









主要步骤
- 界定问题并从着眼于全局
- 获取数据
- 通过发现并可视化数据来得到见解
- 为机器学习算法准备数据
- 选择多种候选模型并训练,进而选择表现最佳的系统
- 优化模型
- 展示结果
- 启动、监控并维护学习系统
0、处理真实数据
以下是一些提供开放数据集的网站:
- UC Irvine Machine Learning Repository
- Kaggle datasets
- Amazon’s AWS datasets
- Data Portals
- OpenDataMonitor
- Quandl
- Wikipedia’s list of Machine Learning datasets
- The datasets subreddit
- Quora.com
1、界定问题并从着眼于全局
- 用商业术语定义目标
- 您的解决方案将如何使用?
- 目前的解决方案/变通方法
- 如何界定问题?
- 如何定量评估模型的表现:均方根差法(Root Mean Square Error (RMSE)),数学公式如下:
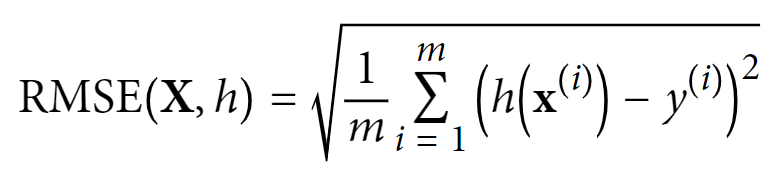
- 其中 m 表示用于计算 RMSE 的数据集中的实例数;x(i) 表示数据集中第 i 个实例的全部特征值组成的向量,y(i) 表示第 i 个实例对应的标签(即想要的输出值);X 表示数据集中所有实例的所有特征值组成的矩阵,每一行都表示一个实例,第 i 行表示 x(i) 的转置,记作 (x(i))T ;h 表示系统的预测值,又叫做假设(hypothesis);RMSE(X, h) 表示在样例集上使用假设 h 的开销函数
- 模型的性能是否与商业目标相一致?
- 达到商业目标的最低性能要求是什么?
- 可以进行类比的问题是什么?能否使用其经验或工具?
- 人类的专业知识是否可用?
- 您如何手动的解决这个问题?
- 列出你或其他人迄今为止做出的假设?
- 如果可能的话,对假设进行验证?
2、获取数据
- 列出所需的数据及数据量
- 寻找并记录您可以在哪里获取这些数据?
- 检查它需要多少空间?
- 检查法律义务,并在必要时获取授权
- 获取访问授权
- 创建工作区(具有足够的存储空间)
- 获取数据
- 将数据转换为易于处理的格式,但是不改变数据本身内容
- 确保敏感性数据被删除或保护
- 检查数据规模和类型
- 从训练数据中采样一个测试集(通常是20%,如果数据量非常大,可以适当减小),把它放到一边,不要用它训练模型
问题:下载数据时报错:urlretrieve timeout[WinError 10060]
方案:下载数据之前先设置代理,如下:
# set proxy
proxy = urllib.request.ProxyHandler({"https":"http://your proxy IP:port"})
opener = urllib.request.build_opener(proxy)
urllib.request.install_opener(opener)
urllib.request.retrieve(housing_url, tgz_path)
3、探索数据
- 创建用于探索的数据副本(如有必要,将其降低到可管理的规模)
- 创建Jupyter笔记,对数据探索进行记录
- 研究每个属性及其特征:名称、类型、缺失值的比例、噪声和噪声类型(随机、异常值、舍入错误等)、对任务的有用性、分布类型(高斯分布、均匀分布、对数分布等)
- 对于监督学习任务,识别任务属性
- 可视化数据
- 研究数据之间的相关性
- 研究如何手动解决问题
- 识别您可能想应用的有望实现或完成任务的转换
- 识别可能有用的额外数据
- 记录你所学到的东西
4、准备数据
注意事项:
1、只处理数据副本,保证原始数据不变
2、为使用的所有数据转换编写函数,有以下原因:① 下一次可以很容易地处理新的数据;② 在未来的项目中也可以使用这些转换函数;③ 清洗数据并准备测试集;④ 在解决方案启动后,清洗并准备新的数据实例;⑤ 使得选择超参数变得容易
- 数据清洗:① 修复或删除异常值(可选); ② 填充缺失值或删除这些记录
- 特征选择(可选):删除对于任务没有作用的属性
- 特征工程(设计制造):① 离散连续属性; ② 分解属性; ③ 如果对任务有帮助,则进行属性转换; ④ 如果对任务有帮助,将多个属性聚合成一种新属性
- 特征缩放:标准化(standardize)或规范化(normalize)特征
5、列出合适的候选模型
注意事项:
1、如果数据很庞大,你可能想要采样较小的训练集,这样你可以在相对合适的时间训练多个不同的模型(这种方法不适用于复杂的模型,比如大型神经网络、随机森林,因为它们需要大规模数据的训练才能保证良好的表现)
2、尽可能将这些步骤自动化
- 使用标准参数对快速而粗糙的模型(如线性回归、简单贝叶斯、(支持向量机)SVM、随机森林、神经网络)进行训练
- 测试并比较它们的性能:对于每一种模型,通过N层交叉验证并计算性能测试的平均值和标准分布
- 对每一种算法,分析最重要的那些变量
- 分析每个模型产生的错误的类型:人类会使用哪些数据来避免这些错误?
- 快速进行一轮特征选择和工程(设计制造)
- 对前面的5个步骤进行一次或2次快速迭代
- 把性能最好的2-5个模型列入候选,优先选择产生不同错误类型的模型
6、微调系统
注意事项:
1、这一步你可能希望使用尽可能多的数据,尤其是快到微调步骤的尾声时
2、尽可能将这些步骤自动化
3、不要在测试完泛化误差后微调系统
- 使用交叉验证微调超参数:① 把你的数据转换选择作为超参数,尤其是当你不确定时(比如是否用0或平均值代替缺失值,还是丢弃这些数据);② 除非可选的超参数值很少,否则更推荐随机搜索而不是网格搜索。如果训练时间很长,更推荐贝叶斯优化算法
- 尝试整体方法。将表现最好的模型组合使用的效果会比单独使用单独运行它们更好
- 当你对最终的模型很有信心时,在测试集上测试以估计该算法的泛化错误
7、展示你的解决方案
- 记录你所做的一切
- 创建一个好的展示方案:确保优先突出显示全局
- 解释为什么你的解决方案实现了目标
- 不要忘记展示你在这个过程中发现的有趣的地方:① 描述哪些方法奏效,哪些不奏效 ② 列出你的假设以及系统的局限性
- 确保你的发现通过优美的可视化或容易记住的描述来展示:
8、启用你的项目
- 让您的解决方案为实际应用做好准备
- 编写监控代码,以检查你的系统在一定时间内的实时性能,当其下降时做出预警:① 小心缓慢的退化;② 测试性能可能需要人力资源; ③ 也要监控输入数据的质量,对于在线学习尤其重要
- 根据新数据,定期重新训练您的模型














 339
339











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









