






 本文深入探讨了多层感知器(MLP)神经网络的基本结构和工作原理,解释了神经元如何通过加权和及激活函数处理信息,以及隐含层在识别模式中的关键作用。
本文深入探讨了多层感知器(MLP)神经网络的基本结构和工作原理,解释了神经元如何通过加权和及激活函数处理信息,以及隐含层在识别模式中的关键作用。
学习目的
(要带着目的 问题去看视频)
1.理解神经网络为什么会是这样的结构?
2.明白机器网络“学习”究竟代表什么。


(接下来的几个视频只会讨论
最简单的原味版 多层感知器MLP)
MLP = multilayer perceptron 多层感知器
一、神经网络的结构(p1)
(目前只有p1)

MLP的神经网络结构
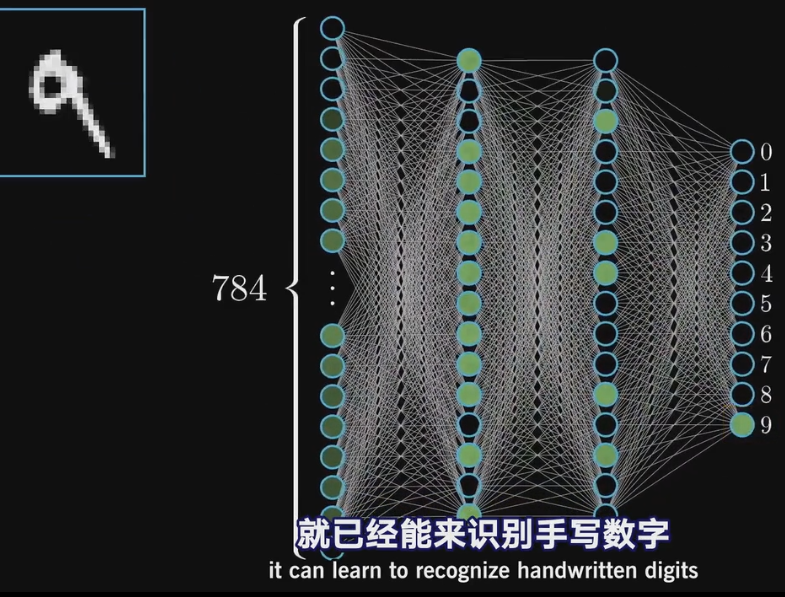
从左到右 顾名思义“多层”
MLP已经能够识别手写的数字
既然神经网络之名来源于人的大脑结构
graph LR
神经元[神经元]-->|层层连接|神经网络[神经网络]
那么
(1)我们先看看什么是神经元?
我们先把他理解成一个用来装数字的容器
装着0-1之间的数字 就这么简单

像这张图片里的“9” 有28×28=784个像素

我们让每一个像素对应一个神经元
神经元中装着的数字代表对应像素的灰度值
神经元里面的值叫做 “激活值(Activation)”

0表示纯黑像素 1表示纯白像素
所以很明显 激活值越大 神经元就越亮(白)
(2)神经元是如何连接起来的?
于是 784个神经元就构成了神经网络的第一层
graph LR
784个神经元-->神经网络的第一层
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SRiVR5kH-1584794462729)(https://note.youdao.com/yws/public/resource/5d4cbaf02375d65bc4dae659b12e2d7b/xmlnote/B68E1ABBC19443CC84A14C221C02AAA1/337)]
现在到了最后一层
最后一层有十个神经元 分别代表0-9

而这十个神经元的激活值
代表系统对图像里数字判断的可能性
中间的我们叫做“隐含层”
隐含层 Hidden layers
在这个实例中 我们假设隐含层都有16个神经元
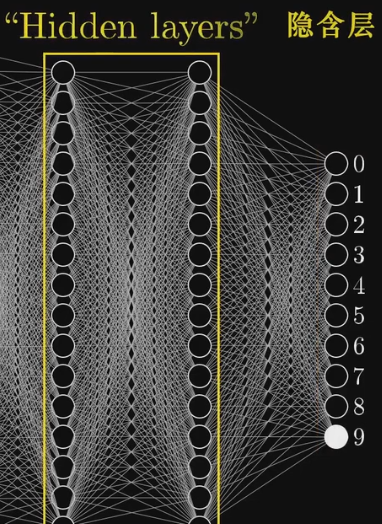
我们先把隐含层看成“大黑箱” 里面进行着处理识别数据的工作
神经网络运作时 上一层激活值将决定下一层的激活值
这里让人联想到生物学中 神经元的神经传递
只不过还是很浅显的 因为这是单层的(MLP) 而真正的神经网络是 纵横交错的
所以说 神经网络处理信息的核心机制正是
一层的激活值是通过怎样的计算 算出下一层的激活值的
其实就是想模仿神经元的传导
一个神经元兴奋,刺激下一个神经元兴奋。
当MLP已经被训练好了 可以识别数字了
那么它的整个流程就是
graph LR
图片对应像素-->|输入像素灰度值|网络输入神经层的784个神经元
网络输入神经层的784个神经元-->代表图案
代表图案-->|n层图案|输出层
输出层-->判断结果
网络每层间如何影响我们还没有学
还有训练过程的数学原理
为什么这样的层状结构可以做到智能判断?
好像中间层(隐含层)是关键
我们在认识数字时候 可能我们意识不到 但我们是这样认识的

我们把9分成了“上面”的一个“圆”和“一条长竖”
8则分成了上下的两个圆
4分成了三笔
我们希望这是最后一层 然后最后一层的组合让我们判断数字各自的概率
接着就是一个常用的、有效的思想
还是“分而治之”的思想
也是化大为小 逐个击破
我们把分开的各部分再拆开

我们可以把接收的像素(灰度值)对应这样的 “短边”
现在我们希望这是神经网络的第二层
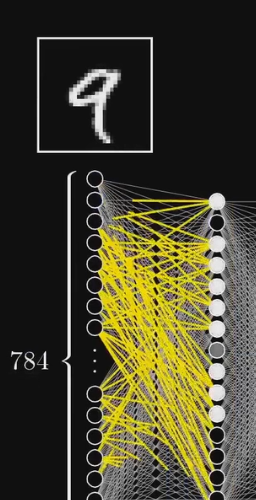
这是输入图像
我们希望输入的灰度值在第二层的时候可以点亮
关联短边的所有神经元
接着是
对应顶部圆圈和长条的神经元
最后点亮
对应9字的神经元
如果神经网络真能完成这类边缘和图案
它就能很好地完成其他图像的识别任务上来
除了图像识别 很多其他人工智能的任务
都可以转化为抽象元素 一层层的抽丝剥茧
这个方法 也可以运用到生活中来
把大问题拆分成n个小问题 逐个解决
像语音识别 人工智能可以把
音频分解成一个个音节(英文)
逐层点亮 最后判断出单词、短语最后是句子
我们还需要知道层层之间到底是怎么激活的
刚刚我们说过 我们希望第二层是短边
如果我们能根据输入层的灰度值
得到短边的存在
那么第一层就相当于“激活”了第二层
接下来我们开始做这件事情
我们来求一个加权和
首先 要知道 我们确定一个区域是否存在短边
我们则会“注意力”不同程度的放在不同的区域
对于区域外的不可能对区域内的短边是否存在有影响 那我们就应该把注意力赋值0

而在区域内 我们需要把注意力根据需要赋值0-1的数
现在我们把注意力叫成权重
我们可以理解权重是注意力数字程度的体现

每个像素的灰度值以它的权重就得到了我们关注区域的加权和(像素和)
如果我们想识别出这里是否存在一条短边
我们只需要给周围一圈像素赋予负的权重
这样当中间像素亮 周围像素暗时
根据下面的式子 我们就会得到最大的加权和
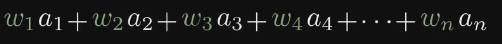
a是第一层神经元的灰度值
但是我们需要在神经元中储存的是一个0-1的数字

于是我们引进一个函数
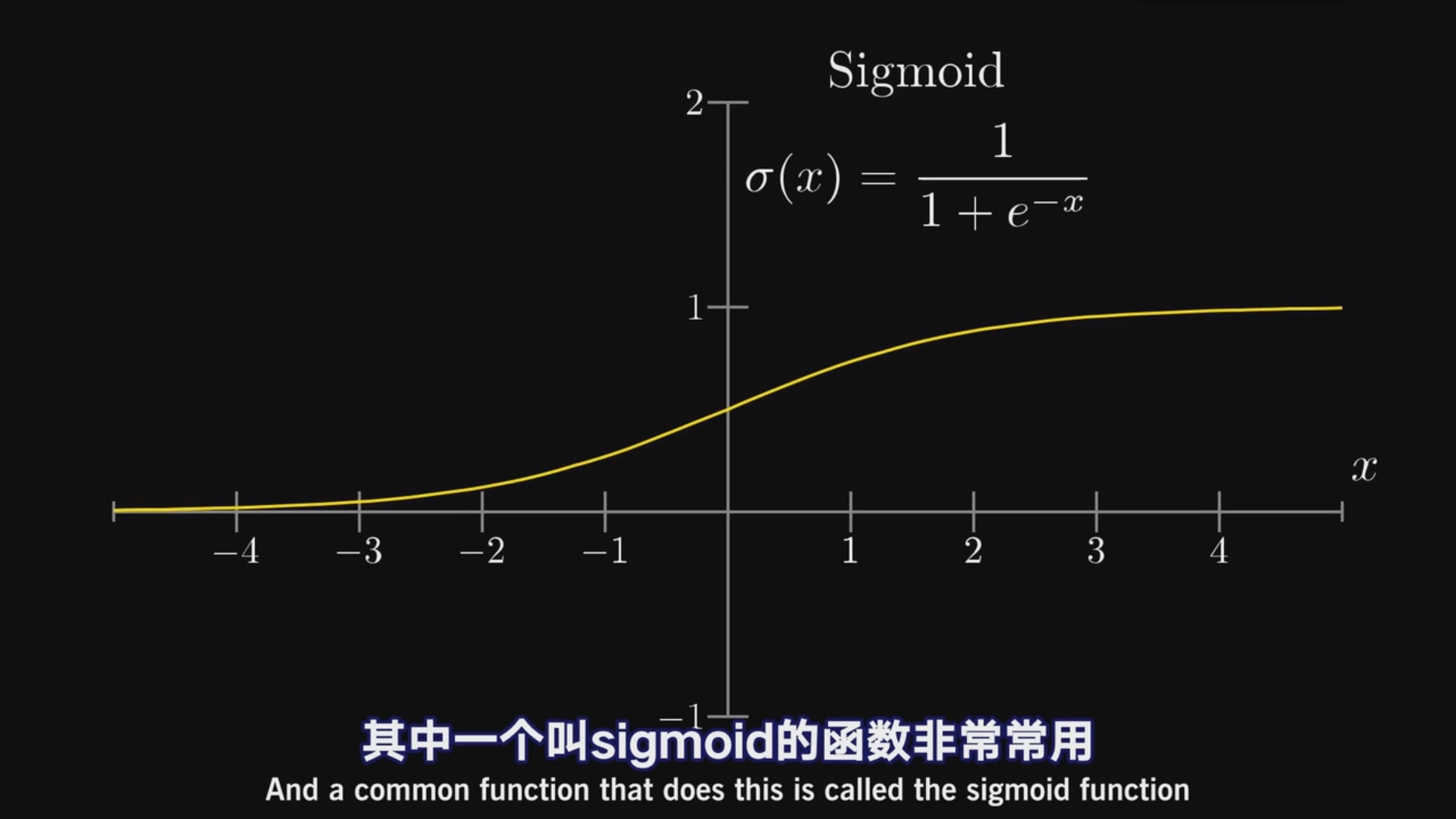
也叫logistic曲线(逻辑斯蒂)
考虑到点亮神经元的难易程度
有时我们并不想它那么容易点亮
于是我们就会设置一个“偏置”(bias)
我的理解是就像神经元要兴奋会有一个“阈值” 只有超过阈值时我们才会点亮神经元

总结说:“权重告诉我们第二层的神经元关注什么样的图案”
“偏置则告诉你加权和得有多大”
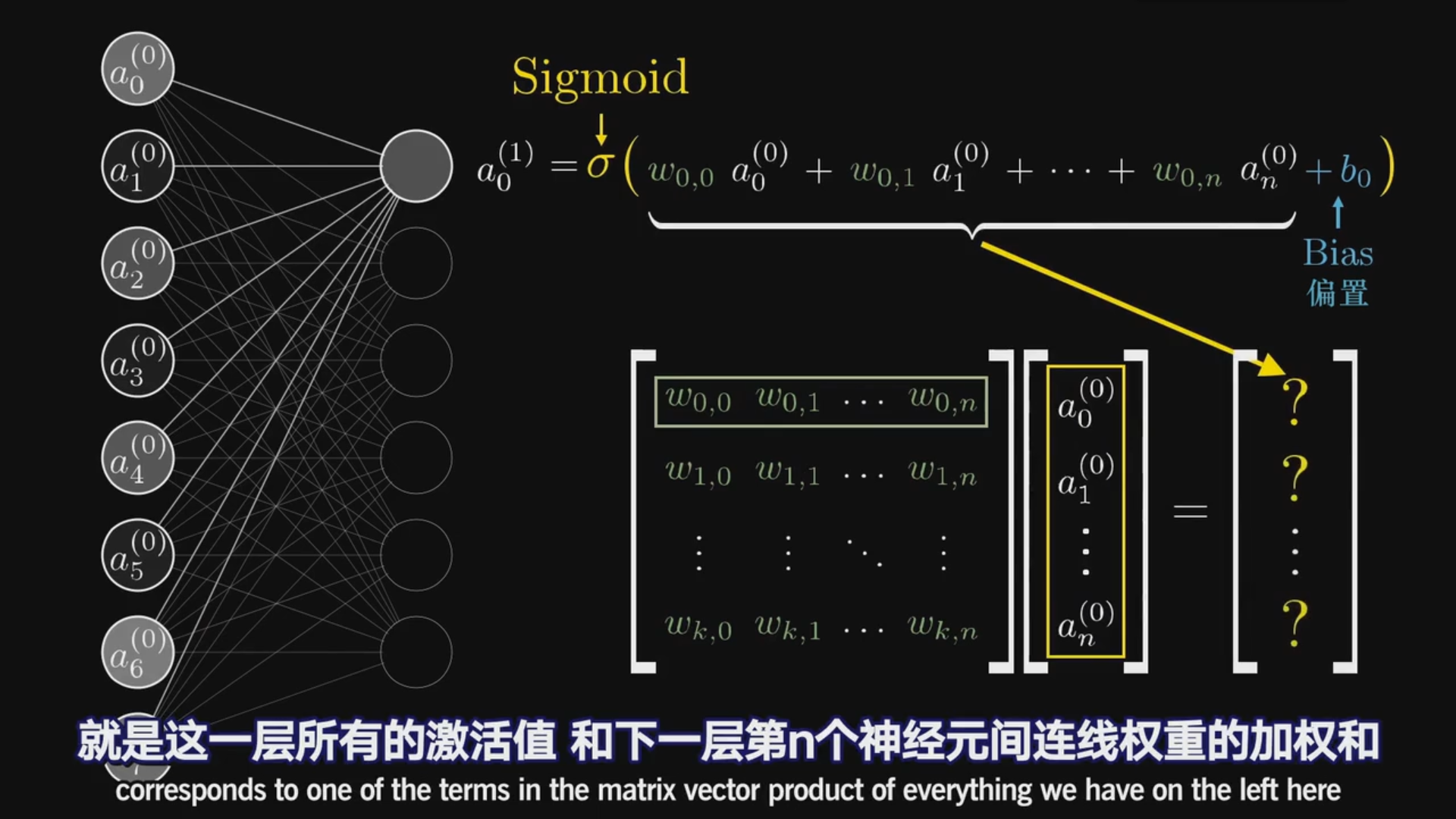
同样的 根据加权算出第二层所有的神经元的“灰度值”
这其中我们要考虑的权重计算有784×16+16×16+16×10
从第二层开始每一个神经元都有一个bias则16+16+10
正是这么多的权重(13,002)让结果变得更加准确
下面是激活值用矩阵(更好理解也更专业)的表达


于是矩阵的n行即是对应层神经元的个数
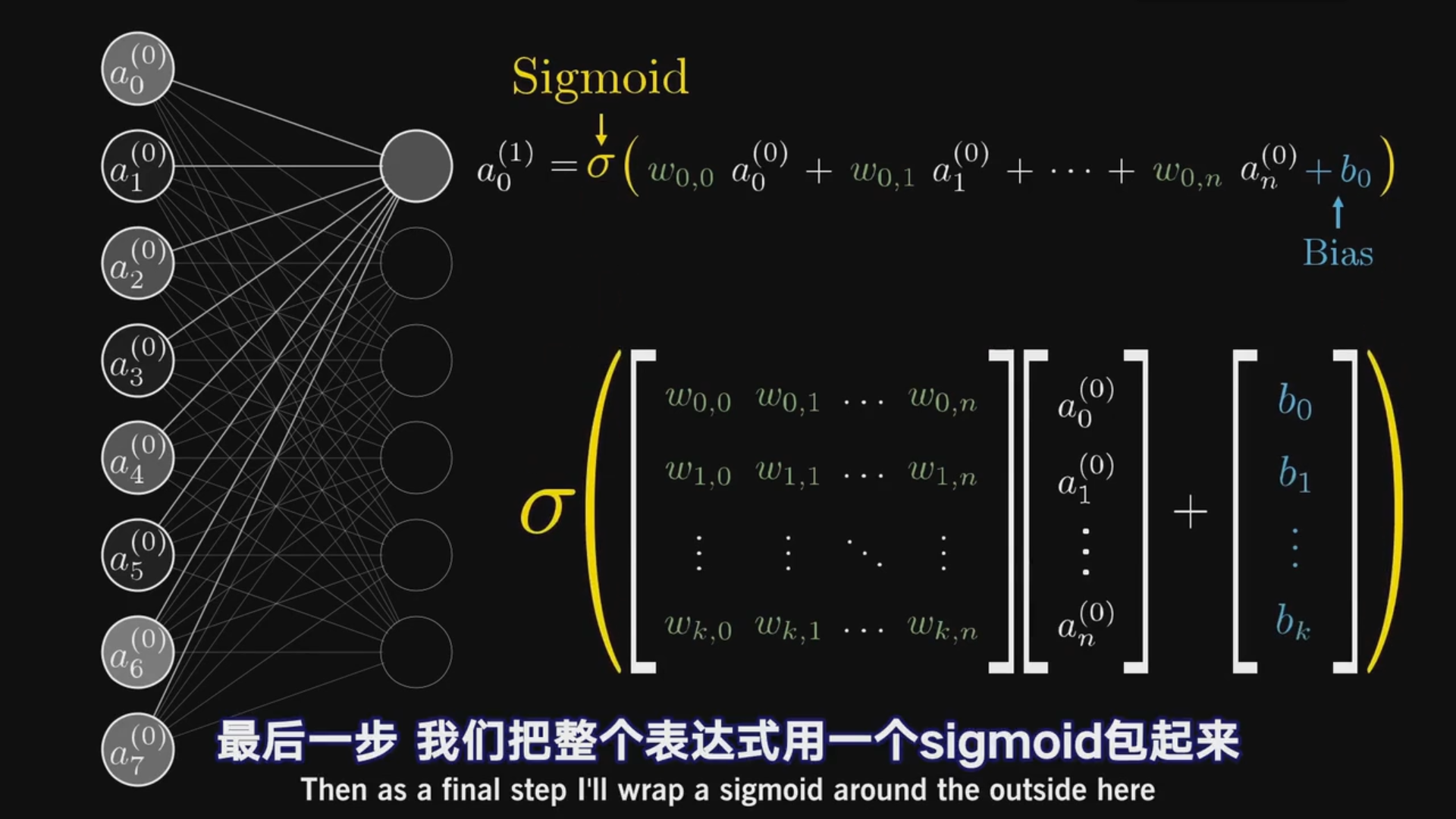
加权和 加上偏置 再取sigmoid就可以了
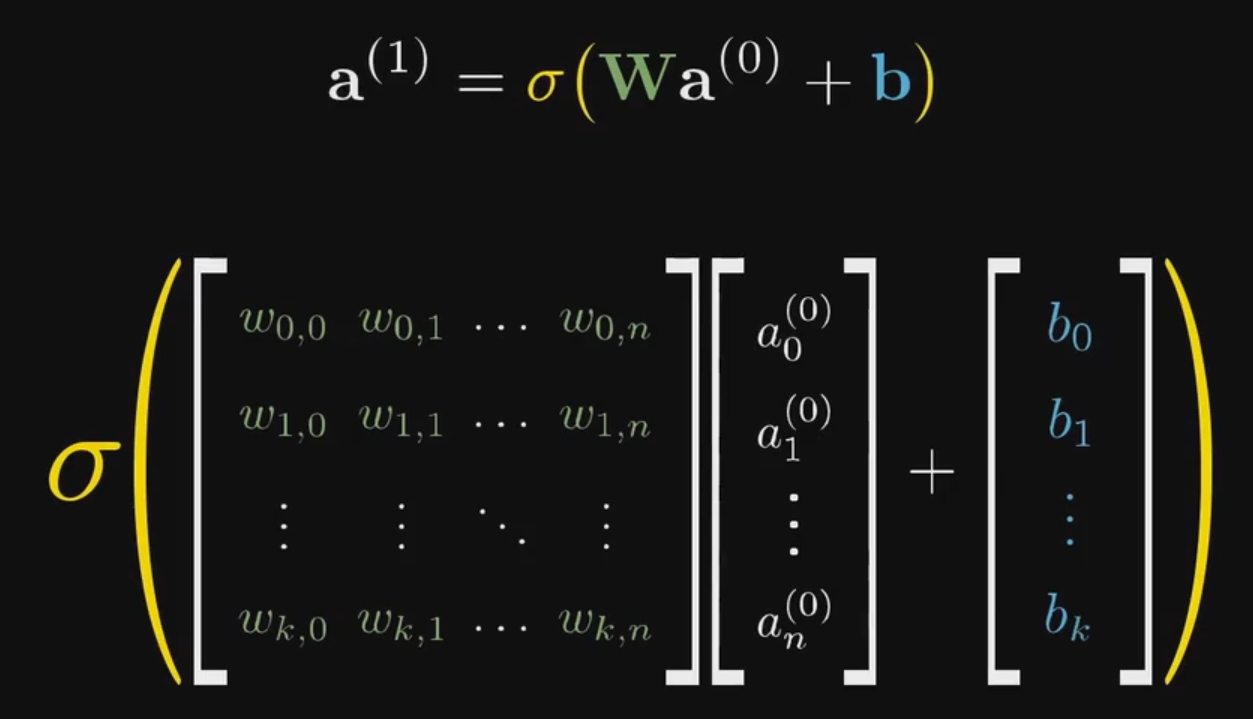
线代很重要
值得一提的是sigmoid因为训练得太慢了
所以很多神经网络更多用的是线性整流函数(Rectified Linear Unit, ReLU)
这样我们就可以得到层与层之间的灰度关系
现在回过头来看神经元 它更像是一个函数 值域是0-1
它的输入则是上一层所有神经元的输出
再进一步想其实整个神经网络就是一个函数 输出0-9的整数
好啦 这样看完这个视频
MLP神经网络的结构以及传递的原理已经很清晰了
学习目的
(要带着目的 问题去看视频)
1.理解神经网络为什么会是这样的结构?
2.明白机器网络“学习”究竟代表什么。
(接下来的几个视频只会讨论
最简单的原味版 多层感知器MLP)
MLP = multilayer perceptron 多层感知器
一、神经网络的结构(p1)
(目前只有p1)
MLP的神经网络结构
从左到右 顾名思义“多层”
MLP已经能够识别手写的数字
既然神经网络之名来源于人的大脑结构
graph LR
神经元[神经元]-->|层层连接|神经网络[神经网络]
那么
(1)我们先看看什么是神经元?
我们先把他理解成一个用来装数字的容器
装着0-1之间的数字 就这么简单
像这张图片里的“9” 有28×28=784个像素
我们让每一个像素对应一个神经元
神经元中装着的数字代表对应像素的灰度值
神经元里面的值叫做 “激活值(Activation)”
0表示纯黑像素 1表示纯白像素
所以很明显 激活值越大 神经元就越亮(白)
(2)神经元是如何连接起来的?
于是 784个神经元就构成了神经网络的第一层
graph LR
784个神经元-->神经网络的第一层
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fX7hO3Ln-1584794529592)(https://note.youdao.com/yws/public/resource/5d4cbaf02375d65bc4dae659b12e2d7b/xmlnote/B68E1ABBC19443CC84A14C221C02AAA1/337)]
现在到了最后一层
最后一层有十个神经元 分别代表0-9
而这十个神经元的激活值
代表系统对图像里数字判断的可能性
中间的我们叫做“隐含层”
隐含层 Hidden layers
在这个实例中 我们假设隐含层都有16个神经元
我们先把隐含层看成“大黑箱” 里面进行着处理识别数据的工作
神经网络运作时 上一层激活值将决定下一层的激活值
这里让人联想到生物学中 神经元的神经传递
只不过还是很浅显的 因为这是单层的(MLP) 而真正的神经网络是 纵横交错的
所以说 神经网络处理信息的核心机制正是
一层的激活值是通过怎样的计算 算出下一层的激活值的
其实就是想模仿神经元的传导
一个神经元兴奋,刺激下一个神经元兴奋。
当MLP已经被训练好了 可以识别数字了
那么它的整个流程就是
graph LR
图片对应像素-->|输入像素灰度值|网络输入神经层的784个神经元
网络输入神经层的784个神经元-->代表图案
代表图案-->|n层图案|输出层
输出层-->判断结果
网络每层间如何影响我们还没有学
还有训练过程的数学原理
为什么这样的层状结构可以做到智能判断?
好像中间层(隐含层)是关键
我们在认识数字时候 可能我们意识不到 但我们是这样认识的
我们把9分成了“上面”的一个“圆”和“一条长竖”
8则分成了上下的两个圆
4分成了三笔
我们希望这是最后一层 然后最后一层的组合让我们判断数字各自的概率
接着就是一个常用的、有效的思想
还是“分而治之”的思想
也是化大为小 逐个击破
我们把分开的各部分再拆开
我们可以把接收的像素(灰度值)对应这样的 “短边”
现在我们希望这是神经网络的第二层
这是输入图像
我们希望输入的灰度值在第二层的时候可以点亮
关联短边的所有神经元
接着是
对应顶部圆圈和长条的神经元
最后点亮
对应9字的神经元
如果神经网络真能完成这类边缘和图案
它就能很好地完成其他图像的识别任务上来
除了图像识别 很多其他人工智能的任务
都可以转化为抽象元素 一层层的抽丝剥茧
这个方法 也可以运用到生活中来
把大问题拆分成n个小问题 逐个解决
像语音识别 人工智能可以把
音频分解成一个个音节(英文)
逐层点亮 最后判断出单词、短语最后是句子
我们还需要知道层层之间到底是怎么激活的
刚刚我们说过 我们希望第二层是短边
如果我们能根据输入层的灰度值
得到短边的存在
那么第一层就相当于“激活”了第二层
接下来我们开始做这件事情
我们来求一个加权和
首先 要知道 我们确定一个区域是否存在短边
我们则会“注意力”不同程度的放在不同的区域
对于区域外的不可能对区域内的短边是否存在有影响 那我们就应该把注意力赋值0
而在区域内 我们需要把注意力根据需要赋值0-1的数
现在我们把注意力叫成权重
我们可以理解权重是注意力数字程度的体现
每个像素的灰度值以它的权重就得到了我们关注区域的加权和(像素和)
如果我们想识别出这里是否存在一条短边
我们只需要给周围一圈像素赋予负的权重
这样当中间像素亮 周围像素暗时
根据下面的式子 我们就会得到最大的加权和
a是第一层神经元的灰度值
但是我们需要在神经元中储存的是一个0-1的数字
于是我们引进一个函数
也叫logistic曲线(逻辑斯蒂)
考虑到点亮神经元的难易程度
有时我们并不想它那么容易点亮
于是我们就会设置一个“偏置”(bias)
我的理解是就像神经元要兴奋会有一个“阈值” 只有超过阈值时我们才会点亮神经元
总结说:“权重告诉我们第二层的神经元关注什么样的图案”
“偏置则告诉你加权和得有多大”
同样的 根据加权算出第二层所有的神经元的“灰度值”
这其中我们要考虑的权重计算有784×16+16×16+16×10
从第二层开始每一个神经元都有一个bias则16+16+10
正是这么多的权重(13,002)让结果变得更加准确
下面是激活值用矩阵(更好理解也更专业)的表达
于是矩阵的n行即是对应层神经元的个数
加权和 加上偏置 再取sigmoid就可以了
线代很重要
值得一提的是sigmoid因为训练得太慢了
所以很多神经网络更多用的是线性整流函数(Rectified Linear Unit, ReLU)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









