







Hadoop-3.1.3 集群安装部署
本文介绍在内网的四台服务器上部署hadoop集群的详细流程。
参考资料:
环境
服务器操作系统:CentOS 6.10
JDK安装包(版本):jdk-8u251-linux-x64.rpm
Hadoop版本:hadoop-3.1.3
集群设备
四台服务器,一台作为master,三台slave:
1.Hostname配置
Hadoop集群内部有时候会通过主机名来互相通信,因此我们需要保证每一台主机名都不相同。同时,好的主机名有助于我们区分不同的节点。
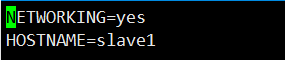
对于每台机器,执行vim /etc/sysconfig/network命令,将HOSTNAME修改为该台机器的主机名,例如master或者slave1。
然后(对于每台主机),执行vim /etc/hosts命令,建立ip和主机的映射关系

执行reboot命令重启服务器,然后执行hostname命令查看主机名修改是否成功。
2.解压hadoop和安装jdk
通过Xshell 6中的Xftp工具将hadoop安装包和jdk安装包上传到每个服务器的/opt文件夹下,然后进行安装和解压。
1)安装jdk:
rpm -ivh jdk-8u101-linux-x64.rpm
2)解压hadoop:
tar zxf hadoop-3.1.3.tar.gz
通过命令java -verison查看jdk安装是否成功:

3.环境变量配置
1)找到环境变量位置
HADOOP_HOME就是hadoop安装包解压的位置,JAVA_HOME可通过以下方式找出:

2)配置环境变量
执行命令 vim /etc/profile,添加以下代码以配置环境变量(根据java和hadoop的安装位置)

4.SSH免密登录配置
1)在本地机器上生成公钥、私钥对:
ssh-keygen -t rsa
2)将公钥追加到authorized_keys文件中:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
3)将authorized_keys权限修改为600:
chmod 0600 ~/.ssh/authorized_keys
4)将公钥拷贝到其它机器(每一个节点都执行以下拷贝操作,当然,不用拷贝给当前所在节点。例如,你正在master,就不用执行下面):
ssh-copy-id -i ~/.ssh/id_rsa.pub master
ssh-copy-id -i ~/.ssh/id_rsa.pub slave1
ssh-copy-id -i ~/.ssh/id_rsa.pub slave2
ssh-copy-id -i ~/.ssh/id_rsa.pub slave3
5)测试是否配置成功:

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4552
4552











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









