







最近学习字符串的算法,在哈希之后,开始学习KMP,看了一些资料,稍微有些了解,先记下来,给自己看,所以把理解的过程写的详细一些
先引入一些基本概念:KMP是主要用于字符串匹配的算法。字符串匹配就是给定一个主串(称作T)例如:a b a c a a b a c a b a c a b a a b b,再给定一个要匹配的模式串(称作W)为:a b a c a b,看看主串T中是否有模式串W。
如果是采用暴力匹配的话,那就是从头依次比较两个串的每个字符,当发现不同时,此次匹配失败(称为失配)。接下来就从主串的第二个字符开始再从头比较。------这样的效率当然是很低的。
改进的方法就是研究模式串w,根据模式串的特点,减少无效的比较次数。
主要的思想就是:假设两个指针i和j分别指向主串和模式串并开始进行匹配,比较指针i指向的字符和j指向的字符,如果两个字符相同,则两个指针都+1,继续比较下一个字符;当比较到某个字符不同时,指向主串的指针i不必回溯到上次开始位置的下一个字符,而是保持i指针不动,只需要适当移动模式串的指针j就可以了。这样就减少了比较次数
也就是说匹配的过程中,出现有不一样的字符时,说明这一次匹配失败了。这是不需要回溯主串的指针i。至于模式串的指针j,有可能让j=0,从头开始重新匹配模式串;也有可能让j等于一个不为0的数,也就是j也可能不必回溯到0,而是模式串的某一个位置重新开始匹配就可以了。
下面通过几个例子一步一步分析:
第一种情况,主串“abcdx…”,模式串“abcde”,每一个字符都不相同,i和j都从0开始进行匹配,当i=4、j=4时,本次匹配失败。我们当然没有必要让i=1,j=0开始下一次匹配,而是让i=4保持不变,让j=0就可以了。也就是从主串的’x’这个字符开始重新开始匹配模式串。
为什么可以这样呢?因为模式串“abcde”是5个都不相同的字符,前4个已经匹配成功,说明主串的第0、1、2、3个字符和子串的第0、1、2、3个字符是一样的,都是各不相同的“abcd”这几个字符。这样,也就没有必要让i=1、j=0做下一次匹配,因为主串的第1个字符‘b’肯定不等于与子串的第0个字符‘a’,同理,主串的第2、3个字符‘c’、‘d’也都不同于子串的第0个字符‘a’,因此没有必要一一比较。只需要直接从主串的第4个字符重新开始和子串的第0个匹配就可以。
第二种情况:
这一次模式串“abcae”中不是完全不同的5个字符了,而是有两个相同的‘’a’。而且凑巧的是,当i=4、j=4匹配到第5个字符的时候失配了。当然,为了减少比较次数,我们仍然让i保持i=4不变。但这时,j不必回到0从模式串的开头重新下一次的匹配,而是让j=1,从模式串的第1个字符开始比较。因为在刚才已经匹配的前4个字符串“abca”,最后一个字符和第一个字符都是‘a’,主串的T[4]=‘x’和模式串的W[4]='e’比较失配,在开始新的一轮匹配时,相当于主串中刚才已经匹配的最后一个字符T[3]='a’已经和模式串的第0个字符W[0]='a’匹配上了,这时只需要让主串当前位置i=4的T[4]='x’和模式串的第1个字符W[1]='b’比较就可以了。
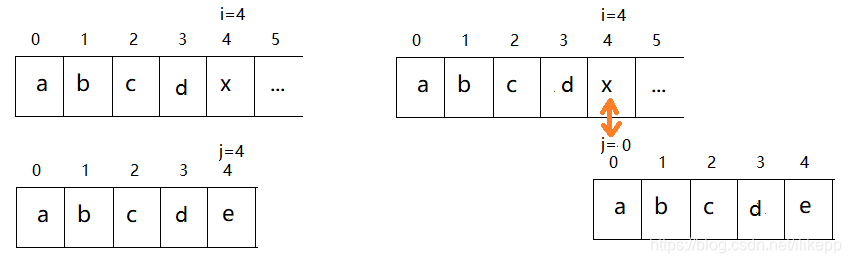
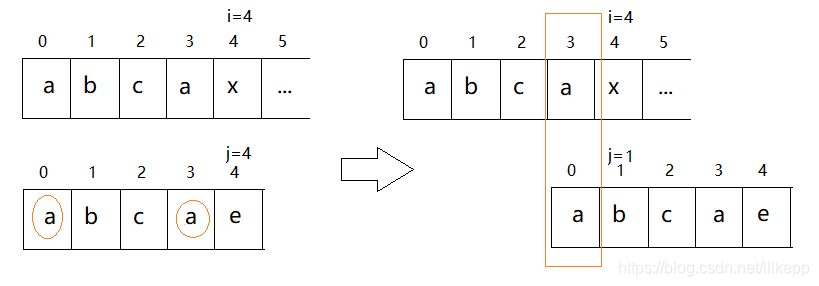
在这种情况中,j之所以不需要回0,是因为在已经匹配的部分“abca”中,开头的字符和结尾的字符相同,都是’a’,也就是有相同的前缀和后缀,这个末尾的’a’可以认为是下一次匹配时已经和模式串开头的’a’匹配好了,j这时只需要指向下一个字符j=1继续进行比较就可以了。
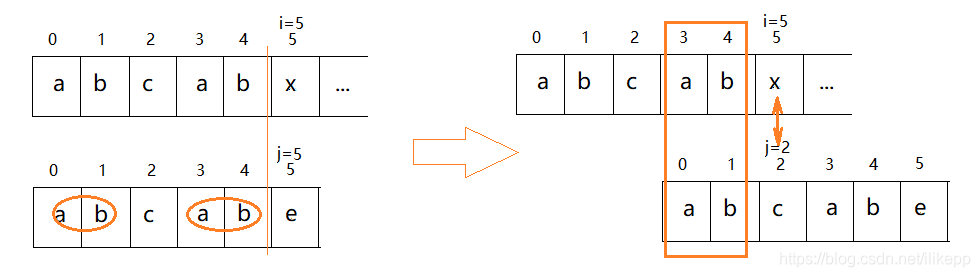
类似的,再如下图模式串是“abcabe”,当比较到第5个字符j=5,w[5]=‘e’时失配。这时,已经匹配的部分’abcab’中,前两个字符’ab’和后两个字符’ab’是一样的,即有相同的前后缀’ab’,那么让j=2,从w[2]='c’开始新的一次匹配就可以了。
当然,在这种情况下让j=2也不是最好的选择,这个一会再进一步研究。
现在继续找规律:
可以发现我们不用关心主串,只要研究模式串就可以了。在匹配的过程中,当比较到模式串某一个位置 j 时出现失配,我们只要研究模式串中 j 这个位置以前的这一部分,就可以知道下一次重新匹配时 j 该指向哪里(主串中的i是要保持不变的)。如果 j 前面的部分有 最大长度为k个字符的共同前后缀,那么下一次重新匹配时,让i保持不变,j=k就可以了。
当然,我们不用在匹配的过程中每次失配时,再来检查j前面有没有共同的前后缀,来决定下一次匹配时j应该指向模式串的哪里。我们可以提前把模式串中每个字符前面的最大长度前后缀算好,放在一个名叫next[j]的数组中,在每次匹配过程中,当发生失配时,让j=next[j]并开始下一次匹配就可以了。
计算next[j]的原理:看看这第j个字符之前的(j-1)个字符串 w[0 … j-1 ]有没有相同的前后缀,如果有最大长度为k个字符的前后缀,那么next[j] = k。而第0个字符的next值一般为“-1”:next[0]= -1
例如:
| 0 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|
| w | a | b | c | a | b | d |
| next[i] | -1 | 0 | 0 | 0 | 1 | 2 |
next[ 0 ] = -1 :第0个字符的next值为“-1”
next[ 1 ] = 0 :第1个字符‘b’前面的字符串“a”的前后缀长度为0
next[ 2 ] = 0 :第2个字符‘c’前面的字符串“ab”的前后缀长度为0
next[ 3 ] = 0 :第3个字符‘a’前面的字符串“abc”的前后缀长度为0
next[ 4 ] = 1 :第4个字符‘b’前面的字符串“abca”的前后缀长度为1
next[ 5 ] = 2 :第5个字符‘d’前面的字符串“abcab”的前后缀长度为2
下面我们看看给定一个模式串,计算生成它的next[ ]数组的代码该如何实现。
public static int[] getNext(String ps) {
char[] w = ps.toCharArray();
int[] next = new int[w.length];
//--初始化---
next[0] = -1; //next[0]=-1,首字符的next值为-1
int j = 0; //指针j初值为0,查找前后缀时的右指针
int k = -1; //k可以理解为当前找到的共同前后缀长度,也是左指针,初值为-1
while (j < w.length - 1) { //指针j小于模式串长度-1时循环处理
if (k == -1 || w[j] == w[k]) { //是前后缀(左右指针字符相同)
next[++j] = ++k; //j指针的下一个字符的next值为++k
} else {
k = next[k];
}
}
return next;
}
在这里,要通过对模式串w[]查找它每一个子串的前后缀长度来确定每一个next[]的值。因此设置了两个指针j和k,我理解j是指向当前处理到w[ ]中第几个字符。也可以理解为指向模式串右边当前字符的指针。j为某一个值时,代表着正在处理w[0…j]这个子串,要计算出w[0…j]这个子串的最大前后缀的长度,并把这个长度当做next[j+1]的值。
例如:当j=5时,就是要计算w[0…5]这前6个字符的前后缀最大长度,如果这个长度是2,那么next[6]的值就是2,
k是记录当前前后缀的长度,也相当于左指针,初始值为-1,循环开始后,k从0开始处理。每次拿最右边的字符(也就是w[j])和最左边的字符(也就是w[k],这时k=0 )比较,如果相同,找到了一个字符的前后缀,这是k加1,j也加1,继续比较最右边的下一个字符w[j]和左边的下一个字符w[k]
因此这个k,既是当前前后缀的长度,也是代表找前后缀过程中指向前缀的指针。当k=0时,代表还没有共同前后缀,k也指向字符串最左边的字符w[0]。如果要找前后缀的话,就是比较w[0]和w[j],如果两字符相同,k加成1,j也加1,这时前后缀的长度为1,接下来也要比较w[1]和w[j],以此类推……。当w[k]和w[j]不同时,最终k还是要回到0,从最左边的w[0]重新开始找下一个前后缀。
所以,代码中初始值j=0、k=-1。循环开始后,当w[j] == w[k]时 next[++j] = ++k;
最关键的,也是比较难的一点是,当比较w[j] ≠ w[k]时怎么办呢?是否可以直接让k重新回到0,下次再从新从最左边w[0]开始找前后缀呢?答案是不可以。
比如w[]= “abad…abab”,前后缀的长度已经是3了,左右两边都有“aba”,在比较“abad”和“abab”时发现这两个长度为4个字符的前后缀是不同的,这时,还需要再缩短子串的长度,看看长度为2的前后缀(最左边的2个和最右边的2个)是否相同,也就是“ab”和“ab”。

假设当前j=8,k=0,这时 w[0]=w[8],此时前9个字符有公共子串‘a’,所以,k要加1,j也要加1,代表着w[9]之前的9个字符子串“a……a”,共同前后缀长度为1,所以:next[9] = 1。
这时,要接着循环(因为 j < w.length - 1))
接下来的这次循环,要继续匹配下一个前后缀字符,也就是:上一次循环时,k=0, j=8时,w[0] == w[8],这一次k=1, j=9,要比较 w[1] == w[9]了。当然这一次也匹配上了 w[1]=w[9]=‘b’,所以,k++,j++,next[10]=2;
再一次循环,k=2,j=11, w[2] 和w[11]都是‘a’,又匹配了,所以,k++,j++,next[11]=3
再一次循环,k=3,j=12, w[3] 和w[12]比较,这次不一样,w[3]是‘d’,而w[12]是‘b’。当w[j] == w[k] 这个条件不成立时,要执行k = next[k];,他的意思是,k=3,最左边的4个字符和最右边的4个字符失配,但刚才已经匹配了3个字符,最左边的3个和最右边除了最后一个的前3个是匹配的,长度为4的前后缀匹配失败了,并不意味着就完全失配,这时应缩短长度再检查一下,把前后缀的长度减小到3、2、1再检查一下,也许就匹配了。也就是现在只是左边第4个和最右边的一个不一样,也许
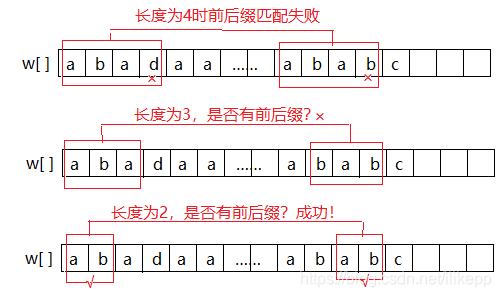
代码中,当出现:w[j] == w[k] 不成立时, 执行:k = next[k]。为什么是k=next[k]呢?还是通过例子分析吧:
在这个例子中,此时的j=11、k=3、w[3]=‘d’、w[11]=‘b’;next[3]=1。这个时候意味着最左边的3个字符w[0…2]和目前右边的三个w[8…10]相同,左边的第4个w[3]和最右边的w[11]不同。也就是前后缀匹配到了第4个字符的时候失败了,按照刚才的思路,接下来要看看前后缀的长度缩短后能不能找到共同前后缀,比如在这前12个字符的串中,最左3个和最右3个是否相同?最左2个和最右2个是否相同?第1个和最后一个是否相同?如果连第1个和最后1个也不相同的话,那就说明这12个字符的串是没有共同前后缀的。如果能找到短一点的共同前后缀,那说明前面相同的这三个字符组成的串本身也是有共同前后缀的,即“aba”的共同前后缀是‘a’,这样最左边的‘ab’才有可能和最右边的‘ab’匹配成为较短的一个共同前后缀。
综上所述,当w[k]≠w[j]时,说明前面已经有k个字符是匹配的了,这是next[k]的值就是刚才这k个已匹配的字符的共同前后缀长度,把next[k]作为新的k值,下一次比较w[k]和w[j]就可以,如果还不相等,就再一次把next[k]做为新的k值,直到k值为0,比较w[0]和w[j],再不相等,k=next[k]值将变为-1。
还是上例中的情况,j=11、k=3、w[3]=‘d’、w[11]=‘b’;next[3]=1,w[3]<>w[11],因此执行了k=next[k]之后,k变为1,这样,下一次循环时就要比较 w[1]和w[11]是不是相等了。在此例中w[1]是‘b’,w[11]也是‘b’,正好相等,执行 next[++j]=++k;,在j的下一个单元next[12]中记录k值为2,且j和k都加1,这就是对于前12个字符找到了长度为2的共同前后缀。如果这次比较还是不同,那么将再一次执行k=next[k],k值变为0,下一次比较w[0]和w[11],如果还不相同,再k=next[k]后k值变为-1,意味着一直找到头也不相同(w[0]就是最左边的字符了)。
k变为-1之后,在下一次循环时,if的条件成立,将执行next[++j] = ++k;,k和j首先都加1,k=0、j指向右边下一个字符,开始计算下一个字符的next值。














 654
654











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









