






matlab程序:含冰蓄冷装置的冷电联供型微网经济优化运行
摘要:针对冷电联供型微网的运行成本优化,引入冰蓄冷储能系统,建立了含光伏、风电、微型燃气轮机、电储能和冰蓄冷等可再生能源和常规能源以及冷电储能装置的优化模型。
以经济运行成本最小为目标,运用混合线性整数规划方法,并利用数学优化软件 CPLEX 求解。
最后在算例中建立 3 种不同场景的冷电联供微网系统进行对比分析,验证了本文所建立模型的有效性和可行性,结果表明含冰蓄冷装置的冷电联供型微网能够有效地降低运行成本,电储能和冷储能结合与单一储能模式相比具有显著的经济效益,体现了综合能源利用和优化。
ID:69100669486398675
Seven
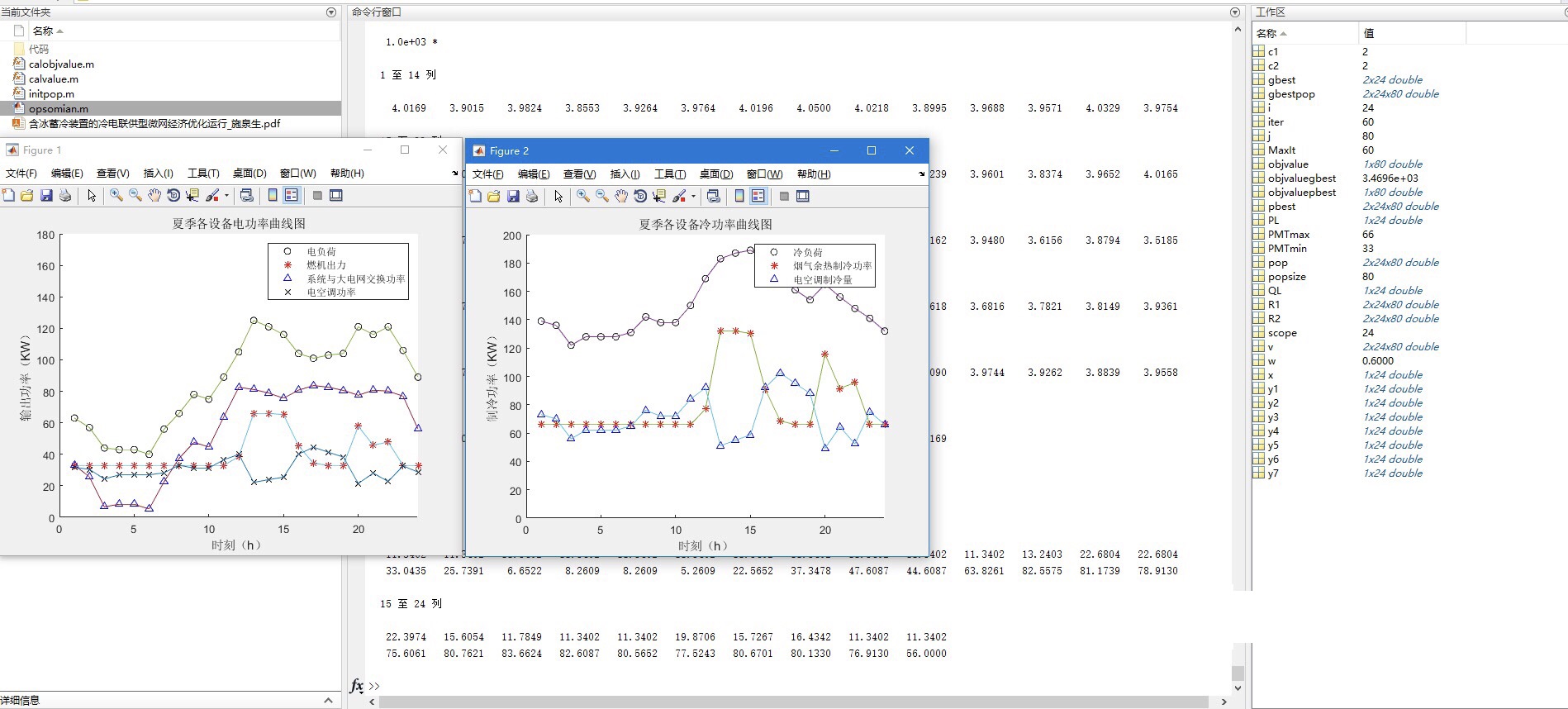
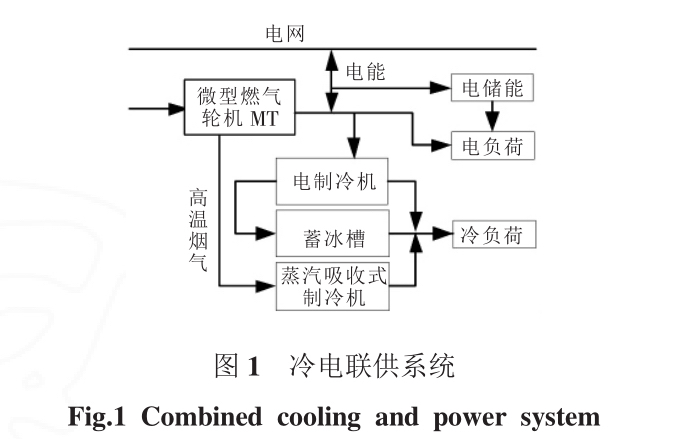

摘要:随着能源消耗的不断增加,传统的能源供应方式已经面临着极大的挑战。为了实现能源的高效利用和经济优化运行,冷电联供型微网已成为一个备受关注的研究领域。为了降低运行成本,本文引入了冰蓄冷储能系统,并建立了含光伏、风电、微型燃气轮机、电储能和冰蓄冷等多种能源的优化模型。通过混合线性整数规划方法和数学优化软件CPLEX的应用,使得微网的运行成本最小化。
在算例分析中,本文建立了三种不同场景的冷电联供微网系统,进行了对比分析,验证了所建立模型的有效性和可行性。结果显示,含冰蓄冷装置的冷电联供型微网能够有效地降低运行成本,并且电储能和冷储能的结合相较于单一储能模式具有显著的经济效益,充分体现了综合能源利用和优化的优势。
第一部分:引言
1.1 研究背景和意义
1.2 国内外研究现状
1.3 本文的研究目的和内容
第二部分:冷电联供型微网的组成和运行原理
2.1 冷电联供型微网的定义和概念
2.2 冷电联供型微网的组成和结构
2.3 冷电联供型微网的运行原理
第三部分:含冰蓄冷装置的冷电联供型微网优化模型的建立
3.1 冷电联供型微网的运行成本分析
3.2 冷电联供型微网优化模型的建立
3.3 冷蓄冷装置的引入和优化策略
第四部分:混合线性整数规划方法和数学优化软件CPLEX的应用
4.1 混合线性整数规划方法的基本原理
4.2 数学优化软件CPLEX的介绍和应用
第五部分:算例分析和结果验证
5.1 算例设置和数据收集
5.2 不同场景的冷电联供微网系统对比分析
5.3 结果分析和经济效益评估
第六部分:结论和展望
6.1 主要研究成果总结
6.2 存在的不足和改进方向
6.3 对未来发展的展望和建议
通过以上的结构安排和内容展开,本文全面分析了含冰蓄冷装置的冷电联供型微网的经济优化运行。通过引入冰蓄冷储能系统并建立多种能源的优化模型,采用混合线性整数规划方法和数学优化软件CPLEX的应用,本文验证了含冰蓄冷装置的冷电联供型微网能够有效地降低运行成本,并体现了综合能源利用和优化的优势。本研究对于推动冷电联供型微网的发展和应用具有重要的指导意义,为实现能源的高效利用和经济优化运行提供了有益的参考。
以上相关代码,程序地址:http://matup.cn/669486398675.html















 1838
1838

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









