








Buffer的基本用法
使用Buffer读写数据一般遵循以下四个步骤:- 写入数据到Buffer
- 调用flip()方法
- 从Buffer中读取数据
- 调用clear()方法或者compact()方法
一旦读完了所有的数据,就需要清空缓冲区,让它可以再次被写入。有两种方式能清空缓冲区:调用clear()或compact()方法。clear()方法会清空整个缓冲区。compact()方法只会清除已经读过的数据。任何未读的数据都被移到缓冲区的起始处,新写入的数据将放到缓冲区未读数据的后面。
Buffer的capacity,position和limit
缓冲区可以认为是一个容器,可以看做是某个类型的数组,既然是容器、数组那就应该有容量大小、下标(index),不可能无限读或者写,读写时必须有指定的下标值:
缓存区的读写模式内部其实是使用三个状态变量来控制:
- capacity
- position
- limit
这里有一个关于capacity,position和limit在读写模式中的说明,详细的解释在插图后面。
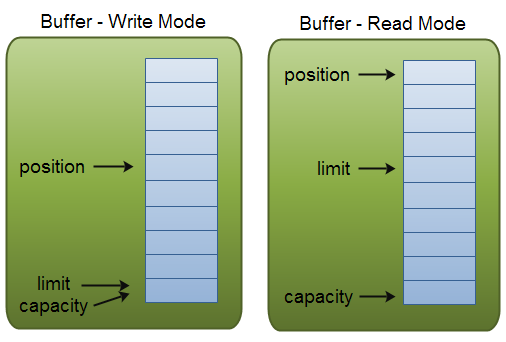
1.capacity
这个状态变量表示缓冲区的容量大小,这个值是固定不变的,指向缓冲区底层数组的最后一个位置;
2. position
在读模式下,该值表示下一个读取数据的位置,通过flip方法切换为读模式时,该值为指向缓存区第一个数据位置;
在写模式下,该值表示下一个要写入数据的位置,通过clear方法切换为写模式时,该值指向缓存区第一个数据位置;
3. limit
这个状态变量表示缓存区可读/写的最大位置:
在写模式下,该值等于capacity;
在读模式下,该值等于切换为读模式时position的位置,表示可读数据位置;
读写模式改变方法
1.flip方法
该方法必须要在读取缓冲区数据前调用;flip方法将limit变量的位置设置为当前position,将position设置为0,然后就可从缓冲区读取数据;
该方法必须要在读取缓冲区数据前调用;flip方法将limit变量的位置设置为当前position,将position设置为0,然后就可从缓冲区读取数据;
2. clear方法
该方法必须在向缓冲区写入数据前调用;clear方法将limit变量设置为和capacity一样,将position设置为0;
该方法必须在向缓冲区写入数据前调用;clear方法将limit变量设置为和capacity一样,将position设置为0;
3. compact方法
该方法可以作为切换写模式调用,它并不像clear方法清空整个缓冲区,只是清除已经读取过的数据,没有被读取过的数据会移动到缓冲区前面:position位置设置为 limit-position,而limit还是设置为和capacity一样;
该方法可以作为切换写模式调用,它并不像clear方法清空整个缓冲区,只是清除已经读取过的数据,没有被读取过的数据会移动到缓冲区前面:position位置设置为 limit-position,而limit还是设置为和capacity一样;
4. rewind方法
该方法将position变量从设置为0,limit变量保存不变,改方法可以用于读取数据后进行重新读取;
该方法将position变量从设置为0,limit变量保存不变,改方法可以用于读取数据后进行重新读取;
5. mark方法与reset方法
通常这个两个方法是一起配合使用的;mark方法用于标记当前缓冲区的position位置,reset方法用于恢复position为mark的位置;可以用于重复读取某段数据;如果调用reset方法是,缓冲区中没有一个mark,将会抛出InvalidMarkException异常;注意:调用clear、flip、compact、rewind方法会清除掉这个mark;
创建缓冲区
缓冲区分配与包装
在对通道进行读和写之前,必须先有一个缓冲区;创建缓冲区,通常通过静态方法allocate分配一个缓冲区:ByteBuffer buffer = ByteBuffer.allocate(1024);另外还可以通过一个现有的数组直接包装为缓冲区:
byte array[] = new byte[1024];
ByteBuffer buffer = ByteBufer.wrap(array);缓冲区分片
缓冲区可以使用slice方法创建一个子缓冲区,即是创建一个新的缓冲区,但是共享原缓冲区的一部分数据,使用下面实例代码说明slice方法:public static void main(String[] args) {
//创建一个容量为10的字节缓冲区
ByteBuffer buffer = ByteBuffer.allocate(10);
//设置缓冲区中的数据
for (int i=0; i<buffer.capacity(); ++i) {
buffer.put(i, (byte) i);
}
//手动设置状态变量,创建一个包含原缓冲区index3-6的子缓冲区(分片)
buffer.position(3);
buffer.limit(7);
ByteBuffer slice = buffer.slice();
//对新创建的子缓冲区中每个数据乘10操作
for (int i=0; i<slice.capacity(); ++i) {
byte b = slice.get(i);
b*=10;
slice.put(i, b);
}
//重设状态变量
buffer.position(0);
buffer.limit(buffer.capacity());
while (buffer.hasRemaining()) {
System.out.println(buffer.get());
}
}输出的结果为:
0
1
2
30
40
50
60
7
8
9分片对于方法调用是有很大作用的,对调用的方法,如果只想方法处理其中一部分数据,可以通过slice传递一个子缓冲区作为参数;
只读缓冲区
只读缓冲区只能用于读取数据,不能写入数据;通过缓冲区的asReadOnlyBuffer创建一个新的缓冲区,它与原缓冲区共享数据,但是是只读的;只读缓冲区主要用于数据的保护,比如:调用一个方法是,可能需要保证缓冲区的数据不被修改,那就可以创建一个只读缓冲区作为参数;















 1200
1200

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









