







 本文深入讲解JavaScript的基础知识,包括HelloWorld示例、运算符、switch语句等内容。详细介绍了算术、赋值、比较和位运算符的特点及优先级,探讨了switch语句的用法与案例。
本文深入讲解JavaScript的基础知识,包括HelloWorld示例、运算符、switch语句等内容。详细介绍了算术、赋值、比较和位运算符的特点及优先级,探讨了switch语句的用法与案例。
一. 基础知识
1.1 JavaScript之HelloWorld
<script>
console.log("hello world!!!")
</script>
script可以内联代码,也可以通过src属性来引入外部指定脚本代码
1.2 运算符
运算元: 指的是运算符作用的对象
一元运算符: 作用于一个运算元
二元运算符: 作用于两个运算元
JavaScript中运算符主要用于连接简单表达式,组成一个复杂的表达式。常见的有算数表达式、比较表达式、逻辑表达式、赋值表达式等,也有单目运算符,指操作原始表达式。大多数运算符都由标点符号组成(+、>=、!),也有关键字表示的运算符,如typeof、delete、instanceof等。
-
一、算数运算符:
1、加法运算符:a + b
2、减法运算符: a - b
3、乘法运算符: a * b
4、除法运算符:a / b
5、余数运算符:a % b
6、自增运算符:++a 或者a++
7、自减运算符:–a 或者 a–
8、求负运算符:-a
9、数值运算符: +a -
二、赋值运算符:
赋值运算符用于给变量赋值,最常见的赋值运算符是等号,表达式a=b表示将b赋值给a.
1、a += b // 等同于 a = a + b
2、a -= b // 等同于 a = a - b
3、a *= b // 等同于 a = a * b
4、a /= b // 等同于 a = a / b
5、a %= b // 等同于 a = a % b
6、a >>= b // 等同于 a = a >> b
7、a <<= b // 等同于 a = a << b
8、a >>>= b // 等同于 a = a >>> b
9、a &= b // 等同于 a = a & b
10、a |= b // 等同于 a = a | b
11、a ^= b // 等同于 a = a ^ b -
三、比较运算符:
比较运算符比较两个值,然后返回一个布尔值,表示是否满足比较条件。JavaScript提供了8个比较运算符。
1、相等:==
2、严格相等: ===
3、不相等:!=
4、严格不相等:!==
5、小于:<
6、小于或等于:<=
7、大于:>
8、大于或等于:>= -
四、三元运算符:
语法:表达式1 ? 表达式2 : 表达式3
说明:如果表达式1为true ,则整个表达式的结果就是表达式2的值,如果表达式false,则整个表达式的结果就是表达式3的值. -
五、位运算符:
1、或运算:符号为|,表示两个二进制位中有一个为1,则结果为1,否则为0。
2、与运算:符号为&,表示两个二进制位都为1,则结果为1,否则为0。
3、否运算:符号为~,表示将一个二进制位变成相反值。
4、异或运算:符号为ˆ,表示两个二进制位中有且仅有一个为1时,结果为1,否则为0。
5、左移运算:符号为<<右
6、移运算:符号为>>
运算符的优先级
| 优先级 | 运算符 | 说明 | 结合性 |
|---|---|---|---|
| 1 | []、.、() | 字段访问、数组索引、函数调用和表达式分组 | 从左向右 |
| 2 | ++ – -~!delete new typeof void | 一元运算符、返回数据类型、对象创建、未定 义的值 | 从右向左 |
| 3 | *、/、% | 相乘、相除、求余数 | 从左向右 |
| 4 | +、- | 相加、相减、字符串串联 | 从左向右 |
| 5 | <<、>>、>>> | 左位移、右位移、无符号右移 | 从左向右 |
| 6 | <、<=、>、>=、instanceof | 小于、小于或等于、大于、大于或等于、是否 为特定类的实例 | 从左向右 |
| 7 | 、!=、=、!== | 相等、不相等、全等,不全等 | 从左向右 |
| 8 | & | 按位“与” | 从左向右 |
| 9 | ^ | 按位“异或” | 从左向右 |
| 10 | | | 按位“或” | 从左向右 |
| 11 | && | 短路与(逻辑“与”) | 从左向右 |
| 12 | || | 短路或(逻辑“或”) | 从左向右 |
| 13 | ?: | 条件运算符 | 从右向左 |
| 14 | =、+=、-=、*=、/=、%=、&=、|=、^=、<、<=、>、>=、>>= | 混合赋值运算符 | 从右向左 |
| 15 | , | 多个计算 | 按优先级计算,然后从右向左 |
1.3 switch语句
switch 语句可以替代多个 if 判断。
switch 语句为多分支选择的情况提供了一个更具描述性的方式。
switch 语句有至少一个 case 代码块和一个可选的 default 代码块。
let a = 2 + 2;
switch (a) {
case 3:
alert( 'Too small' );
case 4:
alert( 'Exactly!' );
case 5:
alert( 'Too big' );
default:
alert( "I don't know such values" );
}
任何表达式都可以成为 switch/case 的参数
let a = "1";
let b = 0;
switch (+a) {
case b + 1:
alert("this runs, because +a is 1, exactly equals b+1");
break;
default:
alert("this doesn't run");
}
这里 +a 返回 1,这个值跟 case 中 b + 1 相比较,然后执行对应的代码。
Case分组
共享同一段代码的几个 case 分支可以被分为一组:
比如,如果我们想让 case 3 和 case 5 执行同样的代码:
let a = 3;
switch (a) {
case 4:
alert('Right!');
break;
case 3: // (*) 下面这两个 case 被分在一组
case 5:
alert('Wrong!');
alert("Why don't you take a math class?");
break;
default:
alert('The result is strange. Really.');
}
switch的case执行的是严格相等,因此类型必须匹配
1.4 值的比较
值的比较
我们知道,在数学中有很多用于比较大小的运算符:
- 大于 / 小于:
a > b,a < b。 - 大于等于 / 小于等于:
a >= b,a <= b。 - 检查两个值的相等:
a == b(注意表达式中是两个等号=,若写为单个等号a = b则表示赋值)。 - 检查两个值不相等,在数学中使用
≠符号,而在 JavaScript 中则通过在赋值符号前加叹号表示:`a != b
和其他运算符一样,比较运算符也会有返回值,返回值为布尔值(Boolean)。
true—— 表示“yes(是)”,“correct(正确)”或“the truth(真相)”。false—— 表示“no(否)”,“wrong(错误)”或“not the truth(非真相)”。
示例:
alert( 2 > 1 ); // true(正确)
alert( 2 == 1 ); // false(错误)
alert( 2 != 1 ); // true(正确)
和其他类型的值一样,比较的结果可以被赋值给任意变量:
let result = 5 > 4; // 把比较的结果赋值给 result
alert( result ); // true
在比较字符串的大小时,JavaScript 会使用“字典(dictionary)”或“词典(lexicographical)”顺序进行判定。
换言之,字符串是按字符(母)逐个进行比较的。
例如:
alert( 'Z' > 'A' ); // true
alert( 'Glow' > 'Glee' ); // true
alert( 'Bee' > 'Be' ); // true
字符串的比较算法非常简单:
- 首先比较两个字符串的首位字符大小。
- 如果一方字符较大(或较小),则该字符串大于(或小于)另一个字符串。算法结束。
- 否则,如果两个字符串的首位字符相等,则继续取出两个字符串各自的后一位字符进行比较。
- 重复上述步骤进行比较,直到比较完成某字符串的所有字符为止。
- 如果两个字符串的字符同时用完,那么则判定它们相等,否则未结束(还有未比较的字符)的字符串更大。
在上面的例子中,'Z' > 'A' 在算法的第 1 步就得到了返回结果,而字符串 Glow 与 Glee 则继续逐个字符比较:
G和G相等。l和l相等。o比e大,算法停止,第一个字符串大于第二个。
非真正的字典顺序,而是 Unicode 编码顺序
在上面的算法中,比较大小的逻辑与字典或电话簿中的排序很像,但也不完全相同。
比如说,字符串比较对字母大小写是敏感的。大写的 "A" 并不等于小写的 "a"。哪一个更大呢?实际上小写的 "a" 更大。这是因为在 JavaScript 使用的内部编码表中(Unicode),小写字母的字符索引值更大。我们会在 字符串 这章讨论更多关于字符串的细节。
当对不同类型的值进行比较时,JavaScript 会首先将其转化为数字(number)再判定大小。
例如:
alert( '2' > 1 ); // true,字符串 '2' 会被转化为数字 2
alert( '01' == 1 ); // true,字符串 '01' 会被转化为数字 1
对于布尔类型值,true 会被转化为 1、false 转化为 0。
例如:
alert( true == 1 ); // true
alert( false == 0 ); // true
一个有趣的现象
有时候,以下两种情况会同时发生:
- 若直接比较两个值,其结果是相等的。
- 若把两个值转为布尔值,它们可能得出完全相反的结果,即一个是
true,一个是false。
例如:
let a = 0;
alert( Boolean(a) ); // false
let b = "0";
alert( Boolean(b) ); // true
alert(a == b); // true!
对于 JavaScript 而言,这种现象其实挺正常的。因为 JavaScript 会把待比较的值转化为数字后再做比较(因此 "0" 变成了 0)。若只是将一个变量转化为 Boolean 值,则会使用其他的类型转换规则。
普通的相等性检查 == 存在一个问题,它不能区分出 0 和 false:
alert( 0 == false ); // true
也同样无法区分空字符串和 false:
alert( '' == false ); // true
这是因为在比较不同类型的值时,处于相等判断符号 == 两侧的值会先被转化为数字。空字符串和 false 也是如此,转化后它们都为数字 0。
如果我们需要区分 0 和 false,该怎么办?
严格相等运算符 === 在进行比较时不会做任何的类型转换。
换句话说,如果 a 和 b 属于不同的数据类型,那么 a === b 不会做任何的类型转换而立刻返回 false。
让我们试试:
alert( 0 === false ); // false,因为被比较值的数据类型不同
同样的,与“不相等”符号 != 类似,“严格不相等”表示为 !==。
严格相等的运算符虽然写起来稍微长一些,但是它能够很清楚地显示代码意图,降低你犯错的可能性。
当使用 null 或 undefined 与其他值进行比较时,其返回结果常常出乎你的意料。
-
当使用严格相等
===比较二者时它们不相等,因为它们属于不同的类型。
alert( null === undefined ); // false -
当使用非严格相等
==比较二者时JavaScript 存在一个特殊的规则,会判定它们相等。他们俩就像“一对恋人”,仅仅等于对方而不等于其他任何的值(只在非严格相等下成立)。
alert( null == undefined ); // true -
当使用数学式或其他比较方法
< > <= >=时:null/undefined会被转化为数字:null被转化为0,undefined被转化为NaN。
下面让我们看看,这些规则会带来什么有趣的现象。同时更重要的是,我们需要从中学会如何远离这些特性带来的“陷阱”。
通过比较 null 和 0 可得:
alert( null > 0 ); // (1) false
alert( null == 0 ); // (2) false
alert( null >= 0 ); // (3) true
是的,上面的结果完全打破了你对数学的认识。在最后一行代码显示“null 大于等于 0”的情况下,前两行代码中一定会有一个是正确的,然而事实表明它们的结果都是 false。
为什么会出现这种反常结果,这是因为相等性检查 == 和普通比较符 > < >= <= 的代码逻辑是相互独立的。进行值的比较时,null 会被转化为数字,因此它被转化为了 0。这就是为什么(3)中 null >= 0 返回值是 true,(1)中 null > 0 返回值是 false。
另一方面,undefined 和 null 在相等性检查 == 中不会进行任何的类型转换,它们有自己独立的比较规则,所以除了它们之间互等外,不会等于任何其他的值。这就解释了为什么(2)中 null == 0 会返回 false。
undefined 不应该被与其他值进行比较:
alert( undefined > 0 ); // false (1)
alert( undefined < 0 ); // false (2)
alert( undefined == 0 ); // false (3)
为何它看起来如此厌恶 0?返回值都是 false!
原因如下:
(1)和(2)都返回false是因为undefined在比较中被转换为了NaN,而NaN是一个特殊的数值型值,它与任何值进行比较都会返回false。(3)返回false是因为这是一个相等性检查,而undefined只与null相等,不会与其他值相等。
我们为何要研究上述示例?我们需要时刻记得这些古怪的规则吗?不,其实不需要。虽然随着代码写得越来越多,我们对这些规则也都会烂熟于胸,但是我们需要更为可靠的方法来避免潜在的问题:
除了严格相等 === 外,其他凡是有 undefined/null 参与的比较,我们都需要额外小心。
除非你非常清楚自己在做什么,否则永远不要使用 >= > < <= 去比较一个可能为 null/undefined 的变量。对于取值可能是 null/undefined 的变量,请按需要分别检查它的取值情况。
- 比较运算符始终返回布尔值。
- 字符串的比较,会按照“词典”顺序逐字符地比较大小。
- 当对不同类型的值进行比较时,它们会先被转化为数字(不包括严格相等检查)再进行比较。
- 在非严格相等
==下,null和undefined相等且各自不等于任何其他的值。 - 在使用
>或<进行比较时,需要注意变量可能为null/undefined的情况。比较好的方法是单独检查变量是否等于null/undefined。
1.5 函数Function
一、函数基本概念
为完成某一功能的程序指令(语句)的集合,称为函数。
二、JavaScript函数的分类
1、自定义函数(我们自己编写的函数),如:function funName(){}
2、系统函数(JavaScript自带的函数),如alert函数。
三、函数的调用方式
1、普通调用:functionName(实际参数…)
2、通过指向函数的变量去调用:
var myVar=函数名;
myVar(实际参数…);
四、函数返回值
1.当函数无明确返回值时,返回的值就是"undefined"。
2.当函数有返回值时,返回值是什么就返回什么。
五、函数的可变参数:
函数的参数列表可以是任意多个,并且数据类型可以是任意的类型,JavaScript的函数天然支持可变参数,JavaScript有一个arguments变量可以访问所有传到函数内部的参数。
范例:JavaScript使用arguments创建参数可变的函数
[ ](javascript:void(0)😉
](javascript:void(0)😉
1 <script type="text/javascript">
2 /*add函数是一个参数可变的函数*/
3 function add(){
4 var result=0;
5 for(var i=0;i<arguments.length;i++){
6 //alert(arguments[i]);
7 result+=arguments[i];
8 }
9
10 return result;
11 }
12 alert("add(1,2,3)="+add(1,2,3));//调用add函数时传入3个参数
13 alert("add(1,2,3,4,5,6)="+add(1,2,3,4,5,6));//调用add函数时传入6个参数
14 alert("add()="+add());//调用add函数时不传入参数
15 alert("add(1,\"HelloWorld\")="+add(1,"HelloWorld"));//调用add函数时传入不同类型的参数
16 </script>
六、函数的动态创建
创建动态函数的基本格式:var 变量名 = new Function(“参数1”,“参数2”,“参数n”,“执行语句”);
1 <script type="text/javascript">
2 var square = new Function ("x","y","var sum ; sum = x+y;return sum;");
3 alert("square(2,3)的结果是:"+square(2,3));
4 </script>
七、匿名函数
直接声明一个匿名函数,立即使用。用匿名函数的好处就是省得定义一个用一次就不用的函数,而且免了命名冲突的问题,js中没有命名空间的概念,因此很容易函数名字冲突,一旦命名冲突以最后声明的为准。
alert(function(i1, i2) { return i1 + i2; }(10,10));
八、JavaScript不支持函数重载
九. 函数表达式
另一种创建函数的语法称为 函数表达式。
通常会写成这样:
let sayHi = function() {
alert( "Hello" );
};
在这里,函数被创建并像其他赋值一样,被明确地分配给了一个变量。不管函数是被怎样定义的,都只是一个存储在变量 sayHi 中的值。
上面这两段示例代码的意思是一样的:“创建一个函数,并把它存进变量 sayHi”。
我们还可以用 alert 打印这个变量值:
function sayHi() {
alert( "Hello" );
}
alert( sayHi ); // 显示函数代码
注意,最后一行代码并不会运行函数,因为 sayHi 后没有括号。在其他编程语言中,只要提到函数的名称都会导致函数的调用执行,但 JavaScript 可不是这样。
在 JavaScript 中,函数是一个值,所以我们可以把它当成值对待。上面代码显示了一段字符串值,即函数的源码。
的确,在某种意义上说一个函数是一个特殊值,我们可以像 sayHi() 这样调用它。
但它依然是一个值,所以我们可以像使用其他类型的值一样使用它。
我们可以复制函数到其他变量:
function sayHi() { // (1) 创建
alert( "Hello" );
}
let func = sayHi; // (2) 复制
func(); // Hello // (3) 运行复制的值(正常运行)!
sayHi(); // Hello // 这里也能运行(为什么不行呢)
解释一下上段代码发生的细节:
(1)行声明创建了函数,并把它放入到变量sayHi。(2)行将sayHi复制到了变量func。请注意:sayHi后面没有括号。如果有括号,func = sayHi()会把sayHi()的调用结果写进func,而不是sayHi函数 本身。- 现在函数可以通过
sayHi()和func()两种方式进行调用。
注意,我们也可以在第一行中使用函数表达式来声明 sayHi:
let sayHi = function() {
alert( "Hello" );
};
let func = sayHi;
// ...
这两种声明的函数是一样的。
为什么这里末尾会有个分号?
你可能想知道,为什么函数表达式结尾有一个分号 ;,而函数声明没有:
function sayHi() {
// ...
}
let sayHi = function() {
// ...
};
答案很简单:
- 在代码块的结尾不需要加分号
;,像if { ... },for { },function f { }等语法结构后面都不用加。 - 函数表达式是在语句内部的:
let sayHi = ...;,作为一个值。它不是代码块而是一个赋值语句。不管值是什么,都建议在语句末尾添加分号;。所以这里的分号与函数表达式本身没有任何关系,它只是用于终止语句。
1.6 现代模式"use strict"
严格模式是在ES5中引入的,它可以视为JS的一个子集,在严格模式下,限制了JS的标准使用下一些行为。
- 严格模式消除了一些 JavaScript的静默错误,通过改变它们来抛出错误。
- 严格的模式修复了 JavaScript引擎难以执行优化的错误:有时候,严格模式代码可以比非严格模式的相同的代码运行得更快。
- 严格模式禁用了在ECMAScript的未来版本中可能会定义的一些语法。
这个指令看上去像一个字符串 "use strict" 或者 'use strict'。当它处于脚本文件的顶部时,则整个脚本文件都将以“现代”模式进行工作。
"use strict" 可以被放在函数主体的开头,而不是整个脚本的开头。这样则可以只在该函数中启用严格模式。但通常人们会在整个脚本中启用严格模式。
没有类似于 "no use strict" 这样的指令可以使程序返回默认模式。
一旦进入了严格模式,就没有回头路了。
一:简单介绍
严格模式是在ES5中引入的,它可以视为JS的一个子集,在严格模式下,限制了JS的标准使用下一些行为。
- 严格模式消除了一些 JavaScript的静默错误,通过改变它们来抛出错误。
- 严格的模式修复了 JavaScript引擎难以执行优化的错误:有时候,严格模式代码可以比非严格模式的相同的代码运行得更快。
- 严格模式禁用了在ECMAScript的未来版本中可能会定义的一些语法。
但是需要注意的是:**不支持严格模式的浏览器将会执行与支持严格模式的浏览器不同行为的严格模式代码。**所以不要依靠严格模式,而是应当加强自己代码的鲁棒性
二:使用方法
严格模式可以应用于整个脚本或单个函数中。其中的脚本不仅仅包括了单个文件,还包括了dom中事件处理,eval(),Function(),以及window.setTimeOut()中的字符串。
1:为某个脚本使用严格模式
需要在所有代码前,声明
"use strict";
PS:注意,必须为"use strict";或者’use strict’;,且必须带分号结束。
但这种使用方式在存在代码引用和合并的时候,会无法正常激活严格模式。因为,当一个声明了严格模式的脚本,被引入合并到一个新的未使用严格模式的脚本中的时候,由于声明并没有在所有代码前使用,从而导致严格模式声明失败。
为了保证严格模式的正常使用,一般的做法是用一个外部匿名函数将使用严格模式的脚本封装,然后执行。代码一般如下
(function () {
'use strict';
/**** 原有脚本代码 ****/
})()
但需要注意的是,这种方法,会将原有的代码封装到一个全局环境的函数中,原有脚本代码的作用域由全局变为了函数内部作用域,因此在使用的时候,务必注意。
PS:一个变通的方法是,将内部脚本需要全局的变量,直接声明为全局变量,即不用var或者let定义,比如a,不适用var a;或者let a;,而是直接 a = xxx
2:单函数使用严格模式
单函数使用严格模式,只需要在函数代码开头声明
"use strict";
即可
三:严格模式带来的具体差异
1:消除了静默错误,改为抛出错误
- 无法静默声明全局变量
全局变量必须显式声明,标准模式下,如果一个变量没有声明就赋值,默认是全局变量。严格模式禁止这种用法,全局变量必须显式声明。
"use strict";
v = 1; // 报错,v未声明
for(i = 0; i < 2; i++) { // 报错,i未声明
}
- 函数的参数必须命名唯一
在正常模式中,如果函数的参数中出现重名,则最后出现的重名参数替换之前出现的参数,但之前出现的参数依然可以通过arguments属性读取。在严格模式下,禁止出现这种情况,此时会跳出错误。
function sum(a, a, c){ // !!! 语法错误
"use strict";
return a + a + c; // 代码运行到这里会出错
}
- 对象的属性名必须唯一
严格模式要求一个对象内的所有属性名在对象内必须唯一。正常模式下重名属性是允许的,最后一个重名的属性决定其属性值。
"use strict";
var o = { p: 1, p: 2 }; // !!! 语法错误
- 禁止出现八进制数字数据
在ES标准中,并没有八进制数据,但现在的浏览器都支持以0开头作为八进制数据。严格模式下禁止了这种数据类型,但在ES6中,新引入了’0o’前缀来表示八进制数据
var a = 015; // 错误
var a = 0o10; // ES6: 八进制
- 任何在正常模式下引起静默失败的赋值操作 (给不可赋值的全局变量赋值,给不可写属性赋值, 给只读属性(getter-only)赋值赋值, 给不可扩展对象(non-extensible object)的新属性赋值) 都会抛出异常
"use strict";
NaN = 1; // 不可复制的全局变量
var o = {
get v() {
return this.v
}
};
Object.defineProperty(o, "v", { value: 1, writable: false }); // 不可写的属性
o.v = 2; // 报错
var o1 = {
get v() { return 1; } // 只读属性
};
o1.v = 2; // 报错
// 给不可扩展对象的新属性赋值
var fixed = {};
Object.preventExtensions(fixed);
fixed.newProp = "ohai"; // 抛出TypeError错误
- 试图删除不可删除的属性时会抛出异常
"use strict";
delete Object.prototype; // 抛出TypeError错误
- ECMAScript 6中的严格模式禁止设置primitive值的属性.
2:修复了JS的随意性,提升了优化能力
在标准模式下,JS的随意性,或者灵活性,是的很多变量,只有在运行时才能确切知道具体指向,这就使得变量名到内存的映射也只有到运行时才能完成。严格模式修复了大部分这种行为,使得所有的变量名在编译的时候,就已经可以一起进行优化,从而提升了执行速度。
- 禁止使用with
在标准模式中,使用with的时候,with代码块内的变量,只有在运行时,才能根据with引入的Obj是否存在相应的属性,来确定具体的指向。因此,严格模式禁止使用with
"use strict";
var x = 17;
with (obj) // !!! 语法错误
{
// 如果没有开启严格模式,with中的这个x会指向with上面的那个x,还是obj.x?
// 如果不运行代码,我们无法知道,因此,这种代码让引擎无法进行优化,速度也就会变慢。
x;
}
- eval不在为上层作用域引入新变量
在标准模式下,如果某个函数内部引入了eval代码。那么在函数内部,所有出现的名称(也就是所有的变量名)应当映射到的变量,除了引用到函数的参数,以及函数的内部变量,可以在编译的时候确定外,其他所有的名称只有在运行的时候,执行完eval代码后才能映射到相应的变量。因为有些变量可能是由eval代码引入到函数作用域的。
var x = 17;
var evalX = eval("'use strict'; var x = 42; x");
console.log(x === 17); // true 未能引入x,所以还是原来的x,但如果去掉 use strict,那么为false
console.log(evalX === 42); // true
但在严格格式下,eval不在为上层作用域引入新的局部变量和全局变量。所有的eval中出现的变量,只在eval的字符串代码块中有效。
另外如果判定eval是否为严格模式,也存在各种复杂的情况。
– 如果直接调用eval(…)代码的代码块显式使用了严格格式,那么eval()也执行严格格式。如下面代码
function test () {
'use strict';
eval(...) // 无论eval中的字符串是否包含 use strict; 都会进入严格格式
}
– 如果直接调用eval的代码块未使用严格模式,而是更上级别的代码块使用了严格模式,则eval代码按照标准模式执行,如下面代码
function test () {
'use strict';
f(){} // 无论eval中的字符串是否包含 use strict; 都会进入严格格式
}
– 如果eval(…)的字符串中显式使用了’use strict’; 则必然进入严格模式
- 严格模式禁止删除声明变量
"use strict";
var x;
delete x; // !!! 语法错误
eval("var y; delete y;"); // !!! 语法错误
3:让eval和arguments变的更加简单
- 严格模式下,eval和arguments作为保留字
在严格模式下,不允许对eval和arguments进行赋值或者绑定,以下代码全部为错误语法
"use strict";
eval = 17;
arguments++;
++eval;
var obj = { set p(arguments) { } };
var eval;
try { } catch (arguments) { }
function x(eval) { }
function arguments() { }
var y = function eval() { };
var f = new Function("arguments", "'use strict'; return 17;");
经过测试,这里的不得对arguments的复制,指的是arguments这个变量,而不是指的其中的元素,比如
function test (a, b) {
'use strict';
a = 42;
arguments[1] = 17; // 可以通过语法检测,但并不会修改b的值
}
依然是允许的,也可以通过语法检测。
- 严格模式下,参数的值,不会随arguments对象的值的变化而修改。arguments对象的值的修改也不会影响同名函数。
在标准模式下,比如一个函数第一个参数为arg,那么在函数内部,修改arg的时候,也会同步修改arguments[0],反之亦然。但在严格模式下,两者进行了隔离。函数的 arguments 对象会保存函数被调用时的原始参数。arguments[i] 的值不会随与之相应的参数的值的改变而变化,同名参数的值也不会随与之相应的 arguments[i] 的值的改变而变化。 - 不再支持arguments. callee
4:更加安全的JS
- 对this的严格限制
在普通模式下,无论任何情况下,this都是一个对象。需要注意:this的指向不在函数定义的时候是确定不了的,只有函数执行的时候才能确定this到底指向谁,在标准模式下,只想调用函数的对象。但如果是箭头函数,则this为定义时上下文的this。
-使用new新建对象
function test () {
console.log(typeof this);
return this;
}
var t = new test()
console.log(t) // this 为新建的对象
-使用call,apply,bind传入this,如果传入的是数字,字符串,布尔值等,那么就会将这些基本数据的this转换为Number,String,Boolean对象类型。如果传入的是null和undefined,则为全局变量window,默认调用下,this也为window
function fun() {
console.log(typeof this)
return this;
}
console.log(fun()); // window 需要注意,单独的此类 fun(),等价于window.fun()。所以为window
console.log(fun.call(2)); // Number
console.log(fun.call('2018-01-01 10:00:00')); // String
console.log(fun.apply(null)); // window
console.log(fun.call(undefined)); // window
console.log(fun.bind(true)()); // Boolean
上面的这种模式既增加了转换为对象的对象的开销,又因为将全局对象window暴露出来造成安全性问题。
因此在严格模式下指定的this不再被封装为对象,而且如果没有指定this的话它值是undefined,上面的结果如下:
'use strict';
function fun() {
console.log(typeof this)
return this;
}
console.log(fun()); // undefined
console.log(fun.call(2)); // 2
console.log(fun.call('2018-01-01 10:00:00')); // '2018-01-01 10:00:00'
console.log(fun.apply(null)); // null
console.log(fun.call(undefined)); // undefined
console.log(fun.bind(true)()); // true
- 禁止对函数扩展,fun.caller和fun.arguments进行读取和复制
在普通模式下用这些扩展的话,当一个叫fun的函数正在被调用的时候,fun.caller是最后一个调用fun的函数,而且fun.arguments包含调用fun时用的形参。通过这些扩展,可以让不安全的用户操作到危险的属性。
因此在严格模式下,fun.caller和fun.arguments都是不可删除的属性而且在存值、取值时都会报错
5:对未来的兼容
- 增加了一些保留字
在严格模式中一部分字符变成了保留的关键字。这些字符包括implements, interface, let, package, private, protected, public, static和yield - 禁止不在脚本或者函数层面声明函数
所谓的脚本层面,指的是文件的全局作用域。而函数层面,指的是函数的直接作用域,这里并不包括了脚本中的块作用域,以及函数中嵌套的块作用域
"use strict";
if (true){
function f() { } // !!! 语法错误
f();
}
for (var i = 0; i < 5; i++){
function f2() { } // !!! 语法错误
f2();
}
function baz() { // 合法
function eit() { } // 同样合法
}
1.7 变量
如果将变量想象成一个“数据”的盒子,盒子上有一个唯一的标注盒子名字的贴纸。这样我们能更轻松地掌握“变量”的概念。
例如,变量 message 可以被想象成一个标有 "message" 的盒子,盒子里面的值为 "Hello!":
我们可以在盒子内放入任何值。
并且,这个盒子的值,我们想改变多少次,就可以改变多少次:
当值改变的时候,之前的数据就被从变量中删除了:
变量命名
JavaScript 的变量命名有两个限制:
- 变量名称必须仅包含字母,数字,符号
$和_。 - 首字符必须非数字。
全局变量和局部变量
全局变量: 声明在全局环境下的变量或者在函数中未使用var而直接赋值的变量也会被自动提升到全局环境
局部变量: 在函数内容声明的变量,只在函数内部有效,如果与全局变量重名,则优先级更高
1.8 条件运算符和?
if(...) 语句计算括号里的条件表达式,如果计算结果是 true,就会执行对应的代码块。
if (…) 语句会计算圆括号内的表达式,并将计算结果转换为布尔型。
- 数字
0、空字符串""、null、undefined和NaN都会被转换成false。因为他们被称为 “falsy” 值。 - 其他值被转换为
true,所以它们被称为 “truthy”。
所以,下面这个条件下的代码永远不会执行:
if (0) { // 0 是 falsy
...
}
……但下面的条件 —— 始终有效:
if (1) { // 1 是 truthy
...
}
我们也可以将未计算的布尔值传入 if 语句,像这样:
let cond = (year == 2015); // 相等运算符的结果是 true 或 false
if (cond) {
...
}
if 语句有时会包含一个可选的 “else” 块。如果判断条件不成立,就会执行它内部的代码。
有时我们需要测试一个条件的几个变体。我们可以通过使用 else if 子句实现。
let year = prompt('In which year was ECMAScript-2015 specification published?', '');
if (year < 2015) {
alert( 'Too early...' );
} else if (year > 2015) {
alert( 'Too late' );
} else {
alert( 'Exactly!' );
}
条件运算符
这个运算符通过问号 ? 表示。有时它被称为三元运算符,被称为“三元”是因为该运算符中有三个操作数。实际上它是 JavaScript 中唯一一个有这么多操作数的运算符。
语法:
let result = condition ? value1 : value2;
计算条件结果,如果结果为真,则返回 value1,否则返回 value2。
例如:
let accessAllowed = (age > 18) ? true : false;
技术上讲,我们可以省略 age > 18 外面的括号。问号运算符的优先级较低,所以它会在比较运算符 > 后执行。
下面这个示例会执行和前面那个示例相同的操作:
// 比较运算符 “age > 18” 首先执行
//(不需要将其包含在括号中)
let accessAllowed = age > 18 ? true : false;
1.9 交互:alert、prompt 和 confirm
语法:
alert(message);
运行这行代码,浏览器会弹出一个信息弹窗并暂停脚本,直到用户点击了“确定”。
举个例子:
alert("Hello");
弹出的这个带有信息的小窗口被称为 模态窗。“modal” 意味着用户不能与页面的其他部分(例如点击其他按钮等)进行交互,直到他们处理完窗口。在上面示例这种情况下 —— 直到用户点击“确定”按钮。
prompt 函数接收两个参数:
result = prompt(title, [default]);
浏览器会显示一个带有文本消息的模态窗口,还有 input 框和确定/取消按钮。
-
title显示给用户的文本
-
default可选的第二个参数,指定 input 框的初始值。
用户可以在 prompt 对话框的 input 框内输入一些内容,然后点击确定。或者他们可以通过按“取消”按钮或按下键盘的 Esc 键,以取消输入。
prompt 将返回用户在 input 框内输入的文本,如果用户取消了输入,则返回 null。
举个例子:
let age = prompt('How old are you?', 100);
alert(`You are ${age} years old!`); // You are 100 years old!
IE 浏览器会提供默认值
第二个参数是可选的。但是如果我们不提供的话,Internet Explorer 会把 "undefined" 插入到 prompt。
我们可以在 Internet Explorer 中运行下面这行代码来看看效果:
let test = prompt("Test");
所以,为了 prompt 在 IE 中有好的效果,我们建议始终提供第二个参数:
let test = prompt("Test", ''); // <-- for IE
语法:
result = confirm(question);
confirm 函数显示一个带有 question 以及确定和取消两个按钮的模态窗口。
点击确定返回 true,点击取消返回 false。
例如:
let isBoss = confirm("Are you the boss?");
alert( isBoss ); // 如果“确定”按钮被按下,则显示 true
总结
我们学习了与用户交互的 3 个浏览器的特定函数:
-
alert显示信息。
-
prompt显示信息要求用户输入文本。点击确定返回文本,点击取消或按下 Esc 键返回
null。 -
confirm显示信息等待用户点击确定或取消。点击确定返回
true,点击取消或按下 Esc 键返回false。
这些方法都是模态的:它们暂停脚本的执行,并且不允许用户与该页面的其余部分进行交互,直到窗口被解除。
上述所有方法共有两个限制:
- 模态窗口的确切位置由浏览器决定。通常在页面中心。
- 窗口的确切外观也取决于浏览器。我们不能修改它。
1.10 数据类型
值类型(基本类型):字符串(String)、数字(Number)、布尔(Boolean)、对空(Null)、未定义(Undefined)、Symbol。
引用数据类型:对象(Object)、数组(Array)、函数(Function)。
**注:**Symbol 是 ES6 引入了一种新的原始数据类型,表示独一无二的值。
typeof 操作符
你可以使用 typeof 操作符来查看 JavaScript 变量的数据类型。
typeof "John" // 返回 string
typeof 3.14 // 返回 number
typeof NaN // 返回 number
typeof false // 返回 boolean
typeof [1,2,3,4] // 返回 object
typeof {name:'John', age:34} // 返回 object
typeof new Date() // 返回 object
typeof function () {} // 返回 function
typeof myCar // 返回 undefined (如果 myCar 没有声明)
typeof null // 返回 object
请注意:
- NaN 的数据类型是 number
- 数组(Array)的数据类型是 object
- 日期(Date)的数据类型为 object
- null 的数据类型是 object
- 未定义变量的数据类型为 undefined
(很多开发人员将undefined和undeclared混为一谈,但在JavaScript中它们是两码事。undefined是值的一种,表示变量声明过但还没有进行赋值。undeclared则表示变量还没有被声明过。)
如果对象是 JavaScript Array 或 JavaScript Date ,我们就无法通过 typeof 来判断他们的类型,因为都是 返回 object。
constructor 属性
constructor 属性返回所有 JavaScript 变量的构造函数。
"John".constructor // 返回函数 String() { [native code] }
(3.14).constructor // 返回函数 Number() { [native code] }
false.constructor // 返回函数 Boolean() { [native code] }
[1,2,3,4].constructor // 返回函数 Array() { [native code] }
{name:'John', age:34}.constructor // 返回函数 Object() { [native code] }
new Date().constructor // 返回函数 Date() { [native code] }
function () {}.constructor // 返回函数 Function(){ [native code] }
JavaScript 类型转换
JavaScript 变量可以转换为新变量或其他数据类型:
- 通过使用 JavaScript 函数
- 通过 JavaScript 自身自动转换
将数字转换为字符串
全局方法 String() 可以将数字转换为字符串。
该方法可用于任何类型的数字,字母,变量,表达式:
String(x) // 将变量 x 转换为字符串并返回
String(123) // 将数字 123 转换为字符串并返回
String(100 + 23) // 将数字表达式转换为字符串并返回
Number 方法 toString() 也是有同样的效果。
x.toString()
(123).toString()
(100 + 23).toString()
在 Number 方法 章节中,你可以找到更多数字转换为字符串的方法:
| 方法 | 描述 |
|---|---|
| toExponential() | 把对象的值转换为指数计数法。 |
| toFixed() | 把数字转换为字符串,结果的小数点后有指定位数的数字。(只包含小数位) |
| toPrecision() | 把数字格式化为指定的长度。(包含整数位) |
将布尔值转换为字符串
全局方法 String() 可以将布尔值转换为字符串。
String(false) // 返回 "false"
String(true) // 返回 "true"
Boolean 方法 toString() 也有相同的效果。
false.toString() // 返回 "false"
true.toString() // 返回 "true"
将日期转换为字符串
Date() 返回字符串。
Date() // 返回 Thu Jul 17 2014 15:38:19 GMT+0200 (W. Europe Daylight Time)
全局方法 String() 可以将日期对象转换为字符串。
String(new Date()) // 返回 Thu Jul 17 2014 15:38:19 GMT+0200 (W. Europe Daylight Time)
Date 方法 toString() 也有相同的效果。
实例
obj = new Date()
obj.toString() // 返回 Thu Jul 17 2014 15:38:19 GMT+0200 (W. Europe Daylight Time)
| getDate() | 从 Date 对象返回一个月中的某一天 (1 ~ 31)。 |
|---|---|
| getDay() | 从 Date 对象返回一周中的某一天 (0 ~ 6)。 |
| getFullYear() | 从 Date 对象以四位数字返回年份。 |
| getHours() | 返回 Date 对象的小时 (0 ~ 23)。 |
| getMilliseconds() | 返回 Date 对象的毫秒(0 ~ 999)。 |
| getMinutes() | 返回 Date 对象的分钟 (0 ~ 59)。 |
| getMonth() | 从 Date 对象返回月份 (0 ~ 11)。 |
| getSeconds() | 返回 Date 对象的秒数 (0 ~ 59)。 |
| getTime() | 返回 1970 年 1 月 1 日至今的毫秒数。 |
将字符串转换为数字
全局方法 Number() 可以将字符串转换为数字。
字符串包含数字(如 “3.14”) 转换为数字 (如 3.14).
空字符串转换为 0。
其他的字符串会转换为 NaN (不是个数字)。
Number("3.14") // 返回 3.14
Number(" ") // 返回 0
Number("") // 返回 0
Number("99 88") // 返回 NaN
| parseFloat() | 解析一个字符串,并返回一个浮点数。 |
|---|---|
| parseInt() | 解析一个字符串,并返回一个整数。 |
一元运算符 +
Operator + 可用于将变量转换为数字:
var y = "5"; // y 是一个字符串
var x = + y; // x 是一个数字
如果变量不能转换,它仍然会是一个数字,但值为 NaN (不是一个数字):
var y = "John"; // y 是一个字符串
var x = + y; // x 是一个数字 (NaN)
将布尔值转换为数字
Number(false) // 返回 0
Number(true) // 返回 1
将日期转换为数字
全局方法 Number() 可将日期转换为数字。
d = new Date();
Number(d) // 返回 1404568027739
日期方法 getTime() 也有相同的效果。
d = new Date();
d.getTime() // 返回 1404568027739
自动转换类型
当 JavaScript 尝试操作一个 “错误” 的数据类型时,会自动转换为 “正确” 的数据类型。
5 + null // 返回 5 null 转换为 0
"5" + null // 返回"5null" null 转换为 "null"
"5" + 1 // 返回 "51" 1 转换为 "1"
"5" - 1 // 返回 4 "5" 转换为 5
自动转换为字符串
当你尝试输出一个对象或一个变量时 JavaScript 会自动调用变量的 toString() 方法:
document.getElementById("demo").innerHTML = myVar;
myVar = {name:"Fjohn"} // toString 转换为 "[object Object]"
myVar = [1,2,3,4] // toString 转换为 "1,2,3,4"
myVar = new Date() // toString 转换为 "Fri Jul 18 2014 09:08:55 GMT+0200"
数字和布尔值也经常相互转换:
myVar = 123 // toString 转换为 "123"
myVar = true // toString 转换为 "true"
myVar = false // toString 转换为 "false"
下表展示了使用不同的数值转换为数字(Number), 字符串(String), 布尔值(Boolean):
| 原始值 | 转换为数字 | 转换为字符串 | 转换为布尔值 | 实例 |
|---|---|---|---|---|
| false | 0 | “false” | false | 尝试一下 » |
| true | 1 | “true” | true | 尝试一下 » |
| 0 | 0 | “0” | false | 尝试一下 » |
| 1 | 1 | “1” | true | 尝试一下 » |
| “0” | 0 | “0” | true | 尝试一下 » |
| “000” | 0 | “000” | true | 尝试一下 » |
| “1” | 1 | “1” | true | 尝试一下 » |
| NaN | NaN | “NaN” | false | 尝试一下 » |
| Infinity | Infinity | “Infinity” | true | 尝试一下 » |
| -Infinity | -Infinity | “-Infinity” | true | 尝试一下 » |
| “” | 0 | “” | false | 尝试一下 » |
| “20” | 20 | “20” | true | 尝试一下 » |
| “Runoob” | NaN | “Runoob” | true | 尝试一下 » |
| [ ] | 0 | “” | true | 尝试一下 » |
| [20] | 20 | “20” | true | 尝试一下 » |
| [10,20] | NaN | “10,20” | true | 尝试一下 » |
| [“Runoob”] | NaN | “Runoob” | true | 尝试一下 » |
| [“Runoob”,“Google”] | NaN | “Runoob,Google” | true | 尝试一下 » |
| function(){} | NaN | “function(){}” | true | 尝试一下 » |
| { } | NaN | “[object Object]” | true | 尝试一下 » |
| null | 0 | “null” | false | 尝试一下 » |
| undefined | NaN | “undefined” | false | 尝试一下 » |
2.0.1 值
-
数组
- 和其他强类型语言不同,在JavaScript中,数组可以容纳任何类型的值,可以是字符串、数字、对象(object),甚至是其他数组(多维数组就是通过这种方式来实现的)
- 对数组声明后即可向其中加入值,不需要预先设定大小
- 使用delete运算符可以将单元从数组中删除,但是请注意,单元删除后,数组的length属性并不会发生变化
- 数组通过数字进行索引,但有趣的是它们也是对象,所以也可以包含字符串键值和属性(但这些并不计算在数组长度内)
- 类数组
有时需要将类数组(一组通过数字索引的值)转换为真正的数组例如,一些DOM查询操作会返回DOM元素列表,它们并非真正意义上的数组,但十分类似。另一个例子是通过arguments对象(类数组)将函数的参数当作列表来访问(从ES6开始已废止)。工具函数slice(…)经常被用于这类转换:
Array.prototype.slice.call( arguments )
-
字符串
-
字符串不可变: 指字符串的成员函数不会改变其原始值,而是创建并返回一个新的字符串。而数组的成员函数都是在其原始值上进行操作。
-
许多数组函数用来处理字符串很方便。虽然字符串没有这些函数,但可以通过“借用”数组的非变更方法来处理字符串,如
Array.prototype.join.call(a, "-")Array.prototype.map.call(a, (v) => {});
`Array.prototype
数组逆序(借用Array.prototype.reverse(),但是这个函数只能作用于可变对象,字符串为不可变对象,因此进行变通使用)var a = "hello"; var c = a.split("").reverse().join(""); console.log(c);
-
-
数字
-
JavaScript只有一种数值类型:number(数字),包括“整数”和带小数的十进制数
-
由于数字值可以使用Number对象进行封装(参见第3章),因此数字值可以调用Number.prototype中的方法,
toFixed,toPrecision(),等` -
还可以使用指数形式
1E3, 二进制,八进制和十六进制(0x)来表示 -
较小的数值: 二进制浮点数最大的问题(不仅JavaScript,所有遵循IEEE 754规范的语言都是如此),是会出现如下情况:
0.1 + 0.2 === 0.3为false二进制浮点数中的0.1和0.2并不是十分精确,它们相加的结果并非刚好等于0.3,而是一个比较接近的数字0.30000000000000004,所以条件判断结果为false。
那么应该怎样来判断0.1 + 0.2和0.3是否相等呢?最常见的方法是设置一个误差范围值,通常称为“机器精度”(machine epsilon),对JavaScript的数字来说,这个值通常是2^-52 (2.220446049250313e-16)。
从ES6开始,该值定义在
Number.EPSILON,可以基于这个误差值来解决上述问题function equal(n1, n2){ return Math.abs( n1 - n2 ) < Number.EPSILON; } console.log(equal(0.1+0.2, 0.3));整数的安全范围
能够呈现的最大浮点数大约是1.798e+308(这是一个相当大的数字),它定义在Number. MAXVALUE中。最小浮点数定义在Number.MIN VALUE中,大约是5e-324,它不是负数,但无限接近于0!
数字的呈现方式决定了“整数”的安全值范围远远小于Number.MAX VALUE。
能够被“安全”呈现的最大整数是2^53-1,即9007199254740991,在ES6中被定义为Number.MAX SAFE INTEGER。最小整数是-9007199254740991,在ES6中被定义为Number.MIN SAFE INTEGER。
整数检测ES6:
Number.isInteger()
PolyfillNumber.isInteger = function(num){ return typeof num === "number" && num % 1 == 0; }安全整数检测
ES6:Number.isSafeInteger()Polyfill:
Number.isSafeInteger = function(num){ return Number.isInteger( num ) && Math.abs(num) <= Number.MAX_SAFE_INTEGER; }
-
-
特殊的值
-
undefined和null : undefined类型只有一个值,即undefined。null类型也只有一个值,即null。它们的名称既是类型也是值。undefined和null常被用来表示“空的”值或“不是值”的值。二者之间有一些细微的差别。
例如:
• null指空值(empty value)• undefined指没有值(missing value)或者:• undefined指从未赋值• null指曾赋过值,但是目前没有值null是一个特殊关键字,不是标识符,我们不能将其当作变量来使用和赋值。然而undefined却是一个标识符,可以被当作变量来使用和赋值。 -
void运算符: void并不改变表达式的结果,只是让表达式不返回值
return void setTImeout(doSomething, 100) -
特殊的数字:
NaN是一个“警戒值”(sentinel value,有特殊用途的常规值),用于指出数字类型中的错误情况,即“执行数学运算没有成功,这是失败后返回的结果”。ES6开始我们可以使用工具函数Number.isNaN(..), ES6之前使用window.isNaNInfinity和-Infinity: 如果数学运算(如加法)的结果超出处理范围,则由IEEE 754规范中的“就近取整”(round-to-nearest)模式来决定最后的结果。例如,相对于Infinity, Number.MAX VALUE +Math.pow(2, 969)与Number.MAX VALUE更为接近,因此它被“向下取整”(round down);而Number.MAX VALUE + Math.pow(2, 970)与Infinity更为接近,所以它被“向上取整”(roundup)。
+0和-0: 我们可以使用以下代码来区分+0和-0:
function isNegZero(n){ n = Number( n ); return ( n === 0 ) && ( 1 / n === -Infinity); }
-
-
特殊等式
如前所述,NaN和-0在相等比较时的表现有些特别。由于NaN和自身不相等,所以必须使用ES6中的Number.isNaN(…)(或者polyfill)。而-0等于0(对于===也是如此,参见第4章),因此我们必须使用isNegZero(…)这样的工具函数。ES6中新加入了一个工具方法Object.is(…)来判断两个值是否绝对相等,可以用来处理上述所有的特殊情况:
对于ES6之前的版本,Object.is(…)有一个简单的polyfill:Object.is = function(v1, v2){ // 判断是否为-0 if(v1 === 0 && v2 === 0){ return 1/v1 === 1/v2; } // 判断是否是NaN if(v1 !== v1){ return v2 !== v2; } // 其他情况 return v1 === v2; }
2.0.2 原生函数
常用的原生函数有:
- String()
- Number()
- Boolean()
- Array()
- Object()
- Function()
- RegExp()
- Date()
- Error()
- Symbol()——ES6中新加入的!实际上,它们就是内建函数。
内部属性[[Class]]
所有typeof返回值为"object"的对象(如数组)都包含一个内部属性[[Class]](我们可以把它看作一个内部的分类,而非传统的面向对象意义上的类)。这个属性无法直接访问,一般通过Object.prototype.toString(…)来查看。例如:
console.log(Object.prototype.toString.call([1,2,3]));
console.log(Object.prototype.toString.call(/regexp-literal/i));
// 基本类型值被各自的封装对象自动包装,所以它们的内部[[Class]]属性值分别为"String"、"Number"和"Boolean"。
console.log(Object.prototype.toString.call(undefined));
console.log(Object.prototype.toString.call(null));
console.log(Object.prototype.toString.call("abc"));
console.log(Object.prototype.toString.call(42));
console.log(Object.prototype.toString.call(true));
封装对象包装
封装对象(object wrapper)扮演着十分重要的角色。由于基本类型值没有.length和.toString()这样的属性和方法,需要通过封装对象才能访问,此时JavaScript会自动为基本类型值包装(box或者wrap)一个封装对象:
如果需要经常用到这些字符串属性和方法,比如在for循环中使用i < a.length,那么从一开始就创建一个封装对象也许更为方便,这样JavaScript引擎就不用每次都自动创建了。但实际证明这并不是一个好办法,因为浏览器已经为.length这样的常见情况做了性能优化,直接使用封装对象来“提前优化”代码反而会降低执行效率。
一般情况下,我们不需要直接使用封装对象。最好的办法是让JavaScript引擎自己决定什么时候应该使用封装对象。换句话说,就是应该优先考虑使用"abc"和42这样的基本类型值,而非newString(“abc”)和new Number(42)。
拆封
如果想要得到封装对象中的基本类型值,可以使用valueOf()函数:var a = new String("abc"); console.log(a.valueOf());
在需要用到封装对象中的基本类型值的地方会发生隐式拆封(强制类型转换)var a = new String("abc"); var b = a + "";
2.0.3 强制类型转换
将值从一种类型转换为另一种类型通常称为类型转换(type casting),这是显式的情况;隐式的情况称为强制类型转换(coercion)。
类型转换发生在静态类型语言的编译阶段,而强制类型转换则发生在动态类型语言的运行时(runtime)
在介绍显示和隐式类型转换之前我们需要先掌握字符串,数字和布尔值之间类型转换的基本规则。
-
toString()
它负责非字符串到字符串的强制类型转换- 基本类型值的字符串化规则为: null转换为"null", undefined转换为"undefined", true转换为"true", 数字类型转化为带引号的字符串,数字的极大值,极小值转换为指数形式
- 普通对象,返回内部属性[[Class]](如"[object Object]"),如果对象有自己的toString()方法,就会使用该方法的返回值。
- **数组的toString()就经过了重新定义,将所有单元字符串化以后再用","**连接起来
JSON字符串化
JSON.stringify()并非严格意义上的强制类型转换,因为其中也涉及toString()的相关规则,这里顺带介绍一下,对大多数简单值来说, JSON字符串化和toString()效果基本相同,只不过序列化的结果总是字符串,所有安全的JSON值(JSON-safe)都可以使用JSON.stringify()字符串化,安全的JSON值是指能够呈现为有效JSON格式的值。undefined, function, symbol和包含循环引用的对象都不符合JSON结构标准。JSON.stringify()在对象中遇到undefined,function和symbol时会自动将其忽略,在数组中返回null(以保证数组元素位置不变)console.log(JSON.stringify(undefined)); // undefined console.log(JSON.stringify(function(){})); // undefined console.log(JSON.stringify([1, undefined, function(){}, 4]));对包含循环引用的对象执行JSON.stringify()会报错,如果对象定义了**toJSON()**方法,JSON字符串化会首先调用该方法,然后用它的返回值来进行序列化。
如果要对含有非法JSON值的对象做字符串化,或者对象中的某些值无法被序列化时,就需要定义toJSON()方法来返回一个安全的JSONconsole.log(JSON.stringify(undefined)); // undefined console.log(JSON.stringify(function(){})); // undefined console.log(JSON.stringify([1, undefined, function(){}, 4])); // 循环引用对象的字符串化会报错 var o = {}; var a = { b: 42, c: o, d: function(){} }; // 在a中创建一个循环引用 o.e = a; try { JSON.stringify(a); // TypeError: Converting circular structure to JSON } catch (error) { console.log(error); } // toJSON返回的应该是一个适当的值,可以是任何类型,然后再由JSON.stringify()对其进行格式化, // 也就是toJSON()应该返回一个能够被字符串化的安全的JSON值,而不是返回一个JSON字符串 a.toJSON = function(){ return { b: this.b } } console.log(JSON.stringify(a)); // {"b": 42}我们可以向JSON.stringify()传递一个参数replacer,它可以是数组或者函数,用来指定序列化过程中哪些属性应该被处理,哪些应该被排除
如果replacer是一个数组,那么它必须是一个字符串数组,其中包含序列化要处理的对象的属性名称,除此之外其他属性将被忽略
如果replacer是一个函数,它会对对象本身调用一次,然后对对象中的每个属性各调用一次,每次传递两个参数,键和值,如果要忽略某个键就返回undefined,否则返回指定的值。// 使用replacer参数排除属性 var obj = { name: "david", age: 27, job: "frontender" }; console.log(JSON.stringify(obj, ["name", "age"])); // {"name":"david","age":27}, jon属性被排除了 console.log(JSON.stringify(obj, (k, v) => { console.log("调用"); // 调用4次 if(k !== "job"){ return v } // 排除job属性 }));JSON.stringify()还有一个参数space,用来指定输出的缩进格式,space为正整数时是指定每一级缩进的字符数,它可以为一个字符串,此时最前面的10个字符用于每一级的缩进
// 使用space参数指定缩进 console.log(JSON.stringify(obj, null, 3)); console.log(JSON.stringify(obj, null, "***")); -
toNumber
true转换为1, false转换为0, undefined转换为NaN, null转换为0console.log(Number(true)); // 1 console.log(Number(false)); // 0 console.log(Number(undefined)); // NaN console.log(Number(null)); // 0为了将值转换为相应的基本类型值,抽象操作toPrimitive会首先该值是否有valueOf()方法,如果有并且返回基本类型的值,就是用该值进行强制类型转换,如果没有就使用toString()的返回值(如果存在)
var a = { valueOf: function(){ return "42"; } }; var b = { toString: function(){ return "42"; } }; var c = [4,2]; c.toString = function(){ return this.join(""); // 42 } console.log(Number(a)); // 42 console.log(Number(b)); // 42 console.log(Number(c)); // 42 console.log(Number("")); // 0 console.log(Number([])); // 0 console.log(Number([0])); // 0 console.log(Number(["abc"])); // NaN
* **toBoolean**
首先,也是最重要的一点是,JavaScript中有两个关键词true和false,分别代表布尔类型中的真和假。我们常误以为数值1和0分别等同于true和false。在有些语言中可能是这样,但在JavaScript中布尔值和数字是不一样的。虽然我们可以将1强制类型转换为true,将0强制类型转换为false,反之亦然,但它们并不是一回事。
**假值**
JavaScript中的值可以分为以下两类:
(1) **可以被强制类型转换为false的值**
(2) 其他(被强制类型转换为true的值)
以下这些是假值:**undefined**, **null**, **false**, **+0**、**-0**和**NaN**, ""假值的布尔强制类型转换结果为false。
**真值**
假值列表之外的值都是真值
```javascript
var a = "false";
var b = "0";
var c = "''";
// 因为a,b,c都不是空字符串,因此转换成Boolean,都为真值
console.log(Boolean(a)); // true
console.log(Boolean(b)); // true
console.log(Boolean(c)); // true
var d = Boolean(a && b && c);
console.log(d);
- 显示强制类型转换
字符串和数字之间的转换: 使用String()和Number()(没有new关键字), 转换规则分别遵守前面toString()和toNumber()规则
除了String(…)和Number(…)以外,还有其他方法可以实现字符串和数字之间的显式转换:
var a = 42;
var b = a.toString();
var c = "3.14";
var d = +c;
console.log(b);
console.log(c);
a.toString()是显式的(“toString”意为“to a string”),不过其中涉及隐式转换。因为toString()对42这样的基本类型值不适用,所以JavaScript引擎会自动为42创建一个封装对象,然后对该对象调用toString()。这里显式转换中含有隐式转换。
上例中**+c是+运算符的一元(unary)形式(即只有一个操作数)。+运算符显式地将c转换为数字**,而非数字加法运算(也不是字符串拼接)。
日期显示转换为时间戳
// 显示将日期转换为时间戳
var d = new Date();
console.log(+d);
// JavaScript有一处奇特的语法,即构造函数没有参数时可以不用带()
var timestamp = +new Date;
console.log(timestamp);
// 使用getTime显示获取可能更好些
console.log(new Date().getTime());
// 最好还是使用ES5中新增的Date.now()
console.log(Date.now());
// 为老版本提供polyfill
if(!Date.now){
Date.now = function(){
return +new Date();
}
}
// 我们不建议对日期类型使用强制类型转换,应该使用Date.now()来获得当前的时间戳,使用newDate(..).getTime()来获得指定时间的时间戳。
**奇特的~运算符**
~运算符(即字位操作“非”),它**与某些特殊数字在一起使用时会产生类型强制类型转换的效果**,返回另外一个数字, 它首先将值强制类型转换为32位数字,然后执行字位非(对每一个数字进行反转)
还可以有另外一种诠释,源自早期的计算机科学和离散数学:~返回2的补码。这样一来问题就清楚多了!~x大致等同于-(x+1)。很奇怪,但相对更容易说明问题:
`~42; // -(42 + 1) ==> -43`
在-(x+1)中唯一能够得到0(或者严格说是-0)的x值是-1。也就是说如果x为-1时,~和一些数字值在一起会返回假值0,其他情况则返回真值。
-1是一个“哨位值”,哨位值是那些在各个类型中(这里是数字)被赋予了特殊含义的值。在C语言中我们用-1来代表函数执行失败,用大于等于0的值来代表函数执行成功。JavaScript中字符串的indexOf(…)方法也遵循这一惯例,该方法在字符串中搜索指定的子字符串,如果找到就返回子字符串所在的位置(从0开始),否则返回-1。
var a = "Hello World";
if(a.indexOf("lo") >= 0 ){ // true
console.log("找到匹配");
}
if(a.indexOf("lo") != -1 ){ // true
console.log("找到匹配");
}
if(a.indexOf("ol") < 0){ // true
console.log("没有找到匹配");
}
if(a.indexOf("ol") == -1){ // true
console.log("没有找到匹配");
}
// >= 0和== -1这样的写法不是很好,称为“抽象渗漏”,意思是在代码中暴露了底层的实现细节,
// 这里是指用-1作为失败时的返回值,这些细节应该被屏蔽掉。
// ~和indexOf()一起可以将结果强制类型转换(实际上仅仅是转换)为真/假值:
console.log(~a.indexOf("lo")); // -4 真值
if(~a.indexOf("lo")){
console.log("找到匹配");
}
console.log(!~a.indexOf("ol")); // true
if(!~a.indexOf("ol")){
console.log("未找到匹配");
}
// ~比>= 0和== -1更简洁
**字位截除**
我们可以使用`~~1E20`或者`1E20 | 0` 两种方式来截取到Int32
**显示解析数字字符串**
**解析非字符串**
console.log(parseInt(0.000008)); // "0"来自"0.000008"", .不是数字,解析停止
console.log(parseInt(0.0000008)); // 8 "8"来自8e-7
console.log(false, 16); //250 "fa"来自于"false""
console.log(parseInt, 16); // 15 "f"来自于"function""
console.log(parseInt("0x10")); // 16
console.log(parseInt("103", "2")); // 2 3对于2进制转化超出有限值舍去
**显示转换为布尔值**
与前面的String(…)和Number(…)一样,Boolean(…)(不带new)是显式的ToBoolean强制类型转换
一元运算符!显式地将值强制类型转换为布尔值。但是它同时还将真值反转为假值(或者将假值反转为真值)。所以显式强制类型转换为布尔值最常用的方法是!!,因为第二个!会将结果反转回原值
-
隐式强制类型转换
字符串和数字之间的隐式强制类型转换
通过重载,+运算符即能用于数字加法,也能用于字符串拼接。JavaScript怎样来判断我们要执行的是哪个操作?例如:var a = "42"; var b = "0"; var c = 42; var d = 0; console.log(a + b); console.log(c + d); var e = [1,2]; var f = [3,4]; //因为数组的valueOf()操作无法得到简单基本类型值, // 于是它转而调用toString()。因此上例中的两个数组变成了"1,2"和"3,4"。+将它们拼接后返回"1,23,4"。 console.log(e+f); // 1,23,4 // 简单来说就是,如果+的其中一个操作数是字符串(或者通过以上步骤可以得到字符串),则执行字符串拼接;否则执行数字加法。 // -是数字减法运算符,因此a -0会将a强制类型转换为数字。也可以使用a * 1和a /1,因为这两个运算符也只适用于数字,只不过这样的用法不太常见。 var g = [3]; var h = [2]; console.log(g-h); // 为了执行减法运算,a和b都需要被转换为数字,它们首先被转换为字符串(通过toString()),然后再转换为数字。布尔值到数字的隐式强制类型转换
function onlyOne(){ var sum = 0; for(var i = 0; i < arguments.length; i++){ // 跳过假值 if(arguments[i]){ sum += arguments[i]; } } return sum === 1; } var a = true; var b = false; console.log(onlyOne(b, a));通过sum += arguments[i]中的隐式强制类型转换,将真值(true/truthy)转换为1并进行累加。如果有且仅有一个参数为true,则结果为1;否则不等于1, sum == 1条件不成立。同样的功能也可以通过显式强制类型转换来实现
隐式强制类型转换为布尔值下面的情况会发生布尔值隐式强制类型转换。
(1) if (…)语句中的条件判断表达式。
(2) for ( … ; … ; … )语句中的条件判断表达式(第二个)。
(3) while (…)和do…while(…)循环中的条件判断表达式。
(4) ? :中的条件判断表达式。
(5) 逻辑运算符||(逻辑或)和&&(逻辑与)左边的操作数(作为条件判断表达式)。
||和&&
称它们为“选择器运算符”(selector operators)或者“操作数选择器运算符”(operand selector operators)更恰当些。在JavaScript中它们返回的并不是布尔值。它们的返回值是两个操作数中的一个(且仅一个)。即选择两个操作数中的一个,然后返回它的值。
var a = 42; var b = "abc"; var c = null; console.log(a || b); // 42 console.log(a && b); // abc console.log(c || b); // abc console.log(c && b); // null // 换个角度来理解 console.log(a || b); console.log(a?a:b); console.log(a&&b); console.log(a?b:a); // 短路 function foo(){ console.log("a"); } var a = 42; a && foo();||和&&首先会对第一个操作数(a和c)执行条件判断,如果其不是布尔值(如上例)就先进行ToBoolean强制类型转换,然后再执行条件判断。
对于||来说,如果条件判断结果为true就返回第一个操作数(a和c)的值,如果为false就返回第二个操作数(b)的值。
&&则相反,如果条件判断结果为true就返回第二个操作数(b)的值,如果为false就返回第一个操作数(a和c)的值。
||和&&返回它们其中一个操作数的值,而非条件判断的结果(其中可能涉及强制类型转换)。c&& b中c为null,是一个假值,因此&&表达式的结果是null(即c的值),而非条件判断的结果false。
符号的强制类型转换ES6中引入了符号类型,它的强制类型转换有一个坑,在这里有必要提一下。ES6允许从符号到字符串的显式强制类型转换,然而隐式强制类型转换会产生错误
var s1 = Symbol("cool"); console.log(String(s1)); var s2 = Symbol("not cool"); console.log(s2 + ""); // TypeError: Cannot convert a Symbol value to a string符号不能够被强制类型转换为数字(显式和隐式都会产生错误),但可以被强制类型转换为布尔值(显式和隐式结果都是true)
-
宽松相等和严格相等
“允许在相等比较中进行强制类型转换,而=不允许。”
相等比较操作的性能
有人觉得会比=慢,实际上虽然强制类型转换确实要多花点时间,但仅仅是微秒级(百万分之一秒)的差别而已。
如果进行比较的两个值类型相同,则和=使用相同的算法,所以除了JavaScript引擎实现上的细微差别之外,它们之间并没有什么不同。
如果两个值的类型不同,我们就需要考虑有没有强制类型转换的必要,有就用==,没有就用===,不用在乎性能。
和=都会检查操作数的类型。区别在于操作数类型不同时它们的处理方式不同, 会进行强制类型转换,而=不会。
宽松不相等(loose not-equality)! =就是的相反值,! 同理
1.字符串和数字之间的相等比较(将字符串转化为数字进行比较)
(1) 如果Type(x)是数字,Type(y)是字符串,则返回x == ToNumber(y)的结果。
(2) 如果Type(x)是字符串,Type(y)是数字,则返回ToNumber(x) == y的结果。
2.其他类型和布尔类型之间的相等比较(布尔值转化为数字进行比较)
(1) 如果Type(x)是布尔类型,则返回ToNumber(x) == y的结果;
(2) 如果Type(y)是布尔类型,则返回x == ToNumber(y)的结果。
3. null和undefined之间的相等比较
**在中null和undefined相等(它们也与其自身相等),除此之外其他值都不存在这种情况。
4.对象和非对象之间的相等比较(将对象转化为基本数据类型进行比较)
(1) 如果Type(x)是字符串或数字,Type(y)是对象,则返回x == ToPrimitive(y)的结果;
(2) 如果Type(x)是对象,Type(y)是字符串或数字,则返回ToPrimitive(x) == y的结果。
5.安全运用隐式强制类型转换
• 如果两边的值中有true或者false,千万不要使用**。
• 如果两边的值中有[]、""或者0,尽量不要使用==。完整比较图:-
红色:===
-
橙色:==
-
黄色:<= 和 >= 同时成立,== 不成立
-
蓝色:只有 >=
-
绿色:只有 <=
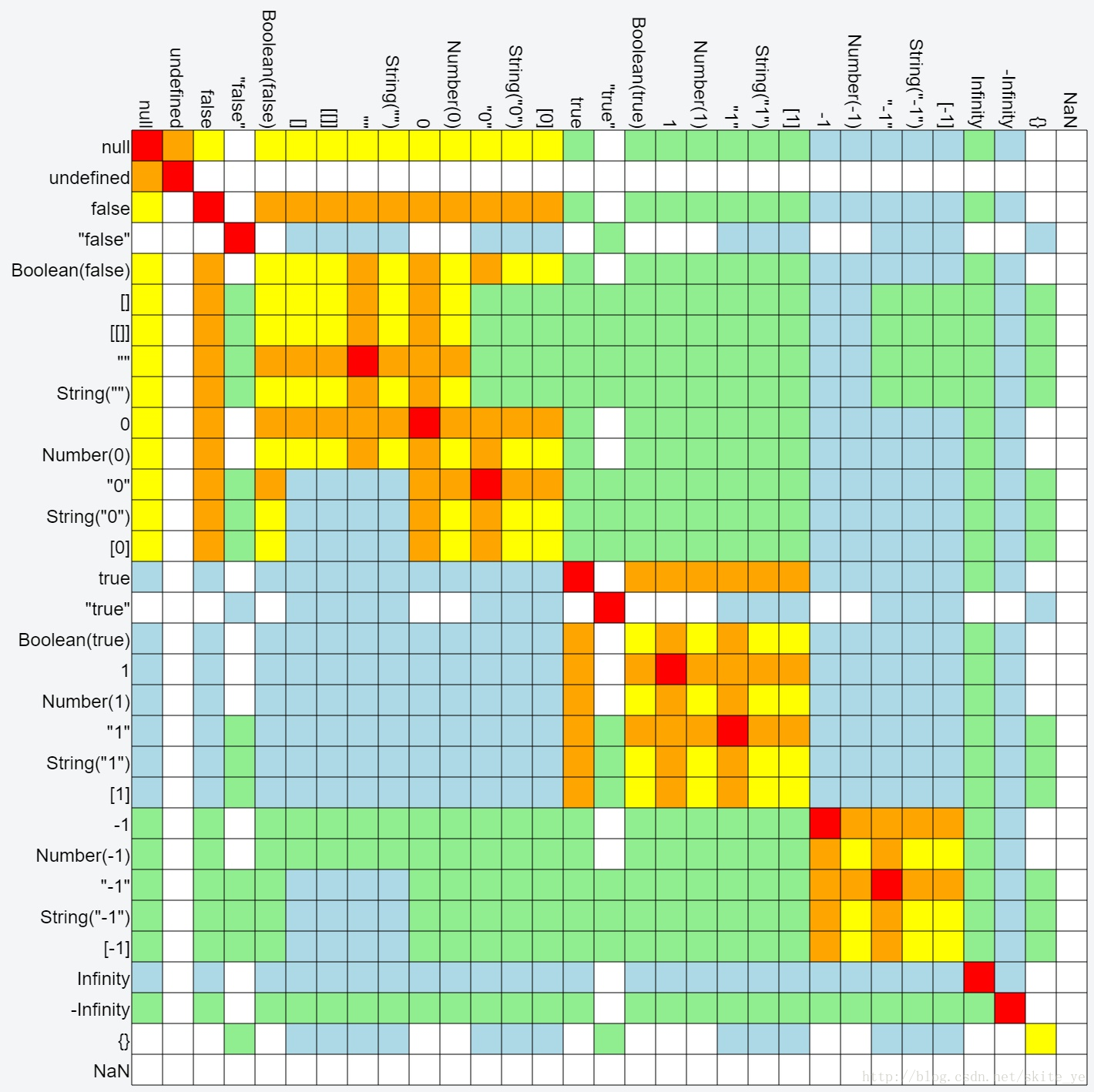
-
-
抽象关系比较
a < b中涉及的隐式强制类型转换不太引人注意,不过还是很有必要深入了解一下。“抽象关系比较”(abstract relational comparison),分为两个部分:比较双方都是字符串(后半部分)和其他情况(前半部分)。该算法仅针对a < b, a=""> b会被处理为b < a比较双方首先调用ToPrimitive,如果结果出现非字符串,就根据ToNumber规则将双方强制类型转换为数字来进行比较。var a = [42]; var b = ["43"]; a < b // true b < a // false如果比较双方都是字符串,则按字母顺序来进行比较
var a = ["42"]; var b = ["043"]; a < ba和b并没有被转换为数字,因为ToPrimitive返回的是字符串,所以这里比较的是"42"和"043"两个字符串,它们分别以"4"和"0"开头。因为"0"在字母顺序上小于"4",所以最后结果为false。
var a = { b: 42 }; var b = { b: 43 }; a < b 结果还是false,因为a是[object Object], b也是[object Object](Object.prototype.toString()获得[[Class]]属性值),所以按照字母顺序a < b并不成立。
1.11 循环
我们经常需要重复执行一些操作。
例如,我们需要将列表中的商品逐个输出,或者运行相同的代码将数字 1 到 10 逐个输出。
循环 是一种重复运行同一代码的方法。
- for
- forEach
- do…while
- while
- for…in
- for…of
- for…in vs for…of
for
const list = ['a', 'b', 'c']
for (let i = 0; i < list.length; i++) {
console.log(list[i]) //value
console.log(i) //index
}
- 您可以使用break中断for循环
- 您可以使用continue继续for循环的下一次迭代
forEach
在ES5中引入。给定一个数组,您可以使用list.forEach()迭代其属性:
const list = ['a', 'b', 'c']
list.forEach((item, index) => {
console.log(item) //value
console.log(index) //index
})
//index is optional
list.forEach(item => console.log(item))
不过需要注意的是你无法摆脱这个循环。
do…while
const list = ['a', 'b', 'c']
let i = 0
do {
console.log(list[i]) //value
console.log(i) //index
i = i + 1
} while (i < list.length)
您可以使用break中断while循环:
do {
if (something) break
} while (true)
你可以使用continue跳转到下一个迭代:
do {
if (something) continue
//do something else
} while (true)
while
const list = ['a', 'b', 'c']
let i = 0
while (i < list.length) {
console.log(list[i]) //value
console.log(i) //index
i = i + 1
}
您可以使用break中断while循环:
while (true) {
if (something) break
}
你可以使用continue跳转到下一个迭代:
while (true) {
if (something) continue
//do something else
}
与do…while的区别在于do…while总是至少执行一次循环。
for…in
迭代对象的所有可枚举属性,给出属性名称。
for (let property in object) {
console.log(property) //property name
console.log(object[property]) //property value
}
for…of
ES2015引入了for循环,它结合了forEach的简洁性和破解能力:
//iterate over the value
for (const value of ['a', 'b', 'c']) {
console.log(value) //value
}
//get the index as well, using `entries()`
for (const [index, value] of ['a', 'b', 'c'].entries()) {
console.log(index) //index
console.log(value) //value
}
注意使用const。此循环在每次迭代中创建一个新范围,因此我们可以安全地使用它而不是let。
for…in VS FOR…OF
与for…in的区别在于:
- for…of 迭代属性值
- for…in 迭代属性名称
二. 深入学习
2.1 作用域和闭包
2.1.2 编译原理
传统的编译语言中,程序中的一段源代码在执行之前会经历三个步骤,被称为”编译“
- 分词/词法分析(Tokenizing/Lexing)
这个过程会将由字符组成的字符串分解成(对编程语言来说)有意义的代码块,这些代码块被称为词法单元(token)。例如,考虑程序var a = 2;。这段程序通常会被分解成为下面这些词法单元:var、a、=、2 、;。空格是否会被当作词法单元,取决于空格在这门语言中是否具有意义。 - 解析/语法分析(Parsing)
这个过程是将词法单元流(数组)转换成一个由元素逐级嵌套所组成的代表了程序语法结构的树。这个树被称为“抽象语法树”(Abstract Syntax Tree, AST)。var a = 2;的抽象语法树中可能会有一个叫作VariableDeclaration的顶级节点,接下来是一个叫作Identifier(它的值是a)的子节点,以及一个叫作AssignmentExpression的子节点。AssignmentExpression节点有一个叫作NumericLiteral(它的值是2)的子节点。 - 代码生成
将AST转换为可执行代码的过程被称为代码生成。这个过程与语言、目标平台等息息相关。抛开具体细节,简单来说就是有某种方法可以将var a = 2;的AST转化为一组机器指令,用来创建一个叫作a的变量(包括分配内存等),并将一个值储存在a中。
JavaScript引擎要复杂得多,在语法分析和代码生成阶段有特定的步骤来对运行性能进行优化,包括对冗余元素进行优化等。
2.1.3 理解作用域
重要概念
- 引擎从头到尾负责整个JavaScript程序的编译及执行过程。
- 编译器引擎的好朋友之一,负责语法分析及代码生成等脏活累活。
- 作用域引擎的另一位好朋友,负责收集并维护由所有声明的标识符(变量)组成的一系列查询,并实施一套非常严格的规则,确定当前执行的代码对这些标识符的访问权限。
var a = 2;
针对上述的代码语句,编译器将执行下述处理逻辑
- 遇到var a,编译器会询问作用域是否已经有一个该名称的变量存在于同一个作用域的集合中。如果是,编译器会忽略该声明,继续进行编译;否则它会要求作用域在当前作用域的集合中声明一个新的变量,并命名为a。
- 接下来编译器会为引擎生成运行时所需的代码,这些代码被用来处理a = 2这个赋值操作。引擎运行时会首先询问作用域,在当前的作用域集合中是否存在一个叫作a的变量。如果是,引擎就会使用这个变量;如果否,引擎会继续查找该变量。如果引擎最终找到了a变量,就会将2赋值给它。否则引擎就会举手示意并抛出一个异常!总结:变量的赋值操作会执行两个动作,首先编译器会在当前作用域中声明一个变量(如果之前没有声明过),然后在运行时引擎会在作用域中查找该变量,如果能够找到就会对它赋值。
引擎和作用域的对话
function foo(a){
console.log(a);
}
foo(2);
让我们把上面这段代码的处理过程想象成一段对话,这段对话可能是下面这样的。
引擎:我说作用域,我需要为foo进行RHS引用。你见过它吗?
-
作用域:别说,我还真见过,编译器那小子刚刚声明了它。它是一个函数,给你。
-
引擎:哥们太够意思了!好吧,我来执行一下foo。
-
引擎:作用域,还有个事儿。我需要为a进行LHS引用,这个你见过吗?
-
作用域:这个也见过,编译器最近把它声名为foo的一个形式参数了,拿去吧。
-
引擎:大恩不言谢,你总是这么棒。现在我要把2赋值给a。
-
引擎:哥们,不好意思又来打扰你。我要为console进行RHS引用,你见过它吗?
-
作用域:咱俩谁跟谁啊,再说我就是干这个。这个我也有,console是个内置对象。给你。
-
引擎:么么哒。我得看看这里面是不是有log(…)。太好了,找到了,是一个函数。
-
引擎:哥们,能帮我再找一下对a的RHS引用吗?虽然我记得它,但想再确认一次。
-
作用域:放心吧,这个变量没有变动过,拿走,不谢。
-
引擎:真棒。我来把a的值,也就是2,传递进log(…)。
LHS和RHS
LHS 和 RHS是对变量的两种查找操作,查找的过程是由作用域(词法作用域)进行协助,在编译的第二步中执行。
LHS(Left-hand Side)引用和RHS(Right-hand Side)引用。通常是指等号(赋值运算)的左右边的引用。
RHS的目的是取得源值
LHS是取得源引用
function foo(a){
var b = a;
return a + b;
}
var c = foo(2);
- LHS找到c
- RHS寻找foo(2)的值
- 把2赋值给a时,LHS找到a
- var b = a时候, LHS找到b, RHS找到a
- return a + b时候,RHS找到a和b
所以一共3次LHS,3次RHS
2.1.4作用域嵌套
当一个块或函数嵌套在另一个块或函数中时,就发生了作用域的嵌套。因此,在当前作用域中无法找到某个变量时,引擎就会在外层嵌套的作用域中继续查找,直到找到该变量,或抵达最外层的作用域(也就是全局作用域)为止。
function foo(a) {
console.log(a+b);
}
var b = 2;
foo(2);
对b进行的RHS引用无法在函数foo内部完成,但可以在上一级作用域(在这个例子中就是全局作用域)中完成。
因此,回顾一下引擎和作用域之间的对话,会进一步听到:
- 引擎:foo的作用域兄弟,你见过b吗?我需要对它进行RHS引用。
- 作用域:听都没听过,走开。
- 引擎:foo的上级作用域兄弟,咦?有眼不识泰山,原来你是全局作用域大哥,太好了。你见过b吗?我需要对它进行RHS引用。
- 作用域:当然了,给你吧。遍历嵌套作用域链的规则很简单:引擎从当前的执行作用域开始查找变量,如果找不到,就向上一级继续查找。当抵达最外层的全局作用域时,无论找到还是没找到,查找过程都会停止。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SZ5Nfcbq-1604914071618)(/img/作用域查找.jpg)]
这个建筑代表程序中的嵌套作用域链。第一层楼代表当前的执行作用域,也就是你所处的位置。建筑的顶层代表全局作用域。LHS和RHS引用都会在当前楼层进行查找,如果没有找到,就会坐电梯前往上一层楼,如果还是没有找到就继续向上,以此类推。一旦抵达顶层(全局作用域),可能找到了你所需的变量,也可能没找到,但无论如何查找过程都将停止。
为什么区分LHS和RHS
因为在变量没有声明(在任何作用域中都无法找到该变量)的情况下,这两种查询的行为是不一样的
function foo(a){
console.log(a+b);
b = a;
}
foo(2);
第一次对b进行RHS查询时是无法找到该变量的。也就是说,这是一个“未声明”的变量,因为在任何相关的作用域中都无法找到它。如果RHS查询在所有嵌套的作用域中遍寻不到所需的变量,引擎就会抛出ReferenceError异常。值得注意的是,ReferenceError是非常重要的异常类型。相较之下,当引擎执行LHS查询时,如果在顶层(全局作用域)中也无法找到目标变量,全局作用域中就会创建一个具有该名称的变量,并将其返还给引擎,前提是程序运行在非“严格模式”下。“不,这个变量之前并不存在,但是我很热心地帮你创建了一个。”
ES5中引入了“严格模式”。同正常模式,或者说宽松/懒惰模式相比,严格模式在行为上有很多不同。其中一个不同的行为是严格模式禁止自动或隐式地创建全局变量。因此,在严格模式中LHS查询失败时,并不会创建并返回一个全局变量,引擎会抛出同RHS查询失败时类似的ReferenceError异常。接下来,如果RHS查询找到了一个变量,但是你尝试对这个变量的值进行不合理的操作,比如试图对一个非函数类型的值进行函数调用,或者引用null或undefined类型的值中的属性,那么引擎会抛出另外一种类型的异常,叫作TypeError。ReferenceError同作用域判别失败相关,而TypeError则代表作用域判别成功了,但是对结果的操作是非法或不合理的。
总结
作用域是一套规则,用于确定在何处以及如何查找变量(标识符)。
如果查找的目的是对变量进行赋值,那么就会使用LHS查询;如果目的是获取变量的值,就会使用RHS查询。赋值操作符会导致LHS查询。=操作符或调用函数时传入参数的操作都会导致关联作用域的赋值操作。
JavaScript引擎首先会在代码执行前对其进行编译,在这个过程中,像var a = 2这样的声明会被分解成两个独立的步骤:
- 首先,var a在其作用域中声明新变量。这会在最开始的阶段,也就是代码执行前进行。
- 接下来,a = 2会查询(LHS查询)变量a并对其进行赋值。LHS和RHS查询都会在当前执行作用域中开始,如果有需要(也就是说它们没有找到所需的标识符),就会向上级作用域继续查找目标标识符,这样每次上升一级作用域(一层楼),最后抵达全局作用域(顶层),无论找到或没找到都将停止。不成功的RHS引用会导致抛出ReferenceError异常。不成功的LHS引用会导致自动隐式地创建一个全局变量(非严格模式下),该变量使用LHS引用的目标作为标识符,或者抛出ReferenceError异常(严格模式下)。
2.1.5 词法作用域
词法作用域就是定义在词法分析阶段的作用域
作用域查找会在找到第一个匹配的标识符时停止, 在多层的嵌套作用域中可以定义同名的标识符,这叫做”遮蔽效应“(内部的标识符遮蔽了外部的标识符)。
无论函数在哪里调用,也无论它如何被调用,它的词法作用域都只由函数被声明时所处的位置决定。
词法作用域只会查找一级标识符,比如a, b, c,类似于foo.bar.baz,词法作用域只会试图查找foo标识符,找到这个变量后,对象属性访问规则会分别接管对bar和baz属性的访问。
注意
通过eval和with可以做到欺骗词法,但是会导致性能大大降低,因此我们应该尽量避免使用eval和with
2.1.6 函数作用域
属于这个函数的全部变量都可以在这个函数的范围内使用(在嵌套的作用域中也可以访问),这能够充分利用JavaScript变量可以根据需要动态改变值的特性。
隐藏内部实现
我们可以从缩写的代码中挑选出任意一个小片段,然后用函数声明对它进行包装,也就是说这段代码中涉及到的变量或者函数都将绑定在这个新创建的包装函数的作用域中。
最小授权原则: 在软件设计中,应该最小限度地暴露必要的内容,而将其他内容都”隐藏“起来,比如某个某个模块或者对象的API的设计
规避冲突
”隐藏“作用域中的变量和函数所带来的另一个好处,是可以避免同名标识符之间的冲突,两个标识符可能具有相同的名字但用途却不一样,无意间可能造成命名冲突,冲突会导致变量的值被恶意修改。
function foo(){
function bar(a){
i = 3;
console.log(a + i);
}
for(var i = 0; i < 10; i++){
bar(i * 2);
}
}
上述代码因为变量冲突导致了死循环
全局命名空间
很多第三方库在全局作用域中声明一个名字足够独特的变量,通常是一个对象,这个对象被用作库的命名空间,所有需要暴露给外界的功能都会成为这个对象(命名空间)的属性,而不是将自己的标识符暴露在顶级的词法作用域中。
比如:
var jQuery = (function(){
return {
addClass(){},
removeClass(){}
...
}
});
模块管理
另外一种避免全局冲突的方法是使用模块机制,如Seajs, require.js,commonjs等,这写工具并没有违反词法作用域规则,而是强制所有标识符都不能注入到共享作用域中,而是保持在私有的,无冲突的作用中。
2.1.7 函数声明,函数表达式,匿名函数
区分函数声明和表达式最简单的方法是看function关键字出现在声明中的位置(不仅仅是第一行代码, 而是整个声明中的位置),如果function是声明中的第一个词,则为函数声明,否则就是一个函数表达式。
如以下两段代码
var a = 2;
function foo(){
var a = 3;
console.log(a);
}
foo();
console.log(a);
var a =2 ;
(function(){
var a = 3;
console.log(a);
})();
console.log(a);
第1段代码必须显示声明函数foo并显示调用,污染了所在的作用域
第2段代码为一个函数表达式,并使用匿名函数免除了对所在作用域的污染
回调函数中的匿名函数表达式
setTimeout(function(){
console.log("I wanted 1 second!!");
});
上述代码使用setTimeout的回调函数使用了匿名函数表达式
匿名函数表达式写起来非常简单快捷,但是同时也存在几个缺点:
- 在追踪堆栈中不会显示出有意义的函数名,使得调试困难。
- 如果没有函数名,就只能通过过时的arguments.callee引用自身
- 函数名对于代码的可读性、可理解性很重要
始终给函数表达式添加函数名是最佳实践
setTimeout(function timeoutHandler(){
console.log("I wanted 1 second!!!");
});
2.1.8 立即执行函数(IIFE, Immediately invoked Function Expression)
由于函数被包含在一对()括号内部,因此成为了一个表达式,通过在末尾加上另外一个()可以立即执行这个函数,比如(function foo(){ … })()。第一个()将函数变成表达式,第二个()执行了这个函数。
IIFE传递参数
var a = 2;
(function(global){
var a = 3;
console.log(a);
console.log(global.a);
})(window);
console.log(a);
我们将window对象的引用传递进去,但将参数命名为global,因此在代码风格上对全局对象的引用变得比引用一个没有“全局”字样的变量更加清晰。当然可以从外部作用域传递任何你需要的东西,并将变量命名为任何你觉得合适的名字。这对于改进代码风格是非常有帮助的。
IIFE运行顺序的倒置,UMD代码封装用到
(function(def){
def(window);
})(function(global){
var a = 3;
console.log(a);
console.log(global.a);
});
2.1.9 块作用域
下述两段代码暴露了一些问题
for(var i=0; i<10; i++){
console.log(i);
}
var foo = true;
if(foo){
var bar = foo * 2;
bar = something(bar);
console.log(bar);
}
for循环的循环变量会暴露到外部作用域,而不是只被限制在了for循环的范围内
而if内的变量声明也会暴露到外部作用域中
因此我们需要块作用域的存在
with
with的使用会创建出一个块级作用域
try/catch
非常少有人会注意到JavaScript的ES3规范中规定try/catch的catch分句会创建一个块作用域,其中声明的变量仅在catch内部有效
let
到目前为止,我们知道JavaScript在暴露块作用域的功能中有一些奇怪的行为。如果仅仅是这样,那么JavaScript开发者多年来也就不会将块作用域当作非常有用的机制来使用了。
幸好,ES6改变了现状,引入了新的let关键字,提供了除var以外的另一种变量声明方式。let关键字可以将变量绑定到所在的任意作用域中(通常是{ … }内部)。换句话说,let为其声明的变量隐式地劫持了所在的块作用域。
const
除了let以外,ES6还引入了const,同样可以用来创建块作用域变量,但其值是固定的(常量)。之后任何试图修改值的操作都会引起错误。
2.1.10 提升
提升只会发生在函数声明和变量声明,函数表达式不会发生提升
console.log(foo());
console.log(foo1()); // TypeError
console.log(str); // undefined
function foo(){
return "hello foo";
}
var foo1 = function() {
return "hello foo1"
}
var str = "hello str";
在提升过程中,函数声明比变量声明优先级高
foo();
function foo(){
console.log("1");
}
var foo = function(){
console.log("2");
}
上述代码发生提升后
function foo(){
console.log("1");
}
foo();
2.1.11 作用域和闭包
闭包就是能够读取其他函数内部变量的函数。例如在javascript中,只有函数内部的子函数才能读取局部变量,所以闭包可以理解成“定义在一个函数内部的函数“。在本质上,闭包是将函数内部和函数外部连接起来的桥梁。
当函数可以记住并访问所在的词法作用域,即使函数是在当前词法作用域之外执行,这时就产生了闭包。
// 打印5个5,因为5个匿名函数使用的i都为全局作用域的i,而setTimeout的回调函数会在for循环执行完成之后执行
for(var i = 0; i < 5; i++){
setTimeout(function(){
console.log(i);
});
}
// 正常打印0,1,2,3,4,5,使用IIFE创建新的作用域,每个匿名函数产生闭包
for(var i = 0; i < 5; i++){
(function(i){
setTimeout(function(){
console.log(i);
});
})(i);
}
// 正常打印0,1,2,3,4,5, 使用let创建块级作用域,只在for循环内才能访问到i
for(let i = 0; i < 5; i++){
setTimeout(function(){
console.log(i);
});
}
模块
var CommonUtils = (function(){
var str = "common utils";
function printStr(){
console.log(str);
}
return {
printStr: printStr
}
})();
CommonUtils.printStr();
IIFE匿名函数内部return回模块的公共API, 内部函数引用了外部作用域的变量,这样便构成了一个模块
现代的模块机制
一个简单的例子
var Modules = (function Manager(){
var modules = {};
function define(name, deps, impl){
for(var i = 0; i < deps.length; i++){
deps[i] = modules[deps[i]];
}
modules[name] = impl.apply(impl, deps);
}
function get(name){
return modules[name];
}
return {
define: define,
get: get
}
})();
Modules.define("bar", [], function(){
function hello(who){
return "Let me introduce: " + who;
}
return {
hello: hello
}
})
Modules.define("foo", ["bar"], function(bar){
var hungry = "hippo";
function awesome(){
console.log(bar.hello(hungry).toUpperCase());
}
return {
awesome: awesome
};
});
var bar = Modules.get("bar");
var foo = Modules.get("foo");
console.log(bar.hello("hippo"));
foo.awesome();
2.2 this
当一个函数被调用的时候,引擎会创建执行上下文,用来记录函数在哪里被调用(调用栈),函数的调用方式,传入的参数信息,this就是这些记录的一个属性。this是在调用时候被绑定的,完全取决于函数的调用位置。
我们分析一下下述代码中的调用栈
function baz(){
// 当前调用栈为: baz
console.log("baz");
bar(); // <-- bar 的调用位置
}
function bar(){
// 当前调用栈为baz -> bar
console.log("bar");
foo(); // <-- foo 的代用位置
}
function foo(){
// 当前调用栈为baz -> bar -> foo
console.log("foo");
}
baz(); // <-- baz的调用位置
我们可以把调用栈想象为一个函数调用链,我们也可以在每个函数内添加断点利用浏览器的开发者恐惧来得到调用栈。
2.2.1 this的绑定规则
-
默认绑定
函数直接调用,即不通过点操作符进行调用,非严格模式下,this指向window, 严格模式下为undefined -
隐式绑定
调用位置如果被某个对象拥有或者包含function foo(){ console.log(this.a); } var obj = { a: 2, foo: foo } obj.foo();上述代码foo函数被调用时候调用位置会使用obj上下文来引用函数,因此我们可以说函数被调用时,obj对象拥有或者包含它
对象属性引用链可能包含多级属性引用,调用位置会把最后一层作为上下文来引用函数如
obj1.obj2.foo()会使用obj2作为foo函数调用时候的是上下文。
隐式丢失function foo(){ console.log(this.a); } var obj = { a: 2, foo: foo }; var bar = obj.foo; var a = 'oops, global'; bar();上述代码中,虽然bar是obj.foo的一个引用,它引用的是foo函数本身,因此此时bar()其实是一个函数的直接调用,因此会采用默认绑定规则。
回调函数中也会发生隐式赋值,fn也只是引用foo函数本身,因此执行时候也是等同于函数的直接低啊用,会采用默认绑定规则
function foo(){ console.log(this.a); } function doFoo(fn){ fn(); } var obj = { a: 2, foo: foo }; var a = "oops, global"; doFoo(obj.foo); -
显示绑定(使用call和apply)
从this的绑定角度上来说,call和apply是一样的,二者不同点体现在其他参数上-
硬绑定
function foo(something){ console.log(this.a, something); return this.a + something; } var obj = { a:2 }; var bar = function(){ return foo.apply(obj, arguments); } var b = bar(3); console.log(b); -
创建一个可以复用的辅助函数
function foo(something){ console.log(this.a, something); return this.a + something; } var obj = { a:2 }; function bind(fn, obj){ return function(){ return fn.apply(obj, arguments); } } var obj = { a: 2 }; var bar = bind(foo, obj); var b = bar(3); console.log(b);我们也可以使用ES5提供的内置的方法Function.prototype.bind
-
-
new绑定
在JavaScript中,构造函数只是一些使用new操作符调用的普通函数, 其实并不存在构造函数的调用,而是对于函数的"构造调用"
使用new来调用函数,或者说发生构造函数调用时,会自动执行下面的操作:- 创建一个全新的对象
- 这个新对象会被执行**[[Prototype]]**连接
- 这个新对象会绑定到函数调用的this
- 如果函数没有返回其他对象,那么new表达式中的函数调用会自动返回这个新对象
2.2.2 this绑定规则的优先级
显示绑定优先级高于隐式绑定
function foo(){
console.log(this.a);
}
var obj1 = {
a: 2,
foo: foo
};
var obj2 = {
a: 3,
foo: foo
};
obj1.foo();
obj2.foo();
obj1.foo.call(obj2);
obj2.foo.call(obj1);
new绑定优先级高于隐式绑定优先级
function foo(something){
this.a = something;
}
var obj1 = {
foo: foo
};
var obj2 = {};
// 隐式绑定
obj1.foo(2);
console.log(obj1.a); // 2
// 显示绑定
obj1.foo.call(obj2, 3);
console.log(obj2.a); // 3
// new 绑定
var bar = new obj1.foo(4);
console.log(obj1.a); // 2
console.log(bar.a) /// 4
new绑定和显示绑定的比较
New不能和call,apply一起使用,我们使用硬绑定来测试它们的优先级
function foo(something){
this.a = something;
}
var obj1 = {};
// 将foo函数的this应绑定到this上面
var bar = foo.bind(obj1);
bar(2);
console.log(obj1.a); // 2
var baz = new bar(3);
console.log(obj1.a); // 2
console.log(baz.a); // 3
new bar(3)并没有像我们预计的那样把obj1.a修改为3,而是修改了硬绑定(到obj1)调用bar中的this,创建了一个新的对象
判断this
- 函数是否使用new调用,如果是的话this绑定的是新创建的对象
- 函数是否通过call, apply显示绑定或者通过bind函数硬绑定调用,如果是的话,this绑定的是指定的对象
- 函数是否在某个上下文调用(隐式绑定),如果是的话,this绑定的是那个上下文对象
- 如果都不是的话,使用默认绑定,如果在严格模式下, 就绑定到undefined,否则绑定到全局对象。
绑定中的一些特殊情况
-
把null,undefined作为绑定的对象传入call,apply或者bind,这些值在调用时会被忽略,实际应用的是默认绑定规则(比如在进行函数柯里化或者this指向不重要的时候)
然而,总是使用null来忽略this绑定可能产生一些副作用,如果某个函数确实使用了this,那默认绑定规则会把this绑定到全局对象(在浏览器中这个对象是window),这将导致不可预计的结果(比如修改全局对象)
-
更安全的this
我们使用一个空的委托对象(或者叫非军事区对象DMZ: demilitarized zone)来表达我们希望this为空的意图function foo(a, b){ console.log("a: " + a + ",b: " + b); } var ø = Object.create(null); foo.apply(ø, [2, 3]); var bar = foo.bind(ø, 2); bar(3);
软绑定
硬绑定可以把this强制绑定到指定的对象(除了使用new时),防止函数调用应用默认绑定规则,但是硬绑定会大大降低函数的灵活性,使用硬绑定之后就无法使用隐式绑定或者显示绑定来修改this的指向了。
如果可以给默认绑定指定一个全局对象和undefined以外的值,那就可以实现和硬绑定相同的效果,同时保留隐式绑定或者显示绑定修改this的能力。
可以使用一种称为软绑定的方法来实现我们想要的结果:
if(! Function.prototype.softBind ){
Function.prototype.softBind = function(obj){
var fn = this;
var curried = [].slice.call(arguments, 1);
var bound = function(){
return fn.apply(
(!this || this === (window || global))? obj : this,
curried.concat.apply(curried, arguments)
);
}
bound.prototype = Object.create(fn.prototype);
return bound;
}
}
function foo(){
console.log("name: " + this.name);
}
var obj = { name: "obj" },
obj2 = { name: "obj2" },
obj3 = { name: "obj3" };
var fooOBJ = foo.softBind(obj);
fooOBJ(); // name: obj
fooOBJ.call(obj2) // name: obj2
obj2.foo = foo.softBind(obj);
obj2.foo(); // name: obj2
setTimeout(obj2.foo, 10); // name: obj
2.2.3 箭头函数的this绑定规则
function foo(){
return (a) => {
console.log(this.a);
}
}
var obj1 = {
a: 2
};
var obj2 = {
a: 3
};
var bar = foo.call(obj1);
bar.call(obj2);
foo()内部创建的箭头函数会捕获调用时foo()的this。由于foo()的this绑定到obj1,bar(引用箭头函数)的this也会绑定到obj1, 箭头函数的绑定无法被修改。(new也不行)
回调函数中使用箭头函数
function foo1(){
setTimeout(() => {
console.log(this.a);
}, 100);
}
var obj = {
a:2
};
foo1.call(obj);
2.3 对象
对象的两种定义方式:
- 使用对象字面量{}
- 使用构造函数Object
2.3.1 类型
JS包括六种主要类型
string, number, boolean, null, undefined, object
内置对象
内置对象表现形式像其他语言中的type或者class,但是在JS中,它们实际上只是一些内置函数,它们可以当做构造函数(使用new来调用), 从而构造一个对应子类型的新对象。
2.3.2 对象属性
对象的内容由一些存储在特定命名位置(任意类型)值组成,它们就是对象的属性,表现形式上属性好像存储在对象内部,但是在引擎内部这些值的存储方式是多种多样的,一般不会存在对象容器内,存储在对象容器内部的是这些属性的名称,它们就像指针(引用),指向这些值的真正的存储位置。
属性的访问方式
var myObj = {
a: 2
};
myObj.a // 属性访问
myObj['a'] // 键访问
ES6新增了可计算属性名
myObj: { [prefix + 'bar']: "hello"}
数组
数组可以只用数组字面量[]或者Array构造函数来声明
var arr = [] or var arr = new Array()
数组元素类型没有限制,如果试图向数组添加一个属性,但是属性名看起来像一个数字,那它会作为下标
var arr['0'] = 'hello'
2.3.3 对象复制
对于JSON安全 (可以被序列化一个JSON字符串并且可以根据这个字符串解析出一个结构和值完全一样的对象)的对象来说,可以使用
var obj1 = JSON.parse(JSON.stringify(obj));
ES6提供了Object.assign实现浅复制
Object.assign({}, obj)
2.3.4 属性描述符
ES5提供了属性描述符来描述属性的特性(值value, 可写writable, 可枚举enumerable(决定属性是否能被for…in循环和Object.keys()遍历到), 可配置configurable)
我们可以使用**Object.defineProperty()**来定义属性或者修改属性
var obj = {};
Object.defineProperty(obj, "name", {
value: 2,
writable: true,
configurable: true,
enumerable: true
});
configurable属性代表可配置性
值为false的话,不可以使用delete进行属性删除, 可以把writable由true改为false, 不能由false改为true
对象常量
结合writable: false和configurable: false就可以创建一个真正的属性常量(不可修改,重定义或者删除)
var obj = {};
Object.defineProperty(obj, "FAVORITE NUMBER", {
value: 2,
writable: false,
configurable: false
});
禁止扩展
禁止一个对象添加新属性并且保留已有属性,可以使用Object.preventExtensions()
在严格模式下会抛出TypeError, 非严格模式下静默失败
密封
在Object.preventExtensions()的基础上把现有所有属性设置为configurable: false可以使用 Object.seal()
密封后不仅不能添加新属性,也不能重新配置或者删除任何现有属性(可以修改属性的值)
冻结
Object.freeze() 在密封基础上把现有所有属性设置为writable: false
禁止对于对象本身及其任意直接属性的修改(不过,这个对象引用的其他对象是不受影响的), 如果要实现
深度冻结则需要遍历调用Object.freeze()
const objDeepFreeze = (obj) => {
if(!obj) throw new TypeError("被冻结对象不能为空");
if(typeof obj !== 'object') throw new TypeError("被冻结目标必须是对象");
Object.freeze(obj);
for(const key in obj){
const value = obj[key];
if( typeof value === 'object' ){
dhelper.objDeepFreeze(value);
}
}
};
2.3.5 setter和getter
1.通过对象初始化器在创建对象的时候指明(也可以称为通过字面值创建对象时声明)
(function () {
var o = {
a : 7,
get b(){return this.a +1;},//通过 get,set的 b,c方法间接性修改 a 属性
set c(x){this.a = x/2}
};
console.log(o.a);
console.log(o.b);
o.c = 50;
console.log(o.a);
})();
2.使用 Object.create 方法
(function () {
var o = null;
o = Object.create(Object.prototype,//指定原型为 Object.prototype
{
bar:{
get :function(){
return this.a;
},
set : function (val) {
console.log("Setting `o.a` to ",val);
this.a = val;
}
}
}//第二个参数
);
console.log(o.a);
o.a = 12;
console.log(o.a);
})();
Object.prototype也可以替换成想要继承的原型对象,如var o = {a: 10};
3.使用 Object.defineProperty 方法
(function () {
var o = { a : 1}//声明一个对象,包含一个 a 属性,值为1
Object.defineProperty(o,"b",{
get: function () {
return this.a;
},
set : function (val) {
this.a = val;
},
configurable : true
});
console.log(o.b);
o.b = 2;
console.log(o.b);
})();
4.使用 Object.defineProperties方法
(function () {
var obj = {a:1,b:"string"};
Object.defineProperties(obj,{
"A":{
get:function(){return this.a+1;},
set:function(val){this.a = val;}
},
"B":{
get:function(){return this.b+2;},
set:function(val){this.b = val}
}
});
console.log(obj.A);
console.log(obj.B);
obj.A = 3;
obj.B = "hello";
console.log(obj.A);
console.log(obj.B);
})();
5.使用 Object.prototype.defineGetter 以及 Object.prototype.defineSetter 方法
(function () {
var o = {a:1};
o.__defineGetter__("giveMeA", function () {
return this.a;
});
o.__defineSetter__("setMeNew", function (val) {
this.a = val;
})
console.log(o.giveMeA);
o.setMeNew = 2;
console.log(o.giveMeA);
})();
2.3.6 使用in 或者 hasOwnProperty判断属性存在性
属性返回值可能为undefined,但是这个undefined可能是属性中存储的undefined也可能是因为属性不存在所以返回undefined,可以使用hasOwnProperty函数来区分这两种情况
var myObj = { a: 2 };
console.log("a" in myObj);
console.log(myObj.hasOwnProperty("a"));
如果通过Object.create(null)来创建对象,原型没有连接到Object.prototype,这种情况下可以使用更强硬的方法来进行判断:
Object.prototype.hasOwnProperty.call(myObj, 'a');
它借用了基础的hasOwnProperty()方法并把它显示绑定到myObj上
注意
in操作符是判断某个属性名是否存在,对于数组[2,4,6], 属性名为0,1,2,因此4 in [2,4,6]会得到false值
一些常用的属性操作函数
- obj.propertyIsEnumable()检查给定属性是否可枚举
- Object.keys()会返回一个数组,包含所有可枚举属性
- Object.getOwnPropertyNames()会返回一个数组,包含所有属性,无论他们是否可以枚举
- Object.keys()和Object.getOwnPropertyNames()都只会查找对象直接包含的属性,不会查找原型链[[Prototype]]
- in和hasOwnProperty的区别在于是否查找原型链, in会查找原型链, hasOwnProperty不会查找原型链
- 目前没有内置方法获取in操作符使用的属性列表(对象本身的属性及原型链中的属性),我们可以递归某个对象的整条原型链并保存每一层中使用Object.keys()得到的属性列表—只包含可枚举属性。
2.3.7 对象的遍历
- for…in循环可以用来遍历对象的可枚举属性列表(包括[[Prototype]]链)
- 对于数值索引的数组来说,可以使用标准的for循环来遍历值:
- ES5中增加了一些数组的辅助迭代器,包括forEach(…)、every(…)和some(…)。每种辅助迭代器都可以接受一个回调函数并把它应用到数组的每个元素上,唯一的区别就是它们对于回调函数返回值的处理方式不同。forEach(…)会遍历数组中的所有值并忽略回调函数的返回值。every(…)会一直运行直到回调函数返回false(或者“假”值), some(…)会一直运行直到回调函数返回true(或者“真”值)。every(…)和some(…)中特殊的返回值和普通for循环中的break语句类似,它们会提前终止遍历
- 遍历数组下标时候采用的数字顺序,但是遍历对象属性时的顺序是不确定的,在不同的JavaScript引擎中可能不一样,因此,在不同的环境中需要保证一致性时,一定不要相信任何观察到的顺序,它们是不可靠的。
- ES6增加了一种用来遍历数组的for…of循环语法(如果对象本身定义了迭代器的话也可以遍历对象):
2.4 类, 继承, 混入
类不是JS必须的编程基础,而是一种可选的代码抽象。JS实际上并没有类,类只是一种设计模式,我们可以使用一些方法来实现近似类的功能,为了满足对于类设计模式的最普遍的需求,JavaScript提供了一些近似类的语法。
2.4.1 类的机制
类和实例
一个类就是一张蓝图,为了获得真正可以交互的对象,我们必须按照类来建造(也可以说实例化)一个东西,这个东西通常称为实例,有需要的话,我们可以直接在实例上调用方法并访问其所有公有的数据属性。这个对象就是类中描述的所有特性的一份副本。
构造函数
类的实例由一个特殊的类方法构造,这个方法名通常和类名相同,被称为构造函数,这个方法的任务就是初始化实例需要的所有信息(状态)
2.4.2 类的继承
JS中 类的声明有两种形式:
// 类的声明
function Animal() {
this.name = 'name'
}
// ES6中的class声明
class Animal2 {
constructor() {
this.name = name;
}
}
而实例化类,就是一个简单的 new 就完了
// 实例化
console.log(new Animal(), new Animal2());
-
原型链继承
/** * 将原型对象赋值为另一个类型的实例,原型对象将包含一个指向另一个原型的指针 * 构成实例与原型的链条 */ function Person(){ this.name = "person"; this.arr = [1,2,3]; } function Child(){ this.type = "child"; } // 将子类的原型对象赋值为父类的实例 Child.prototype = new Person(); console.log(new Child().__proto__.__proto__.constructor); // Function Person // 原型对象是共用的 var s1 = new Child(); var s2 = new Child(); s1.arr.push(4); console.log(s1.arr, s2.arr);注意
通过原型链实现继承时候,不能使用对象字面量创建原型方法,因为这样会重写原型链
这种继承方式会实现为各个实例共享原型对象, 且在创建子类型的时候不能向超类型的构造函数中传递参数。 -
构造函数方式继承
用子类型的构造函数内部调用要继承的父类的构造函数,构造函数去继承构造函数,不存在共享和无法传递参数的问题了。function Person(){ this.name = "person"; this.arr = [1,2,3]; } function Child(){ this.type = "child"; // 调用超类的构造函数,构造函数继承了构造函数 Person.call(this); } Person.prototype.sayName = function(){ return "person"; } console.log(new Child()); var s1 = new Child(); var s2 = new Child(); s1.arr.push(4); console.log(s1.arr, s2.arr); // TypeError: s1.sayName is not a function console.log(s1.sayName());最大优势是可以在调用超累的构造函数时候传递参数
问题是:无法继承原型中的方法和属性, 且因为使用构造函数来实现,创建每个实例时候,超类的方法和属性都要在每个实例上重新创建一遍,性能损耗严重。 -
组合继承
将原型链继承和构造函数继承相结合进行使用,原型链继承来实现对原型链上方法和属性的继承(实现属性和方法的共用),构造函数继承实现对实例属性的继承(实现私有的实例化),这样既实现了原型上方法和属性的复用,又能够保证每个实例有自己的属性。function Person(){ this.name = "person"; } function Child(){ this.type = "child"; // 构造函数继承, 第一次调用Person() Person.call(this); } // 原型链继承,第二次调用Person() Child.prototype = new Person(); var p = new Person(); var c = new Child(); console.log(p.constructor); // [Function: Person] console.log(c.constructor); // [Function: Person] // 修复constructor的指向,否则无法继承后无法区分p和c的具体类型 Child.prototype.constructor = Child; console.log(p.constructor); // [Function: Person] console.log(c.constructor); // [Function: Child]这种方式的最大问题是要调用两次超类的构造函数
组合继承的优化
优化步骤1/** * 针对两次调用超类构造函数的问题优化版本1 * 修改原型链继承方式,作为继承超类原型来用, * 完善借用构造函数继承无法继承到超类原型的缺点 */ function Person(){ this.name = "person"; } function Child(){ this.type = "child"; Person.call(this); } // 子类的原型指向了超类的原型 Child.prototype = Person.prototype; var s = new Child(); // 无法区分s的具体类型了 console.log(s instanceof Child, s instanceof Person); // true, true console.log(s.constructor); // [Function: Person]优化步骤2
/** * 针对两次调用超类构造函数的问题优化版本2 * 修改子类的constructor指向 * 利用Object.create() 去 创建中间对象从而将子类和超类区分开; */ function Person(){ this.name = "person"; } function Child(){ this.type = "child"; Person.call(this); } // 利用Object.create来作为中间链,将子类和超类区分开,且保持正确的链接 Child.prototype = Object.create(Person.prototype); // 修复constructor指向 Child.prototype.constructor = Child; var s = new Child(); console.log(s instanceof Child, s instanceof Person); // true, true console.log(s.constructor); // [Function: Person] -
基于Object.create()函数的原型继承
Object.create函数规范化了原型继承,这个函数接收两个参数,第一个参数为原型对象,第二个参数为为新对象定义的额外属性的对象var person = { name: "david", friends: ["Shelly", "Court", "Van"] }; var person1 = Object.create(person); person1.name = "person1 name"; person1.friends.push("Rob"); var person2 = Object.create(person); person2.name = "person2 name"; person2.friends.push("Barbie"); console.log(person.friends); console.log(person1.friends); console.log(person2.friends); console.log(person.name); console.log(person1.name); console.log(person2.name);Object.create中继承的参数的内容并不是直接放到子类中,而是存在与子类的原型中; 所以会出现覆盖(实例属性覆盖继承的原型属性)和共享属性的特征(如上例中的person.friends)
-
寄生式继承
与原型式继承紧密相关的一种思路,即创建一个用于封装过程的函数,该函数在内部以某种方式增强对象,最后就像真的是它做了所有工作一样返回对象。function createAnother(origin){ var clone = Object.create(origin); clone.sayHi = function(){ console.log("hi"); } return clone; } var person = { name: "david", friends: ["Sheldy", "Court", "Van"] }; var anotherPerson = createAnother(person); anotherPerson.friends.push("tom"); console.log(anotherPerson.friends); console.log(person.friends); anotherPerson.sayHi();使用寄生继承来为对象添加函数,不能做到函数复用而降低性能,这一点与构造函数继承类似
-
寄生组合继承
function inheritPrototype(subtype, supertype){ // 以超类的原型对象为参数创建新对象,新对象的原型链接到超类的原型 var middle = Object.create(supertype.prototype); // 中间对象的构造函数指定为子类的构造函数 middle.constructor = subtype; // 指定middle为子类的原型对象 subtype.prototype = middle; } function SuperType(name){ this.name = name; this.colors = ["red", "blue", "green"]; } SuperType.prototype.sayName = function () { console.log(this.name); } function SubType(name, age){ // 调用父类的构造函数,完成实例属性的继承 SuperType.call(this, name); this.age = age; } // 需先完成原型继承(这一步从父类原型链上继承来所有方法和属性),然后再扩展子类的原型,否则会覆盖掉在SubType.prototype上面定义的方法 inheritPrototype(SubType, SuperType); SubType.prototype.sayAge = function(){ console.log(this.age); } var instance1 = new SubType("Nicholas", 29); instance1.colors.push("black"); instance1.sayName(); instance1.sayAge(); console.log(instance1.colors); var instance2 = new SubType("Greg", 27); instance2.sayName(); instance2.sayAge(); console.log(instance2.colors); -
ES6 class使用extends完成继承
class Polygon { constructor(height, width) { this.name = "Polygon"; this.height = height; this.width = width; } sayName() { console.log("Hi, I am a ", this.name + "."); } } class Square extends Polygon { constructor(length) { super(length, length); this.name = "Square"; } get area() { return this.height * this.width; } set area(value) { this.area = value; } } var mySquare = new Square(4, 4); console.log(mySquare);
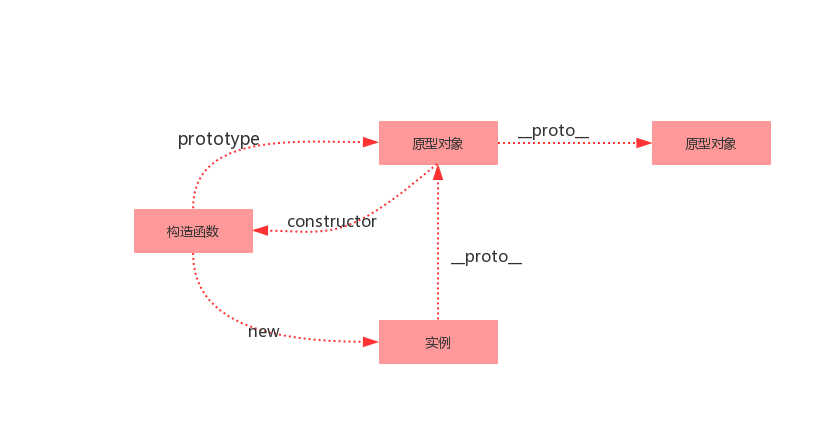
2.5 原型和原型链
JavaScript中的对象有一个特殊的[[Prototype]]内置属性,其实就是对于其他对象的引用。几乎所有的对象在创建时[[Prototype]]属性都会被赋予一个非空的值。
当你通过各种语法进行属性查找时都会查找[[Prototype]]链,直到找到属性或者查找完整条原型链。
但是到哪里是[[Prototype]]的“尽头”呢?
所有普通的[[Prototype]]链最终都会指向内置的Object.prototype。由于所有的“普通”(内置,不是特定主机的扩展)对象都“源于”(或者说把[[Prototype]]链的顶端设置为)这个Object.prototype对象,所以它包含JavaScript中许多通用的功能。
一、prototype
在JavaScript中,每个函数都有一个prototype属性,这个属性指向函数的原型对象。
例如:
function Person(age) {
this.age = age
}
Person.prototype.name = 'kavin'
var person1 = new Person()
var person2 = new Person()
console.log(person1.name) //kavin
console.log(person2.name) //kavin
上述例子中,函数的prototype指向了一个对象,而这个对象正是调用构造函数时创建的实例的原型,也就是person1和person2的原型。
原型的概念:每一个javascript对象(除null外)创建的时候,就会与之关联另一个对象,这个对象就是我们所说的原型,每一个对象都会从原型中“继承”属性。
让我们用一张图表示构造函数和实例原型之间的关系:

二、proto
这是每个对象(除null外)都会有的属性,叫做__proto__,这个属性会指向该对象的原型。
function Person() {
}
var person = new Person();
console.log(person.__proto__ === Person.prototype); // true
而关系图:

补充说明:
绝大部分浏览器都支持这个非标准的方法访问原型,然而它并不存在于 Person.prototype 中,实际上,它是来自于 Object.prototype ,与其说是一个属性,不如说是一个 getter/setter,当使用 obj.proto 时,可以理解成返回了 Object.getPrototypeOf(obj)。
三、constructor
每个原型都有一个constructor属性,指向该关联的构造函数。
function Person() {
}
console.log(Person===Person.prototype.constructor) //true
所以再更新下关系图:

function Person() {
}
var person = new Person();
console.log(person.__proto__ == Person.prototype) // true
console.log(Person.prototype.constructor == Person) // true
// 顺便学习一个ES5的方法,可以获得对象的原型
console.log(Object.getPrototypeOf(person) === Person.prototype) // true
补充说明:
function Person() {
}
var person = new Person();
console.log(person.constructor === Person); // true
当获取 person.constructor 时,其实 person 中并没有 constructor 属性,当不能读取到constructor 属性时,会从 person 的原型也就是 Person.prototype 中读取,正好原型中有该属性,所以:
person.constructor === Person.prototype.constructor
四、实例与原型
当读取实例的属性时,如果找不到,就会查找与对象关联的原型中的属性,如果还查不到,就去找原型的原型,一直找到最顶层为止。
function Person() {
}
Person.prototype.name = 'Kevin';
var person = new Person();
person.name = 'Daisy';
console.log(person.name) // Daisy
delete person.name;
console.log(person.name) // Kevin
在这个例子中,我们给实例对象 person 添加了 name 属性,当我们打印 person.name 的时候,结果自然为 Daisy。
但是当我们删除了 person 的 name 属性时,读取 person.name,从 person 对象中找不到 name 属性就会从 person 的原型也就是 person.proto ,也就是 Person.prototype中查找,幸运的是我们找到了 name 属性,结果为 Kevin。
但是万一还没有找到呢?原型的原型又是什么呢?
五、原型的原型
在前面,我们已经讲了原型也是一个对象,既然是对象,我们就可以用最原始的方式创建它,那就是:
var obj = new Object();
obj.name = 'Kevin'
console.log(obj.name) // Kevin
其实原型对象就是通过 Object 构造函数生成的,结合之前所讲,实例的 proto 指向构造函数的 prototype ,所以我们再更新下关系图:

六、原型链
简单的回顾一下构造函数、原型和实例的关系:每个构造函数都有一个原型对象,原型对象都包含一个指向构造函数的指针,而实例都包含一个指向原型对象的内部指针。那么假如我们让原型对象等于另一个类型的实例,结果会怎样?显然,此时的原型对象将包含一个指向另一个原型的指针,相应地,另一个原型中也包含着一个指向另一个构造函数的指针。假如另一个原型又是另一个类型的实例,那么上述关系依然成立。如此层层递进,就构成了实例与原型的链条。这就是所谓的原型链的基本概念。——摘自《javascript高级程序设计》
其实简单来说,就是上述四-五的过程。
继上述五中所说,那 Object.prototype 的原型呢?
console.log(Object.prototype.__proto__ === null) // true
所以查找属性的时候查到 Object.prototype 就可以停止查找了。
最后一张关系图也可以更新为:

图中由相互关联的原型组成的链状结构就是原型链,也就是蓝色的这条线。
七. 属性的设置和屏蔽
给一个对象设置属性并不仅仅是添加一个新属性或者修改已有的属性。
myObject.foo = "bar"
-
如果myObject对象中包含名为foo的普通数据访问属性,这条赋值语句只会修改已有的属性值。
-
如果foo不是直接存在于myObject中,[[Prototype]]链就会被遍历,类似[[Get]]操作。如果原型链上找不到foo, foo就会被直接添加到myObject上。然而,如果foo存在于原型链上层,赋值语句myObject.foo = "bar"的行为就会有些不同(而且可能很出人意料)。稍后我们会进行介绍
-
如果属性名foo既出现在myObject中也出现在myObject的[[Prototype]]链上层,那么就会发生屏蔽。myObject中包含的foo属性会屏蔽原型链上层的所有foo属性,因为myObject.foo总是会选择原型链中最底层的foo属性。屏蔽比我们想象中更加复杂。下面我们分析一下如果foo不直接存在于myObject中而是存在于原型链上层时myObject.foo = "bar"会出现的三种情况。
-
如果在[[Prototype]]链上层存在名为foo的普通数据访问属性(参见第3章)并且没有被标记为只读(writable:false),那就会直接在myObject中添加一个名为foo的新属性,它是屏蔽属性。
"use strict" function Person(name){ this.name = name; } Object.defineProperty(Person.prototype, "type", { value: "person", writable: true }); function Student(name, classNo){ Person.call(this, name); this.classNo = classNo; } Student.prototype = Object.create(Person.prototype); Student.prototype.constructor = Student; var s = new Student("david", 1); s.type = "student"; // TypeError: Cannot assign to read only property 'type' of object '#<Student>' console.log(s.type); // student -
如果在[[Prototype]]链上层存在foo,但是它被标记为只读(writable:false),那么无法修改已有属性或者在myObject上创建屏蔽属性。如果运行在严格模式下,代码会抛出一个错误。否则,这条赋值语句会被忽略。总之,不会发生屏蔽。
"use strict" function Person(name){ this.name = name; } Object.defineProperty(Person.prototype, "type", { value: "person", writable: false }); function Student(name, classNo){ Person.call(this, name); this.classNo = classNo; } Student.prototype = Object.create(Person.prototype); Student.prototype.constructor = Student; var s = new Student("david", 1); s.type = "student"; // TypeError: Cannot assign to read only property 'type' of object '#<Student>' console.log(s.type); -
如果在[[Prototype]]链上层存在foo并且它是一个setter(参见第3章),那就一定会调用这个setter。foo不会被添加到(或者说屏蔽于)myObject,也不会重新定义foo这个setter。
"use strict" function Person(name){ this.name = name; this._type = "person"; } Object.defineProperty(Person.prototype, "type", { get(){ return this._type }, set(val){ console.log("setter: " + val); this._type = val; } }); function Student(name, classNo){ Person.call(this, name); this.classNo = classNo; } Student.prototype = Object.create(Person.prototype); Student.prototype.constructor = Student; var s = new Student("david", 1); s.type = "student"; console.log(s.type);
-
2.6 行为委托
下面是一个行为委托的小例子
var Task = {
setId: function(ID){
this.id = ID;
},
outputID: function(){
console.log(this.id)
}
};
// 将XYZ对象委托给Task
var XYZ = Object.create(Task);
XYZ.prepareTask = function(ID, Label){
this.setId(ID);
this.label = Label;
}
XYZ.outputTaskDetails = function(){
this.outputID();
console.log(this.label);
}
XYZ.prepareTask(11, "javascript");
XYZ.outputTaskDetails();
// ABC = Object.create(Task);
// ABC ...
在这段代码中,Task和XYZ并不是类(或者函数),它们是对象。XYZ通过Object. create(…)创建,它的[[Prototype]]委托了Task对象(参见第5章)。
相比于面向类(或者说面向对象),这种编码风格称为“对象关联”(OLOO, objectslinked to other objects)。我们真正关心的只是XYZ对象(和ABC对象)委托了Task对象。
对象关联风格的代码还有一些不同之处
- 在上面的代码中,id和label数据成员都是直接存储在XYZ上(而不是Task)。通常来说,在[[Prototype]]委托中最好把状态保存在委托者(XYZ、ABC)而不是委托目标(Task)上。
- 在类设计模式中,我们故意让父类(Task)和子类(XYZ)中都有outputTask方法,这样就可以利用重写(多态)的优势。在委托行为中则恰好相反:我们会尽量避免在[[Prototype]]链的不同级别中使用相同的命名,否则就需要使用笨拙并且脆弱的语法来消除引用歧义(参见第4章)。这个设计模式要求尽量少使用容易被重写的通用方法名,提倡使用更有描述性的方法名,尤其是要写清相应对象行为的类型。这样做实际上可以创建出更容易理解和维护的代码,因为方法名(不仅在定义的位置,而是贯穿整个代码)更加清晰(自文档)。
- this.setID(ID); XYZ中的方法首先会寻找XYZ自身是否有setID(…),但是XYZ中并没有这个方法名,因此会通过[[Prototype]]委托关联到Task继续寻找,这时就可以找到setID(…)方法。此外,由于调用位置触发了this的隐式绑定规则(参见第2章),因此虽然setID(…)方法在Task中,运行时this仍然会绑定到XYZ,这正是我们想要的。在之后的代码中我们还会看到this.outputID(),原理相同。换句话说,我们和XYZ进行交互时可以使用Task中的通用方法,因为XYZ委托了Task。委托行为意味着某些对象(XYZ)在找不到属性或者方法引用时会把这个请求委托给另一个对象(Task)。
这是一种极其强大的设计模式,和父类、子类、继承、多态等概念完全不同。在你的脑海中对象并不是按照父类到子类的关系垂直组织的,而是通过任意方向的委托关联并排组织的。
下面再看一个例子
function Foo(who){
this.me = who;
}
Foo.prototype.identity = function(){
return "I am " + this.me;
}
function Bar(who){
Foo.call(this, who);
}
Bar.prototype = Object.create(Foo.prototype);
Bar.prototype.speak = function(){
console.log("Hello, " + this.identity() + ".");
}
var b1 = new Bar("b1");
var b2 = new Bar("b2");
b1.speak();
b2.speak();
上面的代码是典型的类设计模式的实现代码,下面用行为委托来进行改写
// 用行为委托来进行改写
var Foo = {
init: function(who){
this.me = who;
},
identity: function(){
return "I am " + this.me;
}
};
var Bar = Object.create(Foo);
Bar.speak = function(){
console.log("Hello, " + this.identity() + ".");
};
var b1 = Object.create(Bar);
b1.init("b1");
var b2 = Object.create(Bar);
b2.init("b2");
b1.speak();
b2.speak();
一个登陆控制的例子
类设计模式写法
function Controller(){
this.errors = [];
}
Controller.prototype.showDialog = function(title, msg){
window.alert(title + msg);
}
Controller.prototype.success = function(msg){
this.showDialog("Success", msg);
}
Controller.prototype.failure = function(err){
this.errors.push(err);
this.showDialog("Error", err);
}
function LoginController(){
Controller.call(this);
}
LoginController.prototype = Object.create(Controller.prototype);
LoginController.prototype.constructor = LoginController;
LoginController.prototype.getUser = function(){
return document.getElementById("username").value;
}
LoginController.prototype.getPassword = function(){
return document.getElementById("password").value;
}
LoginController.prototype.validateEntry = function(user, pw){
user = user || this.getUser();
pw = pw || this.getPassword();
if(!(user && pw)){
return this.failure("Please enter a username & password!");
} else if(pw.length < 5){
return this.failure("Password must be 5+ characters!");
}
return this.success("login success!!!");
};
LoginController.prototype.failure = function(err){
Controller.prototype.failure.call(this, "Login invalid: " + err);
};
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<script src="./登陆控制(类设计模式写法).js"></script>
</head>
<body>
<form action="#" onsubmit="return onSubmit()">
<input type="text" name="username" id="username">
<input type="password" name="password" id="password">
<input type="submit" value="submit">
</form>
<script>
function onSubmit(){
var lc = new LoginController();
lc.validateEntry();
return false;
}
</script>
</body>
</html>
行为委托写法
var Controller = {
errors: [],
showDialog: function(title, msg) {
window.alert(title + msg);
},
success: function(msg) {
this.showDialog("Success", msg);
},
failure: function(err) {
this.errors.push(err);
this.showDialog("Error", err);
},
};
// 将LoginController委托给Controller
var LoginController = Object.create(Controller);
Object.defineProperties(LoginController, {
getUser: {
value: function() {
return document.getElementById("username").value;
},
},
getPassword: {
value: function() {
return document.getElementById("password").value;
},
},
validateEntry: {
value: function(user, pw) {
user = user || this.getUser();
pw = pw || this.getPassword();
if (!(user && pw)) {
return this.failure("Please enter a username & password!");
} else if (pw.length < 5) {
return this.failure("Password must be 5+ characters!");
}
return this.success("login success!!!");
},
},
});
总结
行为委托认为对象之间是兄弟关系,互相委托,而不是父类和子类的关系。JavaScript的[[Prototype]]机制本质上就是行为委托机制。也就是说,我们可以选择在JavaScript中努力实现类机制(参见第4和第5章),也可以拥抱更自然的[[Prototype]]委托机制。
2.6 异步和性能
2.6.1 事件循环
(1)JS为何设计为单线程
js设计为单线程还是跟他的用途有关
试想一下 如果js设计为多线程 那么同时修改和删除同一个dom 浏览器又该如何执行?
#JS为何需要异步
for (var i=0;i<9999;i++){
console.log("我在执行 但用户不知道")
}
console.log("你好啊")
上图例子 for循环耗时会很久
这意味着 用户得不到 ‘你好啊’ 的响应 就会下意识会认为浏览器卡死了 所以js必须要有异步
js通过事件循环来实现异步 这也是js的运行机制
(2)JS事件的循环
1.归类
遇到同步任务直接执行,遇到异步任务分类为宏任务(macro-task)和微任务(micro-task)。
宏任务:整体的Script setTimeout setInterval
微任务:Promise process.nextTick
示例代码
// 这是一个同步任务
console.log('1') --------> 直接被执行
目前打印结果为:1
// 这是一个宏任务
setTimeout(function () { --------> 整体的setTimeout被放进宏任务列表
console.log('2') 目前宏任务列表记为【s2】
});
new Promise(function (resolve) {
// 这里是同步任务
console.log('3'); --------> 直接被执行
resolve(); 目前打印结果为:1、3
// then是一个微任务
}).then(function () { --------> 整体的then[包含里面的setTimeout]被放进微任务列表
console.log('4') 目前微任务列表记为【t45】
setTimeout(function () {
console.log('5')
});
});
第一轮小结:
执行到这里的结果:1、3
宏任务列表如下:
setTimeout(function () {
console.log('2')
});
微任务列表如下:
then(function () {
console.log('4')
setTimeout(function () {
console.log('5')
});
});
住:promise对象详解:http://es6.ruanyifeng.com/#docs/promise
2.有微则微,无微则宏
如果微任务列表里面有任务 会执行完毕后在执行宏任务。
浏览器瞅了一眼微任务列表 发现里面有微任务 就开始全部执行
then(function () {
console.log('4') --------> 直接被执行
目前打印结果为:1、3、4
setTimeout(function () { --------> 被放进宏任务列表了
console.log('5') 目前宏任务列表记为【s2、s5】
});
});
浏览器发现微任务执行完毕了
开始执行宏任务列表
setTimeout(function () {
console.log('2') --------> 直接被执行
目前打印结果为:1、3、4、2
});
setTimeout(function () {
console.log('5') --------> 直接被执行
目前打印顺序为: 1、3、4、2、5、5
});
最终结果为: 1、3、4、2、5
3.总结 + 实战
反复执行以上步骤 就是事件循环(event loop) 一定要分的清任务类型 (宏任务 和 微任务)
TIP: 为了容易辨别起名为p1(p开头 里面打印1)
process.nextTick(function() { --------> 被放微任务列表
console.log('1'); 微任务列表记为:【p1】
})
new Promise(function (resolve) {
console.log('2'); --------> 直接执行
resolve(); 目前打印顺序为:2
}).then(function () { --------> 整体的then被放进微任务列表[包含其中的setTimeout 4]
console.log('3'); 微任务列表记为:【p1 t34】
setTimeout(function () {
console.log('4')
});
});
setTimeout(function () { --------> 被放宏任务列表
console.log('5') 宏任务列表记为:【s5】
});
new Promise(function (resolve) {
setTimeout(function () { --------> 被放宏任务列表
console.log('6') 宏任务列表记为:【s5 s6】
});
resolve()
}).then(function () { --------> 整体的then被放进微任务列表[包含其中的setTimeout和其中的多层嵌套]
setTimeout(function () { 微任务列表记为:【p1 t34 t789】
console.log('7')
new Promise(function (resolve) {
setTimeout(function () {
console.log('8')
});
resolve()
}).then(function () {
setTimeout(function () {
console.log('9')
});
});
});
});
console.log('10') --------> 直接执行
目前打印顺序为:2、10
第一轮小结:
执行结果为:2、10
宏任务列表如下:
// s5
setTimeout(function () {
console.log('5')
});
//s6
setTimeout(function () {
console.log('6')
});
微任务列表如下:
// p1
process.nextTick(function() {
console.log('1');
})
// t34
then(function () {
console.log('3');
setTimeout(function () {
console.log('4')
});
});
// t789
then(function () {
setTimeout(function () {
console.log('7')
new Promise(function (resolve) {
setTimeout(function () {
console.log('8')
});
resolve()
}).then(function () {
setTimeout(function () {
console.log('9')
});
});
});
开始执行第二轮:
有微任务 先执行微任务
将微任务列表代码块搬下来
// p1
process.nextTick(function() { --------> 执行p1
console.log('1'); 目前打印顺序为:2、10、1
})
// t34
then(function () {
console.log('3'); --------> 直接执行
目前打印顺序为:2、10、1、3
setTimeout(function () { --------> 被放宏任务列表
console.log('4') 宏任务列表记为:【s5 s6 s4】
});
});
// t789
then(function () {
setTimeout(function () { --------> 被放宏任务列表
console.log('7') 宏任务列表记为:【s5 s6 s4 s789】
new Promise(function (resolve) {
setTimeout(function () {
console.log('8')
});
resolve()
}).then(function () {
setTimeout(function () {
console.log('9')
});
});
});
})
微任务执行完毕了 该执行我们的宏任务列表了
因为微任务里面包含一部分宏任务
所以现在的宏任务列表已经增加了
现在把当前的宏任务列表搬下来
//s5
setTimeout(function () { --------> 执行s5
console.log('5') 目前打印顺序为:2、10、1、3、5
});
//s6
setTimeout(function () { --------> 执行s6
console.log('6') 目前打印顺序为:2、10、1、3、5、6
});
//s4
setTimeout(function () { --------> 执行s4
console.log('4') 目前打印顺序为:2、10、1、3、5、6、4
});
// s789
setTimeout(function () { --------> 执行s789
console.log('7') 目前打印顺序为:2、10、1、3、5、6、4、7
new Promise(function (resolve) {
setTimeout(function () { --------> 被放宏任务列表
console.log('8') 宏任务列表记为:【s8】
});
resolve()
}).then(function () { --------> 整体的then被放微任务列表[包含里面的setTimeout]
setTimeout(function () { 微任务列表记为:【t9】
console.log('9')
});
});
});
再次小结:
当前结果:2、10、1、3、5、6、4、7
马上就要执行完了心里万分激动啊 ( 浏览器的内心独白 ^▽^ ...)
宏任务列表如下:
// s8
setTimeout(function () {
console.log('8')
});
微任务列表如下:
// t9
then(function () {
setTimeout(function () {
console.log('9')
});
});
继续执行 依旧遵循有微则微 无微则宏
浏览器发现有一条微任务
那就开始执行吧~
//t9
then(function () {
setTimeout(function () { --------> 执行t9 把里面的setTimeout放入宏任务列表
console.log('9') 宏任务列表记为:【s8 s9】
});
});
微任务列表执行完毕
开始执行宏任务(宏任务刚刚又有新增哦~[s9])
// s8
setTimeout(function () { --------> 执行s8
console.log('8') 目前打印顺序为:2、10、1、3、5、6、4、7、8
});
// s9
setTimeout(function () { --------> 执行s9
console.log('9') 目前打印顺序为:2、10、1、3、5、6、4、7、8、9
});
到这里 微任务列表 和 宏任务列表均为空 就执行完毕了
2.6.2 回调
异步回调的问题
1.调用函数过早
调用函数过早的最值得让人注意的问题, 是你不小心定义了一个函数,使得作为函数参数的回调可能延时调用,也可能立即调用。 也即你使用了一个可能同步调用, 也可能异步调用的回调。 这样一种难以预测的回调。
在英语世界里, 这种可能同步也可能异步调用的回调以及包裹它的函数, 被称作是 “Zalgo” (一种都市传说中的魔鬼), 而编写这种函数的行为, 被称作是"release Zalgo" (将Zalgo释放了出来)
var a =1
zalgoFunction () {
// 这里还有很多其他代码,使得a = 2可能被异步调用也可能被同步调用
[ a = 2 ]
}
console.log(a)
结果会输出什么呢? 如果zalgoFunction是同步的, 那么a 显然等于2, 但如果 zalgoFunction是异步的,那么 a显然等于1。于是, 我们陷入了无法判断调用影响的窘境。
这只是一个极为简单的场景, 如果场景变得相当复杂, 结果又会如何呢?你可能想说: 我自己写的函数我怎么会不知道呢?很多时候这个不确定的函数来源于它人之手,甚至来源于完全无法核实的第三方代码。我们把这种不确定的情况稍微变得夸张一些: 这个函数中传入的回调, 有99%的几率被异步调用, 有1%的几率被同步调用。
2.调用次数过多
这里取《你不知道的javascript(中卷)》的例子给大家看一看:
作为一个公司的员工,你需要开发一个网上商城, payWithYourMoney是你在确认购买后执行的扣费的函数, 由于公司需要对购买的数据做追踪分析, 这里需要用到一个做数据分析的第三方公司提供的analytics对象中的purchase函数。 代码看起来像这样
analytics.purchase( purchaseData, function () {
payWithYourMoney ()
} );
在这情况下,可能我们会忽略的一个事实是: 我们已经把payWithYourMoney 的控制权完全交给了analytics.purchase函数了,这让我们的回调“任人宰割”,这种控制权的转移, 被叫做“控制反转”。
然后上线后的一天, 数据分析公司的一个隐蔽的bug终于显露出来, 让其中一个原本只执行一次的payWithYourMoney执行了5次, 这让那个网上商城的客户极为恼怒, 并投诉了你们公司。可你们公司也很无奈, 这个时候惊奇的发现: payWithYourMoney的控制完全不在自己的手里 !!!!!后来, 为了保证只支付一次, 代码改成了这样:
// 判断是否已经分析(支付)过一次了
var analysisFlag = true
analytics.purchase( purchaseData, function(){
if (!analysisFlag) {
payWithYourMoney ()
analysisFlag = false
}
} );
但是, 这种方式虽然巧妙, 但却仍不够简洁优雅(后文提到的Promise将改变这一点)。而且, 在回调函数的无数“痛点”中, 它只能规避掉一个, 如果你尝试规避掉所有的“痛点”,代码将比上面更加复杂而混乱。
3.太晚调用或根本没有调用
因为你失去了对回调的控制权, 你的回调可能会出现预期之外的过晚调用或者不调用的情况(为了处理这个“痛点”你又将混入一些复杂的代码逻辑)
4.吞掉报错
回调内的报错是可能被包裹回调的外部函数捕捉而不报错,(为了处理这个“痛点”你又又又将混入一些复杂的代码逻辑)
5.复杂情况下可读性差
请问这段代码的调用顺序 ?
doA( function(){
doB();
doC( function(){
doD();
} )
doE();
} );
doF();
让人一脸蒙逼的回调函数地狱
setTimeout(function (name) {
var catList = name + ','
setTimeout(function (name) {
catList += name + ',';
setTimeout(function (name) {
catList += name + ',';
setTimeout(function (name) {
catList += name + ',';
setTimeout(function (name) {
catList += name;
console.log(catList);
}, 1, 'Lion');
}, 1, 'Snow Leopard');
}, 1, 'Lynx');
}, 1, 'Jaguar');}, 1, 'Panther');
6.门
什么叫“门”?, 你可以大概理解成: 现在有一群人准备进屋,但只有他们所有人都到齐了,才能“进门” ,也就是: 只有所有的异步操作都完成了, 我们才认为它整体完成了,才能进行下一步操作
下面这个例子里, 我们试图通过两个异步请求操作,希望当a和b的取值都到达的时候才输出!!
var a, b;
function foo(x) {
a = x * 2;
if (a && b) {
baz();
}
}
function bar(y) {
b = y * 2;
if (a && b) {
baz();
}
}
function baz() {
console.log( a + b );
}
// ajax(..)是某个库中的某个Ajax函数
ajax( "http://some.url.1", foo );
ajax( "http://some.url.2", bar );
这段代码比前面那段“链式”里的回调地狱好懂多了,但是却依然存在这一些问题:我们使用了两个 if (a && b) { } 去分别保证baz是在a和b都到达后才执行的,试着思考一下:两个 if (a && b) { } 的判断条件是否可以合并到一起呢,因为这两个判断条件都试图表达同一种语意: a 和 b都到达, 能合并成一条语句的话岂不是更加简洁优雅 ? (一切都在为Promise做铺垫哦~~~~啦啦啦)
7.竞态
一组异步操作,其中一个完成了, 这组异步操作便算是整体完成了。在下面,我们希望通过异步请求的方式,取得x的值,然后执行foo或者bar,但希望只把foo或者bar其中一个函数执行一次
var flag = true;
function foo(x) {
if (flag) {
x = x + 1
baz(x);
flag = false
}
}
function bar(x) {
if (flag) {
x = x*2
baz(x);
flag = false
}
}
function baz( x ) {
console.log( x );
}
// ajax(..)是某个库中的某个Ajax函数
ajax( "http://some.url.1", foo );
ajax( "http://some.url.2", bar );
在这里,我们设置了一个flag, 设它的初始值为true, 这时候foo或者bar在第一次执行的时候, 是可以进入if内部的代码块并且执行baz函数的, 但在if内部的代码块结束的时候, 我们把flag的值置为false,这个时候下一个函数就无法进入代码块执行了, 这就是回调对于竞态的处理。
2.6.3 Promise
Promise 是异步编程的一种解决方案,比传统的解决方案——回调函数和事件——更合理和更强大。它由社区最早提出和实现,ES6 将其写进了语言标准,统一了用法,原生提供了Promise对象。
所谓Promise,简单说就是一个容器,里面保存着某个未来才会结束的事件(通常是一个异步操作)的结果。从语法上说,Promise 是一个对象,从它可以获取异步操作的消息。Promise 提供统一的 API,各种异步操作都可以用同样的方法进行处理。
Promise对象有以下两个特点。
(1)对象的状态不受外界影响。Promise对象代表一个异步操作,有三种状态:pending(进行中)、fulfilled(已成功)和rejected(已失败)。只有异步操作的结果,可以决定当前是哪一种状态,任何其他操作都无法改变这个状态。这也是Promise这个名字的由来,它的英语意思就是“承诺”,表示其他手段无法改变。
(2)一旦状态改变,就不会再变,任何时候都可以得到这个结果。Promise对象的状态改变,只有两种可能:从pending变为fulfilled和从pending变为rejected。只要这两种情况发生,状态就凝固了,不会再变了,会一直保持这个结果,这时就称为 resolved(已定型)。如果改变已经发生了,你再对Promise对象添加回调函数,也会立即得到这个结果。这与事件(Event)完全不同,事件的特点是,如果你错过了它,再去监听,是得不到结果的。
注意,为了行文方便,本章后面的resolved统一只指fulfilled状态,不包含rejected状态。
有了Promise对象,就可以将异步操作以同步操作的流程表达出来,避免了层层嵌套的回调函数。此外,Promise对象提供统一的接口,使得控制异步操作更加容易。
Promise也有一些缺点。首先,无法取消Promise,一旦新建它就会立即执行,无法中途取消。其次,如果不设置回调函数,Promise内部抛出的错误,不会反应到外部。第三,当处于pending状态时,无法得知目前进展到哪一个阶段(刚刚开始还是即将完成)。
如果某些事件不断地反复发生,一般来说,使用 Stream 模式是比部署Promise更好的选择。
Promise是怎么解决问题的
1.回调过早调用
让我们回到那个回调的痛点:我们有可能会写出一个既可能同步执行, 又可能异步执行的“zalgo”函数。但Promise可以自动帮我们避免这个问题:如果对一个 Promise 调用 then(…) 的时候,即使这个 Promise是立即resolve的函数(即Promise内部没有ajax等异步操作,只有同步操作), 提供给then(…) 的回调也是会被异步调用的,这帮助我们省了不少心
- 回调调用次数过多
Promise 的内部机制决定了调用单个Promise的then方法, 回调只会被执行一次,因为Promise的状态变化是单向不可逆的,当这个Promise第一次调用resolve方法, 使得它的状态从pending(正在进行)变成fullfilled(已成功)或者rejected(被拒绝)后, 它的状态就再也不能变化了。所以你完全不必担心Promise.then( function ) 中的function会被调用多次的情况 - 回调中的报错被吞掉
要说明一点的是Promise中的then方法中的error回调被调用的时机有两种情况:
- a. Promise中主动调用了reject (有意识地使得Promise的状态被拒绝), 这时error回调能够接收到reject方法传来的参数(reject(error))
- b. 在定义的Promise中, 运行时候报错(未预料到的错误), 也会使得Promise的状态被拒绝,从而使得error回调能够接收到捕捉到的错误
例如:
var p = new Promise( function(resolve,reject){
foo.bar(); // foo未定义,所以会出错!
resolve( 42 ); // 永远不会到达这里 :(
} );
p.then(
function fulfilled(){
// 永远不会到达这里 :(
},
function rejected(err){
// err将会是一个TypeError异常对象来自foo.bar()这一行
}
);
- 还有一种情况是回调根本就没有被调用,这是可以用Promise的race方法解决(下文将介绍)
// 用于超时一个Promise的工具
function timeoutPromise(delay) {
return new Promise( function(resolve,reject){
setTimeout( function(){
reject( "Timeout!" );
}, delay );
} );
}
// 设置foo()超时
Promise.race( [
foo(), // 试着开始foo()
timeoutPromise( 3000 ) // 给它3秒钟
] ).then(
function(){
// foo(..)及时完成!
},
function(err){
// 或者foo()被拒绝,或者只是没能按时完成
// 查看err来了解是哪种情况
}
);
5.链式
我们上面说了, 纯回调的一大痛点就是“金字塔回调地狱”, 这种“嵌套风格”的代码丑陋难懂,但Promise就可以把这种“嵌套”风格的代码改装成我们喜闻乐见的“链式”风格。因为then函数是可以链式调用的, 你的代码可以变成这样
Promise.then(
// 第一个异步操作
).then(
// 第二个异步操作
).then(
// 第三个异步操作
)
6.门Promise.all,竞态Promise.race见后文
基本用法
ES6 规定,Promise对象是一个构造函数,用来生成Promise实例。下面代码创造了一个Promise实例。
const promise = new Promise(function(resolve, reject) {
// ... some code
if (/* 异步操作成功 */){
resolve(value);
} else {
reject(error);
}
});
Promise构造函数接受一个函数作为参数,该函数的两个参数分别是resolve和reject。它们是两个函数,由 JavaScript 引擎提供,不用自己部署。
resolve函数的作用是,将Promise对象的状态从“未完成”变为“成功”(即从 pending 变为 resolved),在异步操作成功时调用,并将异步操作的结果,作为参数传递出去;reject函数的作用是,将Promise对象的状态从“未完成”变为“失败”(即从 pending 变为 rejected),在异步操作失败时调用,并将异步操作报出的错误,作为参数传递出去。
Promise实例生成以后,可以用then方法分别指定resolved状态和rejected状态的回调函数。
promise.then(function(value) {
// success
}, function(error) {
// failure
});
then方法可以接受两个回调函数作为参数。第一个回调函数是Promise对象的状态变为resolved时调用,第二个回调函数是Promise对象的状态变为rejected时调用。其中,第二个函数是可选的,不一定要提供。这两个函数都接受Promise对象传出的值作为参数。
下面是一个Promise对象的简单例子。
function timeout(ms) {
return new Promise((resolve, reject) => {
setTimeout(resolve, ms, 'done');
});
}
timeout(100).then((value) => {
console.log(value);
});
上面代码中,timeout方法返回一个Promise实例,表示一段时间以后才会发生的结果。过了指定的时间(ms参数)以后,Promise实例的状态变为resolved,就会触发then方法绑定的回调函数。
下面是一个用Promise对象实现的 Ajax 操作的例子。
const getJSON = function(url) {
const promise = new Promise(function(resolve, reject){
const handler = function() {
if (this.readyState !== 4) {
return;
}
if (this.status === 200) {
resolve(this.response);
} else {
reject(new Error(this.statusText));
}
};
const client = new XMLHttpRequest();
client.open("GET", url);
client.onreadystatechange = handler;
client.responseType = "json";
client.setRequestHeader("Accept", "application/json");
client.send();
});
return promise;
};
getJSON("/posts.json").then(function(json) {
console.log('Contents: ' + json);
}, function(error) {
console.error('出错了', error);
});
上面代码中,getJSON是对 XMLHttpRequest 对象的封装,用于发出一个针对 JSON 数据的 HTTP 请求,并且返回一个Promise对象。需要注意的是,在getJSON内部,resolve函数和reject函数调用时,都带有参数。
Promise.prototype.then()
前面说过,then方法的第一个参数是resolved状态的回调函数,第二个参数(可选)是rejected状态的回调函数。
then方法返回的是一个新的Promise实例(注意,不是原来那个Promise实例)。因此可以采用链式写法,即then方法后面再调用另一个then方法。
getJSON("/posts.json").then(function(json) {
return json.post;
}).then(function(post) {
// ...
});
上面的代码使用then方法,依次指定了两个回调函数。第一个回调函数完成以后,会将返回结果作为参数,传入第二个回调函数。
采用链式的then,可以指定一组按照次序调用的回调函数。这时,前一个回调函数,有可能返回的还是一个Promise对象(即有异步操作),这时后一个回调函数,就会等待该Promise对象的状态发生变化,才会被调用。
getJSON("/post/1.json").then(function(post) {
return getJSON(post.commentURL);
}).then(function funcA(comments) {
console.log("resolved: ", comments);
}, function funcB(err){
console.log("rejected: ", err);
});
上面代码中,第一个then方法指定的回调函数,返回的是另一个Promise对象。这时,第二个then方法指定的回调函数,就会等待这个新的Promise对象状态发生变化。如果变为resolved,就调用funcA,如果状态变为rejected,就调用funcB。
如果采用箭头函数,上面的代码可以写得更简洁。
getJSON("/post/1.json").then(
post => getJSON(post.commentURL)
).then(
comments => console.log("resolved: ", comments),
err => console.log("rejected: ", err)
);
Promise.prototype.catch()
Promise.prototype.catch方法是.then(null, rejection)的别名,用于指定发生错误时的回调函数。
p.then((val) => console.log('fulfilled:', val))
.catch((err) => console.log('rejected', err));
// 等同于
p.then((val) => console.log('fulfilled:', val))
.then(null, (err) => console.log("rejected:", err));
下面代码中,getJSON方法返回一个 Promise 对象,如果该对象状态变为resolved,则会调用then方法指定的回调函数;如果异步操作抛出错误,状态就会变为rejected,就会调用catch方法指定的回调函数,处理这个错误。另外,then方法指定的回调函数,如果运行中抛出错误,也会被catch方法捕获。
getJSON('/posts.json').then(function(posts) {
// ...
}).catch(function(error) {
// 处理 getJSON 和 前一个回调函数运行时发生的错误
console.log('发生错误!', error);
});
Promise.prototype.finally()
finally方法用于指定不管 Promise 对象最后状态如何,都会执行的操作。该方法是 ES2018 引入标准的。
promise
.then(result => {···})
.catch(error => {···})
.finally(() => {···});
上面代码中,不管promise最后的状态,在执行完then或catch指定的回调函数以后,都会执行finally方法指定的回调函数。
下面是一个例子,服务器使用 Promise 处理请求,然后使用finally方法关掉服务器。
server.listen(port)
.then(function () {
// ...
})
.finally(server.stop);
finally方法的回调函数不接受任何参数,这意味着没有办法知道,前面的 Promise 状态到底是fulfilled还是rejected。这表明,finally方法里面的操作,应该是与状态无关的,不依赖于 Promise 的执行结果。
Promise.all()
试想一个页面聊天系统,我们需要从两个不同的URL分别获得用户的个人信息和好友列表,这两个任务是可以并行执行的,用Promise.all()实现如下:
var p1 = new Promise(function (resolve, reject) {
setTimeout(resolve, 500, 'P1');
});
var p2 = new Promise(function (resolve, reject) {
setTimeout(resolve, 600, 'P2');
});
// 同时执行p1和p2,并在它们都完成后执行then:
Promise.all([p1, p2]).then(function (results) {
console.log(results); // 获得一个Array: ['P1', 'P2']
});
Promise.race()
有些时候,多个异步任务是为了容错。比如,同时向两个URL读取用户的个人信息,只需要获得先返回的结果即可。这种情况下,用Promise.race()实现:
var p1 = new Promise(function (resolve, reject) {
setTimeout(resolve, 500, 'P1');
});
var p2 = new Promise(function (resolve, reject) {
setTimeout(resolve, 600, 'P2');
});
Promise.race([p1, p2]).then(function (result) {
console.log(result); // 'P1'
});
由于p1执行较快,Promise的then()将获得结果’P1’。p2仍在继续执行,但执行结果将被丢弃。
2.6.4 生成器generator
生成器是一种能够暂停函数执行的函数, 使用function *定义, yield指定执行时候的暂停位置,yield会产出一个值作为it.next()的结果, yield能够接收参数并作为yield暂停处的替代值
比如下述代码
function *foo(x) {
var y = x * (yield);
return y;
}
var it = foo(6);
console.log(it.next());
var res = it.next(7);
console.log(res.value);
第一个next(…)总是启动一个生成器,并运行到第一个yield处。不过,是第二个next(…)调用完成第一个被暂停的yield表达式,第三个next(…)调用完成第二个yield,以此类推。
通过多个生成器在共享的相同变量上的迭代交替执行,会使得程序可能产生多种不同的结果
比如以下代码
var a = 1;
var b = 2;
function* foo(){
a++;
yield;
b = b * a;
a = (yield b) + 3;
}
function* bar(){
b--;
yield;
a = (yield 8) + b;
b = a * (yield 2);
}
// 以为两个生成器共享变量a和b,如果使用next()函数对两个生成器的实例进行迭代的时候的执行顺序不同会导致a和b最终的值不同,这在传统的函数中是不可能的,传统的函数是一个函数的执行必须等待上一个函数执行完毕,比如:
var a = 1;
var b = 2;
function foo(){
a++;
b = b * a;
a = b + 3;
}
function bar(){
b--;
a = 8 + b;
b = a * 2;
}
// 要么foo()先执行,要么bar()先执行,不可能交替执行
异步迭代生成器
function foo(x, y, cb){
ajax("http://some.url", cb);
}
foo(11, 31, function(err, text){
if(err){
console.error(err);
} else {
console.log(text);
}
});
使用生成器来表达同样的任务流程
function foo(x,y){
ajax("http://some.url", function(err, data){
if(err){
// 向*main()抛出一个错误
it.throw(err);
} else {
// 用收到的data回复*main()的执行
it.next(data);
}
});
}
function* main(){
try {
var text = yield foo(11, 31);
console.log(text);
}catch(err) {
console.log(err);
}
}
// 启动
vat it = main();
it.next();
// 生成器使用yield进行流程控制,实现了暂停/阻塞
同步错误处理
生成器yield暂停的特性意味着我们不仅能够从异步函数调用得到看似同步的返回值,还可以同步捕获来自这些异步函数调用的错误!在异步代码中实现看似同步的错误处理(通过try…catch)在可读性和合理性方面都是一个巨大的进步。
生成器+Promise
看似同步的异步代码(生成器)+ 可信任(Promise)是完美的搭配
// 把支持Promise的foo和生成器main放在一起
function foo(x, y){
// 返回一个Promise对象
return request("http://some.url");
}
function* main(){
try {
var text = yield foo(11, 31);
console.log(text);
}catch(err){
console.error(err);
}
}
var it = main();
var p = it.next().value;
// 监测promise状态,在promise决议后恢复生成器执行
p.then(function(text){
it.next(text);
}, function(err){
it.throw(err);
});
封装Generator Runner
function run(gen){
var args = [].slice.call(arguments, 1), it;
// 在当前上下文中初始化生成器
it = gen.apply(this, args);
// 返回一个promise用于生成器完成
return new Promise.resolve()
.then(function handleNext(value){
// 对下一个yield出的值运行
var next = it.next(value);
return (function handleResult(next){
// 判断生成器是否运行完成
if(next.done){
return next.value;
} else {
// 生成器还没有运行完成,继续运行,将promise的决议值发回生成器
return Promise.resolve(next.value)
.then(handleNext, function handleErr(err){
return Promise.resolve(it.throw(err)).
then(handleResult);
});
}
})(next);
});
}
生成器中的Promise并发
想像这样一个场景:你需要从不同的来源数据获取数据,然后把响应结合在一起以形成第三个请求,最终把最后一条响应打印出来。
function *foo(){
var result=yield Promise.all([
request("http://some.url1"),
request("http://some.url2")
]);
var [a,b]=result;
var r=yield request("http://some.url30"+a+","+b);
console.log(r);
}
run(foo);
- 使用了Promise.all()来实现了两个请求的并发。
- [a,b]是ES6的解析赋值,把var a=…var b=…赋值语句简化为var [a,b[=result。
- 最后使用了上面定义的run()来执行生成器。
生成器委托
我们可能会从一个生成器中调用另一个生成器
我们可以使用之前封装的自动运行生成器函数来实现生成器内调用其他生成器
function request(url){
return new Promise(function(resolve){
setTimeout(function(){
resolve(`${url} request success!`);
}, 1000);
});
}
function* foo(){
var r2 = yield request("http://some.url.2");
var r3 = yield request("http://some.url.3");
return [r2, r3];
}
function* bar() {
var r1 = yield request("http://some.url.1");
console.log(r1);
let [r2,r3] = yield run(foo);
console.log(r2);
console.log(r3);
}
run(bar);
我们也可以使用yield *来实现生成器委托yield *foo()
yield *暂停了迭代控制,而不是生成器控制。当你调用*foo()生成器时,现在yield委托到了它的迭代器。但实际上,你可以yield委托到任意iterable, yield *[1,2,3]会消耗数组值[1,2,3]的默认迭代器。
function* num(){
yield* [1,2,3,4,5];
}
var it = num();
console.log(it.next().value); // 1
console.log(it.next().value); // 2
console.log(it.next().value); // 3
console.log(it.next().value); // 4
console.log(it.next().value); // 5
-
生成器委托可以进行双向消息传递(利用
next()和yield) -
异常也会被委托
function *foo() { try { yield "B"; } catch(e){ console.log("error caught inside *foo():", e); } yield "C"; throw "D"; } function *bar() { yield "A"; try { yield *foo(); } catch (e) { console.log("error caught insdie *bar():", e); } yield "E"; yield *baz(); yield "G"; } function* baz(){ throw "F"; } var it = bar(); console.log("outside:", it.next().value); // outside: A console.log("outside:", it.next(1).value); // outside: B console.log("outside:", it.throw(2).value); // error caught inside *foo():2 \n outside: C console.log("outside:", it.next(3).value); // error caught inside *bar(): D \n outside: E try { cconsole.log("outside:", it.next(4).value); } catch (e) { console.log("error caught outside", e); } // error caught outside: F(1) 调用it.throw(2)时,它会发送错误消息2到*bar(),它又将其委托给*foo(),后者捕获并处理它。然后,yield "C"把"C"发送回去作为it.throw(2)调用返回的value。
(2) 接下来从*foo()内throw出来的值"D"传播到*bar(),这个函数捕获并处理它。然后yield"E"把"E"发送回去作为it.next(3)调用返回的value。
(3) 然后,从*baz() throw出来的异常并没有在*bar()内被捕获——所以*baz()和*bar()都被设置为完成状态。这段代码之后,就再也无法通过任何后续的next(…)调用得到值"G", next(…)调用只会给value返回undefined
-
并发委托
function request(){ return new Promise(function(resolve, reject){ setTimeout(function(){ resolve(`${url} request success!!`); }, 1000); }); } const runAllGen = (...genArr) = { const itArr = [], pArr = []; for(const gen of genArr){ const it = gen(); itArr.push(it); const p = it.next().value; pArr.push(p); p.then(function(data){ it.next(data); }); } Promise.all([...pArr]) .then(function(){ for(const it of itArr){ it.next(); console.log(res); } }); }; runAllgen(function *(){ var data = yield request("http://some.url.1"); yield; res.push(data); },function *(){ var data = yield request("http://some.url.2"); yield; res.push(data); },function *(){ var data = yield request("http://some.url.3"); yield; res.push(data); });
2.6.5 性能测试与调优
使用Benchmark.js和jsPerf分析代码性能
var benchmark = require("benchmark");
var suite = new benchmark.Suite;
suite.add('RegExp', function(){
/o/.test('Hello World');
})
.add('indexOf', function(){
'Hello World'.indexOf('o');
})
.on('cycle', function(event){
console.log(String(event.target));
})
.on('complete', function(){
console.log('the fasted method is' + this.filter('fastest').map('name'));
})
.run({'async': true});
/*
RegExp x 33,125,825 ops/sec ±4.06% (77 runs sampled)
indexOf x 797,631,820 ops/sec ±1.69% (87 runs sampled)
the fasted method isindexOf
*/
尾调用优化
是函数式编程一个概念,是指某个函数最后一步是调用另一个函数
function f(x){
return g(x);
}
// 上面代码中,函数f的最后一步是调用函数g,这就叫尾调用。
以下两种情况都不属于尾调用
// 情况一
function f(x){
let y = g(x);
return y;
}
// 情况二
function f(x){
return g(x) + 1;
}
上面代码中,情况一是调用函数g之后,还有别的操作,所以不属于尾调用,即使语义完全一样。情况二也属于调用后还有操作,即使写在一行内。
尾调用不一定出现在函数尾部,只要是最后一步操作即可。
function f(x) {
if (x > 0) {
return m(x)
}
return n(x);
}
函数调用会在内存生成一个”调用记录“,又称为”调用帧(call frame)“,保存调用位置和内部变量等信息,如果在函数A的内部调用函数B,那么在A的调用记录上方,还会形成一个B的调用记录。等到B运行结束,将结果返回到A,B的调用记录才会消失。如果函数B内部还调用函数C,那就还有一个C的调用记录栈,以此类推。所有的调用记录,就形成一个"调用栈"(call stack)。
尾调用由于是函数的最后一步操作,所以不需要保留外层函数的调用记录,因为调用位置、内部变量等信息都不会再用到了,只要直接用内层函数的调用记录,取代外层函数的调用记录就可以了。
function f() {
let m = 1;
let n = 2;
return g(m + n);
}
f();
// 等同于
function f() {
return g(3);
}
f();
// 等同于
g(3);
/*
上面代码中,如果函数g不是尾调用,函数f就需要保存内部变量m和n的值、g的调用位置等信息。但由于调用g之后,函数f就结束了,所以执行到最后一步,完全可以删除 f() 的调用记录,只保留 g(3) 的调用记录。
这就叫做"尾调用优化"(Tail call optimization),即只保留内层函数的调用记录。如果所有函数都是尾调用,那么完全可以做到每次执行时,调用记录只有一项,这将大大节省内存。这就是"尾调用优化"的意义。
*/
尾递归
函数调用自身,称为递归。如果尾调用自身,就称为尾递归。
递归非常耗费内存,因为需要同时保存成千上百个调用记录,很容易发生"栈溢出"错误(stack overflow)。但对于尾递归来说,由于只存在一个调用记录,所以永远不会发生"栈溢出"错误。
function factorial(n) {
if (n === 1) return 1;
return n * factorial(n - 1);
}
factorial(5) // 120
上面代码是一个阶乘函数,计算n的阶乘,最多需要保存n个调用记录,复杂度 O(n) 。
如果改写成尾递归,只保留一个调用记录,复杂度 O(1) 。
function factorial(n, total) {
if (n === 1) return total;
return factorial(n - 1, n * total);
}
factorial(5, 1) // 120
由此可见,“尾调用优化"对递归操作意义重大,所以一些函数式编程语言将其写入了语言规格。ES6也是如此,第一次明确规定,所有 ECMAScript 的实现,都必须部署"尾调用优化”。这就是说,在 ES6 中,只要使用尾递归,就不会发生栈溢出,相对节省内存。
ES6的尾调用优化只在严格模式下开启,正常模式是无效的。
这是因为在正常模式下,函数内部有两个变量,可以跟踪函数的调用栈。
arguments:返回调用时函数的参数。func.caller:返回调用当前函数的那个函数。
尾调用优化发生时,函数的调用栈会改写,因此上面两个变量就会失真。严格模式禁用这两个变量,所以尾调用模式仅在严格模式下生效。
递归函数的改写
尾递归的实现,往往需要改写递归函数,确保最后一步只调用自身。做到这一点的方法,就是把所有用到的内部变量改写成函数的参数。比如上面的例子,阶乘函数 factorial 需要用到一个中间变量 total ,那就把这个中间变量改写成函数的参数。这样做的缺点就是不太直观,第一眼很难看出来,为什么计算5的阶乘,需要传入两个参数5和1?
两个方法可以解决这个问题。方法一是在尾递归函数之外,再提供一个正常形式的函数。
function tailFactorial(n, total) { if (n === 1) return total; return tailFactorial(n - 1, n * total); } function factorial(n) { return tailFactorial(n, 1); } factorial(5) // 120
上面代码通过一个正常形式的阶乘函数 factorial ,调用尾递归函数 tailFactorial ,看起来就正常多了。
函数式编程有一个概念,叫做柯里化(currying),意思是将多参数的函数转换成单参数的形式。这里也可以使用柯里化。
function currying(fn, n) { return function (m) { return fn.call(this, m, n); }; } function tailFactorial(n, total) { if (n === 1) return total; return tailFactorial(n - 1, n * total); } const factorial = currying(tailFactorial, 1); factorial(5) // 120
上面代码通过柯里化,将尾递归函数 tailFactorial 变为只接受1个参数的 factorial 。
第二种方法就简单多了,就是采用ES6的函数默认值。
function factorial(n, total = 1) { if (n === 1) return total; return factorial(n - 1, n * total); } factorial(5) // 120
上面代码中,参数 total 有默认值1,所以调用时不用提供这个值。
总结一下,递归本质上是一种循环操作。纯粹的函数式编程语言没有循环操作命令,所有的循环都用递归实现,这就是为什么尾递归对这些语言极其重要。对于其他支持"尾调用优化"的语言(比如Lua,ES6),只需要知道循环可以用递归代替,而一旦使用递归,就最好使用尾递归。

















 316
316

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









