# 导入模块
from lxml import etree
import requests
import random
import time
import csv
import pandas as pd
import openpyxl
import numpy as np
import re
import os
headers = {
"accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"accept-encoding":"gzip, deflate, br, zstd",
"accept-language":"zh-CN,zh;q=0.9",
"cache-control":"no-cache",
"cookie":"f=n; commontopbar_new_city_info=541%7C%E6%98%86%E6%98%8E%7Ckm; userid360_xml=86A9F3EF6D523C4A2DF9F1720F4957A7; time_create=1736401178025; myLat=""; myLon=""; id58=OVuk4mdOyMuoA/Sr6mjMTw==; mcity=fz; 58tj_uuid=07290b97-a113-4ee5-b0cd-d41422d1cc79; als=0; __utmz=253535702.1733216475.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); hots=%5B%7B%22d%22%3A0%2C%22s1%22%3A%22%E4%BA%91%E5%8D%97%22%2C%22s2%22%3A%22%22%2C%22n%22%3A%22sou%22%7D%5D; xxzlclientid=d6f2d364-65e8-495f-a5a1-1733216492843; xxzlxxid=pfmxmAYm+pnwkBxxHK1vkh1ClYIHzjTfnndQz3L1C7AfeI0f7v++vxKPVzylDmlGFqnH; ppStore_fingerprint=5B8833B176F3FF0FE65B433A67052FE1B92324A6708C8257%EF%BC%BF1733216823104; aQQ_ajkguid=86A978A6-C75C-423E-AF64-F0A601C1C024; sessid=28265EF8-98A7-44BB-9819-9594000E640A; ajk-appVersion=; ctid=304; fzq_h=8faef8f41090c4207ccd3df3be39d79c_1733216870346_713b5efc6e3b4c4e95a0119027013e6d_1882259511; new_uv=2; sessionid=9f5142cc-431e-447f-8de1-11c3192092b2; new_session=0; __utma=253535702.1881678360.1733216475.1733216475.1733809099.2; __utmc=253535702; __utmb=253535702.1.10.1733809099; utm_source=sem-baidu-pc; spm=u-2few7p4vh988mb62t1.2few8w827wgt4eurg.kd_209092640535.cr_83486247659.ac_20304970.cd_7922988087229364418; init_refer=https%253A%252F%252Fwww.baidu.com%252Fbaidu.php%253Furl%253DK00000K3Zd4fCW_uEbV1FAjduYkXLwZFVYZiB1ccnzuCam5QaDQVrFvT6F_jTN0imbcmc6iuFvlwzAaRRU72_OqqZEfzmVUkULLSy8d2VwpzebKS34gGcOu98jK7OZS7B_ou6DQjj4aunR-MXWHEUgvWfoUmuiE8p1-mxrZmYAKpT4UqUazq9hLs0Wi5UP4_VTEwNRLyv4pS-Onp3TNF7V5kfBcL.DY_jI_wKLk_Y2hrtX5ik614PpXjkkqMYNUqh1HxY427x-bdG3PMK_zX5KJCIBTDvozeU8gFuE_L4rM__LTIL-jPzer5u_lTMu3qrex4nst8i1WuvUOA1z984xOOJSe-SW7OOqqT7jHzk8sHfGmWHG1L_3_AxZjdsRP5Qa1Gk_EdwnwGCYX8a9G4I2UM3PQDrr7i_nYQ7xH_3v20.U1Yk0ZDqPH60TA-W5H00TZPGuv3quHT3nHTsryRdrjDsuyfYrH7WnW0LPAw-PHnkuhfzPH00IjYdr0KGUHYznWR0u1dEugK1n0KdpHdBmy-bIfKspyfqPfKWpyf; f=n; city=km; 58home=km; commontopbar_new_city_info=541%7C%E6%98%86%E6%98%8E%7Ckm; commontopbar_ipcity=fz%7C%E7%A6%8F%E5%B7%9E%7C0; xxzlbbid=pfmbM3wxMDMyNXwxLjEwLjB8MTczMzgwOTg1MjUxMTY0NzE0NXwrNmNEM0J2UGN1T2dub3cxOXRLMFRIWDhna2lIZHEyVUtJNjFRcVFRbXVrPXw5Y2JjZjY0NjFiZjkyMzYxNjYxMTU5NTNkMzc0MWE1YV8xNzMzODA5ODUxNDMxX2E3YmNmMzhjNGIzMzQ5Y2I4OGQxOWViZGJmYzNiYTM0XzE4ODIyNTk1MDl8Njc0NjJmZjViMzkxYTBhYTc0MzI0ZTI3ZmQwNWE0OTdfMTczMzgwOTg1MjAyN18yNTY=",
"pragma":"no-cache",
"priority":"u=0, i",
"referer":"https://km.58.com/zufang/?key=%E7%A7%9F%E6%88%BF%E5%AD%90&cmcskey=%E7%A7%9F%E6%88%BF%E5%AD%90&final=1&jump=1&sourcetype=11&PGTID=0d100000-0021-dbff-f1f9-57543e5bc2db&ClickID=8",
"sec-ch-ua":'"Google Chrome";v="131", "Chromium";v="131", "Not_A Brand";v="24"',
"sec-ch-ua-mobile":"?0",
"sec-ch-ua-platform":'"Windows"',
"sec-fetch-dest":"document",
"sec-fetch-mode":"navigate",
"sec-fetch-site":"same-origin",
"sec-fetch-user":"?1",
"upgrade-insecure-requests":"1",
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36"
}
params = {
"key": "租房子",
}
# 爬取及解析函数
def SpiderData(url):
response = requests.get(url=url, params=params, headers=headers)
data = response.text
return data
def ParseData(data,key):
title, huxing, area, location, developer, price, region = [[] for i in range(7)]
tree = etree.HTML(data)
lis = tree.xpath('.//ul[@class="house-list"]/li')
for li in lis:
title.append(''.join(li.xpath('.//a[@class="strongbox"]/text()')).replace(' ','').replace('\n',''))
huxing.append(''.join(li.xpath('.//p[@class="room"]/text()')).replace(' ','').split('\xa0')[0])
area.append(''.join(li.xpath('.//p[@class="room"]/text()')).replace(' ','').split('\xa0')[-1].replace('㎡','').replace('\n',''))
location.append(''.join(li.xpath('.//p[@class="infor"]/text()')).replace(' ','').replace('\xa0','').replace('\n',''))
developer.append(''.join(li.xpath('.//span[@class="jjr_par_dp"]/text()')).replace(" ","").replace("\n",""))
price.append(''.join(li.xpath('.//div[@class="money"]/b/text()')))
region = [key for i in range(len(title))]
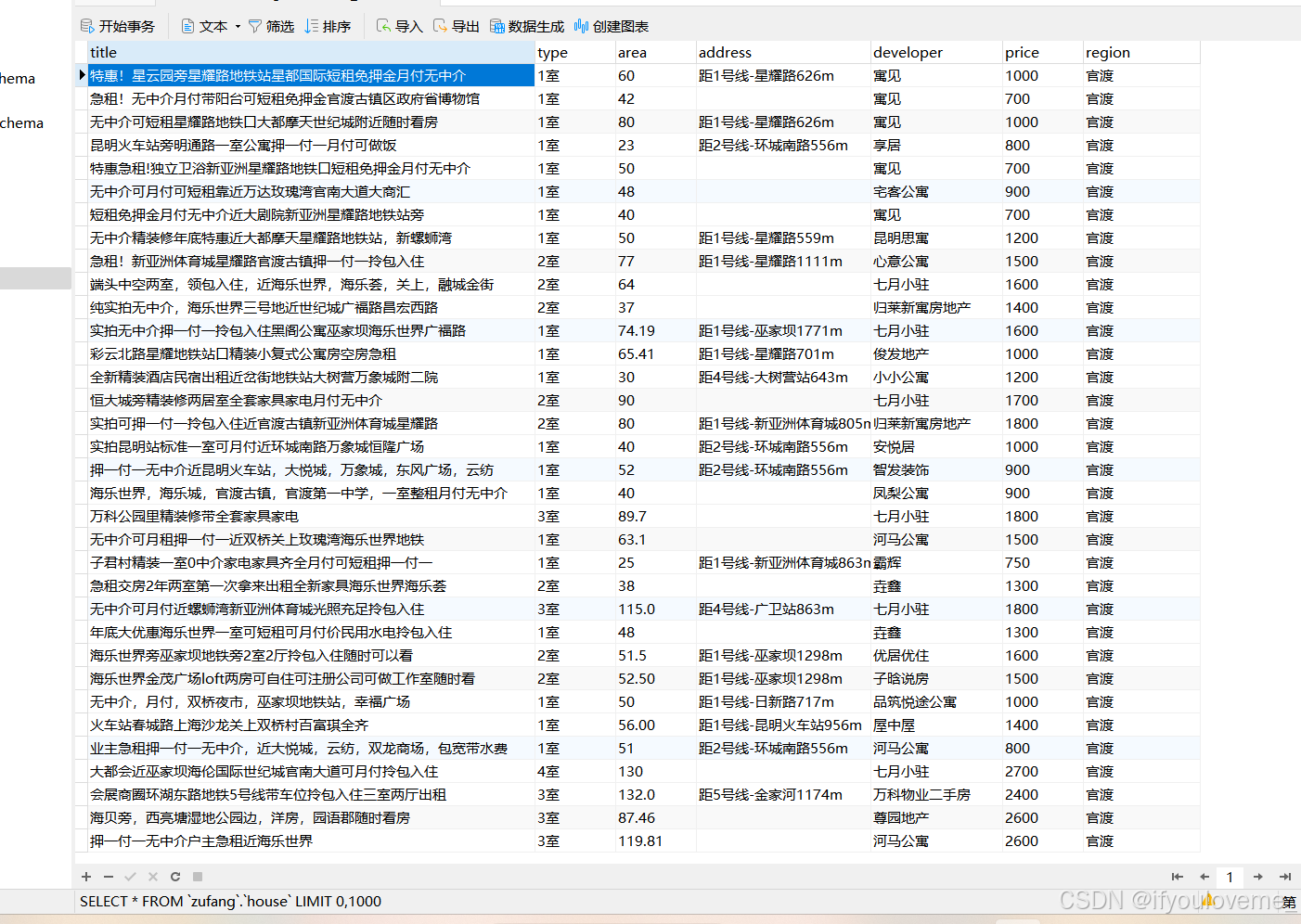
dic = {
'标题':title,
'户型':huxing,
'面积':area,
'地址':location,
'开发商':developer,
'价格':price,
'区域板块':region
}
df1 = pd.DataFrame(dic)
return df1
# 主函数
# 创建空数据框
title, huxing, area, location, developer, price, region = [[] for i in range(7)]
dic = {
'标题':title,
'户型':huxing,
'面积':area,
'地址':location,
'开发商':developer,
'价格':price,
'区域板块':region
}
df = pd.DataFrame(dic)
kunming_region = {
'官渡': 'guandu',
'五华':'wuhua',
'盘龙':'panlong',
'西山':'xishan',
'呈贡':'chenggong',
'安宁':'anning',
'宜良':'yiliang',
'嵩明':'songming',
'石林':'shilin',
'富民':'fumin',
'嵩明':'songming',
'寻甸':'xundian',
'禄劝':'luquan',
'东川':'dongchuan'
}
for key,value in kunming_region.items():
print(f'⬇️⬇️开始爬取昆明市{key}的房源.......')
time.sleep(20)
for page in range(10):
print('*********开始爬取第{}页数据'.format(page+1))
if page == 0:
url = f'https://km.58.com/{value}/zufang/'
else:
url = f'https://km.58.com/{value}/zufang/pn{page+1}/'
data = SpiderData(url)
time.sleep(5)
df1 = ParseData(data,key)
df1.dropna(subset=['标题','户型'], inplace=True)
if len(df1) >= 1:
k = len(df)
df = pd.concat([df,df1], axis=0)
df.drop_duplicates(subset=None, keep='first', inplace=True)
print('*********第{}页数据爬取完成,爬取{}条数据,共爬取{}条数据'.format(page+1,len(df)-k,len(df)))
else:
print('*********第{}页数据为空,该区域已爬取完'.format(page+1))
break
time.sleep(10)
print(f'⬆️⬆️昆明市{key}的房源已爬取完.......')
print('===========================')
df.shape
df.head()
df.to_excel('58同城房源_昆明.xlsx',header=True,index=False)

























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









