









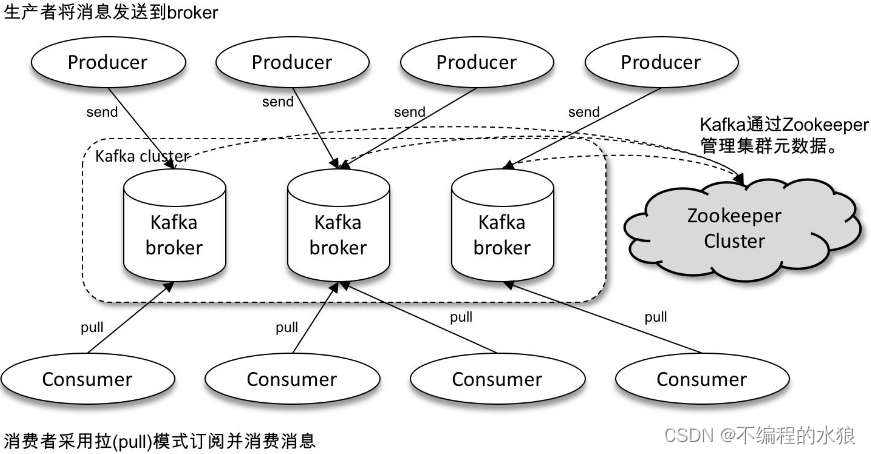
一个典型的Kafka体系架构包括多个Producer,多个Broker,多个Consumer以及一个Zookeeper集群。
Zookeeper负责Kafka集群元数据的管理、控制器的选举等操作;
Producer负责生产消息发送到Broker;
Broker负责将收到的消息存储到磁盘;
Consumer负责从Broker订阅并消费消息;
Kafka体系结构
Kafka核心概念:topic与partition
Kafka底层实现来说,topic和partition都是逻辑上的概念,topic划分为多个分区分布在多个broker集群上,分区可以有1至多个副本,每个副本对应一个日志文件,每个日志文件对应1至多个日志分段(LogSegment),每个日志分段还可以细分为索引文件、日志存储文件、快照文件;
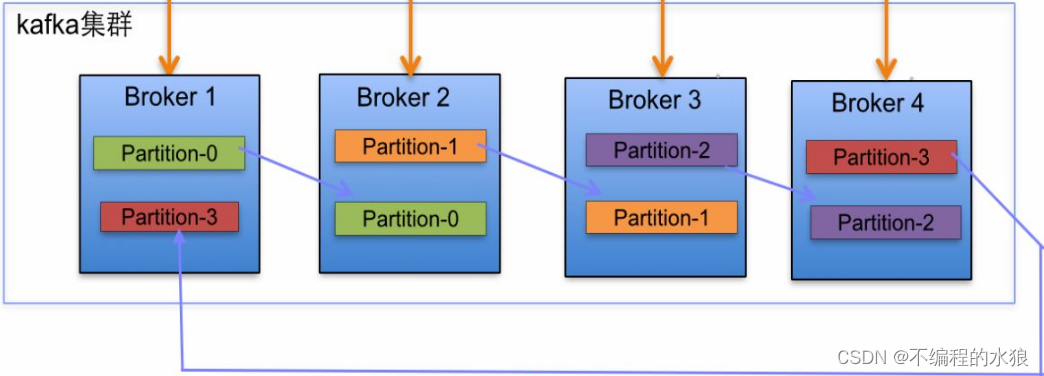
Broker集群的多分区多副本分布
- 4分区2副本的Topic在4个broker集群的分布如下:
分区写入策略(生产者端)
上面提到消息发送至Broker集群存在多分区的情况下,Kafka是如何选择哪个分区存储呢?
这里则需要引入分区策略概念,所谓分区策略是决定生产者将消息发送到哪个分区的算法;
- Kafka在Producer配置中,partitioner.class 配置项可指定自定义分区算法,需配置全限定类名(需实现Partitioner接口);
- 同时Kafka提供了三种可配置分区算法类
1.默认分区算法(DefaultPartitioner):通过计算消息key的hash值取分区数的模 = 选择的分区号
// hash the keyBytes to choose a partition
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
- 轮询分区算法(RoundRobinPartitioner):通过集群内可用的分区数进行轮询计算选择的分区号
int nextValue = nextValue(topic);
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (!availablePartitions.isEmpty()) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// no partitions are available, give a non-available partition
return Utils.toPositive(nextValue) % numPartitions;
}
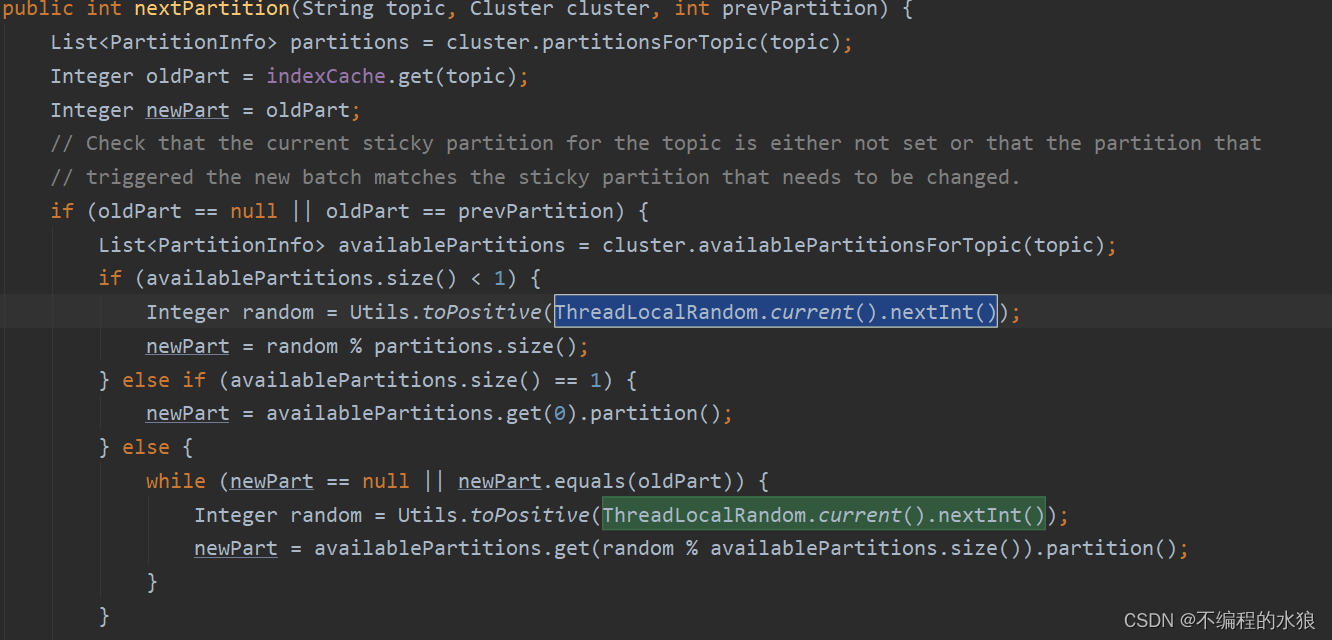
3.Sticky分区算法(UniformStickyPartitioner): 沿用上一次选择的topic分区号,若没有则随机。
Integer part = indexCache.get(topic);
if (part == null) {
return nextPartition(topic, cluster, -1);
}
return part;
分区分配策略(消费者端)
同一个Group组的多个消费者是如何消费一个Topic多个Partition的消息?
- Kafka在Consumer配置中,partition.assignment.strategy 配置项可指定某种分区分配策略,Kafka提供了三种分区分配策略
1.RangeAssignor(默认-范围分区)
对消费者进行排序,使用 分区数/消费者数=n,第i个消费者则消费n*i~ n(i+1)的分区编号的分区,平均每个消费者都消费n个分区,剩余的分区都分配至第一个消费者。
2.RoundRobinAssignor(轮询分区)
按照消费者 顺序依次分配分区,在消费组里的消费者订阅Topic相同时,分区数分布最为均匀。
使用轮询分区策略必须满足两个条件:
(1)每个主题的消费者实例具有相同数量的流
(2)每个消费者订阅的主题必须是相同的
3.StickyAssignor(粘滞分区)
目标:分区的分配尽可能的均匀;分区的分配尽可能和上次分配保持相同;
好处:使得分区发生变化时,由于分区的粘性,减少了不必要的分区移动
分区多副本机制
- kafka为了提高partition的可靠性而提供了副本的概念(Replica),通过副本机制来实现冗余备份
- 一主多从,leader副本负责读写请求,follower副本负责从leader副本同步;
- 此外涉及leader的选举, follower副本的同步
副本同步机制
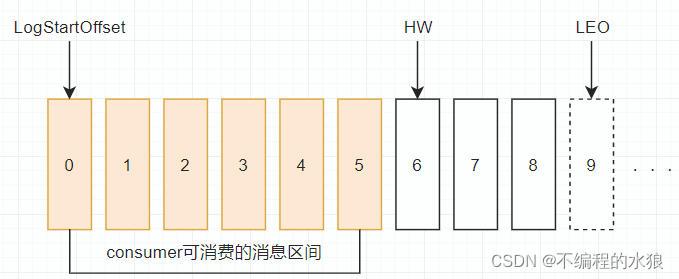
- 要了解Kafka的副本同步机制,就要知道 Kakfa的 ISR,LEO,HW概念
- LEO(Log End Offset): Kafka的每个分区的所有副本都有一个WAL文件,并且采用的是顺序写入,因此kafka会记录分区的写入消息的下一个offset(LEO)
- ISR(In-Sync Replicas)集合:当Follwer副本与Leader副本的LEO的维持在较小的差距则会被加入至ISR集合,即ISR集合里的副本可以认为与Leader副本保持在高度同步的水平。
- HW(High Watermak):即便ISR集合是与Leader副本保持高度同步,仍旧会有差别,因此在ISR集合里最小的LEO则被称为 HW,并且消费者只能消费offset小于 HW的消息;
- 副本同步机制: 根据发送者配置的acks提供 三种模式:
- “all”–等待broker所有isr同步成功后返回
- “1”—等待leader持久化成功后返回
- “0”—无需等待broker持久化直接返回
思考:为什么Kafka的主从模式,不是读写分离模式?
读写分离可以减轻Leader负载,并且更适用于读多写少的场景,并且还需要保持主从高度一致性;而kafka在topic设计上就已经引入了多分区进行负载均衡,所以只需要保证分区的可靠性即可,对主从一致性可做一定的牺牲来提高性能;
Leader 选举
- kafka集群的leader选举,选举出来的leader称为Controller,负责整个集群所有分区Partition和副本follower的状态管理;
- 分区副本Leader选举,leader负责读写,follower负责同步。
参考这篇文章,讲述得很清晰 kafka的Leader选举机制


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









