






一、数组:固定长度的连续存储容器
数组是 Java 中最基础的数据结构之一,适用于存储固定长度、相同数据类型的元素,在内存中占据连续空间,支持通过索引快速访问。
1.1 数组的核心特性
- 长度不可变:数组在创建时必须显式指定长度(如
int[] arr = new int[5]),一旦创建,长度无法动态修改。若需增减元素,需手动创建新数组并复制原元素。 - 元素类型统一:数组中所有元素必须是同一数据类型,可分为两类:
- 基本数据类型数组:存储具体数值(如
int[]、double[]),默认值为对应基本类型的零值(int为 0,double为 0.0,char为'\u0000')。 - 引用数据类型数组:存储对象的引用(如
String[]、Student[]),默认值为null。
- 基本数据类型数组:存储具体数值(如
- 连续内存存储:数组元素在内存中按顺序连续排列,索引(从 0 开始)直接对应元素在内存中的偏移量,因此访问任意元素的时间复杂度为O(1),查询效率极高。
- 默认值初始化:无论是否显式赋值,数组创建后都会自动初始化所有元素为对应类型的默认值,避免空指针或垃圾值问题。
1.2 数组的声明与初始化
数组的初始化分为 “动态初始化”(先指定长度,后赋值)和 “静态初始化”(直接指定元素,长度由元素个数决定),两种方式不可同时使用。
// 1. 动态初始化:指定长度,元素为默认值
int[] arr1 = new int[3]; // 长度3,元素默认值为0、0、0
arr1[0] = 10; // 手动赋值第一个元素
// 2. 静态初始化:指定元素,长度自动为3
int[] arr2 = new int[]{10, 20, 30};
// 简化写法(仅声明时可用)
int[] arr3 = {10, 20, 30};
// 3. 引用数据类型数组初始化
String[] strArr = new String[2]; // 默认值为[null, null]
strArr[0] = "Java"; // 赋值第一个元素为字符串对象
1.3 多维数组
多维数组本质是 “数组的数组”,最常用的是二维数组,适用于存储表格类数据(如矩阵)。
- 二维数组的初始化:
// 1. 规则二维数组(每行长度相同)
int[][] matrix1 = new int[2][3]; // 2行3列,元素默认值为0
matrix1[0][1] = 5; // 给第1行第2列元素赋值
// 2. 不规则二维数组(每行长度可不同)
int[][] matrix2 = new int[2][]; // 先指定行数,不指定列数
matrix2[0] = new int[3]; // 第1行长度为3
matrix2[1] = new int[2]; // 第2行长度为2
- 二维数组的遍历:需通过嵌套循环,外层遍历 “行数组”,内层遍历 “行中的元素”。
for (int i = 0; i < matrix2.length; i++) { // 遍历行
for (int j = 0; j < matrix2[i].length; j++) { // 遍历每行的元素
System.out.print(matrix2[i][j] + " ");
}
System.out.println();
}
1.4 Arrays 工具类
Java 提供java.util.Arrays类,封装了数组的常用操作(排序、查找、填充等),无需手动实现复杂逻辑。
| 方法名 | 功能描述 | 示例 |
|---|---|---|
sort(数组) | 对数组进行升序排序(基本类型用快速排序,引用类型用 TimSort) | Arrays.sort(arr1);(排序 int 数组) |
binarySearch(数组, 目标值) | 二分查找目标值在有序数组中的索引,未找到返回负数 | int index = Arrays.binarySearch(arr2, 20); |
fill(数组, 填充值) | 将数组所有元素替换为指定填充值 | Arrays.fill(arr1, 5);(将 arr1 所有元素设为 5) |
toString(数组) | 将数组转为字符串(如[10, 20, 30]),方便打印 | System.out.println(Arrays.toString(arr2)); |
copyOf(原数组, 新长度) | 复制原数组,新数组长度为指定值,超出部分用默认值填充 | int[] newArr = Arrays.copyOf(arr2, 5);(新数组长度 5,后 2 个元素为 0) |
1.5 数组的使用场景与局限性
- 适用场景:
- 存储长度固定、需频繁查询的数据。
- 底层实现其他数据结构。
- 局限性:
- 长度固定,无法动态增减元素,增删操作需手动处理数组复制,效率低(时间复杂度 O (n))。
- 仅支持索引访问,无内置的增删改查方法,需手动实现(如判断元素是否存在、删除指定元素)。
- 无法直接存储不同数据类型的元素(如需存储多种类型,需用
Object[],但会丢失类型安全性)。
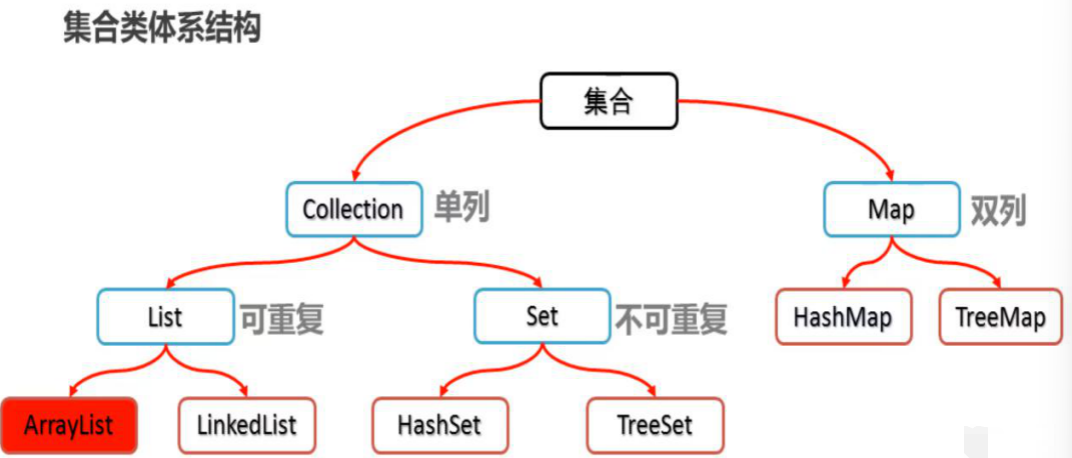
二、集合:动态长度的灵活存储框架
集合是 Java 为解决数组局限性设计的动态数据结构,支持自动扩容、内置增删改查方法,且仅存储引用数据类型(基本类型需通过包装类存储,如int对应Integer)。
集合框架体系
├─ Collection(单列集合:存储单个元素)
│ ├─ List(有序、可重复、有索引)
│ │ ├─ ArrayList(底层数组,查询快、增删慢)
│ │ └─ LinkedList(底层双向链表,增删快、查询慢)
│ └─ Set(无序、不可重复、无索引)
│ ├─ HashSet(底层哈希表,增删查快,无序)
│ └─ TreeSet(底层红黑树,自动排序,有序)
└─ Map(双列集合:存储键值对Key-Value)
├─ HashMap(底层哈希表,无序、键唯一,允许null键/值)
└─ TreeMap(底层红黑树,按键排序,有序,不允许null键)
2.1 Collection 接口:单列集合的顶层规范
Collection是所有单列集合的父接口,定义了单列集合的通用方法,所有实现类(如ArrayList、HashSet)都需遵守这些规范。
2.1.1 Collection 的通用方法
| 方法名 | 功能描述 | 示例代码 |
|---|---|---|
boolean add(E e) | 向集合添加元素,成功返回true,失败(如 Set 重复)返回false | List<String> list = new ArrayList<>(); list.add("Java"); |
boolean remove(Object o) | 删除集合中指定元素,成功返回true,无此元素返回false | list.remove("Java"); |
boolean removeIf(Predicate filter) | 按条件删除元素(Java 8+),过滤逻辑由Predicate接口实现 | list.removeIf(s -> s.length() > 5);(删除长度 > 5 的元素) |
void clear() | 清空集合中所有元素,集合变为空(长度 0) | list.clear(); |
boolean contains(Object o) | 判断集合是否包含指定元素,包含返回true | boolean hasJava = list.contains("Java"); |
boolean isEmpty() | 判断集合是否为空(长度 0),空返回true | boolean isEmpty = list.isEmpty(); |
int size() | 返回集合中元素的个数(长度) | int count = list.size(); |
Object[] toArray() | 将集合转为数组,方便兼容数组操作 | Object[] arr = list.toArray(); |
2.1.2 Collection 的遍历方式
遍历是集合的核心操作,Collection提供 3 种常用遍历方式,适用于不同场景:
方式 1:迭代器(Iterator)—— 支持遍历中删除元素
迭代器是Collection的内置遍历工具,通过iterator()方法获取,支持在遍历过程中安全删除元素(避免ConcurrentModificationException异常)。
List<String> list = new ArrayList<>();
list.add("apple");
list.add("banana");
list.add("cherry");
// 1. 获取迭代器对象
Iterator<String> iterator = list.iterator();
// 2. 遍历:hasNext()判断是否有下一个元素,next()获取元素并移动指针
while (iterator.hasNext()) {
String element = iterator.next();
if ("banana".equals(element)) {
// 迭代器的remove()方法:删除当前遍历到的元素
iterator.remove();
}
System.out.println(element); // 输出apple、banana、cherry(删除后集合中无banana)
}
方式 2:增强 for 循环(for-each)—— 简洁的遍历
增强 for 循环是 Java 5 引入的简化语法,底层基于迭代器实现,适用于 “仅遍历,不修改集合结构” 的场景,代码简洁易读。
// 语法:for (元素类型 变量名 : 集合/数组)
for (String element : list) {
System.out.println(element); // 输出apple、cherry(已删除banana)
}
方式 3:Lambda 表达式 + forEach(Java 8+)—— 函数式遍历
Java 8 为Collection新增forEach()方法,支持通过 Lambda 表达式传递遍历逻辑,代码更简洁,适合函数式编程风格。
// 语法:collection.forEach(元素 -> 遍历逻辑)
list.forEach(element -> {
if (element.startsWith("a")) { // 筛选以"a"开头的元素
System.out.println(element); // 输出apple
}
});
2.1.3 List 接口:有序可重复的单列集合
List是Collection的子接口,特点是有序(存储与取出顺序一致)、可重复(允许元素值相同)、有索引(支持通过索引访问元素),适用于需要 “按顺序存储、可通过位置操作” 的场景(如购物车、任务列表)。
2.1.3.1 List 的核心特性
- 索引支持:可通过索引(0 开始)访问、修改、删除元素(如
get(0)获取第一个元素,set(1, "new")修改第二个元素)。 - 元素可重复:允许添加多个值相同的元素(如
list.add("Java"); list.add("Java"),集合中会存在两个 "Java")。 - 有序性:元素的存储顺序与取出顺序完全一致(如按
A、B、C的顺序添加,遍历也会按A、B、C返回)。
2.1.3.2 ArrayList实现类:数组实现的高效查询集合
ArrayList底层基于动态数组实现,默认初始容量为 10,当元素个数超过阈值(容量 × 负载因子 0.75)时,会自动扩容为原容量的 1.5 倍(如 10→15→22...),适合频繁查询、少量增删的场景。
(1)ArrayList 的构造方法
| 构造方法 | 功能描述 | 示例 |
|---|---|---|
ArrayList() | 创建默认初始容量为 10 的空集合 | List<String> list = new ArrayList<>(); |
ArrayList(int initialCapacity) | 创建指定初始容量的空集合(避免频繁扩容) | List<String> list = new ArrayList<>(20);(初始容量 20) |
ArrayList(Collection<? extends E> c) | 将其他 Collection 集合转为 ArrayList | Set<String> set = new HashSet<>(); List<String> list = new ArrayList<>(set); |
(2)ArrayList 的核心方法
- 索引相关操作:
List<String> list = new ArrayList<>(); list.add("apple"); // 末尾添加元素 list.add(1, "banana"); // 索引1处插入元素(原元素后移) String first = list.get(0); // 获取索引0的元素(apple) list.set(0, "orange"); // 修改索引0的元素为orange String removed = list.remove(1); // 删除索引1的元素(banana),返回被删除元素
(3)ArrayList 的性能分析
- 查询效率:通过索引直接访问元素,时间复杂度O(1),效率极高。
- 增删效率:
- 末尾增删:直接操作数组末尾,时间复杂度O(1)。
- 中间增删:需移动后续元素(如在索引 1 插入元素,需移动索引 1 及之后的所有元素),时间复杂度O(n),效率低。
- 扩容机制:扩容时需创建新数组并复制原元素,频繁扩容会消耗性能,因此建议提前估算元素个数,通过
ArrayList(int initialCapacity)指定初始容量。
2.1.3.3 LinkedList实现类:链表实现的高效增删集合
LinkedList底层基于双向链表实现,每个元素(节点)包含 “前驱节点引用、自身值、后继节点引用”,无需连续内存空间,适合频繁增删、少量查询的场景(如队列、栈)。
(1)LinkedList 的特有方法(操作首尾元素)
由于链表结构的特性,LinkedList提供了直接操作首尾元素的方法,时间复杂度均为O(1):
LinkedList<String> list = new LinkedList<>();
list.addFirst("a"); // 链表开头添加元素
list.addLast("b"); // 链表末尾添加元素
String first = list.getFirst(); // 获取开头元素(a)
String last = list.getLast(); // 获取末尾元素(b)
String removedFirst = list.removeFirst(); // 删除并返回开头元素(a)
String removedLast = list.removeLast(); // 删除并返回末尾元素(b)
(2)LinkedList 的性能分析
- 增删效率:
- 首尾增删:直接修改首尾节点的引用,时间复杂度O(1),效率极高。
- 中间增删:需先通过遍历找到目标节点(时间复杂度 O (n)),再修改节点引用(O (1)),整体效率低于首尾操作。
- 查询效率:无索引,查询指定元素需从链表头 / 尾开始遍历,时间复杂度O(n),效率低。
2.1.3.4 ArrayList 与 LinkedList 的对比选择
| 对比维度 | ArrayList | LinkedList |
|---|---|---|
| 底层结构 | 动态数组 | 双向链表 |
| 查询效率 | 高(O (1)) | 低(O (n)) |
| 首尾增删 | 低(O (n),需扩容 / 移动元素) | 高(O (1)) |
| 中间增删 | 低(O (n),需移动元素) | 中(O (n),需遍历找节点) |
| 内存占用 | 连续内存,可能有空闲空间(扩容预留) | 非连续内存,每个节点需存储前后引用,内存开销略大 |
| 适用场景 | 频繁查询、少量增删(如商品列表、数据展示) | 频繁首尾增删(如队列、栈)、少量查询 |
2.1.4 Set 接口:无序不可重复的单列集合
Set是Collection的子接口,特点是无序(存储与取出顺序可能不一致)、不可重复(元素值唯一)、无索引,适用于需要 “去重” 的场景(如用户 ID 列表、不重复的标签)。
2.1.4.1 Set 的核心特性(补充 Collection)
- 元素不可重复:添加重复元素时,
add()方法返回false,集合不会存储重复值(去重逻辑由具体实现类决定)。 - 无索引:不支持通过索引访问元素,因此无法使用普通
for循环遍历,只能用迭代器、增强for或forEach。 - 无序性:
HashSet:完全无序,元素存储顺序与添加顺序无关。TreeSet:有序,会按元素的 “自然顺序” 或 “自定义比较器顺序” 排序。
2.1.4.2 HashSet:哈希表实现的高效去重集合
HashSet 判断元素是否重复的过程如下:
HashSet底层基于哈希表(数组 + 链表 / 红黑树) 实现,是Set最常用的实现类,特点是增删查效率高、完全无序、支持 null 元素。
(1)HashSet 的去重原理:hashCode () + equals ()
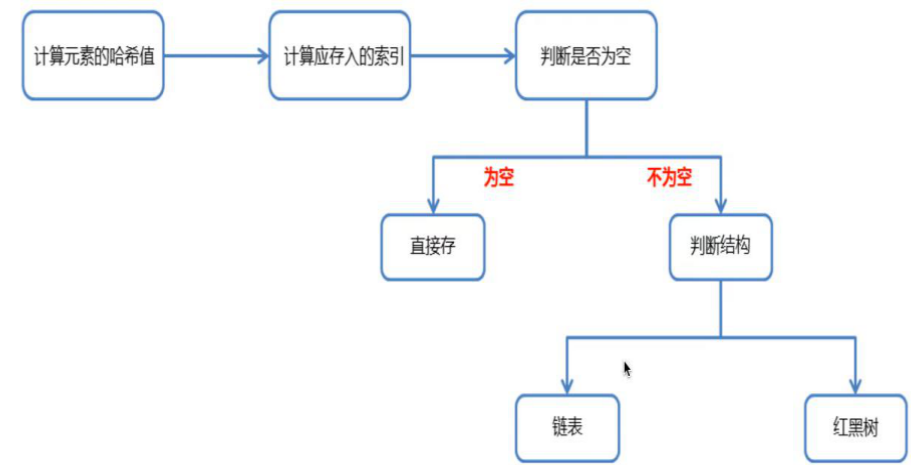
HashSet判断元素是否重复的核心是 “先比哈希值,再比内容”,需依赖元素的hashCode()和equals()方法,具体流程如下:
- 调用新增元素的
hashCode()方法,计算其哈希值,根据哈希值确定在哈希表中的 “桶位置”(数组索引)。 - 若该桶位置为空,直接将元素存入(无重复)。
- 若该桶位置不为空(哈希冲突),则调用元素的
equals()方法,与桶中已有的元素逐一比较:- 若
equals()返回true:元素重复,不存入。 - 若
equals()返回false:元素不重复,将元素存入桶中(JDK 8 + 中,若桶中元素超过 8 个,链表会转为红黑树,提升查询效率)。
- 若
因此,为了确保 HashSet 能够正确判断元素的唯一性,需要重写元素类的 hashCode() 和 equals() 方法。
(2)关键注意事项
- 若自定义类(如
Student、Book)的对象要存入HashSet,必须重写hashCode()和equals()方法,否则会默认使用Object类的方法(hashCode()返回对象地址,equals()比较地址),导致无法正确去重。 - 重写规则:
- 若两个对象
equals()返回true,则它们的hashCode()必须相等。 - 若两个对象
hashCode()不相等,则equals()必须返回false(减少哈希冲突)。
- 若两个对象
(3)HashSet 的构造方法与常用方法
// 1. 构造方法
HashSet<String> set1 = new HashSet<>(); // 默认初始容量16,负载因子0.75
HashSet<String> set2 = new HashSet<>(20); // 指定初始容量
Set<String> temp = new ArrayList<>();
HashSet<String> set3 = new HashSet<>(temp); // 从其他Collection转换
// 2. 常用方法(与Collection一致,无特有方法)
set1.add("Java");
set1.add("Python");
set1.add("Java"); // 重复元素,add()返回false,集合中仅存1个"Java"
boolean hasPython = set1.contains("Python"); // true
set1.remove("Python"); // 删除元素,返回true
int size = set1.size(); // 1
2.1.4.3 TreeSet:红黑树实现的有序去重集合
TreeSet底层基于红黑树(一种自平衡二叉搜索树) 实现,特点是自动排序、元素不可重复、不支持 null 元素,适用于需要 “去重且排序” 的场景(如按价格排序的商品列表、按学号排序的学生列表)。
(1)TreeSet 的排序方式
TreeSet的排序依赖 “比较逻辑”,分为两种方式:
-
自然排序(默认):元素类需实现
Comparable接口,并重写compareTo()方法,定义元素的排序规则。// 自定义Student类,实现Comparable接口,按学号升序排序 class Student implements Comparable<Student> { private int id; private String name; // 构造方法、getter/setter省略 @Override public int compareTo(Student other) { // 按id升序:当前id - 其他id,返回正数则当前元素在后,负数在前 return this.id - other.id; } } // 使用TreeSet存储Student,自动按id升序排序 TreeSet<Student> studentSet = new TreeSet<>(); studentSet.add(new Student(3, "Alice")); studentSet.add(new Student(1, "Bob")); studentSet.add(new Student(2, "Charlie")); // 遍历输出:Bob(id=1)、Charlie(id=2)、Alice(id=3) for (Student s : studentSet) { System.out.println(s.getName()); } -
自定义排序:若元素类无法修改(如
String、Integer),或需临时改变排序规则,可在创建TreeSet时传入Comparator接口实现类(或 Lambda 表达式)。// 存储String,按字符串长度降序排序(自定义比较器) TreeSet<String> strSet = new TreeSet<>((s1, s2) -> { // 按长度降序:s2长度 - s1长度 return s2.length() - s1.length(); }); strSet.add("apple"); // 5个字符 strSet.add("banana"); // 6个字符 strSet.add("pear"); // 4个字符 // 遍历输出:banana(6)、apple(5)、pear(4) for (String s : strSet) { System.out.println(s); }
(2)TreeSet 的关键注意事项
- 排序逻辑决定去重:
TreeSet判断元素是否重复的依据是 “compareTo()或compare()方法返回 0”,若返回 0,认为元素重复,不存入。 - 不支持 null 元素:由于排序时无法比较
null与其他元素,存入null会抛出NullPointerException。 - 排序效率稳定:红黑树的增删查时间复杂度均为O(log n),适合需要排序且数据量较大的场景。
2.1.4.4 HashSet 与 TreeSet 的对比选择
| 对比维度 | HashSet | TreeSet |
|---|---|---|
| 底层结构 | 哈希表(数组 + 链表 / 红黑树) | 红黑树 |
| 排序特性 | 完全无序 | 有序(自然排序 / 自定义排序) |
| 增删查效率 | 高(O (1),无哈希冲突时) | 中(O (log n)) |
| 去重依据 | hashCode() + equals() | compareTo() / compare()返回 0 |
| null 支持 | 支持 1 个 null 元素 | 不支持 null 元素 |
| 适用场景 | 仅需去重,无需排序(如用户 ID、标签) | 去重且需排序(如排序的商品价格、学号) |
2.2 Map 接口:键值对存储的双列集合
Map是 Java 中专门用于存储键值对(Key-Value) 的双列集合,每个键(Key)对应唯一的值(Value),键不可重复,值可重复,适用于 “通过键快速查找值” 的场景(如用户信息表:Key 为用户 ID,Value 为用户对象)。
2.2.1 Map 的核心特性
- 键值对结构:每个元素是一个 “键值对”(Java 中称为
Map.Entry对象),键与值一一对应,通过键可唯一确定值。 - 键唯一:同一个
Map中,键不能重复(重复添加会覆盖原键对应的值),值可以重复。 - 无索引:不支持通过索引访问元素,需通过键或键值对遍历。
- 引用类型存储:键和值都必须是引用数据类型(基本类型需用包装类,如
int对应Integer)。
2.2.2 Map 的通用方法
所有Map实现类(如HashMap、TreeMap)都支持以下通用方法:
// 创建Map对象(以HashMap为例)
Map<String, Integer> scoreMap = new HashMap<>();
// 1. 添加/修改键值对:键存在则覆盖值,返回旧值;键不存在则添加,返回null
Integer oldScore = scoreMap.put("Alice", 95); // null(首次添加)
oldScore = scoreMap.put("Alice", 98); // 95(覆盖旧值,返回旧值)
scoreMap.put("Bob", 88);
// 2. 删除键值对:根据键删除,返回被删除的值;键不存在返回null
Integer removedScore = scoreMap.remove("Bob"); // 88
// 3. 判断存在性
boolean hasAlice = scoreMap.containsKey("Alice"); // true(判断键是否存在)
boolean has98 = scoreMap.containsValue(98); // true(判断值是否存在)
// 4. 获取值:根据键获取值,键不存在返回null
Integer aliceScore = scoreMap.get("Alice"); // 98
// 5. 清空与长度
scoreMap.clear(); // 清空所有键值对
int size = scoreMap.size(); // 0(清空后长度为0)
boolean isEmpty = scoreMap.isEmpty(); // true
2.2.3 Map 的遍历方式
Map的遍历需围绕 “键”“值”“键值对” 三种维度,共 3 种常用方式:
方式 1:遍历键集(keySet ())—— 通过键找值
先获取所有键的集合(keySet()),再遍历键,通过get(Key)获取对应的值,适合仅需键和值的场景。
Map<String, Integer> scoreMap = new HashMap<>();
scoreMap.put("Alice", 95);
scoreMap.put("Bob", 88);
// 1. 获取所有键的集合
Set<String> keys = scoreMap.keySet();
// 2. 遍历键,获取对应值
for (String key : keys) {
Integer value = scoreMap.get(key);
System.out.println(key + " : " + value); // Alice:95, Bob:88
}
方式 2:遍历键值对集(entrySet ())—— 直接遍历键值对
获取所有键值对的集合(entrySet()),每个元素是Map.Entry对象,可直接通过getKey()和getValue()获取键和值,效率比方式 1 高(无需多次调用get(Key))。
// 1. 获取所有键值对的集合
Set<Map.Entry<String, Integer>> entrySet = scoreMap.entrySet();
// 2. 遍历键值对
for (Map.Entry<String, Integer> entry : entrySet) {
String key = entry.getKey();
Integer value = entry.getValue();
System.out.println(key + " : " + value); // Alice:95, Bob:88
}
// Lambda简化遍历(Java 8+)
scoreMap.entrySet().forEach(entry -> {
System.out.println(entry.getKey() + " : " + entry.getValue());
});
方式 3:遍历值集(values ())—— 仅遍历值
若仅需遍历值,无需键,可通过values()获取所有值的集合(Collection类型),直接遍历。
// 1. 获取所有值的集合
Collection<Integer> values = scoreMap.values();
// 2. 遍历值
for (Integer value : values) {
System.out.println(value); // 95, 88
}
2.2.4 HashMap:哈希表实现的高效键值对集合
HashMap是Map最常用的实现类,底层基于哈希表(数组 + 链表 / 红黑树) 实现,特点是无序、键唯一、支持 null 键和 null 值、增删查效率高,适用于大多数键值对存储场景。
(1)HashMap 的核心特性
- 无序性:键值对的存储顺序与添加顺序无关,遍历顺序不固定。
- null 支持:允许 1 个 null 键,允许多个 null 值(如
map.put(null, 10); map.put(null, 20);会覆盖为 null 键对应的值 20)。 - 线程不安全:多线程环境下,若同时修改
HashMap(如添加 / 删除元素),可能导致数据不一致或抛出ConcurrentModificationException,若需线程安全,可使用ConcurrentHashMap(推荐)或Collections.synchronizedMap(new HashMap<>())。
(2)HashMap 的扩容机制
- 初始容量:默认初始容量为 16(数组长度),可通过构造方法指定(如
new HashMap<>(32))。 - 负载因子:默认值为 0.75,表示当键值对数量超过 “容量 × 负载因子”(如 16×0.75=12)时,触发扩容。
- 扩容规则:扩容时将数组长度扩大为原容量的 2 倍(如 16→32→64...),并重新计算所有键的哈希值,将键值对迁移到新数组中(“重哈希”),频繁扩容会消耗性能,建议提前估算数据量,指定合适的初始容量。
(3)HashMap 的构造方法
// 1. 默认构造:初始容量16,负载因子0.75
Map<String, Integer> map1 = new HashMap<>();
// 2. 指定初始容量:负载因子默认0.75
Map<String, Integer> map2 = new HashMap<>(32);
// 3. 指定初始容量和负载因子
Map<String, Integer> map3 = new HashMap<>(32, 0.8f);
// 4. 从其他Map转换
Map<String, Integer> tempMap = new HashMap<>();
tempMap.put("a", 1);
Map<String, Integer> map4 = new HashMap<>(tempMap);
2.2.5 TreeMap:红黑树实现的有序键值对集合
TreeMap底层基于红黑树实现,特点是按键排序、键唯一、不支持 null 键、有序,适用于需要 “按键排序” 的键值对场景(如按日期排序的日志记录:Key 为日期,Value 为日志内容)。
(1)TreeMap 的排序方式
与TreeSet类似,TreeMap的排序依赖键的比较逻辑,分为两种方式:
-
自然排序:键的类需实现
Comparable接口,并重写compareTo()方法,按键的自然顺序排序。// 键为Integer(已实现Comparable),按键升序排序 Map<Integer, String> treeMap1 = new TreeMap<>(); treeMap1.put(3, "C"); treeMap1.put(1, "A"); treeMap1.put(2, "B"); // 遍历输出:1:A, 2:B, 3:C(按键升序) for (Map.Entry<Integer, String> entry : treeMap1.entrySet()) { System.out.println(entry.getKey() + ":" + entry.getValue()); } -
自定义排序:创建
TreeMap时传入Comparator接口实现类,自定义键的排序规则。// 键为String,按字符串长度降序排序 Map<String, Integer> treeMap2 = new TreeMap<>((k1, k2) -> { return k2.length() - k1.length(); // 按键长度降序 }); treeMap2.put("apple", 5); treeMap2.put("banana", 6); treeMap2.put("pear", 4); // 遍历输出:banana:6, apple:5, pear:4(按键长度降序) for (Map.Entry<String, Integer> entry : treeMap2.entrySet()) { System.out.println(entry.getKey() + ":" + entry.getValue()); }
(2)TreeMap 的特有方法(排序相关)
由于TreeMap按键有序,提供了一些基于键排序的特有方法:
Map<Integer, String> treeMap = new TreeMap<>();
treeMap.put(1, "A");
treeMap.put(2, "B");
treeMap.put(3, "C");
treeMap.put(4, "D");
Integer firstKey = treeMap.firstKey(); // 获取最小键(1)
Integer lastKey = treeMap.lastKey(); // 获取最大键(4)
Integer lowerKey = treeMap.lowerKey(3); // 获取小于3的最大键(2)
Integer higherKey = treeMap.higherKey(3); // 获取大于3的最小键(4)
// 获取键≥2且<4的子Map(包含2,不包含4)
Map<Integer, String> subMap = treeMap.subMap(2, true, 4, false);
// 子Map内容:2:B, 3:C
2.2.6 HashMap 与 TreeMap 的对比选择
| 对比维度 | HashMap | TreeMap |
|---|---|---|
| 底层结构 | 哈希表(数组 + 链表 / 红黑树) | 红黑树 |
| 排序特性 | 无序(按哈希值存储) | 有序(按键的自然 / 自定义顺序) |
| 增删查效率 | 高(O (1),无哈希冲突时) | 中(O (log n)) |
| 键的 null 支持 | 允许 1 个 null 键 | 不允许 null 键(会抛空指针) |
| 线程安全 | 不安全 | 不安全 |
| 适用场景 | 无需排序,需高效增删查(如用户信息、配置映射) | 需按键排序(如按日期的日志、按价格的商品映射) |
三、不可变集合:线程安全的常量容器
不可变集合是创建后无法修改的集合(添加、删除、修改元素会抛出UnsupportedOperationException),具有线程安全、不可篡改的特性,适用于存储常量数据(如配置参数、固定枚举值)或作为公共 API 的返回值(避免外部修改)。
3.1 不可变集合的创建方式
Java 提供 4 种创建不可变集合的方式,各有适用场景:
方式 1:Collections.unmodifiableXXX () —— 不可变视图(浅拷贝)
通过Collections工具类的unmodifiableList()、unmodifiableSet()、unmodifiableMap()方法,从现有可变集合创建 “不可变视图”。
- 特点:视图依赖原集合,原集合修改会同步影响视图(浅拷贝),仅限制视图的修改操作。
- 示例:
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class UnmodifiableExample {
public static void main(String[] args) {
// 1. 创建可变集合
List<String> mutableList = new ArrayList<>();
mutableList.add("apple");
// 2. 创建不可变视图
List<String> immutableList = Collections.unmodifiableList(mutableList);
// 3. 视图修改会抛异常
// immutableList.add("banana"); // UnsupportedOperationException
// 4. 原集合修改,视图会同步变化(浅拷贝特性)
mutableList.add("banana");
System.out.println(immutableList); // 输出:[apple, banana]
}
}
方式 2:List/Set/Map.of () —— 直接创建不可变集合(深拷贝)
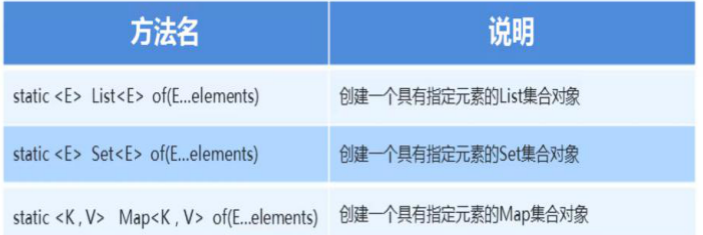
Java 9 + 中,List、Set、Map接口新增of()静态方法,可直接传入元素创建不可变集合,元素不可修改,且不依赖原集合(深拷贝)。
- 特点:
- 元素不可重复(
Set.of()、Map.of()),重复会抛IllegalArgumentException。 Map.of()最多支持 10 个键值对,超过需用Map.ofEntries()。
- 元素不可重复(
- 示例:
import java.util.List;
import java.util.Map;
import java.util.Set;
public class ImmutableOfExample {
public static void main(String[] args) {
// 1. 创建不可变List
List<String> immutableList = List.of("apple", "banana", "cherry");
// 2. 创建不可变Set(元素不可重复)
Set<Integer> immutableSet = Set.of(1, 2, 3);
// 3. 创建不可变Map(键不可重复,最多10个键值对)
Map<String, Integer> immutableMap = Map.of(
"apple", 1,
"banana", 2,
"cherry", 3
);
// 修改操作均抛异常
// immutableList.add("date"); // UnsupportedOperationException
// immutableSet.remove(1); // UnsupportedOperationException
// immutableMap.put("pear", 4); // UnsupportedOperationException
}
}
方式 3:Collectors.toUnmodifiableXXX () —— Stream 流收集(Java 10+)
Java 10 + 中,Collectors工具类新增toUnmodifiableList()、toUnmodifiableSet()、toUnmodifiableMap()方法,可将Stream流的结果收集为不可变集合。
- 示例:
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class ImmutableCollectorExample {
public static void main(String[] args) {
// 将Stream流中的字符串转为大写,收集为不可变List
List<String> upperList = Stream.of("apple", "banana", "cherry")
.map(String::toUpperCase)
.collect(Collectors.toUnmodifiableList());
// 修改抛异常
// upperList.add("DATE"); // UnsupportedOperationException
System.out.println(upperList); // 输出:[APPLE, BANANA, CHERRY]
}
}
方式 4:第三方库(如 Guava)—— 更灵活的不可变集合
Google 的 Guava 库提供了更强大的不可变集合实现(如ImmutableList、ImmutableMap),支持 Builder 模式,可创建任意长度的不可变集合,且性能优于 JDK 原生方式。
- 依赖(Maven):
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>32.1.3-jre</version>
</dependency>
import com.google.common.collect.ImmutableList;
import com.google.common.collect.ImmutableMap;
public class GuavaImmutableExample {
public static void main(String[] args) {
// 1. 用of()创建不可变List
ImmutableList<String> list = ImmutableList.of("a", "b", "c");
// 2. 用Builder创建不可变Map(支持任意长度)
ImmutableMap<String, Integer> map = ImmutableMap.<String, Integer>builder()
.put("a", 1)
.put("b", 2)
.put("c", 3)
.build();
// 修改抛异常
// list.add("d"); // UnsupportedOperationException
}
}
3.2 不可变集合的核心优势与适用场景
- 核心优势:
- 线程安全:无需同步锁,多线程可安全共享,避免并发修改问题。
- 不可篡改:数据创建后无法修改,保证数据一致性(如配置参数不被意外修改)。
- 性能优化:不可变集合无需预留扩容空间,内存占用更小,部分操作(如哈希值)可提前计算,提升效率。
- 适用场景:
- 存储固定不变的数据(如系统配置、枚举列表、常量字典)。
- 作为方法返回值(避免外部调用者修改集合内容,保证 API 安全性)。
- 多线程环境下共享数据(无需额外同步,简化代码)。
四、数组与集合的对比总结
| 对比维度 | 数组 | 集合 |
|---|---|---|
| 长度特性 | 固定长度,创建后不可修改 | 动态长度,支持自动扩容 |
| 元素类型 | 支持基本类型和引用类型 | 仅支持引用类型(基本类型需用包装类) |
| 内存存储 | 连续内存空间 | 非连续(如 LinkedList、HashSet)或部分连续(如 ArrayList) |
| 核心方法 | 无内置方法,需手动实现(或用 Arrays 工具类) | 内置增删改查方法(add、remove、contains 等) |
| 遍历方式 | 普通 for 循环、增强 for 循环 | 增强 for 循环、迭代器、forEach(Lambda) |
| 线程安全 | 本身无线程安全特性,需手动同步 | 大部分集合(ArrayList、HashMap)不安全,需用 Concurrent 系列或不可变集合 |
| 适用场景 | 固定长度、频繁查询(如数组下标访问) | 动态长度、需频繁增删(如购物车、用户列表) |
五、知识扩展
5.1 哈希表的工作原理(HashMap/HashSet 底层)
哈希表(Hash Table)是 “数组 + 链表 / 红黑树” 的组合结构,核心是通过哈希函数将键映射到数组的指定位置(桶),实现高效的增删查:
- 哈希函数:通过键的
hashCode()计算哈希值,再通过 “哈希值 & (数组长度 - 1)”(等价于取模,效率更高)确定桶位置(数组索引)。 - 哈希冲突:不同键计算出相同桶位置的情况,解决方案:
- 链表法:将同一桶中的元素连成链表,查询时遍历链表。
- 红黑树法:JDK 8 + 中,当链表长度超过 8 且数组长度≥64 时,链表转为红黑树,将查询时间复杂度从 O (n) 降至 O (log n)。
- 负载因子:控制哈希表的 “满度”,默认 0.75,平衡空间与时间效率:负载因子过高会增加哈希冲突,降低查询效率;过低会浪费内存空间。
5.2 红黑树的特性(TreeMap/TreeSet 底层)
红黑树是一种自平衡的二叉搜索树,通过以下规则保证平衡,确保增删查时间复杂度为 O (log n):
- 每个节点要么是红色,要么是黑色。
- 根节点是黑色。
- 所有叶子节点(NIL 节点)是黑色。
- 若一个节点是红色,其两个子节点必须是黑色(无连续红色节点)。
- 从任意节点到其所有叶子节点的路径中,黑色节点的数量相同(黑高一致)。
- 当插入或删除节点破坏上述规则时,红黑树会通过 “旋转”(左旋、右旋)和 “变色” 调整,恢复平衡状态。
5.3 自动装箱与拆箱(集合存储基本类型的原理)
集合仅支持引用类型,存储基本类型时需通过 “自动装箱”(基本类型→包装类)和 “自动拆箱”(包装类→基本类型)实现,本质是编译器的语法糖:
- 自动装箱:如
list.add(10),编译器自动转为list.add(Integer.valueOf(10)),将int转为Integer。 - 自动拆箱:如
int num = list.get(0),编译器自动转为int num = list.get(0).intValue(),将Integer转为int。 - 注意事项:避免在循环中频繁装箱(如
for (int i=0; i<1000; i++) list.add(i)),会创建大量临时Integer对象,建议提前手动装箱或使用基本类型集合(如 Eclipse Collections、FastUtil)。
5.4 线程安全的集合类
默认的集合类(如 ArrayList、HashMap、HashSet)均为线程不安全,多线程环境下需使用线程安全的集合,常用选择:
- Concurrent 系列:JDK 提供的高效线程安全集合,如
ConcurrentHashMap(HashMap 的线程安全版)、CopyOnWriteArrayList(ArrayList 的线程安全版),通过分段锁、写时复制等机制实现安全,性能优于同步集合。 - 同步集合:通过
Collections.synchronizedXXX()创建,如Collections.synchronizedList(new ArrayList<>()),底层用synchronized关键字加锁,性能较低(全表锁),适合并发量小的场景。 - 不可变集合:如
List.of()、ImmutableList,本身不可修改,天然线程安全,适合存储常量数据。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









