






本文描述了大模型对于传统机器学习解决问题方面的优化点
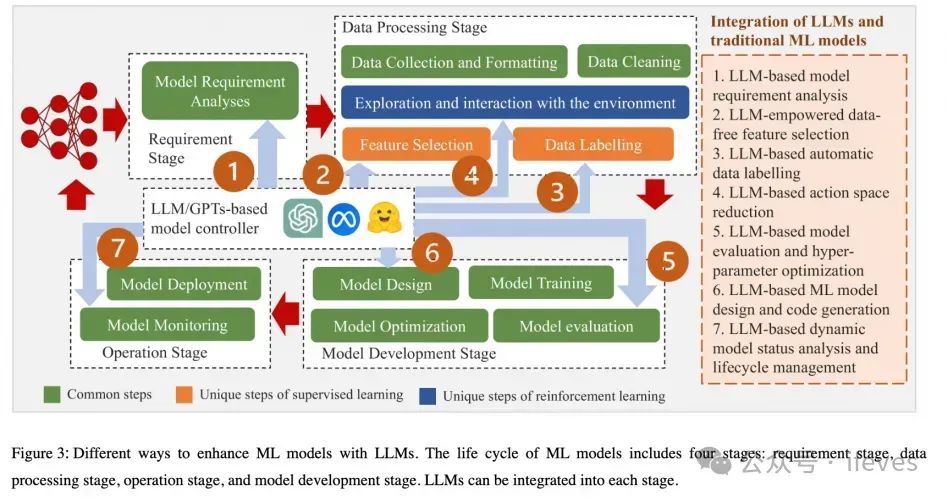
传统机器学习中包括样本构建、数据清洗、特征工程、模型训练、结果评估、结果反馈调参等各个阶段,LLM在各阶段可以实现辅助优化,如下图所示
1. 样本生成
使用llm构造样本:思路为用自然语言来对样本进行描述,从而生成、改写、扩展样本数据
Borisov, V., Sessler, K., Leemann, T., Pawelczyk, M., & Kasneci, G. (2022). Language Models are Realistic Tabular Data Generators. arXiv preprint arXiv:2210.06280.
样本特征用自然语言描述,输入llm进行自监督训练;输入样本描述片段(部分属性),llm输出完整自然语言描述的样本
Yu, Yue, et al. "Large Language Model as Attributed Training Data Generator: A Tale of Diversity and Bias." Advances in Neural Information Processing Systems, vol. 36, 2023.
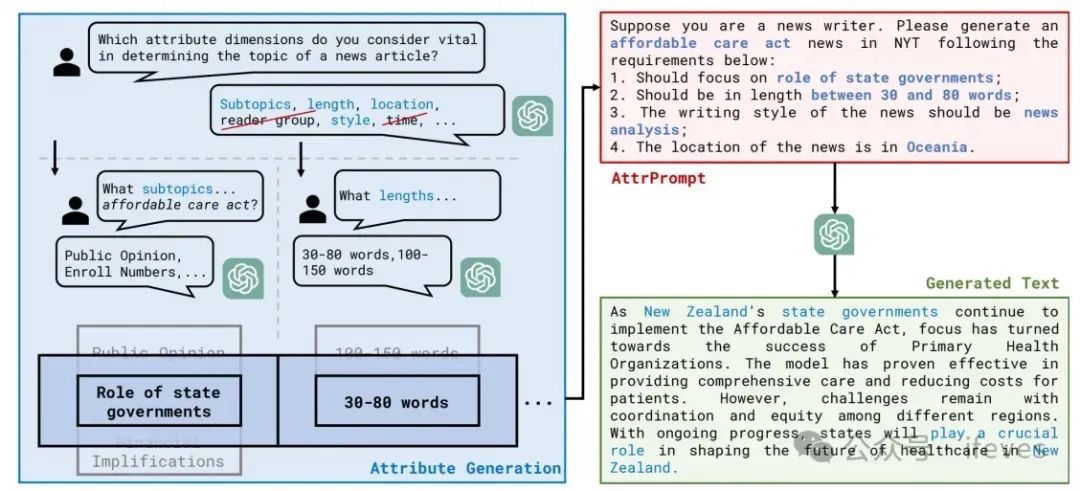
通过prompt输入llm回答哪些特征比较重要
再针对得到的特征种类,分别问每个特征的取值范围
从以上答案中选取组合,构造一个生成数据样本的描述的prompt,输入给llm,得到生成样本,如下图所示
Chen, J., Zhang, Y., & Zhang, Y. (2023). Self-Guided Noise-Free Data Generation for Efficient Zero-Shot Classification. In Proceedings of the International Conference on Learning
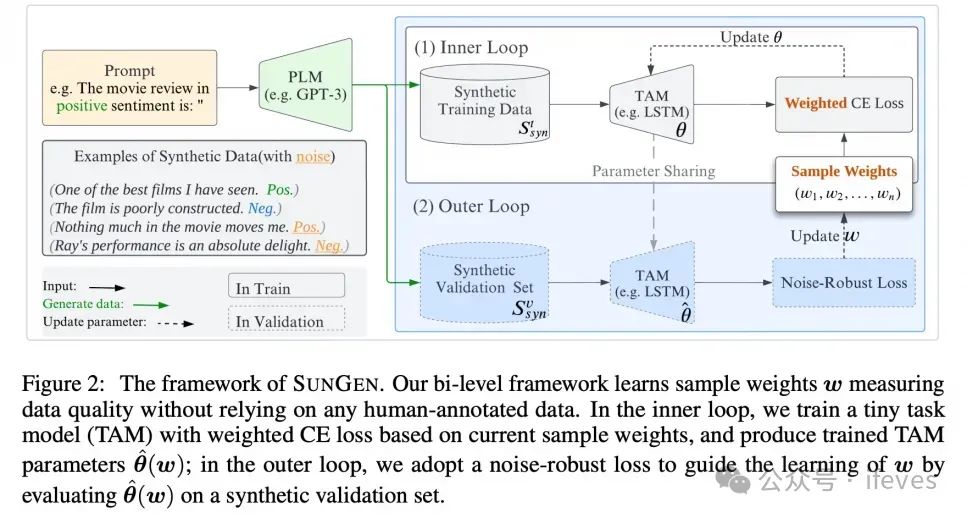
先用llm生成样本:直接指定类别,将类别的描述、特征等输入llm,得到一个生成的数据集
在生成的数据集上通过一个两层相互迭代的优化,更新生成样本中各个样本的权重。通过多次迭代,样本的权重会逐渐分开,最终采样选取高权重的样本出来作为训练样本
挑战
可能会引入bias、无关的特征、噪声等
版权问题、隐私问题等
2. 数据清洗
将样本用自然语言描述,直接问llm某个属性是否是有错、或者是否是离群点;对于缺失值直接让llm给出填充数据
Narayan, A., Chami, I., Orr, L., & Ré, C. (2022). Can Foundation Models Wrangle Your Data?. Proceedings of the VLDB Endowment, 16(4), 738-746
用不同的agent,特征精炼+数据填补
autom3l(mm2024):
特征精炼agent——输入prompt包含特征精炼示例集(包括引入不相关特征,删除冗余特征)、属性名称(包含语义信息)、特征模态(二元、类别、数值等)、任务描述等,输出精炼后的特征集合
数据填补agent——输入prompt包含数据缺失样本、数据填补示例(从数据集中随机选一些样本,遮盖部分特征)、任务描述等,输出填补后的样本
挑战:特征理解可能出错,缺少特定问题的专家经验等
3. 特征工程
3.1. 特征选择
针对已有特征的重要性评估,LMPriors(2022):提供task信息,特征打标规则,一些特征的示例,回答某个特征是否有用

Choi K, Cundy C, Srivastava S, et al. Lmpriors: Pre-trained language models as task-specific priors[J]. arXiv preprint arXiv:2210.12530, 2022
LLM-Select(2024):提供候选特征,问打分、排序、下一个(对话式,给定已有的部分特征序列)
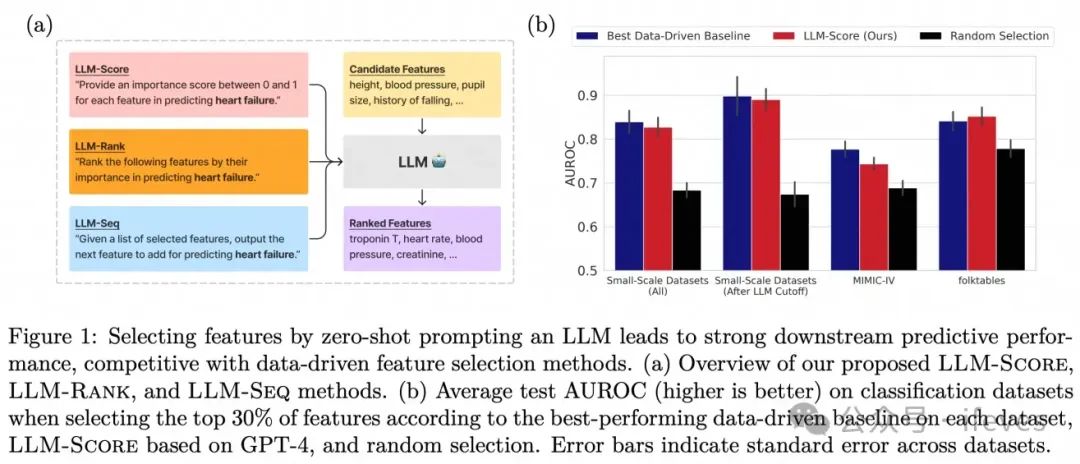
Jeong, D., Kornblith, S., & Shlens, J. (2024). LLM-Select: Feature Selection with Large Language Models. arXiv preprint arXiv:2407.02694
autom3l:特征精炼
o, D., Feng, C., Nong, Y., & Shen, Y. (2024). AutoM3L: An Automated Multimodal Machine Learning Framework with Large Language Models. In Proceedings of the 32nd ACM International Conference on Multimedia (MM '24). ACM, New York, NY, USA, 9 pages
挑战:预训练的llm可能存在bias,导致特征选择也存在bias
3.2. 特征提取
利用LLM生成额外新特征
embedding: 文本特征做embedding
llm生成新特征
使用大模型学习到领域知识,将特定任务数据集prompt给大模型,生成额外的辅助信息(对 item 或 user 的描述、标签、知识图谱补全)作为新的特征
将数据分析分组、针对不同难易的数据分组选择合适的prompt及llm,生成新的特征。
Einy Y, Milo T, Novgorodov S. Cost-Effective LLM Utilization for Machine Learning Tasks over Tabular Data[C]//Proceedings of the Conference on Governance, Understanding and Integration of Data for Effective and Responsible AI. 2024: 45-49.
Portisch, J., & Paulheim, H. (2022). Relational data embeddings for feature enrichment with external knowledge bases. Machine Learning, 111(3), 1369-1407.
llm生成特征工程代码:
编写prompt,输入任务、已知数据集的描述,按模版输出(特征,特征有用的解释,特征计算的代码),添加特征后run出新的结果,加入到prompt中继续迭代(CAAFE,Nips2023)
3.3. 特征融合
基于已有特征组合,生成新特征
使用llm agents对已有特征集合、操作符集合进行组合,生成新的特征,并进行效果验证与迭代搜索
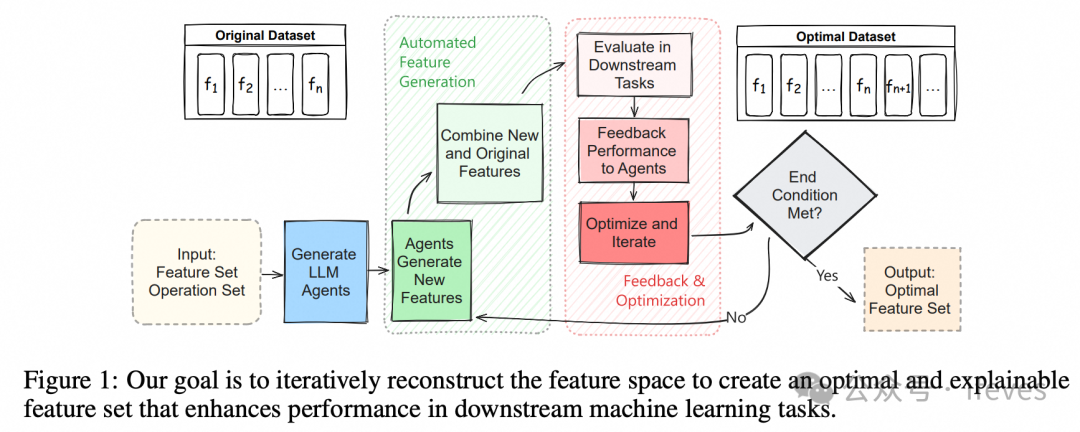
Zhang, X., Zhang, J., Rekabdar, B., Zhou, Y., Wang, P., & Liu, K. (2024). Dynamic and Adaptive Feature Generation with LLM. arXiv preprint arXiv:2406.03505.
异构特征融合(推荐系统领域):筛选出样本的异构特征(用户的点击、加购、等异构行为特征)通过文本prompt给大模型,输出自然语言描述作为融合后的特征。根据不同的具体任务,构建对应的指令集来finetune大模型。然后可以再沿用FeSTE的方法,将finetune后大模型的输出作为新的特征和原始数据连接,用于训练ml模型
TableLLM:使用text template把各个属性用转换成自然语言描述,并结合prompt指令作为输入,目标类别的判断作为输出。用这样的输入、输出finetune大模型(very-few shot的情况下大模型效果更好)
大模型对label的预测结果作为一个特征:利用LLM 的外部通用知识和逻辑推理能力,主要是利用大模型的 In-Context Learning能力。可以是直接让大模型进行排序 or 重排
对于某个属性类别的预测问题重构为<context, class, label>的句子对分类问题,使得即使不同数据集的类别不同都能以一个统一的任务形式去finetune大模型
Harari, A., & Katz, G. (2022). Few-Shot Tabular Data Enrichment Using Fine-Tuned Transformer Architectures. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1577-1591. Association for Computational Linguistics.
引申:可以使用领域知识预料构建一个类似于DBpedia的结构化知识库,然后沿用FeSTE的方法
4. 模型训练
4.1. 模型选择
基于检索的方法
主要是需求层面的选择:llm解析用户的需求,和已有模型的描述(提前建好,或者通过llm根据论文等信息生成),选择匹配度最高的模型
MLCopilot(2023):
offline-stage:收集历史ml案例(task,code,performance),llm总结成经验(task,model,参数选择,performance评价),llm再从经验总结成一些知识点
online-stage:根据新的task,匹配得到相关的历史经验、知识点,根据检索到的这些信息,prompt给llm,输出solution的描述,包含模型、参数的选择
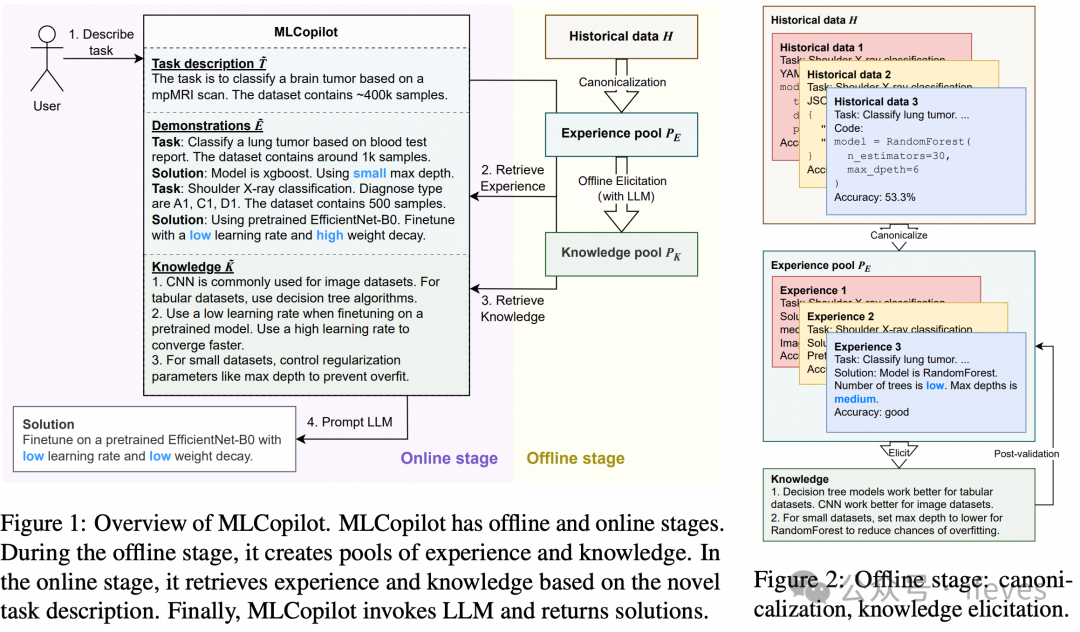
Zhang, L., Zhang, Y., Ren, K., Li, D., & Yang, Y. (2024). MLCopilot: Unleashing the Power of Large Language Models in Solving Machine Learning Tasks. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), 2931–2959. Association for Computational Linguistics.
基于生成的方法
ModelGPT(2024):
requirement generator:用户提供样本数据(特征,label)+描述,llm总结出精炼的task requirement
model customizer:根据用户数据、以及requirement,生成模型,参数(都是神经网络模型)
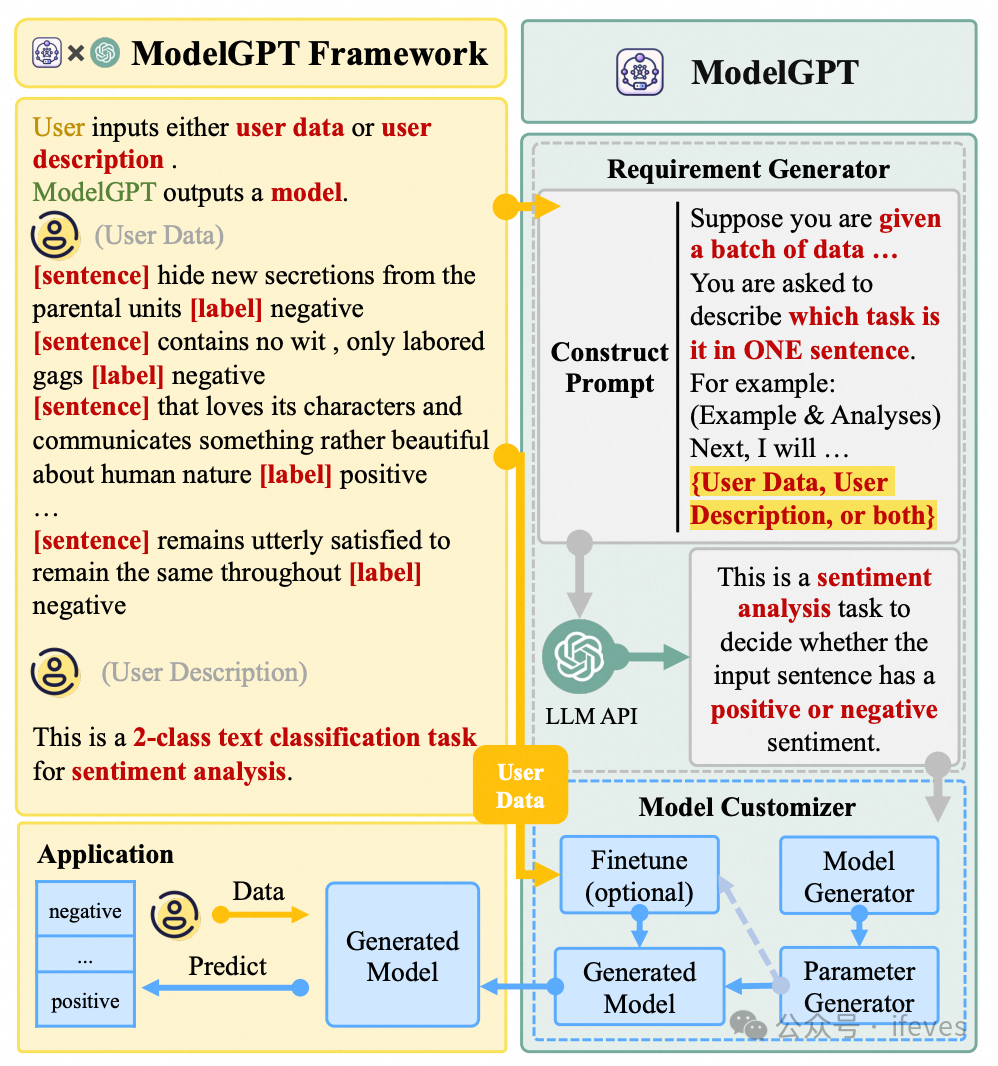
Tang Z, Lv Z, Zhang S, et al. Modelgpt: Unleashing llm's capabilities for tailored model generation[J]. arXiv preprint arXiv:2402.12408, 2024.
4.2. llm指导超参搜索
自动化HPO
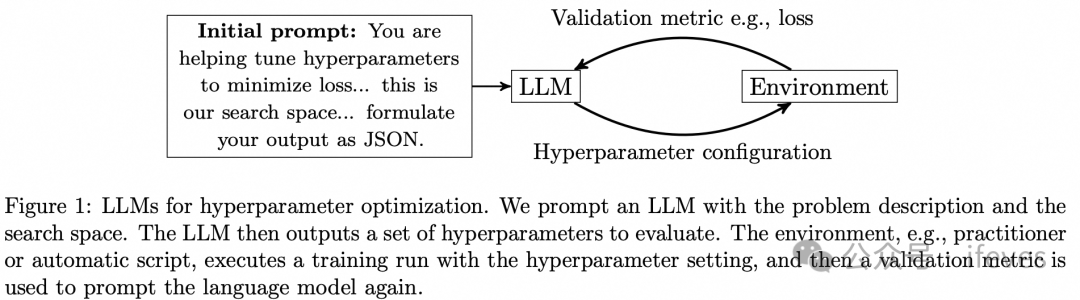
Zhang M R, Desai N, Bae J, et al. Using large language models for hyperparameter optimization[J]. arXiv preprint arXiv:2312.04528, 2023.
AgentHPO(2024)
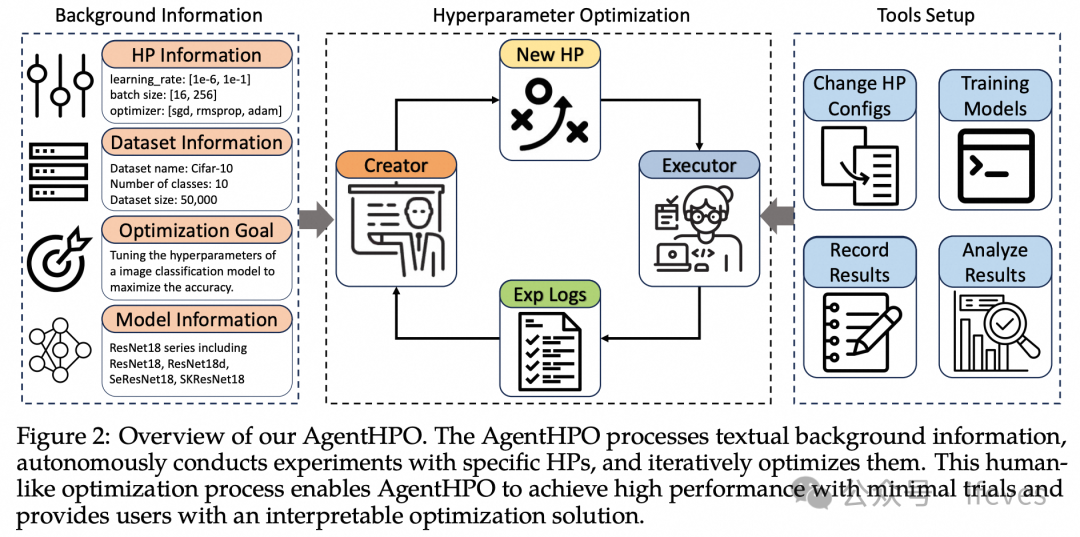
Liu S, Gao C, Li Y. AgentHPO: Large Language Model Agent for Hyper-Parameter Optimization[C]//The Second Conference on Parsimony and Learning (Proceedings Track).
通过llm自动构建ml参数选择-训练-效果评估的迭代pipeline
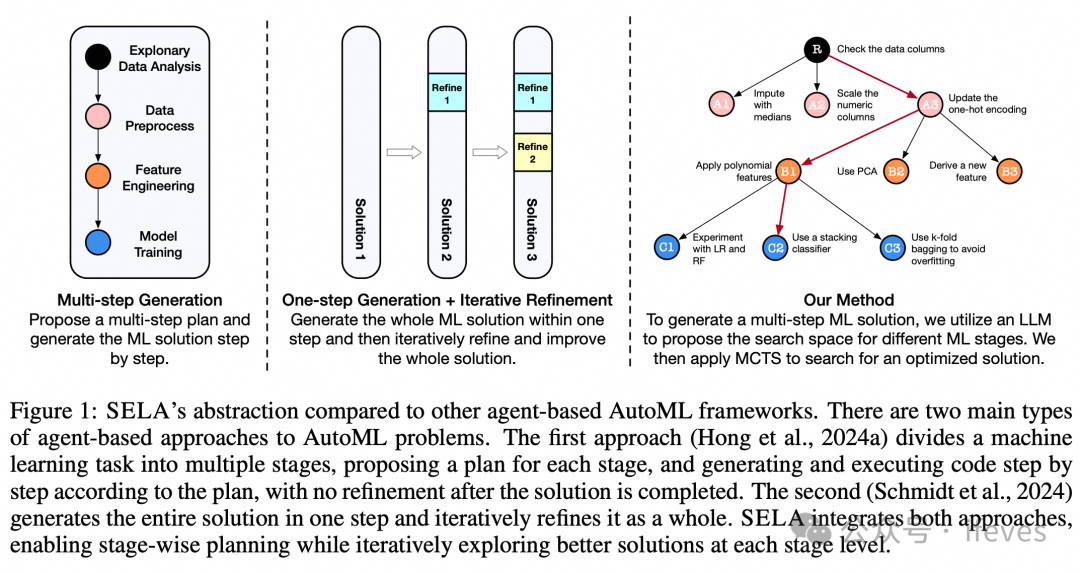
Chi Y, Lin Y, Hong S, et al. SELA: Tree-Search Enhanced LLM Agents for Automated Machine Learning[J]. arXiv preprint arXiv:2410.17238, 2024.
SELA:用llm控制automl的pipeline,加入了树搜索
4.3. llm实现workflow
Data Interpretor(2024):
task graph:将复杂问题分解为可管理的子问题,动态生成节点并优化图结构
action graph:细化并验证每个子问题,逐步改进代码生成结果和鲁棒性
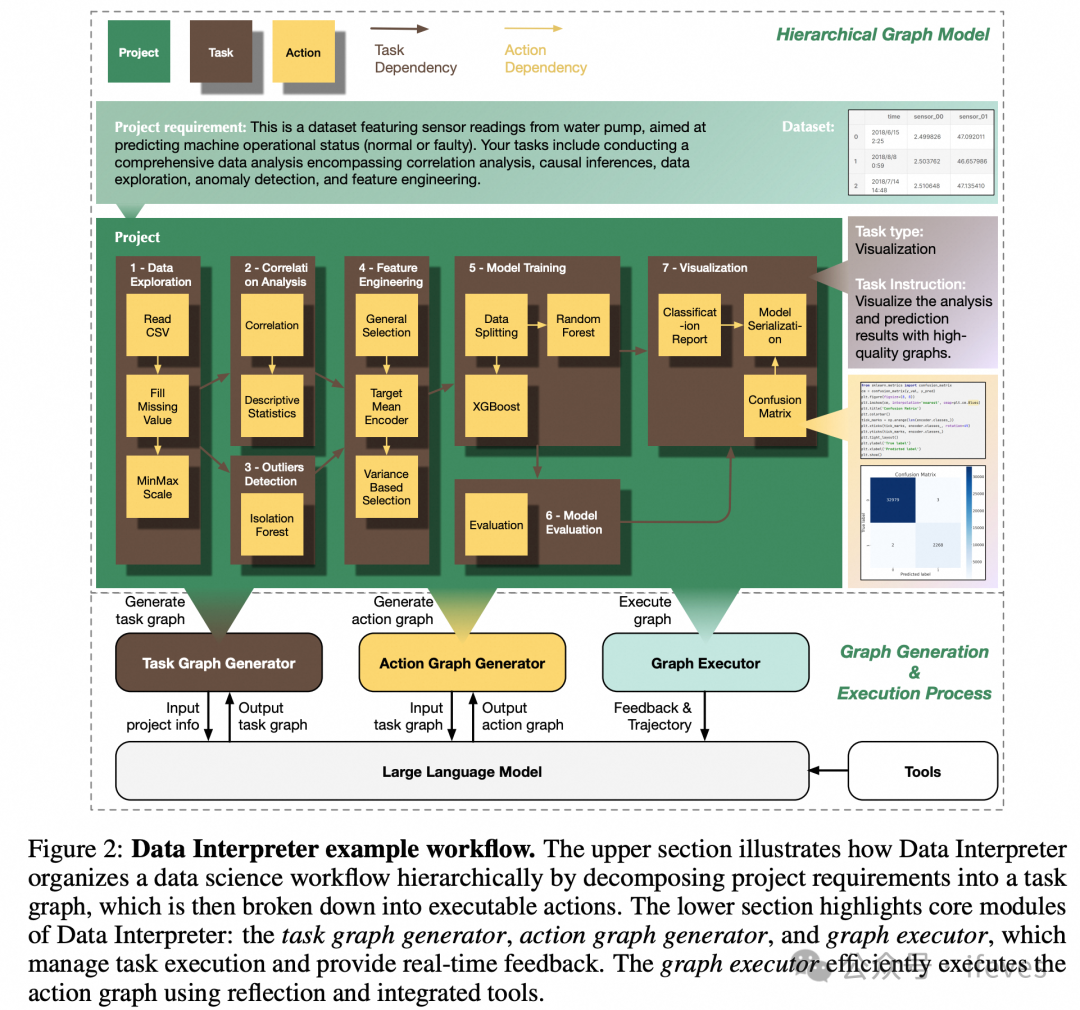
Hong S, Lin Y, Liu B, et al. Data interpreter: An llm agent for data science[J]. arXiv preprint arXiv:2402.18679, 2024.
Verbalized Machine Learning(VLM):
自然语言(pattern description)作为参数空间,一个具体的description文本序列就是一套参数,论文称发现description就是训练数据中蕴含的模式参数优化就是prompt优化
两个LLM,一个作为function approximator,一个作为optimizer

Hong, S., Lin, Y., Liu, B., et al. (2024). Verbalized Machine Learning: Revisiting Machine Learning with Language Models. arXiv preprint arXiv:2406.04344.
4.4. 最后
传统机器学习的小模型受制于建模能力,往往能够拟合的数据规模、多样性、复杂性都比较有限,更专注于处理具体的任务,不同任务之间训练不同小模型使用的特征可能不同,训练得到的模型所蕴含的领域经验也比较难以迁移。可以将使用各种小模型完成的不同的具体任务的输入、输出数据都喂给大模型进行学习,大模型可以作为一个专家模型,不断通过新的数据进行finetune,不断积累经验,同时融合不同任务对应小模型的经验。当有新的具体任务的时候,除了当前已有的数据,可以将数据输入数据喂给大模型,通过大模型输出一些相关领域的特征值(专家特征)或者通过大模型给出一个初步的预测结果(专家经验),这个结果可以与传统机器学习模型的预测结果融合,或者作为增强特征用于传统机器学习模型的训练。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









