark 提供的实时内存计算是比 Hadoop 中 MapReduce 快的多的技术,但是 Spark 又依赖于 Hadoop 中的 HDFS 来存储数据。虽然 Spark 也可以基于于别的系统进行搭建,但是大家一致认为 Spark 和 Hadoop 更配。
我们可以把这个生态圈看作是厨房,其中的各项技术都是厨房中的工具。锅碗瓢盆的功能虽有重合,但是各自也有各自的特性。使用一些奇怪的组合也能功能,但未必是最佳选择。
2.2 技术介绍
2.2.1 大数据概念
大数据只的是哪些数据量特别大,数据类型特别复杂的数据集。这些数据集无法使用传统的数据库进行存储、管理和处理。大数据的主要特点为:数据量大(Volume),数据类型特别复杂(Variety),数据处理速度快(Velocity)和数据真实性高(Veracity),合起来称为 4V。
2.2.2 HDFS
大数据技术首要的要求就是先把数据存下来。HDFS(Hadoop Distributed FileSystem)的设计本质就是为了大量的数据能够横跨成千上万台机器存储,但是对于用户来说看到的是一个文件系统而不是许多文件系统。比如说你要获取 /hdfs/tmp/aaa 的数据,虽然使用的是一个路径,但找个文件的数据可能存放在很多台不同的机器上。作为用户来说不需要知道数据到底存储在哪儿,就像你在单机上并不关心文件到底存储在磁盘那个扇区一样。这些数据交由 HDFS 来管理,用户可以更关注于数据的使用和处理。
2.2.3 MapReduce
能够存储数据后,接下来就要考虑怎么处理数据了。一台计算机处理成 T 上 P 的数据可能需要几天甚至好几周,对于大部分公司都是不可接受的。比如微博的热搜,每 24 小时更新一次,就要求必须在 24 小时内分析完所有数据。如果我们使用很多台计算机进行处理就面临了计算机之间如何分配任务,如何通信,如何进行数据交换等问题。这就是 MapReduce/Tez/Spark 所要解决的问题:提供一种可靠的,能够运行在集群上的计算模型。
2.2.4 Hive
在使用了一段时间的 MapReduce 以后,程序员发现 MapReduce 的程序写起来太麻烦。希望能够封装出一种更简单的方式去完成 MapReduce 程序,于是就有了 Pig 和 Hive。Pig 是以类似脚本的方式去描述 MapReduce,而 Hive 则是以 SQL 的方式。它们会自动把脚本或者 SQL 翻译成 MapReduce 程序,然后丢给计算引擎去计算处理。有了 Hive 以后人们发现 SQL 的优势太大了。一是容易写,一两行的 SQL 换成 MapReduce 可能要几十上百行。二是容易上手,即使非计算机背景的用户也可以很快的学会。三是易写易改,一看就懂,容易维护。所以自从 Hive 问世很快就成长为大数据仓库的核心技术。使用了一段时间的 Hive 后人们发现 Hive 运行在 MapReduce 上太慢了。于是有开发出了针对于 SQL 优化的技术 Impala,Drill 和 Presto 等。这些技术牺牲了系统的通用性和稳定性来提高 SQL 的效率,最终并没有流行起来。
2.2.5 小结
上面介绍的就是数据仓库的基本架构了,底层是 HDFS,上面运行的是 MapReduce/Tez/Spark,在往上封装的是 Pig 和 Hive。
2.2.6 Storm
如果想要更快的计算速度,比如视频网站的热博榜,要求更新延迟在一分钟内,上面的任何一种手段都无法胜任。于是 Streaming(流)计算模型被开发出来了。Storm 是最流行的流计算平台。流处理的思路就是在数据进入系统的时候就进行处理,基本无延迟。缺点是不灵活,必须事先直到需要统计的数据,数据流过就没有了,没法进行补算。因此它是个好东西,但还是无法代替上述体系的。
2.2.7 HBase
HBase 是一个构建与 HDFS 的分布式,面向列的存储系统。以 kv 对的方式存储数据并对存取操作做了优化,能够飞快的根据 key 获取绑定的数据。例如从几个 P 的数据中找身份证号只需要零点几秒。
2.2.8 其他
除此之外还有需要定制的组件。比如:Mahout 是机器学习和推荐引擎,Nutch 是搜索引擎,Zookeeper 是集群管理工具,Sqoop 是 Hadoop 和数据库之间的导入导出工具,Flume 是日志采集工具,Oozie 是作业流调度系统等。
2.2.9 yarn
为了使这么多工具有序的运行在同一个集群上,我们需要使用一个调度系统进行协调指挥。目前流行的是使用 yarn 来进行管理。
三、Hadoop 的历史
一切起源于谷歌的三遍论文:
- Google FileSystem:怎么使用普通计算机存储海量的数据;
- Google MapReduce:怎么快速的计算海量的数据;
- Google BigTable:怎么实现海量数据的快速查询;
Doug Cutting 在完成 Java 搜索引擎 Nutch 的时候接触到了这三篇论文,根据其理论作出了 Java 的实现,就是 Hadoop 系统。随后将其开源并交与 Apache 基金会进行管理,Hadoop 就逐渐壮大起来。
四、Hadoop 的发行版
4.1 Hadoop 1.x
该系列有 HDFS + MapReduce 组成。HDFS 负责存储数据,MapReduce 负责处理数据。
4.2 Hadoop 2.x
该系列把 1.x 系列的 MapReduce 拆成了 MapReduce + Yarn。MapReduce 负责定义功能,Yarn 负责资源管理和调度,实现功能。
4.3 CDH
全称 Cloudera’s Distribution Including Apache Hadoop。是 Cloudera 公司在 Hadoop 的基础上进行了商业化的产品,通常称为 CDH。共有 5 个版本,目前最新的是 CDH 5。虽然是商业化的产品,但是可以免费使用。
4.5 other
Intel 发型版,华为发型版等都是收费的,用的人不多。















 608
608

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









