







引子:一场关于智慧尺寸的较量
科技巨头微软,近日在人工智能领域投下了一颗引人注目的石子——正式发布了 Phi-4 Reasoning 系列模型。这标志着微软在大型语言模型(LLM)的“推理”或“思考”能力赛道上,迈出了重要一步。
我们不禁要问:这些全新的模型有何特别之处?尤为关键的是,在追求模型尺寸越来越小的今天,一个“小个子”能否拥有媲美甚至挑战“大块头”的强大推理能力?今天,我们就来深入探讨一番,揭开 Phi-4 Reasoning 模型的神秘面纱。

第一部分:一年耕耘,Phi 模型家族的迭代与进化
回溯微软的 Phi 系列模型,其发展历程已近一年(虽然感觉更长一些!)。从最初的版本至今,Phi 模型经历了显著的迭代。其核心理念一直非常清晰:探索并验证利用合成数据(通常由 GPT-4 等顶尖大模型“蒸馏”而来)来高效训练小型语言模型的可行性。
而本次发布的核心焦点,正是全新的 Phi-4 Reasoning 系列。正如其名,这一系列模型被明确设定了目标——专注于提升模型的推理能力。
第二部分:认识新力量:Phi-4 Reasoning 系列的阵容与定位
微软此次一口气推出了三款推理模型:
-
Phi-4 Reasoning
-
Phi-4 Reasoning Plus
-
Phi-4 Mini Reasoning

没错,没有“Max”版本,但最引人注目的莫过于“Mini”版本。它直击我们最关心的问题:推理能力究竟能在多小的模型尺寸上实现?
然而,客观地说,本次发布的时机略显尴尬。仅仅一周前,阿里云智旗下的 Qwen 3 系列模型横空出世,其中甚至包含了参数量低至 0.6B 的推理模型。这多少让 Phi-4 Mini 的“小尺寸推理”光环显得不那么耀眼,微软似乎被“抢跑”了。

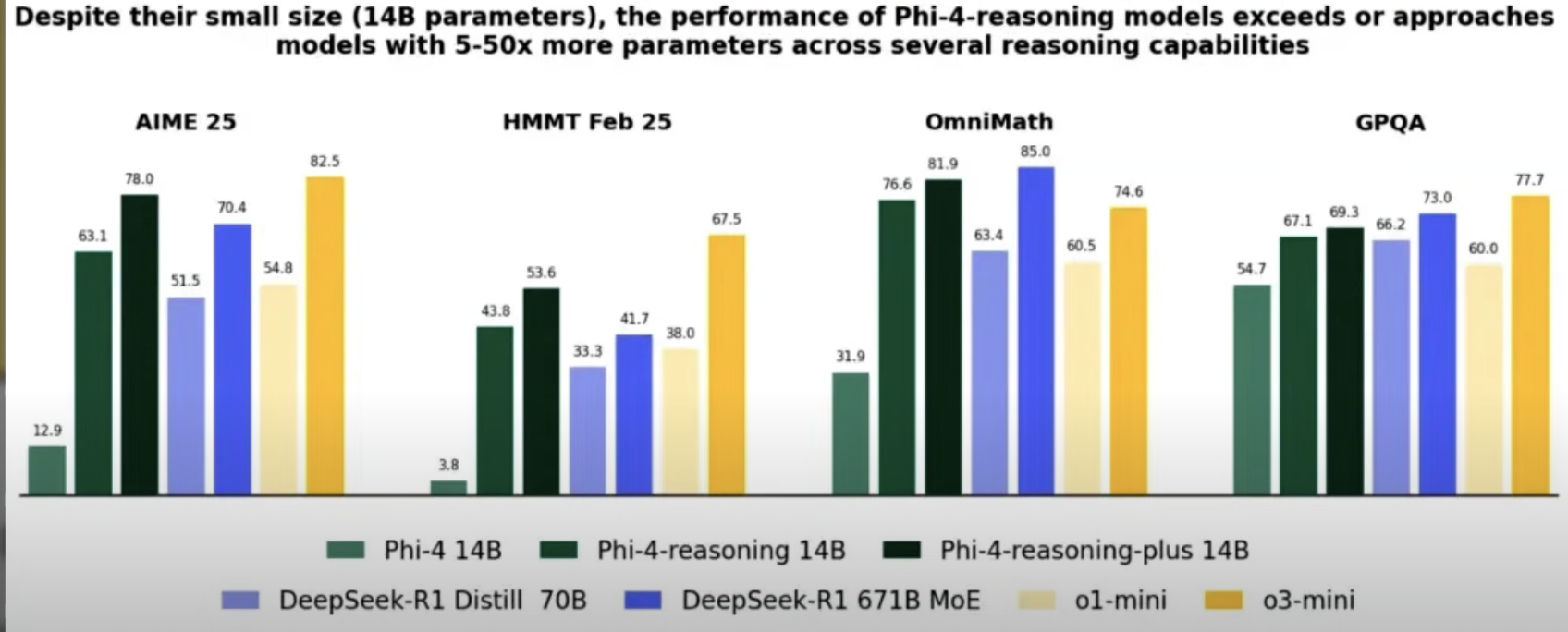
抛开时机不谈,微软官方强调,这些新模型主要针对推理场景进行了优化,旨在提升推理时的效率和可预测性,例如更好地生成和处理长链条的思维过程(Chain-of-Thought, CoT)。从目前披露的信息看,它们的训练似乎主要集中在数学推理这一特定领域。
在训练方法上,微软提到了“蒸馏”与“强化学习”的结合,这也预示着这些模型并非完全从零开始,而是站在了巨人的肩膀上。
第三部分:深度揭秘:这些“推理引擎”是如何被“炼成”的?
要理解 Phi-4 Reasoning 系列的能力,必须深入其训练方法。微软在技术博客和相关论文中,提供了不少关键细节。
-
Phi-4 Reasoning (140亿参数):
这款模型参数量相对较大,并非通常意义上的“小型”。它的训练主要依赖于从 O3-mini 模型中精心筛选出的合成数据。这是一种典型的蒸馏过程:利用更强大的模型生成数据,然后用这些数据来微调一个较小的(或已有的)模型,使其具备类似的能力。值得注意的是,这里使用的是 O3-mini 的数据,而非更强大的 O3 模型。 -
Phi-4 Reasoning Plus:
正如其名,Plus 版本在 Phi-4 Reasoning 的基础上进行了增强。它引入了强化学习(RL),并在训练中使用了约1.5倍于基础版的数据量。正是强化学习的加入,使得 Plus 版本的推理质量有了显著提升,表现更接近那些顶级的推理模型。 -
Phi-4 Mini Reasoning (38亿参数) - 本次技术探索的亮点:
Mini 版本无疑是技术层面最令人兴奋的一个。它基于 Phi-4 Mini 基座模型进行训练,而其核心的训练数据,竟然主要来源于 DeepSeekR1。从这个角度看,称其为“Phi-DeepSeek”模型也并不为过,因为它很大程度上是 DeepSeekR1 能力的一种蒸馏呈现。微软的博客中甚至没有明确提及使用其他模型的合成数据来训练 Mini 版本。这一点再次凸显了一个关键事实,也是 DeepSeek 模型发布时曾引发的讨论:蒸馏模型,绝不等同于它的原始大模型! 很多人曾误以为在本地运行 DeepSeekR1 的蒸馏版本就等同于原版,这完全是误解。蒸馏版通常参数量小得多,并且经过量化等处理,其表现与完整的原版 DeepSeekR1 模型存在巨大差距。Phi-4 Mini Reasoning 的情况也印证了这一点——纯蒸馏的模型,其最终推理质量往往难以企及被蒸馏的原始顶尖模型。微软在其基准测试中,也常拿蒸馏版的自家模型与对手的蒸馏版进行对比,而非与原始模型。
不过,微软团队在 Phi-4 Mini Reasoning 的论文中,非常详细地披露了其多阶段的训练流程,这为我们理解如何在小尺寸模型中注入推理能力提供了宝贵的线索:
-
持续预训练 (Continued Pre-training): 首先,模型在精选的思维链(CoT)数据集上进行持续的下一词预测训练。这并非传统的有监督微调,而是让模型“观察”并“学习模仿”更复杂的思维过程结构。这部分数据很可能大量来自 DeepSeekR1。
-
有监督微调 (SFT): 接着,模型在包含输入/输出对的数学问答数据集上进行有监督微调。这个数据集经过精心策划,覆盖了从基础到大学甚至更高难度的数学问题。
-
对齐训练 (Alignment - DPO): 利用数据集中可能存在的错误答案,通过直接偏好优化(DPO)技术,模型被引导去生成那些包含长思维链的 正确 答案,并避免生成长但错误的思维链。
-
RLVR (Reinforcement Learning with Verifiable Rewards): 最后,模型利用可验证的奖励进行强化学习。由于训练数据中包含了标准答案,模型可以根据生成的答案是否正确获得奖励或惩罚。这里使用了 PPO 和 DeepSeek 曾使用的 GRPO 两种强化学习算法。
整个 Mini 模型的训练过程高度依赖于构建高质量的合成思维链数据集。虽然这些最终的训练数据集尚未公开,但其流程展示了利用蒸馏和强化学习相结合训练小型推理模型的有效路径。
-
第四部分:微软的战略棋局:让AI在“自家地盘”自由奔跑?
从本次发布以及微软过去的一些动作来看,Phi 模型系列,尤其是这些高效的推理模型,承载着微软在本地设备AI上的重要战略意图。
微软明确表示,他们正在积极探索如何将 Phi 模型应用于 Windows 设备,使其能在用户的本地硬件上高效运行,无论是 CPU、GPU 还是 NPU。这显然是为了将AI能力更深度地融入 Windows 操作系统及其应用生态。
目前,Phi 模型已经在一些微软产品中得到应用或正在测试中,例如用于 Outlook 的某些功能,或为 Co-pilot 提供离线摘要能力等。这背后一个重要的驱动力可能是:通过在本地运行模型,微软可以减少对外部大型模型API的依赖,从而降低成本并提升用户体验(例如响应速度和隐私保护)。
微软甚至为此推出了一个专门优化的 Phi Silica 版本,旨在提升 Phi 模型在 Windows 系统上的性能。
放眼整个行业,将AI模型深度集成到操作系统中已是大势所趋。虽然苹果在通用 LLM 领域看起来稍慢半拍,但其 MLX 框架已经展示了在本地运行模型的能力,未来很可能也会将模型能力“烘焙”进 macOS 或 iOS。微软的这一举动,无疑走在了前列。Phi-4 Reasoning 系列模型的推出,或许正在向我们暗示,未来操作系统内置的AI能力,其推理水平可能就是基于类似量级的模型。
第五部分:深层思考:为何“小而能思”如此重要?
为何业界如此关注小型但具备强大推理能力的模型?这背后涉及到一个关于AI模型核心职能的哲学探讨。正如 Andre Karpathy 等技术专家曾讨论过的“认知核心”概念一样,许多人认为,当前大型模型浪费了太多参数去记忆海量琐碎的信息,比如过时的网站信息、SHA 哈希值等——这些信息通过外部查询完全可以获取,模型无需“内置”它们。
理想的AI架构,或许是一个精悍的“认知核心”,它擅长逻辑推理、解决问题和进行复杂思考。当需要事实信息时,它知道如何调用外部工具(如搜索引擎、数据库,也就是 RAG - Retrieval Augmented Generation 技术)去获取。
这个专注于思考的“认知核心”,其参数量可能远小于我们目前看到的大型模型。10亿、30亿甚至更小的模型,理论上就可能承载强大的推理能力。而要实现这一点,“蒸馏”——利用强大模型的智慧来引导小型模型的学习——被视为一条极其有效的途径。通过蒸馏,可以将大模型复杂的推理逻辑和思考模式“压缩”并“转移”到小模型中。
这种“小而能思”的模型,不仅部署成本低、运行效率高,更是构建未来更智能、更灵活的AI系统(包括 AGI 的潜在构成单元)的关键模块。
第六部分:实测体验:Phi-4 Mini Reasoning 的“思考”初探
理论说了这么多,实际体验如何?
尝试加载 Phi-4 Mini Reasoning 模型(38亿参数版本)进行推理。这款模型在算力要求上相对友好,可以在如 T4 这样的通用型加速卡上运行。
它的输出格式很有特点:首先会生成一段标记在 [THINK] 标签内的“思考”过程,然后才是最终的答案。这直观地展示了模型试图分解问题的过程。
在数学推理问题上(例如 GSM8K 基准测试中的题目),Phi-4 Mini Reasoning 的表现确实可圈可点。它能够将问题分解为一系列推理步骤,再给出最终解。

然而,在处理更通用、更开放的问题时,其“思考”过程的感觉与专门为此优化的模型有所不同。与 Qwen 3 1.7B 模型对比,Qwen 的思考过程更像是面向用户的,比如会表述“用户想知道这个,我需要先做这些步骤……”,而 Phi-4 Mini Reasoning 则更像是在执行一个任务分解过程,较少提及用户。就个人体验而言,Qwen 在通用推理上的“感觉”可能稍好一些,且其最小推理模型尺寸更小。
当然,与目前顶级的推理模型(如 Gemini 2.5)相比,Phi-4 Mini Reasoning 的推理过程在条理性上还有差距。Gemini 2.5 常能以带编号的、多角度的步骤清晰地呈现思考过程,这一点是目前小型模型难以企及的。
总的来说,对于需要在资源受限环境下部署推理能力的场景,如果 Qwen 模型不是首选,Phi-4 Mini Reasoning 无疑是目前市场上值得认真考虑的优秀选项之一。相关代码示例和资源可以帮助有兴趣的读者自行探索其能力边界。
第七部分:展望与结语
小型推理模型的出现,开启了许多令人兴奋的新可能性。例如,未来或许可以探索让多个模型互相“辩论”,通过交叉验证和修正彼此的推理过程来进一步提升能力。这可能是一个全新的、富有潜力的研究方向。
不可否认,微软 Phi-4 Reasoning 系列的发布,放在其Phi模型家族的演进中意义重大,尤其在推动本地设备AI应用方面迈出了坚实一步。但正如前文所述,紧随 Qwen 3 之后问世,让其在舆论场上未能获得最佳的关注度。如果能早一两周发布,其影响力可能会完全不同。
无论如何,Phi-4 Reasoning 系列,尤其是 Mini 版本,作为小型推理模型的代表,为我们展示了在有限参数下实现复杂思考的可能性,也预示着AI能力向边缘设备普及的加速趋势。


















 270
270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









